
热门标签
热门文章
- 1深度学习中初始化权重_tensorflow初始化权重
- 2The cost from the bebe Daniela
- 3Python 房价预测 kaggle 线性回归 SVM 神经网络 随机森林 集成模型_房价预测可以用分类模型么
- 4当 AI 冲击自动化编程,谁将成为受益者?
- 5语言模型评价指标 bpc(bits-per-character)和困惑度ppl(perplexity)
- 6嵌入式Linux学习(入门)— Vim安装、Linux常用命令_安装vim
- 7JTA transaction unexpectedly rolled back (maybe due to a timeout); 解决方法
- 8MAC 删除自带 ABC 输入法的方法_mac删除abc输入法
- 9史上最详细LRW数据集、LRW-1000数据集、LRS2数据集、LRS3-TED数据集、OuluVS2数据集介绍
- 10MaskRCNN源码解析5:损失部分解析_maskrcnn掩膜预测 损失函数
当前位置: article > 正文
基于Spark2.x新闻网大数据实时分析可视化系统项目_基于spark新闻大数据可视化分析
作者:盐析白兔 | 2024-04-07 05:35:46
赞
踩
基于spark新闻大数据可视化分析
本次项目是基于企业大数据经典案例项目(大数据日志分析),全方位、全流程讲解 大数据项目的业务分析、技术选型、架构设计、集群规划、安装部署、整合继承与开发和web可视化交互设计。
一、业务需求分析
- 捕获用户浏览日志信息
- 实时分析前20名流量最高的新闻话题
- 实时统计当前线上已曝光的新闻话题
- 统计哪个时段用户浏览量最高
二、系统架构图设计
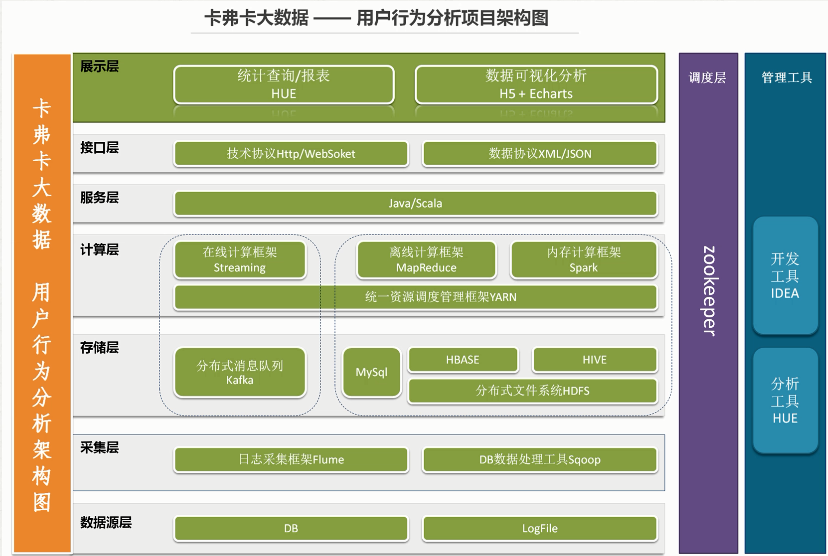
三、系统数据流程设计
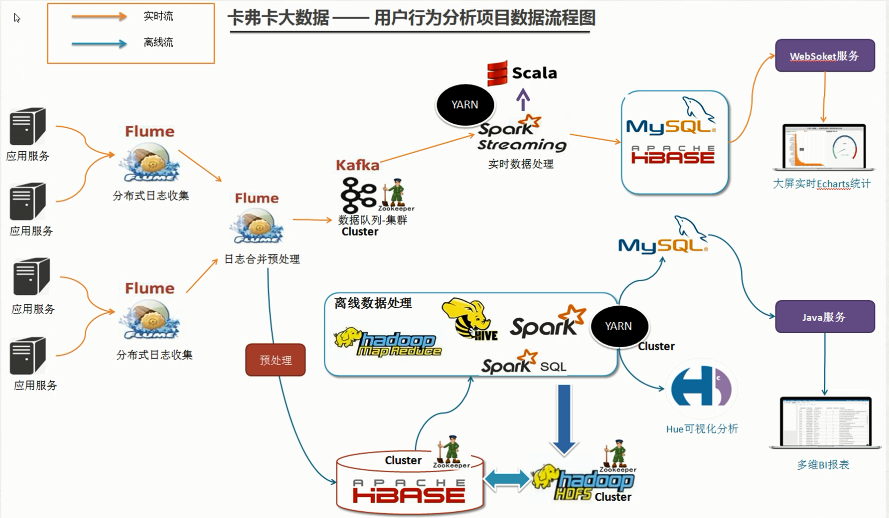
四、集群资源规划设计
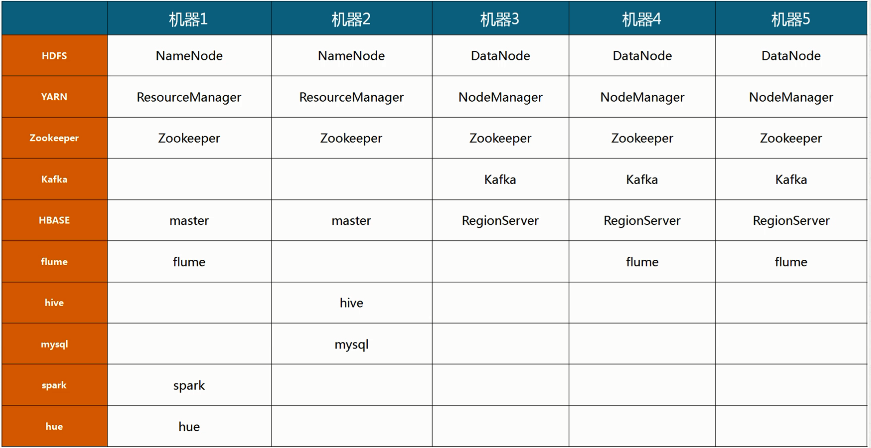
五、步骤详解
考虑到实际情况,本人集群配置共三个节点(node5、node6、node7)。
1. Zookeeper分布式集群部署
参考
博客
2. Hadoop2.X HA架构与部署
参考
博客
3. HBase分布式集群部署与设计
参考
博客
4. Kafka分布式集群部署
参考
博客
5. Flume部署及数据采集准备
参考
博客,node6与node7中flume数据采集到node5中,而且node6和node7的flume配置文件大致相同,node7中将a2改为a3,如下
a2.sources = r1
a2.sinks = k1
a2.channels = c1
a2.sources.r1.type = exec
a2.sources.r1.command = tail -F /opt/data/weblog-flume.log
a2.sources.r1.channels = c1
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 1000
a2.channels.c1.keep-alive = 5
a2.sinks.k1.type = avro
a2.sinks.k1.channel = c1
a2.sinks.k1.hostname = node5
a2.sinks.k1.port = 5555
6. Flume+HBase+Kafka集成与开发
1. 下载Flume源码并导入Idea开发工具
1)将apache-flume-1.7.0-src.tar.gz源码下载到本地解压
2)通过idea导入flume源码
打开idea开发工具,选择File——》Open
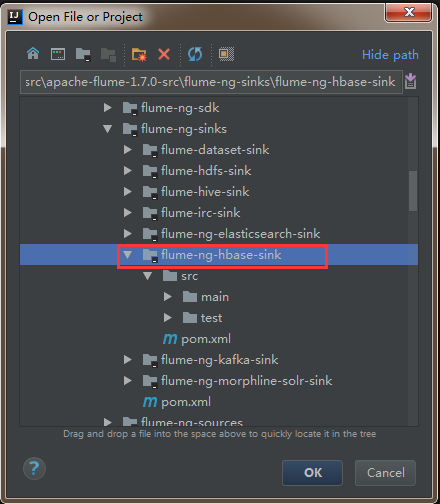
然后找到flume源码解压文件,选中flume-ng-hbase-sink,点击ok加载相应模块的源码。
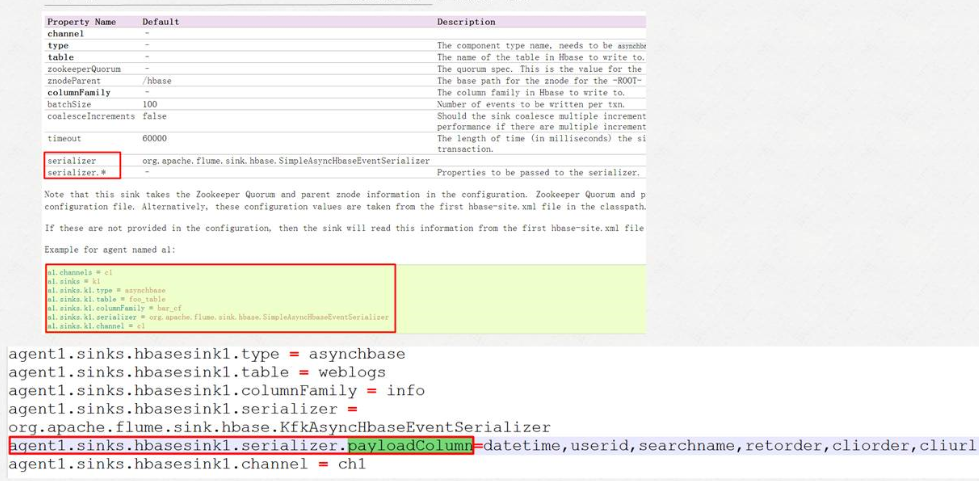
2. 官方flume与hbase集成的参数介绍
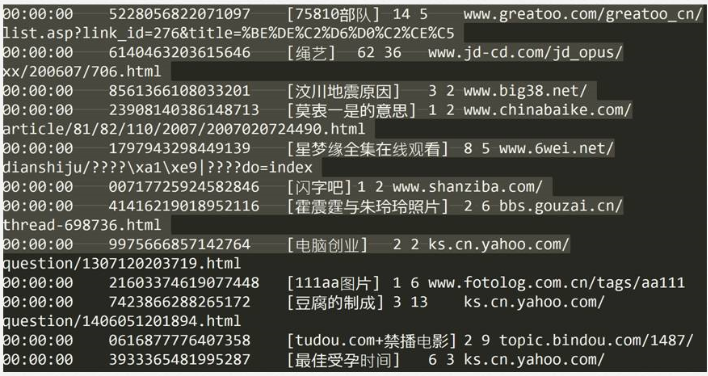
3. 下载日志数据并分析
到搜狗实验室
下载用户查询日志
1)介绍
搜索引擎查询日志库设计为包括约1个月(2008年6月)Sogou搜索引擎部分网页查询需求及用户点击情况的网页查询日志数据集合。为进行中文搜索引擎用户行为分析的研究者提供基准研究语料。
2)格式说明
数据格式为:访问时间\t用户ID\t[查询词]\t该URL在返回结果中的排名\t用户点击的顺序号\t用户点击的URL
其中,用户ID是根据用户使用浏览器访问搜索引擎时的Cookie信息自动赋值,即同一次使用浏览器输入的不同查询对应同一个用户ID
4. node5聚合节点与HBase和Kafka的集成配置
node5通过flume接收node6与node7中flume传来的数据,并将其分别发送至hbase与kafka中,配置内容如下
a1.sources = r1
a1.channels = kafkaC hbaseC
a1.sinks = kafkaSink hbaseSink
a1.sources.r1.type = avro
a1.sources.r1.channels = hbaseC kafkaC
a1.sources.r1.bind = node5
a1.sources.r1.port = 5555
a1.sources.r1.threads = 5
#****************************flume + hbase******************************
a1.channels.hbaseC.type = memory
a1.channels.hbaseC.capacity = 10000
a1.channels.hbaseC.transactionCapacity = 10000
a1.channels.hbaseC.keep-alive = 20
a1.sinks.hbaseSink.type = asynchbase
a1.sinks.hbaseSink.table = weblogs
a1.sinks.hbaseSink.columnFamily = info
a1.sinks.hbaseSink.serializer = org.apache.flume.sink.hbase.KfkAsyncHbaseEventSerializer
a1.sinks.hbaseSink.channel = hbaseC
a1.sinks.hbaseSink.serializer.payloadColumn = datetime,userid,searchname,retorder,cliorder,cliurl
#**推荐阅读
相关标签

