
- 1腾讯老照片修复算法开源,细节到头发丝,3种预训练模型可下载 | GitHub热榜
- 2Linux:进程概念认识
- 3audio_policy_configuration.xml解读与配置_audio_policy_configuration.xml 蓝牙音箱
- 4C#模拟鼠标、键盘操作_c# mouse_event
- 5KPCA提取轴承振动信号的主成分特征_振动信号特征提取
- 6华为鸿蒙小插件,华为鸿蒙系统细节曝光 可添加Widget插件
- 7单片机程序转变成C语言,有人帮忙把这个51单片机程序改成C语言吗
- 8实际S7-200SMART与虚拟WinCC flexible SMART V3联合仿真_s7-200 smart仿真
- 9logcat命令总结
- 10鱼哥赠书活动第②期:《AWD特训营:技术解析、赛题实战与竞赛技巧》《ATT&CK视角下的红蓝对抗实战指南》《智能汽车网络安全权威指南》上下册
Tensorflow模型量化(Quantization)原理及其实现方法_模型量化如何手动实现
赞
踩
量化目的
压缩模型大小,加速模型推断速度,方便将深度学习模型部署到手机等计算资源受限的终端上。
量化分类
对称量化
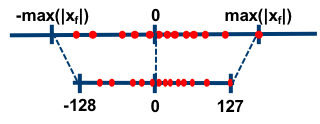
如上图所示,所谓的对称量化,即使用一个映射公式将输入数据映射到[-128,127]的范围内,图中-max(|Xf|)表示的是输入数据的最小值,max(|Xf|)表示输入数据的最大值。对称量化的一个核心即零点的处理,映射公式需要保证原始的输入数据中的零点通过映射公式后仍然对应[-128,127]区间的零点。总而言之,对称量化通过映射关系将输入数据映射在[-128,127]的范围内,对于映射关系而言,我们需要求解的参数即Z和S。
在对称量化中,r 是用有符号的整型数值(int8)来表示的,此时 Z=0,且 q=0时恰好有r=0。在对称量化中,我们可以取Z=0,S的取值可以使用如下的公式,也可以采用其它的公式。
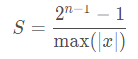
其中,n 是用来表示该数值的位宽,x 是数据集的总体样本。
非对称量化
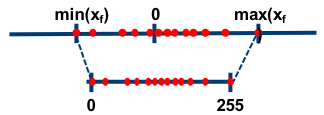
如上图所示,所谓的非对称量化,即使用一个映射公式将输入数据映射到[0,255]的范围内,图中min(Xf)表示的是输入数据的最小值,max(Xf)表示输入数据的最大值。总而言之,对称量化通过映射关系将输入数据映射在[0,255]的范围内,对于映射关系而言,我们需要求解的参数即Z和S。
在非对称量化中,r 是用有符号的整型数值(uint8)来表示的。在非对称量化中,我们可以取Z=min(x),S的取值可以使用如下的公式,也可以采用其它的公式。
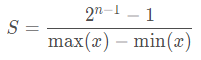
原理详解
模型量化桥接了定点与浮点,建立了一种有效的数据映射关系,使得以较小的精度损失代价获得了较好的收益,要弄懂模型量化的原理就是要弄懂这种数据映射关系。
浮点转换为定点的公式如下所示:
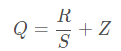
定点转换为浮点的公式如下所示:
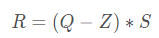
其中R表示输入的浮点数据,Q表示量化之后的定点数据,Z表示Zero Point的数值,S表示Scale的数值,我们可以根据S和Z这两个参数来确定这个映射关系。求解S和Z有很多种方法,这里列举中其中的一种求解方式如下:
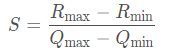

具体案例
训练后的模型权重或激活值往往在一个有限的范围内分布,如激活值范围为[-2.0, 6.0],然后我们使用int8进行模型量化,则定点量化值范围为[-128, 127],那么S和Z的求值过程如下所示:
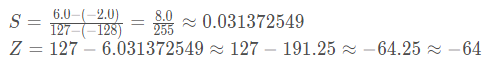
如果此时我们有一个真实的激活值为0.28即R=0.28,那么对应Q的求解过程如下所示:
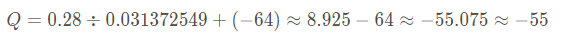
整个网络中的其它参数也按照这种方法就可以获得量化之后的数值。
模型量化实现步骤
对于模型量化任务而言,具体的执行步骤如下所示:
步骤1-在输入数据(通常是权重或者激活值)中统计出相应的min_value和max_value;
步骤2-选择合适的量化类型,对称量化(int8)还是非对称量化(uint8);
步骤3-根据量化类型、min_value和max_value来计算获得量化的参数Z/Zero point和S/Scale;
步骤4-根据标定数据对模型执行量化操作,即将其由FP32转换为INT8;
步骤5-验证量化后的模型性能,如果效果不好,尝试着使用不同的方式计算S和Z,重新执行上面的操作。
注释:在后面用训练时量化方式进行量化方式时,加入伪量化的结点的目的就是统计各个参数的最大、最小值;在将pb模型转化为tflite模型时通过inference_type选择是对称量化(int8)还是非对称量化(uint8)
tensorflow量化分类
量化一般可以分为两种模式:训练后的量化(post training quantizated)和训练中引入量化(quantization aware training)。
训练后的量化
tensorflow训练后量化是针对已训练好的模型而言的,针对大部分我们已训练好的的网络模型来说均可使用此方法进行模型量化。tensorflow提供了一整套完整的模型量化工具,如TensorFlow Lite Optimizing COnverter(toco命令工具)以及TensorFlow Lite converter(API源码调用接口)。
训练后量化方式的实现方法如下:混合量化-仅量化权重、全整型量化-权重和激活值都进行量化、半精度量化-仅量化权重三种。
混合量化-仅量化权重
该方式将浮点型的权重量化为int8整型,可将模型大小直接减少75%、提升推理速度最大3倍。该方式在推理的过程中,需要将int8量化值反量化为浮点型后再进行计算,如果某些Ops不支持int8整型量化,那么其保存的权重依然是浮点型的,即部分支持int8量化的Ops其权重保存为int8整型且存在quantize和dequantize操作,否则依然是浮点型的,因而称该方式为混合量化。该方式可达到近乎全整型量化的效果,但存在quantize和dequantize操作其速度依然不够理想。
混合量化的实现方式比较简单,仅需调用tf.lite.TFLiteConverter的API转化即可。
import tensorflow as tf
# 装载预训练模型
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
# 设置优化器
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
# 执行转换操作
tflite_quant_model = converter.convert()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
全整型量化-权重和激活值都进行量化
该方式试图将权重、激活值及输入值均全部做int8量化,并且将所有模型运算操作置于int8下进行执行,以达到最好的量化效果。为了达到此目的,我们需要一个具有代表性的小数据集,用于统计激活值和输入值等的浮点型范围,以便进行精准量化。
全整型量化的输入输出依然是浮点型的,但如果某些Ops未实现该方法,则转化是没问题的且其依然会自动保存为浮点型,这就要求我们的硬件支持这样的操作。
import tensorflow as tf
def representative_dataset_gen():
for _ in range(num_calibration_steps):
# Get sample input data as a numpy array in a method of your choosing.
yield [input]
# 装载预训练模型
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
# 设置优化器
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# 获得标注数据
converter.representative_dataset = representative_dataset_gen
# 执行转化操作
tflite_quant_model = converter.convert()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
半精度量化-仅量化权重
该方式是将权重量化为半精度float16形式。它可以将模型大小压缩1倍,与int8相比能够获得更小的精度损失,它的前提需要你使用的硬件支持FP16操作,而FP16操作仅在一些设备上面才能使用。使用该方法的示例代码如下所示:
import tensorflow as tf
# 装载预训练模型
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
# 设置优化器
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# 判断当前的设备是否支持FP16操作
converter.target_spec.supported_types = [tf.lite.constants.FLOAT16]
# 执行转换
tflite_quant_model = converter.convert()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
训练后的量化理解起来比较简单,将训练后的模型中的权重由float32量化到int8,并以int8的形式保存,但是在实际推断时,还需要反量化为float类型进行计算。这种量化的方法在大模型上表现比较好,因为大模型的抗噪能力很强,但是在小模型上效果就很差。
训练中引入量化
训练中引入量化是指在训练的过程中对于可识别的某些操作引入伪量化操作,即在前向传播时,采用量化后的权重和激活,但是在反向传播时仍是对float类型的权重做梯度更新;在预测时将全部采用int8的方式进行计算。
注:模型除了可以量化到int8之外,还可以量化到float16,int4等,只是在作者看来量化到int8之后,能保证压缩效果和准确率损失最优。
量化具体实现
训练后的量化
将converter.post_training_quantize设置为True即可。
def tflite_from_sess(ckpt_dir, out_path):
net = Det(ckpt_dir)
with net.sess as sess:
converter = tf.lite.TFLiteConverter.from_session(sess, [net.input_images], [net.seg_maps_pred])
converter.post_training_quantize = True # 启用训练后模型量化,进行量化转换,模型大小会小很多
tflite_model = converter.convert()
open(out_path, "wb").write(tflite_model)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
训练中引入量化(量化感知训练)
tensorflow中的训练时量化是一种伪量化。它是在可识别的某些操作内嵌入伪量化节点(fake quantization nodes),用以统计训练时流经该节点数据的最大值和最小值,便于在使用TOCO转换tflite格式时量化使用并减少精度损失,它参与模型训练的前向推理过程令模型获得量化损失,但梯度更新需要在浮点下进行因而其并不参与反向传播过程。某些操作无法添加伪量化节点,这时候就需要人为的去统计某些操作的最大最小值,但如果统计不准确那么将会带来较大的精度损失,因而需要谨慎检查哪些操作无法添加伪量化节点。值得注意的是,伪量化节点的意义在于统计流经数据的最大最小值并参与前向传播过程来提升模型精度,但其在TOCO工具转换为量化模型后,其工作原理还是与训练后量化方式一致的!具体的量化流程如下图所示:
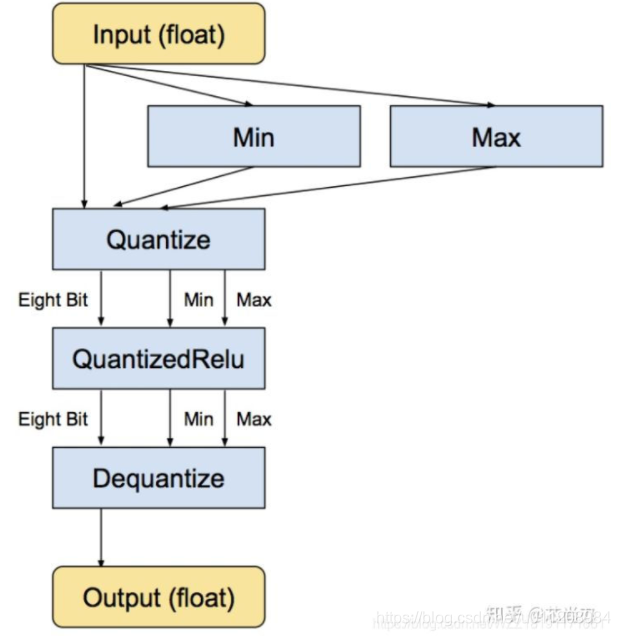
对于Relu节点而言,由于其支持量化操作,输入的数据仍然是FP32类型的,使用Min和Max函数分别来统计输入数据中的最大值和最小值;然后在Relu层的前面添加一个Quantize层来获得量化后的QuantizedRelu,此时已经转化为INT8类型;接着执行相应的Relu计算(INT8类型);接着添加一个dequantize层来将INT8的结果转换为FP32,即该层的最终输出仍然是FP32类型的。需要注意的是,当多个可识别的操作相邻时,多个quantize和dequantize连接时是可以相互抵消的。
实战
步骤1-在训练图结构内添加伪量化节点
在训练代码中加入create_training_graph关键函数后重新训练模型,保存ckpt文件。
# 获取loss函数
loss = tf.losses.get_total_loss()
# 获取原始的图,并在原始的图的基础上创建一个量化图
g = tf.get_default_graph()
tf.contrib.quantize.create_training_graph(input_graph=g, quant_delay=2000000)
# 设计优化器并执行反向传播
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
optimizer.minimize(loss)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
一般是在loss之后optimizer之前添加tf.contrib.quantize.create_training_graph关键函数,其将自动的帮我们在可识别的操作上嵌入伪量化节点,训练并保存模型后,模型图结构就会自动的存在伪量化节点及其统计的参数。
tf.contrib.quantize.create_training_graph的参数input_graph表示训练的默认图层,quant_delay是指多少次迭代之后再进行量化训练,如果是已训练好进行微调量化的话,那么可以将quant_del ay设为0。
quant_delay表示网络在进行量化训练前采用浮点训练的次数,在源码中,quant_delay默认为0。
这个默认值比较适合finetune一个已经训练好的模型。如果重头开始训,quant_delay应该设置为浮点模型收敛时的steps,模型训到此steps之后,量化训练便激活。(从头训练一个模型,quant_delay的值不一定非要取浮点模型收敛时的step值,有时取0,即直接量化训效果会更好)
用saver = tf.train.Saver(tf.global_variables())或者saver=tf.train.Saver()较为保险,不然后面在freeze.py中加载模型进去会说有些节点没有权重初始化。(意思是说图中的有些节点,ckpt中没有保存参数,我就碰到过这种情况)
步骤2-重写推理图结构并保存为新的模型
将图模型和权重文件冻结为一个文件(.pb)
def saveQuantCkpt2Pb(in_ckpt_dir,output_node_names): net = MnistNet(False) # 网络定义在默认图上 graph = tf.compat.v1.get_default_graph() # 获取默认图 tf.contrib.quantize.create_eval_graph(graph) # 在默认图基础上创建一个推理图,使其包含量化结点 sess = tf.compat.v1.Session(graph=graph) # 创建一个会话,设置会话的图为graph # 创建一个模型保存和加载对象 saver = tf.compat.v1.train.Saver() ckpt = tf.train.latest_checkpoint(in_ckpt_dir) # 查找in_ckpt_dir目录下最新保存的checkpoint文件的文件名 print("ckpt:================", ckpt) saver.restore(sess, ckpt) # 将量化训练的ckpt模型参数加载到当前默认会话 # 同时将网络模型结构与参数用二进制格式的pb文件保存 # sess.graph.as_graph_def():导出当前计算图的GraphDef部分,GraphDef保存了从输入层到输出层的计算过程 converted_graph_def = tf.compat.v1.graph_util.convert_variables_to_constants(sess, input_graph_def=sess.graph.as_graph_def(), output_node_names=output_node_names) # #保存指定的节点,并将节点值保存为常数 # tf.gfile.GFile(filename, mode):获取文本操作句柄,类似于python提供的文本操作open()函数,filename是要打开的文件名,mode是以何种方式去读写,将会返回一个文本操作句柄。 # tf.gfile.Open()是该接口的同名,可任意使用其中一个 # with tf.io.gfile.GFile(pb_graph_dir, "wb") as f: # 保存方法一 # f.write(converted_graph_def.SerializeToString()) # SerializeToString()序列化 tf.io.write_graph( # 保存方法二 converted_graph_def, "./pb", "freeze_eval_graph.pb", as_text=False)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
用Netron打开生成的pb文件,如下图。可以看到pb中生成了伪量化节点,伪量化节点中保存了min、max,意味着转换成功。
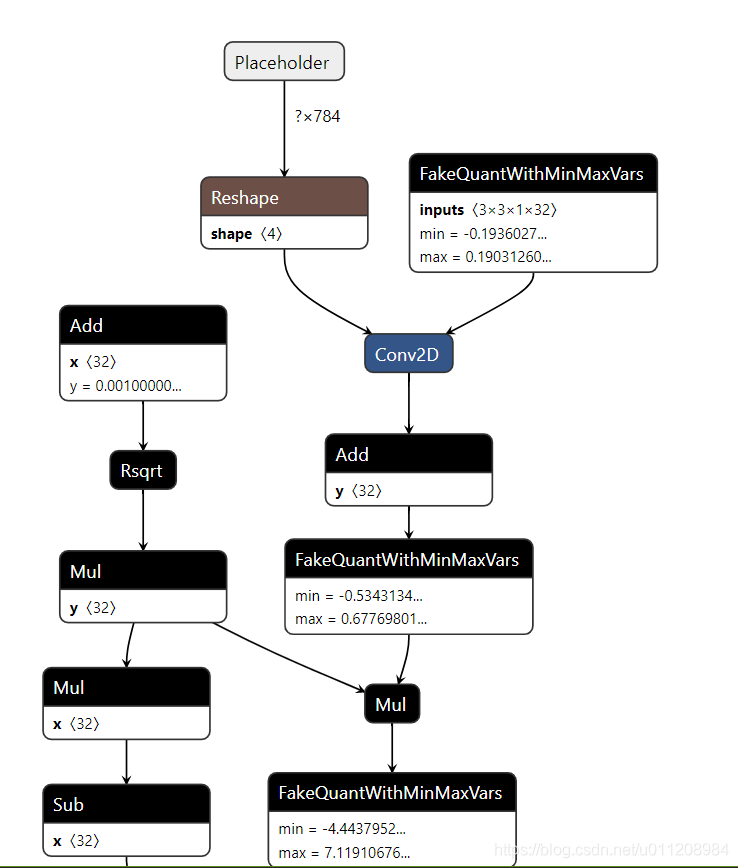
步骤3-量化:将pb模型转换成tflite文件
两种方法:
方法一:利用TFLiteConverter
# 量化后的pb模型转为tflite import tensorflow as tf path_to_frozen_graphdef_pb = './pb/freeze_eval_graph.pb' input_arrays = ["Placeholder"] output_arrays = ["Softmax"] input_shapes = {'Placeholder': [1, 784]} converter = tf.lite.TFLiteConverter.from_frozen_graph(path_to_frozen_graphdef_pb, input_arrays, # 是freeze pb中的输入节点 output_arrays, # 是freeze pb中的输出节点 input_shapes = input_shapes) # converter.target_ops = [tf.lite.OpsSet.TFLITE_BUILTINS,tf.lite.OpsSet.SELECT_TF_OPS] converter.inference_type = tf.uint8 # 标识进行uint8非对称量化 # quantized_input_states是定义输入的均值和方差 converter.quantized_input_stats = {"Placeholder": (127.5, 127.5)} converter.allow_custom_ops = True # default_ranges_states是指量化后的值的范围,其中255就是2^8 - 1 converter.default_ranges_stats = (0, 255) # 由于是进行uint8量化,所以量化值的输出范围为[0,255] tflite_model = converter.convert() # 根据pb模型中的最大最小值等标定数据对模型执行量化操作,即将其由FP32转换为INT8 open("./tflite/eval_graph.tflite", "wb").write(tflite_model) print("finish")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
训练时模型的输入tensor的值在不同范围时,对应的mean_values,std_dev_values分别如下:
- range (0,255) then mean = 0, std_dev = 1
- range (-1,1) then mean = 127.5, std_dev = 127.5
- range (0,1) then mean = 0, std_dev = 255
我查看了我的输入tensor范围是[-1,1], 所以我设置参数为 mean = 127.5, std_dev = 127.5 。
用Netron打开生成的tflite文件,若伪量化节点被消除,则意味着uint8量化转换成功。
方法二:利用TOCO
toco --graph_def_file
./frozen_inference_graph.pb
--output_file test.tflite
--input_format=TENSORFLOW_GRAPHDEF
--output_format=TFLITE
--inference_type=QUANTIZED_UINT8
--input_shape='1,300,300,3' --input_array='FeatureExtractor/MobilenetV2/MobilenetV2/input' --output_array='concat,concat_1'
--std_dev_value 127.5
--mean_value 127.5
--default_ranges_min 0
--default_ranges_max 255
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
tensorflow量化方法比较
两种量化的相同点如下所示:
- 两者均可达到模型量化的作用;
- 两者的推理工作原理是一样的;
- 两者都可工作在Tensorflow lite推理框架下并进行相应加速;
两种量化的不同点如下所示:
- 前者是一种offline的方式,而后者则是一种online的方式;
- 训练后量化工作量稍微简单些,而量化感知训练工作量更繁琐一些;
- 量化感知训练比训练后量化损失的精度更少,官方推荐使用量化感知训练方式;
参考:
tensorflow模型量化实例
Tensorflow模型量化实践3–quantization-aware training
模型量化详解
Tensorflow模型量化(Quantization)原理及其实现方法
Quantization aware training 量化背后的技术
Tensorflow模型量化4 --pb转tflite(uint8量化)小结
量化训练:Quantization Aware Training in Tensorflow(一)
tensorflow实现quantization-aware training(伪量化,fake quantization)

