
- 1全国计算机一级考试攻略,全国计算机等级考试全攻略(一级到四级)
- 2元学习:Meta-Learning in Neural Networks: A Survey
- 3《云栖精选》第7期:2017阿里巴巴技术盘点
- 4用最清晰的语言解释区块链_谁能用听得懂的语言解释区块链
- 5详细教程 - 进阶版 鸿蒙harmonyOS应用 第十七节——鸿蒙OS多线程编程指南_鸿蒙多线程
- 6什么是restorecon -Rv
- 7Windows系统安装adb/fastboot驱动教程_fastboot驱动安装教程
- 8deepfacelab安卓版_deepfacelab
- 9[ PyQt入门教程 ] Qt Designer工具的使用_qtdesigner
- 10消息认证码以及数字签名的认识_数字签名和消息签名
学习笔记Hive(一)—— Hive简介_hive底层将hiveql语句转换为mapreduce任务运行,它允许熟悉sql的用户基于hadoo
赞
踩
一、Hive设计思想
(了解)
Facebook用户社交数据存储与处理
Facebook是美国的一个社交网站 ,于2004年2月4日上线。主要创始人为美国人马克·扎克伯格。Facebook是世界排名领先的照片分享站点。
根据Comscore咨询公司的数据显示,2008年5月Facebook全球独立访问用户首次超过了竞争对手Myspace,前者五月独立访问用户达到了1.239亿,页面浏览量达到500.6亿。2009年12月,Facebook的独立人次达到了4.69亿,其综合浏览量增长了141个百分点,在09年末达到了1930亿。
1.1、Hive由来
Hive是Facebook开发的,构建于Hadoop集群之上的数据仓库应用。2008年Facebook将Hive项目贡献给Apache,成为开源项目。
Hive最初是由Facebook设计的,是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的类SQL查询语言(称为HiveQL)。
底层将HiveQL语句转换为MapReduce任务运行,它允许熟悉SQL的用户基于Hadoop框架分析数据。
优点:学习成本低,对于简单的统计分析,不必开发专门的MapReduce程序,直接通过HiveQL即可实现。
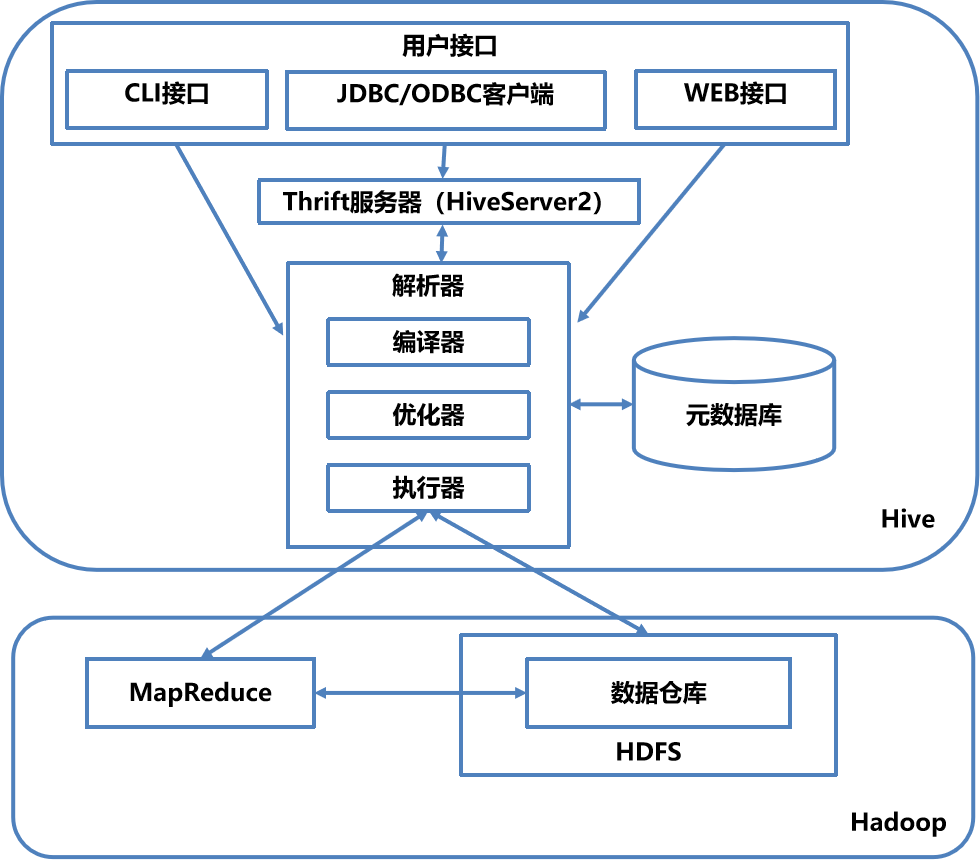
二、Hive体系结构
-
CLI:Cli 启动的时候,会同时启动一个 Hive 副本。
-
JDBC客户端:封装了Thrift,java应用程序,可以通过指定的主机和端口连接到在另一个进程中运行的hive服务器
-
ODBC客户端:ODBC驱动允许支持ODBC协议的应用程序连接到Hive。
-
WUI 接口:是通过浏览器访问 Hive
-
Thrift服务器
基于socket通讯,支持跨语言。Hive Thrift服务简化了在多编程语言中运行Hive的命令。绑定支持C++,Java,PHP,Python和Ruby语言 -
解析器
- 编译器:完成 HQL 语句从词法分析、语法分析、编译、优化以及执行计划的生成。
- 优化器是一个演化组件,当前它的规则是:列修剪,谓词下压。
- 执行器会顺序执行所有的Job。如果Task链不存在依赖关系,可以采用并发执行的方式执行Job。
-
元数据库
- Hive的数据由两部分组成:数据文件和元数据。元数据用于存放Hive库的基础信息,它存储在关系数据库中,如 mysql、derby。元数据包括:数据库信息、表的名字,表的列和分区及其属性,表的属性,表的数据所在目录等。
-
Hadoop
- Hive 的数据文件存储在 HDFS 中,大部分的查询由 MapReduce 完成。(对于包含 * 的查询,比如 select * from tbl 不会生成 MapRedcue 作业)
2.1、运行机制
- 用户通过用户接口连接Hive,发布Hive SQL
- Hive解析查询并制定查询计划
- Hive将查询转换成MapReduce作业
- Hive在Hadoop上执行MapReduce作业
补充知识点:
① 用户接口主要有三个:CLI,Client和WUI.其中最常用的是CLI,CLI启动的时候,会同时启动一个Hive副本。Client是Hive的客户端,用户连接至Hive Server。在启动Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。WUI是通过浏览器访问Hive。
② Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区以及属性,表的属性(是否为外部表等),表的数据所在目录等。
③ 解释器、编辑器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
④ Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成
三、Hive应用场景
3.1、Hive设计特点
- Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。
- 支持索引,加快数据查询。
- 不同的存储类型,例如,文本文件、序列化文件。
- 将元数据保存在关系数据库中,减少了在查询中执行语义检查时间。
- 可以直接使用存储在Hadoop 文件系统中的数据。
- 内置大量用户函数UDF 来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF 函数来完成内置函数无法实现的操作。
- 类SQL 的查询方式,将SQL 查询转换为MapReduce 的job 在Hadoop集群上执行。
- 编码跟Hadoop同样使用UTF-8字符集。
3.2、Hive的优势
- 解决了传统关系数据库在大数据处理上的瓶颈。适合大数据的批量处理。
- 充分利用集群的CPU计算资源、存储资源,实现并行计算。
- Hive支持标准SQL语法,免去了编写MR程序的过程,减少了开发成本。
- 具有良好的扩展性,拓展功能方便。
3.3、Hive的劣势
- Hive的HQL表达能力有限:有些复杂运算用HQL不易表达。
- Hive效率低:Hive自动生成MR作业,通常不够智能。
针对Hive运行效率低下的问题,促使人们去寻找一种更快,更具交互性的分析框架。 SparkSQL 的出现则有效的提高了Sql在Hadoop 上的分析运行效率。
3.4、应用场景
适用场景
- 海量数据的存储处理
- 数据挖掘
- 海量数据的离线分析
不适用场景
- 复杂的机器学习算法
- 复杂的科学计算
- 联机交互式实时查询

