
热门标签
热门文章
- 1NodeJS常见报错_the node.js path can contain
- 2gitcode 上传文件报错文件太大has exceeded the upper limited size
- 3玄子Share-计算机网络参考模型
- 4牛客:C++工程师面试宝典:第二章:基础知识:2.1:基础语言(一)_牛客c++面试宝典
- 5GitHub开源项目权限管理-使用账号和个人令牌访问_gitlub如何开启允许令牌登陆
- 6【安全】web中的常见编码&;浅析浏览器解析机制_web网站码源(1)_浏览器编码
- 7Unity微信小游戏登录授权获取用户信息_unity createuserinfobutton
- 8使用cmd命令行打开MySQL数据库_cmd打开mysql
- 9RabbitMQ配置属性表_rabbitmq表
- 10oracle zfs storage zs3-4,「服务器、工作站」全新原包Oracle ZFS Storage ZS4-4 Appliance-深圳市惟思华-马可波罗网...
当前位置: article > 正文
前向传播和反向传播_推理只是前向传播吗
作者:盐析白兔 | 2024-04-11 14:33:54
赞
踩
推理只是前向传播吗
前向传播和反向传播
例程:生产一批零件,将体积X1和重量X2为特征输入NN,通过NN后输出一个数值
1. 前向传播
前向传播就是搭建模型的计算过程,让模型具有推理能力,可以针对一组输入给出相应的输出
1.1 前向传播过程
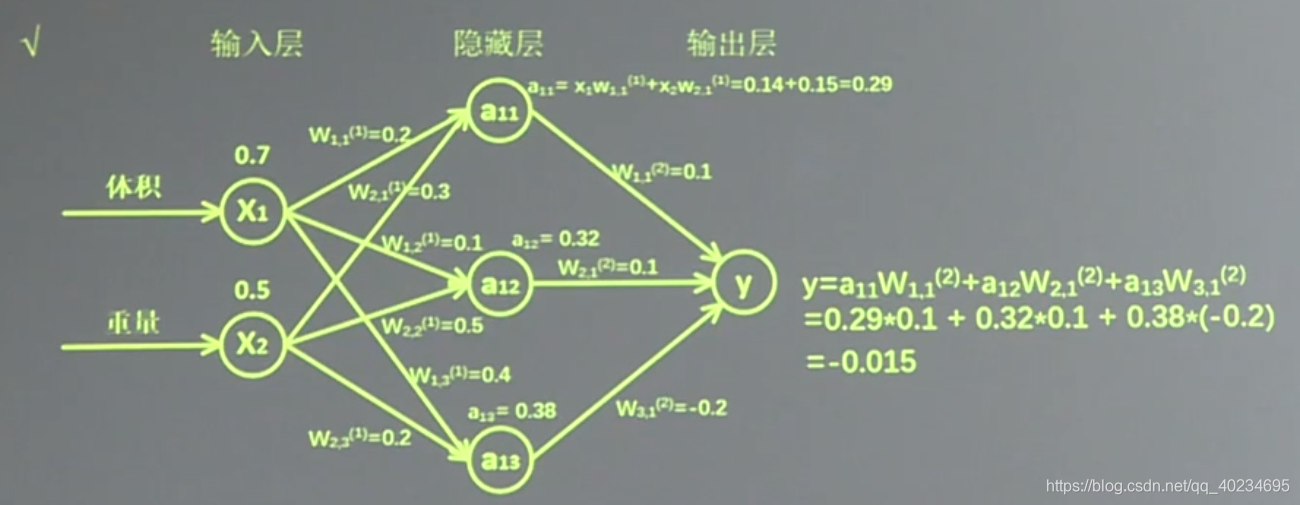
- 第一层
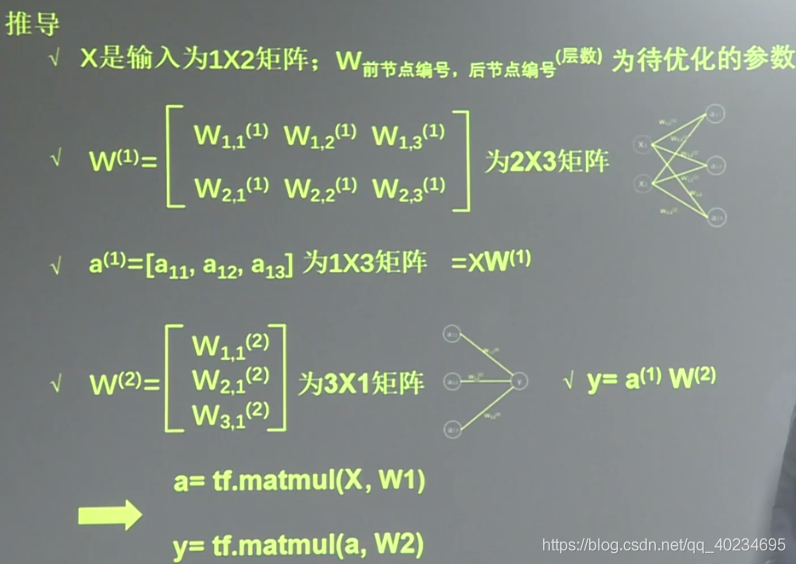
| X | W ( 1 ) W^(1^) W(1) | a |
|---|---|---|
| x 表示输入,是一个 1 行 2 列矩阵,表示1次输入1组特征(包含了体积和重量两个元素) | 对于第一层的 w 前面有两个节点,后面有三个节点 W ( 1 ) W^(1^) W(1) 应该是个2行3列矩阵 | a 为第一层网络,a 是一个1行3列矩阵 |
- 第二层
| W ( 2 ) W^(2^) W(2) |
|---|
| 参数要满足前面三个节点,后面一个节点,所以 是3行1列矩阵 |
注:神经网络共有几层(或当前是第几层网络)都是指的计算层,输入不是计算层,所以 a 为第一层网络
1.2 用Tensorflow表示前向传播
-
变量初始化、计算图节点运算都要用会话(with 结构)实现
with tf.Session() as sess:
sess.run()- 变量初始化:在 sess.run 函数中用 tf.global_variables_initializer()汇总所有待优化变量。
init_op = tf.global_variables_initializer()
sess.run(init_op) - 计算图节点运算:在 sess.run 函数中写入待运算的节点
sess.run(y) - 用 tf.placeholder 占位,在 sess.run 函数中用 feed_dict 喂数据
喂一组数据:
x = tf.placeholder(tf.float32, shape=(1, 2))
sess.run(y, feed_dict={x: [[0.5,0.6]]})
喂多组数据:
x = tf.placeholder(tf.float32, shape=(None, 2))
sess.run(y, feed_dict={x: [[0.1,0.2],[0.2,0.3],[0.3,0.4],[0.4,0.5]]})
- 变量初始化:在 sess.run 函数中用 tf.global_variables_initializer()汇总所有待优化变量。
1.3 实现神经网络前向传播过程,网络自动推理出输出 y 的值
- 例1:用 placeholder 实现输入定义(sess.run 中喂入一组数据)的情况
第一组喂体积 0.7、重量 0.5
#coding:utf-8 import tensorflow as tf #定义输入和参数 x=tf.placeholder(tf.float32,shape=(1,2)) w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)) #定义前向传播过程 a=tf.matmul(x,w1) y=tf.matmul(a,w2) #用会话计算结果 with tf.Session() as sess: init_op=tf.global_variables_initializer() sess.run(init_op) print (sess.run(y,feed_dict={x:[[0.7,0.5]]}))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 例2:用 placeholder 实现输入定义(sess.run 中喂入多组数据)的情况
第一组喂体积 0.7、重量 0.5,第二组喂体积 0.2、重量 0.3,第三组喂体积0.3、重量 0.4,第四组喂体积 0.4、重量 0.5.
#coding:utf-8
import tensorflow as tf
#定义输入和参数
x=tf.placeholder(tf.float32,shape=(None,2))
w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
#定义前向传播过程
a=tf.matmul(x,w1)
y=tf.matmul(a,w2)
#用会话计算结果
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
print(sess.run(y,feed_dict={x:[[0.7,0.5],[0.2,0.3],[0.3,0.4],[0.4,0.5]]}))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
2. 反向传播
反向传播:就是训练模型参数,在所有参数上用梯度下降,使 NN 模型在训练数据上的损失函数最小
2.1 损失函数
损失函数(loss):计算得到的预测值 y 与已知答案 y_的差距
- 损失函数计算方法:有很多方法,均方误差 MSE 是比较常用的方法之一
| 均方误差 MSE | 解释 |
|---|---|
| 定义 | 求前向传播计算结果与已知答案之差的平方再求平均 |
| 公式 | 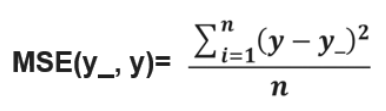 |
| tensorflow 函数表示 | loss_mse = tf.reduce_mean(tf.square(y_ - y)) |
2.2 反向传播训练方法:以减小 loss 值为优化目标
| 反向传播训练方法 | 梯度下降 | momentum 优化器 | adam 优化器 | 、、、 |
|---|---|---|---|---|
| 用 tensorflow 函数表示 | train_step=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss) | train_step=tf.train.MomentumOptimizer(learning_rate, momentum).minimize(loss) | train_step=tf.train.AdamOptimizer(learning_rate).minimize(loss) | |
| 区别 | 使用随机梯度下降算法,使参数沿着梯度的反方向,即总损失减小的方向移动,实现更新参数 | 更新参数时,利用了超参数 | 利用自适应学习率的优化算法,Adam 算法和随机梯度下降算法不同。随机梯度下降算法保持单一的学习率更新所有的参数,学习率在训练过程中并不会改变。而 Adam 算法通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率 | |
| 参数更新的公式 | 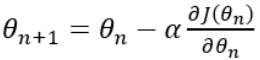 损失函数:J(?) 参数:?,学习率:? 损失函数:J(?) 参数:?,学习率:? | 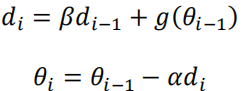 ?为学习率,超参数为?,?为参数,损失函数的梯度:?(??−1) ?为学习率,超参数为?,?为参数,损失函数的梯度:?(??−1) | 无 |
- 学习率
- 决定每次参数更新的幅度
- 优化器中都需要一个叫做学习率的参数,使用时,如果学习率选择过大会出现震荡不收敛的情况,如果学习率选择过小,会出现收敛速度慢的状况。我们可以选个比较小的值填入,比如 0.01、0.001
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/405536
推荐阅读

相关标签

