
- 1Python使用turtle画五星红旗
- 2datatable linq 查询排序用法总结_c# datatable linq 查询
- 3linux或者CentOS环境下安装SQL Server
- 4JMeter —— 3万字讲解让测试彻底臣服的基于 Java 之强大测试工具_jemeter prev.setignore相关
- 5网络协议——STP协议是什么?是如何实现的?
- 6SpringBoot整合redis+mysql_springboot redis+mysql
- 7数据结构(四)—— 线性表的链式存储_线性表的链式存储结构
- 8国内如何快速访问GitHub_国内如何访问github
- 9CommunityToolkit.Mvvm笔记1---Instruction
- 10腾讯测试岗位的面试经历与经验分享【一面、二面与三面】_腾讯实习面试流程
Zero-Shot跨语态抽取式文摘_中英文混合的文本摘要抽取
赞
踩
前言
抽取式摘要可谓是一项很常见的NLP任务,但是由于缺乏训练语料使得这项任务比较难进行train,可是我们知道英文的相关数据集其实很多,于是可以通过跨语态的技术来辅助目标语言的抽取摘要学习。即利用英语的数据集作为监督信息来对齐学习目标语言,进而达到目标语言的监督学习。
今天来介绍的这篇就是解决这个问题的,一起来看下吧~
论文链接:https://arxiv.org/pdf/2204.13512v1.pdf
方法
既然想利用跨语态,那其实首先要解决的就是怎么对齐语种。作者这里借助了两个常见的方法:
Word Replacement (WR):单词替换即从英文句子中随机选取一些word,然后通过词典用目标语言单词替换。
Machine Translation (MT) :这个就很好理解了,直接借助翻译工具进行整句翻译。
接下来说说标签的事,既然要进行监督学习就得有label,具体到抽取式摘要这个任务,其实就是一个分类任务,假设有一个待抽取摘要的英文doc D,其对应的摘要是S,就是说D中的每个句子其实是一个二分类,在S中的label就是1不在的就是0,作者结合跨语态一共设计了4,种label如下:
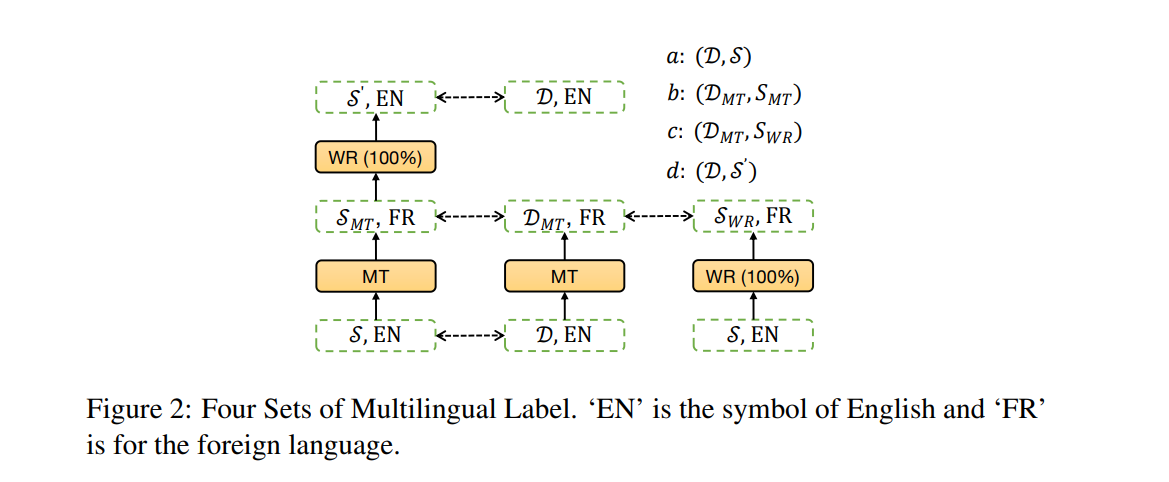
图中EN代表英文,FR代表目标语言,可以看到一共有a,b,c,d四种label。
首先看a就是很简单的英文原始监督语料,b是利用MT分别将D和S翻译成目标语言,c是利用MT将D翻译成目标语言然后利用WR(100%替换)将S替换成目标语言,d是保持D不变对于S先利用MT翻译然后再利用WR回译为英文。
除了上面的,作者还增加了一个Neural Label如下
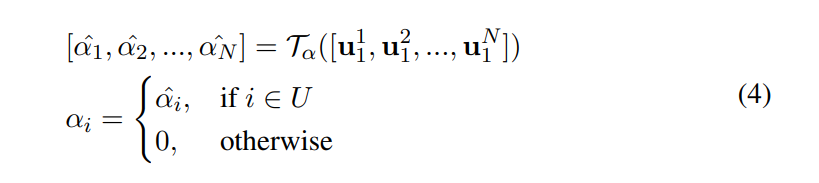
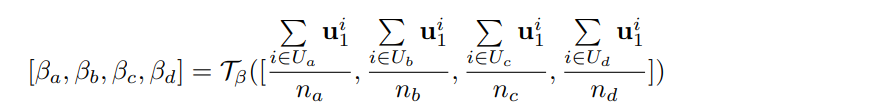
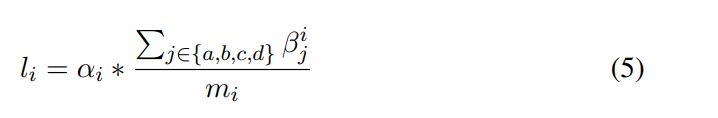
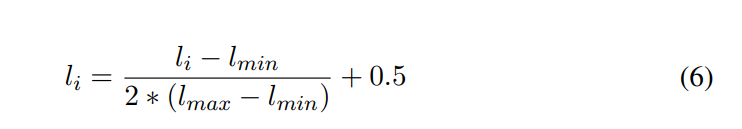
这里公式和符号有点多,我们从上到下一点点来看,第一个公式也即(4)其实就是过了transformer结构得到的表征,U是上述abcd四种情况的集合,对于在U的就是过了模型结构后的概率,不在的直接就是0,第二个公式就是pooling了一下,第三个公式就是得到Neural Label的关键,第四个公式就是归一化了一下,因为对于抽取式摘要结果就是预测一个概率大于0.5的就认为是摘要保留,所以这个加了一个0.5。
有了上述的准备后,下面就可以进行监督学习了,具体的Loss如下
CE是交叉熵,第一个的label句子的非0即1,第二个的l如前面所讲,后面两个句子分别是非pooling和pooling方式,其label也很简单就是在abcd就是1不在就是0。
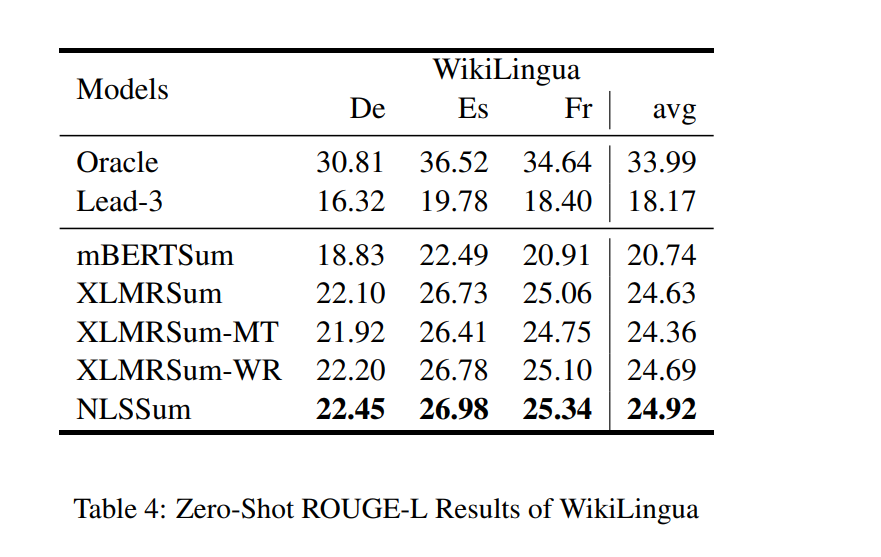
实验效果
更多详细的结果可以看paper
总结
不仅是摘要抽取,其他很多NLP任务其实都存在Zero-Shot问题,而诸如英文等语料非常多,所以可以考虑使用跨语态的方法来辅助增强学习,但是说实话确实有难度,具体是不是有效还是以实验结果为准吧。不论怎样跨语态是一个可以实验的思路吧,而本篇paper的idea大家可以借鉴一下。
关注
欢迎关注,下期再见啦~
欢迎关注笔者微信公众号:

github:
Mryangkaitong · GitHubhttps://github.com/Mryangkaitong
知乎:


