
- 1备战第15届蓝桥杯的同学注意了!蓝桥算法双周赛开始了!_第十五届蓝桥杯青少年
- 2git命令之fetch_your branch is up to date with 'origin/dev'.
- 3PyTorch小技巧:使用Hook可视化网络层激活(各层输出)
- 4【机器学习-周志华】学习笔记-第十二章
- 5大模型微调技术(Adapter-Tuning、Prefix-Tuning、Prompt-Tuning(P-Tuning)、P-Tuning v2、LoRA)_adapter tuning
- 6解决Expected all tensors to be on the same device, but found at least two devices, cuda:0
- 7全面解读:人工智能AI是什么_ai解读
- 8《算法设计与分析》复习
- 9【团队协作开发】从Gitee中克隆项目到IDEA并实现代码更新提交教程(新手)_怎么从gitee上拉取项目到idea
- 10计算机网络基础知识(五)——什么是TCPUDP协议?图文并茂的方式对两大传输层协议进行从头到尾的讲解_什么是tcp/udp协议栈
ChatGPT | 分割Word文字及表格,优化文本分析_unstructuredworddocumentloader
赞
踩
知识库读取Word内容时,由于embedding切片操作,可能会出现表格被分割成多个切片的情况。这种切片方式可能导致“列名栏”和“内容栏”之间的Y轴关系链断裂,从而无法准确地确定每一列的数据对应关系,从而使得无法准确知道每一列的数据汇总。
用下面表格为例子:
| 级数 | T1 | T2 | T3 | T4 | T5 | T6 | T7 |
| 子等 | T1.1-1.2 | T2.1-2.2 | T3.1-3.3 | T4.1-4.3 | T5.1-5.2 | T6.1-6.2 | T7 |
| 专业名称 | 实习 工程师 | 助理 工程师 | 工程师 | 高级 工程师 | 资深 工程师 | 专家级 工程师 | 首席 工程师 |
| 学历 | 本科及以上 | 本科及以上 | 本科及以上 | 本科及以上 | 本科及以上 | 硕士及以上 | 硕士及以上 |
| 工作经验 | 1年以内(兼职) | 1-3年 | 3-5年 | 5-8年 | 8-10年 | 10-15年 | 15年以上 |
| 级数 | T1 | T2 | T3 | T4 | T5 | T6 | T7 |
| 子等 | T1.1-1.2 | T2.1-2.2 | T3.1-3.3 | T4.1-4.3 | T5.1-5.2 | T6.1-T6.2 | T7 |
| 专业名称 | 实习 工程师 | 助理 工程师 | 工程师 | 高级 工程师 | 资深 工程师 | 专家级 工程师 | 首席 工程师 |
| 分值 | 60-64分 | 65-69分 | 70-79分 | 80-89分 | 90-94分 | 95-97分 | 98-100分 |
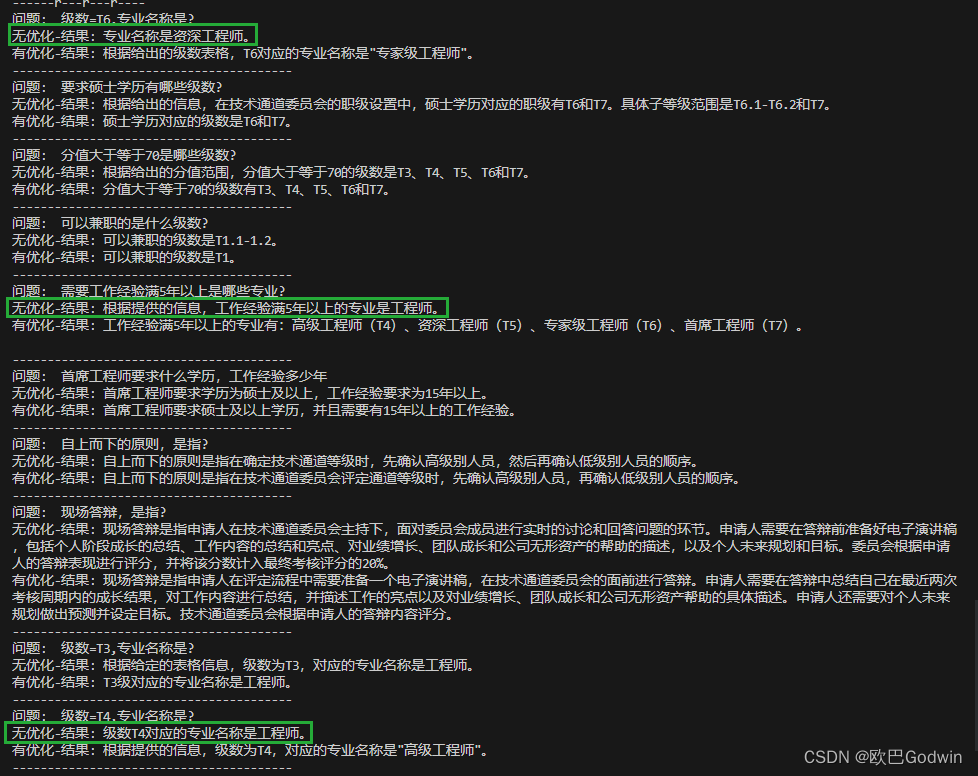
直接演示一下本文代码运行的对比结果,分别展示“无优化”和“有优化”的问答结果,标绿框的是回答错误的:
本文帮助提高文本处理和向量化的效率,以下是对每个步骤的详细说明,详见md_embedding.py源码:
- 分离文字和表格:将原始Word文档中的文字内容和表格分开保存。将文字内容保存为纯文本的Markdown文件,而将表格单独保存为多个只包含Markdown表格的Markdown文件。例如,一个Word文档包含2个表格,即生成1个纯文字Markdown文件,2个纯表格的Markdown文件。
- 切片并向量化处理:对于多个Markdown文件,按照固定的大小切片,确保切片大小是大于Markdown表格的体积,以确保包含完整的表格。然后对这些切片进行向量化处理。
这种方法的优点是能够有效地分离文字和表格,并通过切片和向量化处理提高处理效率。通过将表格转化为向量表示,可以更方便地进行后续的计算和分析。同时,由于切片时保证了表格的完整性,可以避免表格被切断导致信息丢失的问题。
有优化的embedding的源码, md_embedding.py 如下:
- import os
- from langchain.embeddings import OpenAIEmbeddings
- from langchain.text_splitter import RecursiveCharacterTextSplitter
- from langchain.vectorstores import Chroma
- from langchain.document_loaders import TextLoader
- from langchain.text_splitter import CharacterTextSplitter
- from langchain.document_loaders import DirectoryLoader
- from langchain.document_loaders import UnstructuredFileLoader
- from langchain.document_loaders import UnstructuredWordDocumentLoader
-
- from docx import Document
-
-
-
- def convert_word_tables_to_markdown(file_path, output_folder):
- def convert_table_to_markdown(table):
- markdown = ""
- for row in table.rows:
- cells = [cell.text.replace('\n', '').replace('|', '|') for cell in row.cells]
- markdown += "|".join(cells) + "|\n"
- return markdown
-
- doc = Document(file_path)
-
- # 创建输出文件夹(如果不存在)
- os.makedirs(output_folder, exist_ok=True)
-
- # 将每个表格转换为Markdown并保存为单独的TXT文件
- for i, table in enumerate(doc.tables):
- markdown = convert_table_to_markdown(table)
-
- filename_without_ext=os.path.splitext(os.path.basename(file_path))[0]
- # 将Markdown表格写入TXT文件
- output_file_path = os.path.join(output_folder, filename_without_ext+f"_output_{i+1}.md")
- with open(output_file_path, "w", encoding='utf-8') as file:
- file.write(markdown)
-
- return output_folder
-
-
-
- def remove_tables_save_as_md(file_path, output_file_path):
- doc = Document(file_path)
-
- # 移除所有表格
- for table in doc.tables:
- table._element.getparent().remove(table._element)
-
- # 获取剩余内容的纯文本,并构建Markdown格式字符串
- content = [p.text.strip() for p in doc.paragraphs if p.text.strip()]
- markdown_content = '\n\n'.join(content)
-
- # 保存为MD文件
- with open(output_file_path, 'w', encoding='utf-8') as file:
- file.write(markdown_content)
-
- return output_file_path
-
-
- abs_docx_path='D:\CloudDisk\OpenAI\博客的源码\Docx表格优化\带表格DOCX.docx'
- embedding_folder_path=os.path.dirname(abs_docx_path)+'\\md_txt'
- os.makedirs(embedding_folder_path,exist_ok=True)
-
- convert_word_tables_to_markdown(abs_docx_path,embedding_folder_path)
- remove_tables_save_as_md(abs_docx_path,embedding_folder_path+'\\'+os.path.basename(abs_docx_path)+'.md')
-
-
- # 1 定义embedding
- embeddings = OpenAIEmbeddings(openai_api_key='aaaaaaaaaaaaaaaaaa',
- openai_api_base='bbbbbbbbbbbbbbbbbbbbbbbbbb',
- openai_api_type='azure',
- model="text-embedding-ada-002",
- deployment="lk-text-embedding-ada-002",
- chunk_size=1)
-
- # 2 定义文件
- loader = DirectoryLoader(embedding_folder_path, glob="**/*.md")
- pages = loader.load_and_split()
-
- # 按固定尺寸切分段落
- text_splitter_RCTS = RecursiveCharacterTextSplitter(
- chunk_size = 500,
- chunk_overlap = 100
- )
-
- split_docs_RCTS = text_splitter_RCTS.split_documents(pages)
- for item in split_docs_RCTS:
- print(item)
- print('')
-
- #写入向量数据库
- print(f'写入RCTS向量数据库')
- vectordb = Chroma.from_documents(split_docs_RCTS, embedding=embeddings, persist_directory="./MD_RCTS/")
- vectordb.persist()

无优化的embedding的源码,docx_embedding.py 如下:
- import os
- from langchain.embeddings import OpenAIEmbeddings
- from langchain.text_splitter import RecursiveCharacterTextSplitter
- from langchain.vectorstores import Chroma
- from langchain.document_loaders import UnstructuredWordDocumentLoader
-
- # 1 定义embedding
- embeddings = OpenAIEmbeddings(openai_api_key='aaaaaaaaaa',
- openai_api_base='bbbbbbbbbbb',
- openai_api_type='azure',
- model="text-embedding-ada-002",
- deployment="lk-text-embedding-ada-002",
- chunk_size=1)
-
- docx_file_path="D:\CloudDisk\OpenAI\博客的源码\Docx表格优化\带表格DOCX.docx"
-
- # 2 定义文件
- loader = UnstructuredWordDocumentLoader(docx_file_path)
- pages = loader.load_and_split()
-
- # 按固定尺寸切分段落
- text_splitter_RCTS = RecursiveCharacterTextSplitter(
- chunk_size = 500,
- chunk_overlap = 100
- )
-
- split_docs_RCTS = text_splitter_RCTS.split_documents(pages)
- for item in split_docs_RCTS:
- print(item)
- print('')
-
- #写入向量数据库
- print(f'写入RCTS向量数据库')
- vectordb = Chroma.from_documents(split_docs_RCTS, embedding=embeddings, persist_directory="./Word_RCTS/")
- vectordb.persist()
问答测试 chat_qa.py:
- import time
- from langchain.embeddings.openai import OpenAIEmbeddings
- from langchain.vectorstores import Chroma
- from langchain.chains import RetrievalQA
- from langchain.chat_models import AzureChatOpenAI
-
-
- def getQuestionList():
- question_list=[
- '级数=T6,专业名称是?',
- '要求硕士学历有哪些级数?',
- '分值大于等于70是哪些级数?',
- '可以兼职的是什么级数?',
- '需要工作经验满5年以上是哪些专业?',
- '首席工程师要求什么学历,工作经验多少年',
- '自上而下的原则,是指?',
- '现场答辩,是指?',
- '级数=T3,专业名称是?',
- '级数=T4,专业名称是?',
- ]
-
- return question_list
-
- embeddings = OpenAIEmbeddings(openai_api_key='aaaaaaaaaaaaaaaaa',
- openai_api_base='bbbbbbbbbbbbbbbbbbbbbbb',
- openai_api_type='azure',
- model="text-embedding-ada-002",
- deployment="lk-text-embedding-ada-002",
- chunk_size=1)
-
-
- openAiLLm = AzureChatOpenAI(openai_api_key='aaaaaaaaaaaaaaaaaaaaaaaaaaaa', #注意这里,不同 API_BASE 使用不同 APK_KEY
- openai_api_base="bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb",
- openai_api_version='2023-03-15-preview',
- deployment_name='lk-gpt-35-turbo-16k',
- temperature=0.9,
- model_name="gpt-35-turbo-16k",
- max_tokens=300)
-
- print('------r---r---r----')
-
- word_RTCS = Chroma(persist_directory="./Word_RCTS/", embedding_function=embeddings)
- word_qa = RetrievalQA.from_chain_type(llm=openAiLLm,chain_type="stuff",retriever=word_RTCS.as_retriever(),return_source_documents = False)
-
- md_RTCS = Chroma(persist_directory="./MD_RCTS/", embedding_function=embeddings)
- md_qa = RetrievalQA.from_chain_type(llm=openAiLLm,chain_type="stuff",retriever=md_RTCS.as_retriever(),return_source_documents = False)
-
- #print(qa_RTCS)#查看自定义Prompt的结构体内容
- for i in range(0,len(getQuestionList())):
- question_text=getQuestionList()[i]
-
- # 进行问答
- wordchat = word_qa({"query": question_text})
- wordquery = str(wordchat['query'])
- wordresult = str(wordchat['result'])
-
- print("问题: ",wordquery)
- print("无优化-结果:",wordresult)
- time.sleep(1)#每次提问间隔1s
-
-
- csvchat = md_qa({"query": question_text})
- csvquery = str(csvchat['query'])
- csvresult = str(csvchat['result'])
- #print("MD问题: ",csvquery)
- print("有优化-结果:",csvresult)
- print('----------------------------------------')
-
- time.sleep(1)#每次提问间隔1s

