- 1机器翻译的新波:探索零 shot和一 shot翻译方法
- 2前端开发攻略---封装calendar日历组件,实现日期多选。可根据您的需求任意调整,可玩性强。
- 3【个人总结】大二这一年我都干了啥?_字节日常实习简历全部都挂掉了为什么
- 4数据结构(一):数组及面试常考的算法_数据结构常考算法
- 5selenium-语法_selenium版块官方文档
- 6深度强化学习笔记——基本方法分类与一般思路_深度强化学习分类
- 7分布式锁其实很简单,6行代码教你实现redis分布式锁,千万不要再用redisTemplate写redis分布式锁代码实现
- 8【整理】BIOS、BootLoader、uboot对比
- 9java可以开发人工智能吗_java能做智能产品吗
- 10STM32 HAL库F103系列之DAC实验(一)
分布式与一致性协议之CAP(一)
赞
踩
CAP理论
概述。
在开发分布式系统的时候,会遇到一个非常棘手的问题,那就是如何根据业务特点,为系统设计合适的分区容错一致性模型,以实现集群能力。这个问题棘手在当发生分区错误时,应该如何保障系统稳定运行而不影响业务。CAP理论对分布式系统的特性做了高度抽象,比如抽象成一致性、可用性、分区容错性,并对特性间的冲突(也就是CAP不可能三角)做了总结。
问题来了:什么是一致性、可用性和分区容错性?它们之间有什么关系?我们又该如何使用CAP理论来思考和设计分区容错一致性模型呢?
CAP理论:分布式系统的PH试纸,用它来测酸碱度。
CAP理论就像PH试纸一样,可以用来度量分布式系统的酸碱度,帮助我们思考如何设计合适的酸碱度,在一致性和可用性之间进行妥协、这种,进而设计出满足场景特点的分布式系统。那么如何理解CAP理论呢?
CAP三指标
CAP理论对分布式系统的特性做了高度抽象,形成了3个指标:
- 1.一致性(Consistency);
- 2.可用性(Availability)
- 3.分区容错性(Parition Tolerance)
一致性是指客户端的每次读操作,不管访问哪个节点,要么读到的是同一份最新写入的数据,要么读取失败。大家可以把一致性看作分布式系统对访问自己的客户端的一种承诺:不管你访问哪个节点,要么我给你返回的
是绝对一致的最新写入的数据,要么你读取失败。可以看到,一致性强调的是数据正确。
一致性指标
描述的是分布式系统的一个非常重要的特性,强调的是数据正确。也就是说,对客户端而言,它每次都能读取到最新写入的数据。
不过集群毕竟不是单机,当发生分区故障时,不能仅仅因为节点间出现了通信问题,无法响应最新写入的数据,就在客户端查询数据时一直想客户端返回出错信息,举个例子说明.业务集群中的一些关键系统,比如名字路由系统(基于Raft算法的强一致性系统),如果仅仅因为发生了分区故障,
无法响应最新数据(比如因通信异常,候选人都无法赢得大多数选票,使得集群没有了领导者),为了不破坏一致性,在客户端查询相关路由信息时,系统就一直向客户端返回出错信息,此时相关的业务都将因为获取不倒指定路由信息而不可用、瘫痪,出现灾难性的故障。此时,我们就需要牺牲数据正确的要求,在每个节点使用本地数据来响应客户端请求,以保证服务可用,这也是另外一个指标,可用性。
例子
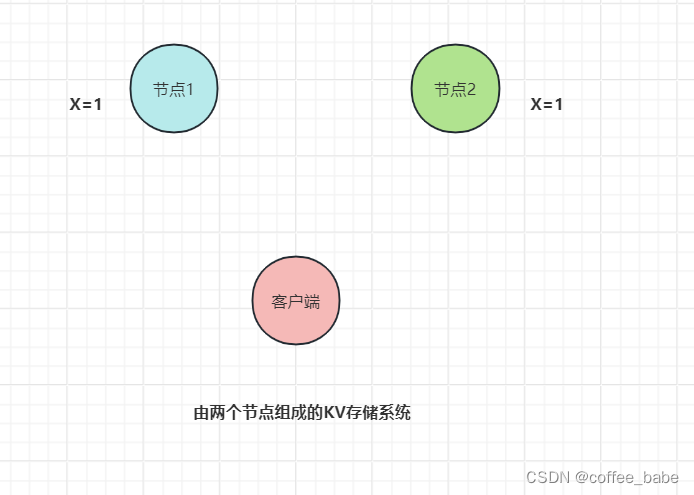
- 举个例子。两个节点的KV存储系统,原始的KV记录为"X=1",如图所示:
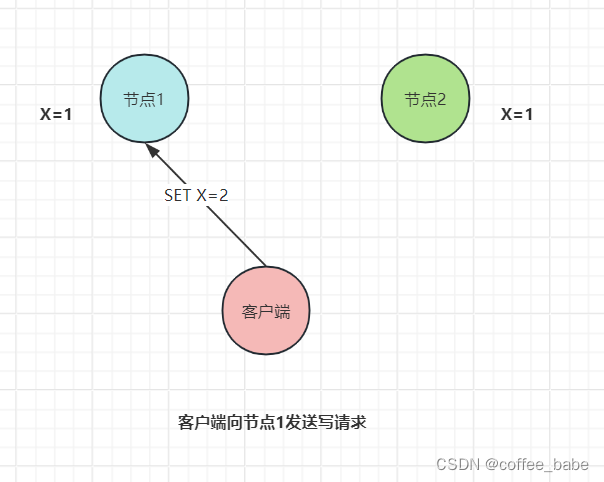
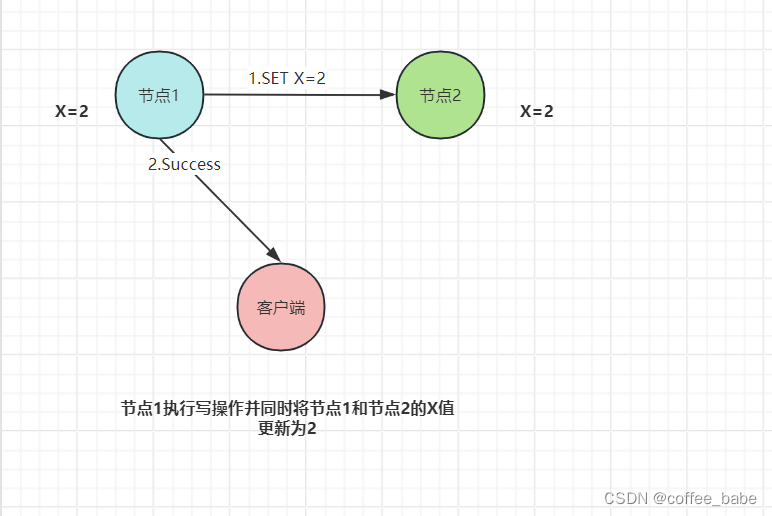
紧接着,客户端向节点1发送写请求"SET X=2",如图所示
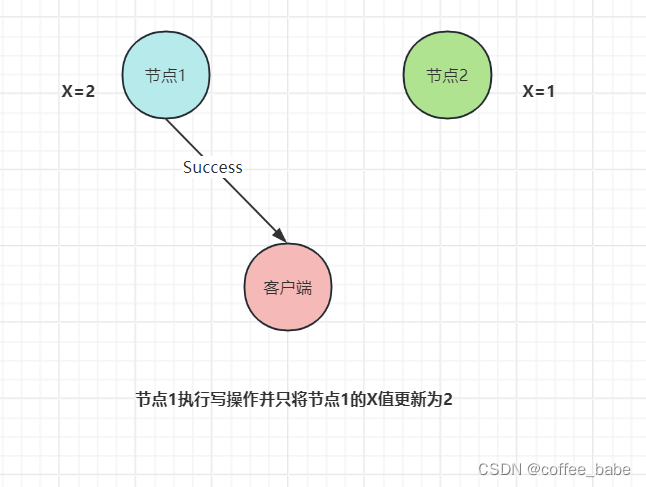
如果节点1收到写请求后,只将节点1的X值更新为2,然后返回Success给客户端,如图所示
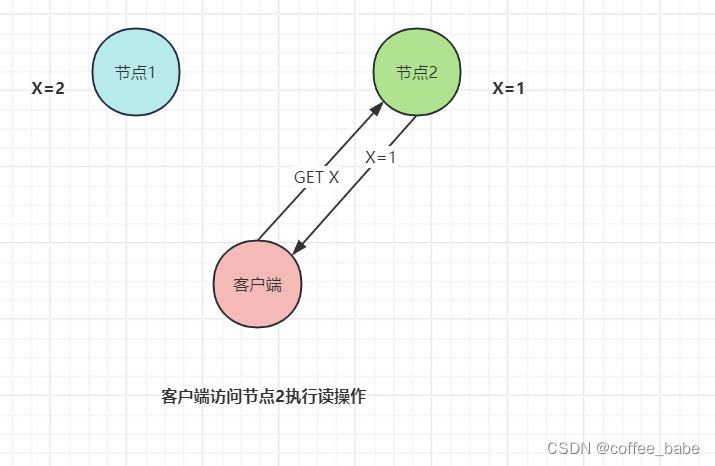
此时如果客户端访问节点2执行读操作,就无法读到最新写入的X值,这就不满足一致性了,如图所示
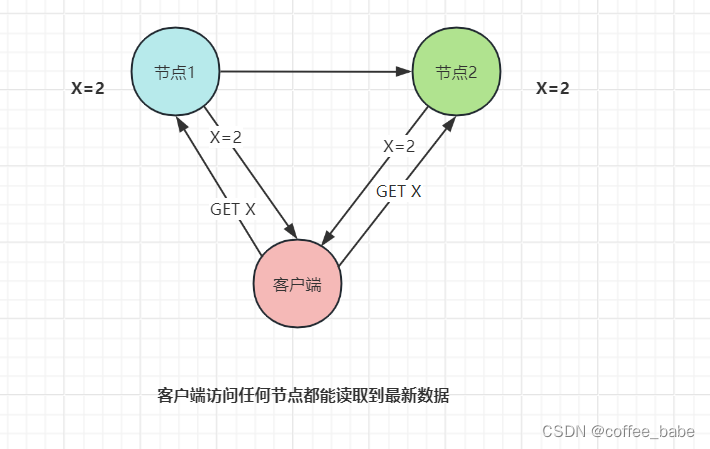
如果节点1收到写请求后,通过节点间的通信,同时将节点1和节点2的X值都更新为2,然后返回Success给客户端,如图所示
那么在完成写请求后,不管客户端访问哪个节点,读取到的都是同一份最新写入的数据,如图所示,这就叫一致性。
可用性
是指任何来自客户端的请求,不管访问哪个非故障节点,都能得到响应数据,但不保证是同一份最新数据。也可以把可用性看作分布式系统对访问本系统的客户端的另外一种承诺:我尽力给你返回数据,不会不响应你,但是我不保证每个节点给你的数据都是最新的。这个指标抢到的是服务可用,但不保证数据正确。
例子
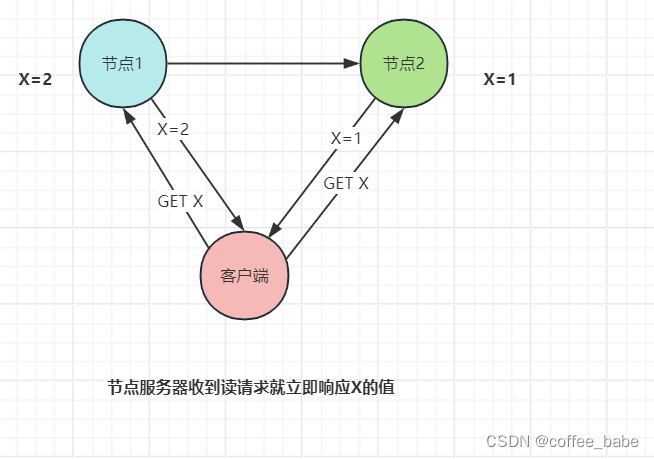
- 举个例子。比如,用户可以选择向节点1或者节点2发起读操作,如果
不考虑节点间的数据是否一致,只要节点服务器收到请求就立即响应X的值,如图所示,那么两个节点的服务是满足可用性的
分区容错性
是指当节点间出现任意数量的消息丢失或高延迟的时候,系统仍然可以继续工作,也就是说,分布式系统告诉访问本系统的客户端:不管我的内部出现什么样的数据同步问题,我都会一直运行。这个指标强调的是集群对分区故障的容错能力.因为分布式系统与单机系统不同,它涉及多节点间的通信和交互,节点间的分区故障是必然发生的,所以,在分布式系统中
分区容错性是必须要考虑的。
现在在了解了一致性、可用性和分区容错性,那么在涉及分布式系统时,是从一致性、可用性、分区容错性中选择其一,还是三者都可以选择呢?这3个指标之间有什么冲突吗?
例子
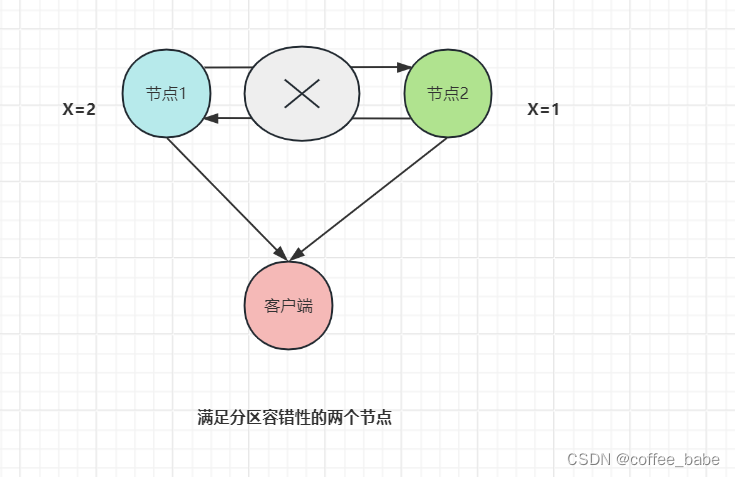
- 举个例子。当节点1和节点2的通信出现问题时,如果系统仍能继续工作,那么两个节点是满足分区容错性的