
- 1Resource wordnet not found. ; [nltk_data] Error loading wordnet: <urlopen error [Errno 11004]_resource wordnet not found. please use the nltk do
- 2神经网络中激活函数选择法则_激活函数的选取准则
- 3负载均衡算法详解与实践_负载算法详解
- 4线性方程组数学原理、矩阵原理及矩阵变换本质、机器学习模型参数求解相关原理讨论...
- 5HomeAssistant快速使用教程二:安装mqtt,作为消息服务器_海纳思安装mqtt
- 6Zynq7020-PS端裸机--EMMC/SD驱动实现_zynq7020 emmc硬件设计
- 7Linux平台利用Ollama和Open WebUI部署大模型_open webui 如何添加模型(1)_ollama网址访问
- 8linux操作系统之超级用户(root)及sudo命令概念及用途详解 简单易懂_chucheer:!:19752:0:99999:7:::
- 9java实现三方登陆:微信登陆功能的实现_java实现微信登录第三方应用
- 10Selenium元素定位方法:css_selector定位_selenium中类选择器
论文精读--Attention is all you need_attention is all you need pdf
赞
踩
Abstract
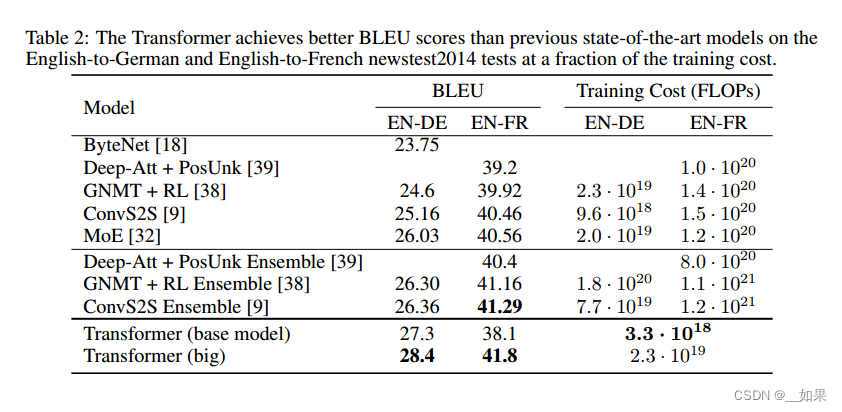
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 Englishto-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
翻译:
主要的序列转导模型是基于复杂的循环或卷积神经网络,包括一个编码器和一个解码器。表现最好的模型还是通过注意机制连接编码器和解码器。我们提出了一个新的简单的网络架构,transformer,完全基于注意力机制,完全摒弃循环和卷积。在两个机器翻译任务上的实验表明,这些模型在质量上更优越,同时更具并行性,并且需要更少的训练时间。我们的模型在WMT 2014英语-德语翻译任务上实现了28.4 BLEU,比现有的最佳结果(包括集合)提高了2个BLEU以上。在WMT 2014英法翻译任务中,我们的模型在8个gpu上训练3.5天后,建立了一个新的单模型最先进的BLEU分数41.8,这是文献中最佳模型训练成本的一小部分。我们通过将Transformer成功地应用于具有大量和有限训练数据的英语选区解析,证明了它可以很好地推广到其他任务。
总结:
提出了一个又新又简单的模型,只使用注意力机制,丢掉RNN与CNN
Introduction
Recurrent neural networks, long short-term memory and gated recurrent neural networks in particular, have been firmly established as state of the art approaches in sequence modeling and transduction problems such as language modeling and machine translation. Numerous efforts have since continued to push the boundaries of recurrent language models and encoder-decoder architectures.
翻译:
递归神经网络,特别是长短期记忆和门控递归神经网络,已经成为序列建模和转导问题(如语言建模和机器翻译)中最先进的方法。从那以后,大量的努力继续推动循环语言模型和编码器-解码器体系结构的边界。
Recurrent models typically factor computation along the symbol positions of the input and output sequences. Aligning the positions to steps in computation time, they generate a sequence of hidden states ht, as a function of the previous hidden state ht−1 and the input for position t. This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples. Recent work has achieved significant improvements in computational efficiency through factorization tricks and conditional computation, while also improving model performance in case of the latter. The fundamental constraint of sequential computation, however, remains.
翻译:
循环模型通常沿输入和输出序列的符号位置进行因子计算。将位置与计算时间中的步骤对齐,它们生成隐藏状态序列ht,作为前一个隐藏状态ht−1的函数和位置t的输入。这种固有的顺序性质排除了训练示例中的并行化,这在较长的序列长度下变得至关重要,因为内存约束限制了跨示例的批处理。最近的工作通过因式分解技巧和条件计算实现了计算效率的显著提高,同时也提高了模型在后者情况下的性能。然而,顺序计算的基本约束仍然存在。
总结:
解释了RNN的缺点:难以并行,必须从左往右算;难以保留长程信息
Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences. In all but a few cases, however, such attention mechanisms are used in conjunction with a recurrent network.
翻译:
注意力机制已经成为各种任务中引人注目的序列建模和转导模型的组成部分,允许在不考虑它们在输入或输出序列中的距离的情况下对依赖关系进行建模。然而,除了少数情况外,在所有情况下,这种注意机制都与循环网络结合使用。
总结:
attention在RNN上的应用:如何把编码器的东西有效地传给解码器
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output.
The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.
翻译:
在这项工作中,我们提出了Transformer,这是一种避免重复的模型架构,而是完全依赖于注意机制来绘制输入和输出之间的全局依赖关系。
Transformer允许显着更多的并行化,并且在8个P100 gpu上经过12小时的培训后,可以达到翻译质量的新状态。
总结:
只使用注意力机制;可并行
Background
The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU, ByteNet and ConvS2S, all of which use convolutional neural networks as basic building block, computing hidden representations in parallel for all input and output positions. In these models, the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet. This makes it more difficult to learn dependencies between distant positions. In the Transformer this is reduced to a constant number of operations, albeit at the cost of reduced effective resolution due to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as described in section 3.2.
翻译:
减少顺序计算的目标也构成了Extended Neural GPU、ByteNet和ConvS2S的基础,它们都使用卷积神经网络作为基本构建块,并行计算所有输入和输出位置的隐藏表示。在这些模型中,将两个任意输入或输出位置的信号关联起来所需的操作数量随着位置之间的距离而增长,ConvS2S为线性增长,ByteNet为对数增长。这使得学习远距离位置之间的依赖关系变得更加困难。在Transformer中,这被减少到一个恒定的操作数量,尽管其代价是由于平均注意加权位置而降低了有效分辨率,我们用3.2节中描述的多头注意抵消了这一影响。
总结:
提到用CNN替换RNN减少时序的计算的工作,但CNN长程建模比较困难。而transformer的注意力机制可以一次看到完整的序列
CNN比较好的地方是可以做多个输出通道,一个输出通道可以认为它可以去识别不同的模式。作者也想达到这样的效果,由此提出了多头注意力机制
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. Self-attention has been used successfully in a variety of tasks including reading comprehension, abstractive summarization, textual entailment and learning task-independent sentence representations.
翻译:
自注意力,有时被称为内注意力,是一种将单个序列的不同位置联系起来以计算该序列的表示的注意力机制。自注意力在阅读理解、抽象总结、文本蕴涵和学习任务无关的句子表征等任务中得到了成功的应用。
总结:
自注意力并不是作者第一个提出的,但是是文章的核心内容之一
End-to-end memory networks are based on a recurrent attention mechanism instead of sequencealigned recurrence and have been shown to perform well on simple-language question answering and language modeling tasks.
翻译:
端到端记忆网络基于循环注意力机制而不是顺序排列的递归,并且在简单语言问答和语言建模任务中表现良好。
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequencealigned RNNs or convolution. In the following sections, we will describe the Transformer, motivate self-attention and discuss its advantages over models such as [17, 18] and [9].
翻译:
然而,据我们所知,Transformer是第一个完全依赖于自注意力来计算其输入和输出表示的转导模型,而不使用序列对齐RNN或CNN。在下面的部分中,我们将描述Transformer,促使自注意力,并讨论它相对于[17,18]和[9]等模型的优势。
总结:
Transformer是第一个完全依赖于自注意力来计算其输入和输出表示的转导模型
Model Architecture
Most competitive neural sequence transduction models have an encoder-decoder structure.
Here, the encoder maps an input sequence of symbol representations (x1, ..., xn) to a sequence of continuous representations z = (z1, ..., zn). Given z, the decoder then generates an output sequence (y1, ..., ym) of symbols one element at a time. At each step the model is auto-regressive, consuming the previously generated symbols as additional input when generating the next.
翻译:
大多数竞争性神经序列转导模型具有编码器-解码器结构。
这里,编码器映射符号表示(x1,…xn)的输入序列到连续表示序列z = (z1,…zn)。给定z,解码器然后生成输出序列(y1,…ym)符号,一次一个元素。在每一步中,模型都是自回归的,在生成下一个符号时,将之前生成的符号作为额外的输入。
总结:
encoder的结果是词向量序列,decoder再把这个序列转成结果,构成自回归,也就是过去的输出会作为当前的输入
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
翻译:
Transformer遵循这个整体架构,使用堆叠的自关注层和点方向层,完全连接编码器和解码器层,分别如图1的左半部分和右半部分所示。
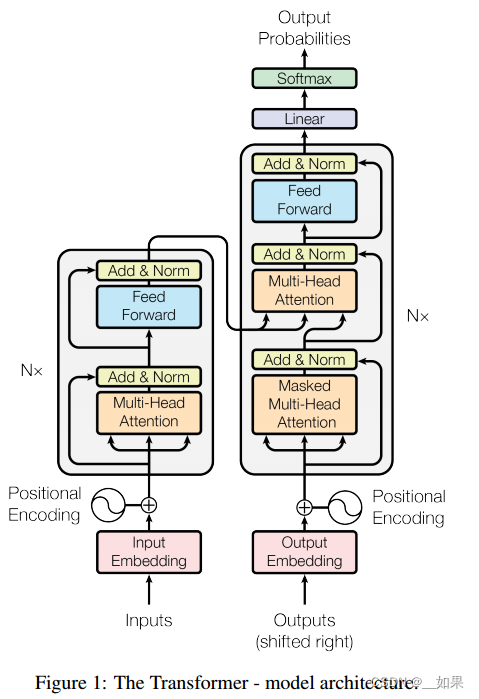
Encoder and Decoder Stacks
Encoder
The encoder is composed of a stack of N = 6 identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, positionwise fully connected feed-forward network. We employ a residual connection around each of the two sub-layers, followed by layer normalization. That is, the output of each sub-layer is LayerNorm(x + Sublayer(x)), where Sublayer(x) is the function implemented by the sub-layer itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension dmodel = 512.
翻译:
编码器由N = 6个相同层的堆栈组成。每一层有两个子层。第一种是多头自注意机制,第二种是简单的、位置完全连接的前馈网络。我们在每一个子层周围使用残差连接,然后进行层归一化。也就是说,每个子层的输出是LayerNorm(x + Sublayer(x)),其中Sublayer(x)是子层本身实现的函数。为了方便这些残差连接,模型中的所有子层以及嵌入层产生的输出维度为dmodel = 512。
总结:
控制了输出维度都为512,使模型相对比较简单。这个简单设计影响到后面一系列网络,例如bert、gpt,其实也就只有N和dmodel两个参数需要调
Decoder
The decoder is also composed of a stack of N = 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization. We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
翻译:
解码器也由N = 6层相同的堆栈组成。除了每个编码器层中的两个子层之外,解码器插入第三个子层,该子层对编码器堆栈的输出执行多头注意力。与编码器类似,我们在每个子层周围使用残差连接,然后进行层规范化。我们还修改了解码器堆栈中的自注意力子层,以防止位置关注后续位置。这种掩蔽,再加上输出嵌入被偏移一个位置的事实,确保了位置i的预测只能依赖于位置小于i的已知输出。
总结:
decoder中的mask保证了注意力看不到该单词之后的部分
Attention
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
翻译:
注意力函数可以描述为将查询和一组键值对映射到输出,其中查询、键、值和输出都是向量。输出是作为值的加权和计算的,其中分配给每个值的权重是由查询与相应键的兼容性函数计算的。
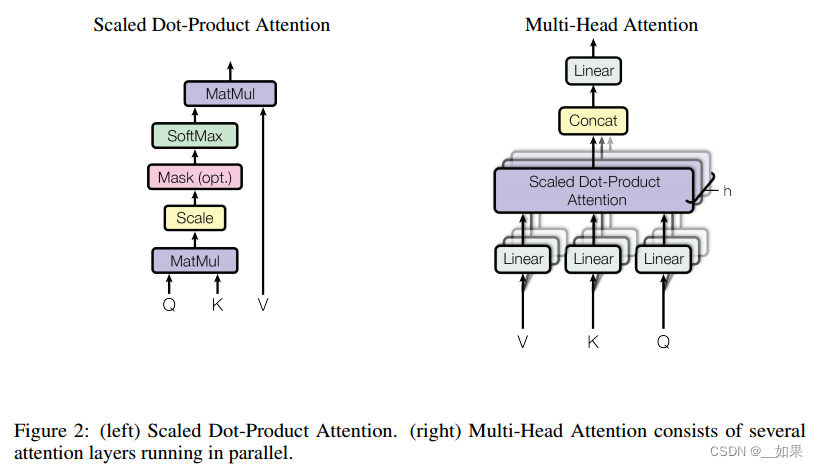
Scaled Dot-Product Attention
We call our particular attention "Scaled Dot-Product Attention" (Figure 2). The input consists of queries and keys of dimension dk, and values of dimension dv. We compute the dot products of the query with all keys, divide each by √ dk, and apply a softmax function to obtain the weights on the values.
In practice, we compute the attention function on a set of queries simultaneously, packed together into a matrix Q. The keys and values are also packed together into matrices K and V . We compute the matrix of outputs as:
The two most commonly used attention functions are additive attention, and dot-product (multiplicative) attention. Dot-product attention is identical to our algorithm, except for the scaling factor of 1 √ dk . Additive attention computes the compatibility function using a feed-forward network with a single hidden layer. While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.
While for small values of dk the two mechanisms perform similarly, additive attention outperforms dot product attention without scaling for larger values of dk. We suspect that for large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients 4 . To counteract this effect, we scale the dot products by 1 √ dk .
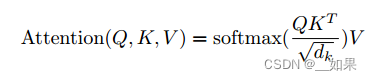
翻译:
我们称我们的特殊关注为“缩放点积关注”(图2)。输入由维度dk的查询和键以及维度dv的值组成。我们计算查询与所有键的点积,每个点积除以√dk,并应用softmax函数来获得值的权重。
在实践中,我们同时计算一组查询的注意力函数,这些查询被打包成矩阵q。键和值也被打包成矩阵K和V。我们计算输出矩阵为:
Attention(Q, K, V) = softmax(QKT/√dk)V
两个最常用的注意函数是additive Attention和dot-product (multiply) Attention。点积注意力和我们的算法是一样的,除了比例因子是1√dk。加性注意使用一个具有单个隐藏层的前馈网络来计算兼容性函数。虽然两者在理论复杂性上相似,但在实践中,点积注意力更快,更节省空间,因为它可以使用高度优化的矩阵乘法代码来实现。
当dk值较小时,两种机制的表现相似,当dk值较大时,加性注意优于点积注意。我们怀疑,对于较大的dk值,点积的大小会变大,从而将softmax函数推入具有极小梯度的区域4。为了抵消这个影响,我们将点积乘以1√dk。
总结:
利用矩阵乘法并行计算
加性注意力可以解决query和key的不等长问题,点积则是上面的式子去掉缩放的√dk
当dk过大时,也就代表你的query和key过长,点积的结果会过大或过小,导致softmax中大的数更靠近1,其他值更靠近0,数值向两端靠拢,导致梯度较小
Multi-Head Attention
Instead of performing a single attention function with dmodel-dimensional keys, values and queries, we found it beneficial to linearly project the queries, keys and values h times with different, learned linear projections to dk, dk and dv dimensions, respectively. On each of these projected versions of queries, keys and values we then perform the attention function in parallel, yielding dv-dimensional output values. These are concatenated and once again projected, resulting in the final values, as depicted in Figure 2.
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
In this work we employ h = 8 parallel attention layers, or heads. For each of these we use dk = dv = dmodel/h = 64. Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.

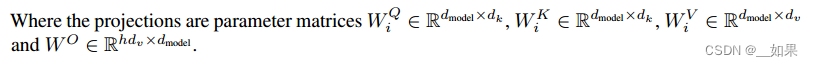
翻译:
我们发现,与其使用dmodel维度的键、值和查询执行单一的注意力函数,不如将查询、键和值分别以不同的、学习过的线性投影h次线性投影到dk、dk和dv维度,这是有益的。然后,在查询、键和值的每个投影版本上,我们并行地执行注意力函数,生成d维输出值。将它们连接起来并再次进行投影,得到最终值,如图2所示。
多头注意允许模型在不同位置共同注意来自不同表示子空间的信息。对于单一注意力头,平均会抑制这一点。
在这项工作中,我们使用h = 8个平行的注意层,或头。对于每一个,我们使用dk = dv = dmodel/h = 64。由于每个头部的维数降低,因此总计算成本与全维的单头部关注相似。
总结:
qkv投影多次到低维做h次注意力函数,输出并在一起再投影得到最终输出
投影的方法是可学习的,目的是使投影到的空间中能匹配不同模式,公式中的W都是可学习投影的
输出维度固定,所以多头注意力维度是dmodel/h
Applications of Attention in our Model
The Transformer uses multi-head attention in three different ways:
• In "encoder-decoder attention" layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence. This mimics the typical encoder-decoder attention mechanisms in sequence-to-sequence models such as [38, 2, 9].
• The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
• Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. We need to prevent leftward information flow in the decoder to preserve the auto-regressive property. We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections. See Figure 2.
翻译:
Transformer以三种不同的方式使用多头注意力:
•在“编码器-解码器注意力”层中,查询来自前一个解码器层,而记忆键和值来自编码器的输出。这允许解码器中的每个位置都参与输入序列中的所有位置。这模仿了序列到序列模型中典型的编码器-解码器注意机制,如[38,2,9]。
•编码器包含自注意力层。在自注意力层中,所有的键、值和查询都来自同一个地方,在这种情况下,是编码器中前一层的输出。编码器中的每个位置都可以处理编码器前一层中的所有位置。
•类似地,解码器中的自注意力层允许解码器中的每个位置关注解码器中的所有位置,直至并包括该位置。我们需要防止解码器中的向左信息流以保持自回归特性。我们通过掩码(设置为−∞)softmax输入中对应于非法连接的所有值来实现缩放点积注意力。参见图2。
总结:
编码器中的多头注意力机制是自注意力机制,qkv都是词嵌入向量
解码器中带掩码的和编码器中的不同点在于增加了mask(-∞)防止穿越
最后一个,kv来自于编码器的输出,q来自于解码器下面的输入,达到从编码器的输出中提取有效关系的结果
Position-wise Feed-Forward Networks
In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between.
While the linear transformations are the same across different positions, they use different parameters from layer to layer. Another way of describing this is as two convolutions with kernel size 1.
The dimensionality of input and output is dmodel = 512, and the inner-layer has dimensionality df f = 2048.
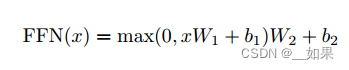
翻译:
除了注意子层之外,编码器和解码器中的每一层都包含一个完全连接的前馈网络,该网络分别相同地应用于每个位置。这包括两个线性转换,中间有一个ReLU激活。
虽然线性变换在不同位置上是相同的,但它们每层使用不同的参数。另一种描述它的方式是两个核大小为1的卷积。
输入和输出的维数为dmodel = 512,内层的维数df = 2048。
总结:
单隐藏层的MLP,维度先扩大四倍再缩小四倍
MLP单独作用于每个词向量,因为在注意力层已经完成了序列信息的提取
Embeddings and Softmax
Similarly to other sequence transduction models, we use learned embeddings to convert the input tokens and output tokens to vectors of dimension dmodel. We also use the usual learned linear transformation and softmax function to convert the decoder output to predicted next-token probabilities. In our model, we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation, similar to [30]. In the embedding layers, we multiply those weights by √ dmodel.
翻译:
与其他序列转导模型类似,我们使用学习嵌入将输入token和输出token转换为维度dmodel的向量。我们还使用通常学习的线性变换和softmax函数将解码器输出转换为预测的下一个token概率。在我们的模型中,我们在两个嵌入层和pre-softmax线性变换之间共享相同的权矩阵,类似于[30]。在嵌入层中,我们将这些权重乘以√dmodel。
总结:
三个Embedding共享权重,训练方便
乘以√dmodel是因为学Embedding的时候多多少少会把向量的L2 Norm学成相对比较小的值
Positional Encoding
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. To this end, we add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension dmodel as the embeddings, so that the two can be summed. There are many choices of positional encodings, learned and fixed.
In this work, we use sine and cosine functions of different frequencies:
where pos is the position and i is the dimension. That is, each dimension of the positional encoding corresponds to a sinusoid. The wavelengths form a geometric progression from 2π to 10000 · 2π. We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset k, P Epos+k can be represented as a linear function of P Epos.
We also experimented with using learned positional embeddings instead, and found that the two versions produced nearly identical results (see Table 3 row (E)). We chose the sinusoidal version because it may allow the model to extrapolate to sequence lengths longer than the ones encountered during training.

翻译:
由于我们的模型不包含递归和卷积,为了使模型利用序列的顺序,我们必须注入一些关于序列中标记的相对或绝对位置的信息。为此,我们在编码器和解码器堆栈底部的输入嵌入中添加了“位置编码”。位置编码与嵌入具有相同的维数模型,因此可以对两者进行求和。位置编码有多种选择,有习得的和固定的。
在这项工作中,我们使用不同频率的正弦和余弦函数
其中pos是位置,i是维度。也就是说,位置编码的每一个维度对应于一个正弦波。波长形成从2π到10000·2π的几何级数。我们选择这个函数是因为我们假设它可以让模型很容易地通过相对位置来学习,因为对于任何固定的偏移量k, P Epos+k可以表示为P Epos的线性函数。
我们还尝试使用学习的位置嵌入,并发现这两个版本产生了几乎相同的结果(见表3 (E)行)。我们选择正弦版本是因为它可以允许模型外推到比训练期间遇到的序列长度更长的序列。
总结:
attention没有时序性,只考虑单词之间的相似度,这是不合理的,因此使用位置编码加入时序信息
Why Self-Attention

第一列是计算复杂度,第二列是顺序计算的步数,第三列是一个数据点到另一个数据点要走多远
n为序列长度,d为向量长度
自注意力中:query有n行d维,key也有n行d维,qk相乘复杂度为for n: for d: for n:...
第四行是指自注意力时,query只和其最近的r个key相乘
Training
5.1Training Data and Batching We trained on the standard WMT 2014 English-German dataset consisting of about 4.5 million sentence pairs. Sentences were encoded using byte-pair encoding [3], which has a shared sourcetarget vocabulary of about 37000 tokens. For English-French, we used the significantly larger WMT 2014 English-French dataset consisting of 36M sentences and split tokens into a 32000 word-piece vocabulary [38]. Sentence pairs were batched together by approximate sequence length. Each training batch contained a set of sentence pairs containing approximately 25000 source tokens and 25000 target tokens.
5.2 Hardware and Schedule We trained our models on one machine with 8 NVIDIA P100 GPUs. For our base models using the hyperparameters described throughout the paper, each training step took about 0.4 seconds. We trained the base models for a total of 100,000 steps or 12 hours. For our big models,(described on the bottom line of table 3), step time was 1.0 seconds. The big models were trained for 300,000 steps (3.5 days).
5.3 Optimizer We used the Adam optimizer [20] with β1 = 0.9, β2 = 0.98 and ϵ = 10−9 . We varied the learning rate over the course of training, according to the formula:
This corresponds to increasing the learning rate linearly for the first warmup_steps training steps, and decreasing it thereafter proportionally to the inverse square root of the step number. We used warmup_steps = 4000.
5.4 Regularization We employ three types of regularization during training:
Residual Dropout We apply dropout [33] to the output of each sub-layer, before it is added to the sub-layer input and normalized. In addition, we apply dropout to the sums of the embeddings and the positional encodings in both the encoder and decoder stacks. For the base model, we use a rate of Pdrop = 0.1.
Label Smoothing During training, we employed label smoothing of value ϵls = 0.1 [36]. This hurts perplexity, as the model learns to be more unsure, but improves accuracy and BLEU score.
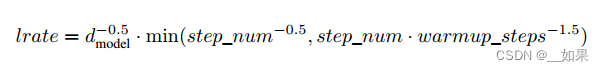
翻译:
5.1 训练数据和批处理我们在标准的WMT 2014英德语数据集上进行训练,该数据集包含约450万句对。句子使用字节对编码[3]进行编码,该编码具有大约37000个标记的共享源-目标词汇表。对于英语-法语,我们使用了更大的WMT 2014英语-法语数据集,该数据集包含3600万个句子,并将标记分割成32000个单词-词汇表[38]。句子对按近似序列长度进行批处理。每个训练批包含一组句子对,其中包含大约25000个源标记和25000个目标标记。
5.2 我们在一台带有8个NVIDIA P100 gpu的机器上训练我们的模型。对于使用本文中描述的超参数的基本模型,每个训练步骤大约需要0.4秒。我们对基本模型进行了总共10万步或12小时的训练。对于我们的大型模型(如表3所示),步长为1.0秒。大模型训练了30万步(3.5天)。
5.3 我们使用Adam优化器[20],β1 = 0.9, β2 = 0.98, λ = 10−9。我们根据公式在训练过程中改变学习率。这对应于在第一个warmup_steps训练步骤中线性增加学习率,然后按步数的倒数平方根成比例地降低学习率。我们使用了warmup_steps = 4000。
5.4 我们在训练中使用了三种类型的正则化:
我们将Dropout[33]应用于每个子层的输出,然后将其添加到子层输入并归一化。此外,我们将dropout应用于编码器和解码器堆栈中的嵌入和位置编码之和。对于基本模型,我们使用Pdrop = 0.1的速率。
在训练过程中,我们使用值ϵls = 0.1的标签平滑[36]。这损害了困惑,因为模型学会了更不确定,但提高了准确性和BLEU分数。
Conclusion
In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention.
For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles.
We are excited about the future of attention-based models and plan to apply them to other tasks. We plan to extend the Transformer to problems involving input and output modalities other than text and to investigate local, restricted attention mechanisms to efficiently handle large inputs and outputs such as images, audio and video. Making generation less sequential is another research goals of ours.
The code we used to train and evaluate our models is available at https://github.com/ tensorflow/tensor2tensor.
翻译:
在这项工作中,我们提出了Transformer,这是第一个完全基于注意力的序列转导模型,用多头自注意力取代了编码器-解码器架构中最常用的循环层。
对于翻译任务,Transformer的训练速度明显快于基于循环层或卷积层的体系结构。在WMT 2014的英语到德语和WMT 2014的英语到法语翻译任务上,我们都达到了一个新的水平。在前一个任务中,我们的最佳模型甚至优于所有先前报道的集成。
我们对基于注意力的模型的未来感到兴奋,并计划将其应用于其他任务。我们计划将Transformer扩展到涉及文本以外的输入和输出模式的问题,并研究局部的、受限的注意力机制,以有效地处理大量的输入和输出,如图像、音频和视频。使生成不那么时序化是我们的另一个研究目标。
我们用来训练和评估模型的代码可以在https://github.com/ tensorflow/tensor2tensor上找到。

