
GitHub 上有哪些优秀的 Python 爬虫项目?_python爬虫github
赞
踩
在Python的学习中,很多的小伙伴喜欢做爬虫,爬虫程序可以快速的从网络上获取大量的我们感兴趣的数据,但是爬虫程序需要不断的及时的维护,而且要自己从零开始,尤其是对于爬虫新手来讲,写一个爬虫程序是非常煎熬的,学习成本太高了。
小编最近在GitHub上看到了一个爬虫项目,是中文开源的,专门针对于爬虫新手来设计的,赶紧跟大家来分享一下。该项目的名称叫做examples-of-web-crawlers,从名字可以看出,该项目是针对于爬虫的,项目的地址为:
https://github.com/shengqiangzhang/examples-of-web-crawlers
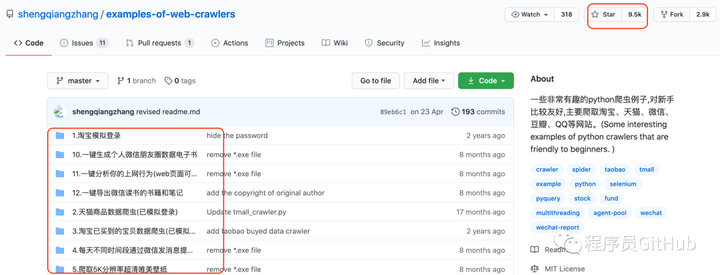
打开该项目的链接后,作者非常清楚的让大家看到,作者提供的是一些非常有趣的,而且代码的通用性和时效性强,最重要的是,代码对于新手非常的友好,配备了大量的注释。
01.项目简介
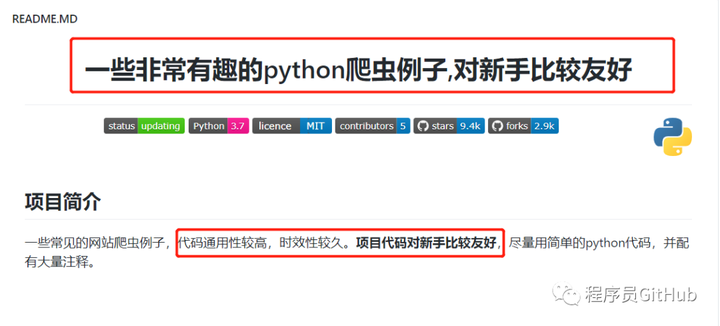
可以看到,作者为大家提供了非常丰富的内容介绍,作者不仅仅告诉大家程序是如何编写的,而且还配上了GIF的动图展示。为了更好的展现作者的项目用途,接下来,小编将利用作者提供的程序,来实际运行一下,看一下程序的效果如何。
02.淘宝模拟登录
我们首先以淘宝模拟登录为例,来进行展示,作者使用的是selenium来进行淘宝网页的模拟登录,程序如下图所示:
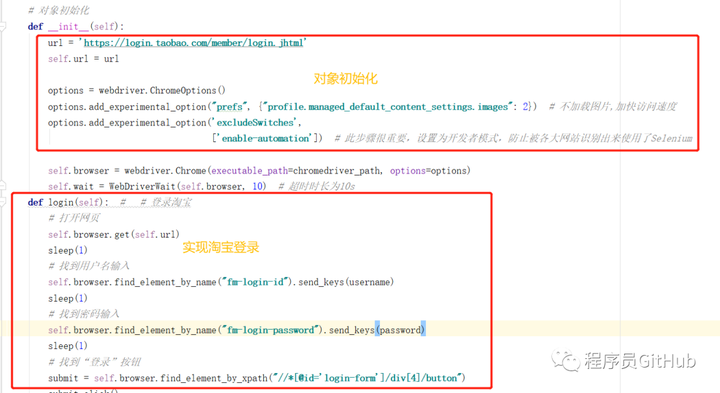
上述的程序中,可以看到,首先是对象的初始化部分,包括了selenium信息的设置,不加载图片,以便加快访问速度,将selenium打开的网页设置为开发者模式。
在login函数中,先是用selenium代开网页,然后是找到用户名输入和密码输入的标签,并分别输入用户名和密码,然后找到“登录”按钮,并点击登录,这样就可以实现淘宝网页的模拟登录,程序运行效果如下图所示:
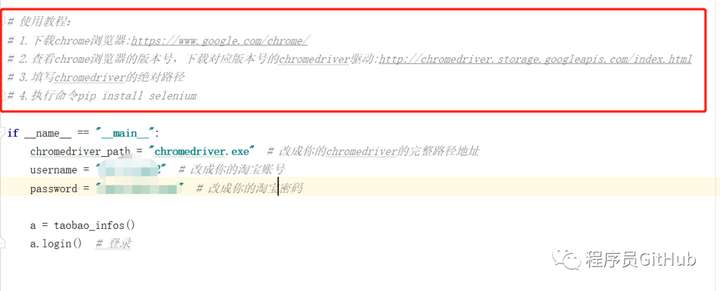
可以看到,程序在执行的过程中,分别找到了用户名和密码的位置 ,并分别输入了用户名和密码后点击登录,登录后的页面中也省略了图片的实现。加快了访问的速度。此外,程序中还给出了非常详尽的使用教程。甚至是包括了浏览器的下载和chromedriver的下载方式。
03.爬取豆瓣排行榜电影数据(含GUI界面版)
该项目中还提供了包含GUI界面的程序,同时作者也给出了具体的操作流程。
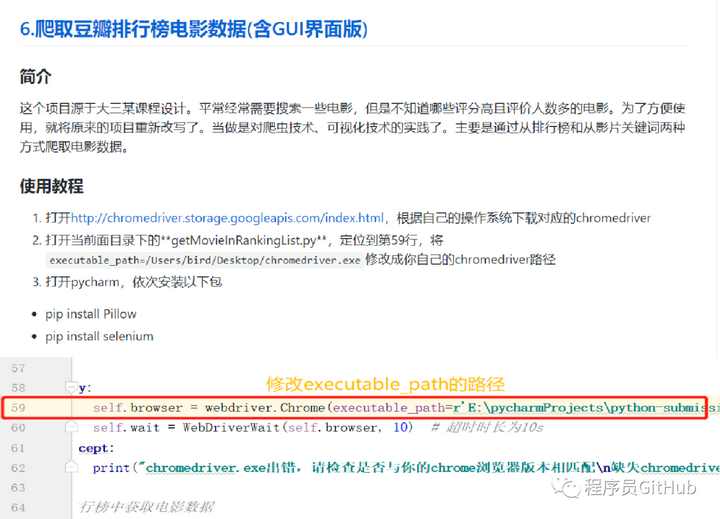
大家只需要按照指示,将getMovieInRankingList.py文件中的第59行中的executable_path改成自己的chromedriver路径即可。然后点击运行main.py程序即可,其运行效果如下图所示。
当程序运行后,大家可以根据自己的喜好,来分别选择“电影类型”、“获取数量”、“电影评分”、“评价人数”等搜索的关键字,并按照“从排行榜搜索”或者是“从关键字搜索”来抓取豆瓣的电影数据。同样,在程序中,作者仍旧给出了大量的中文注释,非常适合小伙伴对于GUI界面和爬虫程序的学习。
04.总结
以上就是今天小编同大家分享的关于examples-of-web-crawlers项目的内容,大家可以下载该项目,然后进行学习,来提升自己的爬虫能力。当然,由于网页变化速度极快,程序可能有存在报错的可能,需要大家耐心的调试,在调试中提升自己的能力。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
朋友们如果需要这份完整的资料可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/496312
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

