
- 1springboot + netty_netty springboot 获得hanlder
- 2Mac m1 homebrew 安装redis及redis.conf路径_/opt/homebrew/etc/redis.conf
- 3Centos 安装docker
- 4Mysql查询性能优化_update inner join select 优化
- 5最小化安装Ubuntu Server 22.04(图文详解版)_ubuntu最小化安装
- 6985毕业入职阿里,2年升职到P7,晒出真实月薪,以为看错了_阿里p7年薪
- 7CocoaPods安装(两种换源方式)和简单使用_cocoapods换源
- 8第一篇:什么是IT行业_it是敲代码的吗
- 9头歌:Spark任务提交
- 10使用 GPT4 和 ChatGPT 开发应用:第四章到第五章
Spark AQE 导致的 Driver OOM问题
赞
踩
背景
最近在做Spark 3.1 升级 Spark 3.5的过程中,遇到了一批SQL在运行的过程中 Driver OOM的情况,排查到是AQE开启导致的问题,再次分析记录一下,顺便了解一下Spark中指标的事件处理情况
结论
SQLAppStatusListener 类在内存中存放着 一个整个SQL查询链的所有stage以及stage的指标信息,在AQE中 一个job会被拆分成很多job,甚至几百上千的job,这个时候 stageMetrics的数据就会成百上倍的被存储在内存中,从而导致Driver OOM。
解决方法:
- 关闭AQE
spark.sql.adaptive.enabled false - 合并对应的PR-SPARK-45439
分析
背景知识:对于一个完整链接的sql语句来说(比如说从 读取数据源,到 数据处理操作,再到插入hive表),这可以称其为一个最小的SQL执行单元,这最小的数据执行单元在Spark内部是可以跟踪的,也就是用executionId来进行跟踪的。
对于一个sql,举例来说 :
insert into TableA select * from TableB;
- 1
在生成 物理计划的过程中会调用 QueryExecution.assertOptimized 方法,该方法会触发eagerlyExecuteCommands调用,最终会到SQLExecution.withNewExecutionId方法:
def assertOptimized(): Unit = optimizedPlan
...
lazy val commandExecuted: LogicalPlan = mode match {
case CommandExecutionMode.NON_ROOT => analyzed.mapChildren(eagerlyExecuteCommands)
case CommandExecutionMode.ALL => eagerlyExecuteCommands(analyzed)
case CommandExecutionMode.SKIP => analyzed
}
...
lazy val optimizedPlan: LogicalPlan = {
// We need to materialize the commandExecuted here because optimizedPlan is also tracked under
// the optimizing phase
assertCommandExecuted()
executePhase(QueryPlanningTracker.OPTIMIZATION) {
// clone the plan to avoid sharing the plan instance between different stages like analyzing,
// optimizing and planning.
val plan =
sparkSession.sessionState.optimizer.executeAndTrack(withCachedData.clone(), tracker)
// We do not want optimized plans to be re-analyzed as literals that have been constant
// folded and such can cause issues during analysis. While `clone` should maintain the
// `analyzed` state of the LogicalPlan, we set the plan as analyzed here as well out of
// paranoia.
plan.setAnalyzed()
plan
}
def assertCommandExecuted(): Unit = commandExecuted
...
private def eagerlyExecuteCommands(p: LogicalPlan) = p transformDown {
case c: Command =>
// Since Command execution will eagerly take place here,
// and in most cases be the bulk of time and effort,
// with the rest of processing of the root plan being just outputting command results,
// for eagerly executed commands we mark this place as beginning of execution.
tracker.setReadyForExecution()
val qe = sparkSession.sessionState.executePlan(c, CommandExecutionMode.NON_ROOT)
val name = commandExecutionName(c)
val result = QueryExecution.withInternalError(s"Eagerly executed $name failed.") {
SQLExecution.withNewExecutionId(qe, Some(name)) {
qe.executedPlan.executeCollect()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
而SQLExecution.withNewExecutionId主要的作用是设置当前计划的所属的executionId:
val executionId = SQLExecution.nextExecutionId
sc.setLocalProperty(EXECUTION_ID_KEY, executionId.toString)
- 1
- 2
该EXECUTION_ID_KEY的值会在JobStart的时候传递给Event,以便记录跟踪整个执行过程中的指标信息。
同时我们在方法中eagerlyExecuteCommands看到qe.executedPlan.executeCollect()这是具体的执行方法,针对于insert into 操作来说,物理计划就是
InsertIntoHadoopFsRelationCommand,这里的run方法最终会流转到DAGScheduler.submitJob方法:
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
JobArtifactSet.getActiveOrDefault(sc),
Utils.cloneProperties(properties)))
- 1
- 2
- 3
- 4
最终会被DAGScheduler.handleJobSubmitted处理,其中会发送SparkListenerJobStart事件:
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos,
Utils.cloneProperties(properties)))
- 1
- 2
- 3
该事件会被SQLAppStatusListener捕获,从而转到onJobStart处理,这里有会涉及到指标信息的存储,这里我们截图出dump的内存占用情况:
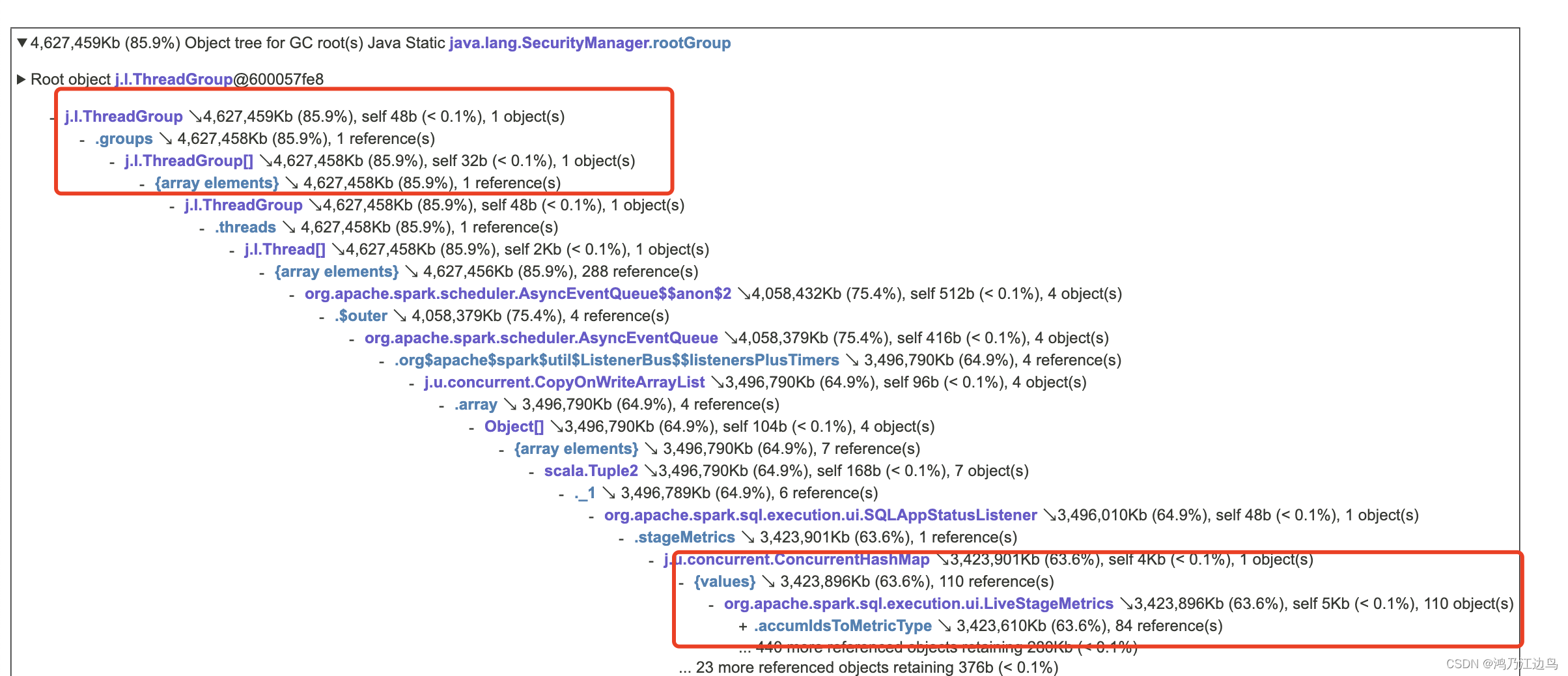
可以看到 SQLAppStatusListener 的 LiveStageMetrics 占用很大,也就是 accumIdsToMetricType占用很大
那在AQE中是怎么回事呢?
我们知道再AQE中,任务会从source节点按照shuffle进行分割,从而形成单独的job,从而生成对应的shuffle指标,具体的分割以及执行代码在AdaptiveSparkPlanExec.getFinalPhysicalPlan中,如下:
var result = createQueryStages(currentPhysicalPlan)
val events = new LinkedBlockingQueue[StageMaterializationEvent]()
val errors = new mutable.ArrayBuffer[Throwable]()
var stagesToReplace = Seq.empty[QueryStageExec]
while (!result.allChildStagesMaterialized) {
currentPhysicalPlan = result.newPlan
if (result.newStages.nonEmpty) {
stagesToReplace = result.newStages ++ stagesToReplace
executionId.foreach(onUpdatePlan(_, result.newStages.map(_.plan)))
// SPARK-33933: we should submit tasks of broadcast stages first, to avoid waiting
// for tasks to be scheduled and leading to broadcast timeout.
// This partial fix only guarantees the start of materialization for BroadcastQueryStage
// is prior to others, but because the submission of collect job for broadcasting is
// running in another thread, the issue is not completely resolved.
val reorderedNewStages = result.newStages
.sortWith {
case (_: BroadcastQueryStageExec, _: BroadcastQueryStageExec) => false
case (_: BroadcastQueryStageExec, _) => true
case _ => false
}
// Start materialization of all new stages and fail fast if any stages failed eagerly
reorderedNewStages.foreach { stage =>
try {
stage.materialize().onComplete { res =>
if (res.isSuccess) {
events.offer(StageSuccess(stage, res.get))
} else {
events.offer(StageFailure(stage, res.failed.get))
}
// explicitly clean up the resources in this stage
stage.cleanupResources()
}(AdaptiveSparkPlanExec.executionContext)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
这里就是得看stage.materialize()这个方法,这两个stage只有两类:BroadcastQueryStageExec 和 ShuffleQueryStageExec,
这两个物理计划稍微分析一下如下:
- BroadcastQueryStageExec
数据流如下:broadcast.submitBroadcastJob || \/ promise.future || \/ relationFuture || \/ child.executeCollectIterator()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
promise的设置在relationFuture方法中,而relationFuture会被doPrepare调用,而submitBroadcastJob会调用executeQuery,从而调用doPrepare,executeCollectIterator()最终也会发送JobSubmitted事件,分析和上面的一样 - ShuffleQueryStageExec
shuffle.submitShuffleJob || \/ sparkContext.submitMapStage(shuffleDependency) || \/ dagScheduler.submitMapStage- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
该submitMapStage会发送MapStageSubmitted事件:
eventProcessLoop.post(MapStageSubmitted(
jobId, dependency, callSite, waiter, JobArtifactSet.getActiveOrDefault(sc),
Utils.cloneProperties(properties)))
- 1
- 2
- 3
最终会被DAGScheduler.handleMapStageSubmitted处理,其中会发送SparkListenerJobStart事件:
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos,
Utils.cloneProperties(properties)))
- 1
- 2
- 3
该事件会被SQLAppStatusListener捕获,从而转到onJobStart处理:
private val liveExecutions = new ConcurrentHashMap[Long, LiveExecutionData]()
private val stageMetrics = new ConcurrentHashMap[Int, LiveStageMetrics]()
...
override def onJobStart(event: SparkListenerJobStart): Unit = {
val executionIdString = event.properties.getProperty(SQLExecution.EXECUTION_ID_KEY)
if (executionIdString == null) {
// This is not a job created by SQL
return
}
val executionId = executionIdString.toLong
val jobId = event.jobId
val exec = Option(liveExecutions.get(executionId))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
该方法会获取事件中的executionId,在AQE中,同一个执行单元的executionId是一样的,所以stageMetrics内存占用会越来越大。
而这里指标的更新是在AdaptiveSparkPlanExec.onUpdatePlan等方法中。
这样整个事件的数据流以及问题的产生原因就应该很清楚了。
其他
为啥AQE以后多个Job还是共享一个executionId呢?因为原则上来说,如果没有开启AQE之前,一个SQL执行单元的是属于同一个Job的,开启了AQE之后,因为AQE的原因,一个Job被拆成了了多个Job,但是从逻辑上来说,还是属于同一个SQL处理单元的所以还是得归属到一次执行中。

