
- 1电子模块|压力传感器模块HX711---硬件介绍_hx711称重传感器
- 2从零开始的Flutter之旅: StatelessWidget_flutter statelesswidget
- 3平衡二叉树的C语言实现(创建、插入、查找、删除、旋转)_c语言实现平衡二叉树包括插入与删除旋转等
- 4Golang精编100题-搞定golang面试_mhedtitupms=:ma/i/nasdtorreaabmle&.sm1o=b{ic/lsi?u
- 5dubbo消费者微服务启动报错zookeeper not connected_dubbo客户端连接到mse zookeeper not connection
- 6 剖析并利用Visual Studio Code在Mac上编译、调试c#程序
- 7详解验证码与打码平台的攻防对抗_对抗验证码
- 8MATLAB机器人工具箱RVC报错:Number of robot DOF must be >= the same number of 1s in the mask matrix_number of robot dof must be >= the number of 1s in
- 9Neo4j Desktop 管理工具的安装和应用
- 10大模型RAG(二)向量化(embedding)_大模型中向量化是什么
python编写聊天机器人(二)_# 定义一些问题和对应的回答语句 responses = { "你好": ["你好!","嗨!",
赞
踩
python编写聊天机器人(二)
一个基于检索的简单聊天机器人系统,基于余弦相似度进行相似语句的匹配。
原理简介
余弦相似度是指比较两个向量之间的余弦相似度,向量当然分别是输入句子的句向量和数据库中所有问题句子的句向量,而句子转为向量的方式是采用的word2vec。
词向量模型可以将词转为对应的向量,这些向量在空间中呈现一种语义上的关系,比如用词向量表示我们的词的时候,会发现 King的向量-Man的向量+Woman的向量=Queen的向量。
那么句子又是怎么转成向量的呢?这里我们采用了平均向量的方法,就是先对句子分词,然后将词向量相加再除以向量的个数。
详细介绍请参见:
http://www.zyiz.net/tech/detail-97215.html
一、数据预处理
1、加载库
我们先加载所需要的库,我们将会用到jieba分词工具和sklearn等nlp和机器学习所需要的库
import codecs
import jieba as jb
import re
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
import random
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
python3下导入jieba报错:
ModuleNotFoundError: No module named ‘jieba’
ModuleNotFoundError: No module named ‘pandas’
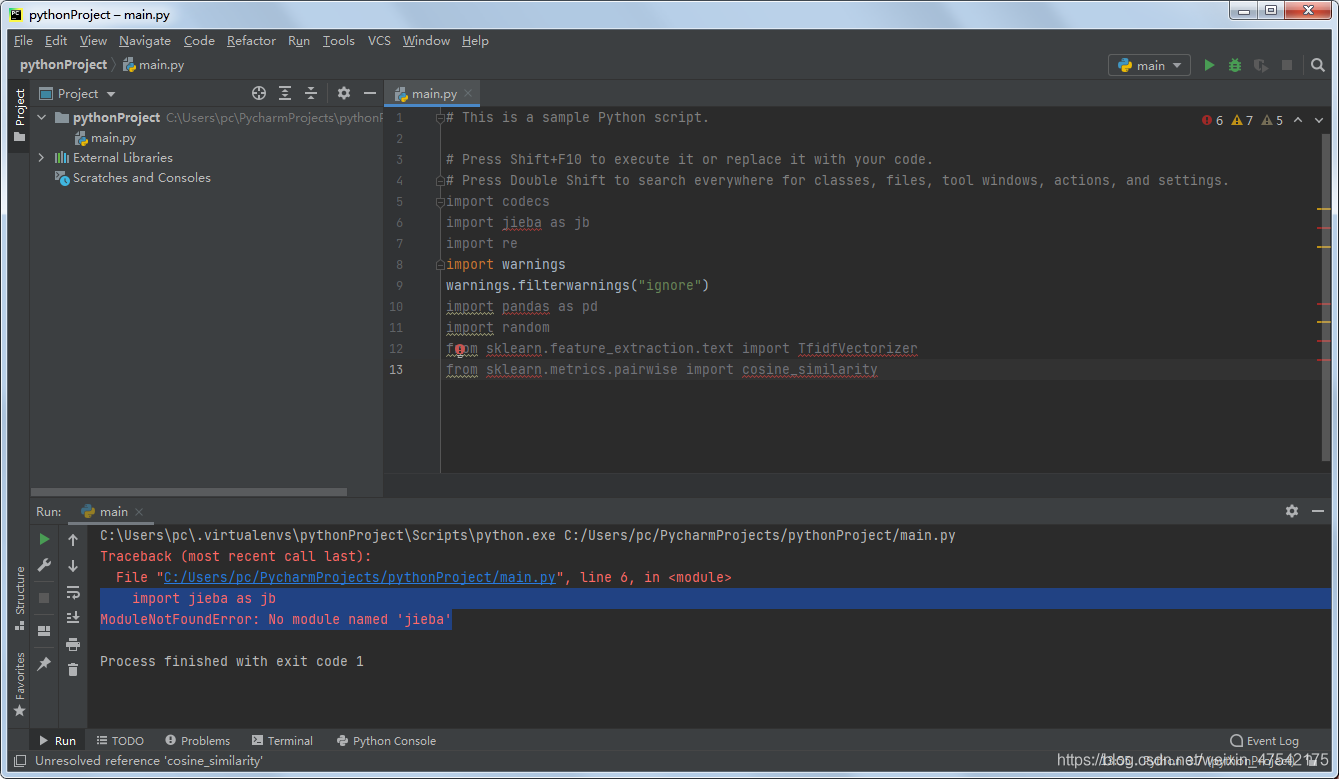
解决办法:安装jieba
pip install jieba
- 1
2、中文字符处理
接下来我们定义几个处理中文字符的函数,其中包括中文分句,删除标点符号,加载停用词等函数。
#中文分句 def SentsTokenizer4Ch(text): sentences = re.split('(。|!|\!|?|\?)',text) new_sents = [] for i in range(int(len(sentences)/2)): sent = sentences[2*i] + sentences[2*i+1] sent = sent.replace('\r\n','') sent = sent.strip() new_sents.append(sent) return new_sents #删除所有符号,只保留字母、数字和中文 def remove_punctuation(line): #line = str(line) if line.strip()=='': return '' rule = re.compile(u"[^a-zA-Z0-9\u4E00-\u9FA5]") line = rule.sub('',line) return line #中文停用词 def stopwordslist(filepath): stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()] return stopwords #加载停用词 stopwords = stopwordslist("./data/chineseStopWords.txt")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
3、加载数据
定义好这些函数以后,我们就可以加载我们的数据了,我们先加载一篇文章,然后把文章中的所有句子都分离出来(分句)
myfile = "./data/chatbot-data/5G-ch.txt"
text = codecs.open(myfile, "r", "utf-8").read()
sent_tokens = SentsTokenizer4Ch(text)
sent_tokens[:10]
#删除除字母,数字,汉字以外的所有符号
df = pd.DataFrame(sent_tokens, columns=['sent'])
df['clean_set']= df['sent'].apply(remove_punctuation)
#分词,并过滤停用词
# df['cut_sent'] = df['clean_set'].apply(lambda x: " ".join([w for w in list(jb.cut(x)) if w not in stopwords]))
df['cut_sent'] = df['clean_set'].apply(lambda x: " ".join([w for w in list(jb.cut(x))]))
df.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
二、 问答设计
1、问候语设计
当用户和机器人初次见面的时候,我们预先定义一些双方的问候语:
GREETING_INPUTS = ("你好", "hi", "有人", "在吗", "嗨","在不在","有人吗",'在','有人')
GREETING_RESPONSES = ["你好", "我在", "请问,有什么可以帮您的吗?", "你好,我在", "你好,很高兴见到你!"]
def greeting(sentence):
rule = re.compile(u"[^a-zA-Z0-9\u4E00-\u9FA5]")
text = rule.sub('',sentence)
if text in GREETING_INPUTS:
return random.choice(GREETING_RESPONSES)
wordlist = [w for w in jieba.cut(sentence)]
for word in wordlist:
if word in GREETING_INPUTS:
return random.choice(GREETING_RESPONSES)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2、机器应答设计
机器应答是本系统的核心模块,我们要设计一个针对用户问题的应答函数。应答的过程是这样的,当用户提出关于5G网络的问题后,系统会将用户的问题先做格式化处理(如分词,删除标点符号,删除停用词等),然后在现有的数据中通过余弦相似度去匹配一条与用户的问题最相似的句子,并将该句子输出给用户。
def response(user_response): robo_response='' user_response = remove_punctuation(user_response) user_response= " ".join([w for w in list(jb.cut(user_response)) if w not in stopwords]) cut_sent = df.cut_sent.values.tolist() cut_sent.append(user_response) tfidf = TfidfVectorizer() tfidf_vec = tfidf.fit_transform(cut_sent) cos_sim = cosine_similarity(tfidf_vec[-1], tfidf_vec) idx=cos_sim.argsort()[0][-2] flat = cos_sim.flatten() flat.sort() req_tfidf = flat[-2] if(req_tfidf==0): robo_response=robo_response+"对不起,我不理解您的意思,我还是个小白...!" return(robo_response) else: robo_response = robo_response+df.sent.values[idx] return(robo_response)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3、流程设计
好了,万事俱备只欠东风,我们要开始设计一个机器人聊天系统的工作流程,首先机器人应该先自我介绍同时告诉用户退出系统的方法,然后等待用户输入问题,用户输入问题后,我们会在系统中搜索与用户问题最相似的句子,并将该句子返回给用户,然后继续等待用户输入下一个问题。直到用户最后输入“bye”,则退出系统。
flag=True print("机器人: 我的名字叫小白. 我可以回答您关于5G的问题. 如果您想退出, 请输入:bye !") while(flag==True): user_response = input() user_response=user_response.lower() if(user_response!='bye'): if(user_response=='多谢' or user_response=='谢谢' ): flag=False print("机器人: 不用谢!") else: if(greeting(user_response)!=None): print("机器人: "+greeting(user_response)) print() else: print("机器人: ",end="") print(response(user_response)) print() else: flag=False print("小白: 再见! 欢迎再次光临!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
效果
三、打包发布
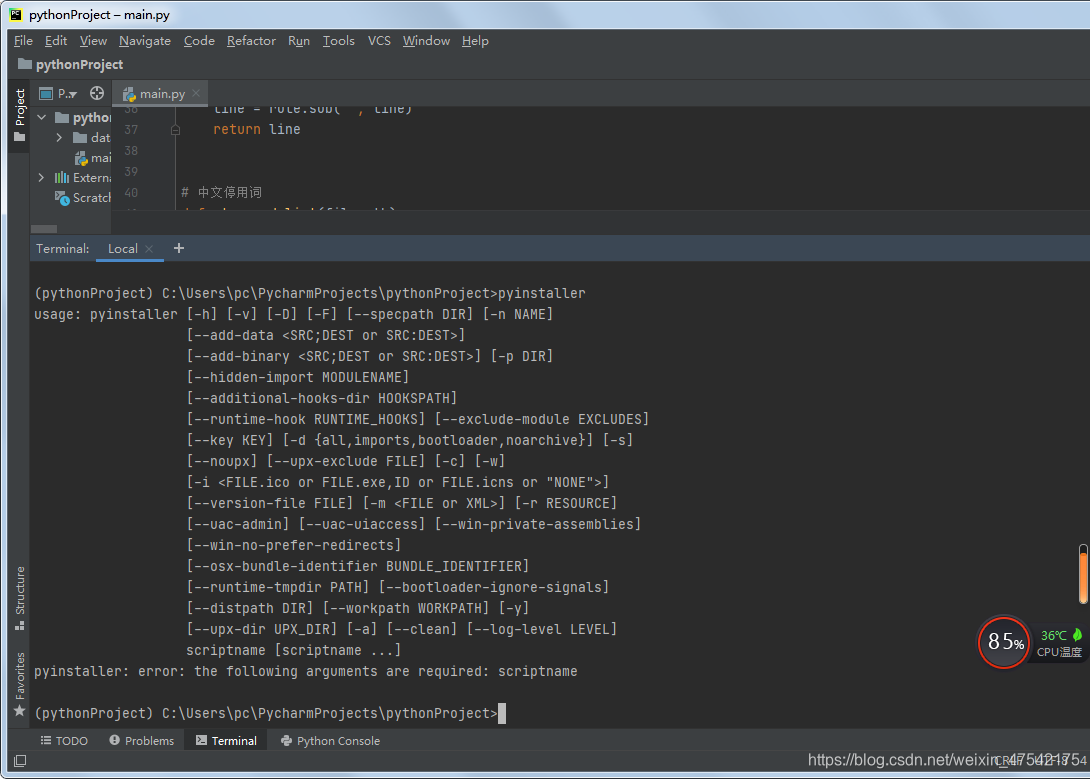
1、安装pyinstaller
点击底部的【Terminal】打开终端,输入命令pip install pyinstaller后回车
2、输入命令 pyinstaller,回车显示安装成功
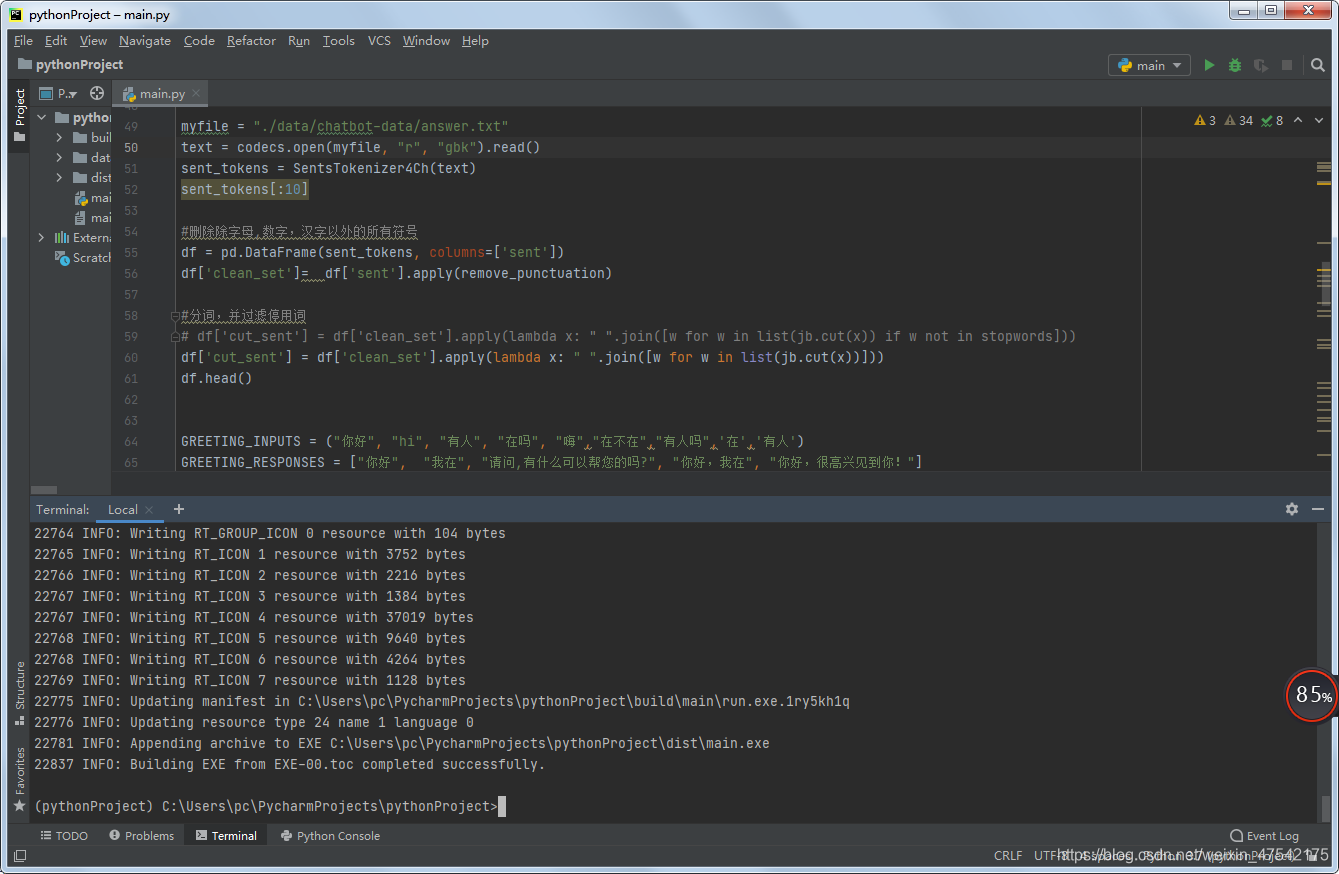
3、输入命令 pyinstaller --console --onefile main.py,
如下图:
打包过程中各种报错及解决办法,请参见:
https://editor.csdn.net/md/?articleId=113173668
4、在工程目录下/dist文件夹中会有打包好的exe文件,如图所示
总结
今天我给大家演示了一个基于检索的简单聊天机器人系统,该系统是基于余弦相似度进行相似语句的匹配。程序中还有很多不完善的地方,有心的读者可以想办法对它进行改进,并希望能分享给我,让我们大家一起进步吧!


