
SQL语句学习(大数据)
赞
踩
一、SQL语句的分类
- SQL: Structured Query Language(结构化查询语言),SQL最早是被美国国家标准局(ANSI)确定为关系型数据库语言的美国标准。后来被国际化标准组织(ISO)采纳为关系型数据库语言的国际标准。
- DDL(Data Definition Language):数据定义语言,用来定义数据库对象(数据库、表、列)创建一个数据库、创建表、添加字段等。
- DML(Data Manipulation Language):数据操作语言,用于定义数据库记录(数据)数据的新增、修改、删除。
- DQL(Data Query Language):数据查询语言,用于查询记录(数据)专门针对数据的查询的。
- TCL(Transaction Control Language):事务控制语言,DCL(Data Control Language):数据控制语言,用于定义访问权限和安全级别控制事务、添加用户、赋予权限、修改密码等。
注:`` 该符号是esc 键下的那个符号 一个表名或者一个字段名添加 `` 可以防止表名和字段名跟关键字冲突,一般创建表的时候都应该写上。 若所建表的表名与关键字相同,则在增删改查的时候也需要加上``。
二、 DDL数据定义语句(Data Definition Language)
注:SQL语句中的关键字都可大写,大写效率高,但为了人看的方便,所以会统一小写。
对数据库的操作
- # 数据库的操作
- # 展示所有的数据库
- show databases;
- # 创建数据库
- create database mydb01;
- # 创建数据库,并采用指定的字符集
- create database mydb02 character set utf8;
- # 查看数据库(了解)
- # 查看创建数据库mydb01定义的信息
- show create database mydb01;
- # 将数据库mydb01的字符集修改为GBK
- alter database mydb01 character set gbk;
- # 删除数据库(一般不能删)
- drop database mydb01;
- # 切换当前使用的数据库
- use mydb01;
- # 查询当前使用的数据库(显示该数据库中的内容)
- select database();
-

- # 表的增删改查操作
- # 展示该数据库中的所有表
- show tables;
- # 创建一个表
- 语法:
- create table 表名( 字段一 数据类型(数据长度),.....);
- 实例:
- create table stu (
- name varchar(255),
- phone varchar(11),
- age int(3)
- );
-
- # 查看表结构:
- desc stu;
- # 查看创建一个表的信息
- show create table stu;
- # 在sql语句中 # 后面的语句不执行,代表注释
- # 修改表已有的名字
- alter table stu rename to student;
-
- # 给一张表添加一个字段
- alter table stu add score double(5,2);
- # 修改一张表的字段类型(int默认11位)
- alter table stu modify score int;
- # 修改一张表的字段名
- alter table stu change name uname varchar(50);
- # 修改一张表的字符集
- alter table stu character set gbk;
- # 修改表添加一个身高字段
- alter table student add height double(5,2);
- # 删除一张表中的某个字段
- alter table stu drop score;
-
- # 表的删除
- drop table stu;
- # 创建一个跟这个表一模一样的表,结构相同
- create table stu2 like stu;
- # 创建一个表,表结构跟另一个表一模一样,并且数据也跟它一模一样,类似于copy 某个表
- create table stu3 as select * from stu;
DDL语句作用:
- 数据库的新增修改删除查看。
- 表的新增修改删除查看
- 表字段的新增修改删除查看(已经涵盖在了表的修改操作中了)
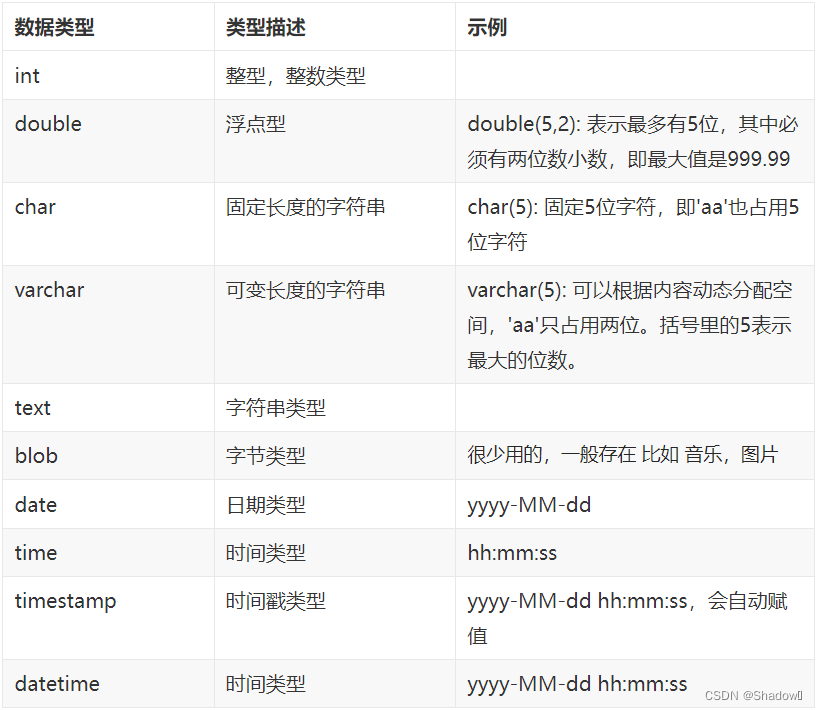
常见的数据类型:
三、DML数据操作语句(Data Manipulation Language)
DML指的是对数据库中的数据进行增、删、改的操作。
INSERT INTO 表名(列名1,列名2 ...)VALUES(列值1,列值2...);注意:列名与列值的类型、个数、顺序要一一对应。
- # 进入需要要进行数据处理的数据库
- mysql> use mydb03;
- Database changed
- # 查看数据库中信息
- mysql> show tables;
- +------------------+
- | Tables_in_mydb03 |
- +------------------+
- | stu |
- +------------------+
- # 查看需要处理表的信息
- mysql> desc stu;
- +--------+--------------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +--------+--------------+------+-----+---------+-------+
- | name | varchar(255) | YES | | NULL | |
- | age | int(11) | YES | | NULL | |
- | height | double(5,2) | YES | | NULL | |
- +--------+--------------+------+-----+---------+-------+
- # 增添数据信息
- mysql> insert into stu(name,age,height) values('zhangsan',22,190.9);
- # insert into 表名 如果表名后面不添加任何的字段名,就是向所有字段插入值。
- mysql> insert into stu values('wangwu',24,175.7);
-
- # 该语句是查询语句,表示查询表stu中所有的数据
- mysql> select * from stu;
-
- # insert into 表名 如果表名后面添加字段名,说明想向这个字段设置值,其他字段默认为空(null)。
- mysql> insert into stu(name) values('zhaoliu');
从stu中,查询数据导入到emp表中。(要求:表stu与emp中有相对应数据类型,emp中多字段亦可以)
- # 从stu中,查询数据导入到emp表中
- insert into emp(sname,sage,sheight) select * from stu;
- # eg:
- mysql> insert into emp(sname,sage,sheight) select * from stu;
- Query OK, 4 rows affected (0.11 sec)
- Records: 4 Duplicates: 0 Warnings: 0
-
- mysql> select * from emp;
- +----------+------+---------+--------+
- | sname | sage | sheight | gender |
- +----------+------+---------+--------+
- | zhangsan | 22 | 191 | NULL |
- | lisi | 23 | 180 | NULL |
- | wangwu | 24 | 175 | NULL |
- | zhaoliu | NULL | NULL | NULL |
- +----------+------+---------+--------+
- 4 rows in set (0.07 sec)
select 语句查询出来的数量以及字段类型和顺序都必须 和 insert into 中表的字段数量、类型、顺序一样,跟表名字、表字段的名字没有半毛钱关系。
对比:
这个语句执行的时候必须有表
insert into 表名 select * from 表2
这个语句执行的时候可以没有表,sql语句帮创建表
create table 表名 as select * from 表2
删除数据:
- # 删除数据
- delete from stu;
- # 删除掉表中所有的数据
- truncate table stue;
-
- # DELETE 和 TRUNCATE区别
- # delete删除表中的数据,表结构还在;删除的数据可以恢复。
- # truncate是直接将表DROP掉,然后再按照原来的结构重新创建一张表。数据不可恢复。
- # truncate删除效率比delete高。
-
- delete from stu where name='zhaoliu';
- # where 后面可以添加条件,满足条件的删除掉
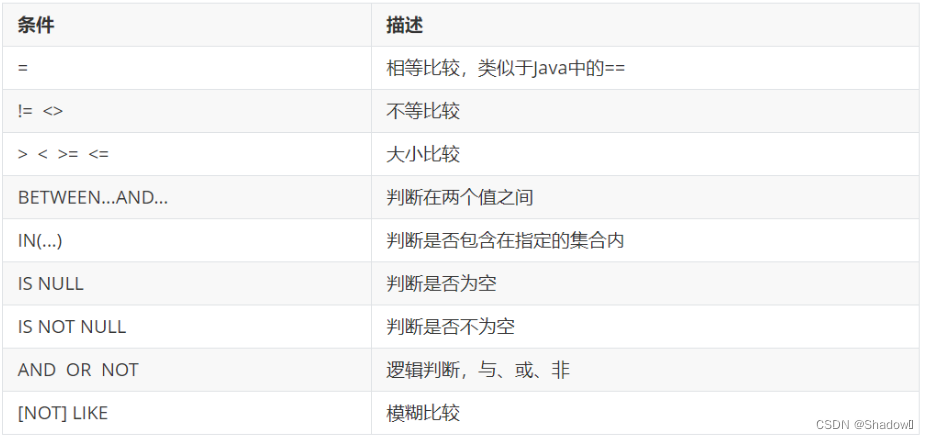
where条件:
修改数据:
考虑语法:
UPDATE 表名 SET 列名1=列值1,列名2=列值2 。。。 WHERE 列名=值
- # eg:只要这个同学姓张,就加10分
- # score = 10 是将 score 的数据重置为 10
- update student set score = 10 where name like '张%';
- # 修改为
- update student set score = score + 10 where name like '张%';
-
- # 将姓名为’lisi’的员工薪水修改为4000元,job改为ccc。
- update emp set salary=4000,job='ccc' where name=';isi';
-
四、DQL:数据查询语句(Data Query Language)
语法:select ... from ...;
select [distinct] ... from ... where ...group by ... having ...order by ... limit ...;
# 注:特别是大数据查询的时候一定记得不要select * from 表 ;要么加条件,要么加limit
什么地方可以使用别名,什么地方不可以?
结论:
- mysql中 group by order by having 后面可以使用别名,where后面不能使用别名
- Oracle中 order by 可以使用别名,group by having where 中不能使用别名。
注: 这里使用别名是来简化sql语句的书写。
基础查询
- # 基础查寻
- # 查询所有列
- select * from stu;
- # 查询指定列
- select sname,age from stu;
-
- # 条件查询
- # 查询性别为女,并且年龄小于50的记录
- select * from stu where gender = 'female' and age <50;
- # 查询学号为S_1001,或者姓名为liSi的记录
- select * from stu where sid = 'S_1001' or sname = 'liSi';
- # 查询学号为S_1001,S_1002,S_1003的记录
- select * from stu where sid in ('S_1001','S_1002','S_1003');
- # 查询学号不为S_1001,S_1002,S_1003的记录
- select * from stu where sid not in ('S_1001','S_1002','S_1003');
-
- # 按照模糊的条件进行查询,可以使用like条件,或者regexp。
- # % : 代表0个或者多个字符
- # _ : 代表任意一个字符
- # 查询所有的姓名以s开头的学生
- select * from stu where sname like 's%';
- # 查询所有的姓名以s开头的,且长度为5的学生
- select * from stu where sname like 's____';
字段控制
- # (distinct) 字段可以去重相同的就展示一次
- # emp中工资都有哪些挡位
- select distinct sal from emp;
-
- # 列之间的计算
- # 计算每一个员工的薪水 (工资 + 绩效)
- select ename,sal + ifnull(comm,0) from emp;
- ifnull 是一个函数,函数就是工具,会用即可。
- # eg:select database();不同函数有不同函数的用法,见一个记住一个,多多益善!
-
- # 给列名添加别名(加不加''都可以)
- select ename 姓名, sal + ifnull(comm,0) 薪水 from emp;
- select ename '姓名', sal + ifnull(comm,0) '薪水' from emp;
-
- # 列的排序
- 查询所有学生记录,按年龄升序排序
- select * from stu order by age asc;
- select * from stu order by age ;
- # 两个查询结果一样,说明order by 默认按照升序排序,asc可写可不写。
- # 查询所有学生记录,按年龄降序排序
- select * from stu order by age desc;
- # desc: desc 表名 --> 查看表结构
- # order by 字段名 desc --> 按照该字段降序排序
- # 查询所有雇员,按月薪降序排序,如果月薪相同时,按编号升序排序
- select * from emp order by sal desc, empno asc;
-
- # order by 字段1 ,字段2 字段二有可能用不上。
- # order by 字段1 字段1是排序的主要字段,只有该字段相同的时候,才会用到第二个字段,假如没有第二个字段。
-
- # 聚合函数
- # max(): 计算指定列数据的最大值
- # min(): 计算指定列数据的最小值
- # count(): 计算指定列不为NULL的数据的数量
- # sum(): 计算指定列的数值的和,如果计算的列的类型不是数值类型,计算结果为0
- # avg(): 计算指定列的数值的平均值,如果计算的列的类型不是数值类型,计算的结果为0
-
- select max(sal) from emp;
- select min(sal) from emp;
- # 月薪是1250的员工有多少人
- select count(*) from emp where sal = 1250;
- # 统计员工人数
- select count(*) from emp;
- select count(empno) from emp;
- # count(字段) 如果该字段为null ,不累加(sum函数相同)
- # eg:select count(comm) from emp;
- select count(1) from emp;
- # 建议使用count(*) 因为这个是标准写法, count(*) 和 count(1) 效率一样
- # count(字段) 会慢一些,原因是要判断该字段是否为null 。
- # 求平均工资
- select avg(sal) from emp;
- select sum(sal) / count(*) from emp;
-
- # 分组查询
- # stu 按照性别分组
- select gender from stu group by gender;
- # 分组查询中,select 和 from 之间写分组字段,也可以写聚合函数放在分组字段后面,其他字段不要写
- # 按照性别分组,并且告知每个性别的人数
- select gender,count(*) from stu group by gender;
- # 注:只要是分组查询select 和 from 之间只能是分组字段或者聚合函数,其他写什么都是错!!!
- # 查询每一个部门的编号以及这个部门的最高工资(sal)
- select deptno,max(sal) from emp group by deptno;
- # 查询每一个工作的名字以及这个工作的人数
- select job,count(*) from emp group by job;
- # 查询每一个部门、每一个工作的人数
- select deptno,job,count(*) from emp group by deptno,job;
- # 注:这里count()放在job后面自然就是作用于job这个字段
- # 查询平均工资高于3000的部门编号及平均工资
- select deptno,avg(sal) from emp group by deptno having avg(sal) > 3000;
-
- # having 的用法:必须和group by 一起使用,作用是分组完之后的数据,进行条件过滤!!!
- # where 的用法:条件过滤,每一条数据按照条件进行过滤,跟分组没关系当然过滤完之后还可以进行分组查询。
-
- # 注:1. having需要写在group by之后,where需要写在group by之前。
- # 2. having之后可以使用聚合函数,where不可以使用聚合函数。
-
- # 分页查询
- # 求工资最高的前5个人
- select * from emp order by sal desc limit 5;
- # 查询表的前5条数据
- select * from emp limit 5;
- # 0 指的是起点,5 指的是条数
- select * from emp limit 0,5;
-
- # 注:特别是大数据查询的时候一定记得不要select * from 表 ;要么加条件,要么加limit
SQL的书写顺序
select ... from 表名 where ... group by ... having ... order by ... limit ....;
SQL的执行顺序
from... where... group by ... having... select... order by... limit...;
- 一、导入依赖
org.apache.poi [详细] 赞
踩

