
- 1Android 之一 Android Studio 安装、配置等新手入门 + 百度地图定位 + 移动摇杆 的实现_ndk was located by using ndk.dir property. this me
- 2UI 自动化测试框架:PO 模式+数据驱动 【详解版】_po框架
- 3UTAustin最新提出!无相机姿态40秒重建3DGS方法_无需相机参数三维重建
- 4【小程序开发必备】微信小程序常用API全介绍,附示例代码和使用场景_微信小程序代码大全
- 5Mac OS X 10.10 Yosemite 关闭Dashboard和Spotlight_spotlightv100能删除吗
- 6Pycharm报错torch.cuda.OutOfMemoryError: CUDA out of memory.
- 7Drools基础篇-01-规则引擎简单介绍_drools规则引擎
- 8华为云注册登录之图像标签识别_华为云aksk登录
- 9DDoS攻击原理是什么?DDoS攻击原理及防护措施介绍_ddos 不挂科
- 10自动化测试(UI)----PO设计模式_自动化测试模式
2024年MathorCup数模竞赛C题超详细解题思路_mathercup数学建模c题
赞
踩
妈妈杯本次比赛报名队伍号高达12500,这也就意味着大概一万只队伍参加报名,仅仅在报名人数这一项,妈妈杯已经成为美赛国赛之后的第三大竞赛。C题作为本次竞赛最简单也最容易获奖的题目,本文将给大家带来手把手超详细解题思路。
注释:最容易获奖是因为,数模竞赛获奖是按着百分比获奖的,并分指定ABCD每一道题目只有400队能获得国奖,而是每道题目选择的50%都可以获奖;选择人数少,一是题目难,二是选择的人都是数学建模的变态。如果选择这种题目,我们需要打败50%的数模老手以及数模变态才可以获奖。
反之,选择选题人数最多的。选择人主要是萌新、小白,都是不太懂数模的。我们只需要淘汰50%的小白即可,加上我们的资料可以保证大家一定可以获奖。
首先,正式解题之前我们需要做数据预处理。数据预处理是所有数据类数模竞赛所必须的步骤,百分制的评审大概可以占到10-15分的分值。对于该题目主要的数据预处理工作在于异常值的判定。例如,对于附件一存在很大的值10万+,也存在很小的数据。对于这种的边缘值我们需要使用一些方式进行判定。比较合理高大上的方式就是首先判定数据分布方式,对于正态分布数据使用3西格玛原则判定异常值,对于非正态分布数据使用箱型图判定异常值。

处理完之后,我们就发现极端数据11000是由于双十一,因此对于判定的异常值,我们需要结合实际情况在进行后续处理。
问题一,建立货量预测模型,对57 个分拣中心未来 30 天每天及每小时的货量进行预测,将预测结果写入结果表1和表2中。
问题一本质就是预测模型,需要对两个主体进行预测,分别是日货量预测模型、小时货量预测模型。对于预测模型,在数学建模没有对错之分,因此可以随意地选择模型。但是预测结果精度越好的模型,得分也会稍微的高一些。这里给大家一些建议:
对于日货量预测模型,我们需要对每一个地区的货量分别进行一个月的预测,选择合适的时间序列预测模型,例如SARIMA(季节性自回归综合移动平均模型),ARIMA、prohet或使用机器学习模型如随机森林、XGBoost。其中,想拿国一可以适当的了解一下prohet(去年国赛指定答案模型,两万七千只队伍仅有一个做出来了)
对于小时货量预测模型,这里有两种思路。其一,将24小时作为一个周期,直接建立时间序列预测,用三万个数据进行预测即可。其二,将每一个地区每天同一时间的数据单独拿出来,一共30组。对这三十组进行预测。这样预测数据量减小,但是还需要进行30步预测,可能预测精度存在一定问题。
对于模型的选择,大家可以根据自己队伍的实力进行选择即可。想要单纯的追求模型复杂度,可以考虑我之前保奖课讲过的加权平均预测,使用多种预测模型,进行加权。以误差最小为目标函数,权重和为1为约束条件,将多种预测模型进行加权起来。类似于下面这种方式。


问题二,过去 90 天各分拣中心之问的各运输线路平均货量如附件3所示。若未来 30 天分拣中心之问的运输线路发生了变化,具体如附件4所示。根据附件 1-4,请对57个分拣中心未来 30 天每天及每小时的货量进行预测,并将预测结果写入结果表3和表4中。
其本质还是预测模型,与问题一相对来讲。问题一是y和t进行建模,问题二就是引入几个x,建立 y和x,t的预测模型。即引入一些新的指标。因此,我们需要基于附件三四的数据引入指标进行预测即可。预测模型的选择可以选择与问题一相同,这样可以保证论文模型的整体性;也可以换一个新的模型,这样可以增加模型的复杂度,但是整体性会下降。
另类思路:
选择新指标为运输线路货量变动【计算每个运输线路在未来的变化情况,这可能包括新的线路增加或现有线路的变化。】,历史货量信息【使用附件3提供的历史平均货量来预估新线路或变更线路的货量影响】
数据整合:整合附件3的货量数据和附件4的线路变化数据。对于新出现的线路,如果没有历史数据,可能需要估计其货量或使用类似线路的平均货量作为预估。
特征构建:将运输线路作为特征加入模型,每个线路可以是一个特征,其值为货量或变化量。
| 路线:由始发分拣中心和到达分拣中心组成的标识。 |
| 货量:该线路的历史平均货量,对于无历史记录的线路为0。 |
| 接下来,我们可以创建以下特征: |
| 是否新线路:如果货量为0,则认为这是新线路。 |
| 历史货量:已有的货量数据,将直接用作预测模型的输入。 |
预测模型更新:根据整合后的数据集更新货量预测模型,可能需要使用多元回归、随机森林或神经网络等方法。使用这些特征,我们可以准备适合于预测的数据集,并选择适合的预测模型,例如随机森林、XGBoost或神经网络等。为了进一步处理,我们需要确定数据的最终形式,并考虑如何将这些数据输入到模型中。具体结果如下所示

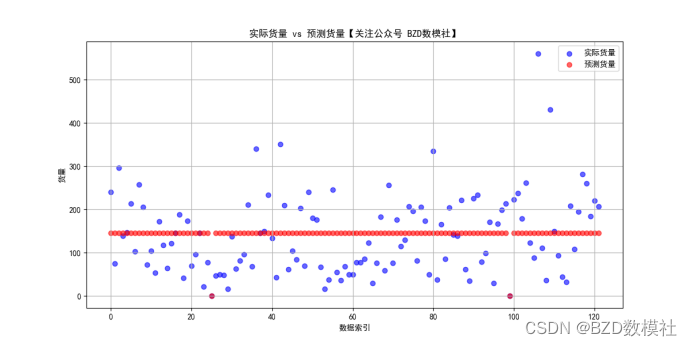
利用该结果进行,对问题一预测结果进行等比放缩即可。
- import tensorflow as tf
- from tensorflow.keras.models import Sequential
- from tensorflow.keras.layers import Dense
- from tensorflow.keras.optimizers import Adam
- from sklearn.preprocessing import StandardScaler
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import mean_squared_error
- import matplotlib.pyplot as plt
- import pandas as pd
- import xgboost as xgb
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import mean_squared_error
- import matplotlib.pyplot as plt
-
- # 加载数据
- attachment3 = pd.read_csv('附件3.csv', encoding='GBK')
- attachment4 = pd.read_csv('附件4.csv', encoding='GBK')
-
- # 创建路线列便于合并
- attachment3['路线'] = attachment3['始发分拣中心'] + '-' + attachment3['到达分拣中心']
- attachment4['路线'] = attachment4['始发分拣中心'] + '-' + attachment4['到达分拣中心']
-
- # 合并数据,附件4为基础进行左连接
- merged_data = attachment4.merge(attachment3[['路线', '货量']], on='路线', how='left')
- merged_data['货量'].fillna(0, inplace=True) # 填充未知货量为0
-
- # 特征构建
- X = merged_data.drop(columns=['始发分拣中心', '到达分拣中心', '路线', '货量'])
- X['是否新线路'] = (merged_data['货量'] == 0).astype(int)
- y = merged_data['货量']
- # 实例化一个 StandardScaler 对象
- scaler = StandardScaler()
-
- # 使用 StandardScaler 对特征数据 X 进行标准化处理
- X_scaled = scaler.fit_transform(X) # 确保 X 已经定义并包含了您希望模型学习的特征
-
- # 使用 train_test_split 将数据分割为训练集和测试集
- X_train_scaled, X_test_scaled, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
-
- # 构建神经网络模型
- model = Sequential([
- Dense(64, activation='relu', input_shape=(X_train_scaled.shape[1],)),
- Dense(64, activation='relu'),
- Dense(1)
- ])
-
- # 编译模型
- model.compile(optimizer=Adam(learning_rate=0.01), loss='mean_squared_error')
-
- # 增加模型的复杂度
- model = Sequential([
- Dense(128, activation='relu', input_shape=(X_train_scaled.shape[1],)),
- Dense(128, activation='relu'),
- Dense(64, activation='relu'),
- Dense(1)
- ])
-
- # 添加Dropout和正则化
- from tensorflow.keras.layers import Dropout
- from tensorflow.keras.regularizers import l2
-
- model = Sequential([
- Dense(128, activation='relu', input_shape=(X_train_scaled.shape[1],), kernel_regularizer=l2(0.001)),
- Dropout(0.5),
- Dense(128, activation='relu', kernel_regularizer=l2(0.001)),
- Dropout(0.5),
- Dense(64, activation='relu', kernel_regularizer=l2(0.001)),
- Dense(1)
- ])
-
- # 使用更慢的学习率和不同的优化器
- optimizer = Adam(learning_rate=0.001)
- model.compile(optimizer=optimizer, loss='mean_squared_error')
-
- # 训练模型
- history = model.fit(X_train_scaled, y_train, validation_split=0.2, epochs=100, verbose=1)
-
-
- # 预测并计算RMSE
- y_pred_nn = model.predict(X_test_scaled).flatten()
- rmse_nn = mean_squared_error(y_test, y_pred_nn, squared=False)
- print("Neural Network RMSE:", rmse_nn)
-
- # 对整个数据集进行预测
- y_full_pred_nn = model.predict(X_scaled).flatten()
-
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用SimHei字体
- plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
- # 可视化实际与预测货量
- plt.figure(figsize=(12, 6))
- plt.scatter(merged_data.index, merged_data['货量'], color='blue', label='实际货量', alpha=0.6)
- plt.scatter(merged_data.index, y_full_pred_nn, color='red', label='预测货量 (NN)', alpha=0.6)
- plt.title('实际货量 vs 预测货量 (神经网络)')
- plt.xlabel('数据索引')
- plt.ylabel('货量')
- plt.legend()
- plt.grid(True)
- plt.show()
-
- # ...(前面的代码不变,包括数据准备、模型构建、训练和预测)
-
- # 将预测结果添加到原始的DataFrame中
- merged_data['预测货量_NN'] = model.predict(X_scaled).flatten()
-
- # 输出预测结果到CSV文件
- output_filename = '预测结果.csv'
- merged_data.to_csv(output_filename, index=False)
-
- print(f"预测结果已保存到文件: {output_filename}")

问题三、假设每个分拣中心有60名正式工,在人员安排时将优先使用正式工,若需额外人员将使用临时工。请基于问题2的预测结果建立模型,给出未来 30 天每个分拣中心每个班次的出勤人数,并写入结果表5中。要求在每天的货量处理完成的基础上,安排的人天数(例如30天每天出200名员工,则总人天数为 6000)尽可能少,且每天的实际小时人效尽量均衡。
优化模型,极值问题的求解。根据问题二的结果设置目标函数、决策变量、约束条件即可。优化模型问什么设什么因此直接可以设置目标函数:最小化总人天数Z ,
决策变量:
xij:第 i 天第 j 个班次的正式工人数。
yij:第 i 天第 j 个班次的临时工人数
总人天数Z=∑∑(xij+yij)
约束条件 每班次的总分拣量不能少于预测货量
正式工使用不超过60人
人员非负性约束
正式工每天最多出勤一个班次
对于这些约束条件,我们需要设置一些变量进行表述
参数:
P:正式工的最高小时人效(25包裹/小时)。
T:临时工的最高小时人效(20包裹/小时)。
Ci:第 i 天每个分拣中心的预测货量。
N:每个分拣中心的正式工人数(60名)。
每班次的总分拣量不能少于预测货量。
Pxij+yijT≥6Ci∀i,j
正式工使用不超过60人。
xi,j≤60∀i,j
人员非负性约束。
∀,xi,j≥0,yi,j≥0∀i,j
正式工每天最多出勤一个班次。
∑xi,j,k≤1∀i,k
问题4:研究特定分拣中心的排班问题,这里不妨以SC60为例,假设分拆中心 SC60 当前有 200名正式工,请基于问题2的预测结果建立模型,确定未来 30 天每名正式工及临时工的班次出勤计划,即给出未来 30 天每天六个班次中,每名正式工将在哪些班次出勤,每个班次需要雇佣多少临时工,并写入结果表6中。每名正式工的出勤率(出的天数除以总天数30)不能高于 85%,且连续出勤天数不能超过7天。要求在每天货量处理完成的基础上,安排的人天数尽可能少,每天的实际小时人效尽量均衡且正式工出勤率尽量均衡。
对于问题四,与问题三相同需要进入一些新的约束条件。主要在于出勤率尽量均衡,两种考虑方式 其一可以引入平衡因子,将其作为目标函数的一项目标函数:最小化总人天数,并尽量平衡正式工的出勤率。
Minimize1∑yi,j+λ×StdDev(Attendance Rate)
其中,λ 是平衡因子,StdDev是出勤率的标准差。
这种方式λ 不好确定,也可以采用将出勤率尽量均衡试做是一个约束条件,我们可以设置出勤率的标准差在一定区间内
参数:
P:正式工的最高小时人效(25包裹/小时)。
T:临时工的最高小时人效(20包裹/小时)。
Ci:第 i 天SC60的预测货量。
N:SC60的正式工人数(200名)。
决策变量:
xi,j,k:第 i 天第 j 个班次是否有第 k 名正式工出勤(二元变量,0或1)。
yi,j:第 i 天第 j 个班次需要雇佣的临时工人数。
约束条件:
每班次的总分拣量不少于预测货量。
∑xi,j,k×P+yi,j×T≥6Ci∀i,j
正式工每天最多出勤一个班次。
∑xi,j,k≤1∀i,k
正式工的出勤率不能超过85%。
∑∑xi,j,k≤25.5∀k
正式工连续出勤天数不超过7天。
人员非负性约束。
yi,j≥0∀i,j
正式工出勤率尽量均衡
StdDev(Attendance Rate)

