
- 1Lightroom Classic 2024 v13.0.1(照片后期制作)_lightroom 2024
- 2Kafka之安装本地windows环境_kafka本地安装
- 3大模型日报2024-04-23
- 4element中 el-tabs 去掉底部的下划线和切换时的下划线_el-tab 下划线去点
- 5数据结构(三)------栈
- 6Windows(Win10、Win11)本地部署开源大模型保姆级教程_win本地模型部署
- 7Java简单快速入门JWT(token生成与验证)_java jwt
- 8使用EasyPoi实现Excel文件导入_easypoi 导入
- 9uniapptabbar的高度是多少_uni-app之tabBar的自己配置
- 10vue科大讯飞文字转语音
使用秘籍|如何实现图数据库 NebulaGraph 的高效建模、快速导入、性能优化_nebula graph 图探索开发
赞
踩
本文整理自 NebulaGraph PD 方扬在「NebulaGraph x KubeBlocks」meetup 上的演讲,主要包括以下内容:
- NebulaGraph 3.x 发展历程
- NebulaGraph 最佳实践
- 建模篇
- 导入篇
- 查询篇
NebulaGraph 3.x 的发展历程
NebulaGraph 自 2019 年 5 月开源发布第一个 alpha 版本以来,陆陆续续发布了 2.0 GA,到现在 v3.6.0,已经是 v3.x 版本中比较后期的版本了。从 3.x 开始,基本上保持了三个月(一个季度)发一个 y 版本的节奏,从 v3.1 到 v3.2,到现在的 v3.6。(演讲时 v3.6 尚未发布,所以没有相关内容展示)
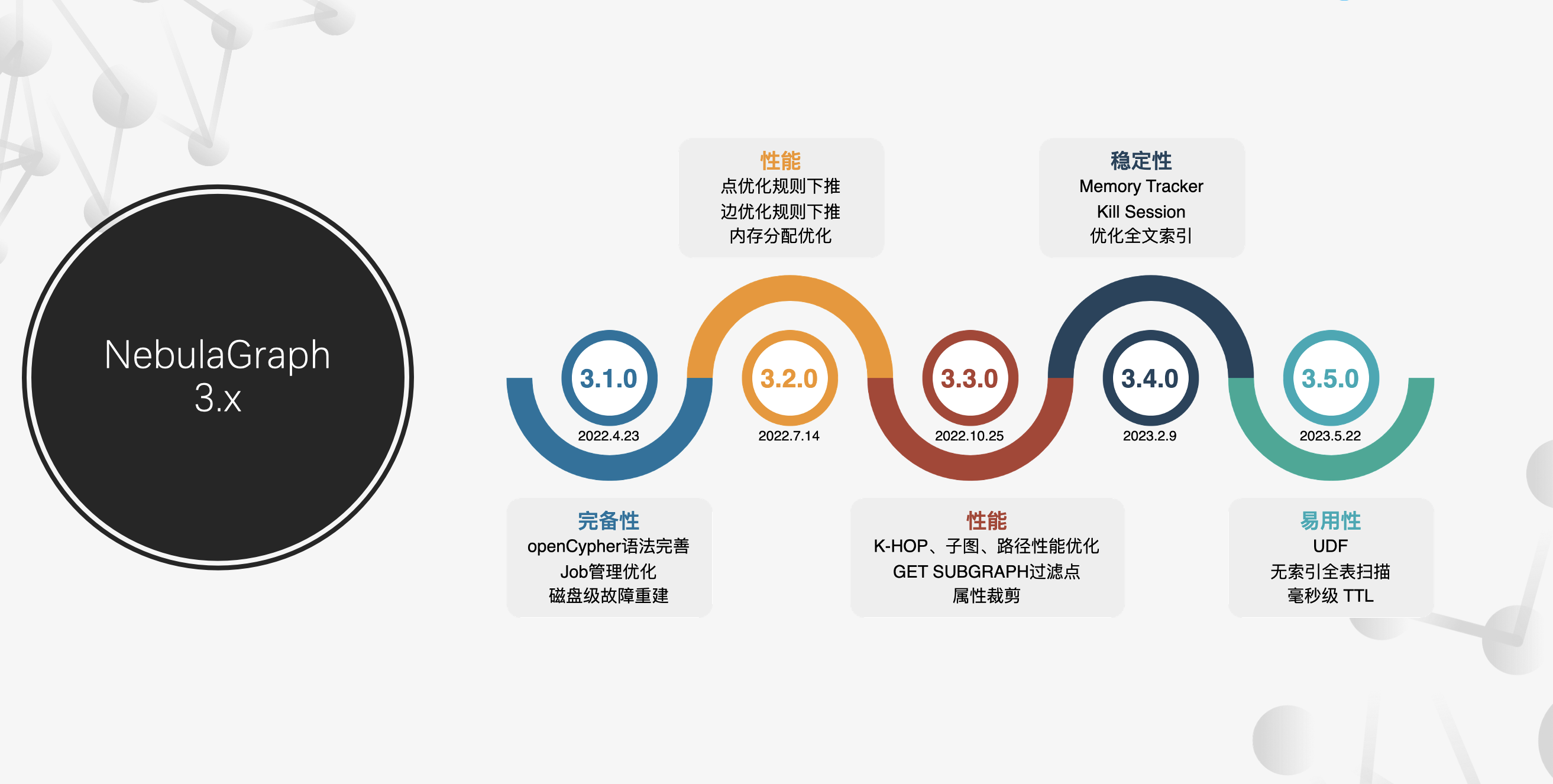
而这几个版本主要是在完备性、性能,稳定性以及易用性上的优化。从 NebulaGraph 作为一款图数据库的产品定位上来说,核心应用场景是 TP 场景,而对 TP 型数据库产品来说,有几个特性是非常重要的:
- 稳定:数据库作为底层的基础设施,许多业务是基于数据库运行的,是在线的系统,因此稳定性是一个非常重要的特性。在 NebulaGraph v3.4 版本,包括最新版本的 v3.6 版本中,系统的稳定性得到了非常大的提升和改善;
- 性能:因为 NebulaGraph 定位是一个 TP 的数据库产品,因此性能,包括高吞吐量是至关重要的;
- 易用:一个好的产品要如何让用户更好地用起来,降低用户的学习成本,也是需要考虑到的;
针对这些特性,我们在 v3.x 这 5 个版本中做了这些尝试:
稳定性
在 v3.x 开始,NebulaGraph 引入 fuzzer,极大提升测试效率。fuzzer 可基于 nGQL(NebulaGraph 的查询语言)的语法进行灵活组合,生成人为不能拟定的查询语句,由此让测试更加完善,从而提高了稳定性。
此外,版本新特性部分还新增 Memory Tracker。图数据库不同于其他数据库,数据一直处于持续地遍历、迭代中,因为即便是数据量不大的情况下,数据的迭代会导致它的结果异常大,这就造成了内存的管理压力。在 v3.4 版本中,NebulaGraph 引入了 Memory Tracker 机制,从论坛的用户反馈上,可以看得出来相关的 OOM 问题大幅度减少了。这里可以阅读下《内存管理实践之 Memory Tracker》;
性能提升
图的经典查询一般包括 K 跳(K-hop)、子图和路径查询。K 跳就是从一个点出发,比如说从我出发,去找寻我好友(一跳)的好友(两跳),这种查询,可能社交或者反欺诈的场景中使用会比较多。此外,就是子图,比如说我现在从一个点出发,找到他的周围的关联的一群人,以及这一群人关联的另外一群人,这时候就可能会用到子图的功能。还有就是路径查询,像是企业和企业之间的关联关系之类的,就比较适合用路径,来找寻二者的关联。在 v3.x 中,这几个图的经典查询性能都有大幅度的提升的,具体大家可以看论坛的性能报告:自测和他测报告合集;
上面提到过内存管理的难点,除了 Memory Tracker 机制之外,属性裁剪能提升内存的利用率,在 NebulaGraph 中如果查询不需要用到某个属性,就会将其裁剪掉,从而提升内存利用率。
易用性
NebulaGraph 在 v2.x 开始支持 openCypher,一开始是比较基础的 openCypher 语法;在 v3.x 开始,NebulaGrpah 做了一个语法完善,像是 OPTIONAL MATCH、多 MATCH 等语法支持,全面覆盖了国际图基准测试之一的 LDBC-SNB 支持的图查询。
此外,在 v3.5 开始支持了 UDF 功能,这个功能是由社区用户 zhaojunnan 提供支持的,它可以用来帮助实现一些内核暂时不支持的功能。这里就不详细展开 UDF 的说明了,具体大家可以看《NebulaGraph UDF 功能的设计与背后的思考》;
最后一点是全文索引优化,这个在后面章节会详细讲述。
NebulaGraph 的最佳实践
在这个部分主要分为:建模、数据导入、查询等三大内容。
数据建模
数据膨胀
这是社区用户在交流群里反馈的一个问题:
- 数据导入之后占用硬盘空间极大,60 MB 的文件导入之后,Storage 占用了 3.5 G;
- Storage 服务占用内存很高

- 并发量大的时候,会出现 ConnectionPool 不够的情况;
- 3 跳查询本来就很慢么?我看官方的 Benchmark 数据规模大的时候会慢,但是当前我们数据量也不是很大;
目前的数据情况:点 594,952,边 798,826。同时,边和点均建了 1 个索引:
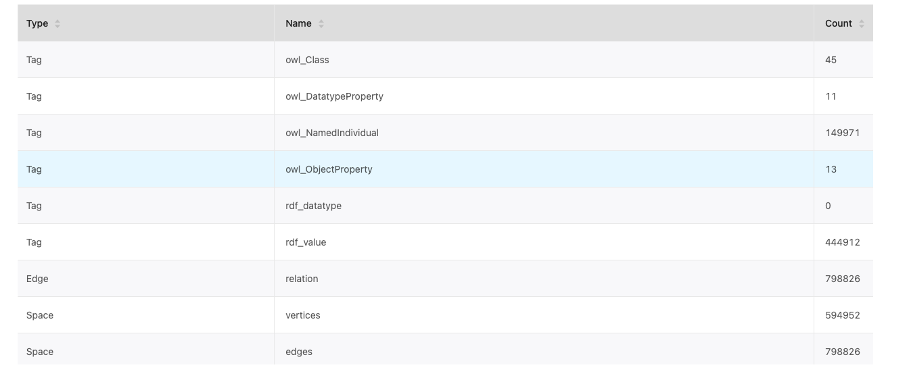
所以它有什么问题呢?

在图数据库 NebulaGraph 中,有个概念叫做 Space,Space里有一个概念是 VID type,VID 是 NebulaGraph 中非常关键、重要的概念,所有的数据字段都是通过 VID 来进行唯一索引,类似主键的概念。比如上图的中间部分:点结构和边结构,可以看到结构中都有 VID,用来进行字段查询;边结构还分起点 srcId 和终点 dstId,就是上图的两处 VertexID。
如上图所示,这个 Space 中配置的 VID 类型是 String,而 NebulaGraph 支持的 VID 类型有两种:一种是 INT,数值类型,像手机号之类的可以用 INT 来存储;一种是 String,比如说人名之类的,当然你要用 String 来存储像是身份证号之类的数值信息也可以。但是,用 VID 的查询效率从经验看是 INT 类型是远高于用 String 作为 VID 类型的。
回到上面的这个例子,一开始用户创建 VID 时,直接选取了 FIXED_STRING 类型,设定为了 256 位的定长 String。但是这里会导致一个问题:
- 594,952(点数)*256 (VID 大小)* (1 + 1) + 798,826(边数)* 256(VID 大小) * (2 + 2 + 2 + 2) = 1.80 GB
上面的例子是数据存储的大小计算过程,点的数量乘以定长的长度(这里是 256),再乘以占据的字节大小,以及边的数量乘以对应 VID 的长度,再乘以对应边 VID 占据的空间大小,算出来是 1.8 GB。由此,我们可以想到一个事情:是不是可以精简下 VID 的定长长度,设置一个合理的数值,比如说是 32,那它空间占据量就是:
- 594,952(点数)*32(VID 大小)* (1 + 1) + 798,826(边数)* 32(VID 大小)* (2 + 2 + 2 + 2) = 0.23 GB
修改 VID 的定长长度之后,整个空间使用量就是之前的 1/8,还是非常可观的一个磁盘容量优化。如果是更多的点和边数据量的话,缩减的磁盘空间会更客观。由此,我们有个建议:VID 的定长长度尽可能短,同理,属性类型设置亦如是。
超级节点

图数据库实践中,超级节点是一个比较常遇到的性能问题。那么,什么是超级节点(稠密点)呢?图论给出的解释是:一个点有着超级多的相邻边,相邻边就是出边(从这个点指向另外一个点)或者是入边(某个点指向这个点)。像是社交网络中 KOL、网红大V 之类的人,或是证券市场的热门股票,交通网络中的枢纽站、银行系统中的四大行、互联网中的高流量站点,或者是电商平台的爆款商品,等等都是整个关系网络中的超级节点。一旦查询中有超级节点,查询速率就会变得异常的缓慢,甚至有时候内存都耗尽了,查询结果还没跑出来。
下面就来讲讲,现阶段你要用 NebulaGraph 可以如何解决或是绕开超级节点:

要在建模环节规避掉超级节点的问题,“拆点”是可行的方式之一。如上图左侧所示,在未优化建模之前,A 通过 transfer 边关系连接到 B1、B2,如果 A 频繁的转账,势必会导致它成为一个超级节点。这时候,你可以将 A 拆分成 A1 和 A2,按照某种约定的方式,比如说转账的日期,或者是由单一客户拆分成对公客户、对私客户,从而达到拆点、避开超级节点形成的目的。不过,这里会涉及到一个 VID 变更的问题,将 A 拆分成 A1 和 A2,会导致对应的 VID 发生变化,当然你可以命名 A1 为 A0721,A2 为 A0722,加上日期数字来标识它们。
相对应拆点,还有拆/合边的方式。在两个点之间,有许多同一类型的边,比如说转账关系,这时候,可以根据业务的逻辑来进行判断,比如取最短边、最新边、最大边、最小边等,在一些不需要明细的场景里,只体现关系出来,这样就能提升查询效率。除了合并之外,拆边也是一种方式,如上图右侧所示,两个点之前有非常多的关系,它们都是交易类型,可能有一部分是发红包,有一部分是转账,这时候,你就可以按照拆点的逻辑,将边进行拆解。
此外,还有截断,NebulaGraph 有个配置参数是 max_edge_returned_per_vertex,用来应对多邻边的超级节点问题。比如我现在 max_edge_returned_per_vertex 设置成 1,000,那系统从点 A 出发,遍历 1,000 个点之后就不再遍历了,便将结果返回给系统。这里会存在一个问题,加入 A 和 B1 之间存在 1 千多条边,A 和 B2 存在 3 条边,按照这种遍历 1,000 条边之后就不再遍历的设定,可能返回结果中 A 和 B2 的关系边就不会返回了,因为这个遍历返回是随机的。
其他的话,同相关的社区用户交流,我发现在许多业务场景中,超级节点并没有太大的实际业务价值。这里就要提下“超级节点的检测”,比如:通过度中心性算法(DegreeCentrality)计算出出入度大小,这个图算法 nebula-algorithm 和 nebula-analytics 都支持。当这个算法跑完之后,得到的二维表就能告诉你哪些是超级节点,提早让用户知道哪些点会影响查询效率。
此外,假如现在你有一个已知的超级节点,且不方便处理,那查询的时候就要尽量避免逆向查询,即从这个超级节点出发,查询其他节点。
数据导入
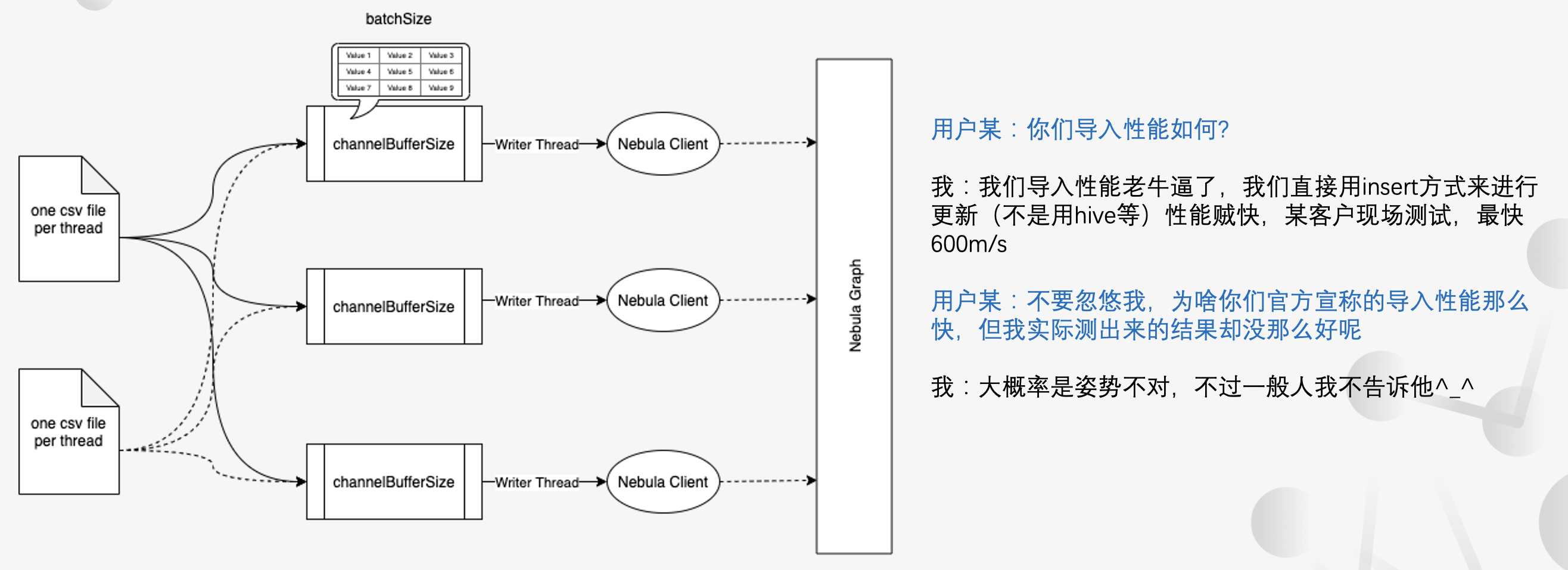
社区用户经常遇到的还有一类问题:数据导入慢的问题。一般新的社区用户都会问:你们的导入性能如何?这时候我们一般会说:导入性能老牛逼了,而且我们是直接用 INSERT 方式导入的,速度贼快,之前遇到最快的是 600MB/s。
这时候用户一般会反问:为什么我测试出来,导入速度没有官方说的那么快。

这里就展开说说如何提升你的数据导入性能。
熟悉 NebulaGraph 的小伙伴都知道,它的底层存储是基于 RocksDB 实现的,而 RocksDB 有 wal_ttl 这么一个配置项,如果你的导入数据量非常大,对应的 wal 日志也会相对应的变大。因此,建议在进行数据导入时,将 wal_ttl 时间设短一点,以防止膨胀的 wal 日志过度地占用磁盘,可以得到及时的清理。此外,就是 Compaction 相关的配置项,主要是 max_subcompactions 和 max_background_jobs 这两个参数项,一般建议将其设置为 CPU 核数的一半。而这个一半的参数建议,主要来源于用户的反馈以及一些经验数据,不同的场景还是需要不同的配置,HDD 和 SSD 的配置也有所不同,大家可以后面看着情况进行调试。
除了配置参数之外,在做数据导入之前,建议大家执行下 SHOW HOSTS 操作,查看 leader 是否分布均匀:NebulaGraph 会将数据分为若干个 partition,每个 partition 会随机分布在节点上,理想状态自然是 partition 的 leader 是均匀地分布在各个节点的。假如 leader 分布不均的话,可以执行 BALANCE LEADER 操作,确保其均匀分布。
在工具配置方面,可能就是数据导入的重头戏了,配置你的数据导入工具参数:
- 配置项
concurrency,表示导入工具连接多少个 graphd(查询)节点,一般设置为导入工具 nebula-importer 所在机器的 CPU 核数; manager.batch,虽然 NebulaGraph 支持你通过INSERT来一个个点插入到数据库中,但是这个有些低效。因此,设立了 batch 字段用来将一批数据导入到数据库中,默认参数设置是 128,不过这里要根据你自身的数据特性来进行优化。假如你的属性值很多,那么建议将 batch 调小;反之,将 batch 值调大即可。整个 batch 的大小,建议小于 4MB;manager.readerConcurrency是数据读取的并发数,即,从数据源读取数据的并发数。默认参数是 50,一般建议设置为 30-50 即可;manager.importerConcurrency,数据读取之后,会根据一定的规则拼接成 batch 块,这里就涉及到这个参数项。manager.importerConcurrency指的是生成待执行的 nGQL 语句的协程数,一般来说它会设置成manager.readerConcurrency字段的 10 倍,默认值是 512;
软件说完了,来说下硬件方面的配置。NebulaGrpah 优先推荐使用 SSD,当然 HDD 也是可以的,不过性能相对会差点。此外,在 data_path 下多配置几块盘,每个路径配置一个盘,这个也是之前的实践经验总结出来的。而机器和机器之间,推荐使用万兆网卡。最后一点是,nebula-importer 之类的导入工具有条件的话尽量单独部署,和集群隔离开,不然的话在一台机器人会存在资源抢占的问题。
软硬件都说完了,剩下就是数据本身的问题。图数据库的定位是关系分析,同此无关的事情,例如:全文搜索(ES 擅长的场景),要看情况是否将该部分数据放入到 NebulaGraph 中。由于 NebulaGraph 进行数据导入时,不存在导入的先后顺序,即点和边一起混合导入,这样设计的好处是,数据无需做预处理,坏处是数据导入之后可能会产生悬挂边,不利于后续的查询。最后要留意起点,或终点为空的数据,或者是异常数据,这些数据在异常处理时很容易一不小心形成超级节点。
查询指南
下面来讲讲如何搞定 NebulaGraph 的查询篇。这里是一些 tips:
MATCH性能比GO略慢,但MATCH是我们优化的重点。如果没有强性能需求的话,推荐还是尽量使用MATCH,表达能加丰富之外,它同将要出炉的 ISO GQL(图查询语言)是匹配的;- 慎用函数(无法下推),在 NebulaGraph 中并没有将函数下推到 storage。因此,像
src(edge)、dst(edge)、rank(edge)、properties($$)之类的函数,性能都不如edge_.src、edge._dst、edge._rank、$$.tag.prop这些下推到 storage 的表达; - 遇到聚合且需要取属性的情况,先聚合再取属性,因为取属性耗时较长;
MATCH如果只是最后需要返回 count,那么对于 count 的变量最好采用count(id(v))类似的形式,这样会应用到属性裁剪,减少内存消耗;- 能不带路径尽量不要带路径,带路径需要进行路径构造,属性裁剪会失效,此外,还会增加很多额外的内存开销。
总的来说,减少模糊、增加确定,越早越好。
内存保护试试 Memory Tracker
在 v3.4 版本中,引入的一个大功能是:Memory Tracker,用来保护内存,防止内存占用过大导致的 OOM 问题。

- 预留内存:
memory_tracker_untracked_reserved_memory_mb(默认 50 MB)。Memory Tracker 机制会管理通过new/delete申请内存,但进程除了通过此种方式申请内存外,还可能存在其他方式占用的内存;比如通过调用底层的malloc/free申请,这些内存通过此 flag 控制,在计算时会扣除此部分未被 track 的内存,所以这里预留了 50 MB; - 内存比例:
memory_tracker_limit_ratio,就是实际可用内存的比例占用多少的情况下,会限制它再申请使用内存。一般默认是 0.8,就是这个内存占用小于 0.8 的情况下,是可以随意使用内存的;当系统内存占用超过 80% 时,系统便会拒绝掉新的查询语句;- 数值范围:(0,1],默认 0.8 且为开启状态。大多数的用户的 storage 和 graph 节点都存在混部情况,这时候就会建议调低
memory_tracker_limit_ratio,顺便说一句,这个参数项是支持在线调整的; - 数值配置成 2,则会对其进行动态调整,这个动态分配的内存占用比例可能会不大精准;
- 数值配置成 3,则关闭 Memory Tracker 功能;
- 数值范围:(0,1],默认 0.8 且为开启状态。大多数的用户的 storage 和 graph 节点都存在混部情况,这时候就会建议调低
此外,你如果要调试 Memory Tracker 的话,可以开启 memory_tracker_detail_log 来获得调试日志,这个参数项默认是关闭的。
经测试,Memory Tracker 对性能有 1% 左右的影响,但是对于上层为平台类产品或者交互式分析类产品,强烈建议打开。为什么呢?因为上层的业务同学不大了解 NebulaGrpah 运行机制的情况下,容易将服务打满,导致内存爆炸,因此开启这个功能之后,至少能保证系统的稳定运行。
最后,如果动态申请内存时,返回报错 GRAPH_MEMORY_EXCEEDED/STORAGE_MEMORY_EXCEEDED 说明这个内存已经不够用,这条查询语句将不会执行(被杀掉)。
语句调试得用 PROFILE
在任意一条 nGQL 查询语句前面加入 PROFILE,并能得到这条语句的执行计划。

上图一条语句的整个生命周期,Planner 是执行计划(Execution Plan)生成器,它会根据 Validator 校验过、语义合法的查询语法树生成可供执行器(Executor)执行的未经优化的执行计划,而该执行计划会在之后交由 Optimizer 生成一个优化的执行计划,并最终交给 Executor 执行。执行计划由一系列节点(PlanNode)组成。而下图则是一些常见的算子,上图每一个 Plan 节点对应了一个算子:
| 算子 | 介绍 |
|---|---|
| GetNeighbor | 根据指定的 vid ,从存储层获取起始点和边的属性 |
| Traverse | 仅用于 MATCH 匹配 ()-[e:0..n]-() 模式,获取拓展过程中的起始点和边的属性 |
| AppendVertices | 供 MATCH 使用,同算子 Traverse 配合获取点的属性 |
| GetEdge | 获取边的属性 |
| GetVertices | 获取点的属性,FETCH PROP 或者 GO 语句中。 |
| ScanEdge | 全表扫描边,例如 MATCH ()-[e]->() RETURN e LIMIT 3 |
| ScanVertices | 全表扫描点,例如 MATCH (v) return v LIMIT 3 |
| IndexScan | MATCH 语句中找到起始点的索引查询 |
| TagIndexPrefixScan | LOOKUP 语句中前缀扫描 LOOKUP ON player where player.name == "Steve Nash" YIELD player.name |
| TagIndexRangeScan | LOOKUP 语句中范围扫描 LOOKUP ON player where player.name > "S" YIELD player.name |
| TagIndexFullScan | LOOKUP 语句中全扫描 LOOKUP ON player YIELD player.name |
| Filter | 按条件过滤,例如 WHERE 语句 |
| Project | 获取上一步算子的列 |
| Dedup | 去重 |
| LeftJoin | 合并结果 |
| LIMIT | 限制输出行数 |
下面这个是一个例子,我们可以结合例子讲解下。一般来说 PROFILE 会生成一个执行计划,同 EXPLAIN 生成执行计划不同,PROFILE 生成的执行计划中会有相对应的执行时间在里面,比如说下面这张图:

一般来说,我们看执行计划不只是看上下的调用关系,还需要去看里面的具体执行细节:
execTime:graphd 的处理时间;totalTime:graphd 算子起到到算子退出时间;total_rpc_time:graphd 调用 storage client 发出请求到接收到请求时间;exec:storaged 的处理时间,同上面的 graphd 处理时间的execTime;total:storage client 接收到 graphd 请求到 storage client 发送请求的时间,即 storaged 本身的处理时间加上序列化和反序列化的时间;
除了查看时间之外,我们还要查看 row 就能看到 graphd 和 storaged 的具体通信量大小。上图有 3 个 Partition,每个 Partition 返回 1 个 limit 1,总共就 3 条数据。
此外,还得查看执行计划中是否包含计算下推:

上面两条查询语句的差异,上面提到过,就是将函数改成其他调用方式,将 properties(edge).degree 改为 follow.degree,很明显地看到计算下推了。
某个功能不支持array
因为产品规划的问题,NebulaGraph 可能有些功能没法直接支持。比如用户反馈的:
当前属性仅支持基本类型 long、string,来构建索引。是否可以支持多值,比如:
long[]、string[]来构建索引?
的确目前不支持 array,有什么曲线救国的法子?这里提供一些方法,仅供参考:
- 把数组放到 string 里,进行查询时,将数据读取出来进行解析,虽然有点不优雅,但是能解决问题;
- 转化成 bitmap,将不同的类型组成 bitmap,虽然导致代码会复杂点,但可以获得比较快的过滤;
- 边上的 array 转换成两点之间的平行边,相当于一条边就是一个属性,可以方便地进行属性过滤,当然它会带了额外的边数量增加问题;
- 点上的 array 转化成自环边,弊端第 3 种方式,会产生大量自己指向自己的平行边;
- 把属性作为 tag,比如我现在有个商品,它在北京、上海、杭州都有仓库,这时候可以将这个货点变成一个 tag 属性,从而方便地对其进行查询。这里需要注意的是,这个方式容易产生超级节点,这里就需要注意避免超级节点的产生。
功能更强了 UDF
用户自定义函数(User-defined Function,UDF),用户可以在 nGQL 中调用函数。与从 nGQL 中调用的内置函数一样,UDF 的逻辑通常扩展或增强了 nGQL 的功能,使其具有 nGQL 没有或不擅长处理的功能。UDF 被定义后可以重复使用。
这里简述下 UDF 的使用过程:
-
准备编译环境 & 下载源码:https://docs.nebula-graph.com.cn/3.5.0/4.deployment-and-installation/1.resource-preparations/
-
进入到 NebulaGraph 代码仓库,创建 UDF 相关源码文件。当前有两个示意文件
standard_deviation.cpp/standard_deviation.h可以参考 -
编译 UDF
g++ -c -I ../src/ -I ../build/third-party/install/include/ -fPIC standard_deviation.cpp -o standard_deviation.o
g++ -shared -o standard_deviation.so standard_deviation.o
- 1
- 2
- 加载 UDF 至 graphd 服务
编辑 graphd 服务配置文件:打开 /usr/local/nebula/etc/nebula-graphd.conf 文件,添加或修改以下配置项:
# UDF C++
--enable_udf=true
# UDF .so
--udf_path=/home/foobar/dev/nebula/udf/
- 1
- 2
- 3
- 4
- 重启 graphd
udo /usr/local/nebula/scripts/nebula.service restart graphd
- 1
- 连接到 graphd 后验证
GO 1 TO 2 STEPS FROM “player100” OVER follow YIELD properties(edge).degree AS d | yield collect($-.d) AS d | yield standard_deviation($-.d)
- 1
不过,目前 UDF 有些问题:
- so 包位置只支持扫描本地,也就是如果你是分布式集群的话,每个机器上都得有个包;
- 函数只在 graphd 层,无法下推到存储;
- 暂不支持 Java(性能考虑),未来版本会支持;
待解决的问题
这里罗列下未来的产品可优化点:
- 全文索引:v3.4 之前的全文索引功能都不太好用,约束比较多,且有些 bug。v3.4 版本做了精简和优化,更加稳定。但实际上,v3.4 及之前的全文索引功能准确讲并不是真正意义的全文索引,主要是支持前缀搜索、通配符搜索、正则表达式搜索和模糊搜索等。并不支持分词、以及查询的分数,v3.6 版本(即将发布)做了全文索引的优化,重新设计了全文索引功能(可以更好的支持 Neo4j 替换)。不过与原有的全文索引不兼容,需要重建索引;
- 关于悬挂边的产生:设计理念,不隐式的对数据进行变更导致(删除点的时候不隐式删除边),当然由此会带来悬挂边和孤儿点的问题,后面这块会考虑进行相关的优化;
- 事务的支持,大多数人对 NebulaGraph 的事务需求来源于,他认为 NebulaGraph 是一款 TP 产品,TP 产品是一定具备事务性的,这并非是业务场景的需求。当然,事务这块撇开这种某款产品必须具备的特性之外这点,一些生产链路上面,事务还是一个强需求,因此在后续的开发中也会新增事务特性。
其他问题交流
下面问题整理自本次分享的 QA 部分:
Q:上文提到 VID 的设定,是越短越好。短的 VID 会带来什么后果么?
方扬:VID 理论上是越短越好,没有任何的副作用。不过它的设定是在满足你既有的业务需求,不要出现重复的 VID 情况下,尽可能的短即可;
Q:截断的话,是对返回的数据量做限制,这个返回的话是有序的么?
训焘:目前数据的返回是 random,随即返回的,随机根据你的 range 来返回一些数据量。
谢谢你读完本文 (///▽///)
如果你想尝鲜图数据库 NebulaGraph,记得去 GitHub 下载、使用、(з)-☆ star 它 -> GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呀~

