
- 1如何批量查询自己的CSDN博客质量分_csdn 怎么查看哪里改进
- 29_帖子详情_帖子详情页面
- 3字节跳动测开面经,听他讲完,紧张得汗流了一背!_字节财经 测开
- 4git基本概念和核心命令使用_git的基本概念
- 5网络攻防演练.网络安全.学习_攻防实战演练csdn
- 6HOW - Canvas 入门系列之基于vue-konva的多维表格(四)
- 7vue+element-ui 表格中图片缩略图悬浮显示_vue el-table 加上传缩略图的功能
- 8通过adb查看当前连接的设备的CPU_windows adb如何查找cpu型号
- 9Docker部署MySQL监控工具Lepus_lepus docker
- 10.NET 8 Host 的一些更新
计算机等级考试2级(Python)知识点整理
赞
踩
计算机等级考试2级(Python)知识点整理
1.基础知识点(记忆、理解)
第1讲Python概述
01. 源代码
02. 目标代码
03. 编译和解释
04. 程序的基本编写方法
第2讲 Python语言基础(一)
01. 用缩进表示代码块:一般用4个空格或1个TAB
02. 代码注释的方法:
单行注释用“#”表示注释开始;多行注释是用三个英文的单引号“‘’'”或双引号““”"”作为注释的开始和结束符号。
03. 标识符命名规则
-
标识符是变量、函数、类、模块和其他对象的名字。
-
标识符第一个字符必须是英文字母或下划线 _ ;
-
标识符的其他的部分由字母、数字和下划线组成;
-
Python语言标识符对大小写敏感,长度没有限制。
例如:x3 、 x_3、my_factor是正确的,而3x、if(保留字)、__init__(预定义标识符)则是错误的。- 1
04. Python 3.x关键字(保留字)列表 (35个)
| if | elif | else | |
|---|---|---|---|
| for | while | break | continue |
| in | and | or | not |
| def | global | return | lambda |
| nonlocal | import | from | as |
| try | finally | except | raise |
| del | is | True | False |
| assert | pass | yield | None |
| class | with | async | await |
05.基本输出实例
输出一个对象并赋值;输出多个对象;指定输出不换行
>>> a,b=2,3
>>> print(“a=”,a)
a= 2
>>> print(“a=”,a,“b=”,b)
a= 2 b= 3

第3讲 Python语言基础(二)
01. 内置数值操作
+ - * / // % **
02. 内置数值函数
divmod(x,y)、pow(x,y) 或 pow(x,y,z)、round(x) 或 round(x,d)、max(x1,x2,…,xn) 或 min(x1,x2,…,xn)
按照以下格式写:
a,b=divmod(10,3) #输出二元形式的商和余数,结果为a=3,b=1
03. math模块及其引用
import math
math库中主要常数及数学函数
| 函数 | 功能 | 示例 |
|---|---|---|
| e | 表示一个常量 | >>> math.e #2.718281828459045 |
| pi | 数字常量,圆周率 | >>> math.pi #3.141592653589793 |
| sqrt(x) | 求x的平方根 | |
| pow(x, y) | *返回x的y次方,即x*y | >>> math.pow(3,4) #81.0 |
| fabs(x) | 返回x的绝对值 |
04. 算数运算符、关系运算符
05. 例 用户输入一个三位自然数,计算并输出其百位、十位和个位上的数字。(两种方法)

第4讲 Python语言基础(三)(重点:字符串应用程序编写)
01. 整型(int)
0x9a、-0X89 (0x**、0X开头表示16进制数**)
0b010、 -0B101 (0b**、0B开头表示2进制数**)
0o123、 -0O456 (0o**、 0O开头表示8进制数**)
02. 字符串有 2类共4种 表示方法
- 由一对单引号或双引号表示,仅表示单行字符串
"请输入带有符号的温度值: " 或者 'C’
- 由一对三单引号或三双引号表示,可表示多行字符串
03. Python转义字符表
| \t | 水平制表符 |
|---|---|
| \ | *一个斜线* |
| ’ | 单引号’ |
| " | 双引号” |
04. 字符串索引
- 字符串是一个字符序列:字符串最左端位置标记为0,依次增加。字符串中的编号叫做“索引”
| H | e | l | l | o | J | o | h | n | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 正向→ | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 反向← | -10 | -9 | -8 | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
>>> s="Python语言" #len(s)结果为8
>>> print(s[2])
t
>>> s="Python语言"
>>> s[-1::-1]
'言语nohtyP'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
05. 练习:获取星期字符串
06. 字符串的格式化
例题:使用format方法进行格式化
date="2018-9-18"
rate=10.2222
print("{}:计算机{}的CPU占用率为{:.2f}%。".format(date,"Python",rate))
运行结果:
2018-9-18:计算机Python的CPU占用率为10.22%。
例题:
c=3
d=4
print("c=",c)
print("c={},d={}".format(c,d))
运行结果:
c= 3
c=3,d=4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
07. 类型转换
| 函数 | 描述 | 示例 |
|---|---|---|
| int(x[,base]) | 将x转换为整数,x可以是浮点数或字符串,base可以是2、8、16,此时x必须是字符串 | int(2.8) #2 int(-2.8) #-2 int(‘2.8’) #错误 int(‘ff’,16) #255 int(‘1011’,2) #11 |
| float(x) | 将x转换为浮点数,x可以是整数或字符串 | float(‘10’) #10.0 float(10) #10.0 |
| str(x) | 将x转换为字符串,x可以是整数或浮点数 | str(3.14) #‘3.14’ |
第5讲 程序控制结构(一)
01. 程序由三种基本结构组成
顺序结构、分支结构、循环结构
02.Python语言共有6个关系操作符
03. Python语言共有3个逻辑操作符
04. 单分支结构: if语句
• if 条件:
• 语句块
05. 二分支结构: if-else语句
if 条件:
语句块1
else:
语句块2
06. 多分支结构: if-elif-else语句
if 条件1:
语句块1
elif 条件2:
语句块2
…
else:
语句块N
07. 例子
PM = eval(input("请输入PM2.5数值: "))
if 0<= PM < 35: # PM>=0 and PM<35
print("空气优质,快去户外运动!")
elif 35 <= PM <75: # PM>=35 and PM<75
print("空气良好,适度户外活动!")
else:
print("空气污染,请小心!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
第6讲 程序控制结构(二)(重点:循环程序编写)
01. 遍历循环: for语句
for <循环变量> in <遍历结构>:
<语句块>
| 循环N次 for i in range(N): | 遍历文件fi的每一行 for line in fi: | 遍历字符串s for c in s: | 遍历列表ls for item in ls: |
|---|---|---|---|
| <语句块> | <语句块> | <语句块> | <语句块> |
【例1】用户输入一个正整数N,计算从1到N(包含1和N)相加之后的结果。
【例2】输入一个正整数n,求 1-1/3+1/5-… 的前n项和。
sum=0;flag=1;denominator =1 ; item=1
n=int(input("请输入整数N:"))
for i in range(1,n+1):
sum = sum + item ; #累加第i项的值
flag = -flag; # 准备下一次循环
denominator = denominator +2;
item = flag / denominator; #计算第i项的值
print("运算结果是:{:.2f}".format(sum))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
02. 无限循环: while语句
while <条件>:
<语句块1>
else: #else****语句块作为"正常"完成循环的奖励
<语句块2>
例题3
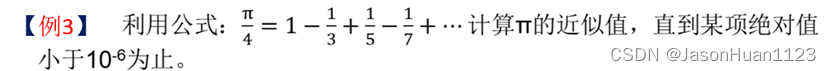
import math
sum=0;flag=1;denominator =1;item=1
while math.fabs(item)>=1e-6:
sum = sum + item ; #累加第i项的值
flag = -flag; # 准备下一次循环
denominator = denominator +2;
item = flag / denominator; #计算第i项的值
sum=4*sum
print("π的近似值为:{}".format(sum))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
03. 循环保留字: break和continue
第7讲 程序控制结构(三)
补充:begin, end = map( int, input(“”).split() ) #以空格隔开输入两个数如:3 8
#结果begin=3, end=8
**【例2修改】**编程(leapyear.py)将1900-2020(包括1900和2020)之间的闰年打印出来,每行5个。判断闰年的条件是:年份能被4整除但不能被100整除,或者能被400整除。
i=0
for y in range(1900,2021):
if ((y%4==0 and y%100!=0) or y%400==0):
print(y,end="\t")
i=i+1
if i%5==0:
print("\n")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
【例5】判断一个自然数是否为素数。
n =int(input("Input an integer:"))
if n == 2:
print('Yes')
elif n%2 == 0: #偶数必然不是素数
print('No')
else:
for i in range(2, n):
if n%i == 0:
print('No')
break #结束循环
else:
print('Yes')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
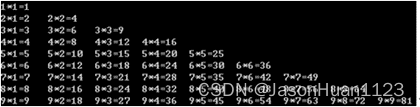
【例6】利用嵌套循环打印运行效果如图所示的九九乘法表
方法一:
for i in range(1,10):
s=""
for j in range(1,i+1):
s=s+"{:1}*{:1}={:<2} ".format(i,j,i*j)
print(s)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
方法二:
for i in range(1,10):
for j in range(1,i+1):
print("{:1}*{:1}={:<2} ".format(i,j,i*j),end="")
print("\n")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
【例7】编写代码,输出由星号*组成的菱形图案,并且可以灵活控制图案的大小。

n=6
for i in range(n): #打印n-1行
print((' * '*i).center(n*3))
for i in range(n, 0, -1):
print((' * '*i).center(n*3))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
第8讲 组合数据类型(一)
01. 组合数据类型概述
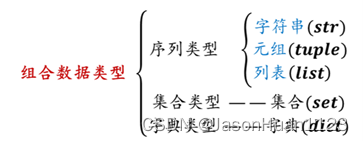
02. 序列
(1) 序列是具有先后关系的一组元素
(2) 序列类型6个通用操作符
03. 元组
元组是一种序列类型,一旦创建就不能被修改
- 使用小括号 () 或 tuple() 创建,元素间用逗号 , 分隔
- 可以使用或不使用小括号
- 实例
04. 列表
(1) 列表是一种序列类型,创建后可以随意被修改
(2) 使用方括号 [] 或list() 创建,元素间用逗号 , 分隔
(3) 列表中各元素类型可以不同,无长度限制
(4) 例题
>>> ls = ["cat", "dog", "tiger", 1024]
>>> lt = ls
- 1
- 2
- 3
方括号 [] 真正创建一个列表,赋值仅传递引用
(5) 列表功能默写
05. 集合
(1) 基本概念
- 集合类型与数学中的集合概念一致
- 集合元素之间无序,每个元素唯一,不存在相同元素
- 集合元素不可更改,不能是可变数据类型
- 集合用大括号 {} 表示,元素间用逗号分隔
- 建立集合类型用 {} 或 set()
- 建立空集合类型,必须使用set()
(2) 集合间操作
- 交(&)、并(|)、差(-)、补(^)、比较(>=<)
(3) 集合类型方法
- .add()、.discard()、.pop()等
(4) 集合类型主要应用于:包含关系比较、数据去重
-
06. 例题
第9讲 组合数据类型(二)
01. 字典
字典(映射)类型是“键-值”数据项的组合,每个元素是一个键值对,即元素是(key, value),元素之间是无序的。键值对(key, value)是一种二元关系。
采用大括号{}和dict()创建,键值对用冒号: 表示 {<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}
**02. **字典功能默写
03. 例子:
>>>Dcountry={"中国":"北京", "美国":"华盛顿", "法国":"巴黎"}
>>>for key in Dcountry:
print(key)
中国
美国
法国
>>>for key in Dcountry:
print(Dcountry [key])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
04. 例题
第10讲 函数和代码复用(一)
01.函数的定义与调用



**02. **局部变量和全局变量



03. lambda函数
lambda函数是一种匿名函数,即没有名字的函数

第11讲 函数和代码复用(二)
1. 递归的实现
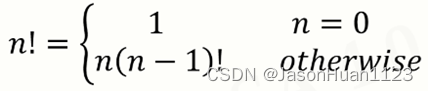

2. 例1
3. 例2
4. 例3
5. 例4
第12讲 文件
1. 文件的打开和关闭
文件处理的步骤: 打开-操作-关闭
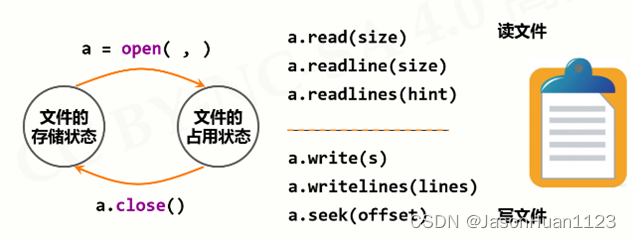
2. 打开模式

3. 例子:

4. 一维数据的读入处理
从空格分隔的文件中读入数据

5. 一维数据的写入处理
采用空格分隔方式将数据写入文件采用空格分隔方式将数据写入文件

第13讲 Python计算生态 (一)(重点:图形绘制填空)
01. random库
random()
生成一个[0.0, 1.0)之间的随机小数
randint(a, b)
生成一个[a,b]之间的整数
02. time库
03. turtle库
- turtle.setup()调整绘图窗体在电脑屏幕中的布局
- 画布上以中心为原点的空间坐标系: 绝对坐标&海龟坐标
- 画布上以空间x轴为0度的角度坐标系: 绝对角度&海龟角度
- RGB色彩体系,整数值&小数值,色彩模式切换
- penup()、pendown()、pensize()、pencolor()
- fd()、circle()、seth()
04. 实例:Python蟒蛇
05. 绘制五角星绘制
2.典型考试题目
真题1:计算斐波那契数列
题目:编写一个函数,计算并返回斐波那契数列的第n项。
解答:
def fibonacci(n):
if n <= 0:
return 0
elif n == 1:
return 1
else:
a, b = 0, 1
for _ in range(2, n + 1):
a, b = b, a + b
return b
# 测试代码
print(fibonacci(10)) # 输出55
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
分析:斐波那契数列是一个经典的数列,其中每个数字是前两个数字的和。这个函数使用迭代方法计算斐波那契数列的第n项,避免了递归可能导致的栈溢出问题。
真题2:判断回文字符串
题目:编写一个函数,判断给定的字符串是否为回文。
解答:
def is_palindrome(s):
return s == s[::-1]
# 测试代码
print(is_palindrome("abcba")) # 输出True
print(is_palindrome("abcde")) # 输出False
- 1
- 2
- 3
- 4
- 5
- 6
分析:判断字符串是否为回文,最简单的方法是将其反转后与原字符串比较。在Python中,可以使用切片[::-1]来反转字符串。
真题3:列表排序并去重
题目:编写一个函数,接收一个整数列表,返回排序后且去重的列表。
解答:
def sort_and_deduplicate(lst):
return sorted(set(lst))
# 测试代码
print(sort_and_deduplicate([3, 1, 2, 1, 4, 3])) # 输出[1, 2, 3, 4]
- 1
- 2
- 3
- 4
- 5
分析:使用set可以去除列表中的重复元素,而sorted函数则可以对去重后的元素进行排序。这种方法简洁且高效。
真题4:文件读写操作
题目:编写一个程序,读取一个文本文件中的内容,并统计其中单词的数量。
解答:
def count_words_in_file(filename):
with open(filename, 'r') as file:
content = file.read()
words = content.split()
return len(words)
# 测试代码(假设文件存在且包含文本内容)
print(count_words_in_file('example.txt')) # 输出单词数量
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
分析:这个程序使用with语句打开文件,确保文件在使用后会被正确关闭。然后,它读取文件内容,使用split()方法将内容分割成单词列表,并返回单词的数量。
真题5:字典操作
题目:编写一个函数,接收一个字典和一个键的列表,返回这些键在字典中对应的值组成的列表。
解答:
def get_values_by_keys(dictionary, keys):
return [dictionary.get(key) for key in keys]
# 测试代码
dict_example = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
keys_list = ['a', 'c', 'd']
print(get_values_by_keys(dict_example, keys_list)) # 输出[1, 3, 4]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
分析:这个函数使用列表推导式从字典中提取指定键对应的值。dict.get(key)方法用于获取字典中指定键的值,如果键不存在则返回None。
题目5:编写一个程序,输入一个年份,判断是否是闰年。
解答:
def is_leap_year(year):
if year % 4 == 0 and (year % 100 != 0 or year % 400 == 0):
return True
return False
year = int(input("请输入年份:"))
if is_leap_year(year):
print(f"{year}是闰年。")
else:
print(f"{year}不是闰年。")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
分析:根据闰年的定义,能被4整除但不能被100整除的年份是闰年,或者能被400整除的年份也是闰年。
题目6:实现一个函数,计算给定列表中所有数字的平均值。
解答:
def average(lst):
return sum(lst) / len(lst) if lst else 0
numbers = [1, 2, 3, 4, 5]
print(average(numbers)) # 输出3.0
- 1
- 2
- 3
- 4
- 5
分析:使用sum函数求和,然后除以列表长度得到平均值。注意处理空列表的情况。
题目7:编写程序,实现字符串的反转。
解答:
def reverse_string(s):
return s[::-1]
print(reverse_string("hello")) # 输出olleh
- 1
- 2
- 3
- 4
分析:Python中字符串切片[::-1]可以实现字符串的反转。
题目8:定义一个函数,接收一个整数n,并输出1到n的所有整数的平方。
解答:
def print_squares(n):
for i in range(1, n + 1):
print(i ** 2)
print_squares(5) # 输出1, 4, 9, 16, 25
- 1
- 2
- 3
- 4
- 5
分析:使用for循环遍历1到n的所有整数,并计算每个整数的平方后打印。
题目9:创建一个字典,将英文星期缩写映射到其中文全称。
解答:
weekdays = {
'Mon': '星期一',
'Tue': '星期二',
'Wed': '星期三',
'Thu': '星期四',
'Fri': '星期五',
'Sat': '星期六',
'Sun': '星期日'
}
print(weekdays['Mon']) # 输出星期一
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
分析:字典是Python中存储键值对的数据结构,适合用于此类映射关系。
题目10:字符串处理
已知字符串s: s=“ABCDABDCACDBCDABCBDACADBBCAD” 考生文件夹下有程序PROG4.PY,请按以下规则编写程序,
规则如下: (1) 将s中的"B?C"替换为"1?2",?表示任意字母,替换后保留,例如: “BAC”、“BDC"分别替换为"1A2”、“1D2”
(2) 要求用循环结构实现算法
(3) 将s存入考生文件夹下“result.txt”的文件中。
def save(content):
filename="result.txt"
with open(filename,mode='w') as fp:
fp.write(content)
s="ABCDABDCACDBCDABCBDACADBBCAD"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
#请在下面位置编写程序
分析:我们可以通过遍历字符串s,并检查每个字符及其相邻字符来寻找匹配"B?C"模式的子串。一旦找到这样的模式,我们就手动进行替换。以下是一个简单的Python程序来实现这个功能:
def replace_b_question_mark_c(s):
result = ""
i = 0
while i < len(s) - 2: # 确保有足够的字符进行检查
if s[i] == 'B' and s[i + 2] == 'C':
result += '1' + s[i + 1] + '2'
i += 3 # 跳过已处理的三个字符
else:
result += s[i]
i += 1
# 添加剩余字符,如果有的话
result += s[i:]
return result
def save(content):
filename = "result.txt"
with open(filename, mode='w') as fp:
fp.write(content)
# 原始字符串
s = "ABCDABDCACDBCDABCBDACADBBCAD"
# 进行替换操作
new_s = replace_b_question_mark_c(s)
# 保存结果到文件
save(new_s)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
在这个程序中,replace_b_question_mark_c函数会遍历输入字符串s,检查每个字符及其后两个字符是否形成"B?C"的模式。如果找到,就将其替换为"1?2",其中’?'是原字符串中位于’B’和’C’之间的字符。函数save将处理后的字符串写入到名为"result.txt"的文件中。
题目11:编写程序,计算给定数字的阶乘。
解答:
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
print(factorial(5)) # 输出120
- 1
- 2
- 3
- 4
- 5
- 6
- 7
分析:使用递归函数计算阶乘,基本情况是n为0时返回1。
题目12:将给定的十进制数转换为二进制数。
解答:
def decimal_to_binary(n):
if n == 0:
return '0'
result = ''
while n > 0:
result = str(n % 2) + result
n //= 2
return result
print(decimal_to_binary(10)) # 输出1010
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
分析:通过不断除以2并取余数,再将余数添加到结果字符串的前面,直到原数为0。
题目13:编写程序,查找并打印列表中最大的数。
解答:
def find_max(lst):
return max(lst)
numbers = [4, 2, 9, 7, 5, 1]
print(find_max(numbers)) # 输出9
- 1
- 2
- 3
- 4
- 5
分析:使用Python内置的max函数可以直接找到列表中的最大值。
题目14:编写程序,查找最大值并排序。
随机生成1到100之间的100个数字的列表,找出值大于50的元素,放入新的列表中,然后按照从小到大排序输出。
import random
# 初始化一个空列表
random_list = []
# 使用循环生成100个随机整数并添加到列表中
for i in range(100):
random_list.append(random.randint(1, 100))
# 初始化一个空列表来存放大于50的元素
greater_than_50_list = []
# 使用循环找出大于50的元素,并添加到新的列表中
for num in random_list:
if num > 50:
greater_than_50_list.append(num)
# 对新列表进行排序
greater_than_50_list.sort()
# 输出排序后的列表
print(greater_than_50_list)
说明:
# 对新列表进行从大到小的排序
greater_than_50_list.sort(reverse=True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
题目15:实现一个函数,接收一个字符串,统计并返回字符串中各个字符出现的次数。
解答:
def count_chars(s):
char_count = {}
for char in s:
if char in char_count:
char_count[char] += 1
else:
char_count[char] = 1
return char_count
print(count_chars("hello")) # 输出{'h': 1, 'e': 1, 'l': 2, 'o': 1}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
分析:通过遍历字符串中的每个字符,并使用字典记录每个字符出现的次数,最后返回该字典。

