
Oriented R-CNN for Object Detection(定向R-CNN的目标检测)
赞
踩
一、前言及相关工作

图1为,生成定向提案的不同方案的比较。(a)旋转RPN密集放置不同尺度、比例、角度的旋转锚。(b) RoI Transformer+从水平RoI中学习定向提案。它包括RPN、RoI对齐和回归。(c)我们以建议为导向的RPN以几乎没有成本的方式产生高质量的建议。定向RPN的参数数约为RoI Transformer+的1/3000,旋转RPN的1/15。
(a)Rotated RPN:它在每个位置放置54个不同角度、尺度和宽高比(3个scales×3 ratios×6角度)的锚点。
Rotated RPN优点:旋转锚点的引入提高了召回率,并且在定向对象稀疏分布时表现出良好的性能
Rotated RPN缺点:大量的锚会导致大量的计算和内存占用。
(b)RoI Transformer:通过复杂的过程从水平RoI中学习定向建议,这涉及到RPN、RoI对齐和回归。
RoI Transformer优点:提供了有前途的定向方案,大大减少了旋转锚点的数量。
RoI Transformer缺点:也带来了昂贵的计算成本。
本文提出了一种有效且简单的定向目标检测框架,称为定向R-CNN,它是一种通用的两阶段定向检测器,具有良好的精度和效率。具体来说,在第一阶段,我们提出了一个面向区域的提案网络(面向RPN),它以几乎无成本的方式直接生成高质量的面向提案。第二阶段是面向R-CNN头部,用于提炼面向兴趣区域(面向roi)并识别它们。
二、定向R-CNN
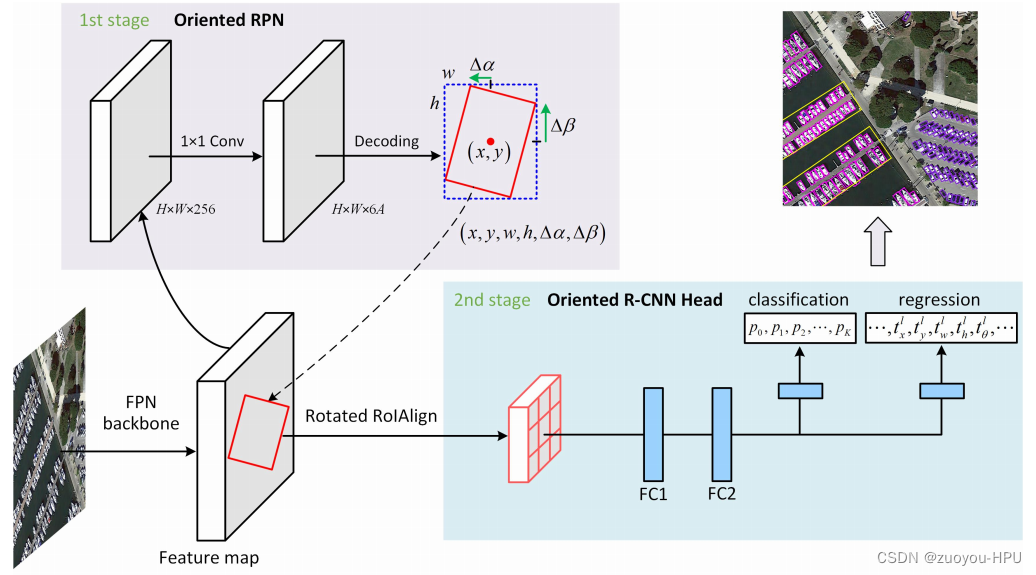
第一阶段通过定向RPN生成定向提案,第二阶段通过定向R-CNN头部对提案进行分类并细化其空间位置。本文提出的目标检测方法,称为定向R-CNN,由一个定向RPN和一个定向RCNN头组成(见图2)。它是一个两阶段检测器,其中第一阶段以几乎无成本的方式生成高质量的定向建议,第二阶段是定向RCNN头,用于建议分类和回归。FPN主干产生了五个级别的特征{P2, P3, P4, P5, P6}。为简单起见,在面向RPN中,没有展示FPN的体系结构和分类分支
2.1定向 RPN
,它将FPN的五个级别的特征{P2, P3, P4, P5, P6}作为输入,并将相同设计的头部(3×3卷积层和两个兄弟1×1卷积层)附加到每个级别的特征上。我们为所有级别特征中的每个空间位置分配三个具有三个纵横比{1:2,1:1,2:1}的水平锚点。锚点在{}上的像素面积分别为
。每个锚点a用一个四维向量a = (
)表示,其中(
)是锚点的中心坐标,
表示锚点的宽度和高度。两个分支的1×1卷积层中的一个是回归分支:输出相对于锚点的建议的偏移δ = (
)。在feature map的每个位置,我们生成A个建议(A为每个位置的锚点数量,在本工作中等于3),因此回归分支有6A个输出。通过对回归输出进行解码,得到定向方案。解码过程描述如下:
其中,为预测候选框的中心坐标,
为预测候选框外接矩形的宽度和高度,
是相对于外接矩形的顶部和右侧的中点的偏移量。
2.1.1 中心点偏移表示
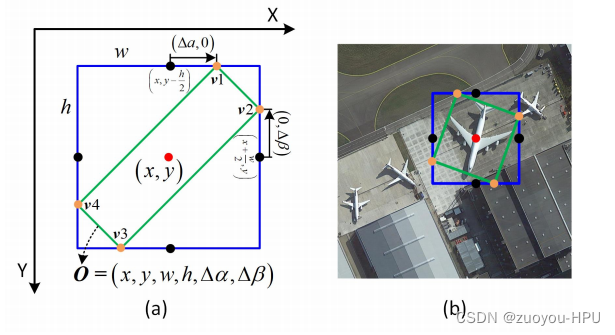
(a)中点偏移表示示意图。(b)一个中点偏移表示的例子
称为中点偏移表示,如图3所示。黑点是水平框的每条边的中点,这是定向边界框O的外部矩形,橙色点代表定向边界框O的顶点。
根据,可以得到每个候选框的四个顶点坐标集
,四个顶点坐标表示为:
通过预测其外部矩形的参数(x, y, w, h)和推断其中点偏移量的参数(∆α,∆β)来实现每个定向候选框的回归。
3.1.2损失函数

黑点是顶部和右侧的中点,橙色点是定向边界框的顶点。(a)锚。(b)真相箱。(c)预测框。
规定正样本:①.②
规定负样本:
非正非负的anchor为无效样本。强调,真实框指的是定向候选框的外部矩形。
定义L1损失为:
是定向RPN分类分支的输出,表示候选框属于前景的概率。
是第
个anchor的真实标签。
是定向RPN回归分支的输出,表示候选框的偏置。
是真实偏置。
3.2 定向RCNN头
定向R-CNN头部以特征映射{P2, P3, P4, P5}和一组定向建议作为输入。对于每个定向提案,我们使用旋转的RoI对齐(简称旋转的RoIAlign)从其相应的特征映射中提取固定大小的特征向量。
每个特征向量被馈送到两个完全连接的层(FC1和FC2,见图2),然后是两个兄弟的完全连接层:一个输出提案属于K+1类(K个对象类加上1个背景类)的概率,另一个生成K个对象类中每个提案的偏移量
3.2.1旋转RoIAlign
旋转RoIAlign是一种从每个定向提案中提取旋转不变性特征的操作
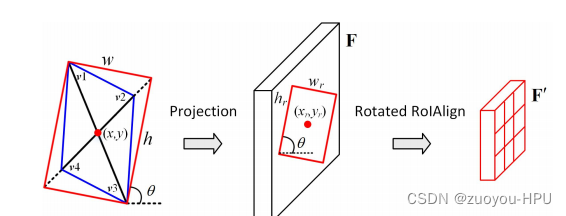
为生成的定向候选框平行四边形的顶点,为了便于计算,需要将每个平行四边形调整为有方向的矩形。通过将较短的对角线扩展至与较长对角线相同的长度来实现。经过这个简单的运算,从平行四边形中得到有向矩形
.接下来,将定向矩形
以s的步长投影到特征映射F上,得到一个旋转的RoI,通过以下操作定义为
。
3.3实现细节
通过对定向RPN和定向R-CNN头进行联合优化,以端到端方式训练有向R-CNN。在推理过程中,定向RPN生成的定向候选框通常有很高的重叠。为了减少冗余,我们在第一阶段每个FPN级别保留2000个候选框,然后是非最大抑制(NMS)。考虑到推理速度,采用了IoU阈值为0.8的水平NMS。将所有级别的剩余候选框合并,并根据其分类得分选择前1000名的候选框作为第二阶段的输入。第二阶段,对预测的类概率大于0.05的面向边界框对每个对象类进行策略NMS。ploynms IoU阈值为0.1。

