
- 1大白话说明:k8s-Service资源的理解以及与Ingress Controller 做区分
- 2Flink 独立集群安装_flink独立集群
- 3辛星和您一起用CSS手写导航条_手写css导航栏
- 44分钟学会Python爬虫,轻松爬取哔哩哔哩视频!_python b站视频下载
- 5广度优先算法(一篇文章讲透)
- 6学习通浏览器刷课脚本_学习通脚本
- 7使用ollama部署llama3-8B
- 8Git分支管理策略_gtee分支 relevance
- 9C++工程管理 版本控制git Makefile cmake LInux_c++ 版本控制
- 10nginx安装http_ssl_module模块_nginx http ssl
专业测评|戴尔Precision塔式工作站AI绘图及训练测评分享_lora模型电脑配置
赞
踩
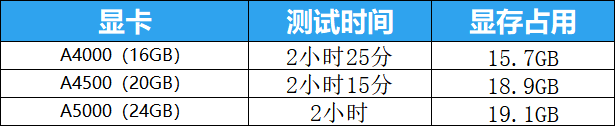
本次测试一共收到三张显卡,分别是NVIDIA RTX™ A4000、NVIDIA RTX™ A4500、NVIDIA RTX™ A5000显卡,显存大小分别是16GB、20GB、24GB,搭配测试的塔式工作站主机是全新戴尔Precision 3660塔式工作站,搭载第十三代英特尔®酷睿™ i7-13700处理器,内存为32GB,硬盘为2T+256G SSD。
01 模型训练的基本要求
Lora与Dreambooth
提到训练模型,我想简单地介绍一下关于Stable Diffusion模型训练的基本概念与模型训练对配置的最低需求(注:这里所指的需求是我结合官网推荐以及本次测试结果综合考量后得到的)!
提到模型的训练,就不得不说一下关于大模型的基础模型和微调模型的概念:
基础模型
大模型的基础模型在SD中指的是Stable diffusion:V1.4/V1.5/V2.0等,这些都是大模型,它们泛化性、通用性很好,是官方利用大量的数据训练而来。对于大模型的基础模型训练我们个人用户或者微小企业而言成本太高了,所以大模型的基础模型训练不在本次的测试范围之内。
微调模型
本次测试的主要内容是训练微调模型,而微调模型的种类很多,其中分为在大模型的基础模型的基础上结合自己的自有数据进行二次训练,从而得到新的微调大模型(Dreambooth),以及在大模型基础模型的基础上,训练Lora、Embedding、Hypernetwork等微调模型。
鉴于Embedding、Hypernetwork这两种微调模型实用性目前来看不是很高,所以此次测试主要以训练Lora模型为主。其中新生成的微调大模型(Dreambooth)就是我们在SD界面中上方所切换的模型。

而微调模型Lora模型,是我们在大模型生成的基础上对画面的风格进行微调时所调用的模型。

对于训练来说,微调大模型(Dreambooth)和微调模型(Lora)又分不同的版本,比如SD1.5版本的Dreambooth模型与Lora模型以及SDXL的Dreambooth模型与Lora模型,两大版本不同的模型在训练过程中对配置的要求是不一样的。

如果想要训练SD1.5的微调模型(Lora),要求我们的硬件显存必须要6G以上,这是最低要求,而我推荐想要进行微调模型的训练,显存最好超过8GB。
如果想要训练SD1.5的大模型(Dreambooth),需要我们的硬件显存必须要12GB以上,这里也是最低要求,我推荐的显存也是12GB。
02 SD生图小试牛刀
上次测试戴尔移动工作站的时候,全新戴尔Precision 5680移动工作站搭载的显卡是NVIDAI RTX™ 3500Ada,显存是12GB,最终在生图阶段遇到SDXL大模型配合Controlnet时表现的不是很好,那么让我们在测试模型训练之前,先来个开胃小菜,看一下NVIDAI RTX™ A4000显卡,在全新戴尔Precision 3660塔式工作站上基于SD生图的表现吧。

从显存占用上来看,全新戴尔Precision 3660塔式工作站搭配NVIDAI RTX™ A4000显卡已经可以胜任所有的出图模式,并且速度很快,那么NVIDAI RTX™ A4500和NVIDAI RTX™ A5000两块显卡的出图测试就不用进行了,因为NVIDAI RTX™ A4500和NVIDAI RTX™ A5000的显存比NVIDAI RTX™ A4000的显卡要高。
03 模型训练测评
测试一:SD1.5Lora模型训练
开始进入正题,对于Lora的训练也是日常使用SD进行出图的小伙伴最为关心的事情,因为Lora模型的训练相对来说比较简单,只不过从11月份之后SD官方自带的训练插件经常出问题,无论是Lora的训练还是接下来测试的Dreambooth模型训练我们都不采用官方的插件了,在市面上有现成的第三方模型训练软件,也就是“丹炉”供我们使用。

在训练模型之前我们首先要准备一定量的图片作为训练集,让AI去学习这些图片,那么在训练模型的时候我们也要对找到的训练集进行一定的处理,在这里我为了保证测试的公平性,在针对Lora训练进行测试的时候,我统一使用相同的训练集,图片数量为35张,每张图片大小为512*512的图进行训练,训练过程中所使用的丹炉为赛博丹炉。
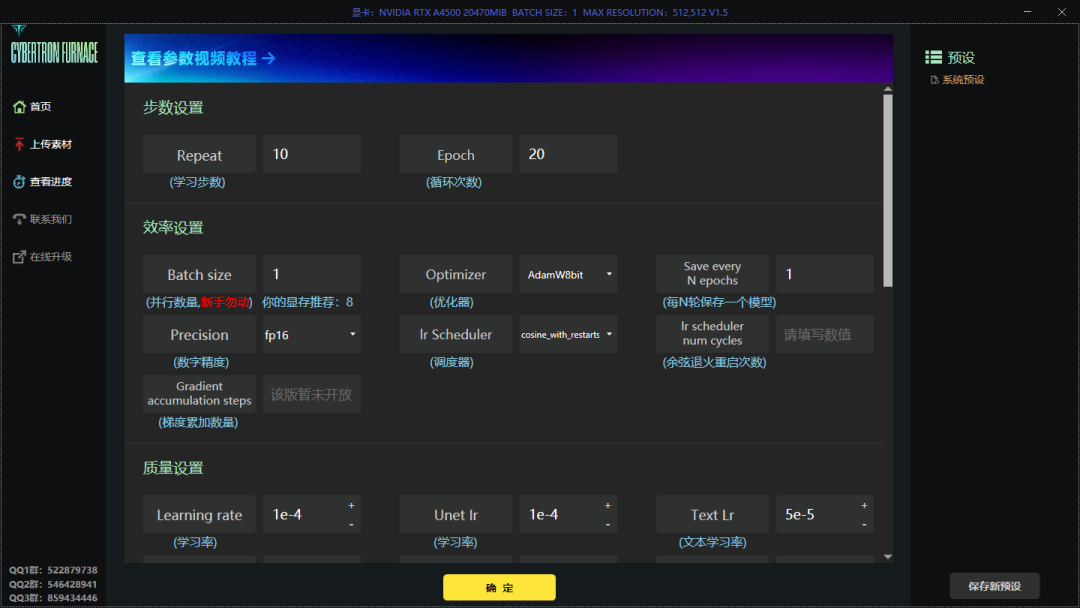
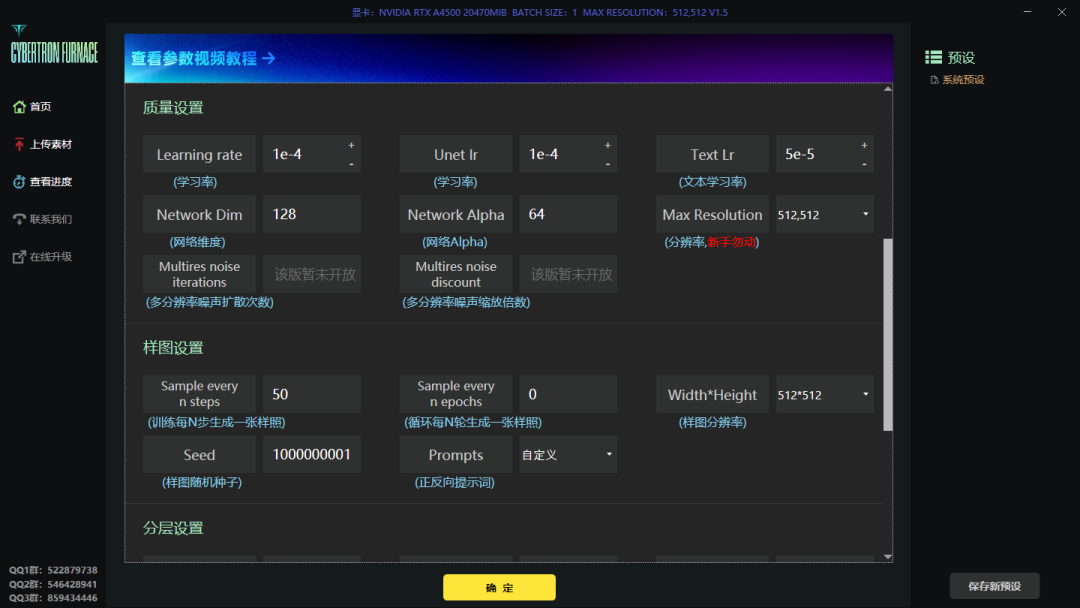
所设置的训练参数如上
其中我们所需要关注的参数有三个,分别是学习步数(Repeat)、循环次数(Epoth)和并行数量(Batch size)。
学习步数的含义就是AI在对所选训练集中每张图片,在每一轮训练过程中的学习次数。次数越高训练时间越长。
循环次数的含义就是让AI一共学习多少轮,循环的意思。循环次数越多,训练时间越长。
并行数量的含义就是AI一次性学习几张图片。并行数量越多对显存资源占用越大,学习时间越短。
那么为了控制变量,本次测试所有参数保持默认,学习步数为10,循环次数为20,只改变不同的并行数量来看三张显卡的资源占用与学习所耗时间。
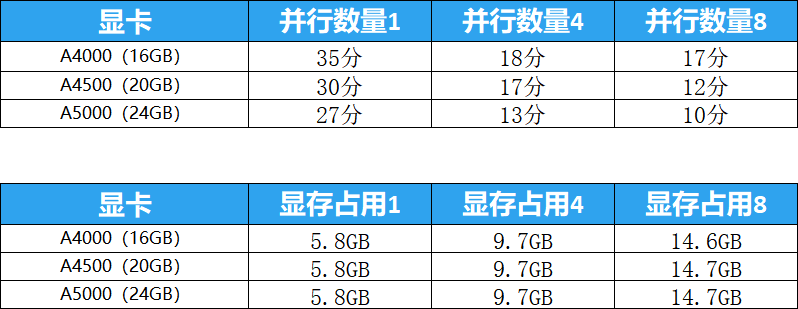
从测试的结果来看,对于SD1.5的Lora训练三张显卡都已满足需求,就算把并行数量拉到最大值8,显存的占用也在15GB左右,而三张显卡中显存最低的A4000,显存容量也有16GB。
小结
上次测试后就有很多人问我有没有适合AI出图的台式机推荐,也有人问关于训练Lora的电脑配置,那么今天第一个训练测试结束后想必大家已有答案。在其它配置一定的情况下,NVIDAI RTX™ A4000显卡的价格最具性价比,无论是出图还是训练Lora模型都是首选。
测试二:SD1.5Dreambooth模型训练
对于想玩模型训练的小伙伴来说,只能微调出图风格的Lora其实已经满足不了大家的需求,AI出图的核心还是要看大模型,那么对于大模型的训练,三张显卡又能有什么用的表现呢?

对于大模型的训练来说,市面上常见的丹炉就不够用了,我们需要借助其它的工具帮助我们辅助训练,我这里所选择的是Kohya's GUI。
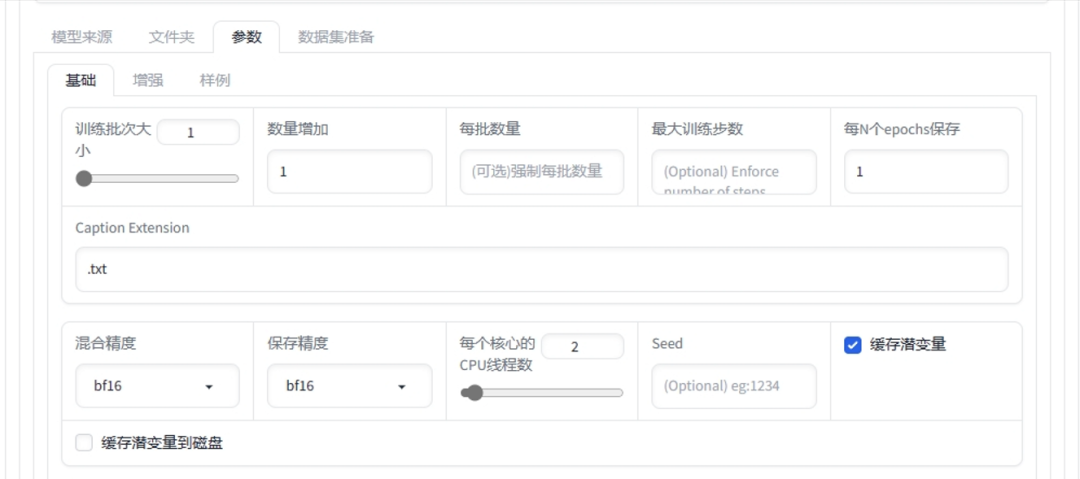
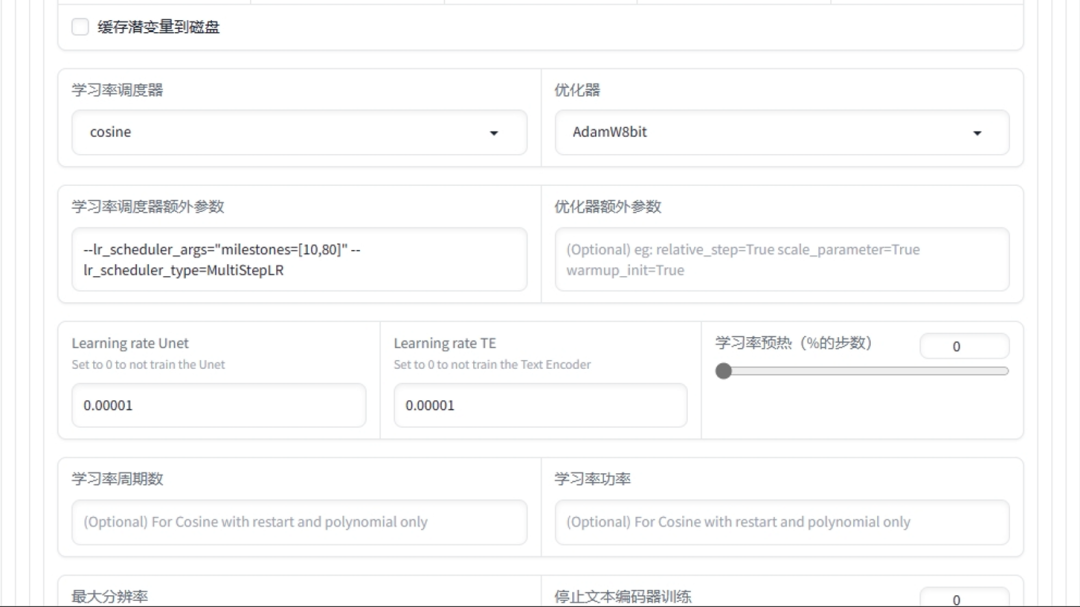
对于大模型的训练,其实参数和训练Lora是一样的,只不过大模型训练需要的训练集多一些,这里所采用的训练集图片数量为150张。
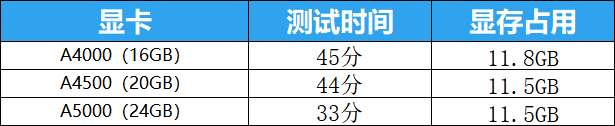
为了节约测试时间,我这里在训练大模型的时候,学习步数设置为40,循环次数设置为1,并行数量设置为1,从而展开测试。
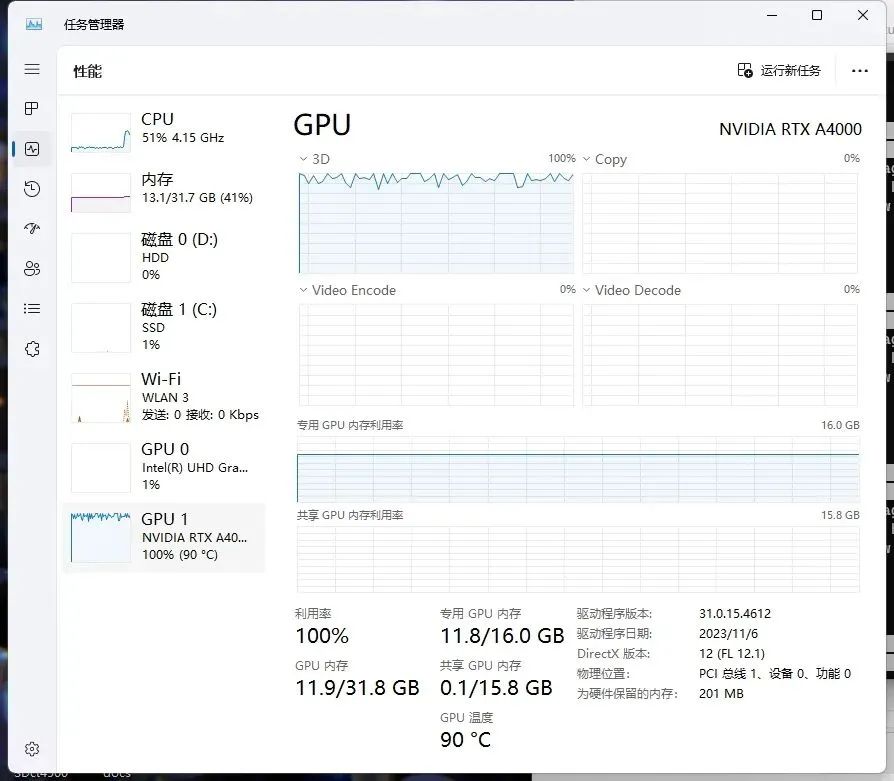
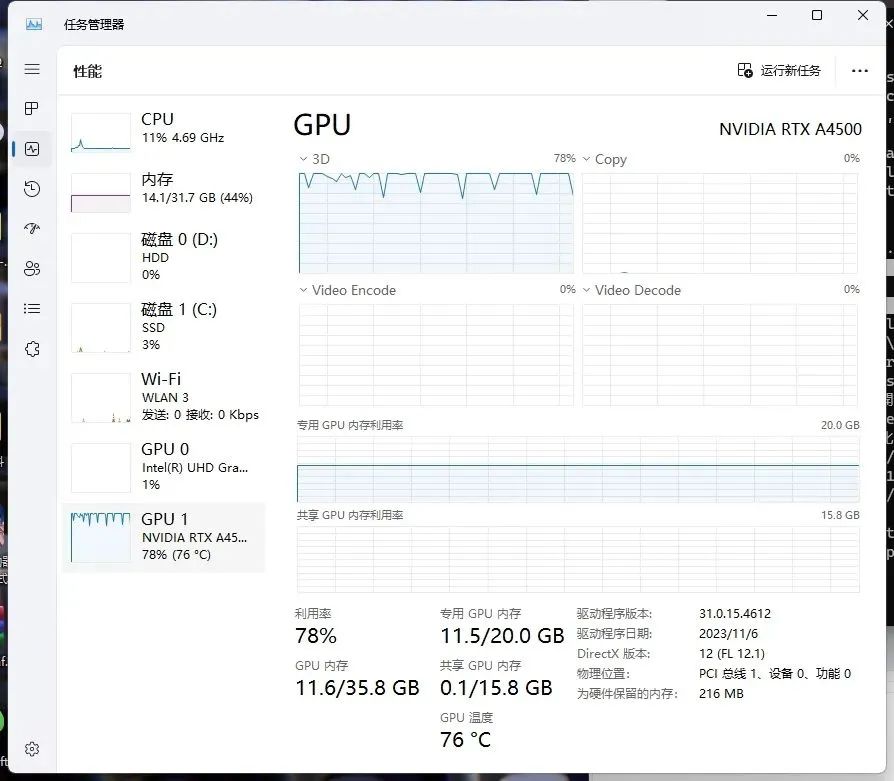
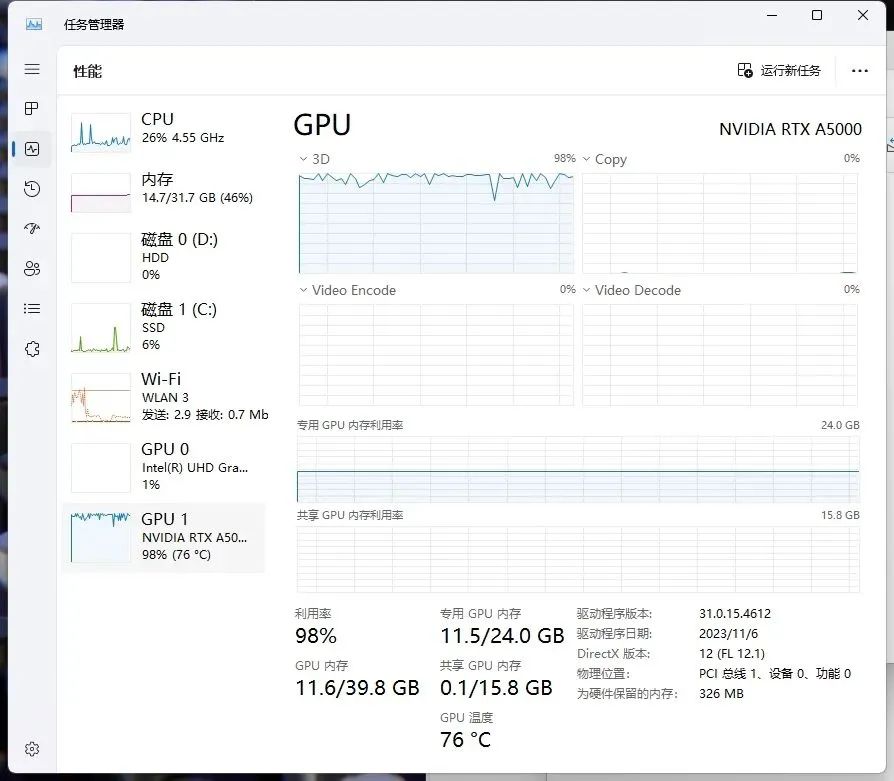
NVIDAI RTX™ A5000资源占用
对于大模型的训练,因为循环次数为1,并行数量也为1,从得到的测试结果中可以看出显存的占用要比训练Lora需求高一些,但是我们本期测评的三张显卡也都完美的承受住了,并且有富余,而且从速度上看起来,NVIDAI RTX™ A4000显卡和NVIDAI RTX™ A4500显卡的差距不大,只有NVIDAI RTX™ A5000显卡明显提速了。
小结
如果未来想针对大模型的训练,预算如果充足可以选择NVIDAI RTX™ A5000显卡进行训练,毕竟本次测试的SD1.5的大模型训练,我设置的循环和并行都为1,正常我们在训练模型的时候循环次数会略微地提高一些的,那么时间成本也是累加上去的。但如果预算不足,还是选择NVIDAI RTX™ A4000显卡更具性价比一些。
测试三:SDXL Lora微调模型训练
对于SD来说,前段时间刚推出的SDXL模型在生成效果上有巨大的提升,并且细节也更好了,详细的出图评测在上次测评中有提到,那么未来对于SDXL模型的相关训练也是大家所关注的,无论是训练的流程还是训练的配置要求亦或是时间。

如果想要训练SDXL的微调模型(Lora),要求我们的硬件显存必须在16GB以上,这里是最低要求,我推荐想要训练SDXL的微调模型显存最好是20GB以上。(后面会有测试结果说明为什么最好20GB)
如果想要训练SDXL的大模型(Dreambooth),要求我们的硬件显存必须在24GB以上,这里是最低要求,我推荐想要训练SDXL的大模型显存最好是48GB以上。(后面会有测试结果说明为什么最好48GB)
SDXL的Lora模型训练,我们使用到的训练平台仍然是Kohya's GUI,训练集图片数量为35张,学习次数统一为10,循环次数统一为20,并行数量为1,让三张卡分别进行训练,让我们来看一下测试结果吧。
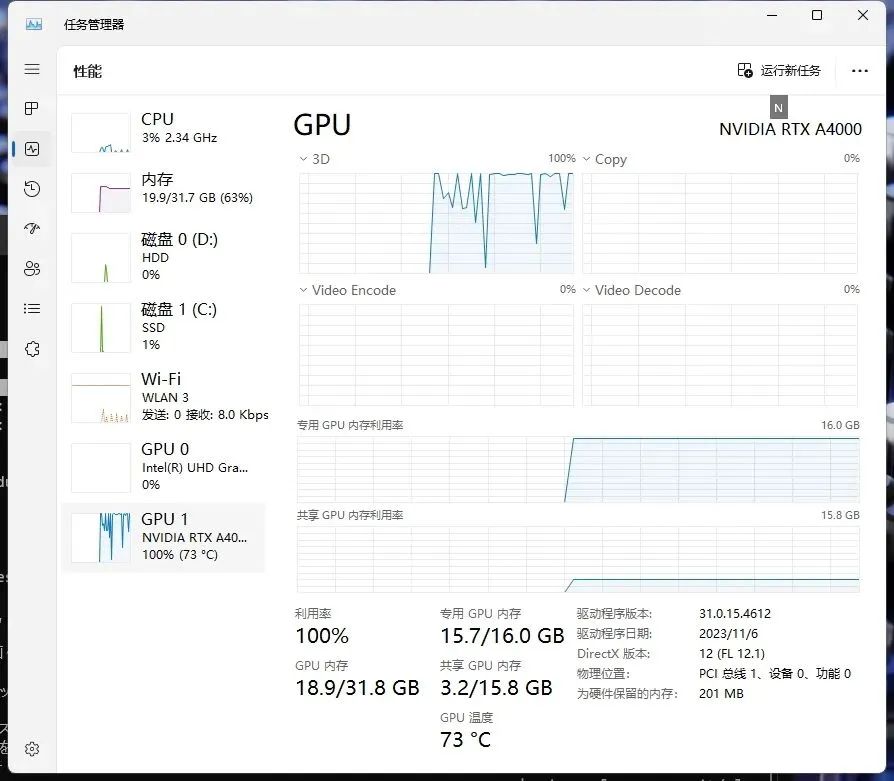
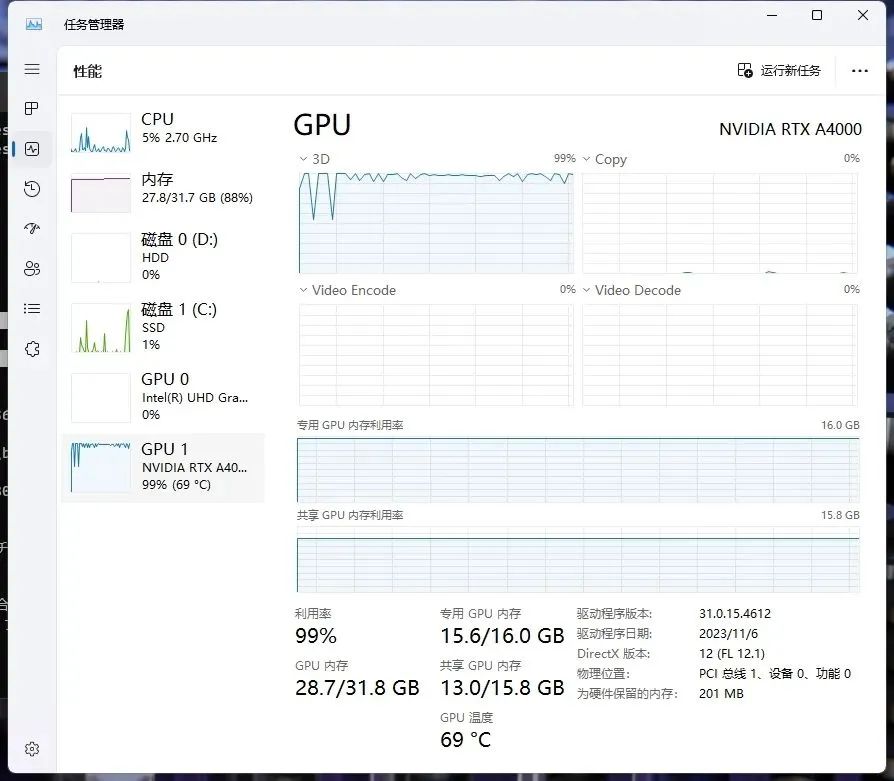
NVIDAI RTX™ A4000资源占用
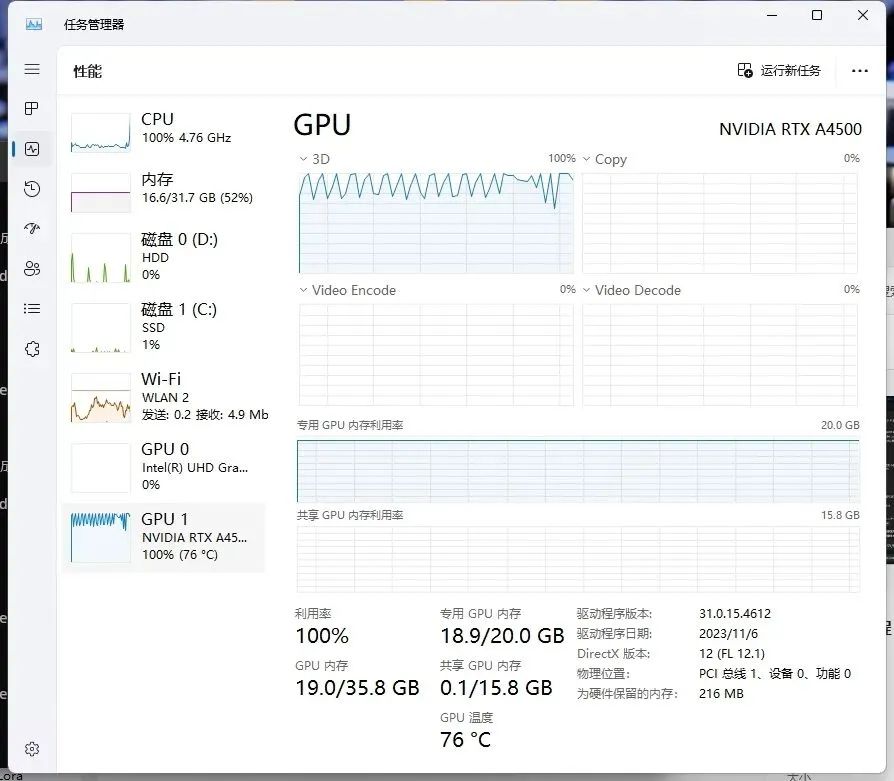
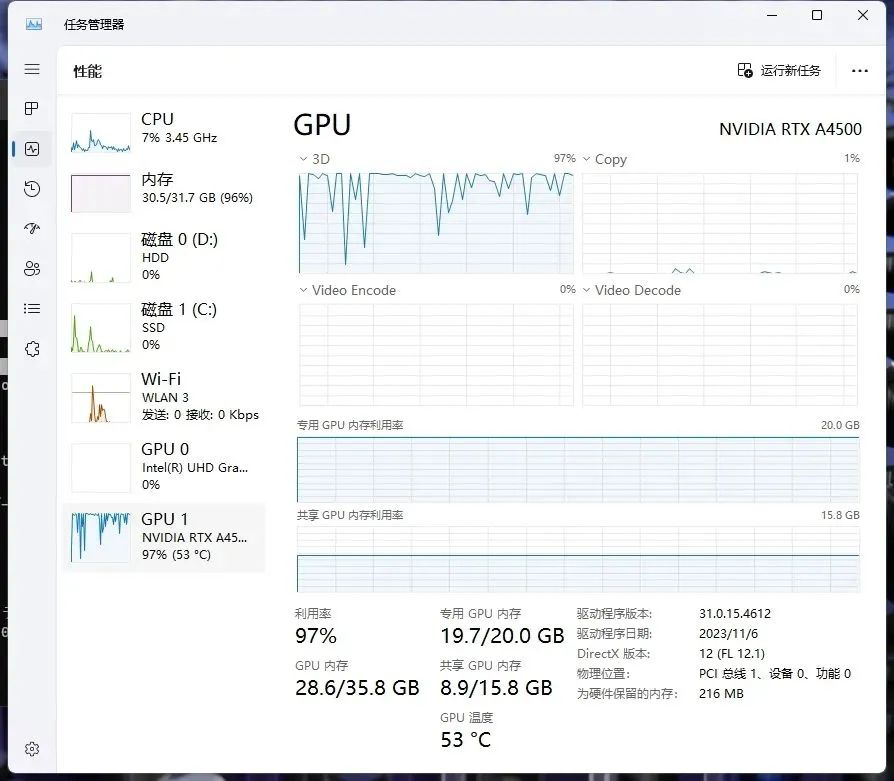
NVIDAI RTX™ A4500资源占用
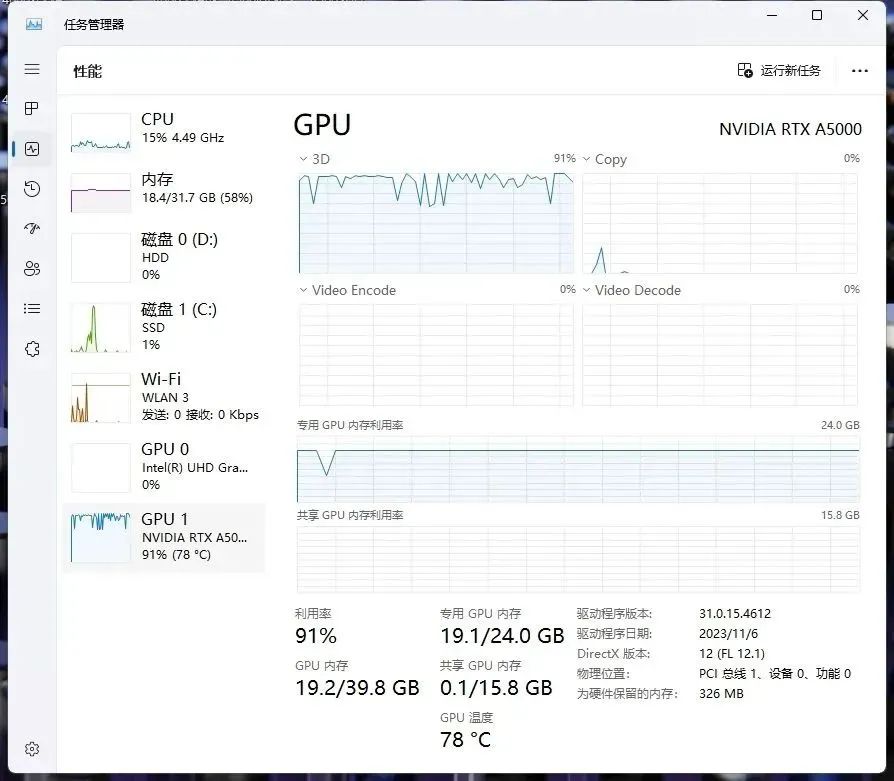
NVIDAI RTX™ A5000资源占用
对于SDXL的Lora模型训练,在文章的最开始我说个人推荐显存20GB,原因就在这里,因为NVIDAI RTX™ A4000显卡虽然能训练出SDXL的Lora模型,但是显存是有些溢出的,已经占用到共享GPU内存了,这对训练时间其实是有一定影响的,而NVIDAI RTX™ A4500的显存占用并没有溢出。
小结
总的来说三张卡都具备训练SDXL Lora模型的能力,只不过本次测试的NVIDAI RTX™ A4000显存有些许的溢出,所以如果想专注于训练SDXL的Lora模型,我推荐选择NVIDAI RTX™ A4500显卡。
测试四:SDXLDreambooth模型训练
在训练完SDXL的Lora模型后我们可以看到,其实Lora模型在并行数量为1的情况下,显存的占用已经达到19GB左右了,那么如果是想训练SDXL的大模型,我觉得24GB的显存也就是NVIDAI RTX™ A5000显卡显存搞不好都会溢出,所以为了测试的继续进行,我连夜海淘了一块显存为48GB的显卡进行测试!
SDXL大模型训练,我们使用到的训练平台仍然是Kohya's GUI,训练集图片数量为150张,学习次数统一为50,循环次数统一为1,并行数量为1,让三张卡分别进行训练,让我们来看一下测试结果吧。
NVIDAI RTX™ A4500资源占用
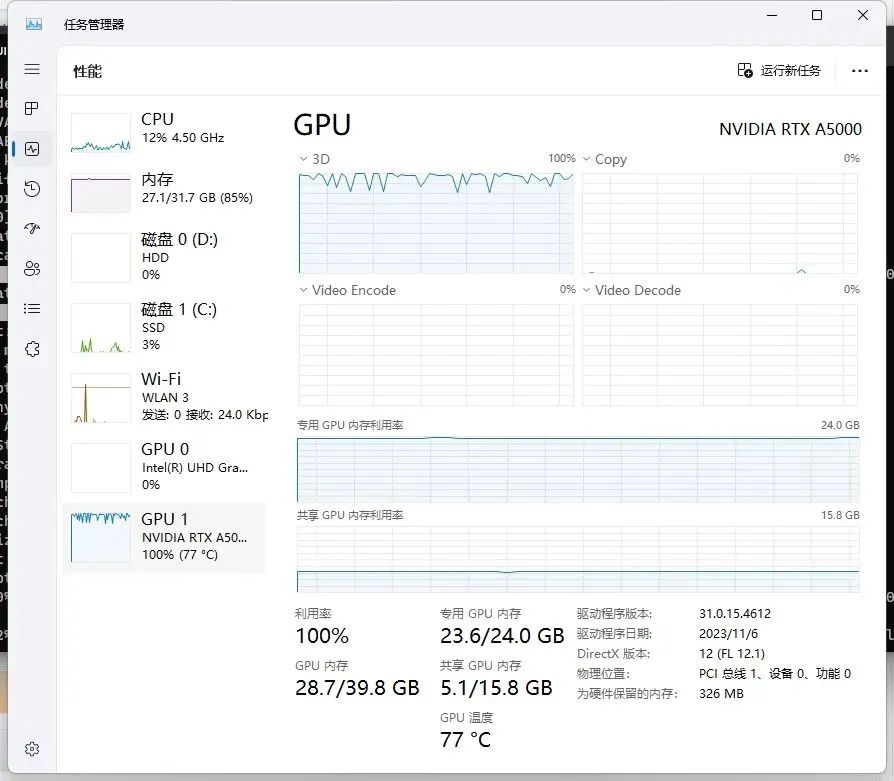
NVIDAI RTX™ A5000资源占用
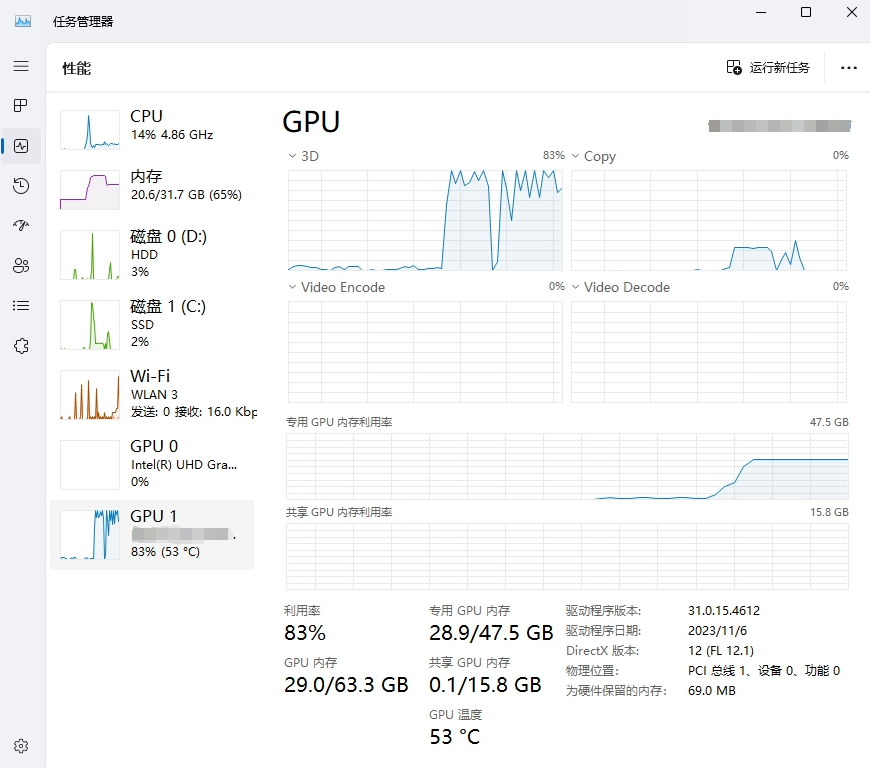
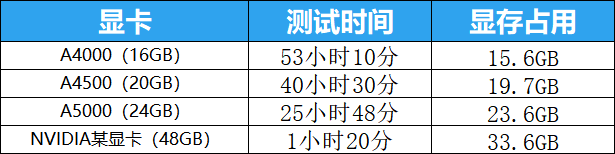
某显存48GB显卡资源占用
通过测试结果可以看出专业显卡即便在显存溢出的情况下也可以正常跑完整个训练过程,这个和之前测试移动工作站的时候就曾提到过,所以对于模型训练我优先推荐的还是专业显卡!
小结
本次测试中,NVIDAI RTX™ A4000、NVIDAI RTX™ A4500、NVIDAI RTX™ A5000在训练的过程中显卡本身的显存都溢出了,都使用到了共享GPU内存,通过某48GB的显卡资源占用来看,想正常训练SDXL大模型需要的显存应该是30GB起步,由于市面上30GB左右显存的显卡甚少,所以在测试的最开始我推荐如果想训练SDXL大模型,最好选择48GB显存的显卡。
如果预算有限,我推荐选择NVIDAI RTX™ A5000显卡,毕竟训练时间能快一点,要知道在实际模型训练中循环次数不会给到1,那么训练时间就是叠加的,对于大模型训练来说时间成本也在我们考虑范围当中。
对于NVIDAI RTX™ A4000以及NVIDAI RTX™ A4500这两款显卡,如果是主训练SDXL大模型,显然有些不够用,除非你能接受那庞大的训练时间。
04 测试汇总与购买建议
经过多方面的测试,对于全新戴尔Precision 3660塔式工作站的表现我还是非常满意的。无论是搭配NVIDIA RTX™ A4000显卡还是NVIDAI RTX™ A4500显卡或者是NVIDAI RTX™ A5000显卡,对于SD生图以及模型训练都没有出现任何崩溃现象,虽然有个别情况时间被拉长许多,但它没有崩溃哦!划重点。

那么关于全新戴尔Precision 3660塔式工作站的选配问题在这要多唠叨几句。如果我们在日常使用当中以Stable diffusion出图较多,我个人推荐选配在购买全新戴尔Precision 3660塔式工作站的时候搭配NVIDIA RTX™ A4000显卡。无论是SD1.5的生图还是SDXL的生图,NVIDAI RTX™ A4000显卡可以完全胜任,并且速度很快。那么这套组合搭配的价格在17000元左右。

那么如果我们在日常使用当中对训练有所需求,打个比方,我们经常训练Lora模型,无论是基于SD1.5版本的Lora还是SDXL的Lora通过测试结果我们能看出全新戴尔Precision 3660塔式工作站搭配NVIDIA RTX™ A4500显卡的效果会更好一些,甚至偶尔训练几个Dreambooth模型都是可以胜任的。这套组合搭配的价格在21000元左右。

最后一种情况就是我们在日常使用当中对训练Dreambooth模型的需求比较多,那么我推荐的搭配组合方案是全新戴尔Precision 3660塔式工作站搭配NVIDIA RTX™ A5000显卡,这套组合搭配的价格在30000元左右。好了,以上就是本期测评的全部内容了

