
热门标签
热门文章
- 1基于深度学习的音乐合成算法实例
- 2C++文件依存关系_people(const std::string &n) : name(n) {}
- 3python报错:’module’object is not callable_module' object is not callable datetime
- 4深度学习与大数据分析: 数据挖掘与知识发现_深度学习数据挖掘项目
- 5Go 延迟调用机制
- 6unity Hub怎么知道人家源工程版本?_unity导入时候怎么看版本
- 7Mac 苹果笔记本 自动化测试Selenium遇到报错:This version of ChromeDriver only supports Chrome version
- 8OLP光路保护,主备路由切换业务不终断_olp保护场景
- 97 款顶级开源 BI(商务智能)软件和报表工具_bi报表设计器 免费版开源
- 10C/C++面试基础知识
当前位置: article > 正文
机器学习:基于python微博舆情分析系统+可视化+Django框架 K-means聚类算法(源码)✅_基于python的微博舆情分析监控与预测
作者:盐析白兔 | 2024-05-30 18:04:26
赞
踩
基于python的微博舆情分析监控与预测
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌感兴趣的可以先收藏起来,点赞、关注不迷路✌
毕业设计:2023-2024年计算机毕业设计1000套(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕业设计选题汇总
1、项目介绍
技术栈:
Python语言+Django框架+数据库+jieba分词+ scikit_learn机器学习(K-means聚类算法)+情感分析 snownlp
2、项目界面
(1)微博舆情分析
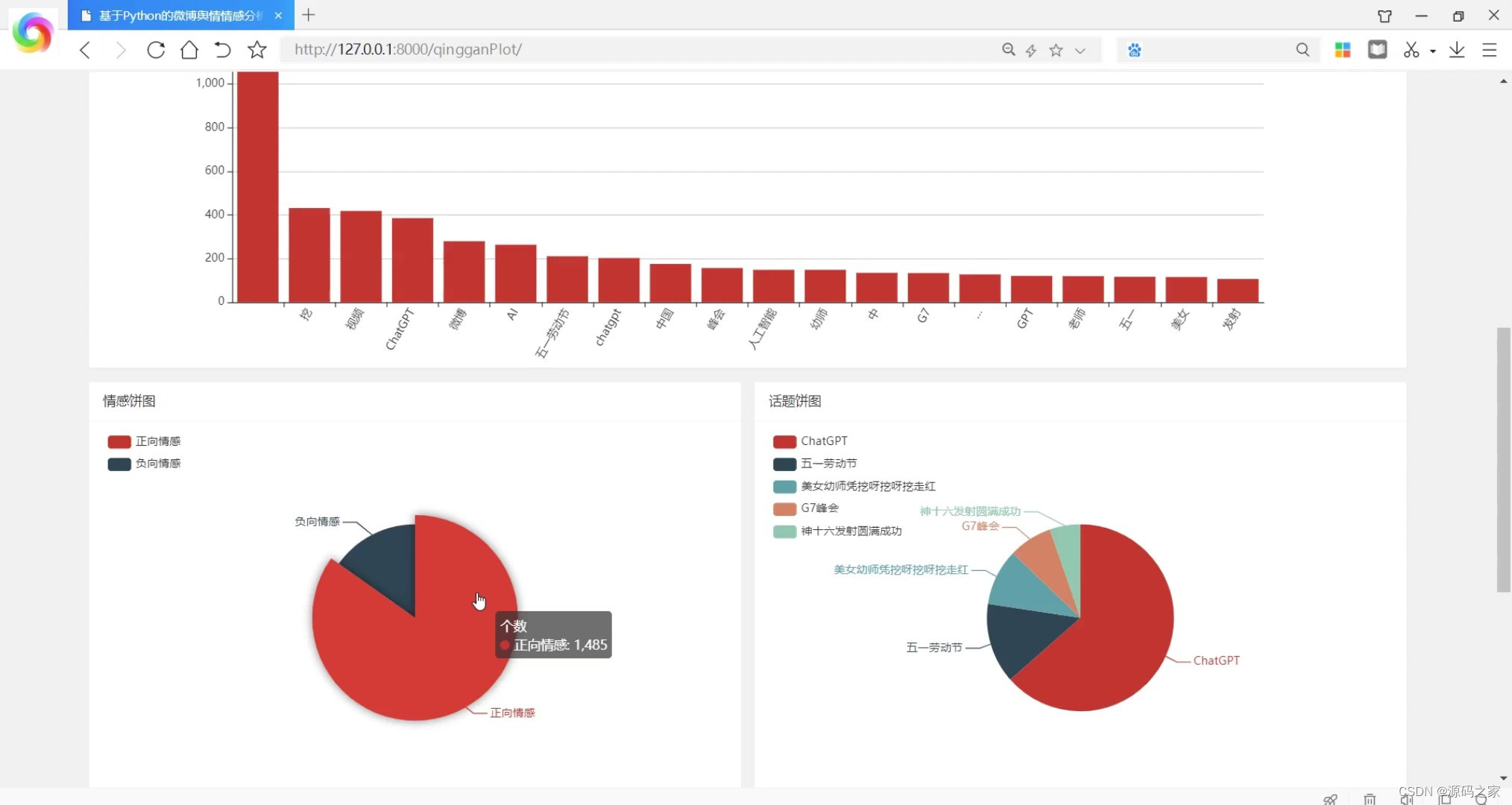
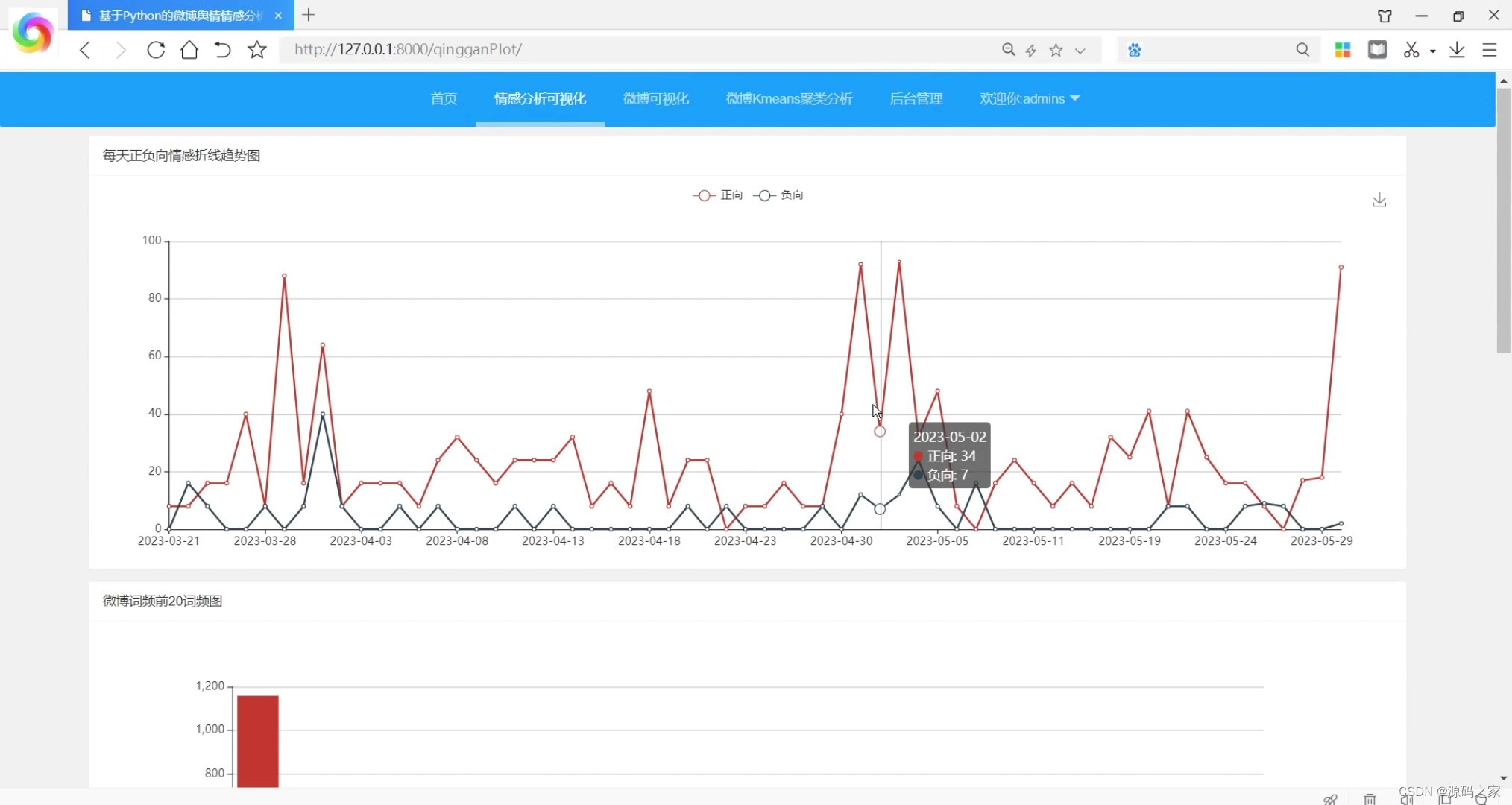
(2)情感分析可视化
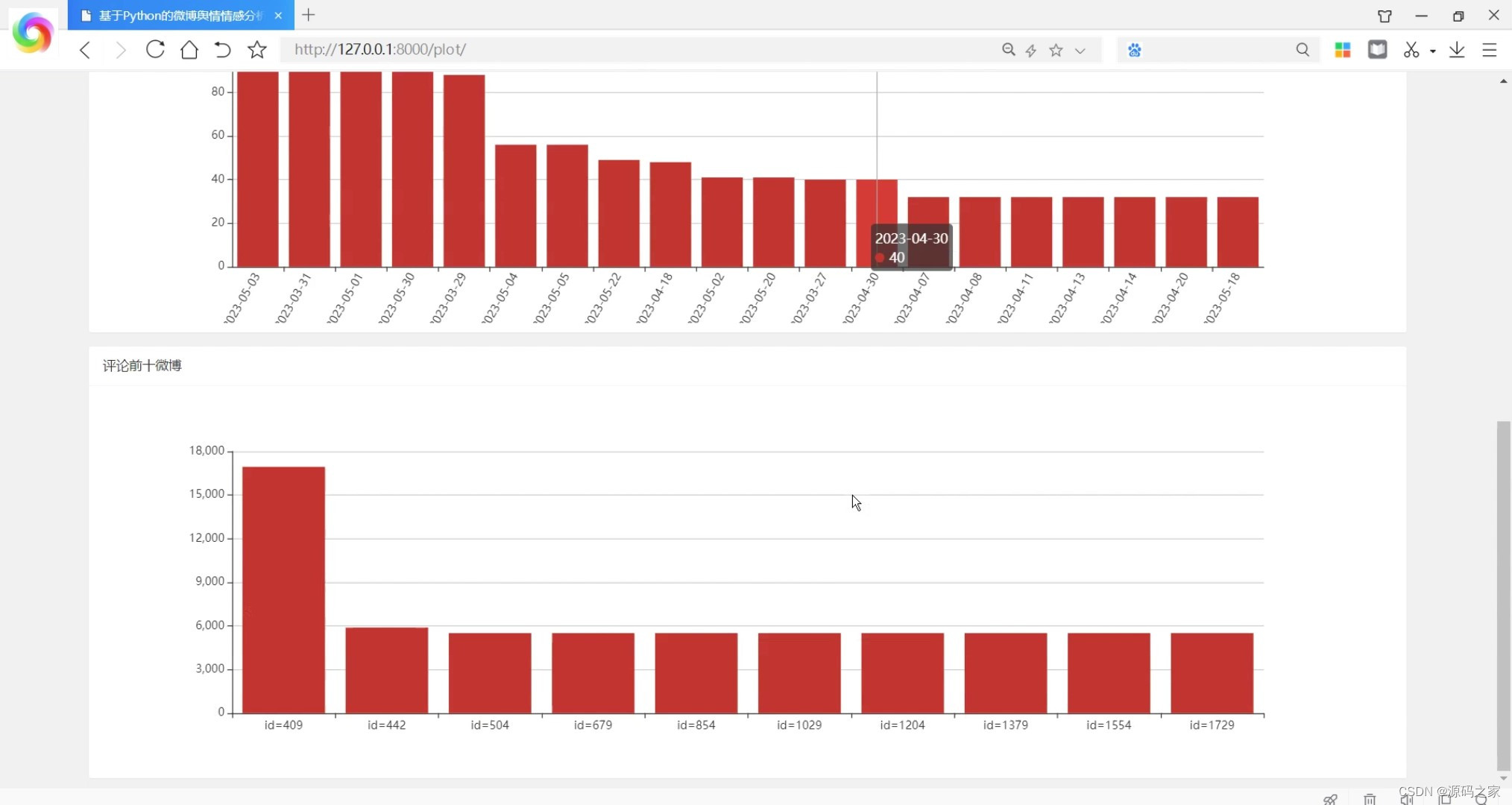
(3)微博数据浏览

(4)评论前十
(5)K-Means聚类分析

(6)K-Means聚类词云图

(7)后台数据管理

(8)注册登录界面
3、项目说明
1、所用技术
Python语言+Django框架+数据库+jieba分词+
scikit_learn机器学习(K-means聚类算法)+情感分析 snownlp
2、SnowNLP是一个常用的Python文本分析库,是受到TextBlob启发而发明的。由于当前自然语言处理库基本都是针对英文的,而中文没有空格分割特征词,Python做中文文本挖掘较难,后续开发了一些针对中文处理的库,例如SnowNLP、Jieba、BosonNLP等。注意SnowNLP处理的是unicode编码,所以使用时请自行decode成unicode。
4、核心代码
###首页 @check_login def index(request): # 话题列表 topic_raw = [item.topic for item in WeiBo.objects.all() if item.topic] topic_list = [] for item in topic_raw: topic_list.extend(item.split(',')) topic_list = list(set(topic_list)) # yon用户信息 uid = int(request.COOKIES.get('uid', -1)) if uid != -1: username = User.objects.filter(id=uid)[0].name # 得到话题 if 'key' not in request.GET: key = topic_list[0] raw_data = WeiBo.objects.all() else: key= request.GET.get('key') raw_data = WeiBo.objects.filter(topic__contains=key) # 分页 if 'page' not in request.GET: page = 1 else: page = int(request.GET.get('page')) data_list = raw_data[(page-1)*20 : page*20 ] return render(request, 'index.html', locals()) # 情感分类 def fenlei(request): from snownlp import SnowNLP # j = '我喜欢你' # s = SnowNLP(j) # print(s.sentiments) for item in tqdm(WeiBo.objects.all()): emotion = '正向' if SnowNLP(item.content).sentiments >0.45 else '负向' WeiBo.objects.filter(id=item.id).update(emotion=emotion) return JsonResponse({'status':1,'msg':'操作成功'} ) # 登录 def login(request): if request.method == "POST": tel, pwd = request.POST.get('tel'), request.POST.get('pwd') if User.objects.filter(tel=tel, password=pwd): obj = redirect('/') obj.set_cookie('uid', User.objects.filter(tel=tel, password=pwd)[0].id, max_age=60 * 60 * 24) return obj else: msg = "用户信息错误,请重新输入!!" return render(request, 'login.html', locals()) else: return render(request, 'login.html', locals()) # 注册 def register(request): if request.method == "POST": name, tel, pwd = request.POST.get('name'), request.POST.get('tel'), request.POST.get('pwd') print(name, tel, pwd) if User.objects.filter(tel=tel): msg = "你已经有账号了,请登录" else: User.objects.create(name=name, tel=tel, password=pwd) msg = "注册成功,请登录!" return render(request, 'login.html', locals()) else: msg = "" return render(request, 'register.html', locals()) # 注销 def logout(request): obj = redirect('index') obj.delete_cookie('uid') return obj # 微博可视化 @check_login def plot(request): """ 折线图 每月发表数 柱状图 每日发表微博前20 饼图 正负向 柱状图 评论前十 """ uid = int(request.COOKIES.get('uid', -1)) if uid != -1: username = User.objects.filter(id=uid)[0].name #1 折线图 每天发布微博折线图 raw_data = WeiBo.objects.all() main1 = [item.time.strftime('%Y-%m-%d') for item in raw_data] main1_x = sorted(list(set(main1))) main1_y = [main1.count(item) for item in main1_x] #2 柱状图 发表微博前20 日期 raw_data = WeiBo.objects.all() main2 = [item.time.strftime('%Y-%m-%d') for item in raw_data] main2set = sorted(list(set(main2))) main2_x = {item:main2.count(item) for item in main2set} main2 = sorted(main2_x.items(),key=lambda x:x[1],reverse=True)[:20] print(main2) main2_x = [item[0] for item in main2] main2_y = [item[1] for item in main2] #3饼图 main3 = [item.emotion+'情感' for item in raw_data] main3_y = {} for item in main3: main3_y[item] = main3_y.get(item,0) + 1 main3 = [{ 'value':v, 'name':k } for k,v in main3_y.items() ] #4柱状图 raw_data = raw_data.order_by('-pinglun')[:10] main4_x = [f'id={itme.id}' for itme in raw_data] main4_y = [itme.pinglun for itme in raw_data] return render(request,'plot.html',locals()) ####情感分类可视化 @check_login def qingganPlot(request): """ 折线图 每月发表数 柱状图 每日发表微博前20 饼图 正负向 柱状图 评论前十 """ uid = int(request.COOKIES.get('uid', -1)) if uid != -1: username = User.objects.filter(id=uid)[0].name #1 折线图 每天发布微博折线图 raw_data = WeiBo.objects.all() main1 = [item.time.strftime('%Y-%m-%d') for item in raw_data] main1_x = sorted(list(set(main1))) main1_y1 = [] for item in main1_x: year = int(item.split('-')[0]) month = int(item.split('-')[1]) day = int(item.split('-')[2]) main1_y1.append(raw_data.filter(emotion='正向',time__year=year,time__month=month,time__day=day).count()) main1_y2 = [] for item in main1_x: year = int(item.split('-')[0]) month = int(item.split('-')[1]) day = int(item.split('-')[2]) main1_y2.append(raw_data.filter(emotion='负向', time__year=year, time__month=month, time__day=day).count()) main1_data = ['正向','负向'] main1_y = [ { 'name': '正向', 'type': 'line', 'data': main1_y1 }, { 'name': '负向', 'type': 'line', 'data': main1_y2 }, ] #2 柱状图 发表微博前20riqi 日期 stop = [item.strip() for item in open(os.path.join('stopwords','hit_stopwords.txt') , 'r',encoding='UTF-8').readlines()] stop.extend([item.strip() for item in open(os.path.join('stopwords','scu_stopwords.txt' ), 'r',encoding='UTF-8').readlines()]) stop.extend([item.strip() for item in open(os.path.join('stopwords','baidu_stopwords.txt'), 'r',encoding='UTF-8').readlines()]) stop.extend([item.strip() for item in open(os.path.join('stopwords','cn_stopwords.txt' ), 'r',encoding='UTF-8').readlines()]) main5_data = WeiBo.objects.filter(emotion='正向')[:1000] main5_json = {} for item in main5_data: text1 = list(jieba.cut(item.content.replace('#','').replace('O','').replace('L','').replace('.',''))) for t in text1: if t in stop or t.strip() == '': continue if t not in main5_json.keys(): main5_json[t] = 1 else: main5_json[t] += 1 result_dict = sorted(main5_json.items(), key=lambda x: x[1], reverse=True)[:20] # 最大到最小 main2_x = [item[0] for item in result_dict] main2_y = [item[1] for item in result_dict] #3饼图 main3 = [item.emotion+'情感' for item in raw_data] main3_y = {} for item in main3: main3_y[item] = main3_y.get(item,0) + 1 main3 = [{ 'value':v, 'name':k } for k,v in main3_y.items() ] ## 5 stop = [item.strip() for item in open(os.path.join('stopwords', 'hit_stopwords.txt'), 'r',encoding='UTF-8').readlines()] stop.extend([item.strip() for item in open(os.path.join('stopwords', 'scu_stopwords.txt'), 'r',encoding='UTF-8').readlines()]) stop.extend([item.strip() for item in open(os.path.join('stopwords', 'baidu_stopwords.txt'), 'r',encoding='UTF-8').readlines()]) stop.extend([item.strip() for item in open(os.path.join('stopwords', 'cn_stopwords.txt'), 'r',encoding='UTF-8').readlines()]) main5_data = WeiBo.objects.filter(emotion='正向')[:1000] main5_json = {} for item in main5_data: text1 = list(jieba.cut(item.content)) for t in text1: if t in stop or t.strip() == '': continue if t not in main5_json.keys(): main5_json[t] = 1 else: main5_json[t] += 1 result_dict = sorted(main5_json.items(), key=lambda x: x[1], reverse=True)[:30] # 最大到最小 # print(result_dict) main5_data = [{ "name": item[0], "value": item[1] } for item in result_dict] # 6 main6_data = WeiBo.objects.filter(emotion='负向')[:1000] main6_json = {} for item in main6_data: text1 = list(jieba.cut(item.content)) for t in text1: if t in stop or t.strip() == '': continue if t not in main6_json.keys(): main6_json[t] = 1 else: main6_json[t] += 1 result_dict = sorted(main6_json.items(), key=lambda x: x[1], reverse=True)[:30] # 最大到最小 # print(result_dict) main6_data = [{ "name": item[0], "value": item[1] } for item in result_dict] ########7话题词云图 topic_raw = [item.topic for item in WeiBo.objects.all() if item.topic] topic_list = [] for item in topic_raw: topic_list.extend(item.split(',')) topic_set = list(set(topic_list)) main7_data = [{ "name": item, "value": topic_list.count(item) } for item in topic_set] main7_data = sorted(main7_data,key=lambda x:x['value'],reverse=True)[:10] return render(request,'qingganPlot.html',locals()) # 个人中心 @check_login def my(request): uid = int(request.COOKIES.get('uid', -1)) if uid != -1: username = User.objects.filter(id=uid)[0].name if request.method == "POST": name,tel,password = request.POST.get('name'),request.POST.get('tel'),request.POST.get('password1') User.objects.filter(id=uid).update(name=name,tel=tel,password=password) return redirect('/') else: my_info = User.objects.filter(id=uid)[0] return render(request,'my.html',locals()) # 清洗文本 def clearTxt(line:str): if(line != ''): line = line.strip() # 去除文本中的英文和数字 line = re.sub("[a-zA-Z0-9]", "", line) # 去除文本中的中文符号和英文符号 line = re.sub("[\s+\.\!\/_,$%^*(+\"\';:“”.]+|[+——!,。??、~@#¥%……&*()]+", "", line) return line return None #文本切割 def sent2word(line): segList = jieba.cut(line,cut_all=False) segSentence = '' for word in segList: if word != '\t': segSentence += word + " " return segSentence.strip() def kmeansPlot(request): uid = int(request.COOKIES.get('uid', -1)) if uid != -1: username = User.objects.filter(id=uid)[0].name # 聚类个数 if 'num' in request.GET: num = int(request.GET.get('num')) else: num = 2 ### 训练 # 清洗文本 clean_data = [item.content for item in WeiBo.objects.all()] clean_data = [clearTxt(item) for item in clean_data] clean_data = [sent2word(item) for item in clean_data] # 该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频 vectorizer = CountVectorizer(max_features=20000) # 该类会统计每个词语的tf-idf权值 tf_idf_transformer = TfidfTransformer() # 将文本转为词频矩阵并计算tf-idf tfidf = tf_idf_transformer.fit_transform(vectorizer.fit_transform(clean_data)) # 获取词袋模型中的所有词语 tfidf_matrix = tfidf.toarray() # 获取词袋模型中的所有词语 word = vectorizer.get_feature_names() # 聚成5类 from sklearn.cluster import KMeans clf = KMeans(n_clusters=num) result_list = clf.fit(tfidf_matrix) result_list = list(clf.predict(tfidf_matrix)) #####k可视化处理 ## 1 饼图 """{ value: 735, name: 'Direct' } """ pie_data = [ { 'value': result_list.count(i), 'name': f'第{i+1}类' } for i in range(num) ] print(pie_data) div_id_list = [f'container{i+1}' for i in range(num)] data_list = [] for label,name in enumerate(div_id_list): tmp = {'id':name,'data':[],'title':f'第{label+1}类'} # 汇总 tmp_text_list = '' for la,text in zip(result_list,clean_data): if la == label: tmp_text_list += ' ' + text tmp_text_list = [item for item in tmp_text_list.split(' ') if item.strip() != ' '] # 得到前30 rank_Data = [ { 'value': tmp_text_list.count(item), 'name': item } for item in set(tmp_text_list) ] rank_Data = sorted(rank_Data,key=lambda x: x['value'],reverse=True)[:100] tmp['data'] = rank_Data data_list.append(tmp) return render(request, 'kmeansPlot.html', locals())

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

