
- 1Git入门-远程仓库GitHub_git是本地库吗,github是远程库吗
- 2【数模比赛】2023美国大学生数学建模比赛(思路、代码......)_数学建模比赛会运行代码吗
- 3Github 2024-05-18 开源项目日报 Top10
- 4统计各位数字之和是5的数_各位数字之和为5的数python
- 5MySQL分区Partition_mysql partition
- 6选择、冒泡、插入排序、二分法、异或应用_冒泡排序与选择排序的时间复杂度与数组的初始状态无关
- 7LitCTF2023 郑州轻工业大学首届网络安全赛 WP 部分_[litctf 2023]vim yyds
- 82. Python--pandas库_pandas python 字典
- 9人工智能相关的比赛_人工智能比赛项目
- 10GitHub优秀开源项目收集
AI大模型应用入门实战与进阶:构建你的第一个大模型:实战指南_ai大模型 实战
赞
踩
2017年是机器学习领域历史性的一年。Google Brain 团队的研究人员推出了 Transformer,它的性能迅速超越了大多数现有的深度学习方法。著名的注意力机制成为未来 Transformer 衍生模型的关键组成部分。Transformer 架构的惊人之处在于其巨大的灵活性:它可以有效地用于各种机器学习任务类型,包括 NLP、图像和视频处理问题。
在过去的几年里,人工智能(AI)领域取得了显著的进展,特别是在大型模型的应用方面。这些大型模型,如OpenAI的GPT-3和谷歌的BERT,已经在各种任务中展示了令人瞩目的性能。本文将为您提供一个关于AI大模型的实战指南,从背景介绍到核心概念、算法原理、具体实践、应用场景、工具和资源推荐,以及未来发展趋势和挑战。我们还将在附录中提供一些常见问题与解答,帮助您更好地理解和应用这些大型模型。
1. 背景介绍
1.1 什么是AI大模型?
AI大模型是指具有大量参数和复杂结构的人工智能模型。这些模型通常需要大量的计算资源和数据来进行训练,以实现高性能的预测和生成能力。近年来,随着计算能力的提高和数据量的增加,AI大模型在各种任务中取得了显著的成果,如自然语言处理、计算机视觉和强化学习等。
1.2 AI大模型的发展历程
AI大模型的发展可以追溯到20世纪80年代,当时研究人员开始尝试使用神经网络进行模式识别。随着计算能力的提高和数据量的增加,神经网络逐渐演变成了深度学习模型,如卷积神经网络(CNN)和循环神经网络(RNN)。近年来,随着Transformer架构的提出,AI大模型在自然语言处理等领域取得了突破性的进展。
2. 核心概念与联系
2.1 深度学习与神经网络
深度学习是一种基于神经网络的机器学习方法,通过模拟人脑神经元的连接和计算方式,实现对复杂数据的建模和预测。神经网络由多个层组成,每个层包含若干个神经元。神经元之间通过权重连接,权重在训练过程中不断更新以优化模型性能。
2.2 Transformer架构
Transformer是一种基于自注意力机制的深度学习架构,用于处理序列数据。与传统的RNN和CNN不同,Transformer可以并行处理序列中的所有元素,从而大大提高了计算效率。此外,Transformer还引入了位置编码和多头自注意力等技术,以实现对长距离依赖关系的建模。
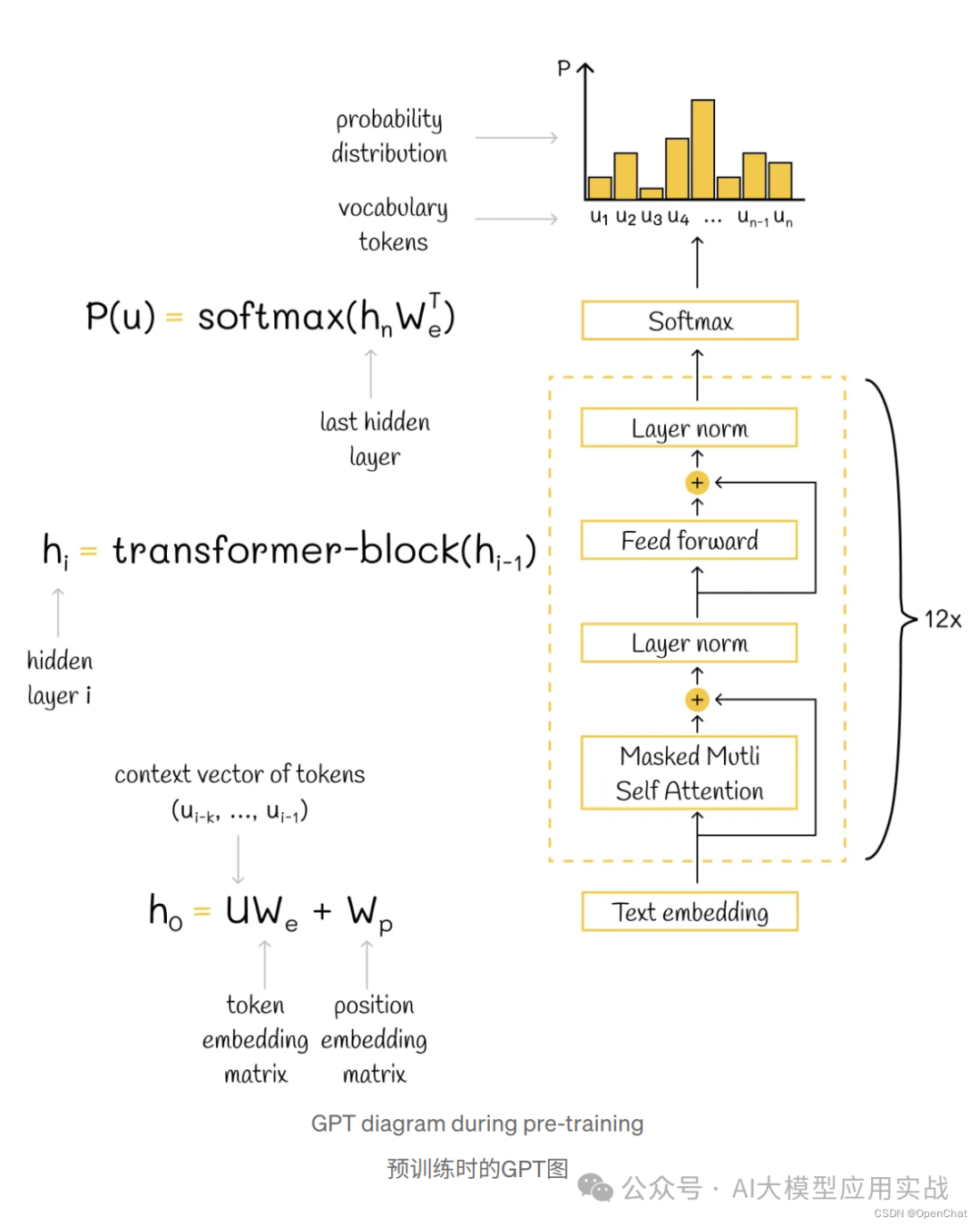
原始的 Transformer 可以分解为两部分,称为编码器和解码器。顾名思义,编码器的目标是以数字向量的形式对输入序列进行编码——这是一种机器可以理解的低级格式。另一方面,解码器获取编码序列并通过应用语言建模任务来生成新序列。
编码器和解码器可以单独用于特定任务。从原始 Transformer 派生出的两个最著名的模型分别是由编码器块组成的 BERT(Transformer 双向编码器表示)和由解码器块组成的 GPT(生成预训练变压器)。

2.3 预训练与微调
对于大多数LLMs来说,GPT的框架由两个阶段组成:预训练和微调。预训练是指在大量无标签数据上训练模型,以学习通用的表示和知识。
微调是指在特定任务的有标签数据上对预训练模型进行调整,以适应该任务的需求。
预训练和微调的过程使得AI大模型能够在各种任务中实现高性能。
让我们研究一下它们是如何组织的。

The parameter k is called the context window size.
参数k称为上下文窗口大小。
The mentioned loss function is also known as log-likelihood.
提到的损失函数也称为对数似然。
https://medium.com/towards-data-science/large-language-models-gpt-1-generative-pre-trained-transformer-7b895f296d3b
Encoder models (e.g. BERT) predict tokens based on the context from both sides while decoder models (e.g. GPT) only use the previous context, otherwise they would not be able to learn to generate text.
编码器模型(例如 BERT)根据双方的上下文来预测标记,而解码器模型(例如 GPT)仅使用先前的上下文,否则它们将无法学习生成文本。
3. 核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 自注意力机制

3.2 位置编码
由于Transformer架构没有明确的顺序结构,因此需要引入位置编码来表示序列中元素的位置信息。位置编码是一个与输入序列相同维度的矩阵,可以通过正弦和余弦函数计算得到:

3.3 多头自注意力与前馈神经网络
多头自注意力是通过将自注意力机制应用于多个不同的表示空间,以捕捉不同的依赖关系。多头自注意力的输出通过线性变换和残差连接后,输入到前馈神经网络中。前馈神经网络由两个线性层和一个激活函数组成,用于进一步提取特征。
4. 具体最佳实践:代码实例和详细解释说明
在本节中,我们将使用Hugging Face的Transformers库来构建一个基于BERT的文本分类模型。首先,安装Transformers库:
`pip install transformers `
* 1
- 1
- 2
- 3
- 4
- 5
- 6
接下来,导入所需的库和模块:
`import torch from transformers import BertTokenizer, BertForSequenceClassification from torch.optim import Adam from torch.utils.data import DataLoader, TensorDataset `
* 1
* 2
* 3
* 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
然后,加载预训练的BERT模型和分词器:
`tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2) `
* 1
* 2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
接下来,准备数据集。这里我们使用一个简单的二分类任务作为示例:
`texts = ['This is a positive example.', 'This is a negative example.'] labels = [1, 0] inputs = tokenizer(texts, return_tensors='pt', padding=True, truncation=True) dataset = TensorDataset(inputs['input_ids'], inputs['attention_mask'], torch.tensor(labels)) dataloader = DataLoader(dataset, batch_size=2) ` * 1 * 2 * 3 * 4 * 5 * 6

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
现在,我们可以开始训练模型:
`optimizer = Adam(model.parameters(), lr=1e-5) for epoch in range(3): for batch in dataloader: input_ids, attention_mask, labels = batch outputs = model(input_ids, attention_mask=attention_mask, labels=labels) loss = outputs.loss loss.backward() optimizer.step() optimizer.zero_grad() ` * 1 * 2 * 3 * 4 * 5 * 6 * 7 * 8 * 9 * 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
最后,我们可以使用训练好的模型进行预测:
`test_text = 'This is a test example.' test_input = tokenizer(test_text, return_tensors='pt', padding=True, truncation=True) test_output = model(**test_input) prediction = torch.argmax(test_output.logits, dim=1).item() print('Prediction:', prediction) `
* 1
* 2
* 3
* 4
* 5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5. 实际应用场景
AI大模型在许多实际应用场景中都取得了显著的成果,例如:
-
自然语言处理:文本分类、情感分析、命名实体识别、问答系统等。
-
计算机视觉:图像分类、目标检测、语义分割、生成对抗网络等。
-
强化学习:游戏智能、机器人控制、推荐系统等。
6. 工具和资源推荐
-
Hugging Face Transformers:一个提供预训练模型和相关工具的开源库,支持多种深度学习框架。
-
TensorFlow:一个用于机器学习和深度学习的开源库,提供了丰富的模型和工具。
-
PyTorch:一个用于机器学习和深度学习的开源库,提供了灵活的动态计算图和易用的API。
7. 总结:未来发展趋势与挑战
AI大模型在近年来取得了显著的进展,但仍面临许多挑战和发展趋势,例如:
-
模型压缩与加速:随着模型规模的增加,计算资源和存储需求也在不断增加。未来的研究需要关注如何压缩和加速大模型,以适应更多的应用场景。
-
数据效率与迁移学习:当前的大模型通常需要大量的数据和计算资源进行训练。未来的研究需要关注如何提高数据效率和迁移学习能力,以降低训练成本。
-
可解释性与安全性:大模型的复杂性使得其内部工作机制难以理解。未来的研究需要关注如何提高模型的可解释性和安全性,以满足监管和用户需求。
8. 附录:常见问题与解答
-
问:AI大模型的训练需要多少计算资源?
答:这取决于模型的规模和任务。一般来说,大型模型需要大量的计算资源,如GPU或TPU。对于个人用户,可以使用云计算服务或预训练模型来降低计算需求。 -
问:如何选择合适的AI大模型?
答:选择合适的模型取决于任务需求和计算资源。一般来说,可以从预训练模型库中选择一个与任务相似的模型作为基础,然后根据需要进行微调。 -
问:AI大模型是否适用于所有任务?
答:虽然AI大模型在许多任务中取得了显著的成果,但并不是所有任务都适用。对于一些简单或特定领域的任务,可能更适合使用小型模型或特定领域的方法。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
-END-
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/653583
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

