
一、性能调优
1.1 性能调优的目的
减少minor gc的频率、将转移到老年代的对象数量降低到最小以及减少full gc的次数,调优的关键是找到性能的瓶颈

#此图来自:http://uule.iteye.com/blog/2114697
1.2 性能调优的手段
#文字内容来自:http://blog.csdn.net/wfzczangpeng/article/details/51816409
1.使用JDK提供的内存查看工具,如JConsole和Java VisualVM 2.控制堆内存各个部分所占的比例 3.采用合适的垃圾收集器
手段1:内存查看工具和GC日志分析
-verbose.gc:显示GC的操作内容。打开它,可以显示最忙和最空闲收集行为发生的时间、收集前后的内存大小、收集需要的时间等。 -xx:+printGCdetails:详细了解GC中的变化。 -XX:+PrintGCTimeStamps:了解这些垃圾收集发生的时间,自JVM启动以后以秒计量。 -xx:+PrintHeapAtGC:了解堆的更详细的信息。
手段2:针对新生代和旧生代的比例
如果新生代太小,会导致频繁GC,而且大对象对直接进入旧生代引发full gc 如果新生代太大,会诱发旧生代full gc,而且新生代的gc耗时会延长 建议新生代占整个堆1/3合适,相关JVM参数如下: -Xms:初始堆大小 -Xmx:最大堆大小 - Xmn:新生代大小 -XX:PermSize=n:持久代最大值 -XX:MaxPermSize=n:持久代最大值 -XX:NewRatio=n:设置新生代和旧生代的比值。如:为3,表示新生代与旧生代比值为1:3,新生代占整个新生代旧生代和的1/4
手段3:针对Eden和Survivor的比例
如果Eden太小,会导致频繁GC 如果Eden太大,会导致大对象直接进入旧生代,降低对象在新生代存活时间 -XX:SurvivorRatio=n:新生代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5 -XX:PretenureSizeThreshold:直接进入旧生代中的对象大小,设置此值后,大于这个参数的对象将直接在旧生代中进行内存分配。 -XX:MaxTenuringThreshold:对象转移到旧生代中的年龄,每个对象经历过一次新生代GC(Minor GC)后,年龄就加1,到超过设置的值后,对象转移到旧生代。
手段4:采用正确的垃圾收集器
通过JVM参数设置所使用的垃圾收集器参考前面的介绍,这里关注其他一些设置。#并行收集器设置-XX:ParallelGCThreads=n:设置并行收集器收集时并行收集线程数 -XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间,仅对ParallelScavenge生效 -XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比,仅对Parallel Scavenge生效#并发收集器设置-XX:CMSInitiatingOccupancyFraction:默认设置下,CMS收集器在旧生代使用了68%的空间后就会被激活。此参数就是设置旧生代空间被使用多少后触发垃圾收集。注意要是CMS运行期间预留的内存无法满足程序需要,就会出现concurrent mode failure,这时候就会启用Serial Old收集器作为备用进行旧生代的垃圾收集。 -XX:+UseCMSCompactAtFullCollection:空间碎片过多是标记-清除算法的弊端,此参数设置在FULL GC后再进行一个碎片整理过程 -XX:CMSFullGCsBeforeCompaction:设置在若干次垃圾收集之后再启动一次内存碎片整理
1.3 调优原则和步骤:
在调优之前,我们需要记住下面的原则:
1、多数的Java应用不需要在服务器上进行GC优化; 2、多数导致GC问题的Java应用,都不是因为我们参数设置错误,而是代码问题; 3、在应用上线之前,先考虑将机器的JVM参数设置到最优(最适合); 4、减少创建对象的数量; 5、减少使用全局变量和大对象; 6、GC优化是到最后不得已才采用的手段; 7、在实际使用中,分析GC情况优化代码比优化GC参数要多得多;
进行监控和调优的一般步骤为:
1,监控GC的状态
使用各种JVM工具,查看当前日志,分析当前JVM参数设置,并且分析当前堆内存快照和gc日志,根据实际的各区域内存划分和GC执行时间,觉得是否进行优化;
2,分析结果,判断是否需要优化
如果各项参数设置合理,系统没有超时日志出现,GC频率不高,GC耗时不高,那么没有必要进行GC优化;如果GC时间超过1-3秒,或者频繁GC,则必须优化;
注:如果满足下面的指标,则一般不需要进行GC:
Minor GC执行时间不到50ms; Minor GC执行不频繁,约10秒一次; Full GC执行时间不到1s; Full GC执行频率不算频繁,不低于10分钟1次;
3,调整GC类型和内存分配
如果内存分配过大或过小,或者采用的GC收集器比较慢,则应该优先调整这些参数,并且先找1台或几台机器进行beta,然后比较优化过的机器和没有优化的机器的性能对比,并有针对性的做出最后选择;
4,不断的分析和调整
通过不断的试验和试错,分析并找到最合适的参数
GC分析 命令调优
#这里摘自:http://www.cnblogs.com/ityouknow/p/6482464.html
GC日志分析
摘录GC日志一部分(前部分为年轻代gc回收;后部分为full gc回收):
2016-07-05T10:43:18.093+0800: 25.395: [GC [PSYoungGen: 274931K->10738K(274944K)] 371093K->147186K(450048K), 0.0668480 secs] [Times: user=0.17 sys=0.08, real=0.07 secs] 2016-07-05T10:43:18.160+0800: 25.462: [Full GC [PSYoungGen: 10738K->0K(274944K)] [ParOldGen: 136447K->140379K(302592K)] 147186K->140379K(577536K) [PSPermGen: 85411K->85376K(171008K)], 0.6763541 secs] [Times: user=1.75 sys=0.02, real=0.68 secs]
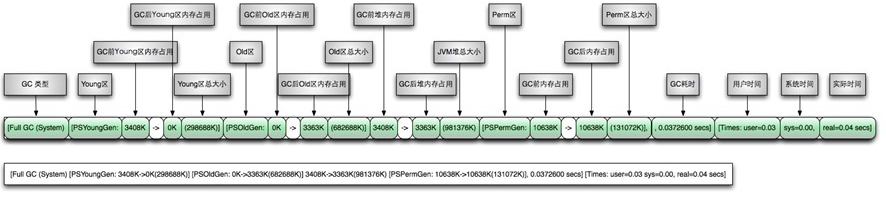
#通过上面日志分析得出,PSYoungGen、ParOldGen、PSPermGen属于Parallel收集器。其中PSYoungGen表示gc回收前后年轻代的内存变化;ParOldGen表示gc回收前后老年代的内存变化;PSPermGen表示gc回收前后永久区的内存变化。young gc 主要是针对年轻代进行内存回收比较频繁,耗时短;full gc 会对整个堆内存进行回城,耗时长,因此一般尽量减少full gc的次数
young gc 日志:
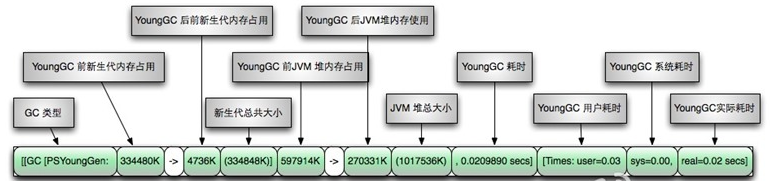
Full GC日志:
调优命令:
Sun JDK监控和故障处理命令有jps jstat jmap jhat jstack jinfo
jps #JVM Process Status Tool,显示指定系统内所有的HotSpot虚拟机进程。 jstat #JVM statistics Monitoring是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。 jmap #JVM Memory Map命令用于生成heap dump文件。 jhat #JVM Heap Analysis Tool命令是与jmap搭配使用,用来分析jmap生成的dump,jhat内置了一个微型的HTTP/HTML服务器,生成dump的分析结果后,可以在浏览器中查看。 jstack #用于生成java虚拟机当前时刻的线程快照。 jinfo #JVM Configuration info 这个命令作用是实时查看和调整虚拟机运行参数。 javap #查看经javac之后产生的JVM字节码代码,自动解析.class文件, 避免了去理解class文件格式以及手动解析class文件内容。 jcmd #几乎集合了jps、jstat、jinfo、jmap、jstack所有功能,一个多功能工具, 可以用来导出堆, 查看Java进程、导出线程信息、 执行GC、查看性能相关数据等。
调优工具:
常用调优工具分为两类,jdk自带监控工具:jconsole和jvisualvm,第三方有:MAT(Memory Analyzer Tool)、GChisto。
jconsole #Java Monitoring and Management Console是从java5开始,在JDK中自带的java监控和管理控制台,用于对JVM中内存,线程和类等的监控。 jvisualvm #jdk自带全能工具,可以分析内存快照、线程快照;监控内存变化、GC变化等。 MAT #Memory Analyzer Tool,一个基于Eclipse的内存分析工具,是一个快速、功能丰富的Java heap分析工具,它可以帮助我们查找内存泄漏和减少内存消耗。 GChisto #一款专业分析gc日志的工具
打印GC信息:
-XX:+PrintGC #输出GC日志 -verbose:gc -XX:+PrintGCDetails #输出GC的详细日志 -XX:+PrintGCTimeStamps #输出GC时间戳(以基准时间的形式) -XX:+PrintHeapAtGC #在进行GC的前后打印出堆的信息 -Xloggc:/path/gc.log #日志文件的输出路径 -XX:+PrintGCApplicationStoppedTime #打印由GC产生的停顿时间
二、JVM调优-命令大全
官网链接:https://docs.oracle.com/javase/9/tools/monitoring-tools-and-commands.htm#JSWOR732
2.1 jps
jps介绍
用来查看基于HotSpot的JVM里面中,所有具有访问权限的Java进程的具体状态, 包括进程ID,进程启动的路径及启动参数等等,与unix上的ps类似,只不过jps是用来显示java进程,可以把jps理解为ps的一个子集。
使用jps时,如果没有指定hostid,它只会显示本地环境中所有的Java进程;如果指定了hostid,它就会显示指定hostid上面的java进程,不过这需要远程服务上开启了jstatd服务,可以参看前面的jstatd章节来启动jstad服务。
Jps(Java Virtual Machine Process Status Tool)是JDK 1.5提供的一个显示当前所有java进程pid的命令,简单实用,非常适合在linux/unix平台上简单察看当前java JVM进程的一些简单情况。
很多Java命令都在jdk的JAVA_HOME/bin/目录下面,jps也不例外,他就在bin目录下,所以,他是java自带的一个命令。
原理
jdk中的jps命令可以显示当前运行的java进程以及相关参数,它的实现机制如下:
java程序在启动以后,会在java.io.tmpdir指定的目录下,就是临时文件夹里,生成一个类似于hsperfdata_User的文件夹,这个文件夹里(在Linux中为/tmp/hsperfdata_{userName}/),有几个文件,名字就是java进程的pid,因此列出当前运行的java进程,只是把这个目录里的文件名列一下而已。 至于系统的参数什么,就可以解析这几个文件获得。
# ls -l /tmp/hsperfdata_hadoop/ #因为java程序我都是用hadoop用户启动的,所以会存在此目录下
总用量 192 -rw------- 1 hadoop hadoop 32768 12月 28 22:11 28677 -rw------- 1 hadoop hadoop 32768 12月 28 22:11 3313 -rw------- 1 hadoop hadoop 32768 12月 28 22:11 6100 -rw------- 1 hadoop hadoop 32768 12月 28 22:11 6483 -rw------- 1 hadoop hadoop 32768 12月 28 22:11 7676 -rw------- 1 hadoop hadoop 32768 12月 28 22:11 836
# jps #就相当于jps -V
32368 Jps #它自己也是java命令,也要开一个进程3313 JournalNode 6483 DFSZKFailoverController 836 RunJar 6100 NameNode 28677 Master 7676 RunJar
先来man帮助一下:
# man jps
概要:
jps [ options ] [ hostid ] options #命令行选项。 hostid #其生成进程报告的主机的标识符。 hostid可以包含指示通信协议,端口号和其他实现特定数据的可选组件。
option参数:
-q #禁止输出类名,JAR文件名和传递给main方法的参数,只产生一个本地JVM标识符列表。 -m #显示传递给主方法的参数。 嵌入式JVM的输出可能为空。输出JVM启动时传递给main()的参数。 -l #显示应用程序主类的完整程序包名称或应用程序JAR文件的完整路径名称。 -v #显示传递给JVM的参数。 -V #禁止输出类名,JAR文件名和传递给main方法的参数,只产生一个本地JVM标识符列表(.hotspotrc文件,或者是通过参数-XX:Flags=指定的文件)。 -Joption #将选项传递给JVM,其中选项是Java应用程序启动器参考页上描述的选项之一。 例如,-J -Xms48m将启动内存设置为48 MB。
主机标识符:
主机标识符或hostid是指示目标系统的字符串。 hostid字符串的语法对应于URI的语法:
[protocol:][[//]hostname][:port][/servername]
protocol #通信协议。 如果省略了协议并且未指定主机名,则默认协议是特定于平台的优化的本地协议。 如果省略了协议并指定了主机名,则默认协议是rmi。 hostname #指示目标主机的主机名或IP地址。 如果省略hostname参数,则目标主机是本地主机。 port #远程rmi的端口,如果没有指定则默认为1099。。 servername #这个参数的处理取决于实现。 对于优化的本地协议,该字段被忽略。 对于rmi协议,此参数是一个字符串,表示远程主机上RMI远程对象的名称。 有关更多信息,请参阅jstatd命令-n选项。
输出格式:
jps命令的输出遵循以下模式:
lvmid [ [ classname | JARfilename | "Unknown"] [ arg* ] [ jvmarg* ] ]
所有输出令牌都由空格分隔。 包含嵌入式空白的arg值在尝试将参数映射到其实际位置参数时会引入歧义。注意:建议您不要编写脚本来解析jps输出,因为在将来的版本中格式可能会更改。 如果您编写解析jps输出的脚本,则希望修改它们以用于此工具的将来版本。
示例:
# jps -l #输出应用程序main class的完整package名 或者 应用程序的jar文件完整路径名
3313 org.apache.hadoop.hdfs.qjournal.server.JournalNode 6483 org.apache.hadoop.hdfs.tools.DFSZKFailoverController 836 org.apache.hadoop.util.RunJar 6100 org.apache.hadoop.hdfs.server.namenode.NameNode 853 sun.tools.jps.Jps 28677 org.apache.spark.deploy.master.Master 7676 org.apache.hadoop.util.RunJar
# jps -m #输出传递给main 方法的参数
3313 JournalNode 883 Jps -m 6483 DFSZKFailoverController 836 RunJar /home/hadoop/apache-hive/lib/hive-service-1.2.2.jar org.apache.hive.service.server.HiveServer2 6100 NameNode 28677 Master --host master.hadoop --port 7077 --webui-port 8080 7676 RunJar /home/hadoop/apache-hive/lib/hive-service-1.2.2.jar org.apache.hadoop.hive.metastore.HiveMetaStore
# jps -v #就非常详细了就跟ps一样了
2.2 jstat
参考:http://www.hollischuang.com/archives/481
jstat(JVM statistics Monitoring)是用于监视虚拟机运行时状态信息的命令,它可以显示出虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。
jstat位于java的bin目录下,主要利用JVM内建的指令对Java应用程序的资源和性能进行实时的命令行的监控,包括了对Heap size和垃圾回收状况的监控。可见,Jstat是轻量级的、专门针对JVM的工具,非常适用。
#直接跟着man帮助解释了。
命令格式:
jstat [ generalOption | outputOptions vmid [ interval[s|ms] [ count ] ]
generalOption #单个常规命令行选项-help或-options。 outputOptions #一个或多个由单个statOption组成的输出选项,以及任何-t,-h和-J选项。 vmid #虚拟机标识符,表示目标JVM的字符串。 一般的语法如下:[protocol:][//]lvmid[@hostname[:port]/servername] interval [s|ms] #以指定单位的采样间隔,秒(s)或毫秒(ms)。默认单位是毫秒。必须是正整数。指定时,jstat命令会在每个时间间隔产生输出。 count #要显示的样本数量。 默认值是无穷大,这会导致jstat命令显示统计信息,直到目标JVM终止或jstat命令终止。 该值必须是正整数。
OPTIONS参数:
jstat命令支持两种类型的选项,一般选项和输出选项。 常规选项使jstat命令显示简单的使用情况和版本信息。 输出选项决定了统计输出的内容和格式。 所有选项及其功能在未来版本中可能会更改或删除。
输出选项:
-statOption #确定jstat命令显示的统计信息。 以下列出了可用的选项。 使用-options常规选项来显示特定平台安装的选项列表。
class #显示有关类加载器行为的统计信息。 compiler #显示有关Java HotSpot VM即时编译器行为的统计信息。 gc #显示有关垃圾回收堆的行为的统计信息。 gccapacity #各个垃圾回收代容量(young,old,perm)和他们相应的空间统计。 gccause #垃圾收集统计概述(同-gcutil),附加最近两次垃圾回收事件的原因。 gcnew #显示新生代行为的统计信息。gcnewcapacity #显示有关新生代及其相应空间大小的统计信息。 gcold #显示有关老年代和metaspace统计信息的统计信息。 gcoldcapacity #年老代行为统计。 gcmetacapacity #显示有关元空间大小的统计信息。 gcutil #显示关于垃圾收集统计信息的摘要。 printcompilation #显示Java HotSpot VM编译方法统计信息。
-h n #每n个样本(输出行)显示一个列标题,其中n是一个正整数。 默认值是0,它显示列标题的第一行数据。
-t #显示一个时间戳列作为输出的第一列。 时间戳是从目标JVM开始时间开始的时间。
-JjavaOption #将javaOption传递给Java应用程序启动器。
参数输出详解:
gcutil选项示例:
# jstat -gcutil 6483 250 7 #查看pid号是6483并以250毫秒的时间间隔取7个样本,显示输出垃圾收集统计信息
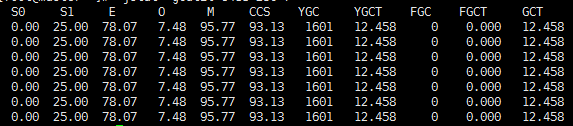
S0:幸存者0空间利用率占空间当前容量的百分比。
S1:幸存者1空间利用率占空间当前容量的百分比。
E: Eden空间利用率占空间当前容量的百分比。
O:旧空间利用率占空间当前容量的百分比。
M:Metaspace利用率占空间当前容量的百分比。
CCS:压缩类空间利用率,以百分比表示。
YGC:年轻一代GC事件的数量。
YGCT:年轻一代的垃圾收集时间(S)。
FGC:完整的GC事件的数量。
FGCT:完整的垃圾收集时间(S)。
GCT:垃圾收集总时间(S)。
-gcnew选项示例:
# jstat -gcnew -h3 836 250 #显示pid 836的250毫秒为时间间隔,每三行输出标题的统计新生代的行为
S0C S1C S0U S1U TT MTT DSS EC EU YGC YGCT 38400.0 28672.0 0.0 28519.4 4 15 45056.0 321536.0 289485.7 15 12.394 38400.0 28672.0 0.0 28519.4 4 15 45056.0 321536.0 289485.7 15 12.394 38400.0 28672.0 0.0 28519.4 4 15 45056.0 321536.0 289485.7 15 12.394 S0C S1C S0U S1U TT MTT DSS EC EU YGC YGCT 38400.0 28672.0 0.0 28519.4 4 15 45056.0 321536.0 289485.7 15 12.394 38400.0 28672.0 0.0 28519.4 4 15 45056.0 321536.0 289485.7 15 12.394 38400.0 28672.0 0.0 28519.4 4 15 45056.0 321536.0 289485.7 15 12.394
S0C:当前幸存者空间0容量(kB)。
S1C:当前幸存者空间1容量(kB)。
S0U:幸存者空间0利用率(kB)。
S1U:幸存者空间1利用率(kB)。
TT:任期阀值
MTT:最大任期阀值
DSS:所需的幸存者大小(kB)。
EC:当前eden空间容量(kB)。
EU:Eden空间利用率(kB)。
YGC:年轻一代GC事件的数量。
YGCT:年轻一代的垃圾收集时间(S)。
-gcoldcapacity选项示例:
$ps -aux|grep 5856 #通过ps可以看到pid是5856的进程实际使用了一共用了4624004KB字节也就是大概4515MB内存。 USER PID %CPU %MEM VSZ RSS root 5856 5.3 7.0 17072476 4624004 #这是个64G内存7.0%也就是大概4447MB
# jstat -gcoldcapacity -t 5856 500 3 #pid 5856的java进程的年老代行为统计,-t是显示时间戳,后面是500毫秒为时间间隔打印3次

OGCMN:最小老年代容量(kB)。#从上图可以看出是670MB
OGCMX:最大老年代容量(kB)。#从上如可以看出最大内存是2730MB
OGC:当前的老年代容量(kB)。 #当前老年代是2730MB
OC:老年代大小(kB)。
YGC:年轻一代GC事件的数量。
FGC:full GC事件的数量。
FGCT:完整的垃圾收集时间(S)。
GCT:垃圾收集总时间(S)。
-class选项示例:
# jstat -class 3313 #输出pid 3313进程的监视类装载、卸载数量、总空间以及耗费的时间
Loaded Bytes Unloaded Bytes Time 4134 8198.2 14 17.7 6.65
Loaded:加载class的数量
Bytes: class字节大小
Unloaded: 卸载的类数。
Bytes: 卸载的千字节数。
Time: 执行类加载和卸载操作的时间。
-compiler选项示例:
# jstat -compiler 28677 #输出pid号是28677的JIT编译过的方法数量耗时等
Compiled Failed Invalid Time FailedType FailedMethod 3705 0 0 13.30 0
Compiled: 执行的编译任务数。
Failed: 编译任务的失败数量。
Invalid: 无效的编译任务数。
Time: 执行编译任务的时间。
FailedType: 编译最后一次失败编译的类型。
FailedMethod: 上次失败编译的类名称和方法。
-gc选项示例:
#还是结合实例来看一下吧:
$free -m #64G的内存
total used free shared buffers cached Mem: 64376 63922 453 0 4625 46199 -/+ buffers/cache: 13098 51277 Swap: 4095 1158 2937$ps -aux|grep 5856 #通过ps可以看到pid是5856的进程实际使用了一共用了4624004KB字节也就是大概4515MB内存。USER PID %CPU %MEM VSZ RSS root 5856 5.3 7.0 17072476 4624004 #这是个64G内存7.0%也就是大概4447MB
# jstat -gc 5856 #显示pid是5856的垃圾回收堆的行为统计
S0C S1C S0U S1U EC EU OC OU PC PU YGC YGCT FGC FGCT GCT 139776.0 139776.0 18275.9 0.0 1118528.0 1030959.8 2796224.0 766118.3 262144.0 143587.8 31456 575.292 941 55.751 631.043
#C即Capacity 总容量,U即Used 已使用的容量
S0C: 当前survivor0区容量(kB)。 #大概是136MB
S1C: 当前survivor1区容量(kB)。 #大概是136MB
S0U: survivor0区已使用的容量(KB) #当前使用了17MB
S1U: survivor1区已使用的容量(KB)
EC: Eden区的总容量(KB) #Eden区的大小现在是1092MB
EU: 当前Eden区已使用的容量(KB) #当前Eden区使用了1006MB
OC: Old空间容量(kB)。 #当前老年代是2730MB
OU: Old区已使用的容量(KB) #当前使用了748MB
MC: Metaspace空间容量(KB) #在jdk1.7的版本MC是PC,也就是256MB
MU: Metacspace使用量(KB) #也就是jdk1.7版本永久代使用了140MB
CCSC: 压缩类空间容量(kB)。
CCSU: 压缩类空间使用(kB)。
YGC: 新生代垃圾回收次数
YGCT: 新生代垃圾回收时间
FGC: 老年代 full GC垃圾回收次数
FGCT: 老年代垃圾回收时间
GCT: 垃圾回收总消耗时间
#算一算啊:136*2+1092+2730+256=4350MB
-gccapacity选项示例:
#这里用个64G内存的ES机器来示例一下。
#free -m
total used free shared buff/cache available Mem: 64152 47777 333 5 16040 15861 Swap: 16063 15268 795
#ps -aux
USER PID %CPU %MEM VSZ RSS COMMAND #也就是内存使用了46766MB root 4557 173 72.9 434279100 47893564 /bin/java -Xms54g -Xmx54g -Djava.awt.headless=true -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:+HeapDumpOnOutOfMemoryError -XX:+DisableExplicitGC
$jstat -gccapacity 4557 500 2 #显示VM内存中三代(young,old,perm)对象的使用和占用大小
NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC OC PGCMN PGCMX PGC PC YGC FGC 0.0 56623104.0 6651904.0 0.0 933888.0 5718016.0 0.0 56623104.0 49971200.0 49971200.0 ? ? ? ? 222917 0 0.0 56623104.0 6651904.0 0.0 933888.0 5718016.0 0.0 56623104.0 49971200.0 49971200.0 ? ? ? ? 222917 0 #54G #6496MB #912MB #5584MB #54G #48800MB #47.65G
NGCMN : 年轻代(young)中初始化(最小)的大小(KB)
NGCMX : 年轻代(young)的最大容量 (KB)
NGC : 年轻代(young)中当前的容量 (KB)
S0C :年轻代中第一个survivor(幸存区)的容量 (KB)
S1C :年轻代中第二个survivor(幸存区)的容量 (KB)
EC :年轻代中Eden(伊甸园)的容量 (KB)
OGCMN :old代中初始化(最小)的大小 (KB)
OGCMX :old代的最大容量(KB)
OGC :old代当前新生成的容量 (KB)
OC :Old代的容量 (KB)
PGCMN :perm代中初始化(最小)的大小 (KB) ,jdk1.8改为了MCMN
PGCMX :perm代的最大容量 (KB),jdk1.8改为了MCMX
PGC :perm代当前新生成的容量 (KB)
PC :Perm(持久代)的容量 (KB)
YGC :从应用程序启动到采样时年轻代中gc次数
FGC :从应用程序启动到采样时old代(全gc)gc次数
jdk1.8还多了下面一些:
MC:Metaspace空间(KB)
CCSMN: 压缩类空间最小容量(kB)。
CCSMX:压缩类空间最大容量(kB)。
CCSC:压缩类空间容量(kB)。
#算一算:
年轻代=912+0+5584=6496(正好是NGC也就是现在新生代当前的容量)
#用老年代当前的内存加上新生代当前使用的内存一加发现比ps查看当前使用的内存要多,对所以swap分区占用了很多嘛。
-gcnewcapacity选项:
$jstat -gcnewcapacity 4557 #pid是4557进程的年轻代对象的信息及其占用量
NGCMN NGCMX NGC S0CMX S0C S1CMX S1C ECMX EC YGC FGC 0.0 56623104.0 4243456.0 0.0 0.0 56623104.0 393216.0 56623104.0 3850240.0 223430 0
NGCMN :年轻代(young)中初始化(最小)的大小(kb)
NGCMX: 年轻代(young)的最大容量 (kb)
NGC :年轻代(young)中当前的容量 (kb)
S0CMX :年轻代中第一个survivor(幸存区)的最大容量 (kb)
S0C: 年轻代中第一个survivor(幸存区)的容量 (kb)
S1CMX :年轻代中第二个survivor(幸存区)的最大容量 (kb)
S1C :年轻代中第二个survivor(幸存区)的容量 (kb)
ECMX :年轻代中Eden(伊甸园)的最大容量 (kb)
EC :年轻代中Eden(伊甸园)的容量 (kb)
YGC :从应用程序启动到采样时年轻代中gc次数
FGC :从应用程序启动到采样时old代(全gc)gc次数
-gcold选项:
$jstat -gcold 4557 #pid是4557的old代对象的信息。
PC PU OC OU YGC FGC FGCT GCT ? ? 49840128.0 16515022.1 223465 0 0.000 46562.453
PC :Perm(持久代)的容量 (kb) #jdk1.8是MC Metaspace容量
PU :Perm(持久代)目前已使用空间 (kb) #jdk1.8是MU Metaspace目前的使用量
OC :Old代的容量 (kb)
OU :Old代目前已使用空间 (kb)
YGC :从应用程序启动到采样时年轻代中gc次数
FGC :从应用程序启动到采样时old代(全gc)gc次数
FGCT :从应用程序启动到采样时old代(full gc)gc所用时间
GCT :垃圾收集总时间
-gcoldcapacity选项:
$jstat -gcoldcapacity 4557 #pid是4557的old代对象的信息及其占用量。
OGCMN OGCMX OGC OC YGC FGC FGCT GCT 0.0 56623104.0 52969472.0 52969472.0 223500 0 0.000 46571.320
OGCMN :old代中初始化(最小)的大小 (kb)
OGCMX :old代的最大容量(kb)
OGC :old代当前的容量 (kb)
OC :Old代的容量 (kb)
YGC :从应用程序启动到采样时年轻代中gc次数
FGC :从应用程序启动到采样时old代(全gc)gc次数
FGCT :从应用程序启动到采样时old代(full gc)gc所用时间
GCT :垃圾收集总时间。
2.3 Jmap
jmap(JVM Memory Map)命令用于生成heap dump文件,如果不使用这个命令,还可以使用-XX:+HeapDumpOnOutOfMemoryError参数来让虚拟机出现OOM的时候·自动生成dump文件。jmap不仅能生成dump文件,还可以查询finalize执行队列、Java堆和永久代的详细信息,如当前使用率、当前使用的是哪种收集器等。
概要:
命令格式:
jmap [ options ] pid jmap [ options ] executable core jmap [ options ] [ pid ] server-id@ ] remote-hostname-or-IP
pid #存储器映射将被打印的进程ID. 这个进程必须是一个Java进程。 要获取计算机上运行的Java进程的列表,请使用jps命令。
executable #从中生成核心转储的Java可执行文件。
core #内存映射将被打印的核心文件。
remote-hostname-or-IP #远程调试服务器主机名或IP地址。 见jsadebugd。
server-id #多个调试服务器在同一个远程主机上运行时使用的可选唯一标识。
options参数:
<no option> #如果不使用选项,则jmap命令将打印共享对象映射。 对于在目标JVM中加载的每个共享对象,将打印起始地址,映射的大小以及共享对象文件的完整路径。 此行为与Oracle Solaris pmap实用程序类似。 -dump:[live,] format=b, file=filename #将hprof二进制格式的Java堆转储为文件名。实时子选项是可选的,但是指定时,只有堆中的活动对象被转储。 要浏览堆转储,可以使用jhat命令来读取生成的文件。 -finalizerinfo #打印正在等待确定的对象的信息。显示在F-Queue队列等待Finalizer线程执行finalizer方法的对象。 -heap #显示堆中对象的统计信息。打印所使用的垃圾收集的堆摘要,头配置和生成智能堆使用情况。 另外,打印字符串的数量和大小。 -histo[:live] #显示堆中对象的统计信息。打印堆的直方图。对于每个Java类,将打印对象的数量,以字节为单位的内存大小以及完全限定的类名称。JVM内部类名称以星号(*)前缀打印。如果指定了活动子选项,则只对活动对象进行计数。 -clstats #打印Java堆的类加载器明智的统计信息。 对于每个类加载器,它的名字,它的活跃程度,地址,父类加载器,以及它所加载类的数量和大小都被打印出来。 -F #当-dump没有响应时,强制生成dump快照。 -h/-help #打印帮助信息。 -Jflag #将标志传递到正在运行jmap命令的Java虚拟机。
示例:
$ jmap -dump:live,format=b,file=dump.hprof 6483 #dump堆到文件,format指定输出格式,live指明是活着的对象,file指定导出的文件名,最后是pid
Dumping heap to /tmp/dump.hprof ... #dump.hprof这个后缀是为了后续可以直接用MAT(Memory Anlysis Tool)打开。 Heap dump file created
$ jmap -finalizerinfo 6483 #打印pid 6483等待回收对象的信息
Attaching to process ID 6483, please wait... Debugger attached successfully. Server compiler detected. JVM version is 25.74-b02 Number of objects pending for finalization: 0 #可以看到当前F-QUEUE队列中并没有等待Finalizer线程执行finalizer方法的对象。
$ jmap -heap 26318 #打印heap的概要信息,GC使用的算法,heap的配置及wise heap的使用情况,可以用此来判断内存目前的使用情况以及垃圾回收情况。
Attaching to process ID 26318, please wait... Debugger attached successfully. Server compiler detected. JVM version is 24.51-b03 using thread-local object allocation. Parallel GC with 4 thread(s) #CG方式Heap Configuration: #堆内存初始化配置 MinHeapFreeRatio = 40 #对应jvm启动参数-XX:MinHeapFreeRatio设置JVM堆最小空闲比率(default 40) MaxHeapFreeRatio = 70 #对应jvm启动参数 -XX:MaxHeapFreeRatio设置JVM堆最大空闲比率(default 70) MaxHeapSize = 1073741824 (1024.0MB) #对应jvm启动参数-XX:MaxHeapSize=设置JVM堆的最大大小 NewSize = 1310720 (1.25MB) #对应jvm启动参数-XX:NewSize=设置JVM堆的‘新生代’的默认大小 MaxNewSize = 17592186044415 MB #对应jvm启动参数-XX:MaxNewSize=设置JVM堆的‘新生代’的最大大小 OldSize = 5439488 (5.1875MB) #对应jvm启动参数-XX:OldSize=<value>:设置JVM堆的‘老生代’的大小 NewRatio = 2 #对应jvm启动参数-XX:NewRatio=:‘新生代’和‘老生代’的大小比率 SurvivorRatio = 8 #对应jvm启动参数-XX:SurvivorRatio=设置年轻代中Eden区与Survivor区的大小比值 PermSize = 21757952 (20.75MB) #对应jvm启动参数-XX:PermSize=<value>:设置JVM堆的‘永生代’的初始大小 MaxPermSize = 536870912 (512.0MB) #对应jvm启动参数-XX:MaxPermSize=<value>:设置JVM堆的‘永生代’的最大大小 G1HeapRegionSize = 0 (0.0MB)Heap Usage: #堆内存使用情况PS Young Generation Eden Space: #Eden区内存分布 capacity = 67633152 (64.5MB) #Eden区已使用 used = 28392072 (27.07678985595703MB) #Eden区已使用 free = 39241080 (37.42321014404297MB) #Eden区剩余容量 41.97951915652253% used #Eden区使用比率From Space: #其中一个Survivor区的内存分布 capacity = 1048576 (1.0MB) used = 884888 (0.8438949584960938MB) free = 163688 (0.15610504150390625MB) 84.38949584960938% used To Space: #另一个Survivor区的内存分布 capacity = 1048576 (1.0MB) used = 0 (0.0MB) free = 1048576 (1.0MB) 0.0% used PS Old Generation #当前的Old区内存分布 capacity = 715653120 (682.5MB) used = 567277296 (540.9977874755859MB) free = 148375824 (141.50221252441406MB) 79.26707508799794% used PS Perm Generation #当前的 “永生代” 内存分布 capacity = 77070336 (73.5MB) used = 76357904 (72.82057189941406MB) free = 712432 (0.6794281005859375MB) 99.07560802641369% used 30524 interned Strings occupying 3308424 bytes. #可以很清楚的看到Java堆中各个区域目前的情况。
$ jmap -histo:live 6483|more #打印堆的对象统计,包括对象数、内存大小等等 (因为在dump:live前会进行full gc,如果带上live则只统计活对象,因此不加live的堆大小要大于加live堆的大小 )
num #instances #bytes class name ---------------------------------------------- 1: 12283 1019696 [C 2: 802 594384 [B 3: 2847 323256 java.lang.Class 4: 12233 293592 java.lang.String 5: 7010 224320 java.util.concurrent.ConcurrentHashMap$Node 6: 1937 132448 [Ljava.lang.Object; 7: 3343 106976 java.util.Hashtable$Entry 8: 1307 106632 [I 9: 44 84256 [Ljava.util.concurrent.ConcurrentHashMap$Node; 10: 2712 69376 [Ljava.lang.String; ...... xml class name是对象类型,说明如下: B byte C char D double F float I int J long Z boolean[ 数组,如[I表示int[][L+类名 其他对象
2.4 jhat
jhat(JVM Heap Analysis Tool)命令是与jmap搭配使用,用来分析jmap生成的dump,jhat内置了一个微型的HTTP/HTML服务器,生成dump的分析结果后,可以在浏览器中查看。在此要注意,一般不会直接在服务器上进行分析,因为jhat是一个耗时并且耗费硬件资源的过程,一般把服务器生成的dump文件复制到本地或其他机器上进行分析。
格式:
jhat [ options ] heap-dump-file #options : 命令行选项。 #heap-dump-file : 要解析的Java堆转储文件
OPTIONS选项:
-stack false|true #关闭跟踪对象分配调用堆栈。 如果分配站点信息在堆转储中不可用,则必须将此标志设置为false。 默认值是true。 -refs false|true #关闭对象引用跟踪(tracking of references to objects)。默认值为true.默认情况下, 返回的指针是指向其他特定对象的对象,如反向链接或输入引用(referrers or incoming references), 会统计/计算堆中的所有对象。 -port port-number #设置jhat HTTP服务器的端口。 默认值是7000。 -exclude exclude-file #指定一个列出应该从可达对象查询中排除的数据成员的文件。例如,如果文件列出了java.lang.String.value,那么只要计算出可以从特定Object o 访问的对象列表,则不会考虑涉及java.lang.String.value字段的引用路径。 -baseline exclude-file #指定一个基准堆转储(baseline heap dump)。 在两个 heap dumps 中有相同 object ID 的对象会被标记为不是新的(marked as not being new). 其他对象被标记为新的(new). 在比较两个不同的堆转储时很有用. -debug int #设置此工具的调试级别。 0级意味着没有调试输出。 为更详细的模式设置更高的值。 -version #报告版本号并退出。 -h/-help #显示帮助信息并退出。 -Jflag #因为jhat 命令实际上会启动一个JVM来执行, 通过 -J 可以在启动JVM时传入一些启动参数. 例如, -J-Xmx512m 则指定运行 jhat 的Java虚拟机使用的最大堆内存为 512 MB. 如果需要使用多个JVM启动参数,则传入多个 -Jxxxxxx.
示例:
$ jhat -J-Xmx512m dump.hprof
#中间的-J-Xmx512m是在dump快照很大的情况下分配512M内存去启动HTTP服务器,运行完之后就可在浏览器打开Http://localhost:7000进行快照分析堆快照分析主要在最后面的Heap Histogram里,里面根据class列出了dump的时候所有存活对象。
Reading from dump.hprof... Dump file created Tue Jan 02 11:33:30 CST 2018 Snapshot read, resolving... Resolving 66380 objects... Chasing references, expect 13 dots............. Eliminating duplicate references............. Snapshot resolved. Started HTTP server on port 7000 Server is ready.
#分析同样一个dump快照,MAT需要的额外内存比jhat要小的多的多,所以建议使用MAT来进行分析,当然也看个人偏好。
打开浏览器Http://localhost:7000,该页面提供了几个查询功能可供使用(在页面的最下方):
All classes including platform #所有类别包括平台。 Show all members of the rootset #显示rootset的所有成员。 Show instance counts for all classes (including platform) #显示所有类的实例计数(包括平台)。 Show instance counts for all classes (excluding platform) #显示所有类的实例计数(不包括平台) Show heap histogram #显示堆直方图。 Show finalizer summary #显示finalizer摘要。 Execute Object Query Language (OQL) query #执行对象查询语言(OQL)查询
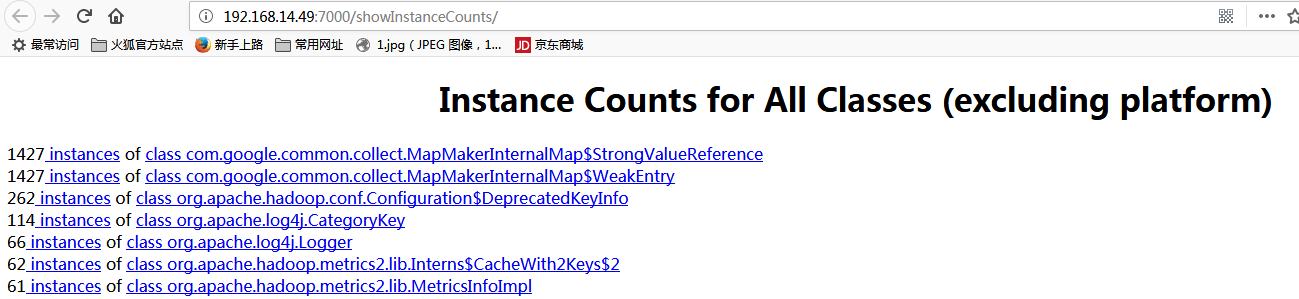
一般查看堆异常情况主要看这个两个部分:
Show instance counts for all classes (excluding platform)。如下图:
Heap Histogram(显示堆直方图),如下图:
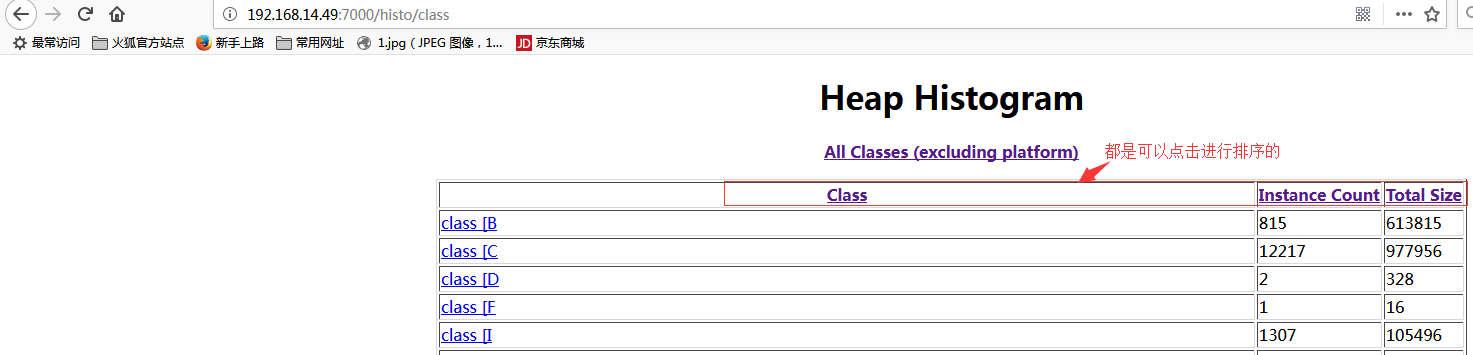
#具体排查时需要结合代码,观察是否大量应该被回收的对象在一直被引用或者是否有占用内存特别大的对象无法被回收。一般情况,转储文件会down到客户端用工具来分析。
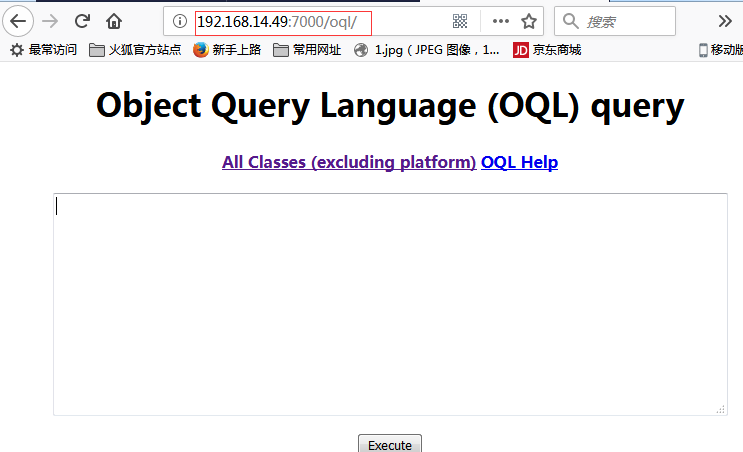
OQL:
jhat还提供了一种对象查询语言(Object Query Language),OQL有点类似SQL,可以用来查询。OQL语句的执行页面: http://localhost:7000/oql/。OQL帮助信息页面为: http://localhost:7000/oqlhelp/,OQL的语法可以在帮助页面查看,这里就不详细讲解了。
2.5 jstack
jstack用于生成java虚拟机当前时刻的线程快照。线程快照是当前java虚拟机内每一条线程正在执行的方法堆栈的集合,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。 线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源。 如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。另外,jstack工具还可以附属到正在运行的java程序中,看到当时运行的java程序的java stack和native stack的信息, 如果现在运行的java程序呈现hung的状态,jstack是非常有用的。
格式:
jstack [ options ] pid jstack [ options ] executable core jstack [ options ] [ server-id@ ] remote-hostname-or-IP #options : 命令行选项。 #pid : 堆栈跟踪打印的进程ID。 #executable : 从中生成核心转储的Java可执行文件。 #core : 要打印堆栈跟踪的核心文件。 #remote-hostname-or-IP : 远程调试服务器主机名或IP地址。 #server-id : 多个调试服务器在同一个远程主机上运行时使用的可选唯一标识。
option参数:
-F #当jstack [-l] pid没有响应时强制堆栈转储。 -l #除堆栈外,显示关于锁的附加信息。 -m #打印具有Java和本机C/C++框架的混合模式堆栈跟踪。 -h/-help #打印帮助说明
$ jstack -l 6483|more
2018-01-02 17:15:23 Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.74-b02 mixed mode): "IPC Parameter Sending Thread #10" #117 daemon prio=5 os_prio=0 tid=0x0000000000f51000 nid=0x7434 waiting on condition [0x00007f84e0836000] java.lang.Thread.State: TIMED_WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000000832ca590> (a java.util.concurrent.SynchronousQueue$TransferStack) at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215) at java.util.concurrent.SynchronousQueue$TransferStack.awaitFulfill(SynchronousQueue.java:460) at java.util.concurrent.SynchronousQueue$TransferStack.transfer(SynchronousQueue.java:362) at java.util.concurrent.SynchronousQueue.poll(SynchronousQueue.java:941) at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1066) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) Locked ownable synchronizers: - None......
#分析文章:http://www.hollischuang.com/archives/110
2.6 jinfo
jinfo(JVM Configuration info)这个命令作用是实时查看和调整虚拟机运行参数。之前的jps -v口令只能查看到显示指定的参数,如果想要查看未被显示指定的参数的值就要使用jinfo口令。
命令格式:
jinfo [ option ] pid jinfo [ option ] executable core jinfo [ option ] [ servier-id ] remote-hostname-or-IP #options : 命令行选项。 #pid : 堆栈跟踪打印的进程ID。 #executable : 从中生成核心转储的Java可执行文件。 #core : 要打印堆栈跟踪的核心文件。 #remote-hostname-or-IP : 远程调试服务器主机名或IP地址。 #server-id : 多个调试服务器在同一个远程主机上运行时使用的可选唯一标识。
OPTIONS选项:
no-option #打印命令行标志和系统属性name-value对。 -flag name #打印指定的命令行标志的名称和值。输出指定args参数的值。 -flag [+|-]name #启用或禁用指定的布尔命令行标志。 -flag name=value #将指定的命令行标志设置为指定的值。 -flags #打印传递给JVM的命令行标志。不需要args参数,输出所有JVM参数的值。 -sysprops #将Java系统属性打印为名称/值对。 -h/-help #打印帮助说明
示例:
$ jinfo -flags 6483 #打印pid是6483所有jvm的参数的值
转自:http://blog.51niux.com/?id=219

