
- 1【2024最新版】我用python代码带你看最绚烂的烟花,浪漫永不过时!_python2024
- 2PyCharm安装教程及基本使用(更新至2024年新版本),教你迈出学习python第一步
- 3小程序手机预览详情界面一直加载或者WebviewId_微信小程序webview一直加载中
- 4[c++] operator 运算符重载
- 5ubuntu20.04 NVIDIA显卡驱动安装教程(Y9000p)_nvidia显卡驱动 y9000p
- 6Vue 中文本内容超出规定行数后展开收起的处理_vue实现多行文字的展开收起
- 7Linux之进程间通信(system V 共享内存)
- 8Maven安装与eclipse配置和创建Maven项目教程【图文教学】_eclipse配置maven
- 905预测识别-依托YOLO V8进行训练模型的识别——对视频中的目标进行跟踪统计_yolov8 识别视频流
- 10C语言 字符串函数_hanshuti 字符串连接
全卷积网络Fully Convolutional Networks (FCN)实战
赞
踩
全卷积网络Fully Convolutional Networks (FCN)实战
使用图像中的每个像素进行类别预测的语义分割。全卷积网络(FCN)使用卷积神经网络将图像像素转换为像素类别。与之前介绍的卷积神经网络不同,FCN通过转置卷积层将中间层特征映射的高度和宽度转换回输入图像的大小,使得预测结果在空间维度(高度和宽度)与输入图像一一对应。给定空间维度上的位置,信道维度的输出将是对应于该位置的像素的类别预测。
将首先导入实验所需的包或模块,然后解释转置卷积层。
%matplotlib inline
from d2l
import mxnet as d2l
from mxnet
import gluon, image, init, np, npx
from mxnet.gluon
import nn
npx.set_np()
- Constructing a Model
展示了一个完全卷积网络模型的最基本设计。如图1所示,全卷积网络首先利用卷积神经网络提取图像特征,然后通过1×1卷积层将通道数转换为类别数,最后利用转置卷积层将特征映射的高度和宽度转换为输入图像的大小。模型输出与输入图像具有相同的高度和宽度,并且在空间位置上具有一对一的对应关系。最终输出信道包含对应空间位置的像素的类别预测。
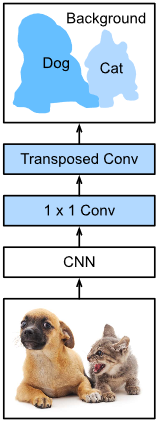
Fig. 1. Fully convolutional network.
下面,我们使用在ImageNet数据集上预先训练的ResNet-18模型来提取图像特征,并将网络实例记录为pretrained_net。如您所见,模型成员变量特性的最后两层是全局最大池化层GlobalAvgPool2D和示例展平层Flatten。输出模块包含用于输出的完全连接层。完全卷积网络不需要这些层。
pretrained_net = gluon.model_zoo.vision.resnet18_v2(pretrained=True)
pretrained_net.features[-4:], pretrained_net.output
(HybridSequential(
(0): BatchNorm(axis=1, eps=1e-05, momentum=0.9, fix_gamma=False, use_global_stats=False, in_channels=512)
(1): Activation(relu)
(2): GlobalAvgPool2D(size=(1, 1), stride=(1, 1), padding=(0, 0), ceil_mode=True, global_pool=True, pool_type=avg, layout=NCHW)
(3): Flatten
),
Dense(512 -> 1000, linear))
接下来,我们创建完全卷积的网络实例网。它复制了除预训练后的神经网络实例成员变量特征和预训练后得到的模型参数外的所有神经层。
net = nn.HybridSequential()
for layer in pretrained_net.features[:-2]:
net.add(layer)
当输入的高度和宽度分别为320和480时,网络的正向计算将使输入的高度和宽度减小到原来的1/32,即10和15。
X = np.random.uniform(size=(1, 3, 320, 480))
net(X).shape
(1, 512, 10, 15)
通过1×1卷积层将输出通道数转换为Pascal VOC2012(21)的类别数。最后,我们需要将特征图的高度和宽度放大32倍,以将它们变回输入图像的高度和宽度。依据卷积层输出形状的计算方法。因为(320−64+16×2+32)/32=10和(480−64+16×2+32)/32=15,我们构造了一个跨距为32的转置卷积层,并将卷积核的高度和宽度设置为64,填充为16。如果s的宽度和高度都是整数,那么s/2的卷积因子很难被放大。
num_classes = 21
net.add(nn.Conv2D(num_classes, kernel_size=1),
nn.Conv2DTranspose(
num_classes, kernel_size=64, padding=16, strides=32))
- 1
- 2
- 3
1.2. Initializing
the Transposed Convolution Layer
转置卷积层可以放大特征地图。在图像处理中,有时需要放大图像,即上采样。上采样的方法有很多种,最常用的方法是双线性插值。简单地说,为了在坐标(x,y)处获得输出图像的像素,首先将坐标映射到输入图像的坐标。
这可以根据三个输入的大小与输出大小的比率来实现。映射值x′还有y′ 通常是实数。然后,我们找到离坐标最近的四个像素(x′,y′)在输入图像上。最后,输出图像在坐标(x,y)处的像素,根据输入图像上的这四个像素及其与(x′,y′)的相对距离计算。双线性插值的上采样可以通过使用以下双线性核函数构造的卷积核的转置卷积层来实现。由于篇幅的限制,我们只给出了双线性_核函数的实现,而不讨论算法的原理。
def bilinear_kernel(in_channels, out_channels, kernel_size):
factor = (kernel_size + 1) // 2 if kernel_size % 2 == 1: center = factor - 1 else: center = factor - 0.5 og = (np.arange(kernel_size).reshape(-1, 1), np.arange(kernel_size).reshape(1, -1)) filt = (1 - np.abs(og[0] - center) / factor) * \ (1 - np.abs(og[1] - center) / factor) weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size)) weight[range(in_channels), range(out_channels), :, :] = filt return np.array(weight)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
将实验双线性插值上采样实现转置卷积层。构造一个转置卷积层,将输入的高度和宽度放大2倍,并用双线性_核函数初始化其卷积核。
conv_trans = nn.Conv2DTranspose(3, kernel_size=4, padding=1, strides=2)
conv_trans.initialize(init.Constant(bilinear_kernel(3, 3, 4)))
读取图像X并将上采样结果记录为Y。为了打印图像,需要调整通道尺寸的位置。
img = image.imread(’…/img/catdog.jpg’)
X = np.expand_dims(img.astype(‘float32’).transpose(2, 0, 1), axis=0) / 255
Y = conv_trans(X)
out_img = Y[0].transpose(1, 2, 0)
如您所见,转置卷积层将图像的高度和宽度都放大了2倍。值得一提的是,除了坐标比例尺不同外,双线性插值放大后的图像与原始图像看起来一样。
d2l.set_figsize((3.5, 2.5))
print(‘input image shape:’, img.shape)
d2l.plt.imshow(img.asnumpy());
print(‘output image shape:’, out_img.shape)
d2l.plt.imshow(out_img.asnumpy());
input image shape: (561, 728, 3)
output image shape: (1122, 1456, 3)

在完全卷积网络中,我们初始化转置卷积层以进行上采样双线性插值。对于1×1 卷积层,我们使用Xavier进行随机初始化。
W = bilinear_kernel(num_classes, num_classes, 64)
net[-1].initialize(init.Constant(W))
net[-2].initialize(init=init.Xavier())
1.3. Reading the Dataset
将随机裁剪的输出图像的形状指定为320×480,所以高度和宽度都可以被32整除。
batch_size, crop_size = 32, (320, 480)
train_iter, test_iter = d2l.load_data_voc(batch_size, crop_size)
Downloading …/data/VOCtrainval_11-May-2012.tar from http://d2l-data.s3-accelerate.amazonaws.com/VOCtrainval_11-May-2012.tar…
read 1114 examples
read 1078 examples
1.4. Training
可以开始训练模型了。这里的损失函数和精度计算与图像分类中使用的损失函数和精度计算没有实质性的不同。因为我们使用转置卷积层的通道来预测像素类别,所以在SoftmaxCrossEntropyLoss中指定了axis=1(通道尺寸)选项。此外,该模型还根据每个像素的预测类别是否正确来计算精度。
num_epochs, lr, wd, ctx = 5, 0.1, 1e-3, d2l.try_all_gpus()
loss = gluon.loss.SoftmaxCrossEntropyLoss(axis=1)
net.collect_params().reset_ctx(ctx)
trainer = gluon.Trainer(net.collect_params(), ‘sgd’,
{'learning_rate': lr, 'wd': wd})
- 1
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, ctx)
loss 0.331, train acc 0.890, test acc 0.841
290.4 examples/sec on [gpu(0), gpu(1)]

1.5. Prediction
在预测过程中,需要对每个通道的输入图像进行标准化,并将其转换为卷积神经网络所需的四维输入格式。
def predict(img):
X = test_iter._dataset.normalize_image(img)
X = np.expand_dims(X.transpose(2, 0, 1), axis=0)
pred = net(X.as_in_ctx(ctx[0])).argmax(axis=1)
- 1
- 2
- 3
- 4
- 5
return pred.reshape(pred.shape[1], pred.shape[2])
为了可视化每个像素的预测类别,我们将预测的类别映射回其在数据集中的标记颜色。
def label2image(pred):
colormap = np.array(d2l.VOC_COLORMAP, ctx=ctx[0], dtype='uint8')
X = pred.astype('int32')
return colormap[X, :]
- 1
- 2
- 3
- 4
- 5
测试数据集中图像的大小和形状各不相同。由于该模型使用了一个跨距为32的转置卷积层,当输入图像的高度或宽度不能被32整除时,转置卷积层输出的高度或宽度会偏离输入图像的大小。为了解决这个问题,我们可以在图像中裁剪多个高宽为32的整数倍的矩形区域,然后对这些区域中的像素进行正演计算。合并时,这些区域必须完全覆盖输入图像。当一个像素被多个区域覆盖时,不同区域的前向计算中输出的转置卷积层的平均值可以用作softmax操作的输入,以预测类别。
为了简单起见,我们只读取一些大的测试图像并裁剪出一个320×480形状的区域
从图像的左上角开始。仅此区域用于预测。对于输入图像,首先打印裁剪区域,然后打印预测结果,最后打印标签类别。
voc_dir = d2l.download_extract(‘voc2012’, ‘VOCdevkit/VOC2012’)
test_images, test_labels = d2l.read_voc_images(voc_dir, False)
n, imgs = 4, []
for i in range(n):
crop_rect = (0, 0, 480, 320)
X = image.fixed_crop(test_images[i], *crop_rect)
pred = label2image(predict(X))
imgs += [X, pred, image.fixed_crop(test_labels[i], *crop_rect)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
d2l.show_images(imgs[::3] + imgs[1::3] + imgs[2::3], 3, n, scale=2);

1.6. Summary
The fully convolutional
network first uses the convolutional neural network to extract image
features, then transforms the number of channels into the number of
categories through the 1×1 convolution layer, and
finally transforms the height and width of the feature map to the size of
the input image by using the transposed convolution layer to output the
category of each pixel.
In a fully convolutional
network, we initialize the transposed convolution layer for upsampled
bilinear interpolation.

