
- 1Mac篇3 安装flutter_mac 设置flutter pubcache
- 2VS Code一秒生成80%代码?鹅厂人真实感受_vscode 1.80
- 3JDK8的新特性--Lambda表达式_;&$clalho8&菧@mhvo)
- 4STC89C52RC单片机额外篇 03 - 认识C51编译器支持的数据类型_stc89c52rc的sfr_stc单片机定义code
- 5【NLP】新闻上的文本分类:机器学习大乱斗
- 6md语法模板。_md 模板
- 7Python数据分析速成课程_拯救者python期末张无忌免费
- 8DALL·E 2 论文阅读笔记_dalle论文
- 9【精通Spark系列】万事开头难?本篇文章让你轻松入门Spark_spark 系列文章_spark入门
- 10网络聊天程序的设计与实现——计网课设_基于winsocket的网络群聊程序的设计与实现
进阶分布式系统架构系列(三):Zookeeper 部署(单机与集群)实践
赞
踩
点击下方名片,设为星标!
回复“1024”获取2TB学习资源!
前面介绍了 Zookeeper 基础概念、应用场景等相关的知识点,今天我将详细的为大家介绍 Zookeeper 安装部署相关知识,希望大家能够从中收获多多!如有帮助,请点在看、转发支持一波!!!
Zookeeper 有三种部署模式:
单机部署:一台集群上运行;
集群部署:多台集群运行;
伪集群部署:一台集群启动多个 Zookeeper 实例运行。
下面就介绍一下这三种模式的部署过程。
Zookeeper 单机安装
环境准备
zookeeper服务器是用Java创建的,运行在JVM之上。需要安装JDK7以上版本(最好JDK8或以上)。
下载
官网下载地址:https://zookeeper.apache.org/releases.html
上传并安装
下载在本地之后可以把安装包上传到服务器或者虚拟机中,我使用的是服务器并远程shell连接
使用xshell 远程连接服务器,在opt目录下新建一个zookeeper目录 使用xftp将刚才下载的安装包上传到zookeeper目录下
使用xftp将刚才下载的安装包上传到zookeeper目录下 进入zookeeper目录下解压
进入zookeeper目录下解压
tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz
安装成功
配置
进入conf配置目录 zoo_sample.cfg就是配置文件,但是此文件不能生效,需要名称为zoo.cfg的文件才能生效。
zoo_sample.cfg就是配置文件,但是此文件不能生效,需要名称为zoo.cfg的文件才能生效。
改名复制一份配置文件
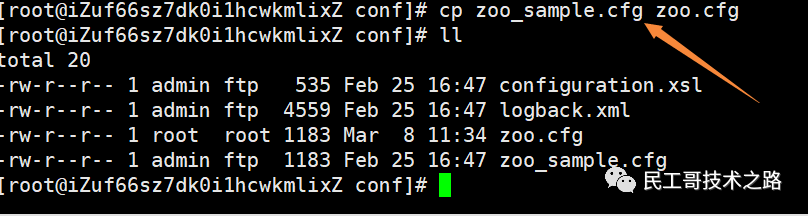 编辑配置文件zoo.cfg /tmp/zookeeper这个目录是zookeeper用于存储持久化的数据到本地的,但是服务器默认是没有的。
编辑配置文件zoo.cfg /tmp/zookeeper这个目录是zookeeper用于存储持久化的数据到本地的,但是服务器默认是没有的。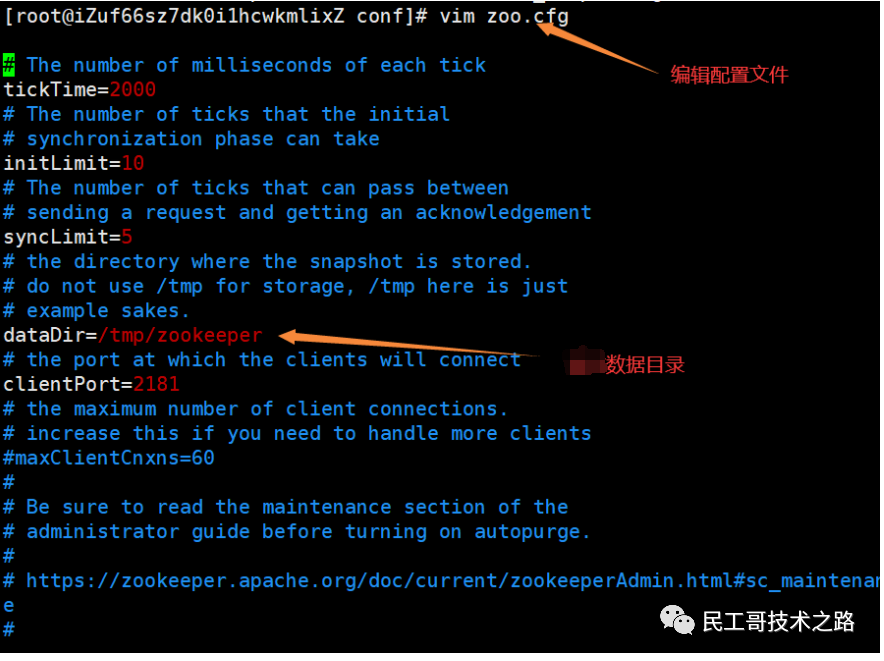 进入opt/zookeeper目录下,新建一个目录zkdata(目录名随意取)用于存放zookeeper的持久化数据。
进入opt/zookeeper目录下,新建一个目录zkdata(目录名随意取)用于存放zookeeper的持久化数据。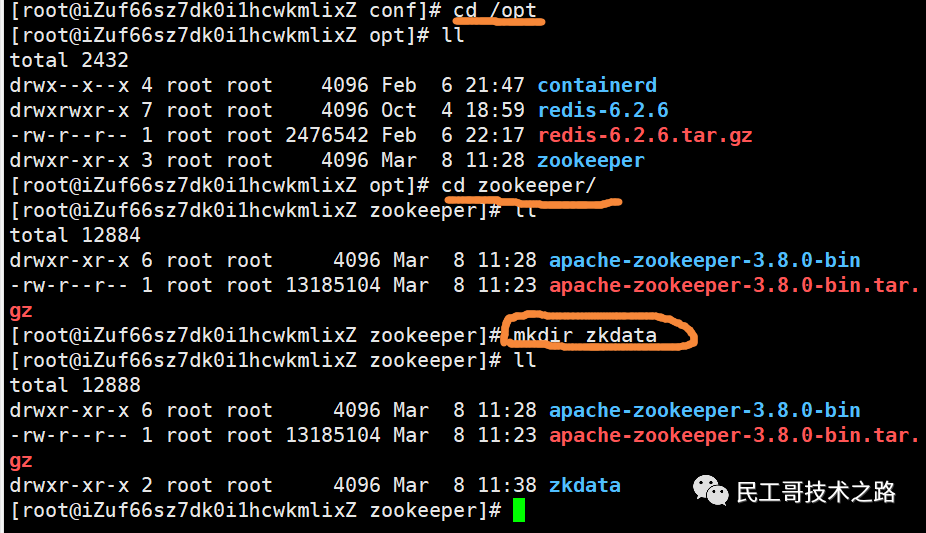 复制此目录/opt/zookeeper/zkdata,将zoo.cfg配置文件中的dataDir修改为/opt/zookeeper/zkdata。
复制此目录/opt/zookeeper/zkdata,将zoo.cfg配置文件中的dataDir修改为/opt/zookeeper/zkdata。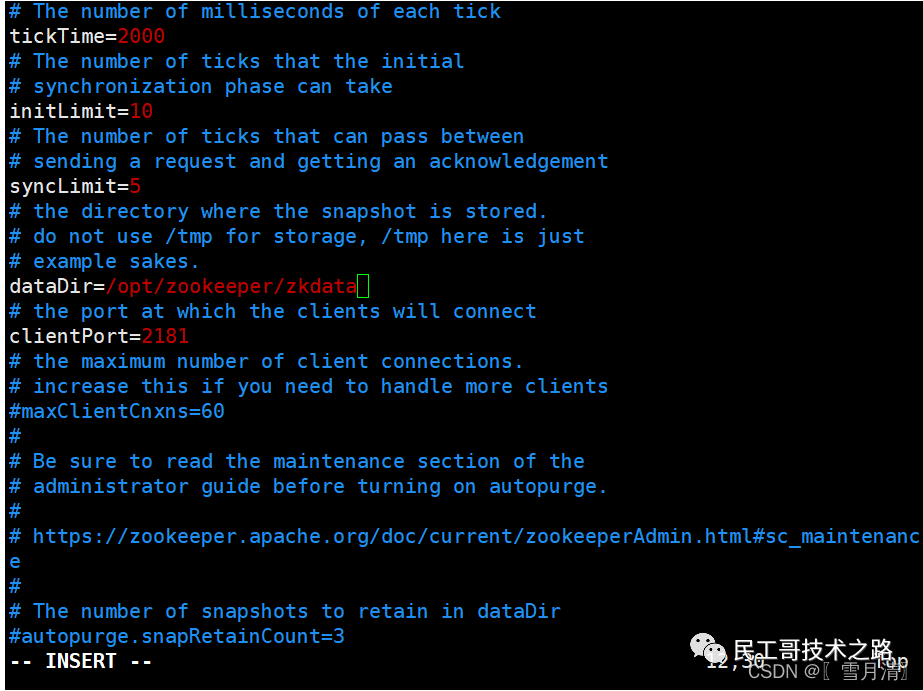 保存退出!
保存退出!
启动zookeeper
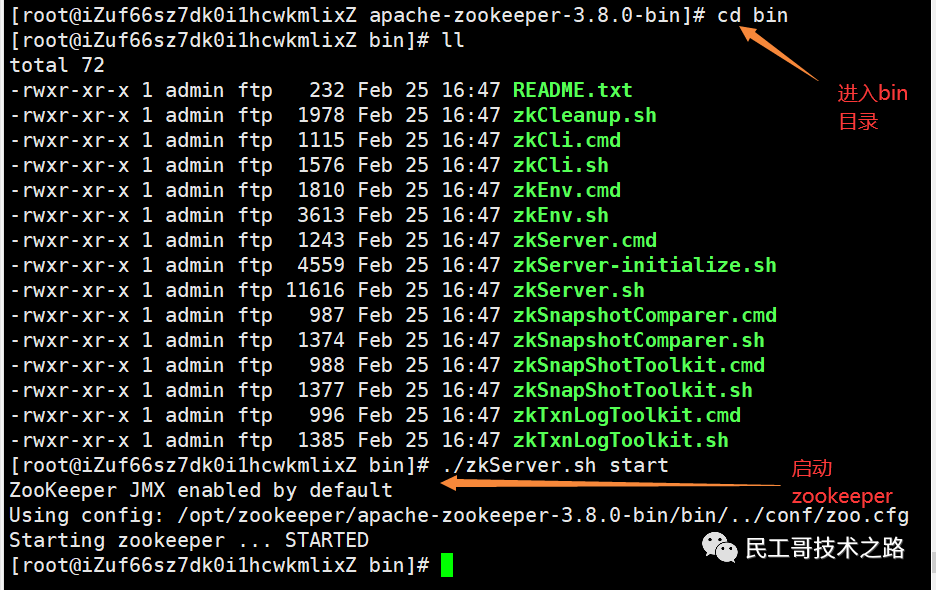 启动成功!
启动成功!
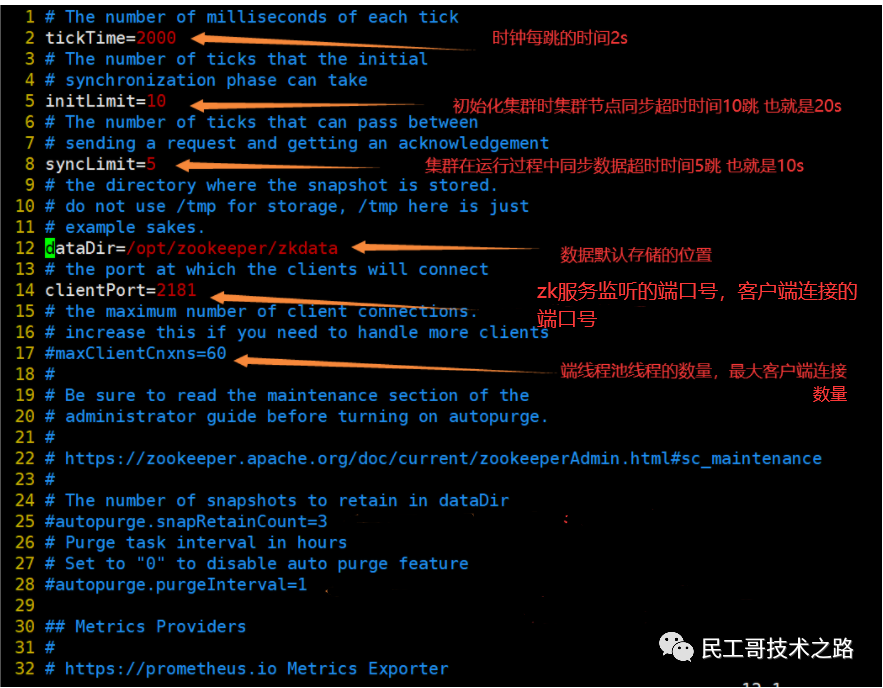
配置文件参数说明
集群部署
伪分布式部署
说明:伪分布即在一台服务器上通过不同端口模拟出分布式集群的效果,分布式一般 3 台起,一主两从。
说明:伪分布安装在了 Windows 开辟的虚拟机上,主机名为 bigdata。
将 zookeeper 安装包 zookeeper-3.4.10.tar.gz 导入 Linux。解压并重命名
- [root@bigdata ~]# cd /software/
- [root@bigdata software]# tar -zxvf zookeeper-3.4.10.tar.gz -C .
- [root@bigdata software]# mv zookeeper-3.4.10 zk
配置环境变量
- # /etc/profile
- export ZOOKEEPER_HOME=/software/zk
- export PATH=.:$PATH:$ZOOKEEPER_HOME/bin
备份及修改 zk 配置文件** zoo_sample.cfg.bak
- [root@bigdata software]# cd zk/conf
- [root@bigdata conf]# cp zoo_sample.cfg zoo1.cfg
- [root@bigdata conf]# vi zoo1.cfg # 修改该文件,注意一下两点即可,其他按默认即可
- # 客户端端口,三个节点需要指定不同端口避免端口冲突
- clientPort=2181
- # 存放数据的目录,自定义,后边创建
- dataDir=/software/zk/data/bigdata1
- # 服务器列表及端口,三个节点需要指定不同的端口避免端口冲突
- server.1=bigdata:2887:3887
- server.2=bigdata:2888:3888
- server.3=bigdata:2889:3889
说明1:需要修改或添加的配置项
修改
clientPort和dataDir下边三行是需要添加的,指定各节点信息端口,格式为:
server.id=hostname:port1:port2参数解释
- tickTime:#zk 服务器和客户端会话心跳超时间间隔,单位为毫秒
- initLimit:#在 zk follower 和 leader 之间进行数据同步最大超时次数,比如 initLimit = 5 ,tickTime = 2000,则允许最大延迟则为 5 * 2000 = 10000 毫秒
- syncLimit:#在 follower 和 leader 之间数据同步和消息发送时,请求和应答不能超过多少个 tickTIme
- dataDir:#zk 内部存储数据的磁盘位置,默认情况下 zk 的日志文件也保存在这个目录中。zk 运行期间会将数据存储在内存,保证访问速度
- server.x:#zk 的服务器列表,格式如下:server.x = hostname:port1:port2 ,x 为从 1 -N 的数字,说明该节点 zk 集群中的编号,该编号在 myid 中配置,hostname 为当前服务器主机名或 IP,port1 为 follower 和 leader 之间通讯端口,port2 为 leader 失效后选举端口
- myid:#在各自的 dataDir 目录中,内容就是当前服务器的编号
zoo1.cfg 配置完后为其他两个节点复制两份,并修改 clientPort 和 dataDir:
- [root@bigdata conf]# cp zoo1.cfg zoo2.cfg
- [root@bigdata conf]# cp zoo1.cfg zoo3.cfg
- [root@bigdata conf]# vi zoo2.cfg
- clientPort=2182
- dataDir=/software/zk/data/bigdata2
- [root@bigdata conf]# vi zoo3.cfg
- clientPort=2183
- dataDir=/software/zk/data/bigdata3
创建节点数据存放目录及 myid
根据 zoox.cfg 中 dataDir 创建目录
- [root@bigdata conf]# mkdir /software/zk/data
- [root@bigdata conf]# cd /software/zk/data
- [root@bigdata data]# mkdir bigdata1 bigdata2 bigdata3
- [root@bigdata data]# vi bigdata1/myid
- 1
- [root@bigdata data]# vi bigdata2/myid
- 2
- [root@bigdata data]# vi bigdata3/myid
- 3
启动 zk 并查看
- # 在 zk/bin 目录下
- zkServer.sh start zoo1.cfg
- zkServer.sh start zoo2.cfg
- zkServer.sh start zoo3.cfg
查看进程
- [root@bigdata zk]# jps
- 2320 Jps
- 2050 QuorumPeerMain
- 2008 QuorumPeerMain
- 1980 QuorumPeerMain
查看节点状态:一个 leader,两个 follower
- [root@bigdata zk]# bin/zkServer.sh status zoo1.cfg
- ZooKeeper JMX enabled by default
- Using config: /software/zk/bin/../conf/zoo1.cfg
- Mode: follower
- [root@bigdata zk]# bin/zkServer.sh status zoo2.cfg
- ZooKeeper JMX enabled by default
- Using config: /software/zk/bin/../conf/zoo2.cfg
- Mode: leader
- [root@bigdata zk]# bin/zkServer.sh status zoo3.cfg
- ZooKeeper JMX enabled by default
- Using config: /software/zk/bin/../conf/zoo3.cfg
- Mode: follower
根据 zk 选举机制,一共 3 台,当第二台启动后就会根据 serverid 选举出 myid 大的作为 leader,myid 小的和第三台作为 follower。
图示: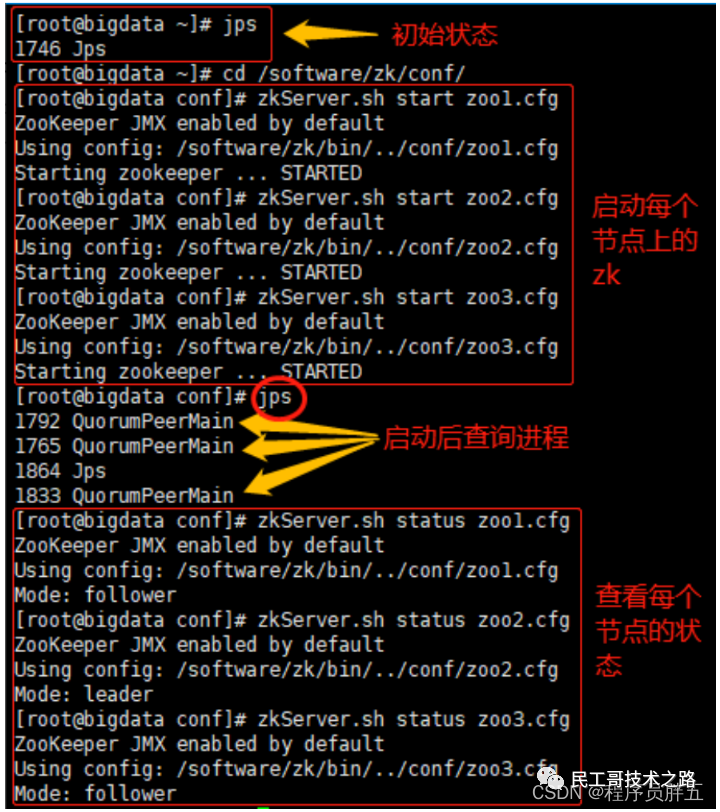
分布式集群安装
上传解压名命名
- # 将zookeeper解压后文件夹重命名为zk
- mv zookeeper-3.4.10.tar.gz /software
- tar -zxvf zookeeper-3.4.10.tar.gz
- mv zookeeper-3.4.10 zk
配置环境变量
- export ZOOKEEPER_HOME=/software/zk
- export PATH=.:$PATH:$ZOOKEEPER_HOME/bin
- # 配置完source一下,使其生效:
- source /etc/profile
修改配置文件
- cd /software/zk/conf
- mv zoo_sample.cfg zoo.cfg
- vi zoo.cfg
- # 在 /software/zk/ 下创建zk的数据存放目录data,并配置到此
- dataDir=/software/zk/data
- # 在最后添加上以下内容,其中2888是通讯端口,3888是选举端口
- server.0=hadoop0:2888:3888
- server.1=hadoop1:2888:3888
- server.2=hadoop2:2888:3888
配置 myid
- mkdir /software/zk/data
- cd /software/zk/data
- vi myid
- # 把 0 写到该文件的最上边,Hadoop1的就写1,Hadoop2的就写2
复制到其他节点上
若 zk 在之前就安装好了,只需修改配置文件和创建 ZooKeeper 的数据存放目录
环境变量的赋值
按 serverID 命名须知,修改 /etc/myid 里的数值(myid 就是 serverID,0~255)
关闭防火墙和 selinux
- # 查看防火墙状态
- systemctl status firewalld.service
- # 停止防火墙命令
- systemctl stop firewalld
- # 开机禁止启动命令
- systemctl disable firewalld
-
- # 查看selinux状态,非 disabled 则需要禁用
- sestatus
- # 修改selinux配置文件
- vi /etc/selinux/config
- sed -i 's/^SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
- # 然后重启机器
- reboot
启动测试
分别在三台机器下启动
- cd /software/zk/bin # 配置了zk的环境变量可以不切到该目录,在任意目录执行start都可以
- zkServer.sh start
- # 查看服务器的各个角色:
- zkServer.sh status
- 有Follower、Leader等等
说明:
leader不一定是在第一个节点上面,是由 Zookeeper 内部的选举机制产生的QuorumPeerMain进程是 ZooKeeper 的进程名字
集群中有哪些角色?
在一个集群中,最少需要 3 台。或者保证 2N + 1 台,即奇数。为什么保证奇数?主要是为了举算法。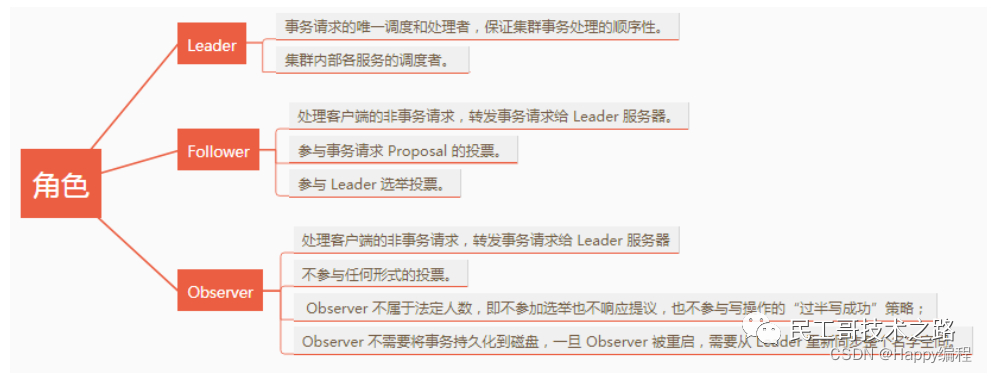
Zookeeper集群中是怎样选举leader的?
流程:开始投票 -> 节点状态变成 LOOKING -> 每个节点选自己-> 收到票进行 PK -> sid 大的获胜 -> 更新选票 -> 再次投票 -> 统计选票,选票过半数选举结果 -> 节点状态更新为自己的角色状态。
当Leader崩溃了,或者失去了大多数的Follower,这时候 Zookeeper 就进入恢复模式,恢复模式需要重新选举出一个新的Leader,让所有的Server都恢复到一个状态LOOKING 。Zookeeper 有两种选举算法:基于 basic paxos 实现和基于 fast paxos 实现。
Zookeeper 是如何保证事务的顺序一致性的呢?
Zookeeper 采用了递增的事务 id 来识别,所有的 proposal (提议)都在被提出的时候加上了zxid 。zxid 实际上是一个 64 位数字。高 32 位是 epoch 用来标识 Leader 是否发生了改变,如果有新的Leader 产生出来, epoch 会自增。低 32 位用来递增计数。当新产生的 proposal 的时候,会依据数据库的两阶段过程,首先会向其他的 Server 发出事务执行请求,如果超过半数的机器都能执行并且能够成功,那么就会开始执行。
ZooKeeper集群中个服务器之间是怎样通信的?
Leader 服务器会和每一个 Follower/Observer 服务器都建立 TCP 连接,同时为每个Follower/Observer 都创建一个叫做 LearnerHandler 的实体。LearnerHandler 主要负责 Leader 和Follower/Observer 之间的网络通讯,包括数据同步,请求转发和 proposal 提议的投票等。Leader 服务器保存了所有 Follower/Observer 的 LearnerHandler 。
参考文章:https://blog.csdn.net/weixin_45579026/article
/details/131080333 https://blog.csdn.net/qq_52595134/
article/details/123467180
读者专属技术群
构建高质量的技术交流社群,欢迎从事后端开发、运维技术进群(备注岗位,已在技术交流群的请勿重复添加)。主要以技术交流、内推、行业探讨为主,请文明发言。广告人士勿入,切勿轻信私聊,防止被骗。
扫码加我好友,拉你进群

推荐阅读 点击标题可跳转

PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧!

