
- 1高级DBA带你处理Mysql数据库10亿大数据条件下迁移实战_数据库迁移
- 2学习智能指针_智能指针的学习
- 3Android 8.0 Activity 启动流程_handleincominguser
- 4利用线程池优化大批量数据库操作_使用java线程池优化for循环
- 5vrep+matlab_vrep 观测末端轨迹
- 6【windows折腾日记】装系统教学,手把手教怎么制作U盘启动系统盘,Ventoy工具下载和使用_ventoy制作启动u盘
- 7windows下不同python版本切换_window切换python版本
- 8开源照片管理服务LibrePhotos
- 9使用py2neo将csv导入neo4j_neo4j导入csv文件创建关系
- 102024年网安最全万字长文,自学网络安全详细路线图来了_网络安全自学路线图
spark的安装与部署_spark安装
赞
踩
目录
前言
为了避免MapReduce框架中多次读写磁盘带来的消耗,以及更充分地利用内存,加州大学伯克利分校的AMP Lab提出了一种新的、开源的、类Hadoop MapReduce的内存编程模型Spark。
一、spark是什么?
Spark是一个基于内存的大数据并行处理框架,其最初由加州大学伯克利分校的AMP Lab研发,现已成为Apache软件基金会的顶级项目之一。Spark不仅提供了可扩展、高容错、高性能的分布式数据处理,还提供了内存级的数据处理。
机器学习的Spark由4个主要组件组成,包括提供交互式数据查询的Spark SQL、实时计算的Spark Streaming、MLlib和图处理的GraphX
Spark与Hadoop类似,但又与Hadoop的数据处理方式不同。
1.Spark的中间结果并没有保存在HDFS中,而是存放在内存中;
2.Spark简化了数据处理流程,从而避免了不必要的排序所带来的开销
3.Hadoop仅支持Java一种编程语言,而Spark的API支持多种编程语言,包括Scala、Java、 Python和R.
二、知识回顾
1.启动zookeeper。
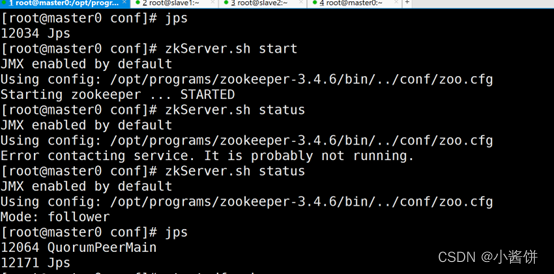
2.启动hdfs和yarn。

3.通过jps查看是否启动成功。

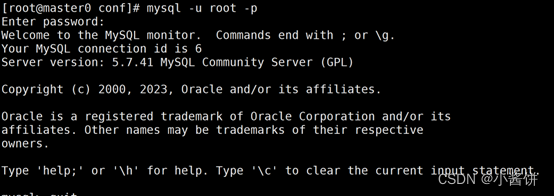
4.进入MySQL。
5.进入hive之后验证
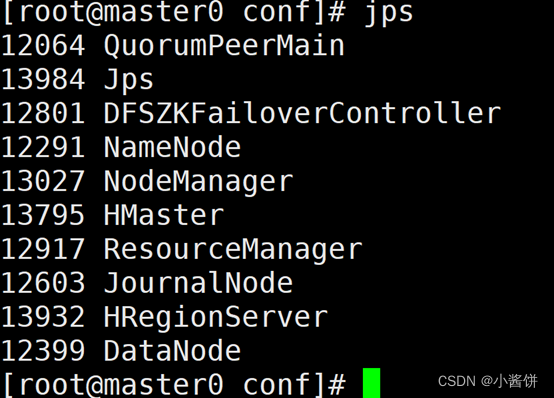
6.启动hbase.

7.查看进程
8.进入hbase并测试是否正常

三、spark的安装与部署
1.安装Scala
1>使用WinSCP软件将下载的Scala安装包上传到master0虚拟机的“/opt/packages” 目录下,然后执行以下命令进入该目录:
# cd /opt/packages
2>执行以下命令,将解压到目录“/opt/programs”下
# tar -zxvf scala-2.12.11.tgz -C /opt/programs

3>修改文件“/etc/profile”配置Scala环境变量
# vim /etc/profile4>在文件末尾加入以下内容
- export SCALA_HOME=/opt/programs/scala-2.12.11
- export PATH=$PATH:$SCALA_HOME/bin

5>然后执行以下命令,刷新profile文件,使修改生效:
# source /etc/profile
6>执行“scala -version”命令,若能输出以下版本信息,则说明安装成功:
![]()
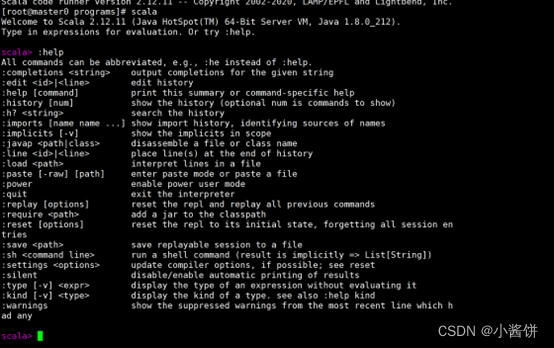
此时,执行“scala”命令,可以进入Scala的命令行模式,在此可以编写Scala表达式和程序。若要查看常用命令可执行“:help”命令;若要退出,可执行:quit”命令。
2.安装与部署spark
在之前搭建好的Hadoop高可用分布式集群 (由master0,slave1和slave2节点组成)之上,演示Spark完全分布式模式的安装方法。
1>使用 WinSCP 软件将下载的 spark安装包 spark-2.1.1-bin-hadoop2.7.tgz上传master0 节点的“/opt/packages”目录下,然后执行以下命令进入该目录
[root@master0 ~]# cd /opt/packages
2>执行以下命令,将解压到目录“/opt/programs”下:
# tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/programs
3>进入Spark安装目录下的“conf”文件夹,将文件复制一份并重命名为spark-envsh:
# cp spark-env.sh.template spark-env.sh
4>再执行以下命令,修改spark-env.sh文件
# vim spark-env.sh
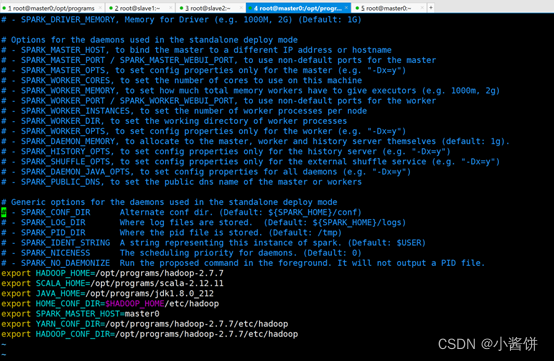

5>在文件末尾加入以下内容
- export SPARK_HOME=/opt/programs/spark-2.1.1-bin-hadoop2.7
- export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH

6>执行以下命令,将slaves.template文件复制一份并重命名为slaves:
# cp slaves.template slaves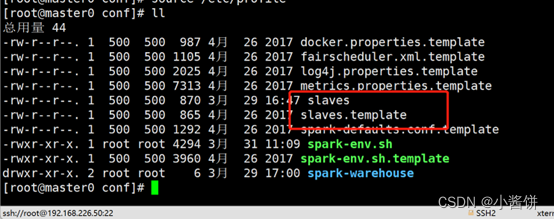
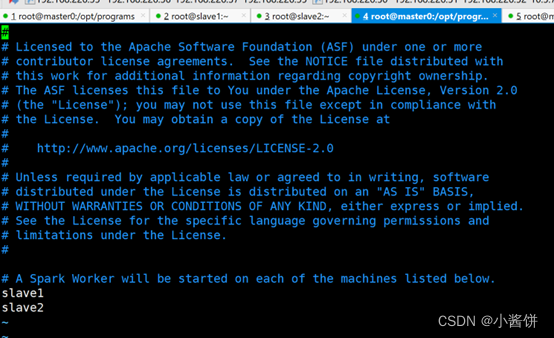
7>再执行以下命令,修改slaves文件
# vim slaves
将文件内容修改为:
slave1
slave2
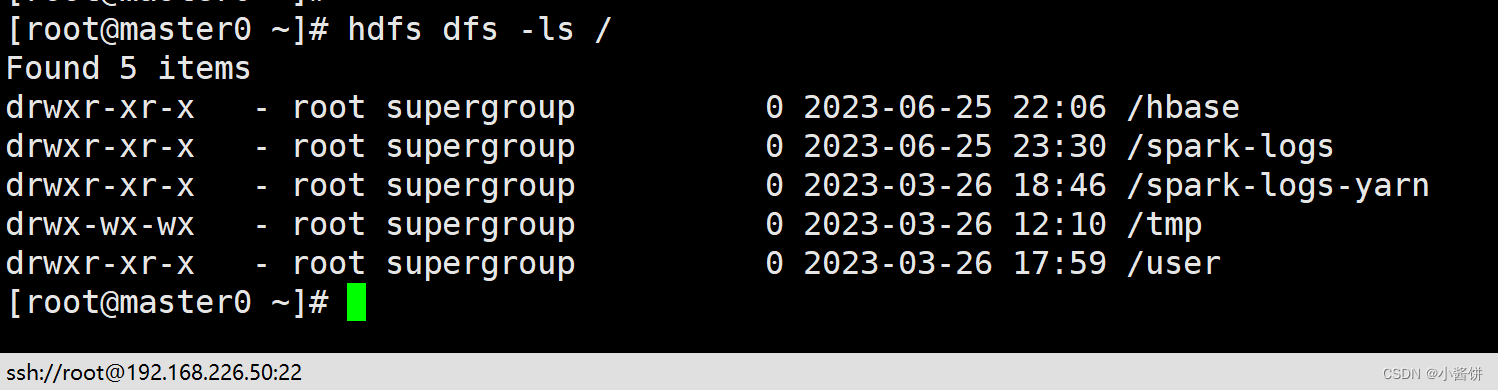
8>.创建spark-logs目录。

查看是否创建成功
9>执行以下命令,将master0节点的整个Spark安装目录远程复制到slave1和slave2节点
- # scp -r /opt/programs/spark-2.1.1-bin-hadoop2.7 root@slave1:/opt/programs/
- # scp -r /opt/programs/spark-2.1.1-bin-hadoop2.7 root@slave2:/opt/programs/



查看进程。

9>启动spark集群。(先启动zookeeper以及Hadoop)
并查看是否有worker进程。
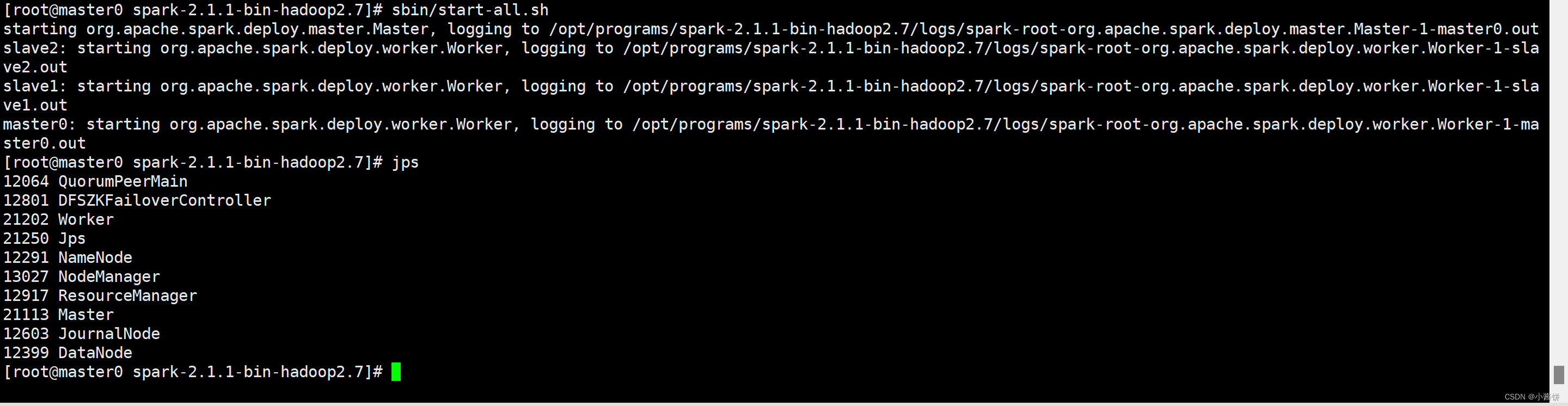

10>执行“bin/spark-shell”命令,可以启动Spark Shell。此时打开浏览器,访问“http://hadoop01:8080”,可以查看Spark集群的运行状态

11>启动spark集群。

总结
Spark是一个高性能、易于使用的开源平台,它既为用户提供了批处理功能,又为用户提供了基于内存的实时数据处理和分析功能。此外,Spark还是一个支持迭代和交互式计算的通用计算引擎。
本文仅简单介绍spark的安装与部署。

