
热门标签
热门文章
- 1windows环境下python安装pycrypto遇到的问题解决_windows python2.7 pycrypto==2.6.1报错
- 2从零搭建若依(Ruoyi-Vue)管理系统(13)--登录和鉴权的实现_ruoyi-vue s
- 3使用DockerUI结合内网穿透工具轻松实现公网访问和管理docker容器_docker内网穿透插件
- 4java如何验证时间合法性_java判断日期是否合法
- 5Android卡顿原理分析和SurfaceFlinger,Surface概念简述_android surface 渲染慢
- 6【Pandas】Python数据分析活用Pandas库学习笔记(一)_python数据分析活用pandas库 pdf
- 7百度发布文心一言!对比GPT-4实测!百度顶住压力,背水一战
- 8python基础学习——字符串格式化
- 9ubuntu下docker: Error response from daemon: could not select device driver with capabilities: [[gpu]]_"docker: error response from daemon: could not sel
- 10常见的网络安全威胁和防护方法
当前位置: article > 正文
python获取知乎问题答案并转换为MarkDown文件
作者:盐析白兔 | 2024-02-10 13:45:56
赞
踩
python获取知乎问题答案并转换为MarkDown文件
前期准备
- python2.7
- html2text
- markdownpad(这里随意,只要可以支持md就行)
- 会抓包
- 最重要的是你要有代理,因为知乎开始封IP了
原理
原理说起来很简单:获取请求到的内容的BODY部分,然后重新构建一个HTML文件,接着利用html2text这个模块将其转换为markdown文件,最后对图片及标题按照markdown的格式做一些处理就好了。目前应用的场景主要是在知乎。
代码实现
获取知乎答案
写代码的时候,主要考虑了两种使用场景。第一,获取某一特定答案的数据然后进行转换;第二,获取某一个问题的所有答案进行然后挨个进行转换,在这里可以 通过赞同数来对要获取的答案进行质量控制。
某一个特定答案的数据获取
url:https://www.zhihu.com/question/27621722/answer/48658220
'''
(前面那个是问题ID,后边的是答案ID)
'''
- 1
- 2
- 3
- 4
这一数据的获取我这里分为了两个部分,第一部分请求上述网址,拿到答案主体数据以及赞同数,第二部分请求下面这个接口:
https://www.zhihu.com/api/v4/answers/48658220
- 1
为什么会这样?因为这个接口得到的答案正文数据不是完整数据,所以只能分两步了。
某一个特定答案的数据获取
这一个数据就可以通过很简单的方式得到了,接口如下:
https://www.zhihu.com/api/v4/questions/27621722/answers?sort_by=default&include=data%5B%2A%5D.is_normal%2Cis_collapsed%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Cmark_infos%2Ccreated_time%2Cupdated_time%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cupvoted_followees%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics&limit=20&offset=3
- 1
返回的都是JSON数据,很方便获取。但是这里有一个地方需要注意,从这里面取的答案正文数据就是文本数据,不是一个完整的html文件,所以需要在构造一下。
保存的字段
- author_name 回答用户名
- answer_id 答案ID
- question_id 问题ID
- question_title 问题
- vote_up_count 赞同数
- create_time 创建时间
- 答案主体
主脚本:zhihu.py
import os import re import json import requests import html2text from parse_content import parse ''' 更多Python学习资料以及源码教程资料,可以在群1136201545免费获取 ''' """ just for study and fun Talk is cheap show me your code """ class ZhiHu(object): def __init__(self): self.request_content = None def request(self, url, retry_times=10): header = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36', 'authorization': 'oauth c3cef7c66a1843f8b3a9e6a1e3160e20', 'Host': 'www.zhihu.com' } times = 0 while retry_times>0: times += 1 print 'request %s, times: %d' %(url, times) try: ip = 'your proxy ip' if ip: proxy = { 'http': 'http://%s' % ip, 'https': 'http://%s' % ip } self.request_content = requests.get(url, headers=header, proxies=proxy, timeout=10).content except Exception, e: print e retry_times -= 1 else: return self.request_content def get_all_answer_content(self, question_id, flag=2): first_url_format = 'https://www.zhihu.com/api/v4/questions/{}/answers?sort_by=default&include=data%5B%2A%5D.is_normal%2Cis_collapsed%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Cmark_infos%2Ccreated_time%2Cupdated_time%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cupvoted_followees%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics&limit=20&offset=3' first_url = first_url_format.format(question_id) response = self.request(first_url) if response: contents = json.loads(response) print contents.get('paging').get('is_end') while not contents.get('paging').get('is_end'): for content in contents.get('data'): self.parse_content(content, flag) next_page_url = contents.get('paging').get('next').replace('http', 'https') contents = json.loads(self.request(next_page_url)) else: raise ValueError('request failed, quit......') def get_single_answer_content(self, answer_url, flag=1): all_content = {} question_id, answer_id = re.findall('https://www.zhihu.com/question/(\d+)/answer/(\d+)', answer_url)[0] html_content = self.request(answer_url) if html_content: all_content['main_content'] = html_content else: raise ValueError('request failed, quit......') ajax_answer_url = 'https://www.zhihu.com/api/v4/answers/{}'.format(answer_id) ajax_content = self.request(ajax_answer_url) if ajax_content: all_content['ajax_content'] = json.loads(ajax_content) else: raise ValueError('request failed, quit......') self.parse_content(all_content, flag, ) def parse_content(self, content, flag=None): data = parse(content, flag) self.transform_to_markdown(data) def transform_to_markdown(self, data): content = data['content'] author_name = data['author_name'] answer_id = data['answer_id'] question_id = data['question_id'] question_title = data['question_title'] vote_up_count = data['vote_up_count'] create_time = data['create_time'] file_name = u'%s--%s的回答[%d].md' % (question_title, author_name,answer_id) folder_name = u'%s' % (question_title) if not os.path.exists(os.path.join(os.getcwd(),folder_name)): os.mkdir(folder_name) os.chdir(folder_name) f = open(file_name, "wt") f.write("-" * 40 + "\n") origin_url = 'https://www.zhihu.com/question/{}/answer/{}'.format(question_id, answer_id) f.write("## 本答案原始链接: " + origin_url + "\n") f.write("### question_title: " + question_title.encode('utf-8') + "\n") f.write("### Author_Name: " + author_name.encode('utf-8') + "\n") f.write("### Answer_ID: %d" % answer_id + "\n") f.write("### Question_ID %d: " % question_id + "\n") f.write("### VoteCount: %s" % vote_up_count + "\n") f.write("### Create_Time: " + create_time + "\n") f.write("-" * 40 + "\n") text = html2text.html2text(content.decode('utf-8')).encode("utf-8") # 标题 r = re.findall(r'\*\*(.*?)\*\*', text, re.S) for i in r: if i != " ": text = text.replace(i, i.strip()) r = re.findall(r'_(.*)_', text) for i in r: if i != " ": text = text.replace(i, i.strip()) text = text.replace('_ _', '') # 图片 r = re.findall(r'!\[\]\((?:.*?)\)', text) for i in r: text = text.replace(i, i + "\n\n") f.write(text) f.close() if __name__ == '__main__': zhihu = ZhiHu() url = 'https://www.zhihu.com/question/27621722/answer/105331078' zhihu.get_single_answer_content(url) # question_id = '27621722' # zhihu.get_all_answer_content(question_id)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
zhihu.py为主脚本,内容很简单,发起请求,调用解析函数进行解析,最后再进行保存。
解析函数脚本:parse_content.py
import time from bs4 import BeautifulSoup ''' 更多Python学习资料以及源码教程资料,可以在群1136201545免费获取 ''' def html_template(data): # api content html = ''' <html> <head> <body> %s </body> </head> </html> ''' % data return html def parse(content, flag=None): data = {} if flag == 1: # single main_content = content.get('main_content') ajax_content = content.get('ajax_content') soup = BeautifulSoup(main_content.decode("utf-8"), "lxml") answer = soup.find("span", class_="RichText CopyrightRichText-richText") author_name = ajax_content.get('author').get('name') answer_id = ajax_content.get('id') question_id = ajax_content.get('question').get('id') question_title = ajax_content.get('question').get('title') vote_up_count = soup.find("meta", itemprop="upvoteCount")["content"] create_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(ajax_content.get('created_time'))) else: # all answer_content = content.get('content') author_name = content.get('author').get('name') answer_id = content.get('id') question_id = content.get('question').get('id') question_title = content.get('question').get('title') vote_up_count = content.get('voteup_count') create_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(content.get('created_time'))) content = html_template(answer_content) soup = BeautifulSoup(content, 'lxml') answer = soup.find("body") print author_name,answer_id,question_id,question_title,vote_up_count,create_time # 这里非原创,看了别人的代码,修改了一下 soup.body.extract() soup.head.insert_after(soup.new_tag("body", **{'class': 'zhi'})) soup.body.append(answer) img_list = soup.find_all("img", class_="content_image lazy") for img in img_list: img["src"] = img["data-actualsrc"] img_list = soup.find_all("img", class_="origin_image zh-lightbox-thumb lazy") for img in img_list: img["src"] = img["data-actualsrc"] noscript_list = soup.find_all("noscript") for noscript in noscript_list: noscript.extract() data['content'] = soup data['author_name'] = author_name data['answer_id'] = answer_id data['question_id'] = question_id data['question_title'] = question_title data['vote_up_count'] = vote_up_count data['create_time'] = create_time return data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
parse_content.py主要负责构造新的html,然后对其进行解析,获取数据。
测试结果展示
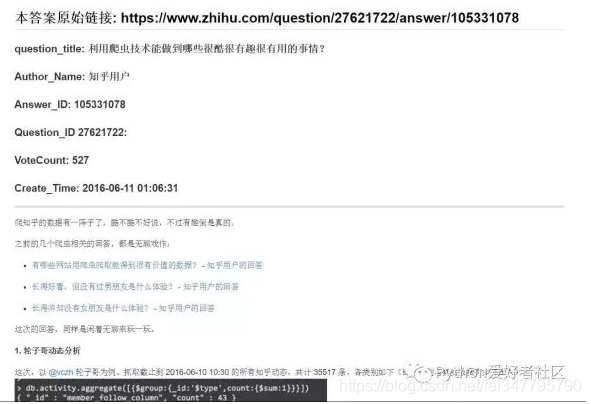
一定要联网!
一定要联网!
一定要联网!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/74360
推荐阅读
相关标签

