
- 1树莓派-系统安装&连接无线&远程连接_连接树莓派
- 2区块链创新:探索 Web3 的去中心化应用_web3应用案例
- 3补番推荐_补番加油站
- 4Git | git push -u origin main 报错 unable to access‘https://****.git‘Recv failure:Connection was reset_$ git push origin main fatal: unable to access
- 5太高效!ChatGPT论文润色攻略_chatgpt3.5英文论文润色
- 6数据库MySQL(笔记)_编写mysql语句,创建名为datab1的数据库
- 7支持多样化同步需求的增量数据同步方案,了解一下
- 8开源模型应用落地-Gradio正确集成Fastapi-助力模型交互-入门篇(一)_gradio fastapi
- 9Elasticsearch中的post_filter后置过滤器技术
- 10架构设计内容分享(四十三):千万级连接,知乎如何架构长连接网关?
hiveSQL常见函数及用法(持续收集)_hive sql
赞
踩
1,时间函数

2,聚合函数
注意:聚合函数常与 SELECT 语句的 GROUP BY 子句一块儿使用。换句话说使用聚合函数时,一个列字段要不在group by里,要没必要须在聚合函数里面,不能单独出现,不然报错。

3,字符串函数

4,连接函数

5,其他函数
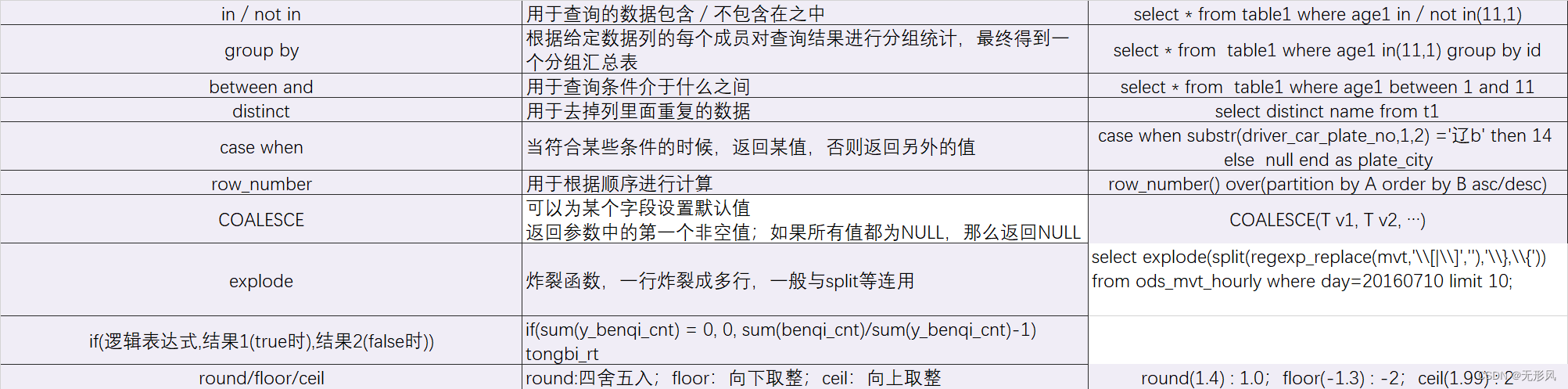
6,窗口函数
1,lead(col,n,m) over(partition by … order by …):
其中col是要取的字段,n是取排序后的第几条记录;m是缺省值,如果后面的记录取不到值就去m,m的数据类型要和col一致,不然会报错,m可不填值,默认为空
2,lag() over(partition by … order by …)
与lead() over(partition by … order by …)相似,只是去上一条记录的某字段;
3,ROW_NUMBER()
为每一组的行按顺序生成一个连续序号。
4,RANK()
也为每一组的行生成一个序号,与ROW_NUMBER()不同的是如果按照ORDER BY的排序,如果有相同的值会生成相同的序号,并且接下来的序号是不连序的。例如两个相同的行生成序号2,那么接下来会生成序号4
5,DENSE_RANK()
和RANK()类似,不同的是如果有相同的序号,那么接下来的序号不会间断。也就是说如果两个相同的行生成序号2,那么接下来生成的序号还是3。
注意:3,4,5都属于排名开窗函数,ORDER BY 指定排名开窗函数的顺序,在排名开窗函数中必须使用ORDER BY语句。
6,Hive-sql特点和sql的区别
1、Hive不支持等值连接
不支持等值连接,一般使用left join、right join 或者inner join替代。
SQL中内关联可以这样写: select * from a , b where a.key = b.key
Hive中应该这样写: select * from a join b on a.key = b.key
hive中不能使用省去join的写法。
- 1
- 2
- 3
2、分号字符
分号是sql语句的结束符号,在hive中也是,但是hive对分号的识别没有那么智能,有时需要进行转义 “;” --> “\073”
3、NULL
sql中null代表空值,但是在Hive中,String类型的字段若是空(empty)字符串,即长度为0,那么对它 is null 判断结果为False
4、Hive不支持将数据插入现有的表或分区中
Hive仅支持覆盖重写整个表。
insert overwrite 表 (重写覆盖)
5、Hive不支持 Insert into 表 Values(), UPDATA , DELETE 操作
insert into 就是往表或者分区中追加数据。
6、Hive支持嵌入mapreduce程序,来处理复杂的逻辑
7、Hive支持将转换后的数据直接写入不同的表,还能写入分区,hdfs和本地目录
避免多次扫描输入表的开销。

