
- 1云栖专辑 | 阿里开发者们的第12个感悟:多维思考,胜过盲目苦干_阿里巴巴 多维度思考例子
- 2(idea)利用SpringSecurity完成登录验证的流程_security登录验证
- 3电脑ffmpeg.dll丢失原因解析,找不到ffmpeg.dll的5种解决方法
- 43. Git_3.git
- 5Eureka入门_eurka
- 6从零开始研发GPS接收机连载——11、电文解析_开源导航接收机解读
- 7入职后的代码拉取及运行:_第一天上班git怎么拉项目
- 8版本管理工具 SVN和git
- 9《数据分析-JiMuReport》积木报表详细入门教程
- 10android串口通信——android-serialport-api
详细介绍NLP文本分类_nlp文本分类算法
赞
踩
基于统计方法的文本分类
基于统计方法的文本分类是文本分类的主要方法之一。统计方法首先是对原始输入数据进行预处理,一般包括分词、数据清洗和数据统计等,然后人工抽取特征并选择具体的统计模型设计分类算法。
根据需要还可能进行特征选择和特征提取,常用的特征选择算法有文档频率、期望交叉熵、互信息等,特征提取转换原始的特征空间生成新的语义空间,能够较好地解决一词多义、一义多词等问题。
常用的统计模型包括朴素贝叶斯算法、支持向量机算法等。
朴素贝叶斯定理:
条件概率:事件A在另外一个事件B已经发生条件下的发生概率。条件概率表示为P(A|B),读作“在B条件下A的概率”
先验概率:是指根据以往经验和分析得到的概率,它往往作为"由因求果"问题中的"因"出现的概率
后验概率:要以先验概率为基础。后验概率可以根据通过贝叶斯公式,用先验概率和似然函数计算出来
朴素贝叶斯定理公式: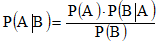
朴素贝叶斯可以简单杯理解为:
朴素贝叶斯分类:
朴素贝叶斯分类是一种十分简单的分类算法,基于朴素贝叶斯算法原理进行文本分类:对于给出的待分类文本(假设是一条句子,或者一段文字),抽取它的文本特征(例如主题词),然后求解在该特征出现的条件下属于各个类别的概率,哪个最大,就认为此待分类文本属于哪个类别。
案例分析:
给定一段文档“在刚刚结束的一场 NBA 常规赛中,金州勇士队球星库里拿到了其个人职业生涯最高分,并带队取得胜利”。假设我们通过主题词抽取算法抽出的主题词为“NBA常规赛”“金州勇士”和“库里”,接下来我们要对这段文档进行文本分类,假设待选分类只有“体育新闻”和“娱乐新闻”两种类别,那么在新闻类别分类中,很显然,根据下面的公式,由于“体育新闻”中“NBA 常规赛”、“金州勇士”和“库里”等词出现的概率远远高于“娱乐新闻”中这些词的出现概率,因此该文档会大概率被分为“体育新闻”。

优点:
(1)对小规模的数据表现很好,能够处理多分类任务,适合增量式训练
(2)对缺失数据不太敏感,算法也比较简单,有稳定的分类效率。
缺点:
(1)理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
(2)需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此 在某些时候会由于假设的先验模型导致预测效果不佳。
(3)由于我们是通过先验和数据来决定后验的概率从而决定分类,因此分类决策存在一定的错误率。
基于朴素贝叶斯的文本分类方法代码实现:
对原始数据去除空格、数字、%0D%0A标点符号无效字符等处理;得到频率出现较高的前 100 个词;先调用机器学习算法库 sklearn 中MultinomialNB 建立朴素贝叶斯分类模型,用 fit() 函数对数据和标签进行训练;预测结果,结果为1表示垃圾邮件,否则为普通邮件。
import re import os from jieba import cut from itertools import chain from collections import Counter import numpy as np from sklearn.naive_bayes import MultinomialNB def get_words(filename): words = [] with open(filename, 'r', encoding='utf-8') as fr: for line in fr: line = line.strip() # 过滤无效字符 line = re.sub(r'[.【】0-9、——。,!~\*]', '', line) # 使用jieba.cut()方法对文本切词处理 line = cut(line) # 过滤长度为1的词 line = filter(lambda word: len(word) > 1, line) words.extend(line) return words all_words = [] def get_top_words(top_num): filename_list = ['邮件_files/{}.txt'.format(i) for i in range(151)] # 遍历邮件建立词库 for filename in filename_list: all_words.append(get_words(filename)) # itertools.chain()把all_words内的所有列表组合成一个列表 # collections.Counter()统计词个数 freq = Counter(chain(*all_words)) return [i[0] for i in freq.most_common(top_num)] top_words = get_top_words(100) vector = [] for words in all_words: ''' words: ['国际', 'SCI', '期刊', '材料', '结构力学', '工程', '杂志', '国际', 'SCI', '期刊', '先进', '材料科学', '材料', '工程', '杂志', '国际', 'SCI', '期刊', '图像处理', '模式识别', '人工智能', '工程', '杂志', '国际', 'SCI', '期刊', '数据', '信息', '科学杂志', '国际', 'SCI', '期刊', '机器', '学习', '神经网络', '人工智能', '杂志', '国际', 'SCI', '期刊', '能源', '环境', '生态', '温度', '管理', '结合', '信息学', '杂志', '期刊', '网址', '论文', '篇幅', '控制', '以上', '英文', '字数', '以上', '文章', '撰写', '语言', '英语', '论文', '研究', '内容', '详实', '方法', '正确', '理论性', '实践性', '科学性', '前沿性', '投稿', '初稿', '需要', '排版', '录用', '提供', '模版', '排版', '写作', '要求', '正规', '期刊', '正规', '操作', '大牛', '出版社', '期刊', '期刊', '质量', '放心', '检索', '稳定', '邀请函', '推荐', '身边', '老师', '朋友', '打扰', '请谅解'] ''' word_map = list(map(lambda word: words.count(word), top_words)) ''' word_map: [0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 10, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0] ''' vector.append(word_map) vector = np.array(vector) # 0-126.txt为垃圾邮件标记为1;127-151.txt为普通邮件标记为0 labels = np.array([1]*127 + [0]*24) model = MultinomialNB() model.fit(vector, labels) def predict(filename): """对未知邮件分类""" # 构建未知邮件的词向量 words = get_words(filename) current_vector = np.array( tuple(map(lambda word: words.count(word), top_words))) # 预测结果 result = model.predict(current_vector.reshape(1, -1)) return '垃圾邮件' if result == 1 else '普通邮件' print('151.txt分类情况:{}'.format(predict('邮件_files/151.txt'))) print('152.txt分类情况:{}'.format(predict('邮件_files/152.txt'))) print('153.txt分类情况:{}'.format(predict('邮件_files/153.txt'))) print('154.txt分类情况:{}'.format(predict('邮件_files/154.txt'))) print('155.txt分类情况:{}'.format(predict('邮件_files/155.txt')))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
基于深度学习的文本分类
传统的机器学习方法存在的主要问题是文本表示是高维度、高稀疏的,特征表达能力很弱,而且神经网络很不擅长对此类数据的处理;此外需要人工进行特征工程,成本很高。
应用深度学习解决大规模文本分类问题最重要的是解决文本表示,利用神经网络结构自动获取特征表达能力,去掉繁杂的人工特征工程,端到端地解决问题。
CNN:
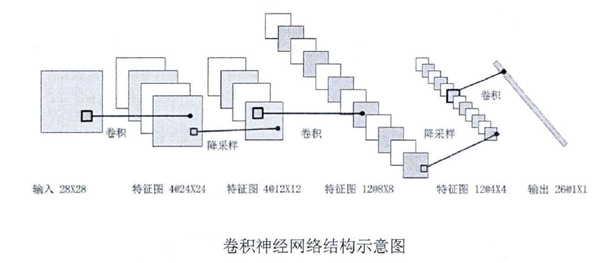
CNN能够在不改变输入序列的位置的情况下提取出显著的特征,具体到文本分类任务中可以利用 CNN 来提取句子中类似 n-gram 的关键信息。
卷积层: 一种滤波器,CNN特有,卷积层的激活函数使用的是ReLU。
卷积:对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积。
池化层: 也叫下采样层,就算通过了卷积层,纬度还是很高 ,需要进行池化层操作。将输入张量的各个子矩阵进行维度压缩,有max和average两种方式。它夹在连续的卷积层中间,减小过拟合,具有特征不变性。
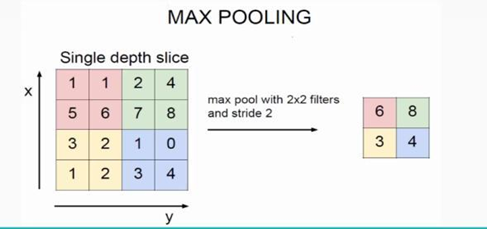
流程:
预处理 :分析数据格式,并读入数据进行预处理,预处理的内容很多,包括去空行、去重等。
分词 :对于中文来讲,要进行分词处理,分词后还要做去停用词等处理。
向量化 :将句子进行编码,例如 one-hot、TF-IDF 等方式,也可以用基于分布式的低维实值词向量表示,使用词嵌入模型抽取词向量。
分类器 :创建 CNN 模型,设置卷积、池化等操作,对输入数据进行训练。
评价 :通过测试集测试分类结果,并评价分析。
文本分类代码实现:
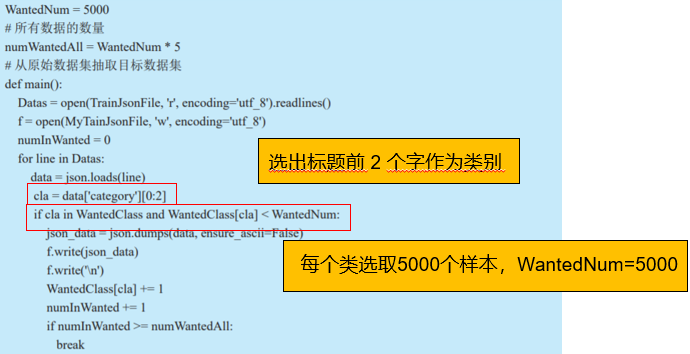
1.数据处理:从原始数据集中选出标题前 2 个字为教育、健康、生活、娱乐和游戏的五个类别,同时每个类别各 5000 个样本数据。
2.CNN模型:基于 Pytorch 搭建的 CNN 网络结构,使用三层卷积层,将三层卷积输出后的向量拼接,经过全连接后输出测试样例属于每个类的概率。

3.模型训练、评估:经过 100 次迭代训练,每次训练后保存模型参数。

开放领域文本分类
传统的分类中,训练集和测试集有着相同的类别,在测试集中出现的类,即已知类别必须在训练集中出现。测试集中出现了训练集没出现过的类别,即未知类别,传统分类算法的性能会大幅下降。学者提出开放领域文本分类的概念及做法,用以区别传统的分类算法,在能够识别已知分类基础上,有效识别未知类别。
基于决策边界的方法:
未知的类别有着和已知类别完全不同的标签,故分类器不知道这些未知类别里面的文本所属于的具体类别,因此在分类时,统一地将这些未知类的数据归为未知类别。
区分未知类和已知类时,引入决策边界(decision boundary),所有的 known class 在边界的内部,unknown class 在边界的外部,外部的空间叫作开放空间(open space)。
决策边界的选择对于开放分类的效果及性能起着至关重要的作用,决策边界过大时,过多的 unknown 数据会被限定在决策边界之内,会被分类成 known class 中的类别,这种现象叫作开放空间风险(openspace risk),决策边界过小,又会使较多的 known class 数据分类为 unknown class,这种风险叫作经验风险。
开放领域文本分类算法的评价指标的选择,和普通的多分类指标大致相同,通常使用宏平均 F1(F1-macro)、准确率(accuracy)作为评价指标。开放领域文本分类是近几年提出的新概念,目前还没有的固定的解决方案,有待进一步的完善。

