
- 1【算法题】编辑距离(动态规划),一文彻底弄懂!
- 2HDFS知识点_块大小及组成文件的块
- 3【git】git rebase详解_git rebase --hard
- 4技术分享 | 关于 MySQL 自增 ID 的事儿_mysql 分区表 自增id间隔是8
- 5制作img文件
- 6Vision Transformer详解(附代码)
- 7SwiftUI 如何隐藏和显示 NavigationView 侧边栏?_swift-ui ipad侧边栏状态
- 8自己动手实现JSON解析_自建json视频解析接口
- 9DFS和BFS_bfs和dfs
- 10springboot对接kafka启动报错ICMP Port Unreachable_javax.security.auth.login.loginexception: icmp por
Hadoop+Hive数据分析综合案例_hadoop+hive的案例
赞
踩
Hadoop+Hive数据分析综合案例(超级详细)
1.1. 需求分析
1.1.1. 背景介绍
聊天平台每天都会有大量的用户在线,会出现大量的聊天数据,通过对聊天数据的统计分析,可以更好的对用户构建精准的用户画像,为用户提供更好的服务以及实现高ROI的平台运营推广,给公司的发展决策提供精确的数据支撑。
我们将基于一个社交平台App的用户数据,完成相关指标的统计分析并结合BI工具对指标进行可视化展现。
1.1.2. 目标
基于Hadoop和Hive实现聊天数据统计分析,构建聊天数据分析报表
1.1.3. 需求
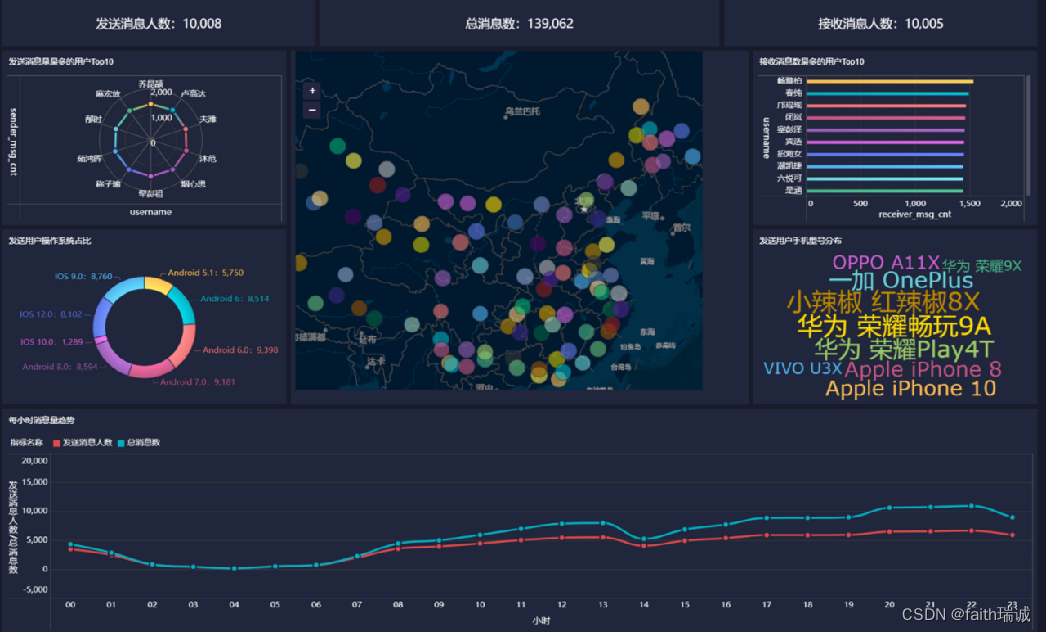
- 统计今日总消息量
- 统计今日每小时消息量、发送和接收用户数
- 统计今日各地区发送消息数据量
- 统计今日发送消息和接收消息的用户数
- 统计今日发送消息最多的Top10用户
- 统计今日接收消息最多的Top10用户
- 统计发送人的手机型号分布情况
- 统计发送人的设备操作系统分布情况
1.1.4. 数据内容
-
数据大小:30万条数据
-
列分隔符:Hive默认分隔符‘\001’
-
数据字典及样例数据
-
数据获取地址
链接:https://pan.baidu.com/s/1Nx69z4YU2DgKb3YA8xbFqA?pwd=ut3v 提取码:ut3v- 1
- 2

1.2. 加载数据
1、创建库表
-- 如果数据库已存在就删除
drop database if exists db_msg cascade;
-- 创建数据库
CREATE database db_msg;
-- 选择数据库
use db_msg;
--如果表已存在就删除
drop table if exists db_msg.tb_msg_source;
-- 建表
create table db_msg.tb_msg_source(
msg_time string comment "消息发送时间",
sender_name string comment "发送人昵称",
sender_account string comment "发送人账号",
sender_sex string comment "发送人性别",
sender_ip string comment "发送人ip地址",
sender_os string comment "发送人操作系统",
sender_phonetype string comment "发送人手机型号",
sender_network string comment "发送人网络类型",
sender_gps string comment "发送人的GPS定位",
receiver_name string comment "接收人昵称",
receiver_ip string comment "接收人IP",
receiver_account string comment "接收人账号",
receiver_os string comment "接收人操作系统",
receiver_phonetype string comment "接收人手机型号",
receiver_network string comment "接收人网络类型",
receiver_gps string comment "接收人的GPS定位",
receiver_sex string comment "接收人性别",
msg_type string comment "消息类型",
distance string comment "双方距离",
message string comment "消息内容"
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
2、数据导入
将课程资料中的chat_data-30W.csv文件上传到node1服务器的/home/hadoop目录下;
在Linux系统内执行以下命令:
# 切换工作目录
cd /home/hadoop
# 在HDFS系统中创建/chatdemo/data目录
hadoop fs -mkdir -p /chatdemo/data
# 将chat_data-30W.csv文件从Linux上传到HDFS系统中
hadoop fs -put chat_data-30W.csv /chatdemo/data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在DBeaver中执行以下命令:
-- 从HDFS系统中加载数据到Hive表
load data inpath '/chatdemo/data/chat_data-30W.csv' into table tb_msg_source;
-- 验证数据加载
SELECT * FROM tb_msg_source tablesample(100 rows);
-- 验证表中的数据条数
SELECT COUNT(*) from tb_msg_source tms ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1.3. ETL数据清洗转换
由于原始数据中存在部分不合规的数据,所以需要对数据进行清洗。
1、原始数据存在的问题
- 问题1:当前数据中,有一些数据的字段(如sender_gps)为空,不是合法数据;
- 问题2:需求中,需要统计每天、每个小时的消息量,但是数据中没有天和小时字段,只有整体时间字段,不好处理;
- 问题3:需求中,需要对经度和维度构建地区的可视化地图,但是数据中GPS经纬度为一个字段,不好处理;
2、数据清洗需求
- 需求1:对字段为空的不合法数据进行过滤;
- 需求2:通过时间字段构建天和小时字段;
- 需求3:从GPS的经纬度中提取经度和维度;
- 需求4:将ETL以后的结果保存到一张新的Hive表中。
-- 创建存储清洗后数据的表
create table db_msg.tb_msg_etl(
msg_time string comment "消息发送时间",
sender_name string comment "发送人昵称",
sender_account string comment "发送人账号",
sender_sex string comment "发送人性别",
sender_ip string comment "发送人ip地址",
sender_os string comment "发送人操作系统",
sender_phonetype string comment "发送人手机型号",
sender_network string comment "发送人网络类型",
sender_gps string comment "发送人的GPS定位",
receiver_name string comment "接收人昵称",
receiver_ip string comment "接收人IP",
receiver_account string comment "接收人账号",
receiver_os string comment "接收人操作系统",
receiver_phonetype string comment "接收人手机型号",
receiver_network string comment "接收人网络类型",
receiver_gps string comment "接收人的GPS定位",
receiver_sex string comment "接收人性别",
msg_type string comment "消息类型",
distance string comment "双方距离",
message string comment "消息内容",
msg_day string comment "消息日",
msg_hour string comment "消息小时",
sender_lng double comment "经度",
sender_lat double comment "纬度"
);
-- 按照需求对原始数据表中的数据进行过滤,然后插入新建的表中
INSERT OVERWRITE TABLE db_msg.tb_msg_etl
SELECT
*,
DATE(msg_time) as msg_day,
HOUR(msg_time) as msg_hour,
SPLIT(sender_gps, ',')[0] as sender_lng,
SPLIT(sender_gps, ',')[1] as sender_lat
FROM db_msg.tb_msg_source
WHERE LENGTH(sender_gps) > 0;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
执行完毕后,打开tb_msg_etl表,可以看到以下数据
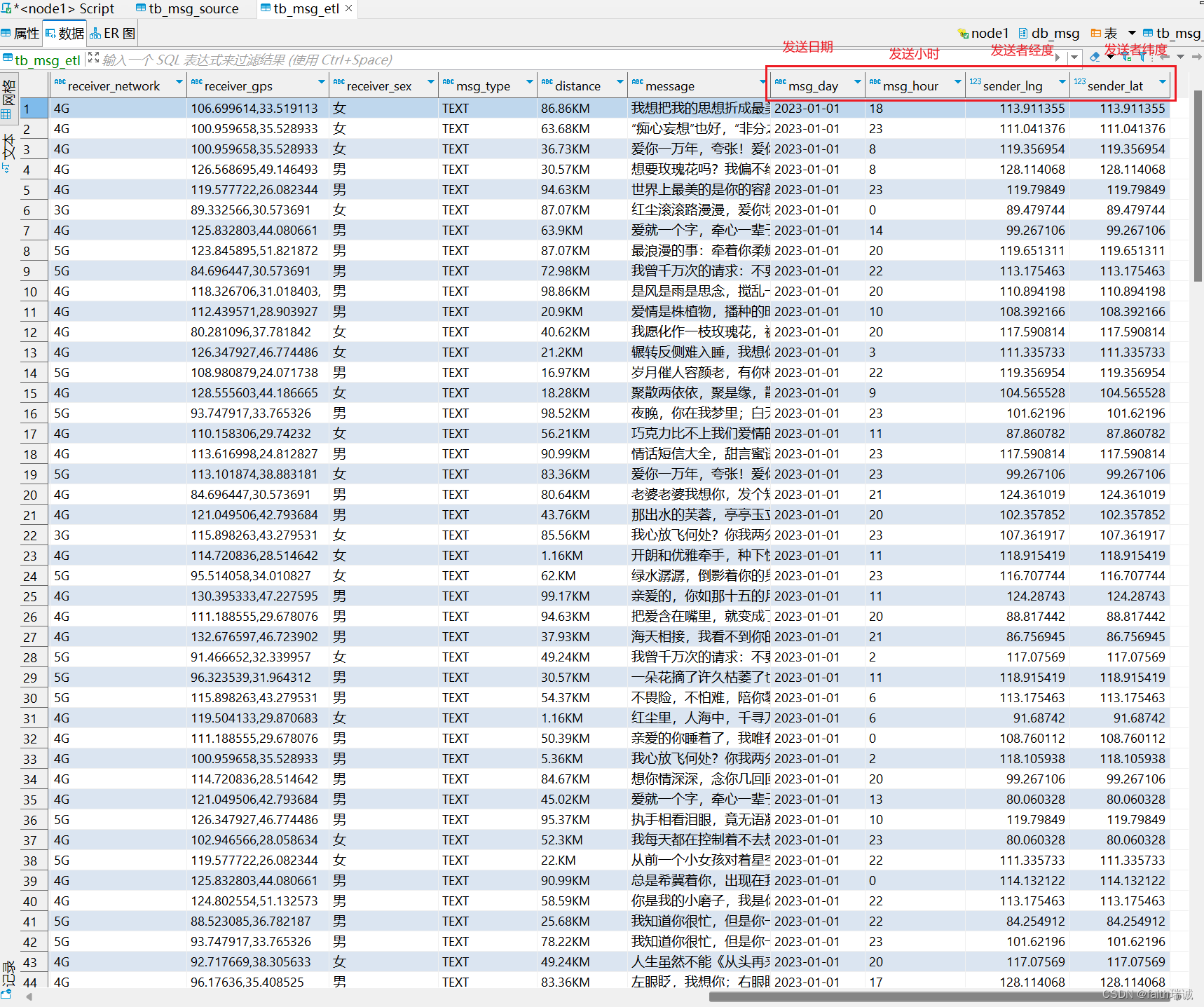
扩展知识:ETL
从表tb_msg_source 查询数据进行数据过滤和转换,并将结果写入到:tb_msg_etl表中的操作。这种操作,本质上是一种简单的ETL行为。
ETL:
- E,Extract,抽取
- T,Transform,转换
- L,Load,加载
从A抽取数据(E),进行数据转换过滤(T),将结果加载到B(L),就是ETL。
1.4. 指标统计
1、指标1:统计每日发送的消息总量
-- 统计每日消息总量
CREATE table db_msg.tb_rs_total_msg_cnt comment '每日消息总量' as
SELECT msg_day, COUNT(*) as total_msg_cnt FROM db_msg.tb_msg_etl GROUP BY msg_day;
123
- 1
- 2
- 3
- 4
2、指标2:统计每小时消息量、发送和接收用户数
-- 统计每小时消息量、发送和接收用户数
CREATE table db_msg.tb_rs_hour_msg_cnt comment '每小时消息量情况' as
SELECT
msg_hour,
COUNT(*) as total_msg_cnt,
COUNT(DISTINCT sender_account) as sender_user_cnt,
COUNT(DISTINCT receiver_account) as receiver_user_cnt
FROM
db_msg.tb_msg_etl
GROUP BY
msg_hour;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3、指标3:统计每日各地区发送消息总量
-- 每日各地区发送消息总量
CREATE table db_msg.tb_rs_loc_cnt comment '每日各地区发送消息总量' as
SELECT
msg_day,
sender_lng,
sender_lat,
COUNT(*) as total_msg_cnt
FROM db_msg.tb_msg_etl
GROUP BY msg_day, sender_lng, sender_lat;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4、指标4:统计每日发送和接收用户数
-- 每日发送和接收用户数
CREATE table db_msg.tb_rs_user_cnt comment '每日发送消息和接收消息人数' as
SELECT
msg_day,
COUNT(DISTINCT sender_account) as sender_user_cnt,
COUNT(DISTINCT receiver_account) as receiver_user_cnt
FROM db_msg.tb_msg_etl
GROUP BY msg_day;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5、指标5:统计发送消息条数最多的TOP10用户
-- 发送消息条数最多的前10个用户
CREATE table db_msg.tb_rs_sneder_user_top10 comment '发送消息条数最多的10个用户' as
SELECT
sender_name,
COUNT(*) as sender_msg_cnt
FROM db_msg.tb_msg_etl
GROUP BY sender_name
SORT BY sender_msg_cnt DESC
LIMIT 10;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
6、指标6:统计接收消息条数最多的TOP10用户
-- 接收消息条数最多的10个用户
CREATE table db_msg.tb_rs_receiver_user_top10 comment '接收消息条数最多的10个用户' as
SELECT
receiver_name,
COUNT(*) as receiver_msg_cnt
FROM db_msg.tb_msg_etl
GROUP BY receiver_name
SORT BY receiver_msg_cnt DESC
LIMIT 10;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
7、指标7:统计发送人的手机型号
-- 统计发送人的手机型号
CREATE table db_msg.tb_rs_sender_phone comment '发送人手机型号分布' as
SELECT
sender_phonetype,
COUNT(*) as cnt
FROM db_msg.tb_msg_etl
GROUP BY sender_phonetype;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
8、指标8:统计发送人的设备操作系统分布情况
-- 统计发送人的设备操作系统分布情况
CREATE table db_msg.tb_rs_sender_os comment '发送人设备操作系统分布' as
SELECT
sender_os,
COUNT(*) as cnt
FROM db_msg.tb_msg_etl tme
GROUP BY sender_os;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.5. FineBI安装&配置
1.5.1. FineBI的下载和安装
1、打开FineBI官方https://www.finebi.com/,注册并下载FineBI个人试用版本客户端;

2、在本地物理机上安装刚才下载的客户端(和安装其他软件一样的操作),安装完成之后,启动FineBI客户端;
3、启动之后,输入FineBI官网提供的激活码,然后点击“使用BI”按钮,此时FineBI客户端开始启动(这个过程可能较长,需要耐心等待,过程中可能会弹出openJDK请求防火墙的权限,需要同意);
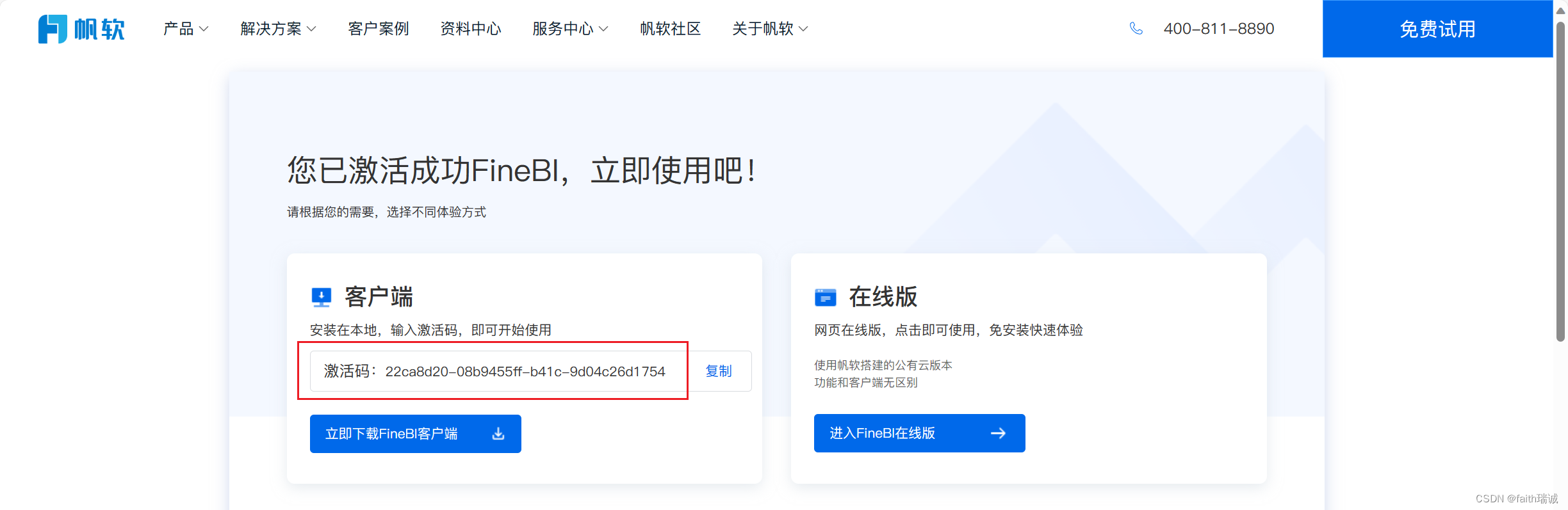
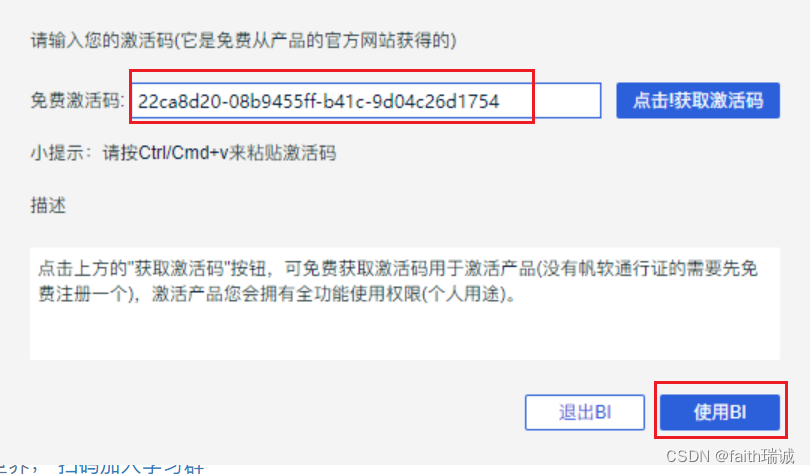
4、FineBI客户端启动成功后,会自动打开浏览器,并打开http://localhost:37799/webroot/decision/login/initialization网页,进入配置页面,此时可以配置BI软件的管理员账号、密码;
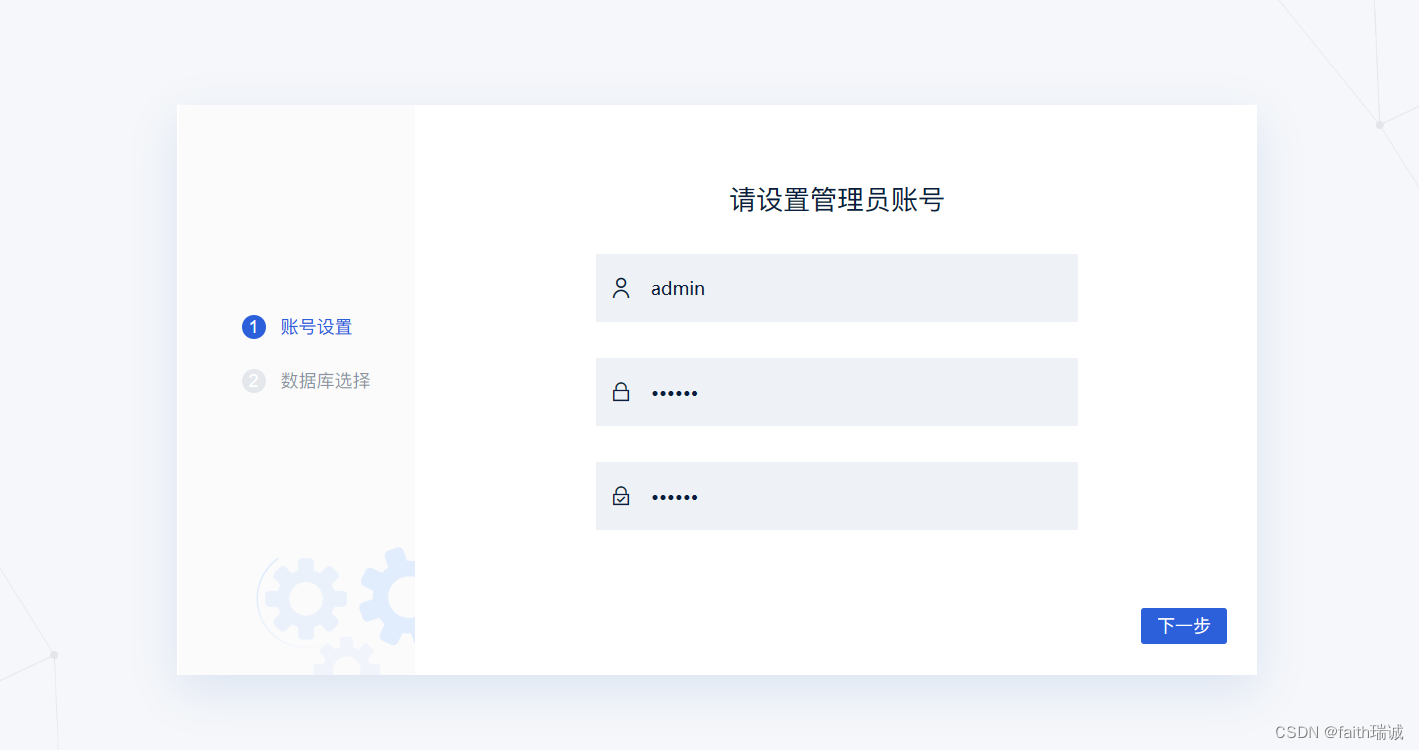
5、账号设置完毕后,需要配置FineBI的数据库,FineBI类似于Hive也有元数据需要管理,对于个人使用来说,可以使用FineBI的内置数据库,若是生产环境使用,则建议使用外接数据库;
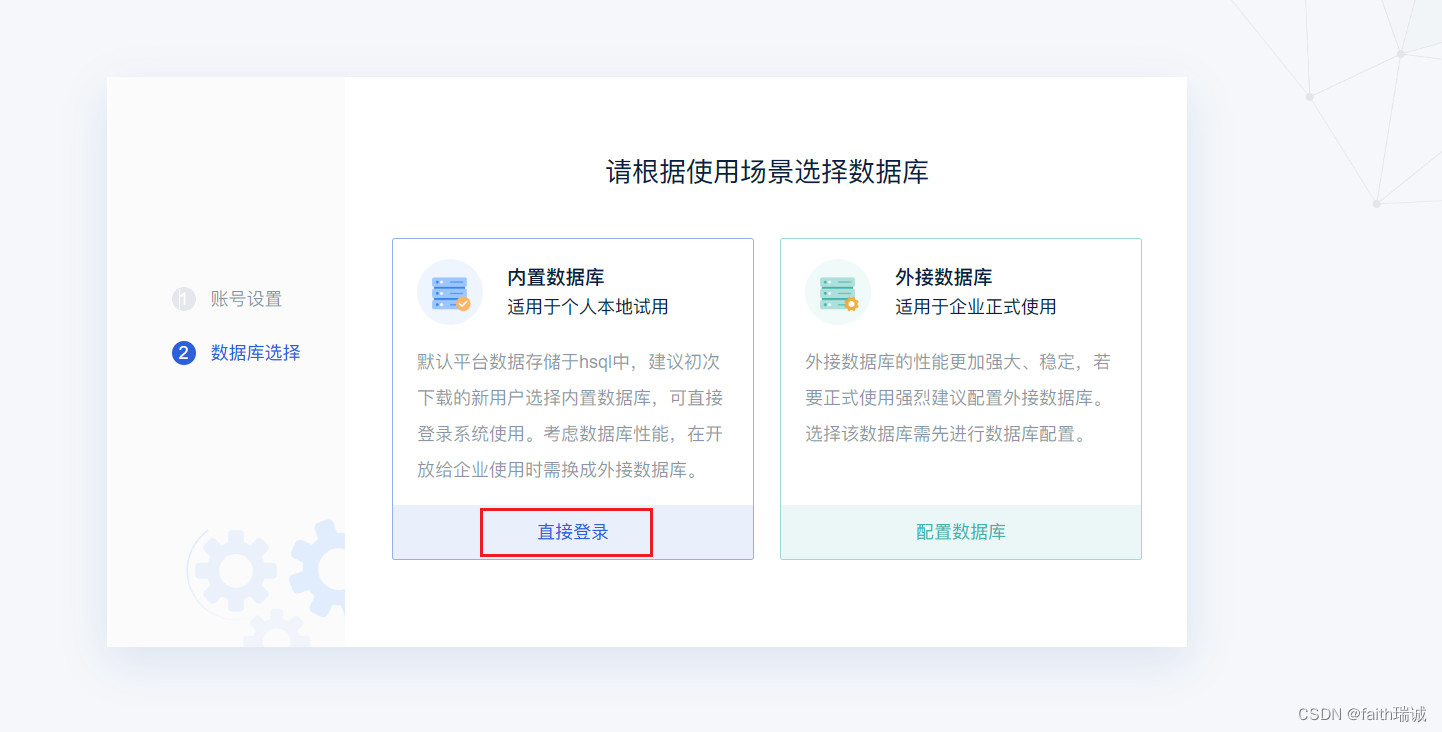
6、点击“直接登录”之后,BI系统会自动跳转到登录界面,输入刚才设置的管理员账号和密码进行登录;
7、登录FineBI系统后,可以在其目录内发现一些内置的模板和样例数据,以及新手入门指引等,可以作为配置个人所需模板的参考;
至此,FineBI客户端已安装完毕。
1.5.2. 配置FineBI与Hive的连接
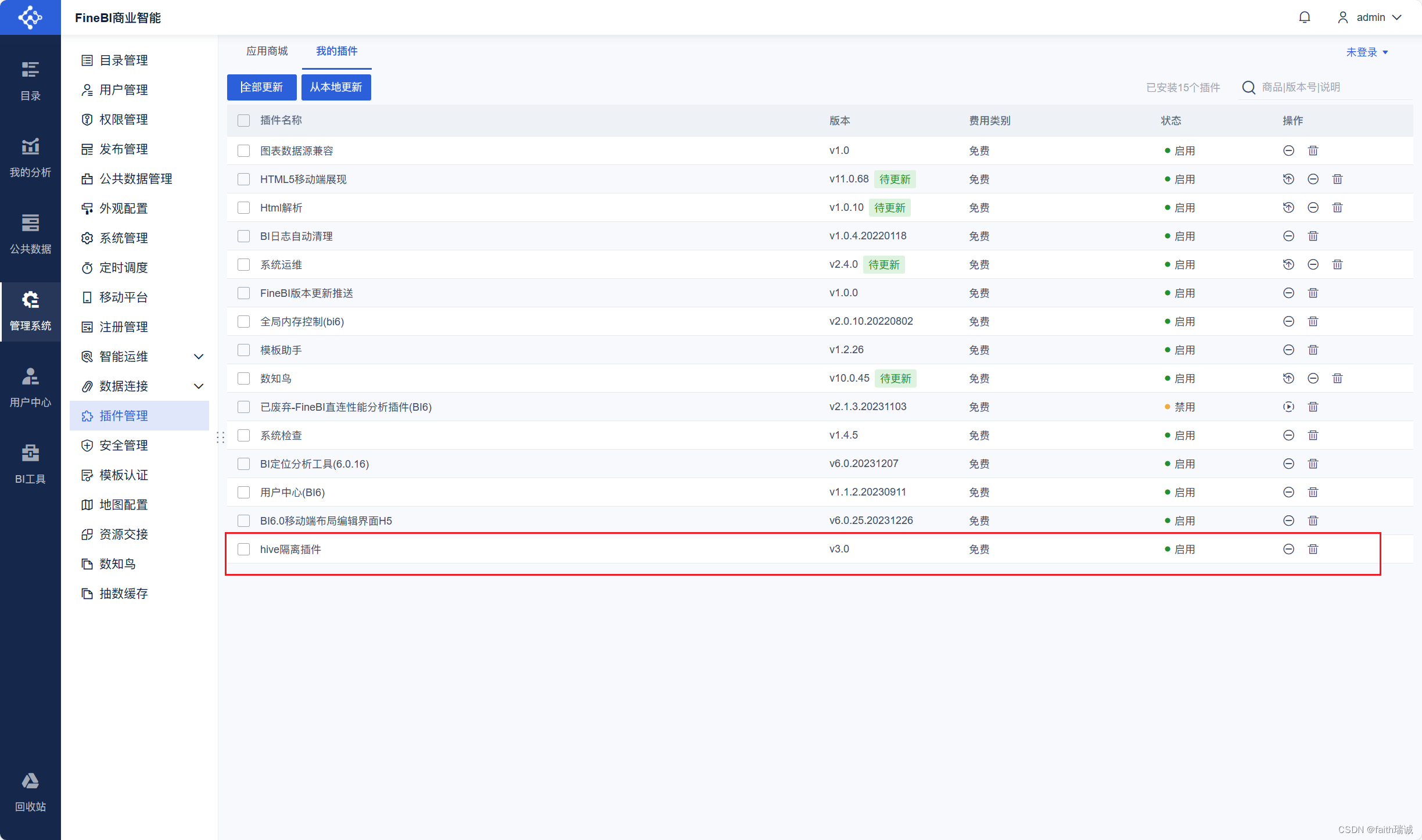
1、接下来需要配置FineBI连接Hive的隔离插件。进入FineBI系统中,在“管理系统-插件管理-我的插件-从本地安装”,然后选择课程资料中,FineBI文件夹中的fr-plugin-hive-driver-loader-3.0.zip,然后系统会安装Hive隔离插件;
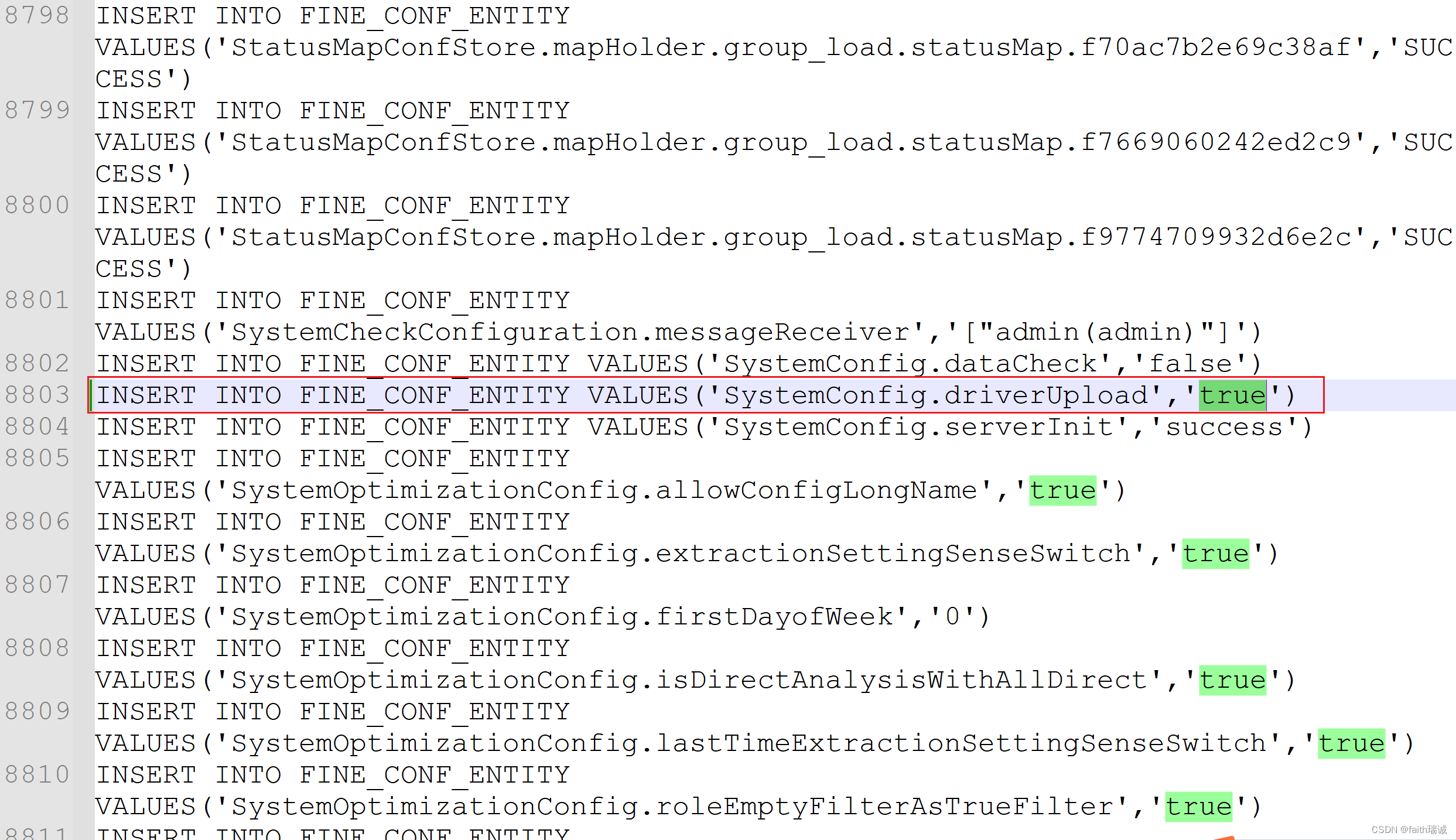
2、然后,使用记事本打开FineBI安装目录下webapps\webroot\WEB-INF\embed\finedb目录下的db.script文件,将其中的INSERT INTO FINE_CONF_ENTITY VALUES('SystemConfig.driverUpload','false')修改为INSERT INTO FINE_CONF_ENTITY VALUES('SystemConfig.driverUpload','true')。这样才能安装Hive驱动。
3、然后,重启FineBI客户端,先关闭FineBI客户端,然后再在桌面重新打开FineBI的客户端;

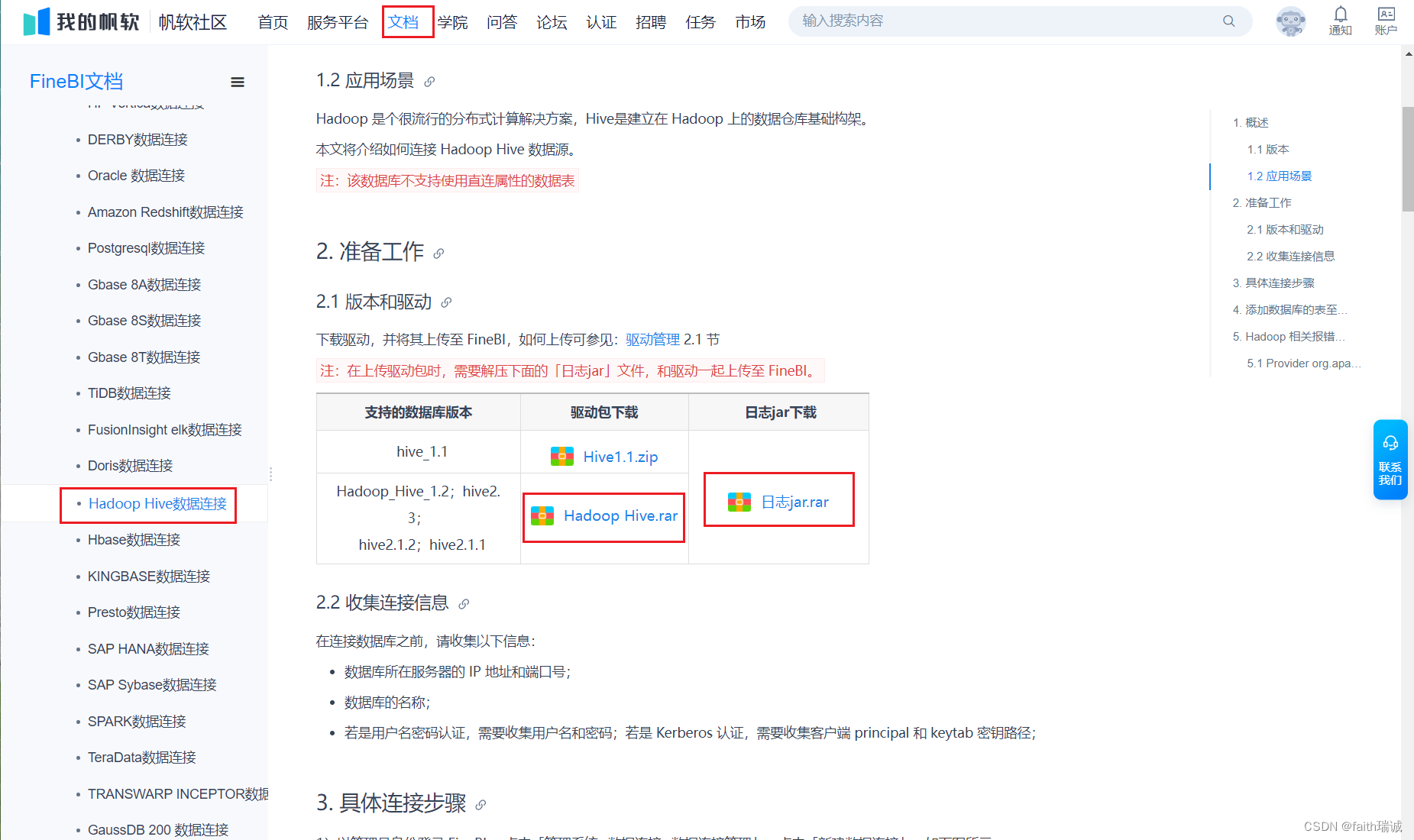
4、重新登录系统后,需要先安装Hive驱动,打开FineBI官方帮助手册,Hadoop Hive数据连接章节:https://help.fanruan.com/finebi/doc-view-301.html,根据其指示下载对应版本的驱动包和日志jar包;
5、下载完成后,将两个压缩包里的所有jar文件解压到一个文件夹中;
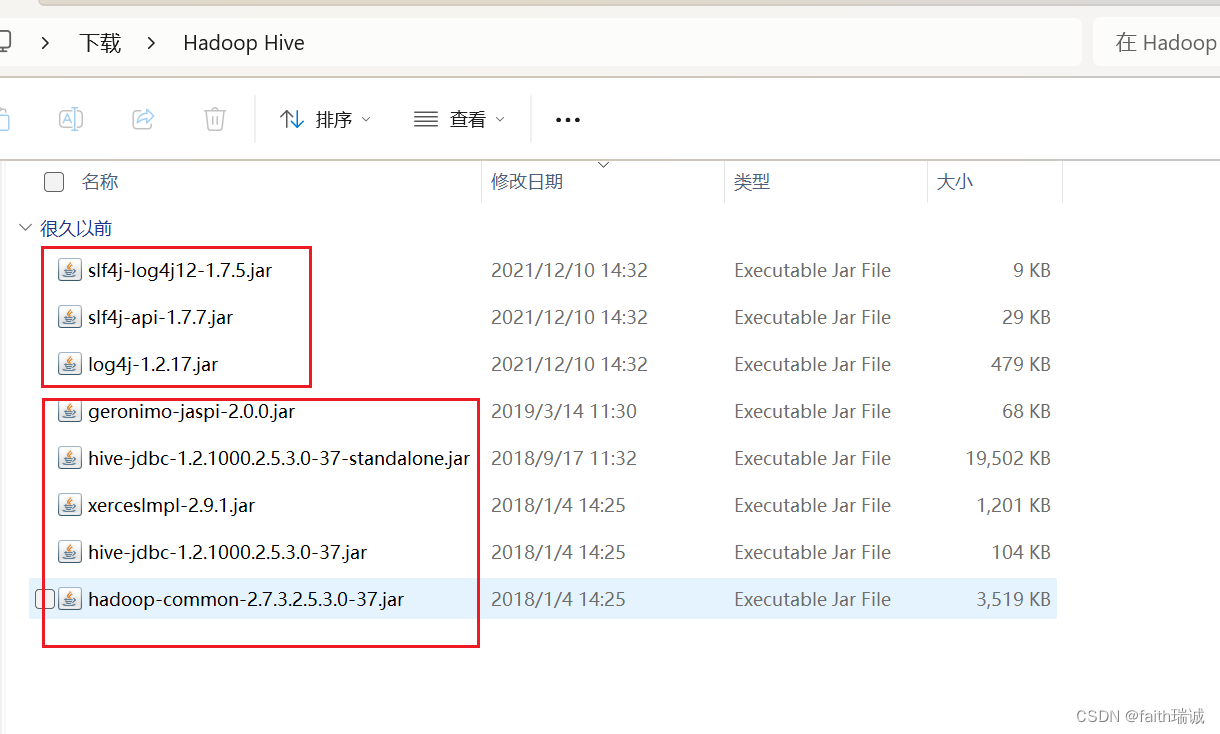
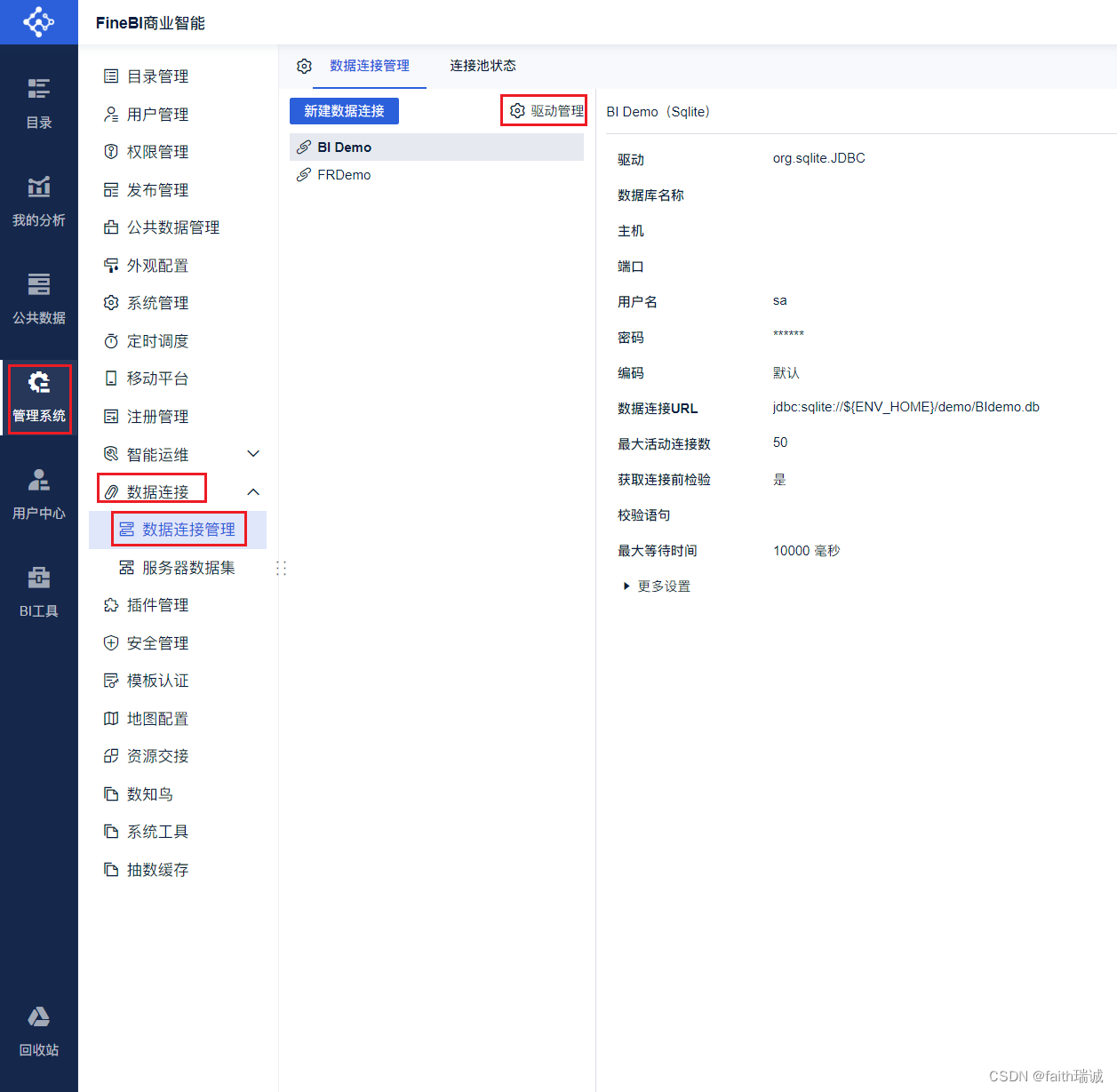
6、在系统中,依次点击“管理系统-数据连接-数据连接管理-驱动管理”,进入驱动管理界面;
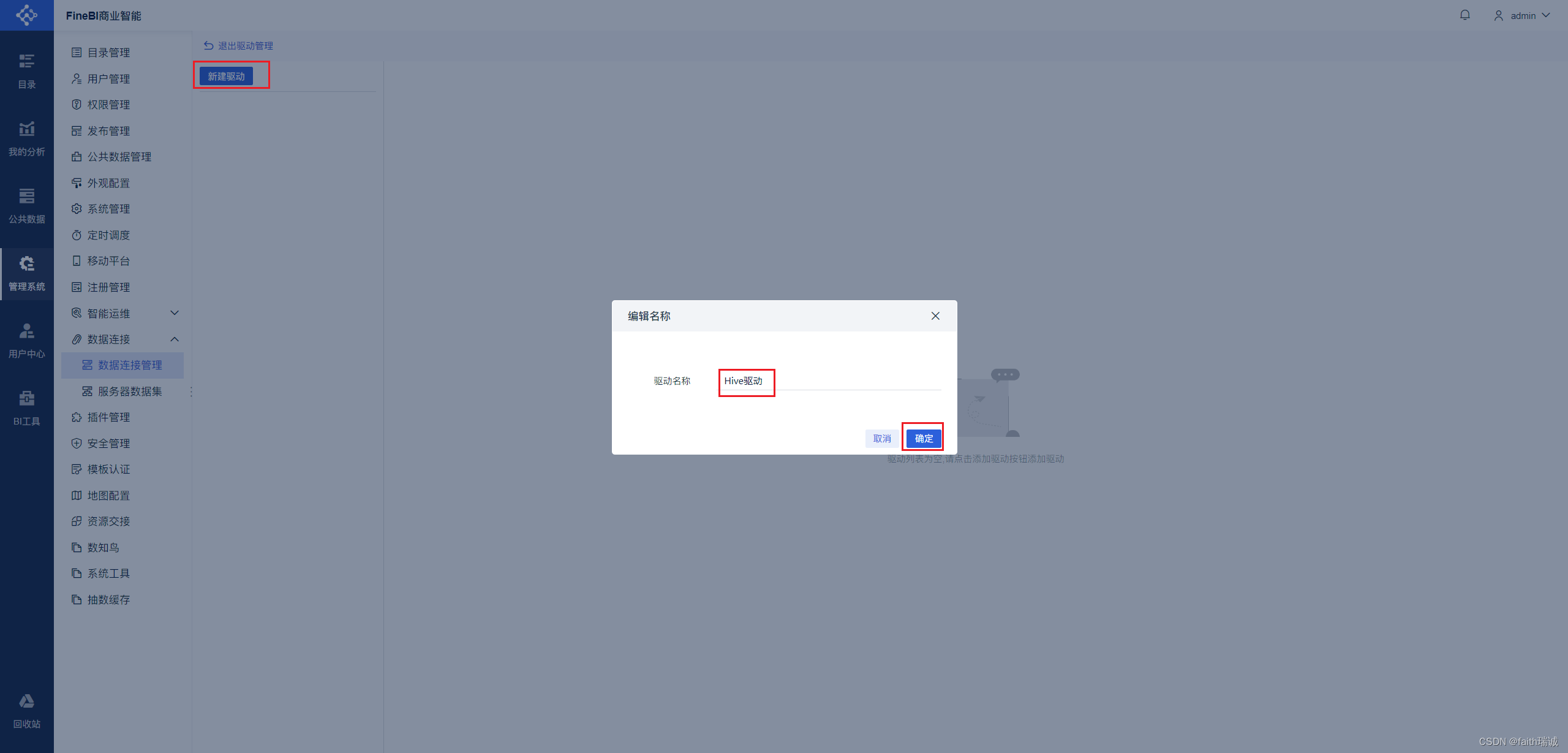
7、在驱动管理界面点击“新建驱动”按钮,填写驱动名称,然后点击“确定”按钮;
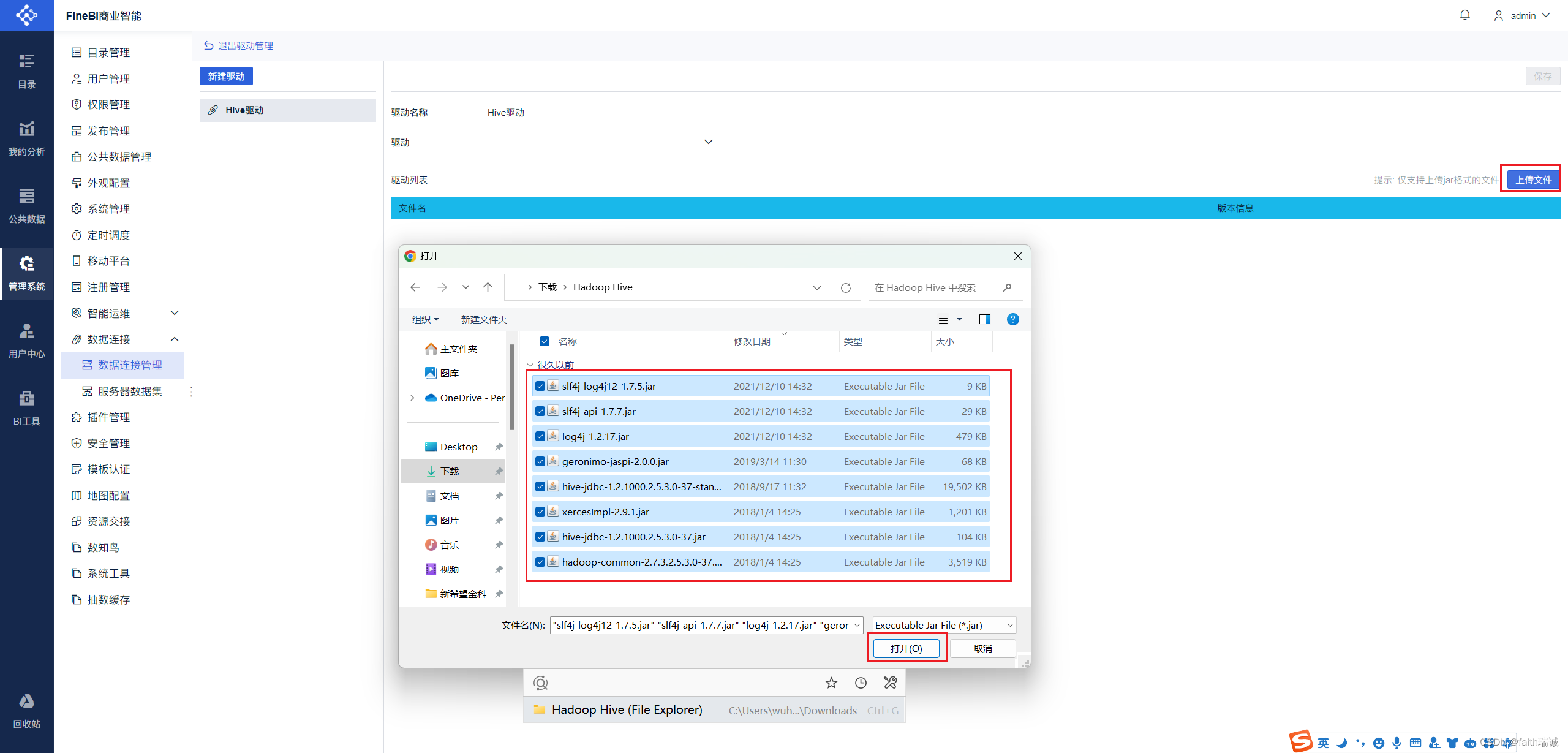
8、然后点击“上传文件”按钮,将刚才解压的所有jar文件选中上传;
9、上传完成后,在“驱动”栏选择Hive驱动,然后点击右上角的“保存”按钮,完成Hive驱动的添加。添加成功后,点击左上角的“退出驱动管理”按钮;
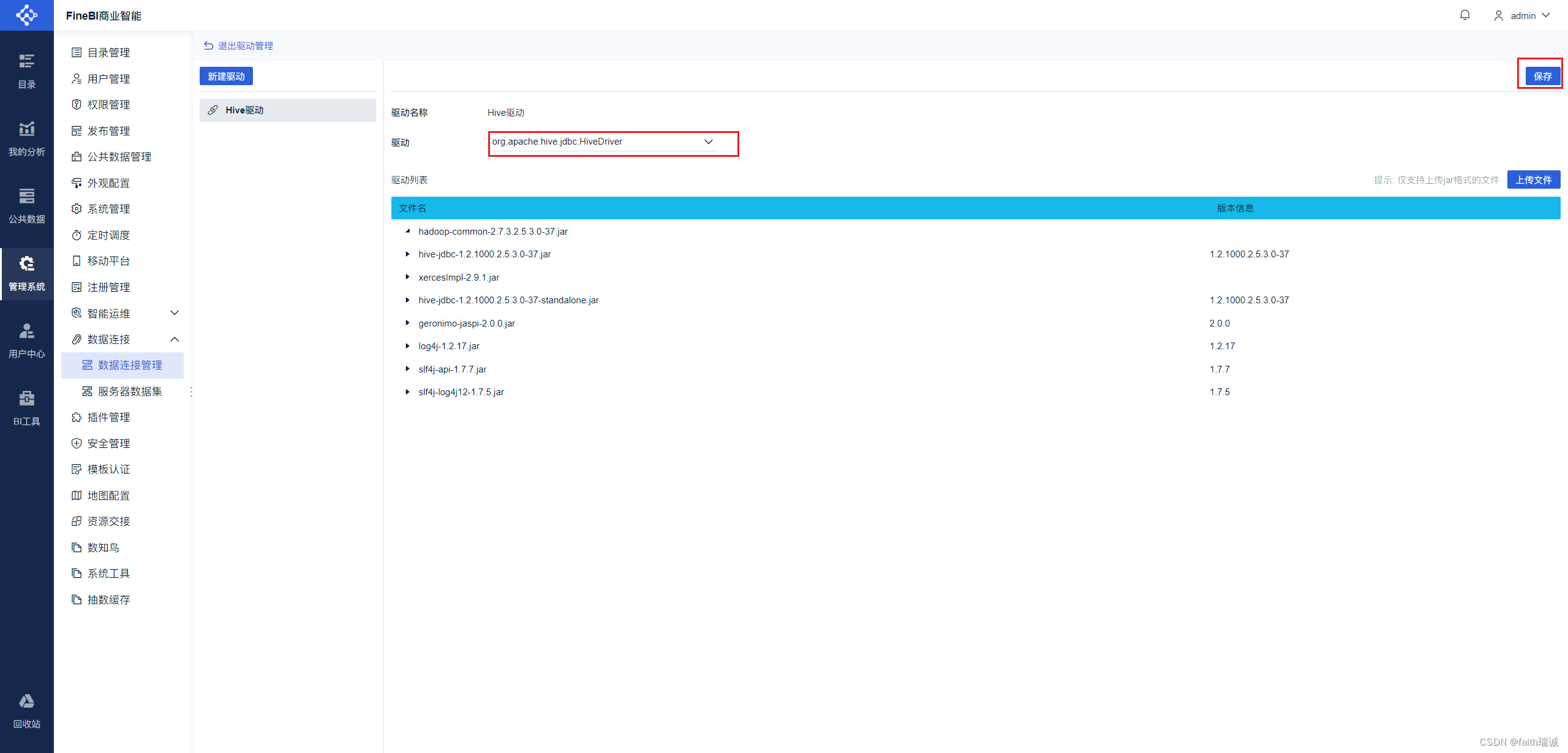
10、点击数据连接管理界面的“新建数据连接”按钮,打开新建数据连接界面;
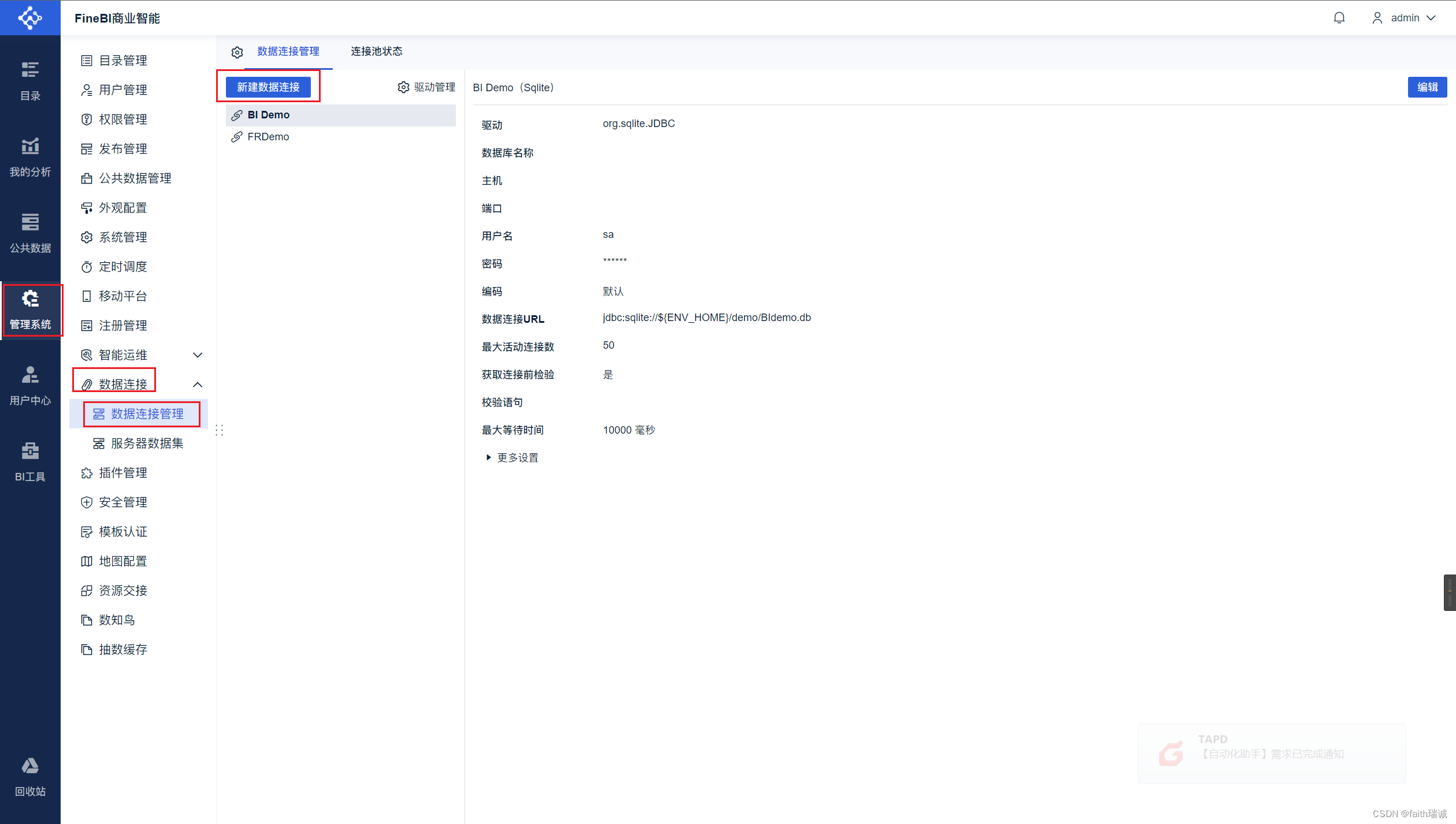
11、在打开的页面中选择“所有”选项卡,然后点击“Hadoop Hive”;

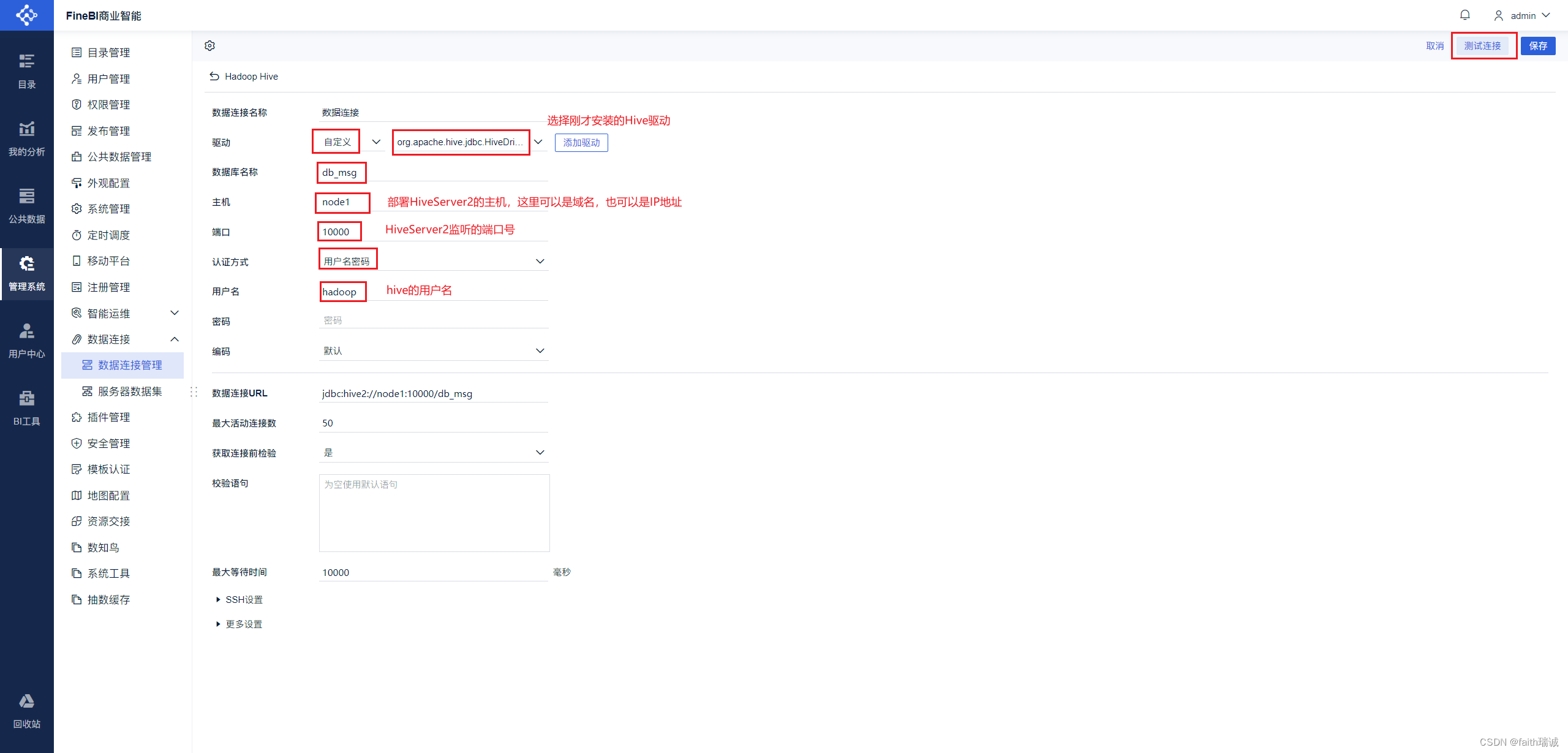
12、在Hadoop Hive页面填写虚拟机Hive服务(即hiveserver2服务)的相关信息,填写完毕后,点击右上角的“测试连接”按钮,看到“连接成功”提示代表配置成功,然后点击右上角的“保存”按钮,Hive连接创建完毕。
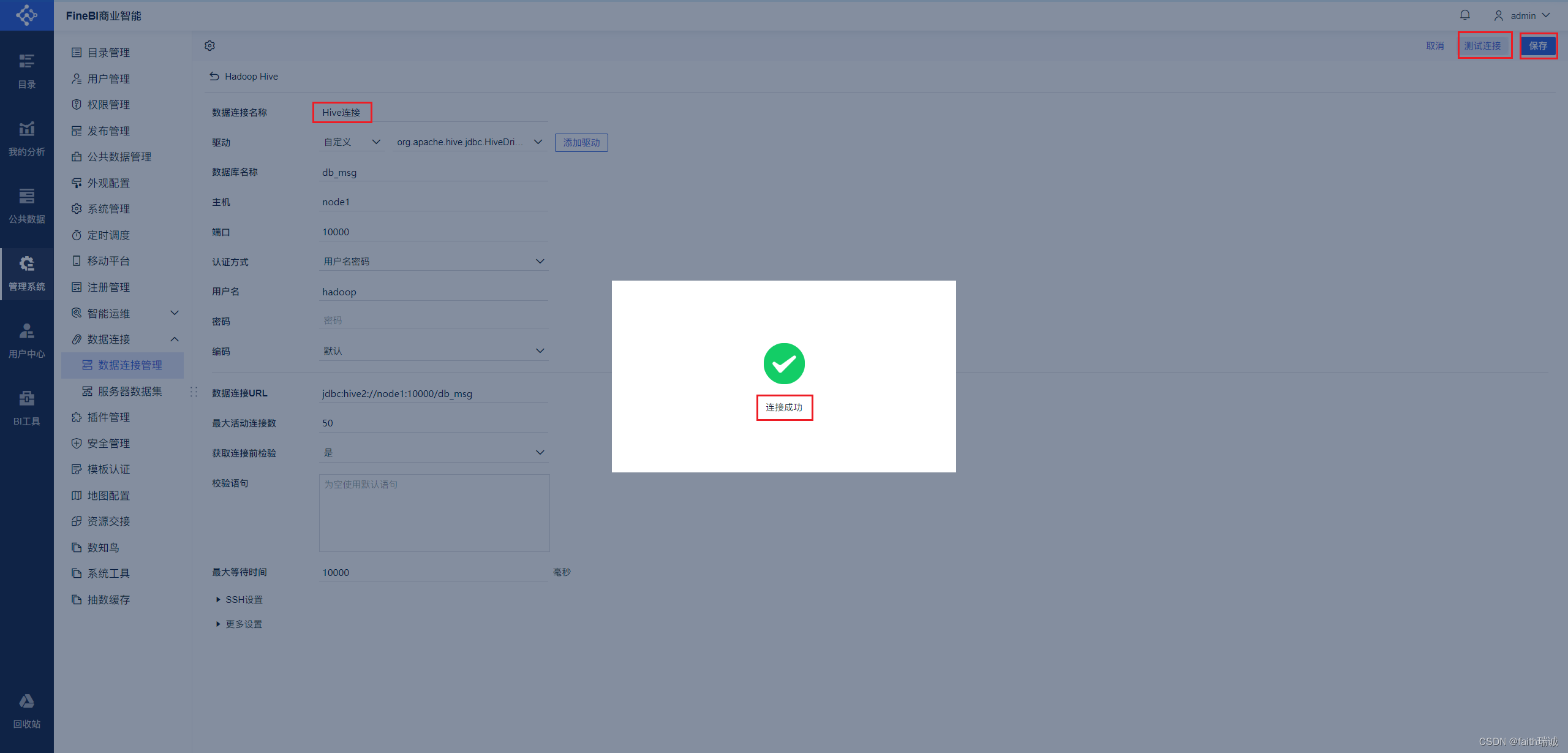
至此,FineBI到Hive的数据连接配置完成。后续将进行可视化面板的配置。
1.6. 可视化展示
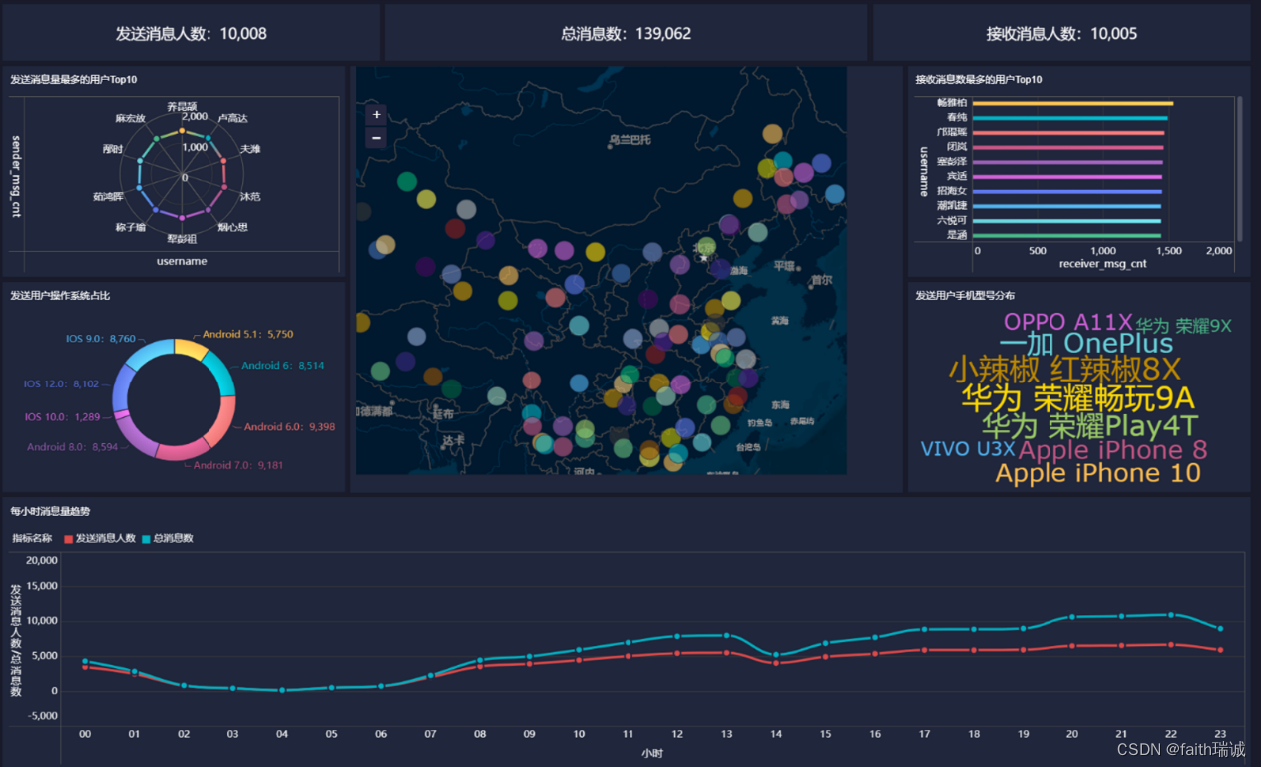
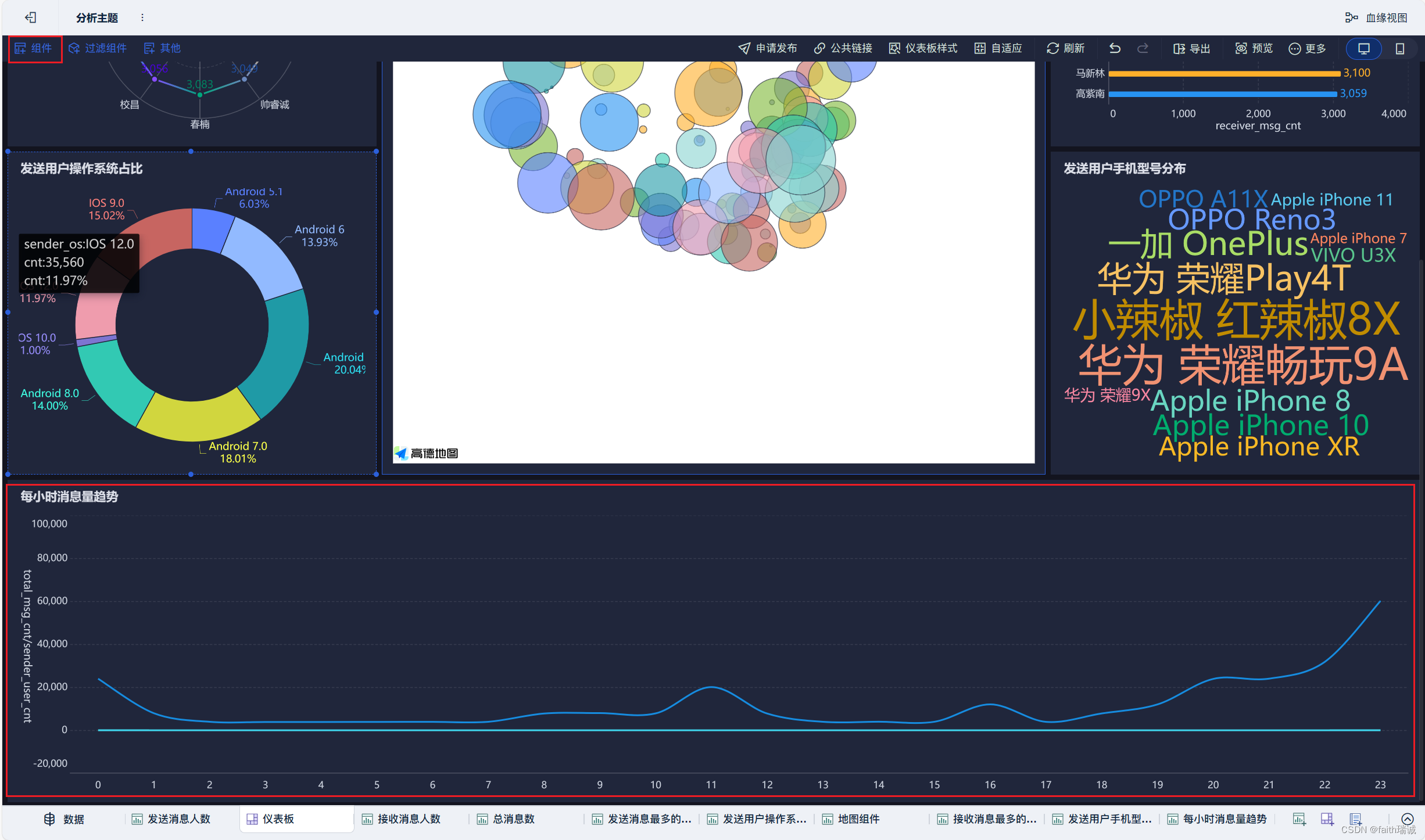
本节的目标是使用FineBI配置出如下的可视化看板。
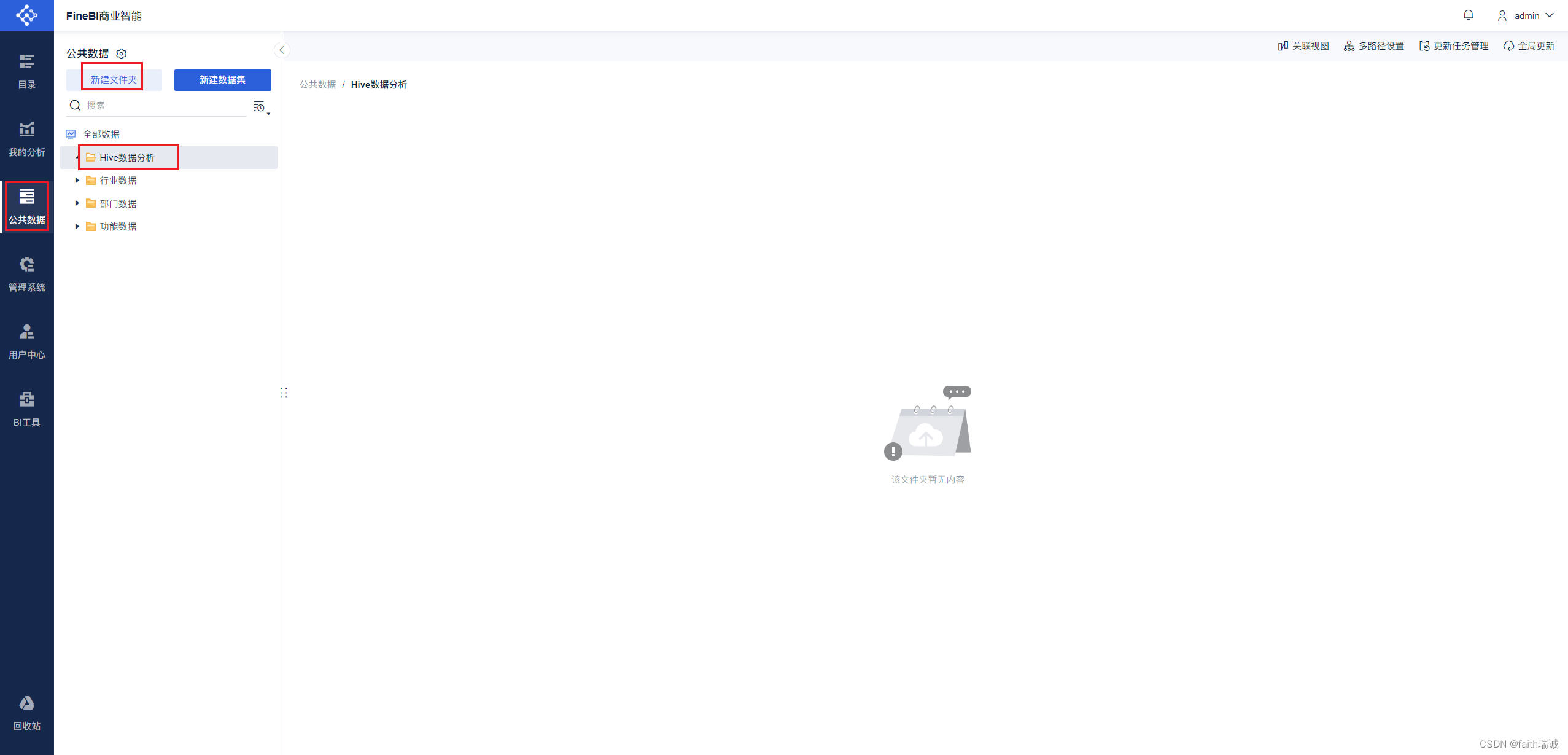
1、创建报表。登录系统后,依次点击“公共数据-新建文件夹”,创建本案例中所使用的文件夹,然后给文件夹命名为“Hive数据分析”。
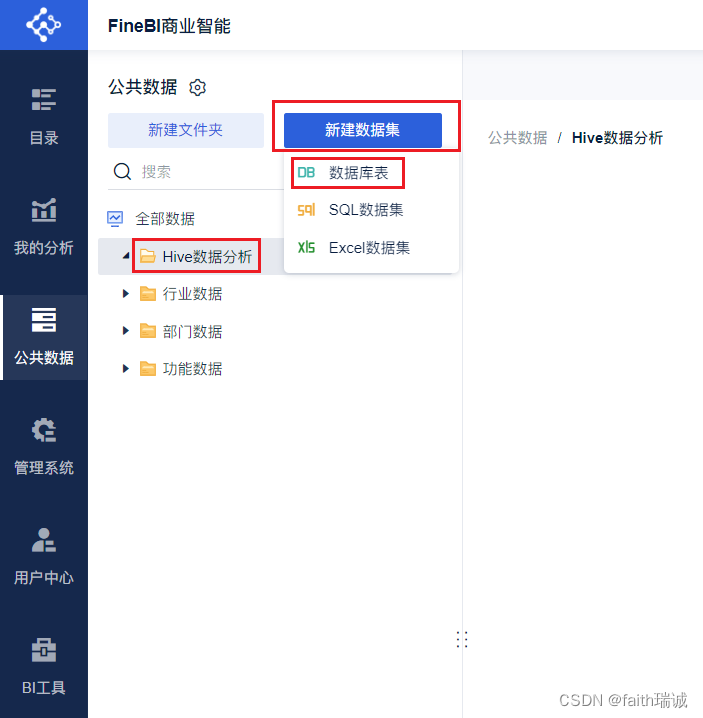
2、选择刚才新建的“Hive数据分析”文件夹,然后点击上方的“新建数据集”按钮,选择“数据库表”。
3、然后将前面章节所创建的8个指标的数据表选中,然后点击右上角的“确定”按钮;
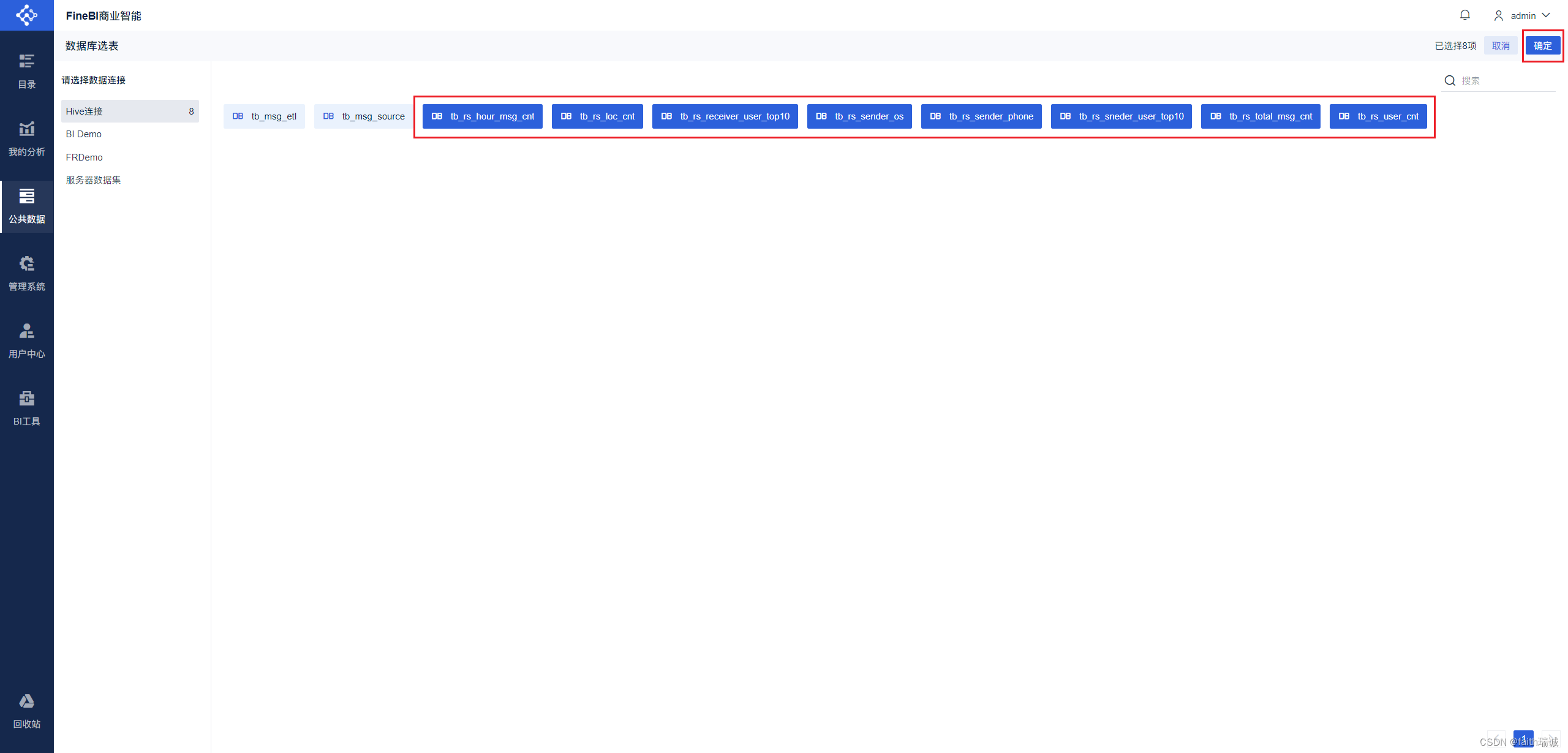
4、点击“确定”后,可以看到在“Hive数据分析”文件夹下出现了前面选中的表(以表注释命名);
5、依次点开每张表,然后点击“更新数据”按钮,将Hive中的数据拉取过来;
6、依次点击“我的分析-新建文件夹”,将新建的文件夹命名为“Hive数据分析”;
7、选择“Hive数据分析”,然后点击“新建分析主题”,会在另一个浏览器窗口打开分析主题页面;
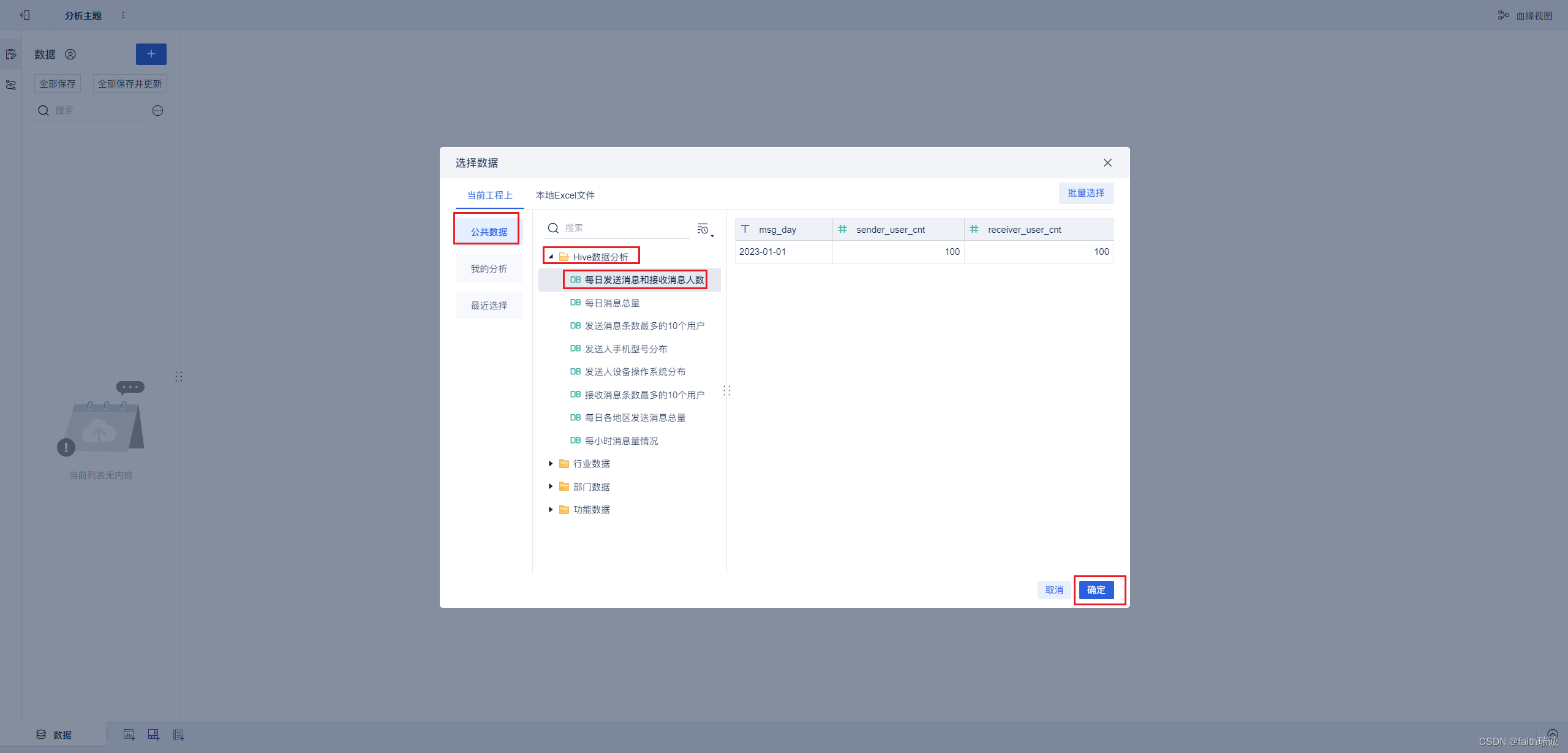
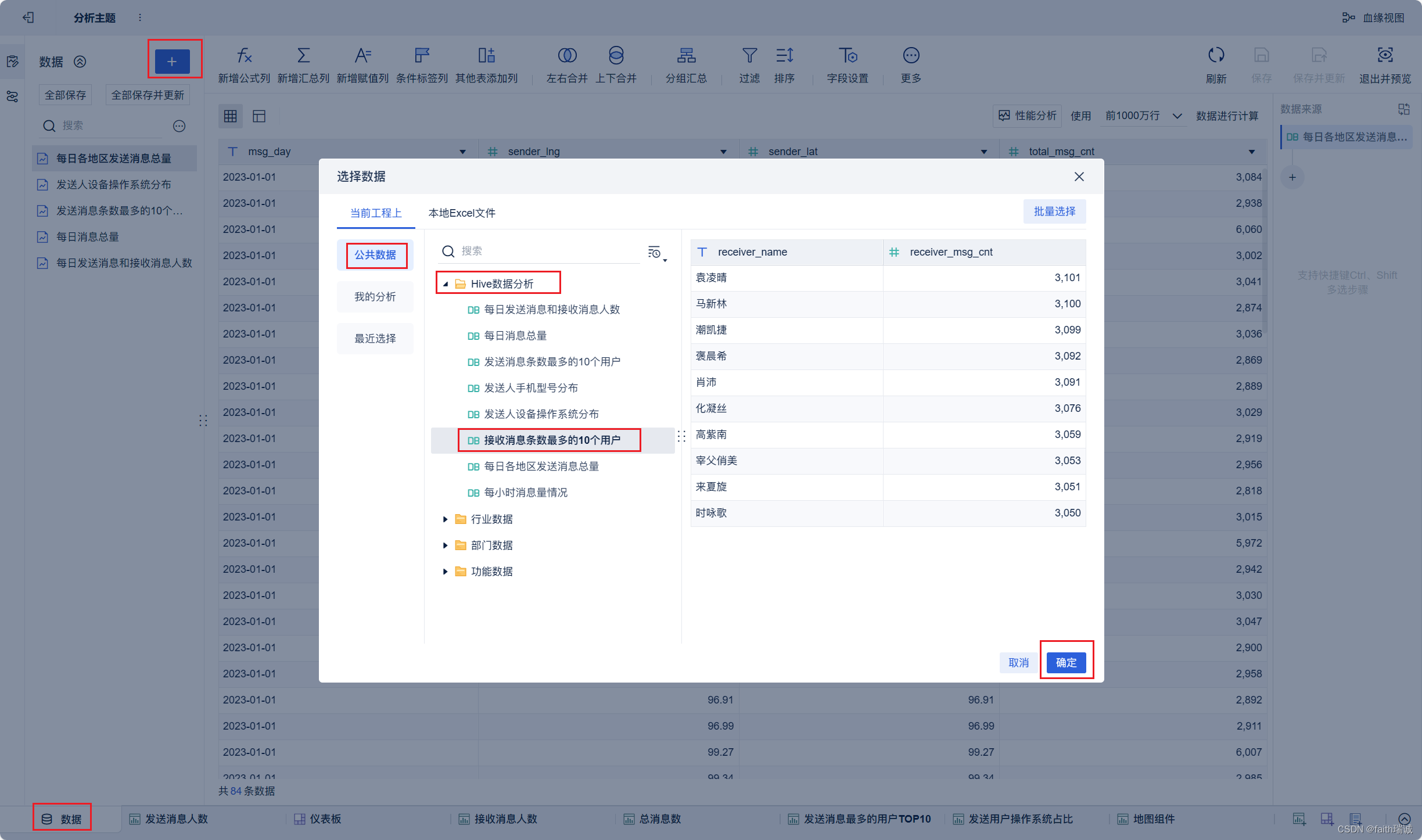
8、在分析主题页面选择“公共数据”-刚才新建的Hive数据分析数据集中的“每日发送消息和接收消息人数”,然后点击“确定”按钮,将该数据构建进来;
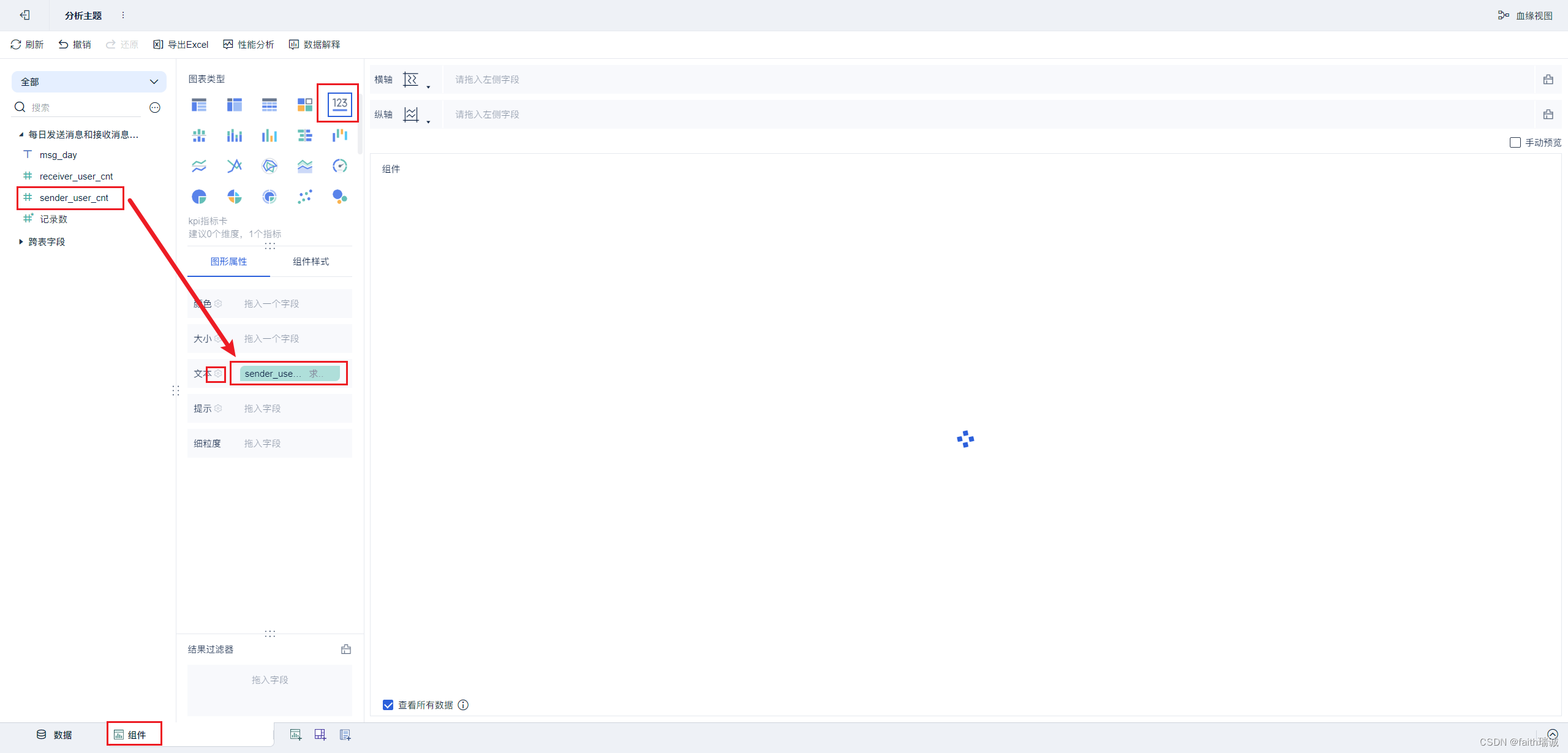
9、构建好后,点击下方的“组件”Tab,进入组件配置中,选择“KPI指标卡”,然后将左侧的“sender_user_cnt”字段拖动到“文本”栏中,然后点击文本栏的配置按钮;
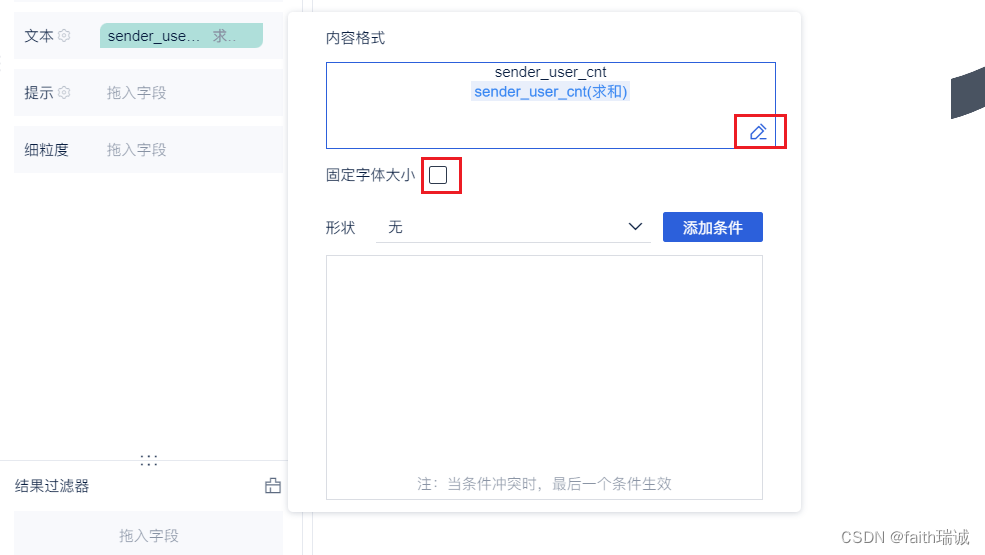
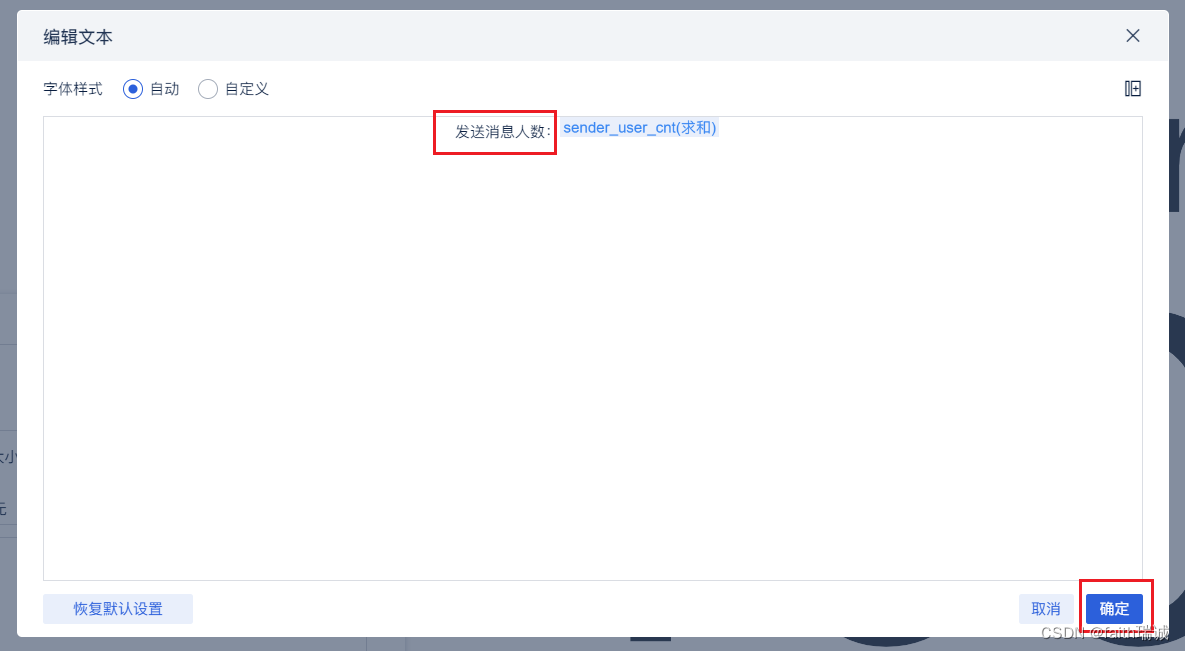
10、在弹出的文本栏配置中,取消“固定字体大小”,然后编辑内容,将内容的前缀改为“发送消息人数:”即可;
11、对组件Tab进行重命名,改为“发送消息人数”,然后点击页面下部的“添加仪表板”按钮,添加一个仪表板;
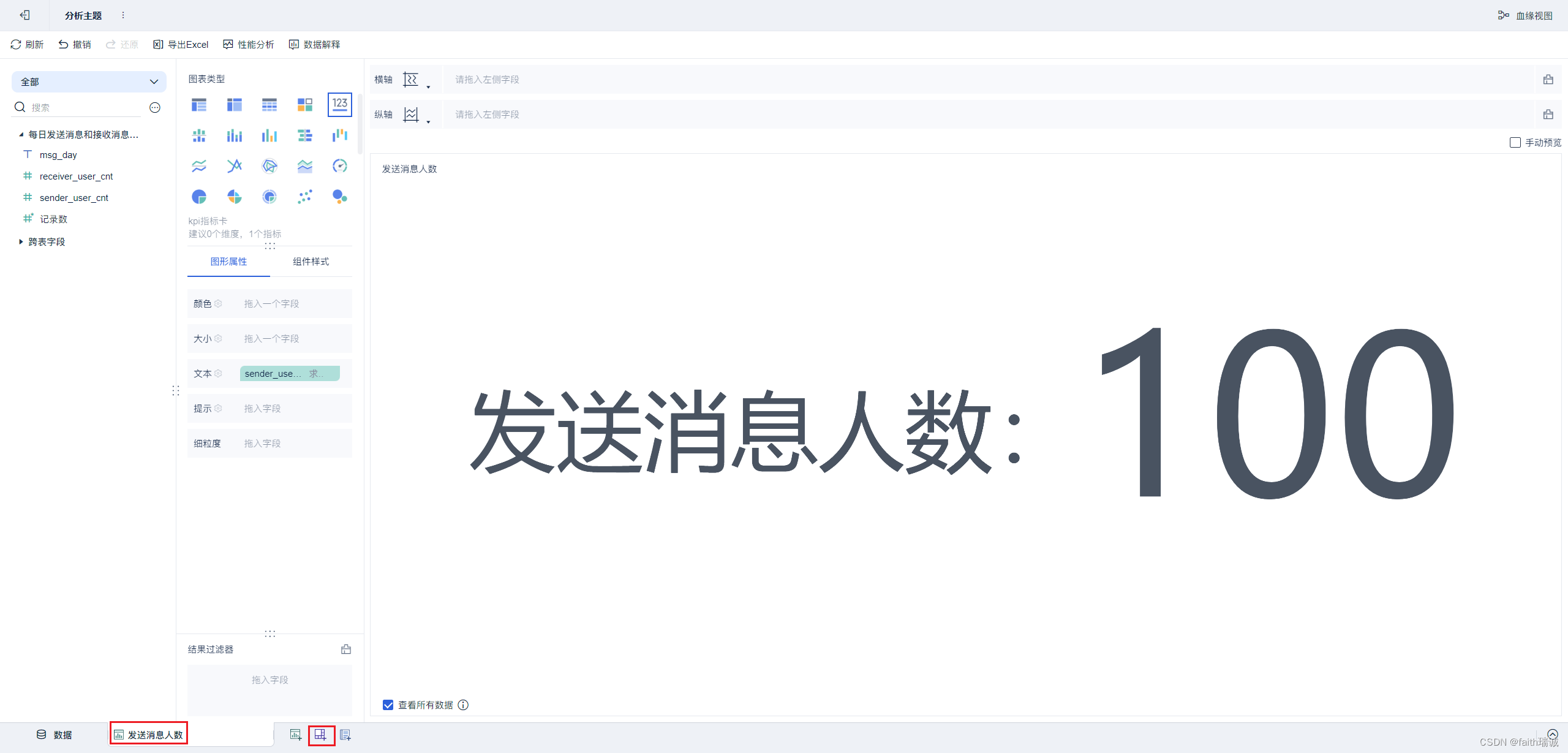
12、然后在仪表板中,将刚才配置好的“发送消息人数”组件拖动到仪表板上,并调整好位置和大小,点击组件旁边的下拉按钮,取消“显示标题”的勾选;
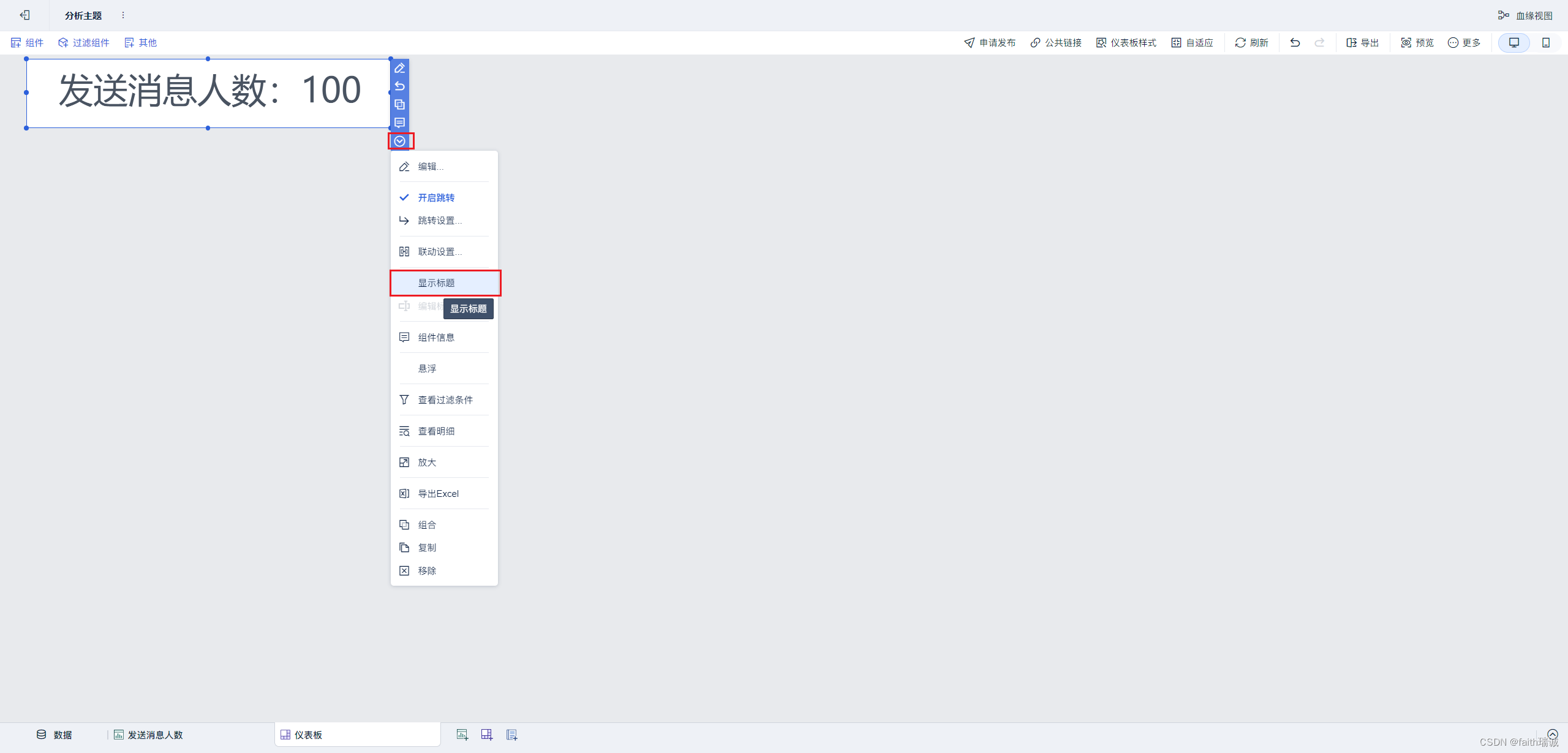
13、然后点击右上角的“仪表板样式”,选择“默认暗黑”就可以修改整个数据看板的背景;
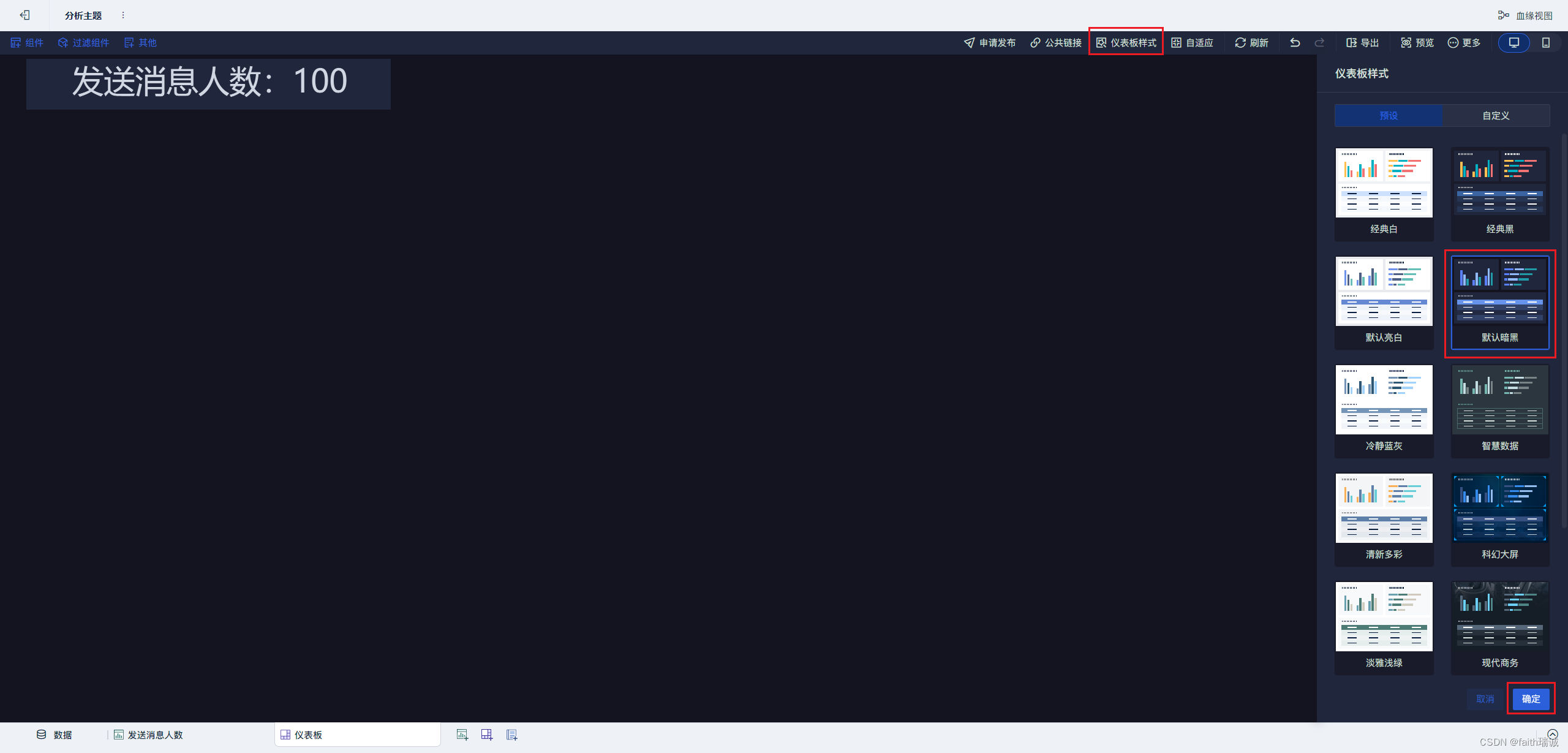
14、然后相同的方式,新建“接收消息人数”的组件,并摆放在该仪表板上;
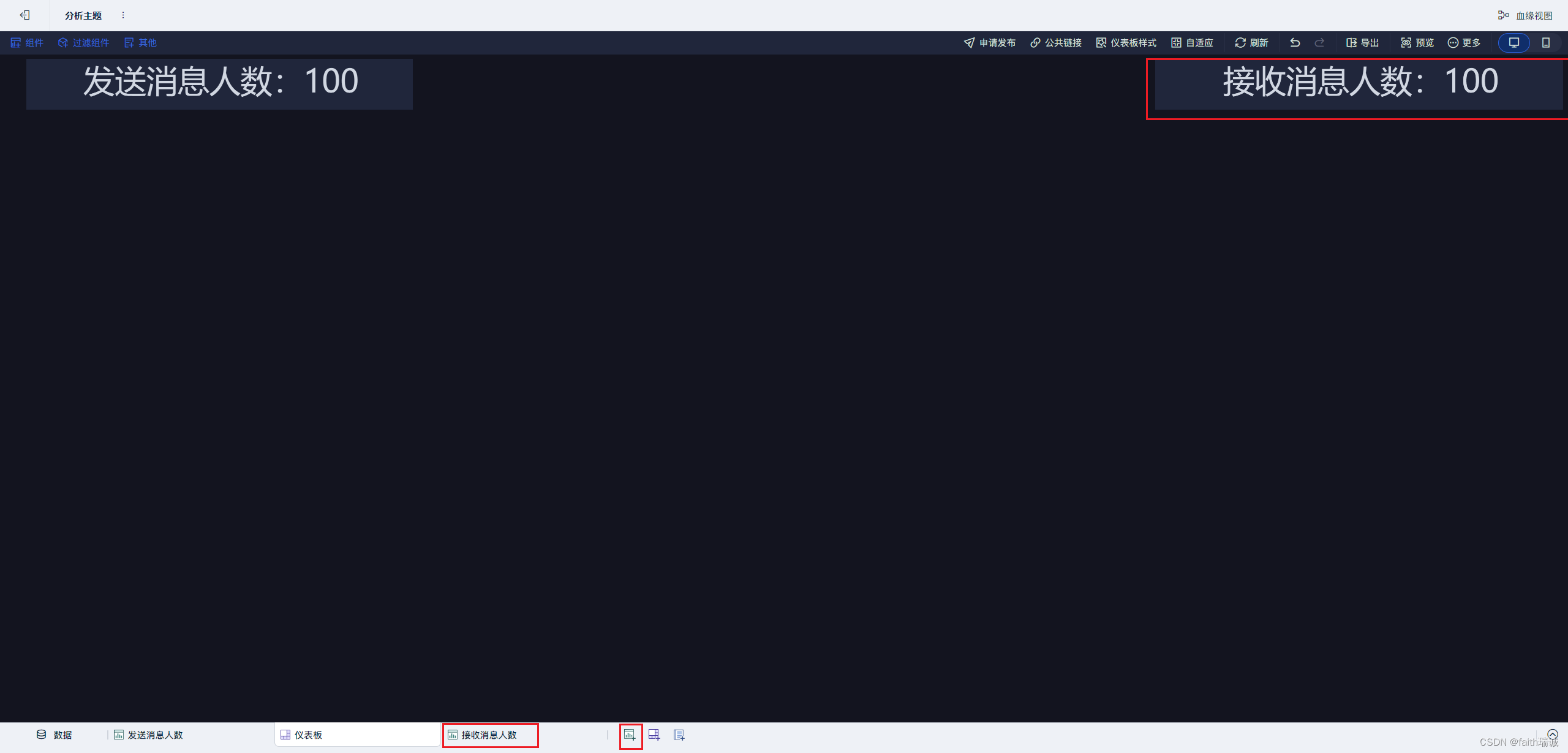
15、选择“数据”Tab,然后点上面的“+”按钮,然后选择“公共数据-Hive数据分析-每日消息总量”,然后点击确定;
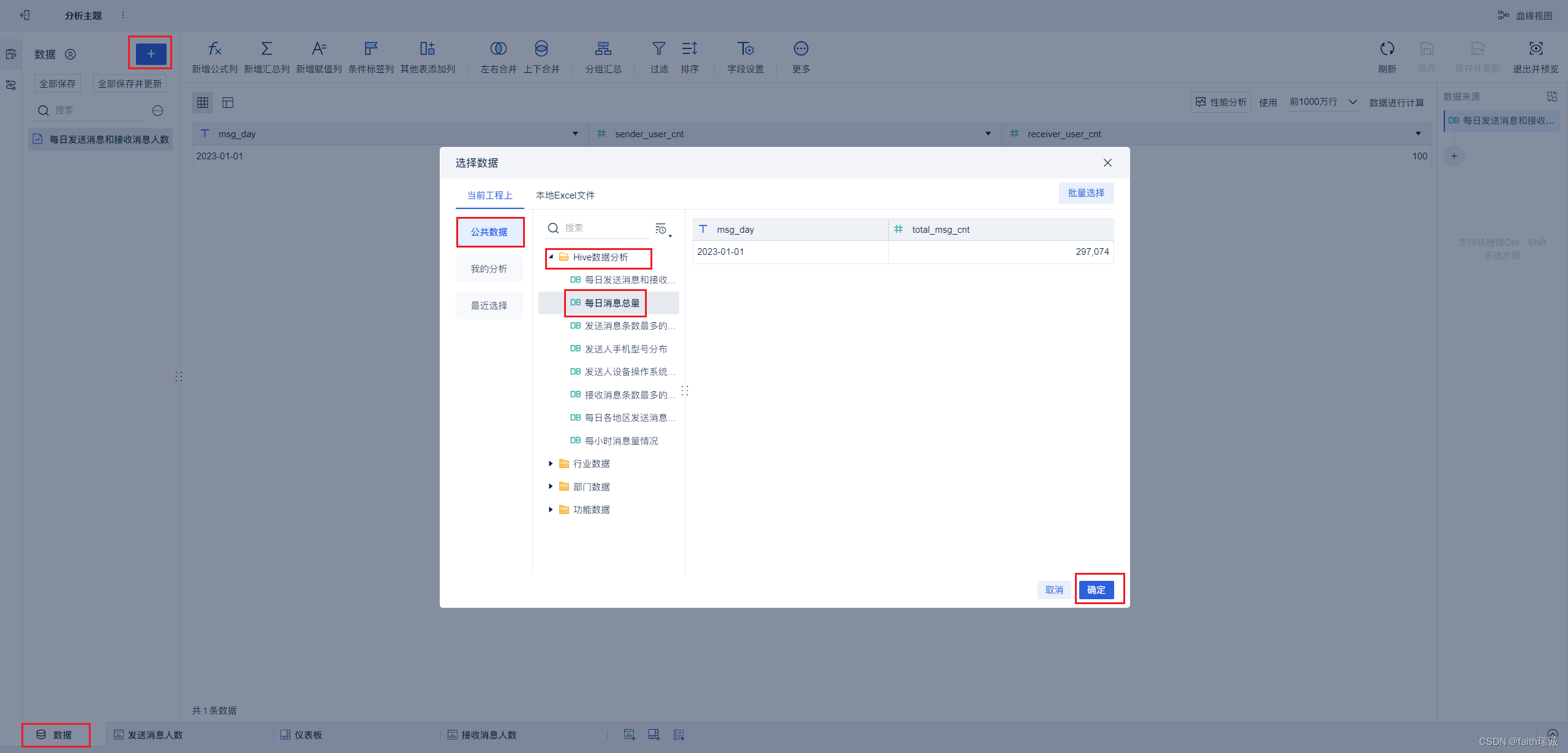
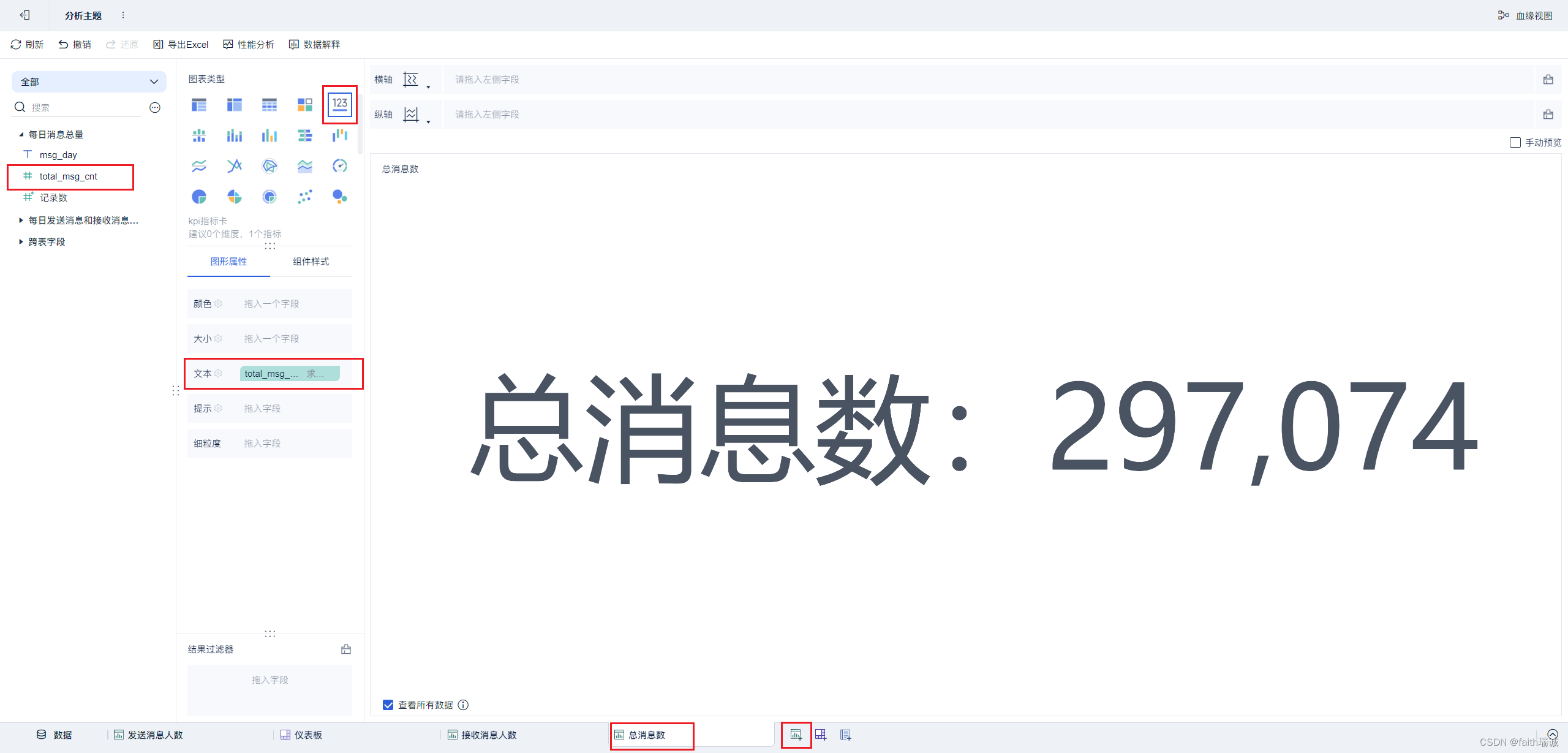
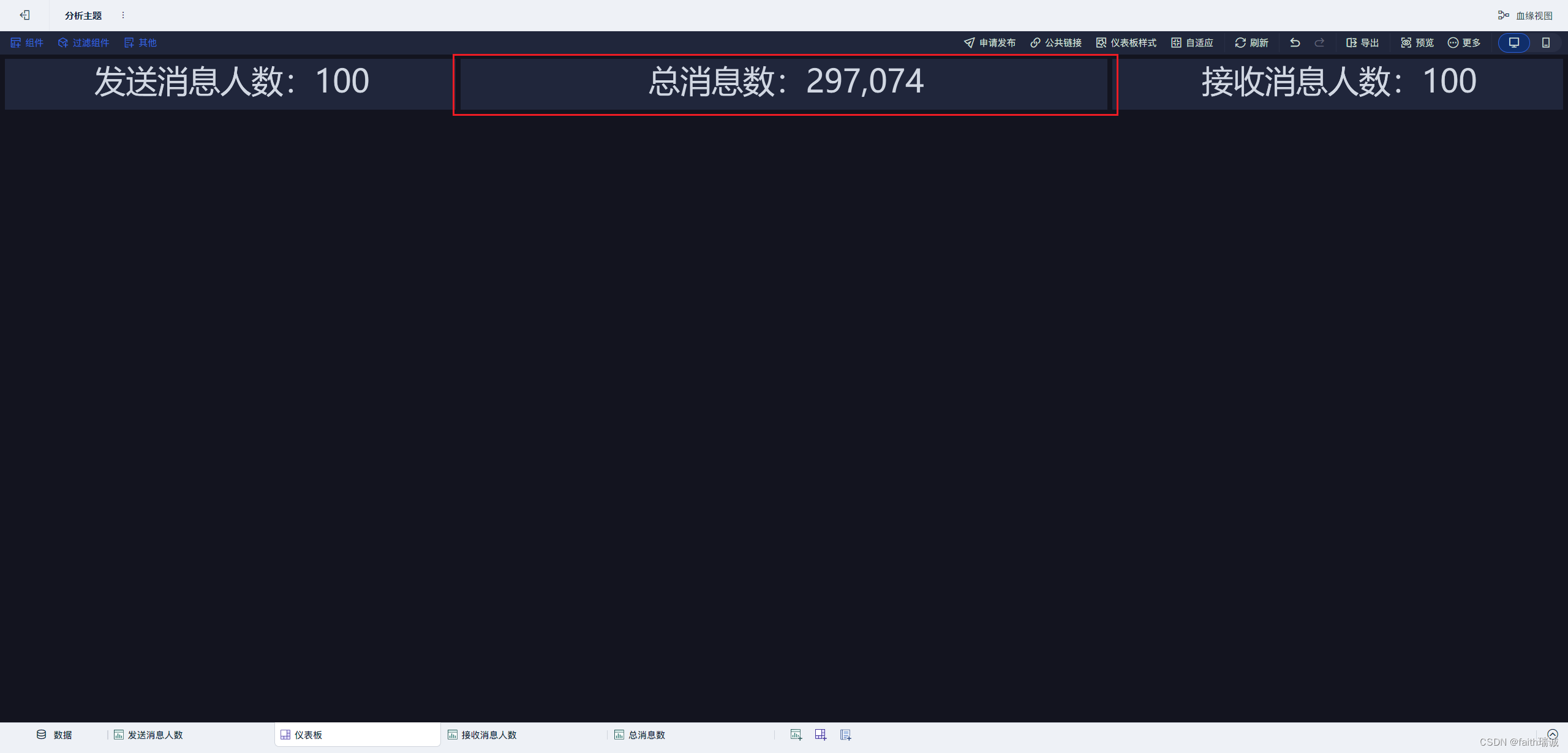
16、然后添加“总消息数”组件,参考上面完成组件配置,并摆放在仪表板上;
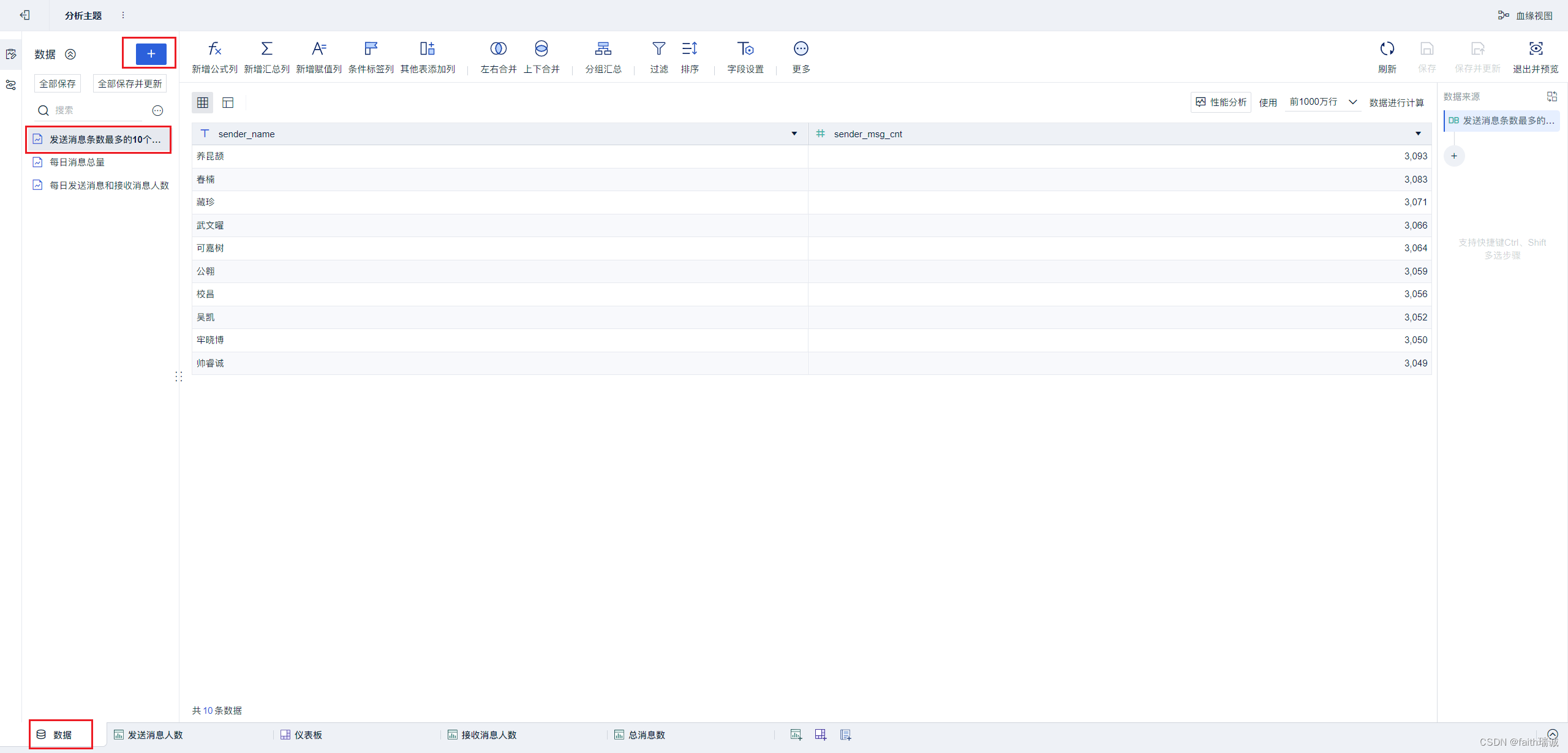
17、按照类似方法创建“发送消息最多的用户TOP10”组件;
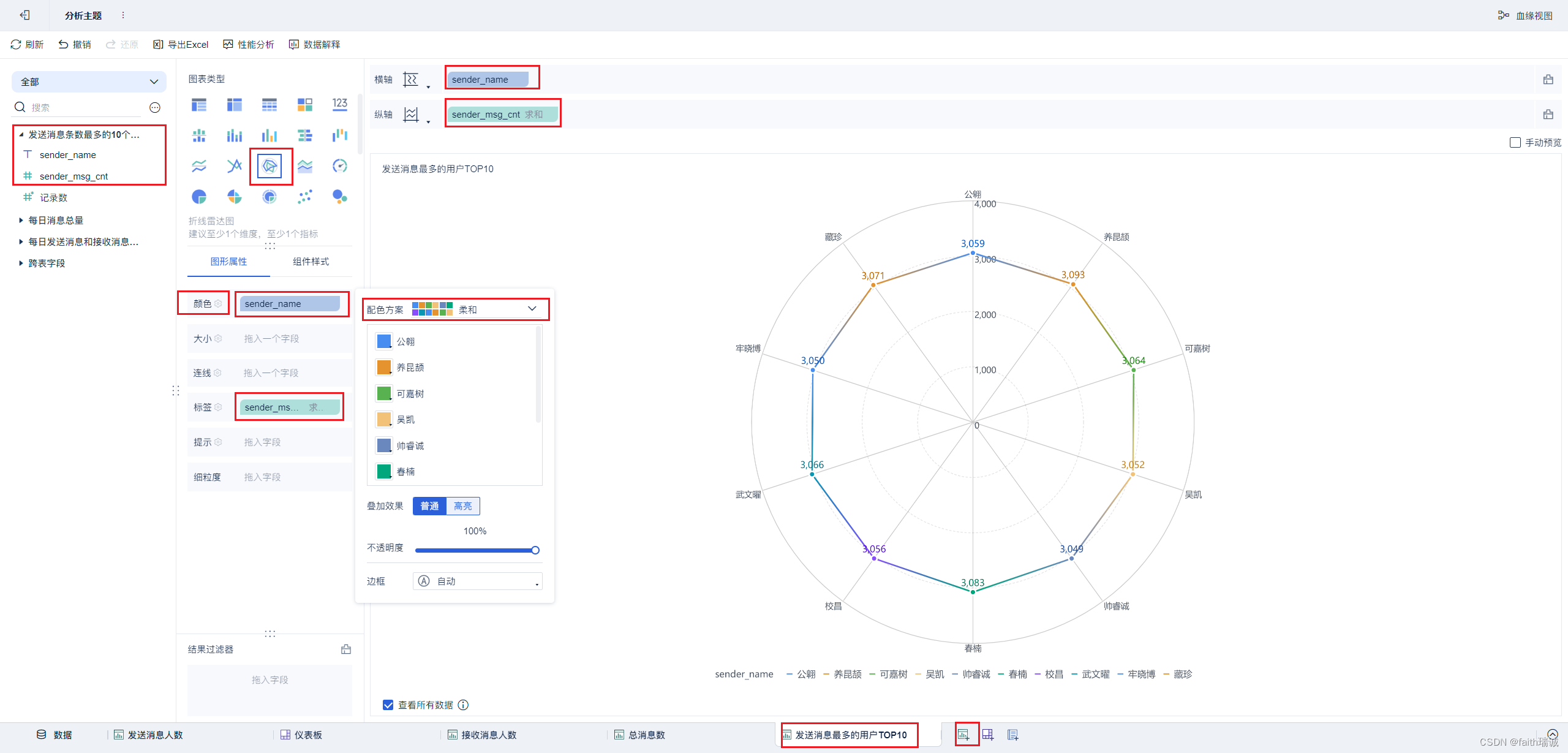
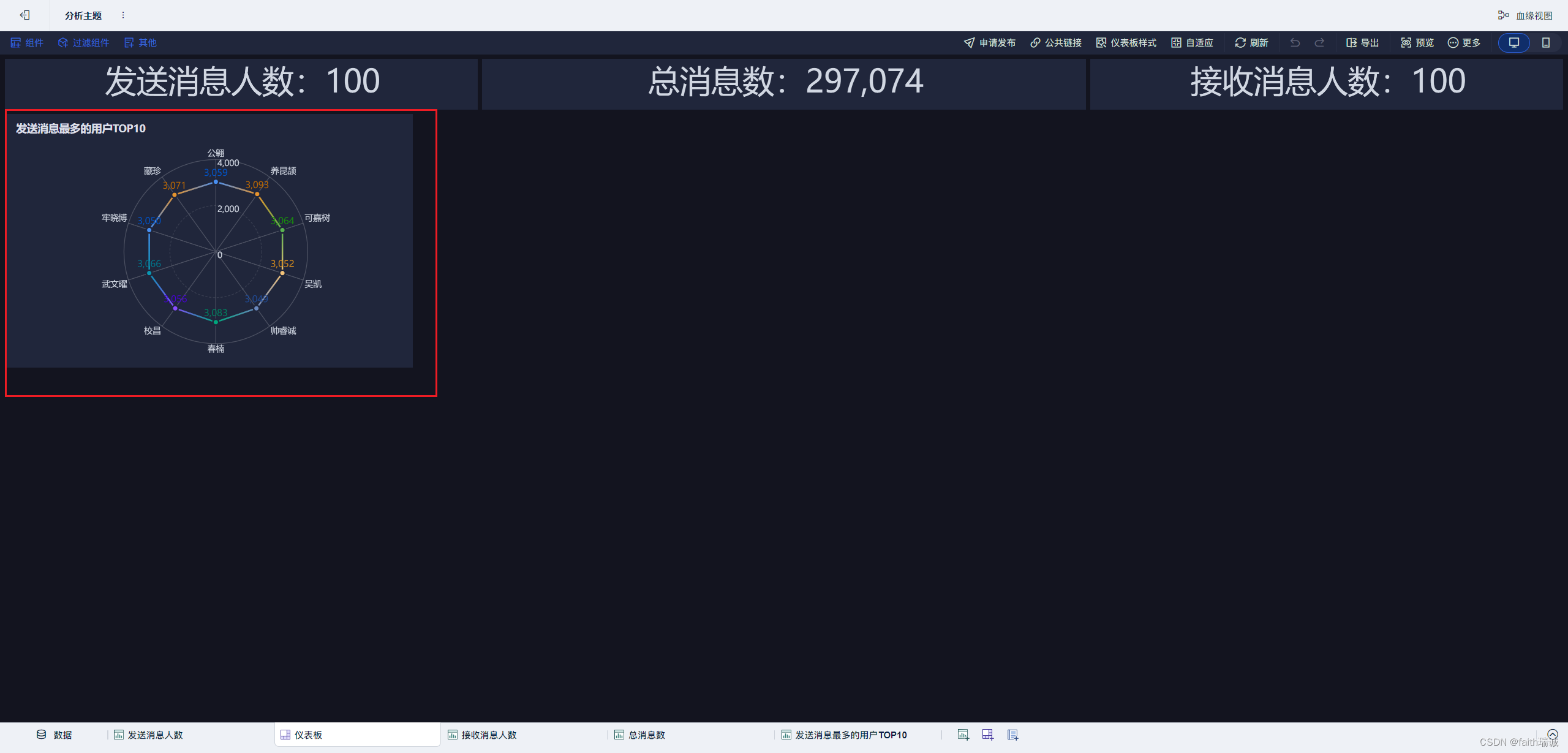
18、按照类似方法创建“发送用户操作系统占比”组件;
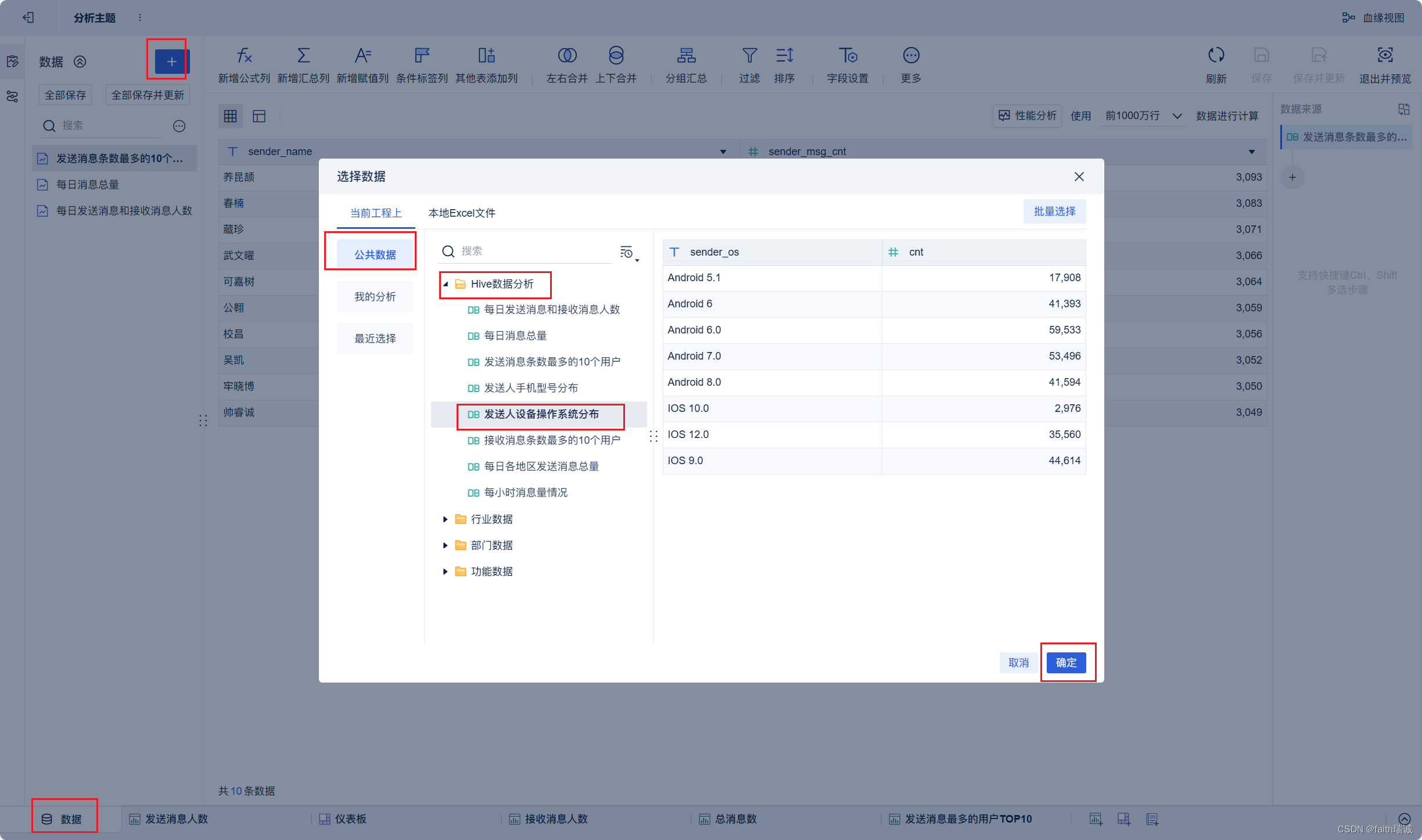
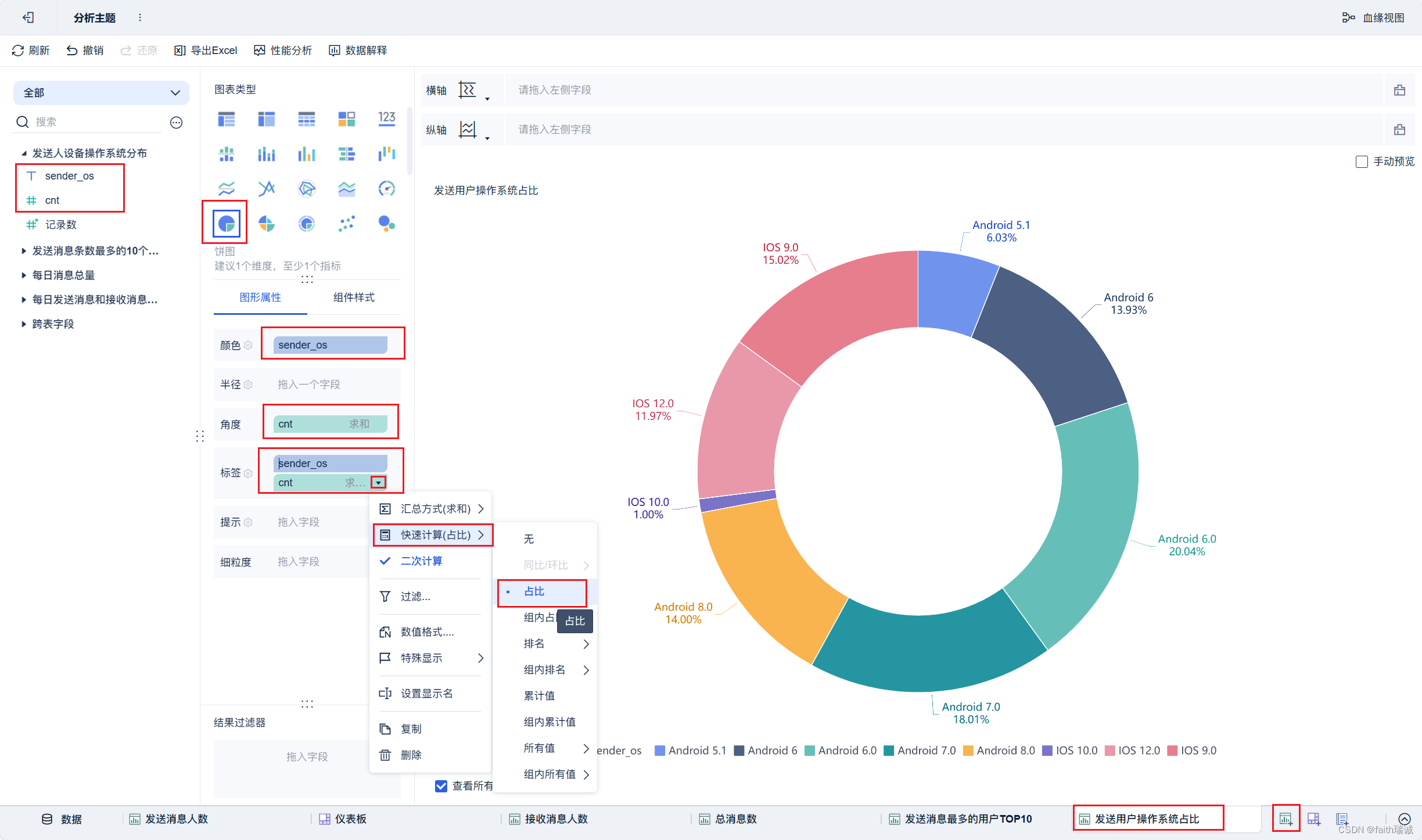
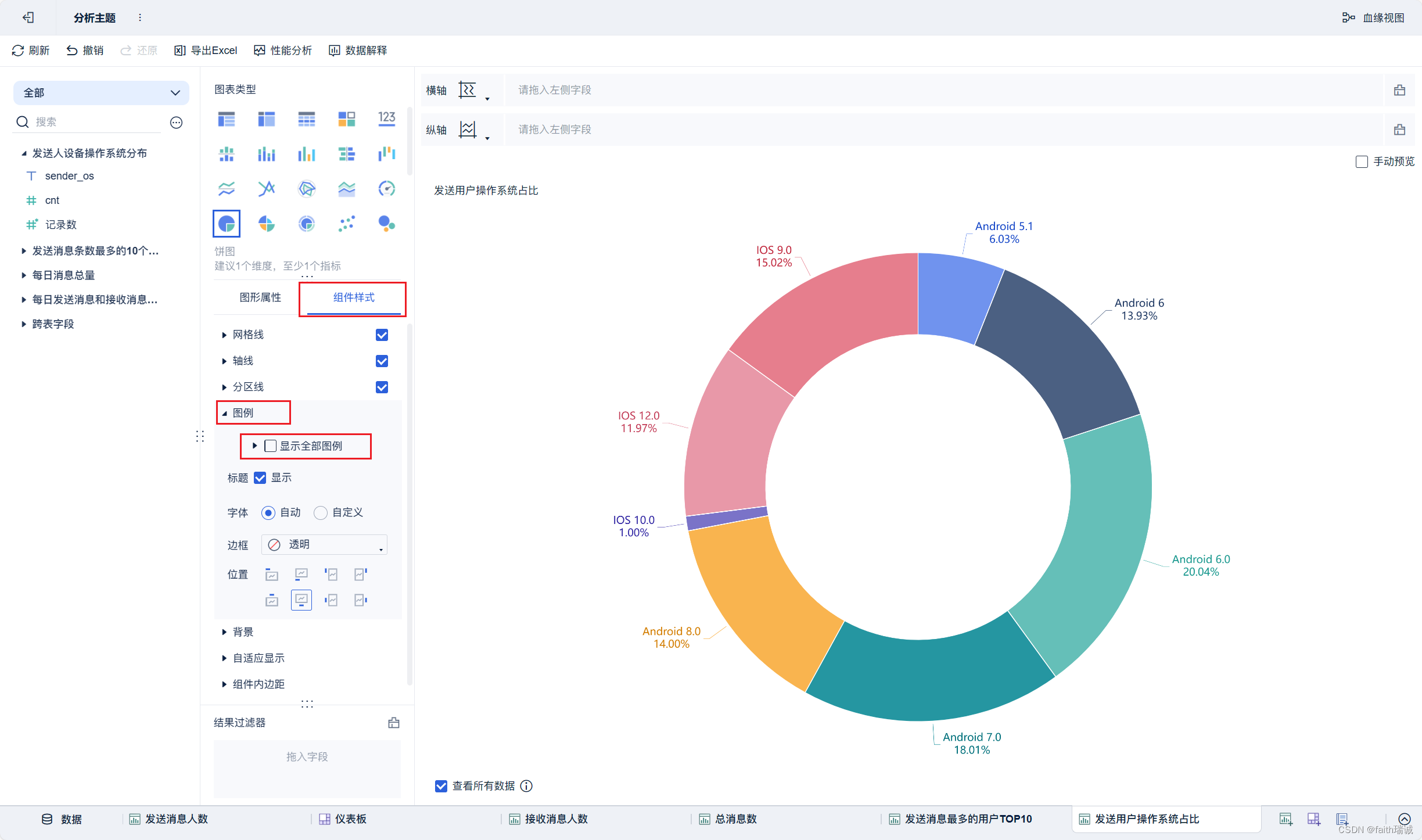
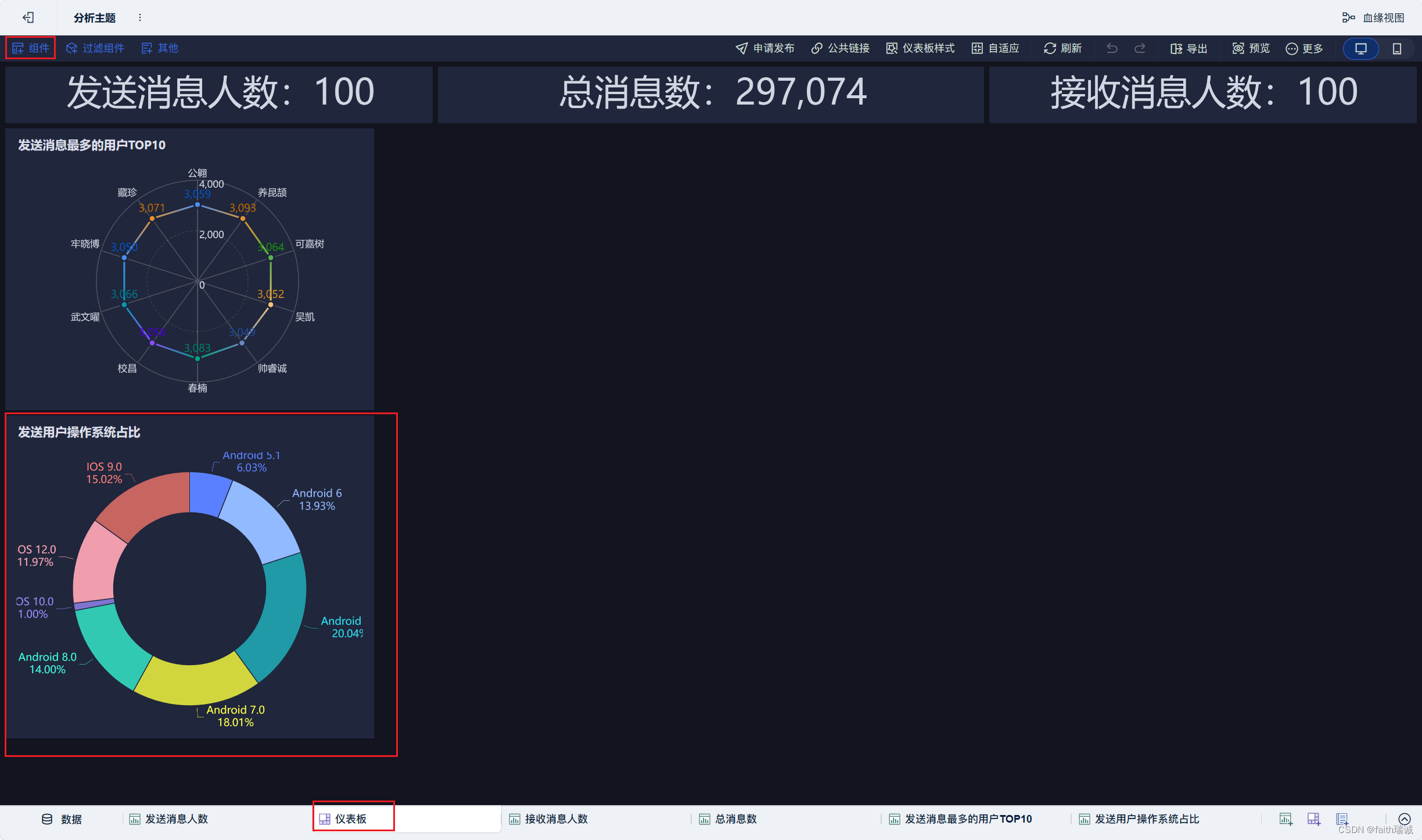
19、按照类似方法创建地图组件;
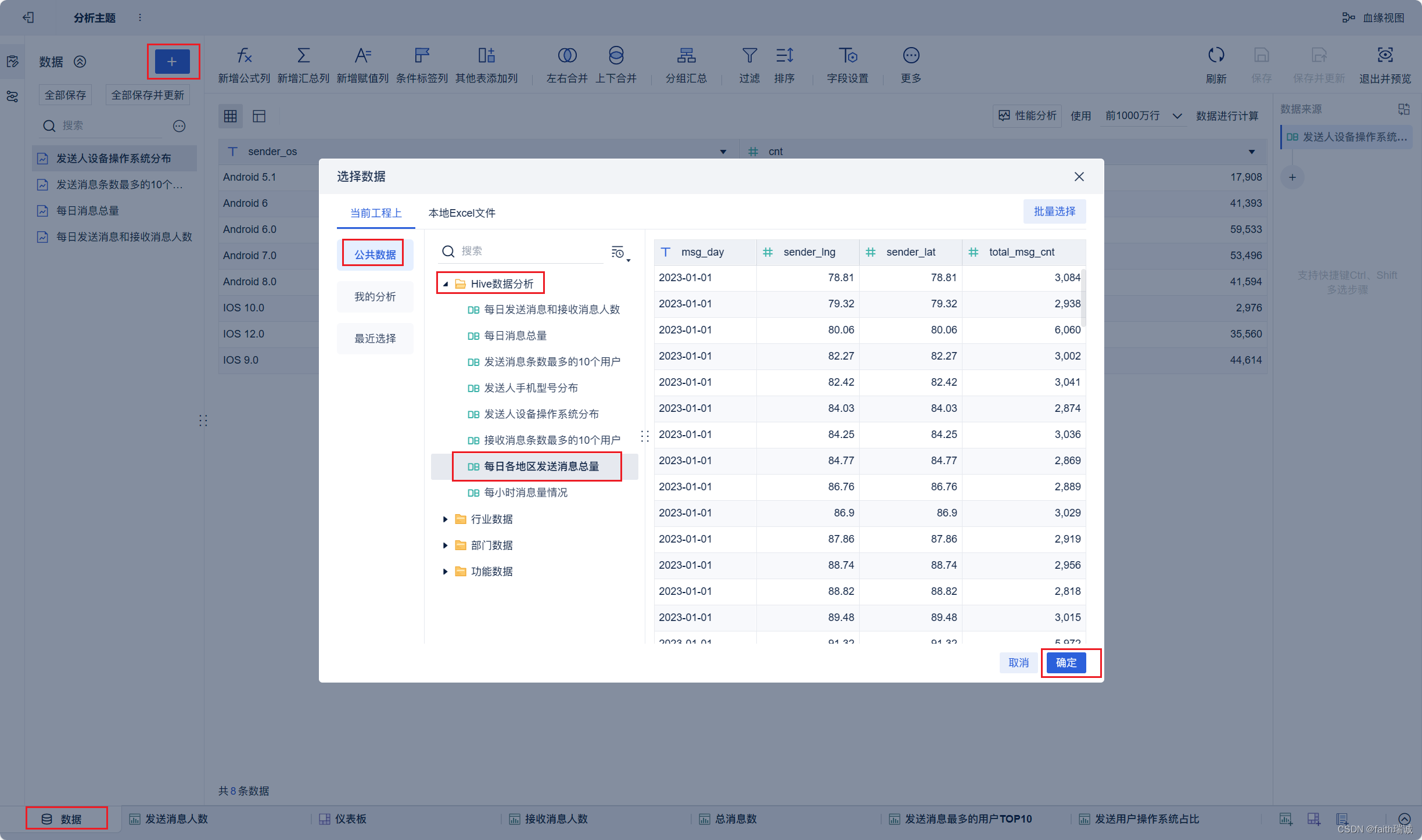
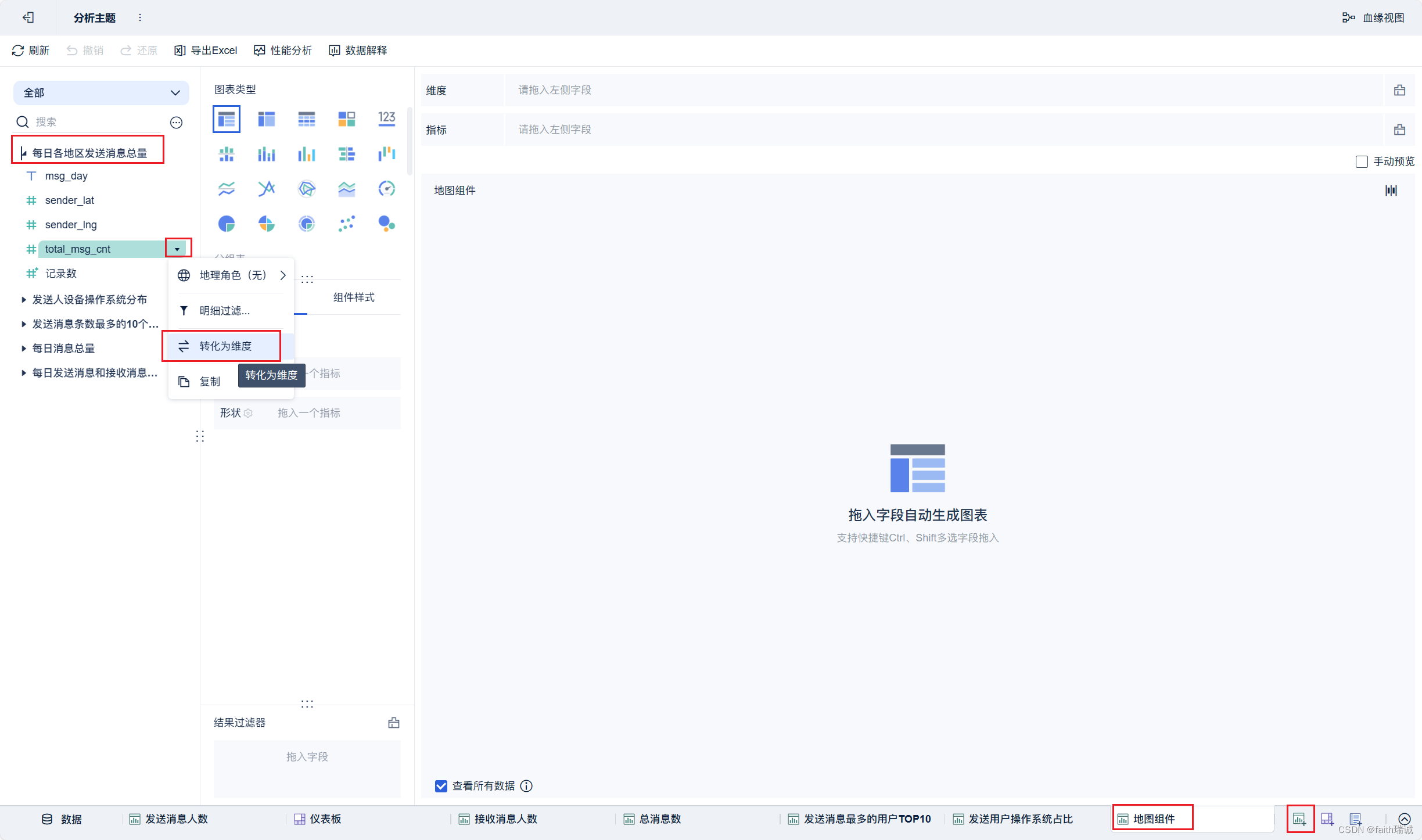
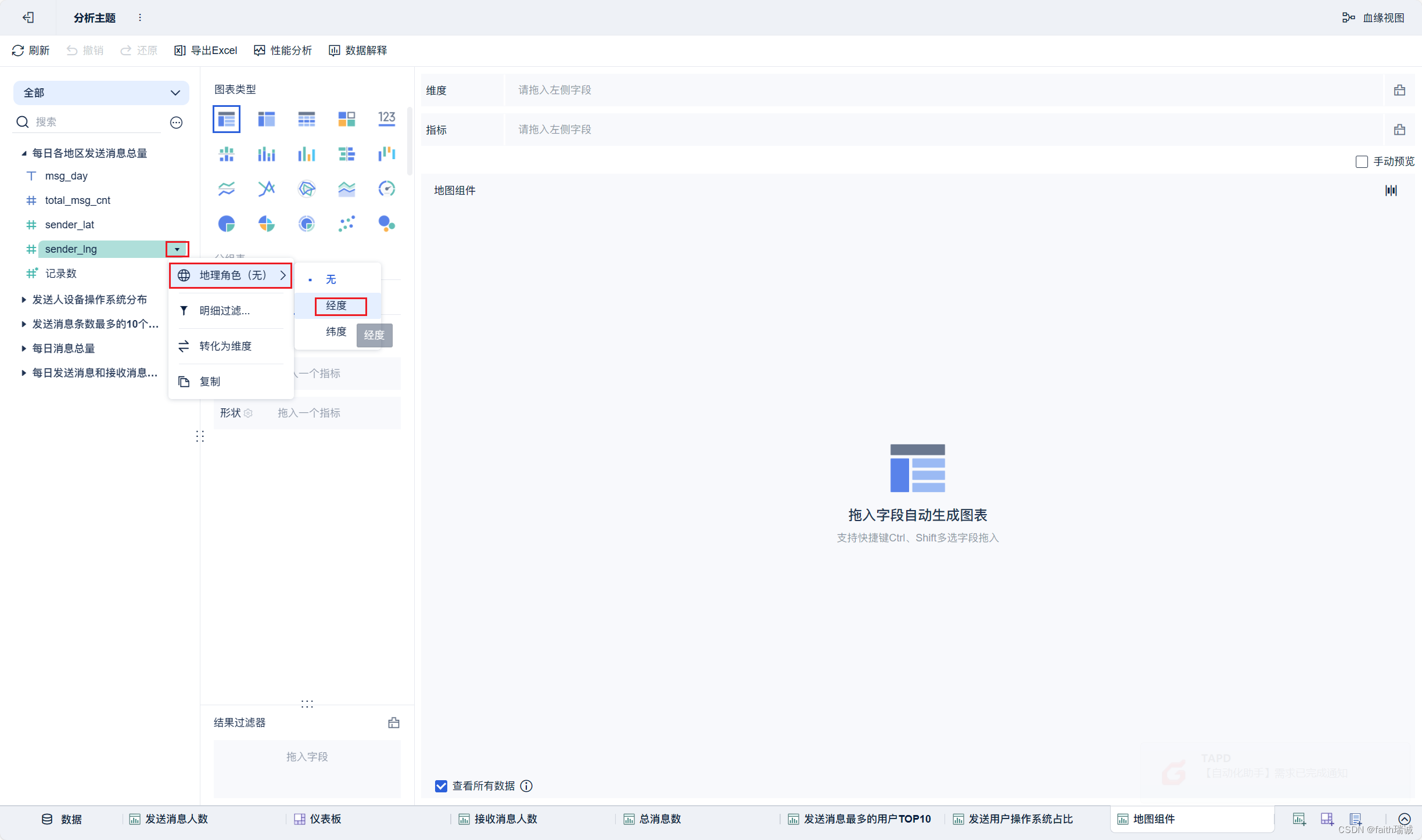
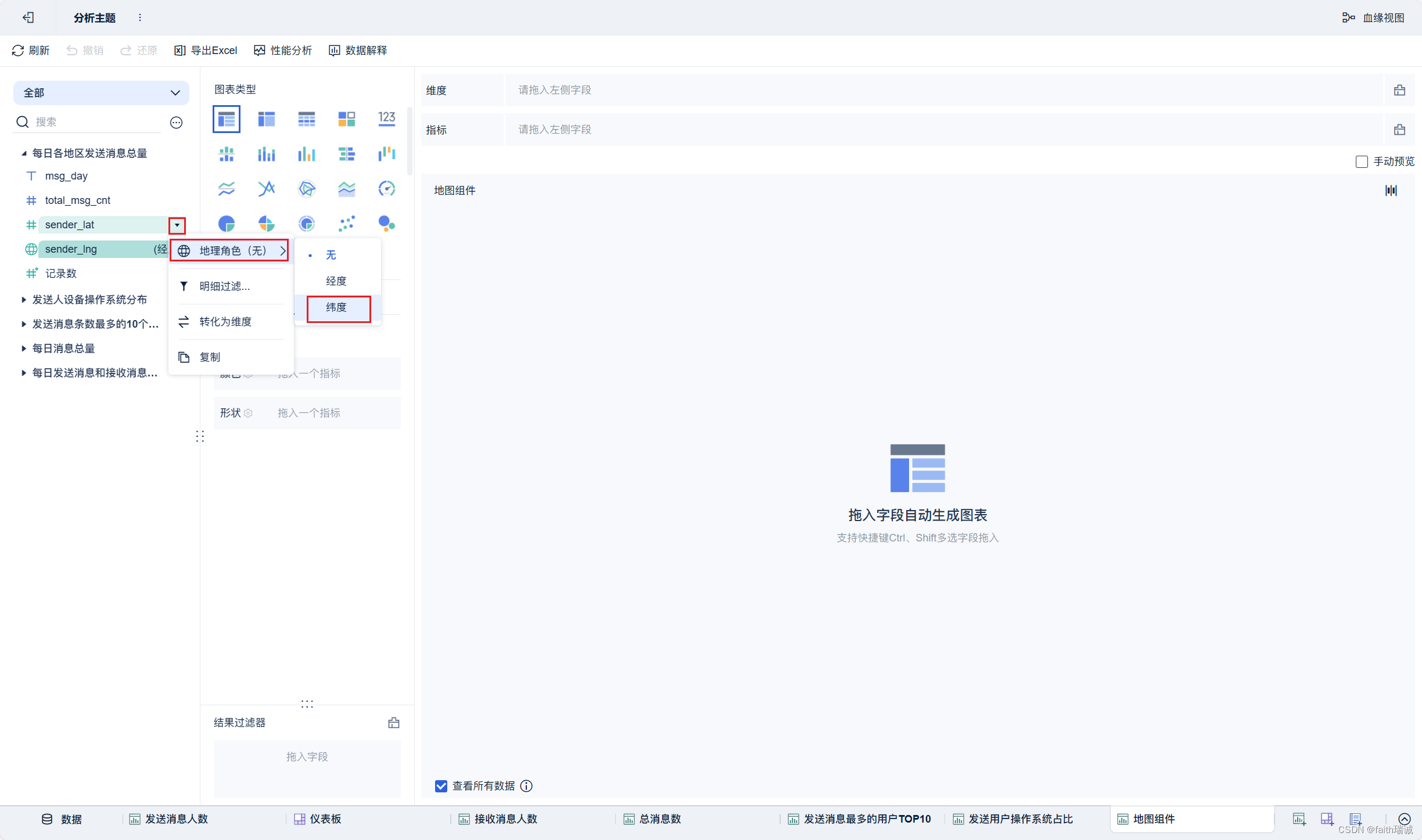
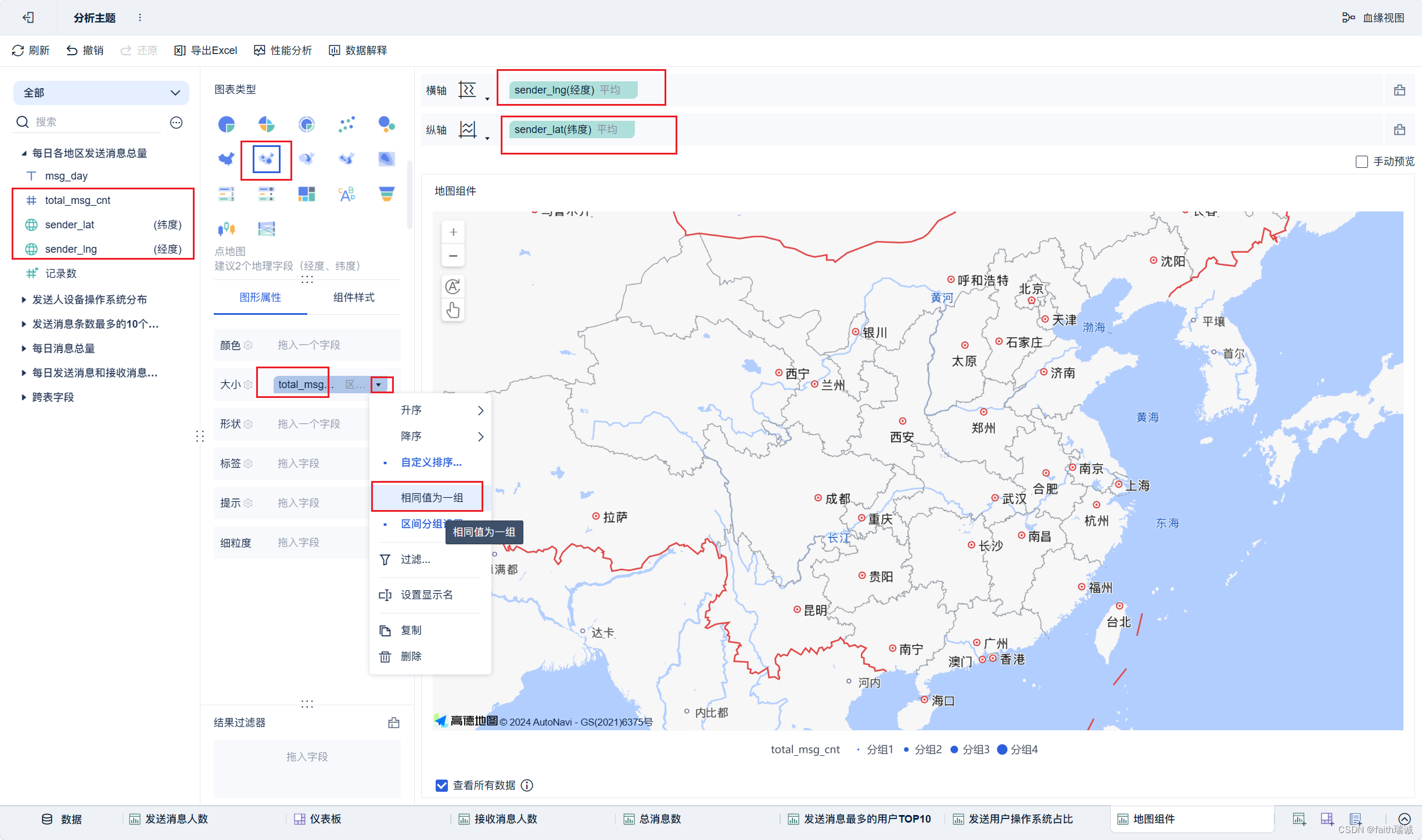
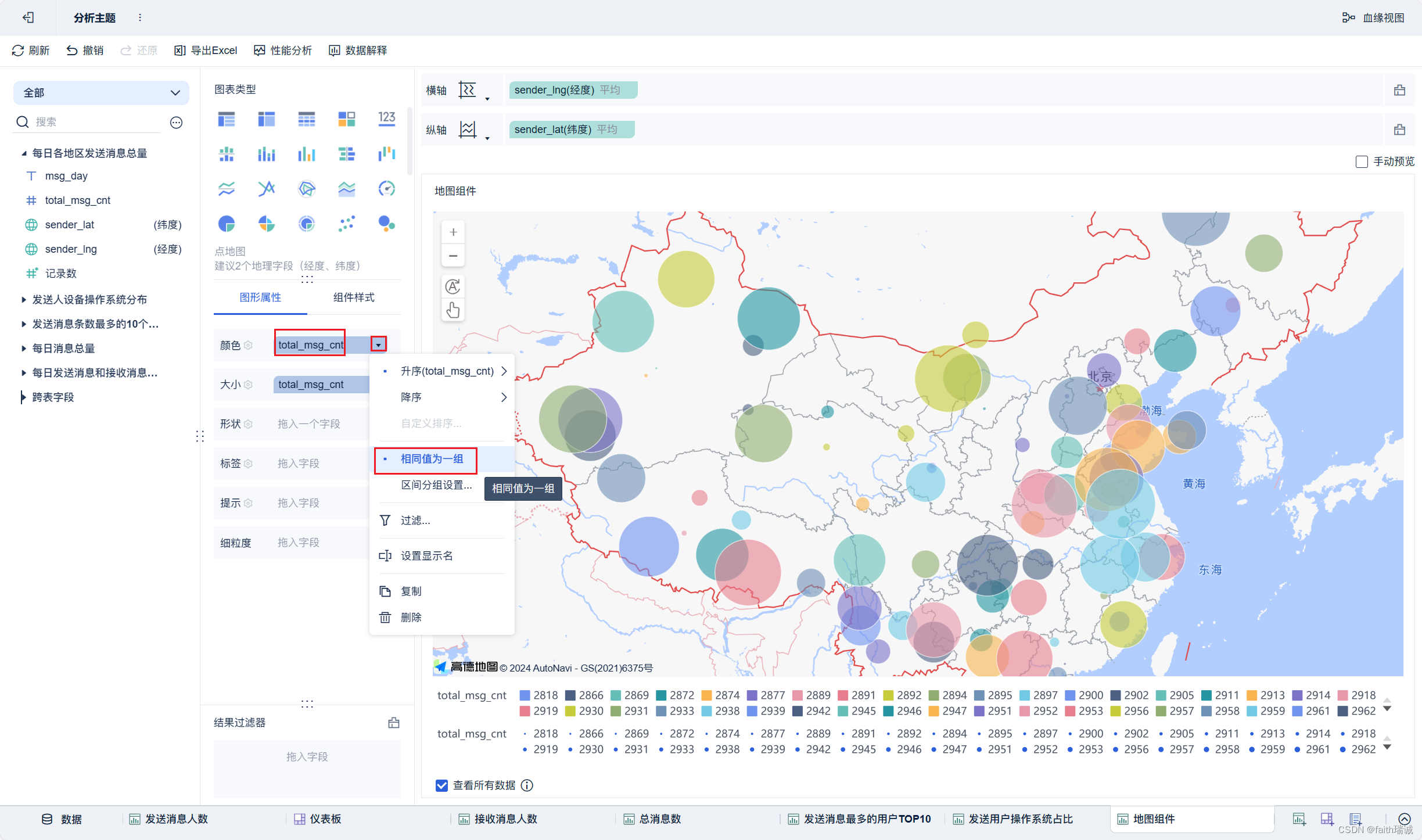
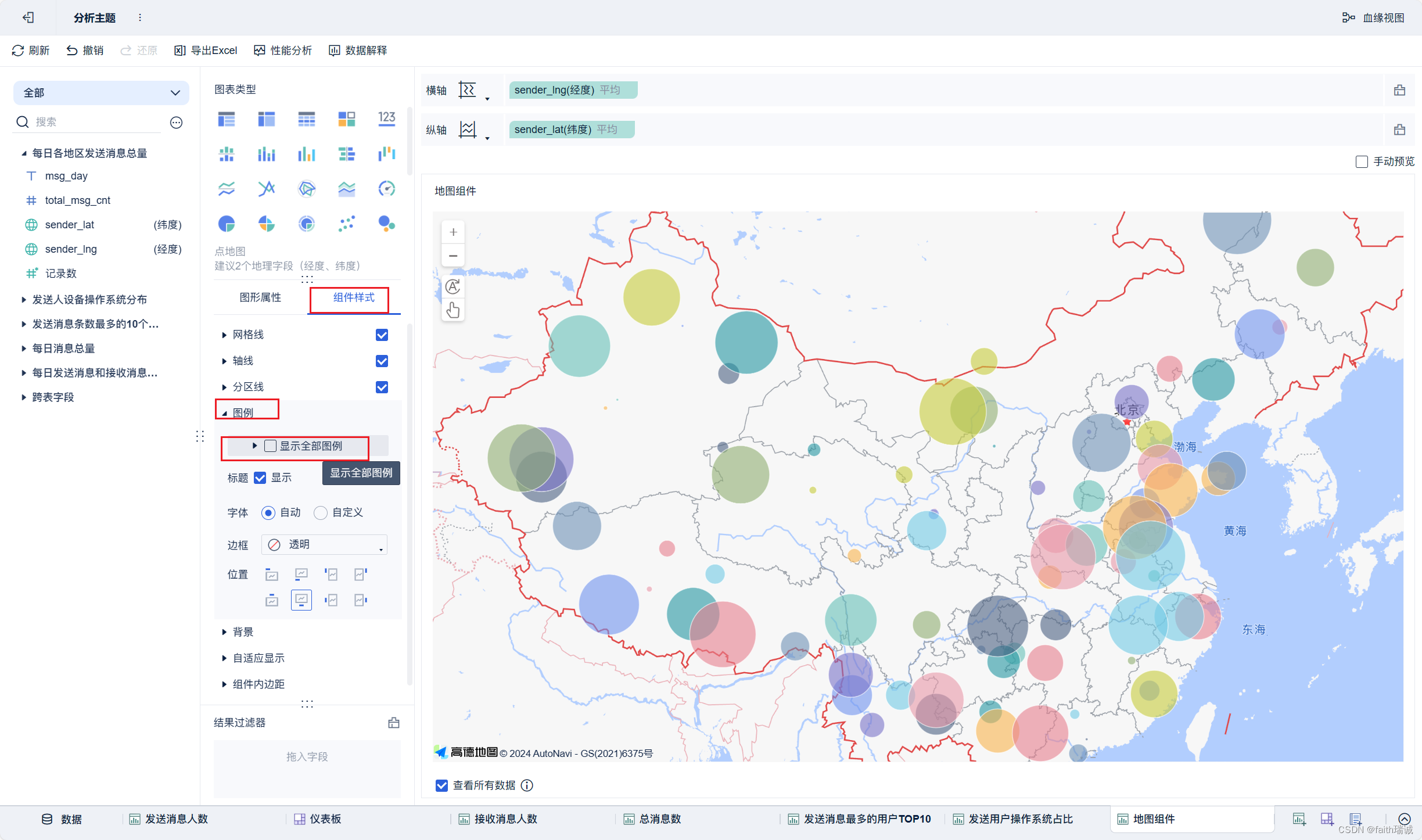
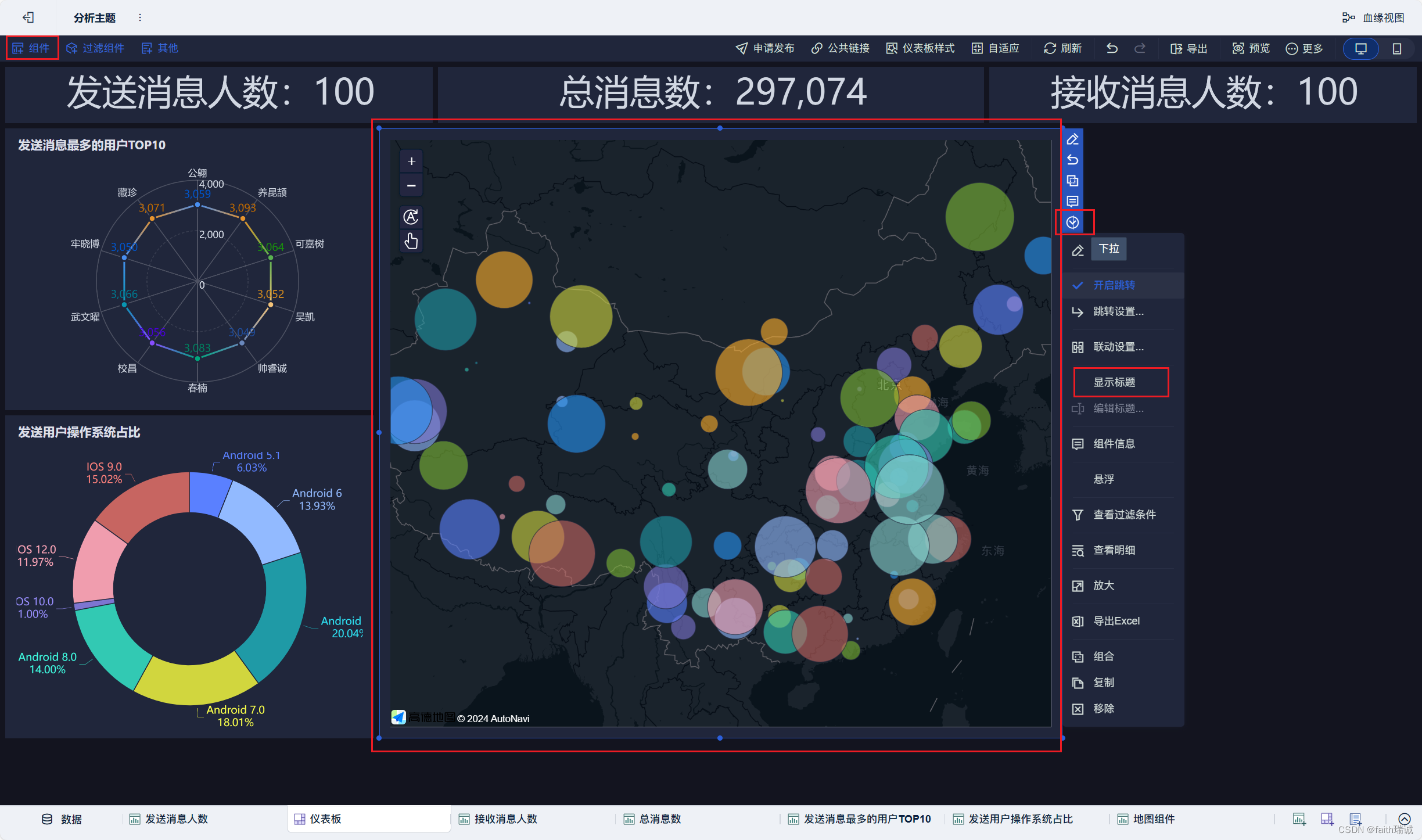
20、按照类似方法创建“接收消息最多的用户TOP10”组件;
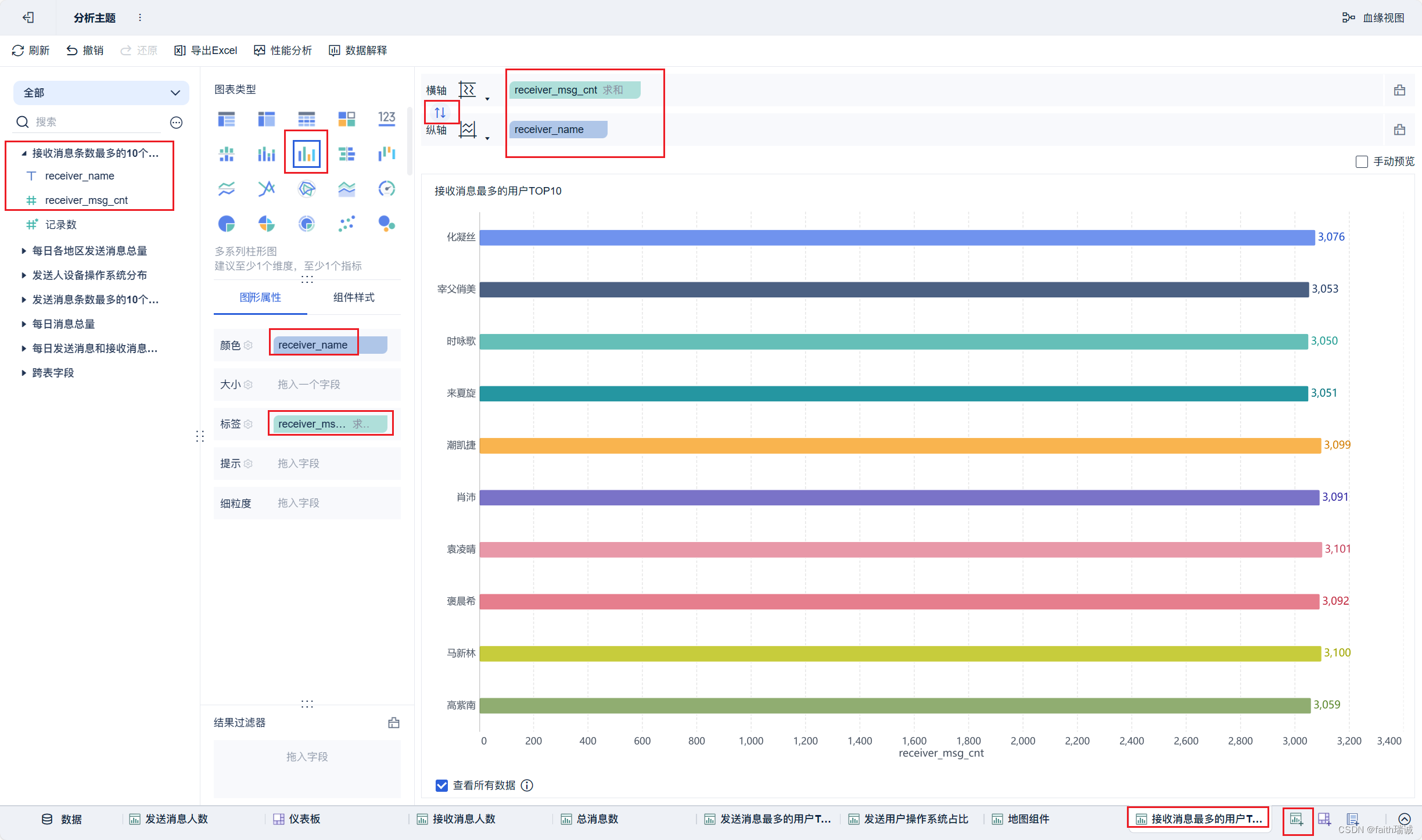
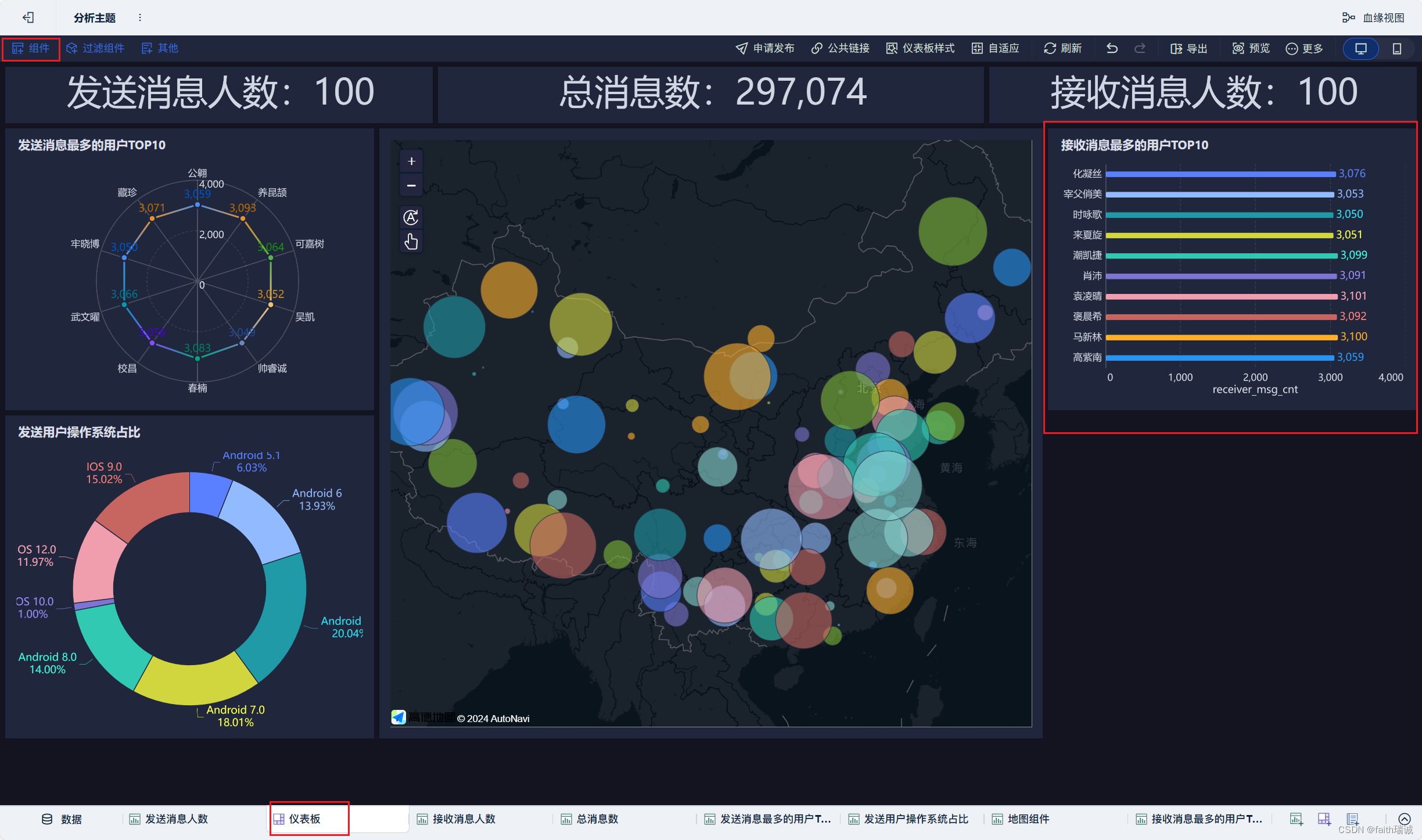
21、按照类似方法创建“发送用户手机型号分布”组件;
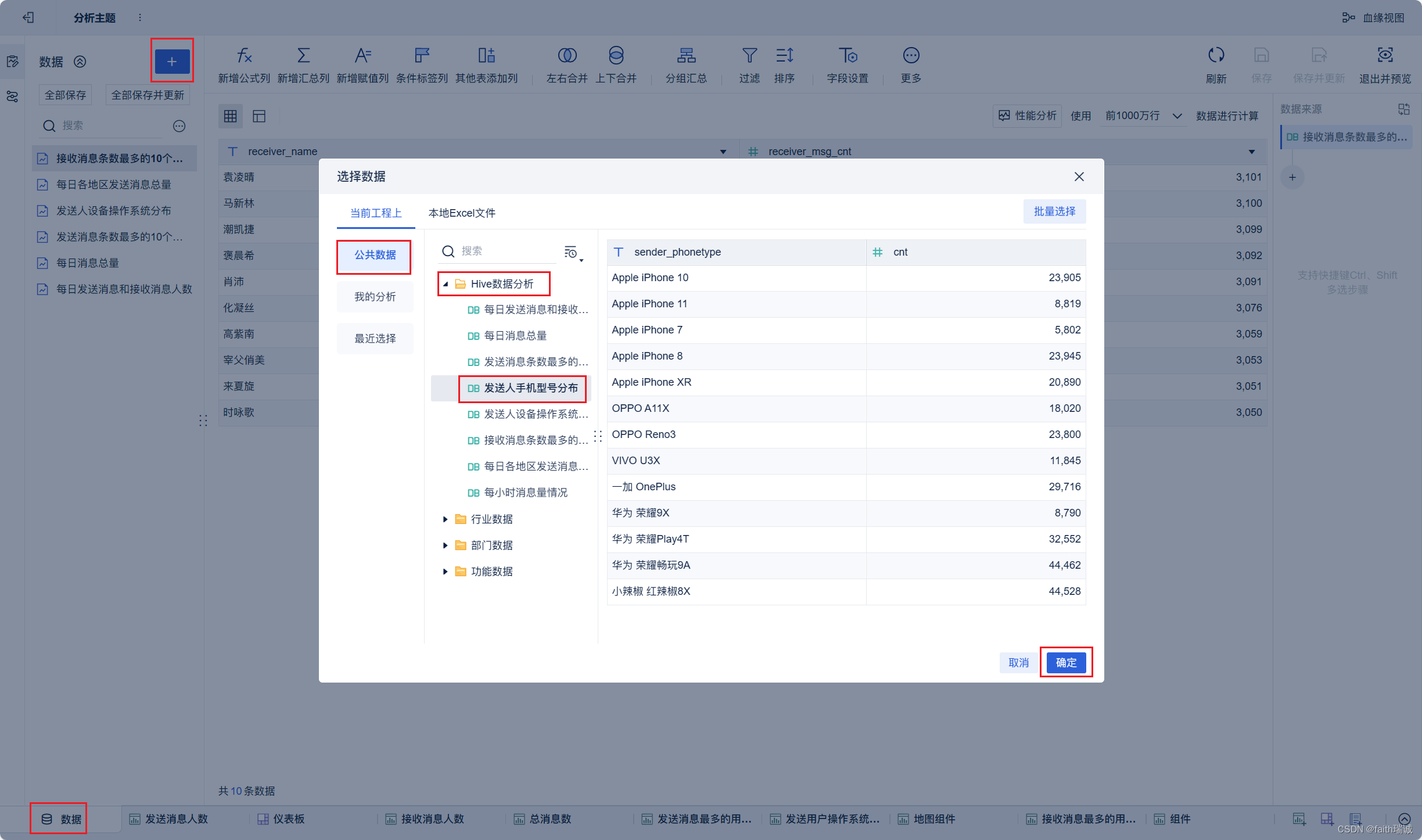
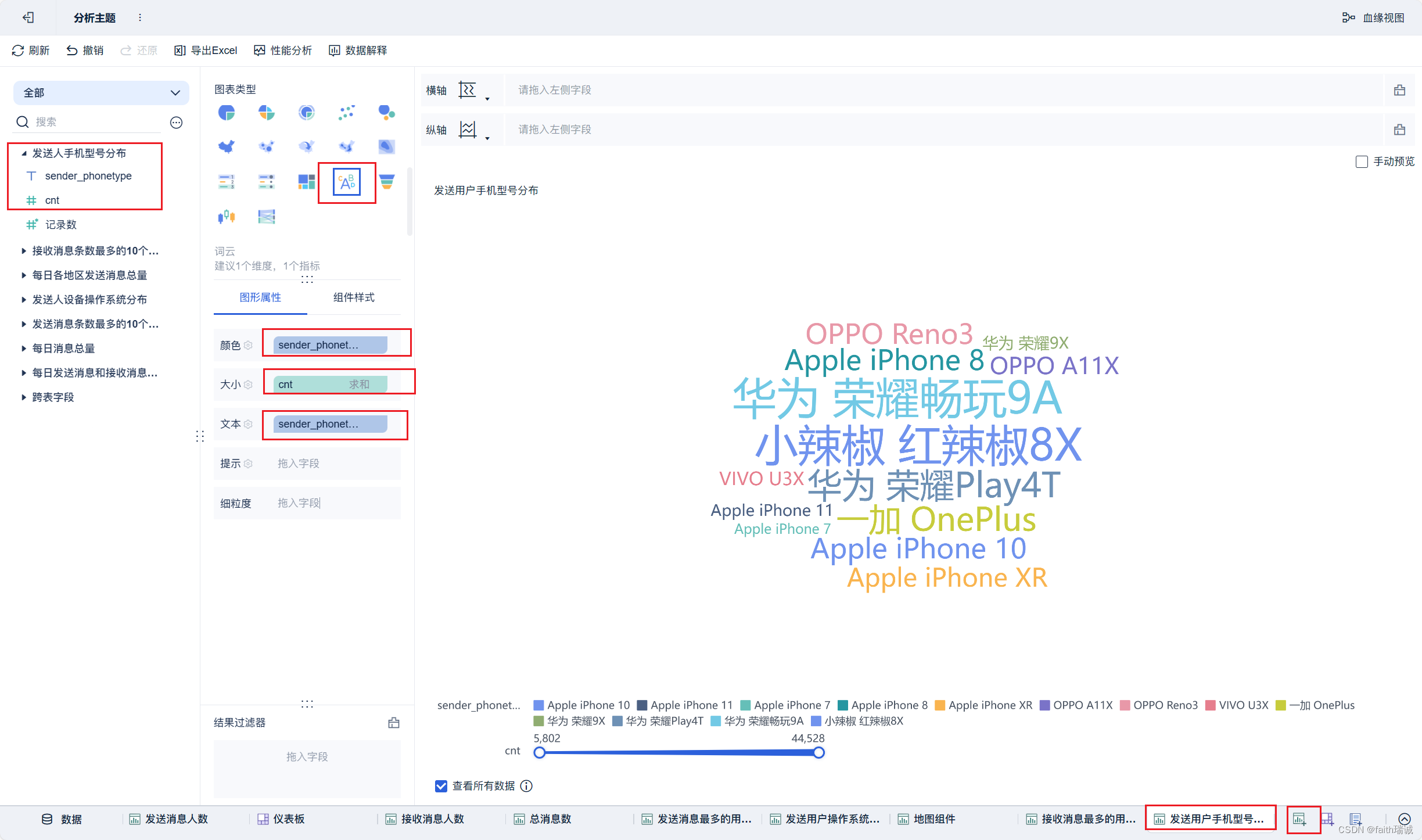
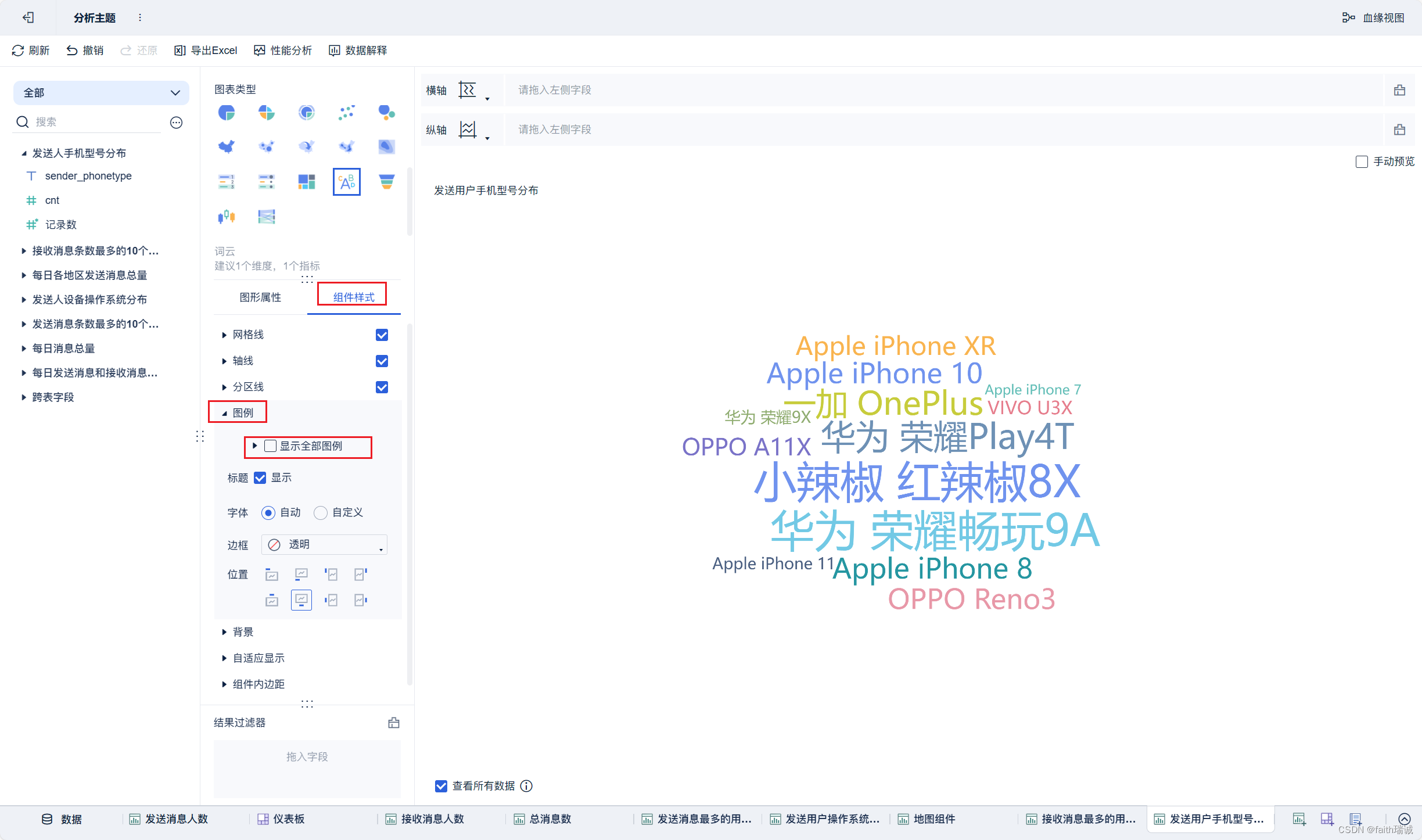
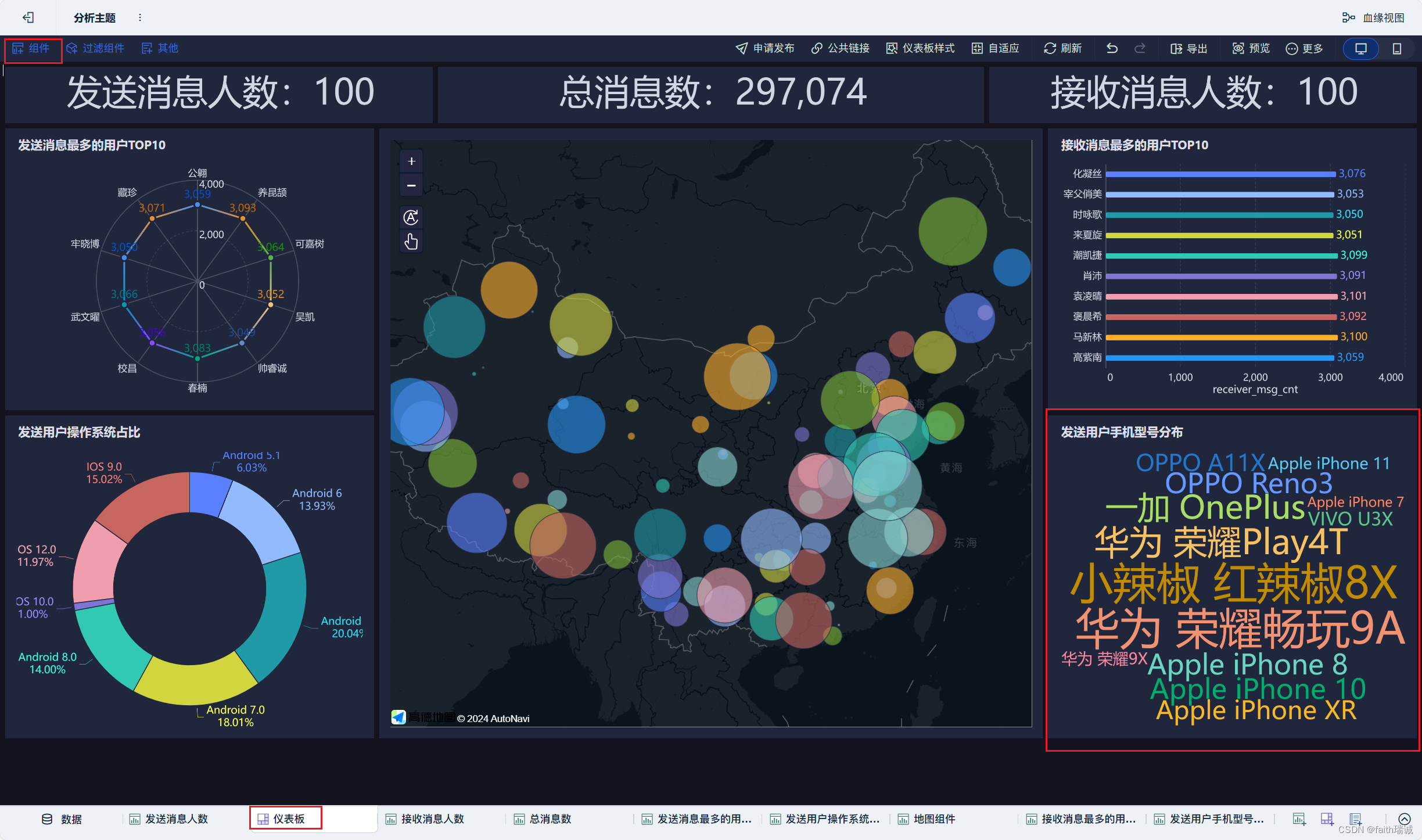
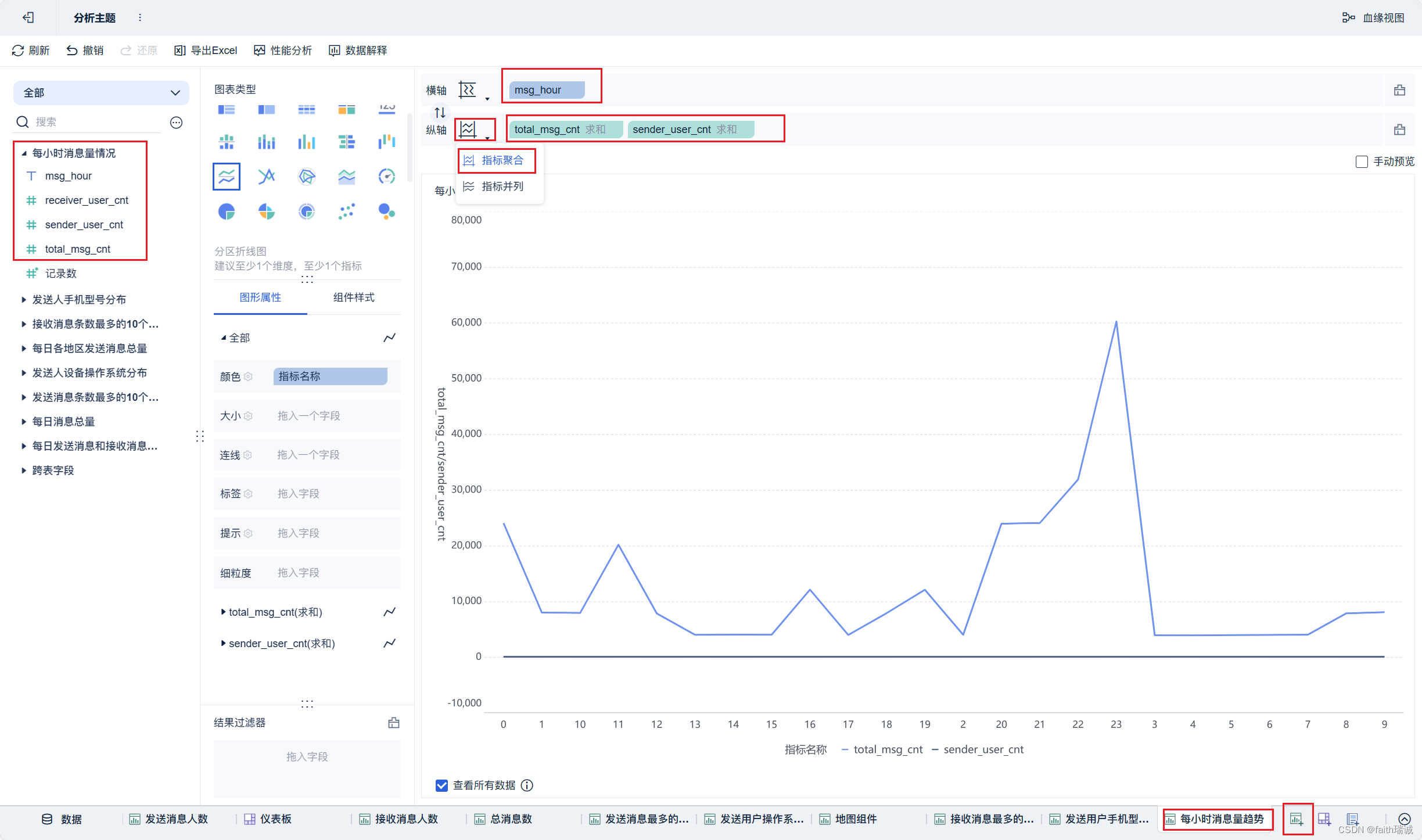
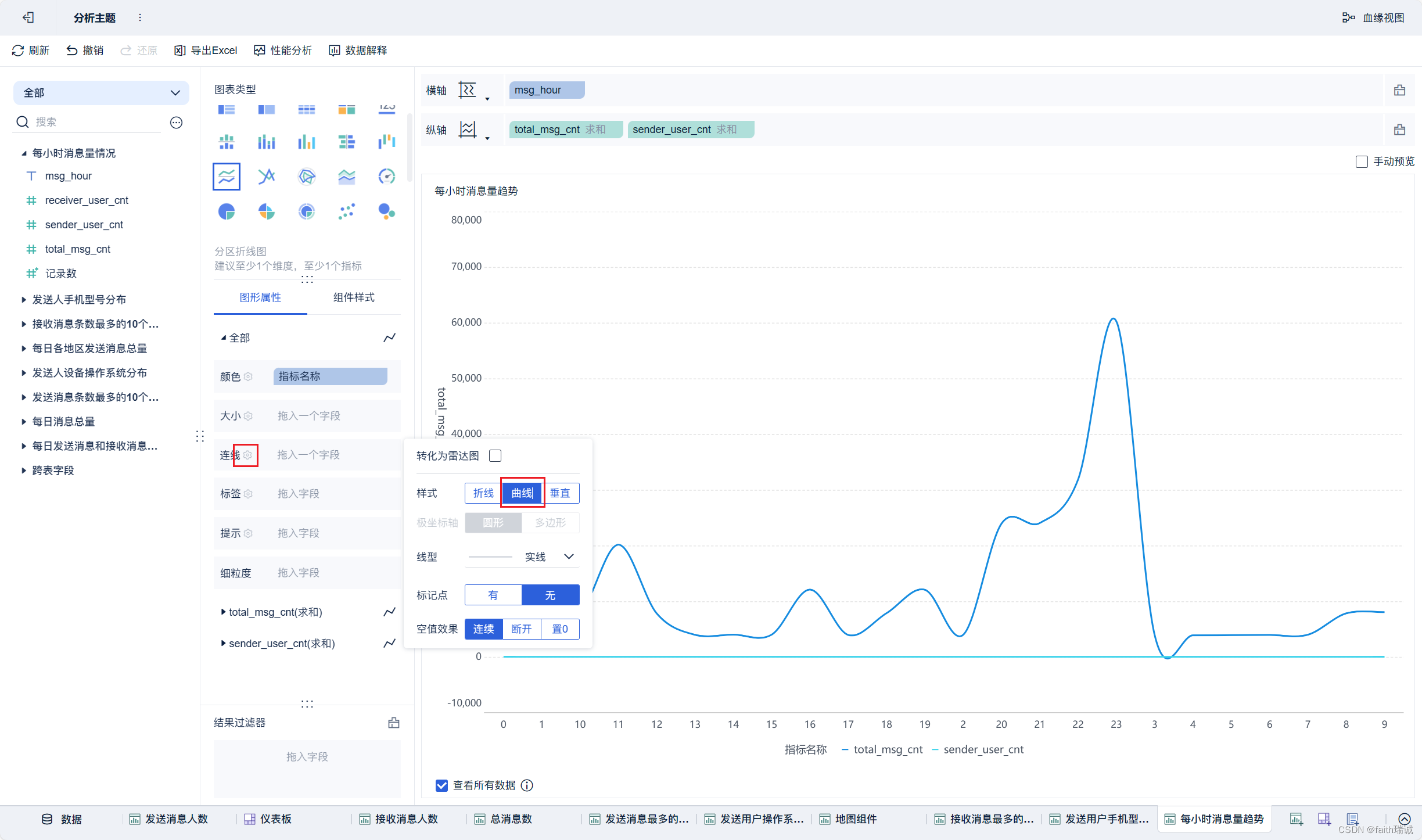
22、按照类似方法创建“每小时消息量趋势”组件;
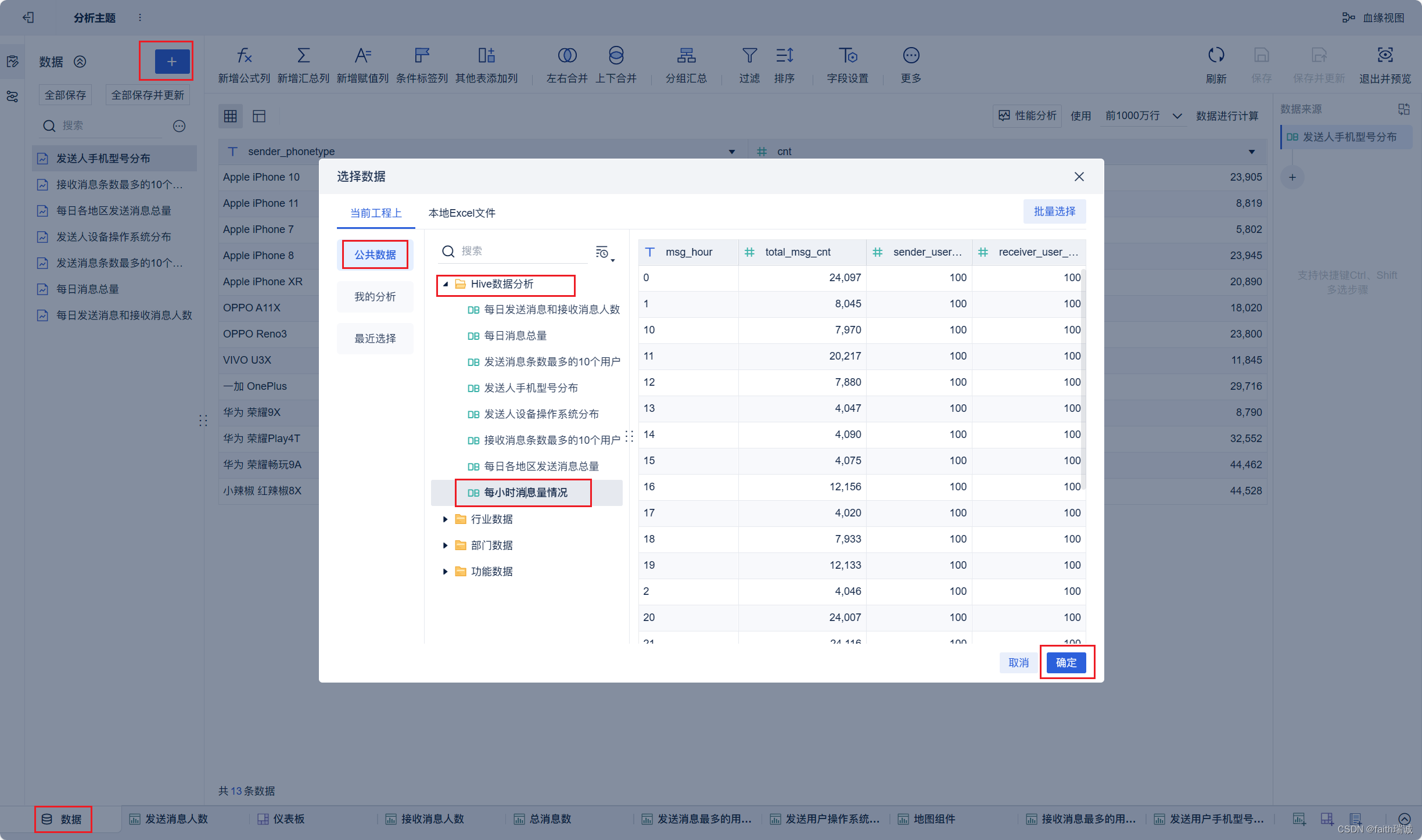
至此,所有内容结束。

