
- 1Pytorch to(device)_pytorch to device
- 2语言中 函数用地址传参的好处
- 3【python教程入门学习】Python字典及基本操作(超级详细)_python字典的基本操作
- 4java导出excel的两种方式
- 5节点内DataNode磁盘使用率不均衡处理指导_dfs.datanode.fsdataset.volume.choosing.policy
- 6二叉树的遍历(C语言)_二叉树遍历代码c语言
- 7【LeetCode】对称二叉树,相同的数_二叉树如果碰到了相同的数字
- 8ClientCnxn: Session 0x0 for server null, unexpected error Connection refused
- 9【从0到1】搭建Neo4j数据库环境_neo4j 社区版 主从环境搭建
- 10MPU6050篇——姿态解算,卡尔曼滤波_mpu6050姿态解算代码
Elasticsearch:从 Java High Level Rest Client 切换到新的 Java API Client_resthighlevelclient 升级
赞
踩
作者:David Pilato

我经常在讨论中看到与 Java API 客户端使用相关的问题。 为此,我在 2019 年启动了一个 GitHub 存储库,以提供一些实际有效的代码示例并回答社区提出的问题。
从那时起,高级 Rest 客户端 (High Level Rest Cliet - HLRC) 已被弃用,并且新的 Java API 客户端已发布。
为了继续回答问题,我最近需要将存储库升级到这个新客户端。 尽管它在幕后使用相同的低级 Rest 客户端,并且已经提供了升级文档,但升级它并不是一件小事。
我发现分享为此必须执行的所有步骤很有趣。 如果你 “只是寻找” 进行升级的拉取请求,请查看:
这篇博文将详细介绍你在这些拉取请求中可以看到的一些主要步骤。
Java 高级 Rest 客户端 (High Level Rest Client)
我们从一个具有以下特征的项目开始:
- Maven 项目(但这也可以应用于 Gradle 项目)
- 使用以下任一方法运行 Elasticsearch 7.17.16:
- Docker compose
- 测试容器
- 使用高级 Rest 客户端 7.17.16
注意:大家在这里对于 7.17.16 的选择可能有点糊涂。我们需要记住的一点是上一个大的版本的最后一个版本和下一个大的版本的第一个是兼容的。

客户端依赖项是:
- <!-- Elasticsearch HLRC -->
- <dependency>
- <groupId>org.elasticsearch.client</groupId>
- <artifactId>elasticsearch-rest-high-level-client</artifactId>
- <version>7.17.16</version>
- </dependency>
-
- <!-- Jackson for json serialization/deserialization -->
- <dependency>
- <groupId>com.fasterxml.jackson.core</groupId>
- <artifactId>jackson-core</artifactId>
- <version>2.15.0</version>
- </dependency>
- <dependency>
- <groupId>com.fasterxml.jackson.core</groupId>
- <artifactId>jackson-databind</artifactId>
- <version>2.15.0</version>
- </dependency>

我们正在检查本地 Elasticsearch 实例是否正在 http://localhost:9200 上运行。 如果没有,我们将启动测试容器:
- @BeforeAll
- static void startOptionallyTestcontainers() {
- client = getClient("http://localhost:9200");
- if (client == null) {
- container = new ElasticsearchContainer(
- DockerImageName.parse("docker.elastic.co/elasticsearch/elasticsearch")
- .withTag("7.17.16"))
- .withPassword("changeme");
- container.start();
- client = getClient(container.getHttpHostAddress());
- assumeNotNull(client);
- }
- }
为了构建客户端(RestHighLevelClient),我们使用:
- static private RestHighLevelClient getClient(String elasticsearchServiceAddress) {
- try {
- final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
- credentialsProvider.setCredentials(AuthScope.ANY,
- new UsernamePasswordCredentials("elastic", "changeme"));
-
- // Create the low-level client
- RestClientBuilder restClient = RestClient.builder(HttpHost.create(elasticsearchServiceAddress))
- .setHttpClientConfigCallback(hcb -> hcb.setDefaultCredentialsProvider(credentialsProvider));
-
- // Create the high-level client
- RestHighLevelClient client = new RestHighLevelClient(restClient);
-
- MainResponse info = client.info(RequestOptions.DEFAULT);
- logger.info("Connected to a cluster running version {} at {}.", info.getVersion().getNumber(), elasticsearchServiceAddress);
- return client;
- } catch (Exception e) {
- logger.info("No cluster is running yet at {}.", elasticsearchServiceAddress);
- return null;
- }
- }
你可能已经注意到,我们正在尝试调用 GET / 端点来确保客户端在开始测试之前确实已连接:
MainResponse info = client.info(RequestOptions.DEFAULT);然后,我们可以开始运行测试,如下例所示:
- @Test
- void searchData() throws IOException {
- try {
- // Delete the index if exist
- client.indices().delete(new DeleteIndexRequest("search-data"), RequestOptions.DEFAULT);
- } catch (ElasticsearchStatusException ignored) { }
- // Index a document
- client.index(new IndexRequest("search-data").id("1").source("{\"foo\":\"bar\"}", XContentType.JSON), RequestOptions.DEFAULT);
- // Refresh the index
- client.indices().refresh(new RefreshRequest("search-data"), RequestOptions.DEFAULT);
- // Search for documents
- SearchResponse response = client.search(new SearchRequest("search-data").source(
- new SearchSourceBuilder().query(
- QueryBuilders.matchQuery("foo", "bar")
- )
- ), RequestOptions.DEFAULT);
- logger.info("response.getHits().totalHits = {}", response.getHits().getTotalHits().value);
- }
所以如果我们想将此代码升级到 8.11.3,我们需要:
- 使用相同的 7.17.16 版本将代码升级到新的 Elasticsearch Java API Client
- 将服务器和客户端都升级到 8.11.3
另一个非常好的策略是先升级服务器,然后升级客户端。 它要求你设置 HLRC 的兼容模式:
- RestHighLevelClient esClient = new RestHighLevelClientBuilder(restClient)
- .setApiCompatibilityMode(true)
- .build()
我选择分两步进行,以便我们更好地控制升级过程并避免混合问题。 升级的第一步是最大的一步。 第二个要轻得多,主要区别在于 Elasticsearch 现在默认受到保护(密码和 SSL 自签名证书)。
在本文的其余部分中,我有时会将 “old” Java 代码作为注释,以便你可以轻松比较最重要部分的更改。
新的 Elasticsearch Java API 客户端
所以我们需要修改 pom.xml:
- <!-- Elasticsearch HLRC -->
- <dependency>
- <groupId>org.elasticsearch.client</groupId>
- <artifactId>elasticsearch-rest-high-level-client</artifactId>
- <version>7.17.16</version>
- </dependency>
到:
- <!-- Elasticsearch Java API Client -->
- <dependency>
- <groupId>co.elastic.clients</groupId>
- <artifactId>elasticsearch-java</artifactId>
- <version>7.17.16</version>
- </dependency>
容易,对吧?
嗯,没那么容易。 。 。 因为现在我们的项目不再编译了。 因此,让我们进行必要的调整。 首先,我们需要更改创建 ElasticsearchClient 而不是 RestHighLevelClient 的方式:
- static private ElasticsearchClient getClient(String elasticsearchServiceAddress) {
- try {
- final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
- credentialsProvider.setCredentials(AuthScope.ANY,
- new UsernamePasswordCredentials("elastic", "changeme"));
-
- // Create the low-level client
- // Before:
- // RestClientBuilder restClient = RestClient.builder(HttpHost.create(elasticsearchServiceAddress))
- // .setHttpClientConfigCallback(hcb -> hcb.setDefaultCredentialsProvider(credentialsProvider));
- // After:
- RestClient restClient = RestClient.builder(HttpHost.create(elasticsearchServiceAddress))
- .setHttpClientConfigCallback(hcb -> hcb.setDefaultCredentialsProvider(credentialsProvider))
- .build();
-
- // Create the transport with a Jackson mapper
- ElasticsearchTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
-
- // And create the API client
- // Before:
- // RestHighLevelClient client = new RestHighLevelClient(restClient);
- // After:
- ElasticsearchClient client = new ElasticsearchClient(transport);
-
- // Before:
- // MainResponse info = client.info(RequestOptions.DEFAULT);
- // After:
- InfoResponse info = client.info();
-
- // Before:
- // logger.info("Connected to a cluster running version {} at {}.", info.getVersion().getNumber(), elasticsearchServiceAddress);
- // After:
- logger.info("Connected to a cluster running version {} at {}.", info.version().number(), elasticsearchServiceAddress);
- return client;
- } catch (Exception e) {
- logger.info("No cluster is running yet at {}.", elasticsearchServiceAddress);
- return null;
- }
- }
主要的变化是我们现在在 RestClient(低级别)和 ElasticsearchClient 之间有一个 ElasticsearchTransport 类。 此类负责 JSON 编码和解码。 这包括应用程序类的序列化和反序列化,以前必须手动完成,现在由 JacksonJsonpMapper 处理。
另请注意,请求选项是在客户端上设置的。 我们不再需要通过任何 API 来传递 RequestOptions.DEFAULT,这里是 info API (GET /):
InfoResponse info = client.info();“getters” 也被简化了很多。 因此,我们现在调用 info.version().number(),而不是调用 info.getVersion().getNumber()。 不再需要获取前缀!
使用新客户端
让我们将之前看到的 searchData() 方法切换到新客户端。 现在删除索引是:
- try {
- // Before:
- // client.indices().delete(new DeleteIndexRequest("search-data"), RequestOptions.DEFAULT);
- // After:
- client.indices().delete(dir -> dir.index("search-data"));
- } catch (/* ElasticsearchStatusException */ ElasticsearchException ignored) { }
在这段代码中我们可以看到什么?
- 我们现在大量使用 lambda 表达式,它采用构建器对象作为参数。 它需要在思想上切换到这种新的设计模式。 但这实际上是超级智能的,就像你的 IDE 一样,你只需要自动完成即可准确查看选项,而无需导入任何类或只需提前知道类名称。 经过一些练习,它成为使用客户端的超级优雅的方式。 如果你更喜欢使用构建器对象,它们仍然可用,因为这是这些 lambda 表达式在幕后使用的内容。 但是,它使代码变得更加冗长,因此你确实应该尝试使用 lambda。
- dir 在这里是删除索引请求构建器。 我们只需要使用 index(“search-data”) 定义我们想要删除的索引。
- ElasticsearchStatusException 更改为 ElasticsearchException。
要索引单个 JSON 文档,我们现在执行以下操作:
- // Before:
- // client.index(new IndexRequest("search-data").id("1").source("{\"foo\":\"bar\"}", XContentType.JSON), RequestOptions.DEFAULT);
- // After:
- client.index(ir -> ir.index("search-data").id("1").withJson(new StringReader("{\"foo\":\"bar\"}")));
与我们之前看到的一样,lambdas (ir) 的使用正在帮助我们创建索引请求。 这里我们只需要定义索引名称 (index("search-data")) 和 id (id("1")) 并使用 withJson(new StringReader("{\"foo\":\ "bar\"}"))。
refresh API 调用现在非常简单:
- // Before:
- // client.indices().refresh(new RefreshRequest("search-data"), RequestOptions.DEFAULT);
- // After:
- client.indices().refresh(rr -> rr.index("search-data"));
搜索是另一场野兽。 一开始看起来很复杂,但通过一些实践你会发现生成代码是多么容易:
- // Before:
- // SearchResponse response = client.search(new SearchRequest("search-data").source(
- // new SearchSourceBuilder().query(
- // QueryBuilders.matchQuery("foo", "bar")
- // )
- // ), RequestOptions.DEFAULT);
- // After:
- SearchResponse<Void> response = client.search(sr -> sr
- .index("search-data")
- .query(q -> q
- .match(mq -> mq
- .field("foo")
- .query("bar"))),
- Void.class);
lambda 表达式参数是构建器:
- sr 是 SearchRequest 构建器。
- q 是查询构建器。
- mq 是 MatchQuery 构建器。
如果你仔细查看代码,你可能会发现它非常接近我们所知的 json 搜索请求:
- {
- "query": {
- "match": {
- "foo": {
- "query": "bar"
- }
- }
- }
- }
这实际上是我一步步编码的方式:
client.search(sr -> sr, Void.class);我将 Void 定义为我想要返回的 bean,这意味着我不关心解码 _source JSON 字段,因为我只想访问响应对象。
然后我想定义要在其中搜索数据的索引:
client.search(sr -> sr.index("search-data"), Void.class);因为我想提供一个查询,所以我基本上是这样写的:
- client.search(sr -> sr
- .index("search-data")
- .query(q -> q),
- Void.class);
我的 IDE 现在可以帮助我找到我想要使用的查询:
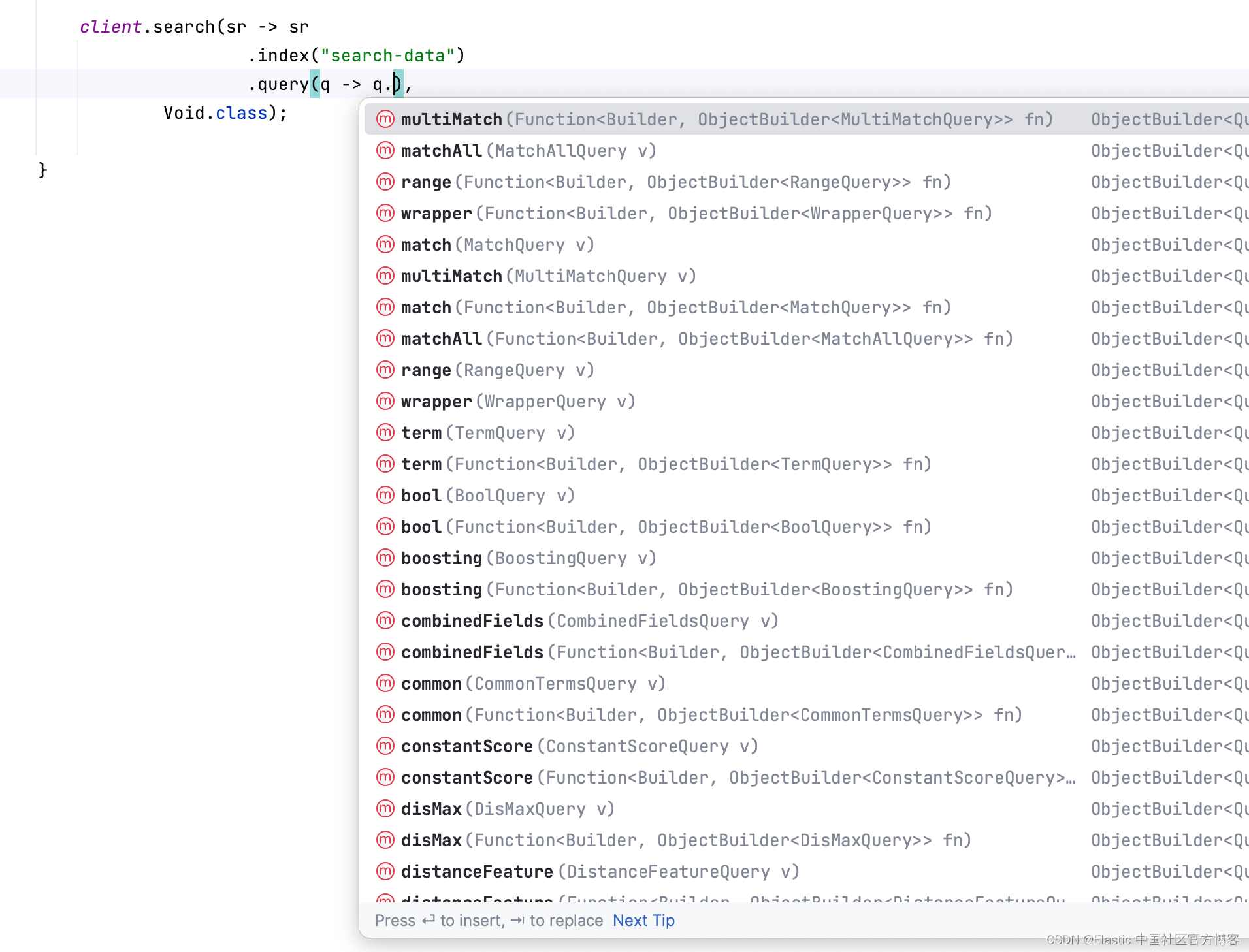
我想使用匹配查询:
- client.search(sr -> sr
- .index("search-data")
- .query(q -> q
- .match(mq -> mq)),
- Void.class);
我只需定义要搜索的 field (foo) 和要应用的 query (bar):
- client.search(sr -> sr
- .index("search-data")
- .query(q -> q
- .match(mq -> mq
- .field("foo")
- .query("bar"))),
- Void.class);
我现在可以要求 IDE 从结果中生成一个字段,并且我可以进行完整的调用:
- SearchResponse<Void> response = client.search(sr -> sr
- .index("search-data")
- .query(q -> q
- .match(mq -> mq
- .field("foo")
- .query("bar"))),
- Void.class);
我可以从响应对象中读取 hits 总数:
- // Before:
- // logger.info("response.getHits().totalHits = {}", response.getHits().getTotalHits().value);
- // After:
- logger.info("response.hits.total.value = {}", response.hits().total().value());
Exists API
让我们看看如何将调用切换到 exists API:
- // Before:
- boolean exists1 = client.exists(new GetRequest("test", "1"), RequestOptions.DEFAULT);
- boolean exists2 = client.exists(new GetRequest("test", "2"), RequestOptions.DEFAULT);
现在可以变成:
- // After:
- boolean exists1 = client.exists(gr -> gr.index("exist").id("1")).value();
- boolean exists2 = client.exists(gr -> gr.index("exist").id("2")).value();
Bulk API
要批量对 Elasticsearch 进行索引/删除/更新操作,你绝对应该使用 Bulk API:
- BinaryData data = BinaryData.of("{\"foo\":\"bar\"}".getBytes(StandardCharsets.UTF_8), ContentType.APPLICATION_JSON);
- BulkResponse response = client.bulk(br -> {
- br.index("bulk");
- for (int i = 0; i < 1000; i++) {
- br.operations(o -> o.index(ir -> ir.document(data)));
- }
- return br;
- });
- logger.info("bulk executed in {} ms {} errors", response.errors() ? "with" : "without", response.ingestTook());
- if (response.errors()) {
- response.items().stream().filter(p -> p.error() != null)
- .forEach(item -> logger.error("Error {} for id {}", item.error().reason(), item.id()));
- }
请注意,该操作也可以是 DeleteRequest:
br.operations(o -> o.delete(dr -> dr.id("1")));BulkProcessor 到 BulkIngester 助手
我一直很喜欢的 HLRC 功能之一是 BulkProcessor。 它就像 “一劳永逸 ”的功能,当你想要使用批量(bulk API)发送大量文档时,该功能非常有用。
正如我们之前所看到的,我们需要手动等待数组被填充,然后准备批量请求。
有了BulkProcessor,事情就容易多了。 你只需添加索引/删除/更新操作,BulkProcessor 将在你达到阈值时自动创建批量请求:
- 文件数量
- 全局有效载荷的大小
- 给定的时间范围
- // Before:
- BulkProcessor bulkProcessor = BulkProcessor.builder(
- (request, bulkListener) -> client.bulkAsync(request, RequestOptions.DEFAULT, bulkListener),
- new BulkProcessor.Listener() {
- @Override public void beforeBulk(long executionId, BulkRequest request) {
- logger.debug("going to execute bulk of {} requests", request.numberOfActions());
- }
- @Override public void afterBulk(long executionId, BulkRequest request, BulkResponse response) {
- logger.debug("bulk executed {} failures", response.hasFailures() ? "with" : "without");
- }
- @Override public void afterBulk(long executionId, BulkRequest request, Throwable failure) {
- logger.warn("error while executing bulk", failure);
- }
- })
- .setBulkActions(10)
- .setBulkSize(new ByteSizeValue(1L, ByteSizeUnit.MB))
- .setFlushInterval(TimeValue.timeValueSeconds(5L))
- .build();
让我们将该部分移至新的 BulkIngester 以注入我们的 Person 对象:
- // After:
- BulkIngester<Person> ingester = BulkIngester.of(b -> b
- .client(client)
- .maxOperations(10_000)
- .maxSize(1_000_000)
- .flushInterval(5, TimeUnit.SECONDS));
更具可读性,对吧? 这里的要点之一是你不再被迫提供 listener,尽管我相信这仍然是正确处理错误的良好实践。 如果你想提供一个 listener,只需执行以下操作:
- // After:
- BulkIngester<Person> ingester = BulkIngester.of(b -> b
- .client(client)
- .maxOperations(10_000)
- .maxSize(1_000_000)
- .flushInterval(5, TimeUnit.SECONDS))
- .listener(new BulkListener<Person>() {
- @Override public void beforeBulk(long executionId, BulkRequest request, List<Person> persons) {
- logger.debug("going to execute bulk of {} requests", request.operations().size());
- }
- @Override public void afterBulk(long executionId, BulkRequest request, List<Person> persons, BulkResponse response) {
- logger.debug("bulk executed {} errors", response.errors() ? "with" : "without");
- }
- @Override public void afterBulk(long executionId, BulkRequest request, List<Person> persons, Throwable failure) {
- logger.warn("error while executing bulk", failure);
- }
- });
每当你需要在代码中添加一些请求到 BulkProcessor 时:
- // Before:
- void index(Person person) {
- String json = mapper.writeValueAsString(person);
- bulkProcessor.add(new IndexRequest("bulk").source(json, XContentType.JSON));
- }
现在变成了:
- // After:
- void index(Person person) {
- ingester.add(bo -> bo.index(io -> io
- .index("bulk")
- .document(person)));
- }
如果你想发送原始 json 字符串,你应该使用 Void 类型这样做:
BulkIngester<Void> ingester = BulkIngester.of(b -> b.client(client).maxOperations(10));- void index(String json) {
- BinaryData data = BinaryData.of(json.getBytes(StandardCharsets.UTF_8), ContentType.APPLICATION_JSON);
- ingester.add(bo -> bo.index(io -> io.index("bulk").document(data)));
- }
当你的应用程序退出时,你需要确保关闭 BulkProcessor,这将导致挂起的操作之前被刷新,这样你就不会丢失任何文档:
- // Before:
- bulkProcessor.close();
现在很容易转换成:
- // After:
- ingester.close();
当然,当使用 try-with-resources 模式时,你可以省略 close() 调用,因为 BulkIngester 是 AutoCloseable 的:
- try (BulkIngester<Void> ingester = BulkIngester.of(b -> b
- .client(client)
- .maxOperations(10_000)
- .maxSize(1_000_000)
- .flushInterval(5, TimeUnit.SECONDS)
- )) {
- BinaryData data = BinaryData.of("{\"foo\":\"bar\"}".getBytes(StandardCharsets.UTF_8), ContentType.APPLICATION_JSON);
- for (int i = 0; i < 1000; i++) {
- ingester.add(bo -> bo.index(io -> io.index("bulk").document(data)));
- }
- }
好处
我们已经在 BulkIngester 部分中触及了这一点,但新 Java API 客户端添加的重要功能之一是你现在可以提供 Java Bean,而不是手动执行序列化/反序列化。 这在编码方面可以节省时间。
因此,要索引 Person 对象,我们可以这样做:
- void index(Person person) {
- client.index(ir -> ir.index("person").id(person.getId()).document(person));
- }
以我的愚见,力量来自于搜索。 我们现在可以直接读取我们的实体:
- client.search(sr -> sr.index("search-data"), Person.class);
- SearchResponse<Person> response = client.search(sr -> sr.index("search-data"), Person.class);
- for (Hit<Person> hit : response.hits().hits()) {
- logger.info("Person _id = {}, id = {}, name = {}",
- hit.id(), // Elasticsearch _id metadata
- hit.source().getId(), // Person id
- hit.source().getName()); // Person name
- }
这里的 source() 方法可以直接访问 Person 实例。 你不再需要自己反序列化 json _source 字段。
更多阅读:
原文:Switching from the Java High Level Rest Client to the new Java API Client | Elastic Blog

