
- 1JAVA判断一个Object对象是否为Array类型_java判断object是对象还是数组
- 2原生 SQLAlchemy 的使用(彻底解决Lost connection to MySQL server)_asyncpg sqlalchemy
- 3Elasticsearch实现Mysql的Like效果_elasticsearch like
- 4AIGC | 为机器学习工作站安装NVIDIA 4070 Ti Super显卡驱动
- 5搭建PyTorch神经网络进行气温预测(手写+调包两种方法)(保证学会!)+找到神经网络的最优情况_jupyter预测气温代码
- 6VALSE 2024 计算机视觉与机器学习 | 文档解析与向量化技术加速多模态大模型训练与应用_valse 2014 workshop
- 7python文本情感分析 逻辑回归_机器学习:使用逻辑回归进行电影评论的情感分析完整实现...
- 8基于Python的电影影片数据分析_基于python的电影数据分析系统
- 9Centos7下安装使用Pyinstaller及Python library not found错误解决方法_python library not found: libpython3.9.so.1.0, lib
- 10动态规划精品课 2024.6.26-24.7.3
neo4j导出导入csv文件_neo4j导出csv
赞
踩
neo4j导出导入csv文件
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
例如:第一章 Python 机器学习入门之pandas的使用
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
有时候需要吧一个数据库导入导入另一个数据库。有两种方法,本文介绍命令行admin方法,还有cypher方法,但好像需要自己指定字段,比较麻烦。
提示:以下是本篇文章正文内容,下面案例可供参考
一、导出csv文件
neo4j图数据库,一般需要配置一个十分强大的apoc插件,可以为neo4j增加非常多的实用功能。在本文中,将会来探讨apoc插件导出csv数据的可能性。
导出数据需要用到apoc工具,去官网下载对应Neo4j版本的jar包
https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases
注意版本匹配问题,github主页有。
关闭neo4j,将下载好的jar放入neo4j的plugins文件夹里。
修改配置文件,在conf中加下列5行
apoc.import.file.use_neo4j_config=true
apoc.export.file.enabled=true
apoc.import.file.enabled=true
dbms.directories.import=import
dbms.security.allow_csv_import_from_file_urls=true
- 1
- 2
- 3
- 4
- 5
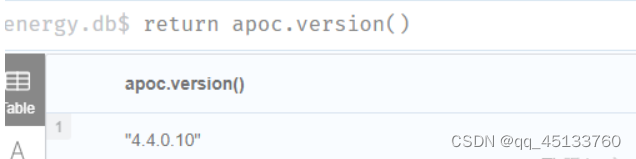
打开neo4j,输入 return apoc.version()检验是否apoc安装成功
下面的代码可以导出一个csv文件,是neo4j数据库内的所有数据,包括结点和关系等。数据都堆在一个数据表里面,基本上没有啥实际的价值,因为把所有的数据都堆一起了,字段堆在一起,数据也是。结点和关系都混到了一起。实在想不出,这种结构有啥使用价值。
CALL apoc.export.csv.all(
'dc.csv', //文件名和类型,也可以是txt格式
{ quotes:'none',//导出的文件中没有引号
useTypes:true
}
)
- 1
- 2
- 3
- 4
- 5
- 6
导出多个文件
这个代码就比较强大了,主要的参数就是bulkImport:true,设置它之后,导出的数据,就按照nodes和relationships分开了。
nodes根据标签的不同,分为多个文件。
relationships按照类型不同,分为多个文件。
这是用在neo4j客户端的
CALL apoc.export.csv.all(
"a.csv",
{
quotes:'none',
useTypes:true,
bulkImport:true
}
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
数据存储在import文件夹。
二、导入csv
如果把这些分开的nodes().csv和relationships().csv,再次导入的话,需要重复设置–nodes和–relationships参数(据文档记载)。
neo4j-admin import --database=neo4j --nodes=import/nodes1.csv --nodes=import/nodes2.csv --relationships=import/relationship1.csv --relationships=import/relationship2.csv --force
- 1
force强制清除原来的数据
看是否有报错信息,正常情况如下:
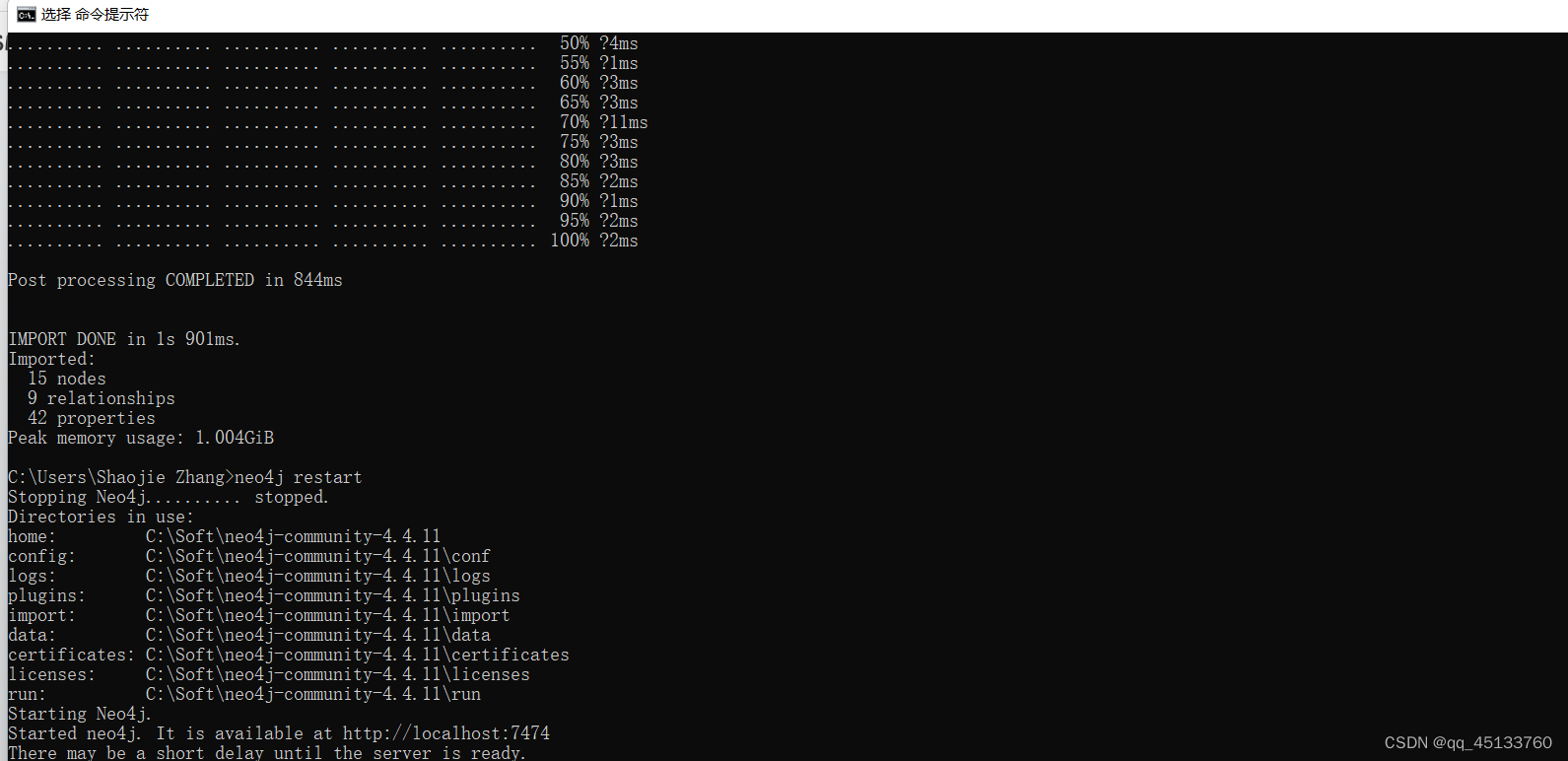
注意数据里那些原子数据(属性)之类的,不要包含逗号,否则,csv文件从,开始切割,导致数据出错,用空格代替。
上述代码导入完成后,重启neo4j
neo4j restart
- 1
如果上述代码出错,可能会搞坏数据库,这时候原来的数据库就无法访问,处于离线状态,可以删掉原来的数据库,重新创建。
总结
参考;
https://seosn.com/say/neo4j-export-csv.html
https://seosn.com/say/neo4j-import-csv.html
https://blog.csdn.net/qq_45092476/article/details/128085903

