
- 1JavaParser的快速介绍_java parser tutorial
- 2深入剖析 Android 网络开源库 Retrofit 的源码详解_android源码开放网络
- 3redis学习笔记7-阻塞_redis hugepage写操作 是什么
- 4A站 的 Swift 实践 ,收获总结。_swift 实践 改造
- 5推荐文章标题:利用FlutterFire打造跨平台的Firebase应用
- 6RabbitMQ MQTT TLS相关配置
- 7中兴新支点操作系统加入腾讯发起的OpenCloudOS开源社区:希望百花齐放_新支点默认字体都是开源字体吗
- 8Java 单链表的反转_单向链表反转java
- 9仓颉编程语言全攻略:学习秘籍+内测资格申请秘籍!_华为仓颉编程语言官网
- 10Variables Reference for vscode
时间序列预测模型实战案例(六)深入理解机器学习ARIMA包括差分和相关性分析_时间序列分析arima模型例题
赞
踩
简介
ARIMA模型是一种广泛应用的时间序列预测模型,它结合了自回归(AR)和移动平均(MA)的概念,具有较好的灵活性和准确性。
本章将介绍一个实战案例,利用Python编程语言实现了ARIMA模型并进行预测。通过这个案例,我们将深入了解ARIMA模型的构建过程和关键步骤,并学习如何使用Python中的相关库来进行模型训练和预测。
在案例中,我们将使用一组客服的接线量数据作为实验对象。通过分析这些数据,我们将探索数据的特征和规律,进行平稳性检验和差分操作,然后通过自相关和偏自相关图来选择合适的ARIMA模型参数。接下来,我们将用选定的参数拟合ARIMA模型,并进行模型评估和预测结果分析。
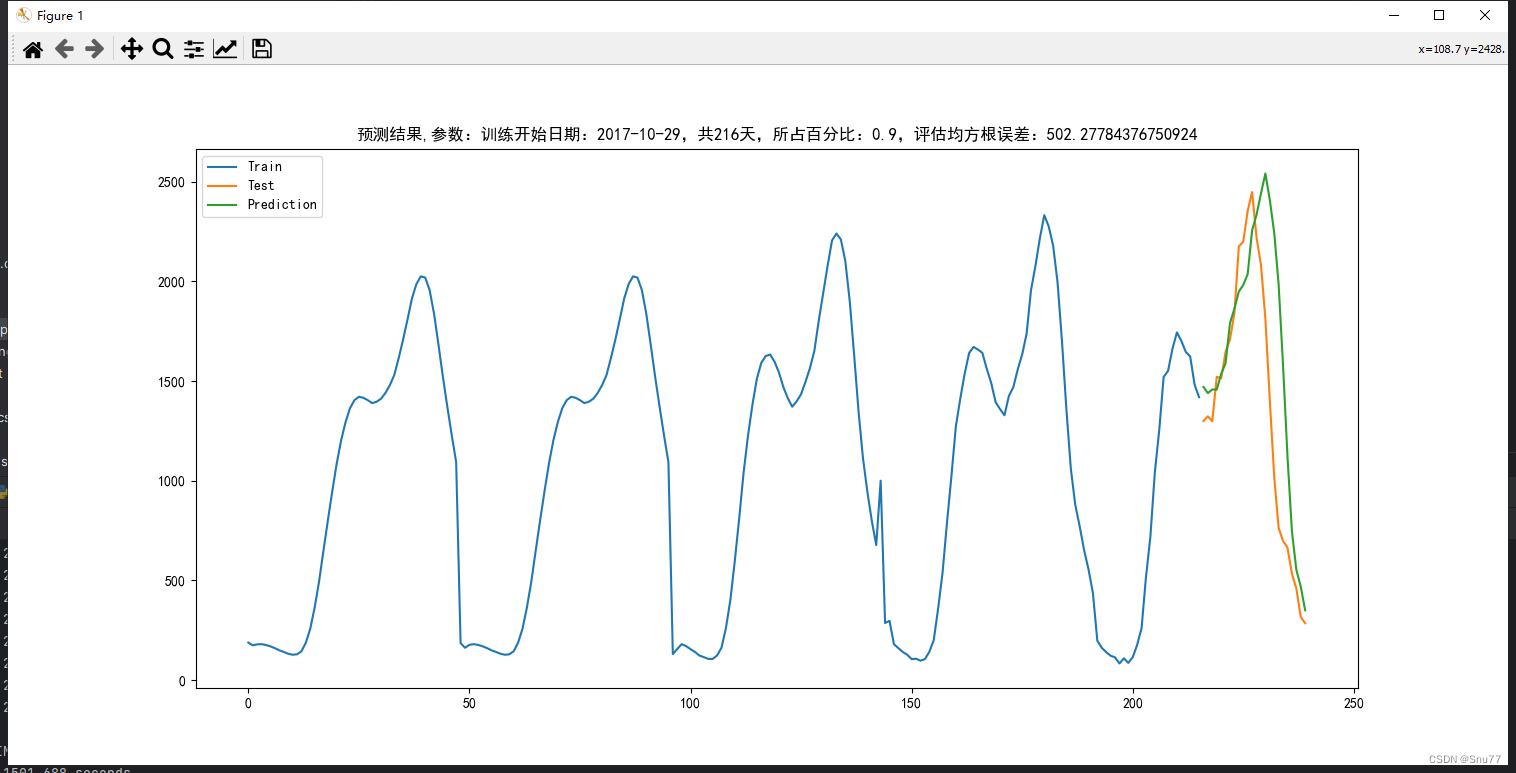
下图为预测未知数据的对比图->
数据收集和准备
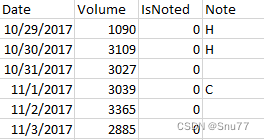
下面是模型所用数据集的部分截图
PS:需要注意的是ARIMA是单变量预测的模型,我们只用的了其中的特征列"Volume"来进行预测,其它两列是用来校验Volume列的标记值。
完整项目代码
- import pandas as pd
- import matplotlib.pyplot as plt
- from pmdarima.arima import auto_arima
- from math import sqrt
- from sklearn.metrics import mean_squared_error
- import statsmodels.tsa.api as smt
- import statsmodels.api as sm
- import numpy as np
-
- firstDate = '2017-10-29'
-
- def loadData(filterDate):
- """
- 加载指定日期之后的数据,只加载第一天之后的数据,第一天可以指定
- :param filterDate:
- :return:
- """
- if filterDate < firstDate:
- filterDate = firstDate
- hp_all = pd.read_csv("hp.csv", index_col=['Date'], parse_dates=['Date'])
- hp_all = hp_all[filterDate:]
- return hp_all
-
-
- def plotData(series):
- """
- 对于输入数据进行折线图显示
- :param series:
- :return:
- """
- plt.rcParams['font.sans-serif'] = ['SimHei']
- plt.rcParams['axes.unicode_minus'] = False
- plt.figure(figsize=(15, 7))
- plt.plot(series)
- plt.title('原始数据')
- plt.grid(True)
- # plt.show()
-
-
- def plotAllData(filterDate):
- """
- 对指定日期之后的数据进行展示,初步处理是将数据中的空值替换为0
- :param filterDate:
- :return:
- """
- hp_all = loadData(filterDate)
- plotData(hp_all['Volume'].fillna(0, inplace=False))
-
-
- def preProcessData(filterDate):
- """
- 对指定日期之后的数据进行预处理,预处理方式将标记的数据使用周围数据的平均值替换
- :param filterDate:
- :return: hp 处理后的数据,其中标记的数据使用平滑值来代替;
- hp_rolling 窗口为17的平滑值,平滑方法是平均值;
- hp_raw 处理后的数据,标记的数据使用0来替换
- """
- hp_all = loadData(filterDate)
- hp = hp_all['Volume'].copy(deep=True)
- hp_all.loc[hp_all['IsNoted'] == 1, 'Volume'] = np.nan
- hp_raw = hp_all[['Volume']].fillna(0, inplace=False)
- hp_rolling = hp_all['Volume'].rolling(window=22, min_periods=1, center=True).mean()
- hp[hp_all['IsNoted'] == 1] = hp_rolling[hp_all['IsNoted'] == 1]
- return hp, hp_rolling, hp_raw
-
-
- def plotProcessedData(filterDate):
- """
- 对原始数据,平滑数据和处理后的数据进行展示
- :param filterDate:
- :return:
- """
- hp, hp_rolling, hp_raw = preProcessData(filterDate)
- plt.rcParams['font.sans-serif'] = ['SimHei']
- plt.rcParams['axes.unicode_minus'] = False
- plt.figure(figsize=(15, 7))
- plt.plot(hp_raw, label='Raw Data')
- # plt.plot(hp_rolling, label='Rolling Data')
- # plt.scatter(hp.index, hp, label='Processed Data', c='red', marker='v', s=5)
- plt.plot(hp, label='Processed Data')
- # plt.title('数据处理:原始数据,平滑数据,处理后的数据')
- plt.title('数据处理:原始数据,处理后的数据')
- plt.grid(True)
- plt.legend(loc='best')
- # plt.show()
-
-
- def train(filterDate, div_para):
- hp, hp_rolling, hp_raw = preProcessData(filterDate)
- train_ds = hp[:int(div_para * len(hp))]
- test_ds = hp[int(div_para * len(hp)):]
-
- plt.rcParams['font.sans-serif'] = ['SimHei']
- plt.rcParams['axes.unicode_minus'] = False
- # plt.figure(figsize=(15, 7))
- # plt.title('训练数据和测试数据')
- # train_ds.plot()
- # test_ds.plot()
-
- model = auto_arima(train_ds, trace=True, error_action='ignore', suppress_warnings=True, seasonal=True,m=7,
- stationary=False)
- model.fit(train_ds)
- forcast = model.predict(n_periods=len(test_ds))
- forcast = pd.DataFrame(forcast, index=test_ds.index, columns=['Prediction'])
- rms = sqrt(mean_squared_error(test_ds, forcast))
- plt.rcParams['font.sans-serif'] = ['SimHei']
- plt.rcParams['axes.unicode_minus'] = False
- plt.figure(figsize=(15, 7))
- # plt.figure('Forecast')
- plt.title('预测结果,参数:训练开始日期:{0},共{1}天,所占百分比:{2},评估均方根误差:{3}'.format(filterDate, len(train_ds), div_para, rms))
- plt.plot(train_ds, label='Train')
- plt.plot(test_ds, label='Test')
- plt.plot(forcast, label='Prediction')
- plt.legend()
- plt.show()
-
-
- def tsplot(y, lags=None, figsize=(12, 7), style='bmh'):
- """
- Plot time series, its ACF and PACF, calculate Dickey–Fuller test
- y - timeseries
- lags - how many lags to include in ACF, PACF calculation
- """
- if not isinstance(y, pd.Series):
- y = pd.Series(y)
-
- with plt.style.context(style):
- fig = plt.figure(figsize=figsize)
- layout = (2, 2)
- ts_ax = plt.subplot2grid(layout, (0, 0), colspan=2)
- acf_ax = plt.subplot2grid(layout, (1, 0))
- pacf_ax = plt.subplot2grid(layout, (1, 1))
-
- y.plot(ax=ts_ax)
- p_value = sm.tsa.stattools.adfuller(y)[1]
- ts_ax.set_title('Time Series Analysis Plots\n Dickey-Fuller: p={0:.5f}'.format(p_value))
- smt.graphics.plot_acf(y, lags=lags, ax=acf_ax)
- smt.graphics.plot_pacf(y, lags=lags, ax=pacf_ax)
- plt.tight_layout()
-
-
-
-
- if __name__ == '__main__':
- """
- "ARIMA",
- """
-
- startDate = '2015-01-15'
- # startDate = firstDate
- # hp_all = loadData(startDate)
- hp, hp_rolling, hp_raw = preProcessData(startDate)
- plotAllData(startDate)
- plotProcessedData(startDate)
-
- # 是否进行差分操作可视化
- tsplot_bool = False
- if tsplot_bool:
- ads = hp_raw
- # tsplot(ads.Ads, lags=60)
- ads_diff = ads.Volume - ads.Volume.shift(24)
- # tsplot(ads_diff[24:], lags=60)
- ads_diff = ads_diff - ads_diff.shift(1)
- tsplot(ads_diff[24 + 1:], lags=60)
-
- print("test")
- # 模型拟合以及预测
- startDate = firstDate
- train(startDate, 0.98)
-
数据预处理
在数据导入之前我们先对数据进行一些预处理操作,其中有注释大家可以进行理解。
- def loadData(filterDate):
- """
- 加载指定日期之后的数据,只加载第一天之后的数据,第一天可以指定
- :param filterDate:
- :return:
- """
- if filterDate < firstDate:
- filterDate = firstDate
- hp_all = pd.read_csv("hp.csv", index_col=['Date'], parse_dates=['Date'])
- hp_all = hp_all[filterDate:]
- return hp_all
-
-
- def preProcessData(filterDate):
- """
- 对指定日期之后的数据进行预处理,预处理方式将标记的数据使用周围数据的平均值替换
- :param filterDate:
- :return: hp 处理后的数据,其中标记的数据使用平滑值来代替;
- hp_rolling 窗口为17的平滑值,平滑方法是平均值;
- hp_raw 处理后的数据,标记的数据使用0来替换
- """
- hp_all = loadData(filterDate)
- hp = hp_all['Volume'].copy(deep=True)
- hp_all.loc[hp_all['IsNoted'] == 1, 'Volume'] = np.nan
- hp_raw = hp_all[['Volume']].fillna(0, inplace=False)
- hp_rolling = hp_all['Volume'].rolling(window=22, min_periods=1, center=True).mean()
- hp[hp_all['IsNoted'] == 1] = hp_rolling[hp_all['IsNoted'] == 1]
- return hp, hp_rolling, hp_raw
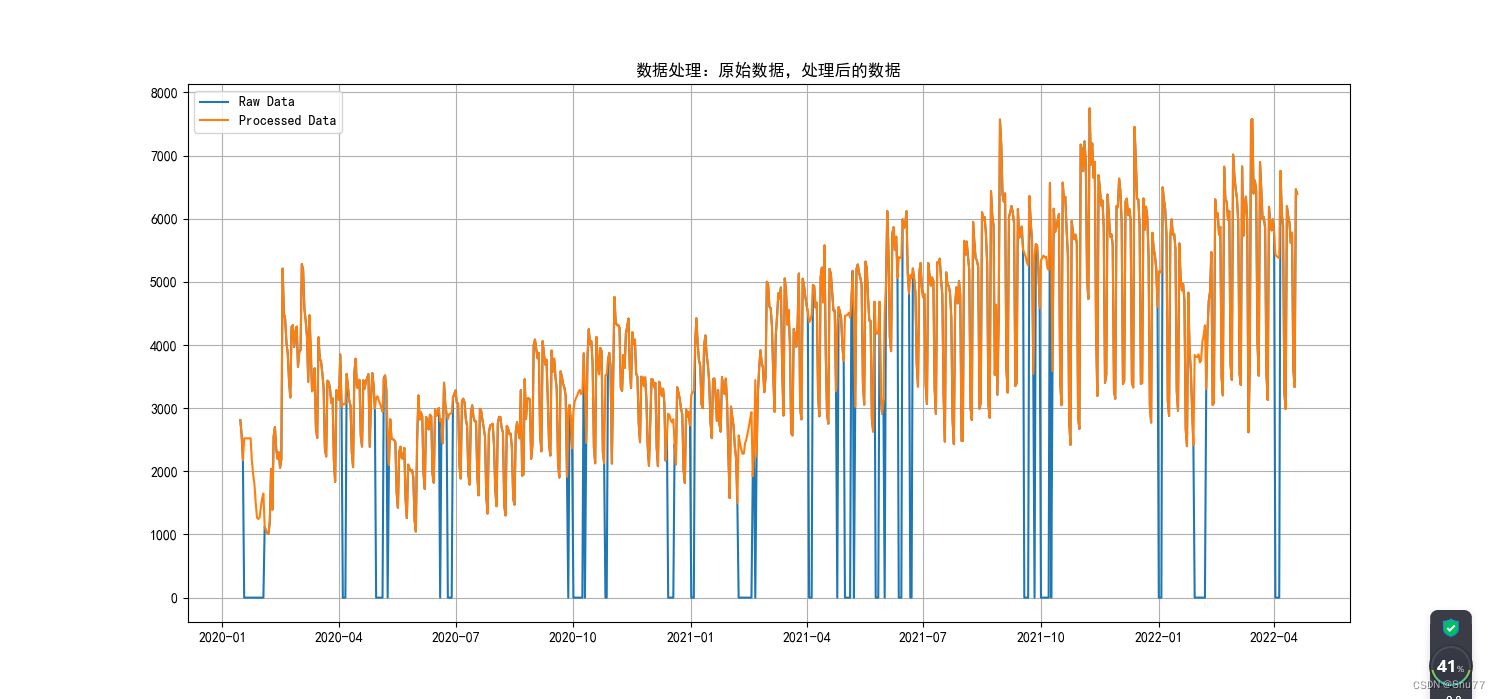
我们可以对比一下经过处理和未经过处理的数据图像进行一个对比,全是蓝色的为原始图像,带部分黄色的为处理后的图像。
一阶差分和二阶差分操作
我们输入数据之后,可以对数据进行一些检验操作,当处理时间序列数据时,差分是一种常见的操作,用于平稳化非平稳时间序列。平稳时间序列的特征是在时间上具有恒定的均值和方差,且自相关性不随时间变化。而非平稳时间序列则可能在均值、方差或自相关性上存在时间相关的变化。。
在开始差分分析之前我们先来简单介绍一下差分操作来让大家对差分有一列简单的理解以及差分操作能够起到什么效果。
当我们对一个时间序列进行差分操作时,一阶差分是指计算当前观测值与前一个观测值之间的差异。二阶差分则是两次进行一阶差分操作,即计算一阶差分序列的差异。
一阶差分的定义如下:
对于一个时间序列 {x₁, x₂, x₃, ..., xn},一阶差分序列为 {y₁, y₂, y₃, ..., yn-1},其中 yi = xi+1 - xi。
二阶差分的定义如下:
对于一阶差分序列 {y₁, y₂, y₃, ..., yn-1},二阶差分序列为 {z₁, z₂, z₃, ..., yn-2},其中 zi = yi+1 - yi。
通过一阶差分操作,我们可以得到一个新的序列,其每个元素表示该时间步与上一时间步之间的差
差分操作的目的是减少或去除时间序列中的趋势和季节性组成部分,使其更接近平稳时间序列。通过计算当前观测值与先前观测值之间的差异,可以得到一阶差分、二阶差分等。差分操作的效果是消除或减弱时间序列中的趋势和季节性特征,使得序列更趋于平稳。
差分操作的一些常见应用包括:
- 消除时间序列的线性趋势。通过一阶差分可以消除时间序列中的线性趋势,使之更接近平稳时间序列。
- 去除季节性变化。通过对具有季节性的时间序列进行适当的季节差分,可以消除季节性变化,以便更好地分析和建模。
- 改善模型的拟合和预测。对平稳时间序列进行差分操作后,更容易建立准确的模型,并进行更可靠的预测。
在时间序列分析中,差分操作通常与自相关函数(ACF)和偏自相关函数(PACF)分析一起使用,以帮助确定适合的差分阶数和建立合适的模型,这个我会在下面讲到。
当我们对差分有一个详细理解之后,我们来看如何利用python进行差分操作以及,进行差分之后的效果图。
一阶差分,这里的图像可以和上面的处理后的数据图像进行对比。
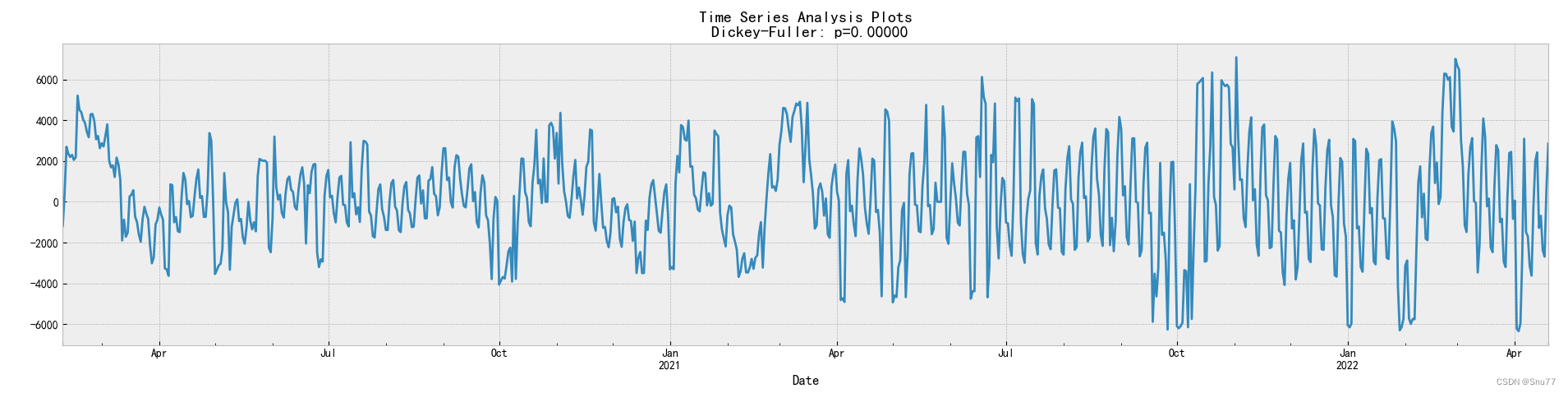
以上的图像就是经过了一阶差分后的图像,可以看出和原始图像相比来说变得更加平稳,如果你看不出来,我们来看二阶差分的图像如下,将会更加明显。
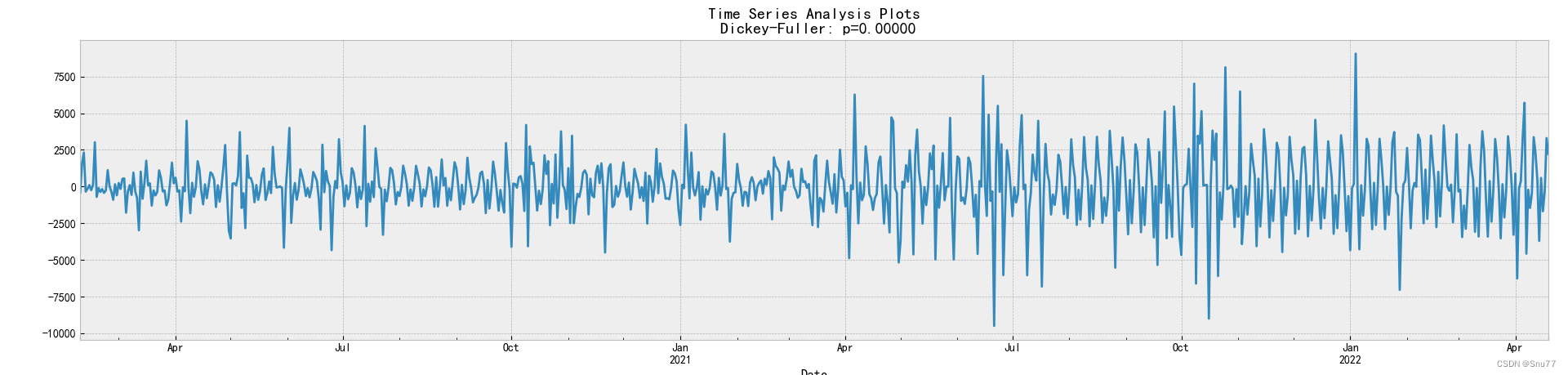 我们从二阶差分的图像来看,差分的效果会更加明显。以上就是介绍了一阶差分和二阶差分对于数据的影响以及作用。
我们从二阶差分的图像来看,差分的效果会更加明显。以上就是介绍了一阶差分和二阶差分对于数据的影响以及作用。
自相关和偏自相关图
当我们对数据进行二阶差分之后,我们就可以来进行自相关和偏相关的分析,以及解决数据滞后性的操作。同样在开始自相关和偏向关分析之前,我们来解释一下自相关和偏向关的定义以及其能够在数据中起到的作用。
自相关函数(ACF)表示一个时间序列与其自身滞后版本之间的相关性。它可以帮助我们确定时间序列是否具有任何明显的自相关模式。通过绘制ACF图表,我们可以观察时间序列在不同滞后阶数下的相关性,并判断是否存在显著的滞后。
偏自相关函数(PACF)则是在考虑了其他滞后阶数的影响后,衡量两个时间序列之间的相关性。PACF提供了直接的滞后阶数(lag)与时间序列之间的部分相关性。通过绘制PACF图表,我们可以识别时间序列的主要滞后阶数,以及建立合适的自回归模型的候选滞后阶数。
ACF和PACF分析可以帮助我们确定适合的差分阶数和建立合适的时间序列模型,本文用到的自回归综合移动平均模型(ARIMA)。通过分析和解释ACF和PACF的图表,我们可以了解时间序列的特征,选择适当的滞后阶数(前面提到过),并构建具有良好拟合和预测性能的模型。下面就是自相关和偏向关的数据分析图。
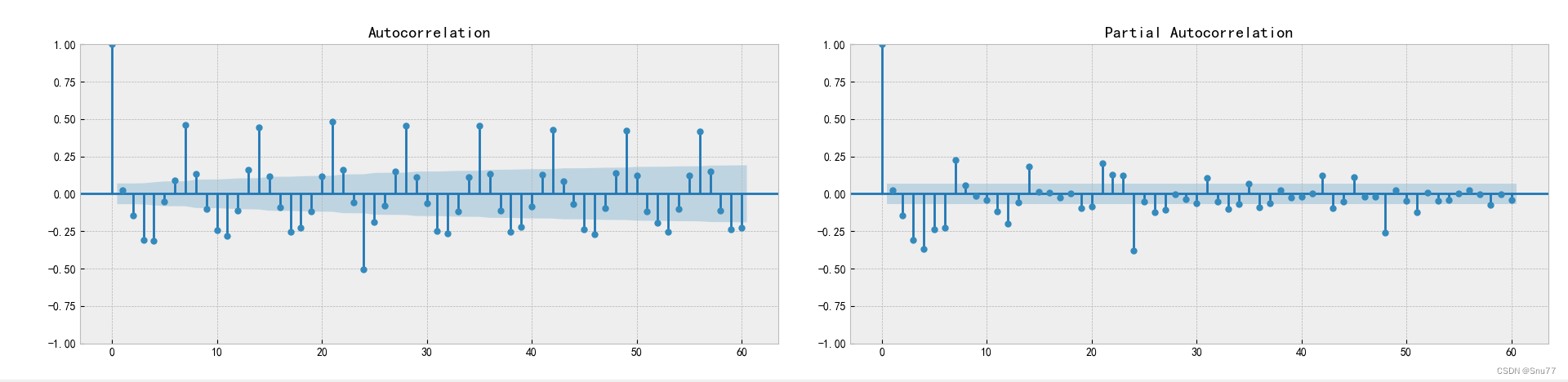
这两个图我们该如何看?
ACF图(左图)的分析:
- 纵轴表示相关性的取值范围,通常在-1到1之间。横轴表示滞后阶数(lag)。
- 通过观察ACF图中的峰值和曲线趋势,可以判断时间序列是否存在自相关模式。
- 峰值表示在特定滞后阶数上有显著的相关性。较大的正峰值表明正相关,较大的负峰值表明负相关。
- 曲线趋势展示了相关性的衰减速度。如果曲线在某个滞后阶数后快速趋近于零,表示相关性衰减得很快,可能可以通过AR模型建模。
PACF图(右图)的分析:
- 纵轴表示相关性的取值范围,通常在-1到1之间。横轴表示滞后阶数(lag)。
- PACF图是在考虑其他滞后阶数的影响后,衡量两个时间序列之间的部分相关性。
- 正相关性表示在该滞后阶数上有显著相关性,负相关性也类似。
- PACF图可以帮助确定适合的滞后阶数,用于构建AR模型的合适候选阶数。
经过分析我们可以看出数据当中存在明显的周期性以及滞后性,以此我们来选定我们后期训练ARIMA模型的参数(滞后系数等)
ARIMA模型拟合
当我们经过差分操作和相关性分析之后我们就可以进行模型拟合的操作来进行模型的训练操作了,
使用`官方的pyramid-arima`库(也被称为`pmdarima`)中的`auto_arima`函数来拟合一个ARIMA模型,这个函数会自动选择最优的ARIMA模型参数。
在这段代码中,首先使用`auto_arima`函数创建了一个模型。`trace=True`表示在模型训练过程中将打印一些诊断信息,`error_action='ignore'`表示如果在模型训练过程中出现错误,将会忽略它们,`suppress_warnings=True`表示将会抑制所有警告,`seasonal=True`表示模型会考虑季节性因素,`m=7`表示季节性周期为7(例如,如果数据是每天的,那么7就表示一周的周期),`stationary=False`表示原始序列不是平稳的,需要进行差分等操作。
然后,使用`fit`方法将模型拟合到训练数据`train_ds`上。
- model = auto_arima(train_ds, trace=True, error_action='ignore', suppress_warnings=True, seasonal=True, m=7,
- stationary=False)
- model.fit(train_ds)
预测与模型评估
使用predict方法预测测试数据集test_ds的未来值。n_periods=len(test_ds)参数表示预测的期数,这里设为测试数据集的长度。
然后,您将预测结果转换为一个Pandas DataFrame,以便于后续的操作。
最后,计算了预测结果和真实测试数据之间的均方根误差(Root Mean Squared Error,RMSE)。这是一种常用的预测性能度量,表示预测值和真实值之间的平均平方误差的平方根。在`mean_squared_error(test_ds, forcast)`中,`test_ds`是真实的测试数据,`forcast`是预测结果。
- forcast = model.predict(n_periods=len(test_ds))
- forcast = pd.DataFrame(forcast, index=test_ds.index, columns=['Prediction'])
- rms = sqrt(mean_squared_error(test_ds, forcast))
预测结果可视化
- plt.rcParams['font.sans-serif'] = ['SimHei']
- plt.rcParams['axes.unicode_minus'] = False
- plt.figure(figsize=(15, 7))
- # plt.figure('Forecast')
- plt.title('预测结果,参数:训练开始日期:{0},共{1}天,所占百分比:{2},评估均方根误差:{3}'.format(filterDate, len(train_ds), div_para, rms))
- plt.plot(train_ds, label='Train')
- plt.plot(test_ds, label='Test')
- plt.plot(forcast, label='Prediction')
- plt.legend()
- plt.show()
经过可视化分析操作我们得到ARIMA模型的预测结果,我们可以看出预测结果,其中用于评估的MSE为924。
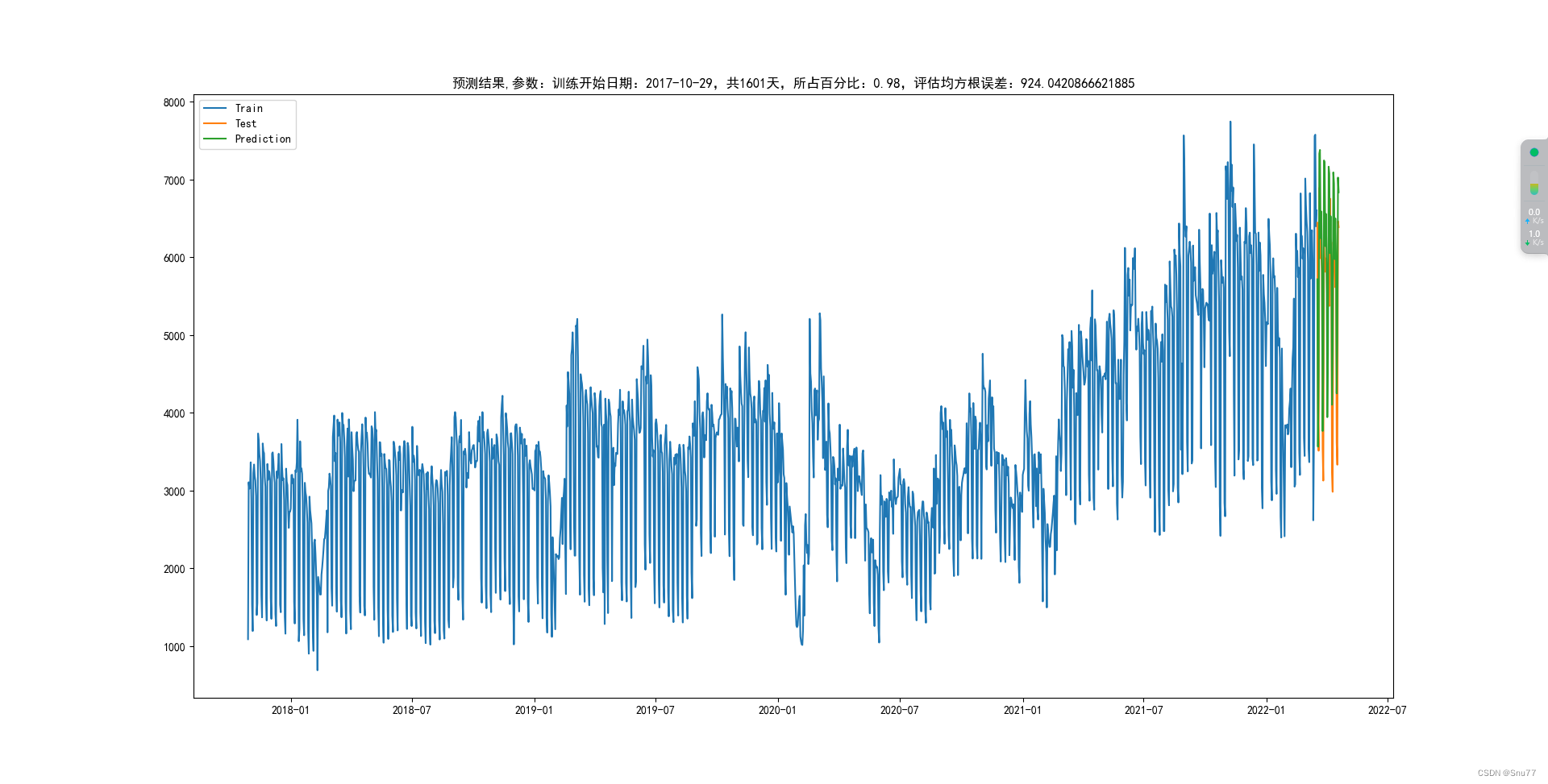
总结
ARIMA模型是一种广泛应用的时间序列预测模型,它结合了自回归(AR)和移动平均(MA)的概念,具有较好的灵活性和准确性。在本篇博客中,我们将深入探讨ARIMA模型的实战应用,并通过Python进行模型的实现和分析。
我们的实战案例基于一组客服接线量的数据。首先,我们对数据进行了详细的探索性分析,以揭示其内在的时间序列特性。对于非平稳的数据,我们使用差分操作使其平稳,以便进行后续的建模和预测。
在模型参数的选择上,我们使用了自相关图(ACF)和偏自相关图(PACF)来帮助确定ARIMA模型的参数。这两个工具可以帮助我们理解数据的自相关性,从而选择最合适的AR和MA参数。
在确定了模型参数后,我们使用Python的statsmodels库实现了ARIMA模型,并进行了训练和预测。。
其它时间序列预测模型的讲解!
时间序列预测模型实战案例(五)基于双向LSTM横向搭配单向LSTM进行回归问题解决
时间序列预测模型实战案例(四)(Xgboost)(Python)(机器学习)图解机制原理实现时间序列预测和分类(附一键运行代码资源下载和代码讲解)
时间序列预测模型实战案例(三)(LSTM)(Python)(深度学习)时间序列预测(包括运行代码以及代码讲解)
【全网首发】(MTS-Mixers)(Python)(Pytorch)最新由华为发布的时间序列预测模型实战案例(一)(包括代码讲解)实现企业级预测精度包括官方代码BUG修复Transform模型
时间序列预测模型实战案例(二)(Holt-Winter)(Python)结合K-折交叉验证进行时间序列预测实现企业级预测精度(包括运行代码以及代码讲解)
如果大家有不懂的也可以评论区留言一些报错什么的大家可以讨论讨论看到我也会给大家解答如何解决!


