
- 1软件测试期末总复习(知识点+习题+答案)_软件测试期末复习
- 2es6 Object.assign()方法_assign方法
- 3AES-128-ECB/CBC 查表法 C#实现_c# aes ecb 128
- 4打开软件后跳出服务器正在运行中,win10系统打开软件提示“服务器正在运行中”的操作步骤...
- 5【iOS ARKit】环境反射
- 6腾讯云游戏服务器购买入口,详细配置精准报价
- 72Git GUI使用,包括创建、提交、下载更新、合并和克隆_git gui here 怎么更新本地
- 8用VSCode开发C++项目_vscode写c++
- 9Ubuntu 18.04下Intel SGX的安装_sgx disabled by bios
- 10CMake安装或CMake Error at CMakeLists
Kafka Connect使用教程
赞
踩
1 kafka connect是什么
根据官方介绍,Kafka Connect是一种用于在Kafka和其他系统之间可扩展的、可靠的流式传输数据的工具。它使得能够快速定义将大量数据集合移入和移出Kafka的连接器变得简单。 Kafka Connect可以获取整个数据库或从所有应用程序服务器收集指标到Kafka主题,使数据可用于低延迟的流处理。导出作业可以将数据从Kafka topic传输到二次存储和查询系统,或者传递到批处理系统以进行离线分析。
例如我现在想要把数据从MySQL迁移到ElasticSearch,为了保证高效和数据不会丢失,我们选择MQ作为中间件保存数据。这时候我们需要一个生产者线程,不断的从MySQL中读取数据并发送到MQ,还需要一个消费者线程消费MQ的数据写到ElasticSearch,这件事情似乎很简单,不需要任何框架。
但是如果我们想要保证生产者和消费者服务的高可用性,例如重启后生产者恢复到之前读取的位置,分布式部署并且节点宕机后将任务转移到其他节点。如果要加上这些的话,这件事就变得复杂起来了,而Kafka Connect 已经为我们造好这些轮子。
Kafka Connect功能包括:
- Kafka connector是一种处理数据的通用框架:kafka连接器制定了一种标准,用来约束kafka系统与其他系统的集成,简化了kafka连接器的开发、部署和管理过程。
- 同时支持分布式模式和单机模式:kafka连接器支持两种模式,既能扩展到支持大型集群,也可以缩小到开发和测试小规模的集群。
- 提供REST 接口:使用REST API来提交请求并管理kafka集群。
- 自动化的offset管理:通过连接器的少量信息,kafka连接器可以自动管理偏移量,开发人员不必担心错误处理的影响。
- 分布式和可扩展:kafka连接器建立在现有的组管理协议基础上,可以通过添加更多的连接器实例来实现水平扩展,实现分布式服务。
- 流/批处理集成:利用kafka系统已有的能力,kafka连接器是桥接数据流和批处理系统的一种理想解决方案。
连接器作为kafka的一部分,是随着kafka系统一起发布的,无须独立安装。在大数据应用场景下,建议在每台物理机上安装一个kafka。根据实际需求,可以在一部分物理机上启动kafka实例(即代理节点broker),在另一部分物理机上启动连接器。
2 kafka connect如何工作
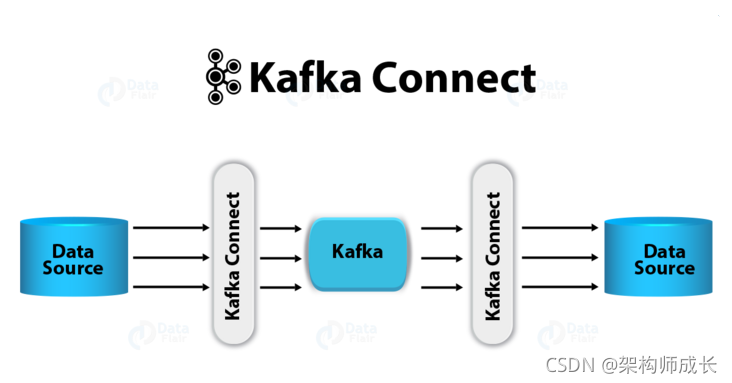
kafka核心概念
- Connectors
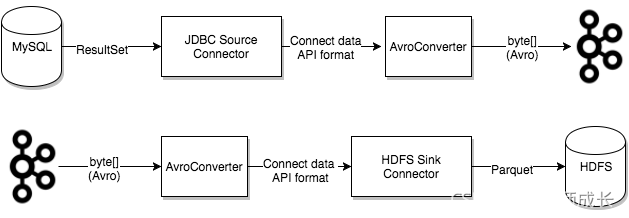
connector决定了数据应该从哪里复制过来以及数据应该写入到哪里去,一个connector实例是一个需要负责在kafka和其他系统之间复制数据的逻辑作业,connector plugin是jar文件,实现了kafka定义的一些接口来完成特定的任务连接器,分为两种 Source(从源数据库拉取数据写入Kafka),Sink(从Kafka消费数据写入目标数据)
连接器其实并不参与实际的数据copy,连接器负责管理Task。连接器中定义了对应Task的类型,对外提供配置选项(用户创建连接器时需要提供对应的配置信息)。并且连接器还可以决定启动多少个Task线程。
用户可以通过Rest API 启停连接器,查看连接器状态。Confluent 已经提供了许多成熟的连接器,详见https://www.confluent.io/product/connectors/?_ga=2.221782104.1728536530.1635839692-1065088786.1635839692
- Task
Task是Connect数据模型中的主要处理数据的角色。每个connector实例协调一组实际复制数据的task。通过允许connector将单个作业分解为多个task,Kafka Connect提供了内置的对并行性和可伸缩数据复制的支持,只需很少的配置。这些任务没有存储任何状态。任务状态存储在Kafka中的特殊主题config.storage.topic和status.storage.topic中。因此,可以在任何时候启动、停止或重新启动任务,以提供弹性的、可伸缩的数据管道。
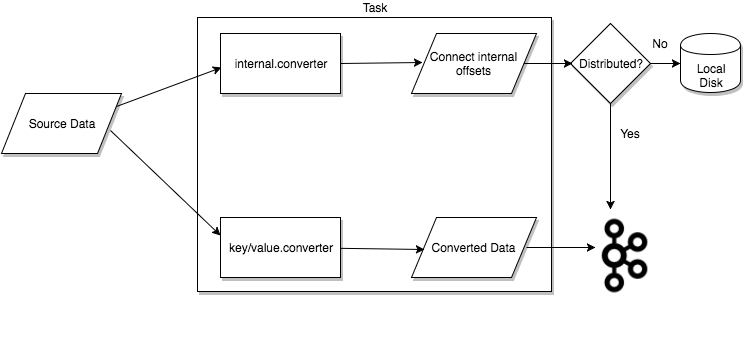
Task Rebalancing
当connector首次提交到集群时,workers会重新平衡集群中的所有connector及其tasks,以便每个worker的工作量大致相同。当connector增加或减少它们所需的task数量,或者更改connector的配置时,也会使用相同的重新平衡过程。当一个worker失败时,task在活动的worker之间重新平衡。当一个task失败时,不会触发再平衡,因为task失败被认为是一个例外情况。因此,失败的task不会被框架自动重新启动,应该通过REST API重新启动。
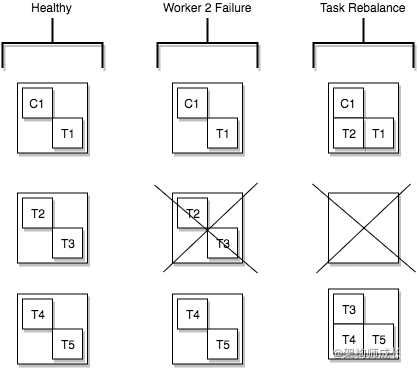
- Worker
刚刚我们讲的Connectors 和Task 属于逻辑单元,而Worker 是实际运行逻辑单元的进程,Worker 分为两种模式,单机模式和分布式模式
单机模式:比较简单,但是功能也受限,只有一些特殊的场景会使用到,例如收集主机的日志,通常来说更多的是使用分布式模式。在单机模式下,连接器的属性都配置在文件中,可通过kafka连接器命令来加载这些配置文件。
分布式模式:为Kafka Connect提供了可扩展和故障转移。相同group.id的Worker,会自动组成集群。当新增Worker,或者有Worker挂掉时,集群会自动协调分配所有的Connector 和 Task(这个过程称为Rebalance)。在分布式模式下,属性配置文件并没有连接器的配置信息,因为在该模式下使用连接器无须制定参数,这些都是通过REST API完成的。例如,对kafka连接器执行启动、停止、重启和查看等操作。
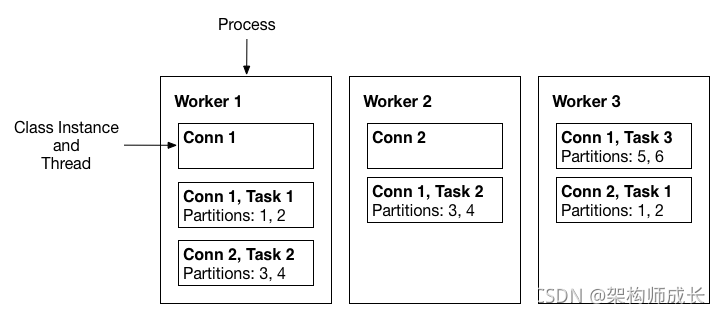
- Converters
converter会把bytes数据转换成kafka connect内部的格式,也可以把kafka connect内部存储格式的数据转变成bytes,converter对connector来说是解耦的,所以其他的connector都可以重用,例如,使用了avro converter,那么jdbc connector可以写avro格式的数据到kafka,当然,hdfs connector也可以从kafka中读出avro格式的数据。
默认支持以下Converter
- AvroConverter io.confluent.connect.avro.AvroConverter: 需要使用 Schema Registry
- ProtobufConverter io.confluent.connect.protobuf.ProtobufConverter: 需要使用 Schema Registry
- JsonSchemaConverter io.confluent.connect.json.JsonSchemaConverter: 需要使用 Schema Registry
- JsonConverter org.apache.kafka.connect.json.JsonConverter (无需 Schema Registry): 转换为json结构
- StringConverter org.apache.kafka.connect.storage.StringConverter: 简单的字符串格式
- ByteArrayConverter org.apache.kafka.connect.converters.ByteArrayConverter: 不做任何转换
- 1
- 2
- 3
- 4
- 5
- 6
- Transforms
Connector可以配置转换,以便对单个消息进行简单且轻量的修改。这对于小数据的调整和事件路由十分方便,且可以在connector配置中将多个转换链接在一起。然而,应用于多个消息的更复杂的转换最好使用KSQL和Kafka Stream实现。
转换是一个简单的函数,输入一条记录,并输出一条修改过的记录。Kafka Connect提供许多转换,它们都执行简单但有用的修改。可以使用自己的逻辑定制实现转换接口,将它们打包为Kafka Connect插件,将它们与connector一起使用。
当转换与source connector一起使用时,Kafka Connect通过第一个转换传递connector生成的每条源记录,第一个转换对其进行修改并输出一个新的源记录。将更新后的源记录传递到链中的下一个转换,该转换再生成一个新的修改后的源记录。最后更新的源记录会被转换为二进制格式写入到kafka。
转换也可以与sink connector一起使用。
- Dead Letter Queue
与其他MQ不同,Kafka 并没有死信队列这个功能。但是Kafka Connect提供了这一功能。
当Sink Task遇到无法处理的消息,会根据errors.tolerance配置项决定如何处理,默认情况下(errors.tolerance=none) Sink 遇到无法处理的记录会直接抛出异常,Task进入Fail 状态。开发人员需要根据Worker的错误日志解决问题,然后重启Task,才能继续消费数据。
设置 errors.tolerance=all,Sink Task 会忽略所有的错误,继续处理。Worker中不会有任何错误日志。可以通过配置errors.deadletterqueue.topic.name = 让无法处理的消息路由到 Dead Letter Topic
3 快速上手
下面我来实战一下,如何使用Kafka Connect,目标是将MySQL中的全量数据同步到Redis
下载连接器:
Mysql连接器:https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc
Redis连接器:https://www.confluent.io/hub/jcustenborder/kafka-connect-redis
将连接器上传到kafka目录
vi /opt/kafka/config/connect-distributed.properties
- 1
修改配置并启动Worker
#在配置文件末尾追加 plugin.path=/opt/kafka/connectors
- 1
启动Worker
bin/connect-distributed.sh -daemon config/connect-distributed.properties
准备MySQL
先确认主机里已经安装了MySQL,使用如下Sql创建表,创建之后随便造几条数据。
CREATE TABLE `test_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ;
- 1
- 2
- 3
- 4
- 5
创建连接器
1) 新建 source.json
{
"name" : "example-source",
"config" : {
"connector.class" : "com.github.taven.source.ExampleSourceConnector",
"tasks.max" : "1",
"database.url" : "jdbc:mysql://192.168.3.21:3306/test?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=UTC&rewriteBatchedStatements=true",
"database.username" : "appadmin",
"database.password" : "zzz123",
"database.tables" : "test_user"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2) 向Worker 发送请求,创建连接器
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @source.json
- 1
source.json 中,有一些属性是Kafka Connect 提供的,例如上述文件中 name, connector.class, tasks.max,剩下的属性可以在开发Connector 时自定义。关于Kafka Connect Configuration 相关请阅读这里 :https://docs.confluent.io/platform/current/installation/configuration/connect/index.html
3) 确认数据是否写入Kafka
- 首先查看一下Worker中的运行状态,如果Task的state = RUNNING,代表Task没有抛出任何异常,平稳运行
bash-4.4# curl -X GET localhost:8083/connectors/example-source/status
{"name":"example-source","connector":{"state":"RUNNING","worker_id":"168.68.38.11:8083"},
"tasks":[{"id":0,"state":"RUNNING","worker_id":"1168.68.38.11:8083"}],"type":"source"}
- 1
- 2
- 3
- 查看kafka 中Topic 是否创建
bash-4.4# bin/kafka-topics.sh --list --zookeeper zookeeper:2181
__consumer_offsets
connect-configs
connect-offsets
connect-status
test_user
- 1
- 2
- 3
- 4
- 5
- 6
这些Topic 都存储了什么?
__consumer_offsets: 记录所有Kafka Consumer Group的Offset
connect-configs: 存储连接器的配置,对应Connect 配置文件中config.storage.topic
connect-offsets: 存储Source 的Offset,对应Connect 配置文件中offset.storage.topic
connect-status: 连接器与Task的状态,对应Connect 配置文件中status.storage.topic
- 1
- 2
- 3
- 4
- 查看topic中数据,此时说明MySQL数据已经成功写入Kafka
bash-4.4# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_user --from-beginning
{"schema":{"type":"struct","fields":[{"type":"int64","optional":false,"field":"id"},{"type":"string","optional":false,"field":"name"}],"optional":false,"name":"test_user"},"payload":{"id":1,"name":"yyyyyy"}}
{"schema":{"type":"struct","fields":[{"type":"int64","optional":false,"field":"id"},{"type":"string","optional":false,"field":"name"}],"optional":false,"name":"test_user"},"payload":{"id":2,"name":"qqqq"}}
{"schema":{"type":"struct","fields":[{"type":"int64","optional":false,"field":"id"},{"type":"string","optional":false,"field":"name"}],"optional":false,"name":"test_user"},"payload":{"id":3,"name":"eeee"}}
- 1
- 2
- 3
- 4
数据结构为Json,可以回顾一下上面我们修改的connect-distributed.properties,默认提供的Converter 为JsonConverter,所有的数据包含schema 和 payload 两项是因为配置文件中默认启动了key.converter.schemas.enable=true和value.converter.schemas.enable=true两个选项
4) List item
- 启动 Sink
新建sink.json
{
"name" : "example-sink",
"config" : {
"connector.class" : "com.github.taven.sink.ExampleSinkConnector",
"topics" : "test_user, test_order",
"tasks.max" : "1",
"redis.host" : "192.168.3.21",
"redis.port" : "6379",
"redis.password" : "",
"redis.database" : "0"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 创建Sink Connector
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @sink.json
- 1
然后查看Sink Connector Status,这里我发现由于我的Redis端口只对localhost开放,所以这里我的Task Fail了,修改了Redis配置之后,
- 重启Task
curl -X POST localhost:8083/connectors/example-sink/tasks/0/restart
- 1
在确认了Sink Status 为RUNNING 后,可以确认下Redis中是否有数据
关于Kafka Connect Rest api 文档,请参考https://kafka.apache.org/documentation.html#connect_rest
- 如何查看Sink Offset消费情况
使用命令
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group connect-example-sink
- 1
Kafka Connect 高级功能
我们的第一个链路达成了。现在两个Task无事可做,正好借此机会我们来体验一下可扩展和故障转移
- 集群扩展
我启动了开发环境中的Kafka Connect Worker,根据官方文档所示通过注册同一个Kafka 并且使用相同的 group.id=connect-cluster 可以自动组成集群。
- 启动Kafka Connect,之后检查两个连接器状态
bash-4.4# curl -X GET localhost:8083/connectors/example-source/status
{"name":"example-source","connector":{"state":"RUNNING","worker_id":"168.68.38.11:8083"},
"tasks":[{"id":0,"state":"RUNNING","worker_id":"168.68.38.11:8083"}],"type":"source"}
- 1
- 2
- 3
bash-4.4# curl -X GET localhost:8083/connectors/example-sink/status
- 1
{"name":"example-sink","connector":{"state":"RUNNING","worker_id":"168.68.38.11:8083"},
"tasks":[{"id":0,"state":"RUNNING","worker_id":"172.21.0.3:8083"}],"type":"sink"}
- 1
- 2
- 观察worker_id 可以发现,两个Connectors 已经分别运行在两个Worker上了
- 故障转移
此时我们通过kill pid结束docker中的Worker进程观察是否宕机之后自动转移,Kafka Connect 的集群扩展与故障转移机制是通过Kafka Rebalance 协议实现的(Consumer也是该协议),当Worker节点宕机时间超过 scheduled.rebalance.max.delay.ms 时,Kafka才会将其踢出集群。踢出后将该节点的连接器和任务分配给其他Worker,scheduled.rebalance.max.delay.ms默认值为五分钟。
REST API
kafka connect的目的是作为一个服务运行,默认情况下,此服务运行于端口8083。它支持rest管理,用来获取 Kafka Connect 状态,管理 Kafka Connect 配置,Kafka Connect 集群内部通信,常用命令如下:
GET /connectors 返回一个活动的connect列表
POST /connectors 创建一个新的connect;请求体是一个JSON对象包含一个名称字段和连接器配置参数
GET /connectors/{name} 获取有关特定连接器的信息
GET /connectors/{name}/config 获得特定连接器的配置参数
PUT /connectors/{name}/config 更新特定连接器的配置参数
GET /connectors/{name}/tasks 获得正在运行的一个连接器的任务的列表
DELETE /connectors/{name} 删除一个连接器,停止所有任务,并删除它的配置
GET /connectors 返回一个活动的connect列表
POST /connectors 创建一个新的connect;请求体是一个JSON对象包含一个名称字段和连接器配置参数
GET /connectors/{name} 获取有关特定连接器的信息
GET /connectors/{name}/config 获得特定连接器的配置参数
PUT /connectors/{name}/config 更新特定连接器的配置参数
GET /connectors/{name}/tasks 获得正在运行的一个连接器的任务的列表
DELETE /connectors/{name} 删除一个连接器,停止所有任务,并删除它的配置
curl -s :8083/ | jq 获取 Connect Worker 信息
curl -s :8083/connector-plugins | jq 列出 Connect Worker 上所有 Connector
curl -s :8083/connectors/<Connector名字>/tasks | jq 获取 Connector 上 Task 以及相关配置的信息
curl -s :8083/connectors/<Connector名字>/status | jq 获取 Connector 状态信息
curl -s :8083/connectors/<Connector名字>/config | jq 获取 Connector 配置信息
curl -s -X PUT :8083/connectors/<Connector名字>/pause 暂停 Connector
curl -s -X PUT :8083/connectors/<Connector名字>/resume 重启 Connector
curl -s -X DELETE :8083/connectors/<Connector名字> 删除 Connector
- swagger:swagger 引入
[详细] 赞
踩

