
- 1使用码云gitee创建项目并用git上传文件测试-图文教程(简单使用)_git上传场景性能测试
- 2推荐项目:Tiktokenizer - 精确的OpenAI提示令牌计算器
- 3从0到1:如何建立一个大规模多语言代码生成预训练模型_训练一个自己的代码生成模型需要怎么做?
- 4免费白嫖ChatGPT4(国内可用)_个人搭建gpt国内使用方法
- 5Varnish、Squid、Ngx_cache性能测试对比_squid多线程还是单线程
- 6Qwen-VL_qwen-vl 合并权重
- 7【微信小程序开发】小程序更新、页面生命周期、用户信息获取应用实战_微信小程序更新
- 8【C++】数据结构之链队列(入队、出队、查找、翻转)_实现队列的翻转csdn c++
- 9C++之继承(万字长文详解)_c++ struct 继承
- 10php mud游戏源码,mud 文字游戏 - 源码下载|游戏|源代码 - 源码中国
Spark 安装部署与快速上手_spark client怎么安装
赞
踩
核心概念
Spark 是 UC Berkeley AMP lab 开发的一个集群计算的框架,类似于 Hadoop,但有很多的区别。
最大的优化是让计算任务的中间结果可以存储在内存中,不需要每次都写入 HDFS,更适用于需要迭代的 MapReduce 算法场景中,可以获得更好的性能提升。
例如一次排序测试![]() http://databricks.com/blog/2014/11/05/spark-officially-sets-a-new-record-in-large-scale-sorting.html中,对 100TB 数据进行排序,Spark 比 Hadoop 快三倍,并且只需要十分之一的机器。
http://databricks.com/blog/2014/11/05/spark-officially-sets-a-new-record-in-large-scale-sorting.html中,对 100TB 数据进行排序,Spark 比 Hadoop 快三倍,并且只需要十分之一的机器。
Spark 集群目前最大的可以达到 8000 节点,处理的数据达到 PB 级别,在互联网企业中应用非常广泛。
Spark 的特性
Hadoop 的核心是分布式文件系统 HDFS 和计算框架 MapReduces。Spark 可以替代 MapReduce,并且兼容 HDFS、Hive 等分布式存储层,良好的融入 Hadoop 的生态系统。
Spark 执行的特点
- 中间结果输出:Spark 将执行工作流抽象为通用的有向无环图执行计划(DAG),可以将多 Stage 的任务串联或者并行执行。
- 数据格式和内存布局:Spark 抽象出分布式内存存储结构弹性分布式数据集 RDD,能够控制数据在不同节点的分区,用户可以自定义分区策略。
- 任务调度的开销:Spark 采用了事件驱动的类库 AKKA 来启动任务,通过线程池的复用线程来避免系统启动和切换开销。
Spark 的优势
- 速度快,运行工作负载快 100 倍。Apache Spark 使用最先进的 DAG 调度器、查询优化器和物理执行引擎,实现了批处理和流数据的高性能。
- 易于使用,支持用 Java、Scala、Python、R 和 SQL 快速编写应用程序。Spark 提供了超过 80 个算子,可以轻松构建并行应用程序。您可以从 Scala、Python、R 和 SQL shell 中交互式地使用它。
- 普遍性,结合 SQL、流处理和复杂分析。Spark 提供了大量的库,包括 SQL 和 DataFrames、用于机器学习的 MLlib、GraphX 和 Spark 流。您可以在同一个应用程序中无缝地组合这些库。
- 各种环境都可以运行,Spark 在 Hadoop、Apache Mesos、Kubernetes、单机或云主机中运行。它可以访问不同的数据源。您可以使用它的独立集群模式在 EC2、Hadoop YARN、Mesos 或 Kubernetes 上运行 Spark。访问 HDFS、Apache Cassandra、Apache HBase、Apache Hive 和数百个其他数据源中的数据。
哪些公司在使用 Spark
日常为我们所熟知的,在国外就有 IBM Almaden(IBM 研究实验室)、Amazon(亚马逊)等,而在国内有 baidu(百度)、Tencent(腾讯)等等,包括一些其它的公司大部分都使用 Spark 来处理生产过程中产生的大量数据。更多详情可以参考链接: 谁在使用 Spark?
2.3 Spark 生态系统 BDAS
目前,Spark 已经发展成为包含众多子项目的大数据计算平台。
BDAS 是伯克利大学提出的基于 Spark 的数据分析栈(BDAS)。
其核心框架是 Spark,同时涵盖支持结构化数据 SQL 查询与分析的查询引擎 Spark SQL,提供机器学习功能的系统 MLBase 及底层的分布式机器学习库 MLlib,并行图计算框架 GraphX,流计算框架 Spark Streaming,近似查询引擎 BlinkDB,内存分布式文件系统 Tachyon,资源管理框架 Mesos 等子项目。这些子项目在 Spark 上层提供了更高层、更丰富的计算范式。
部署前准备
Spark 安装非常简单,简单到只需要下载 binary 包解压即可
安装 Spark 之前需要先安装 Java,Scala 及 Python。
- java 1.8.0
- scala 2.11.8
- python 2.7
安装Java
下载
参考清华软件源:Index of /AdoptOpenJDK/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
bash
wget wget https://mirrors.tuna.tsinghua.edu.cn/AdoptOpenJDK/8/jdk/x64/linux/OpenJDK8U-jdk_x64_linux_openj9_linuxXL_8u282b08_openj9-0.24.0.tar.gz --no-check-certificate
按需求下载之后记得修改环境变量

记得配置环境变量,添加 bin 目录即可
安装Scala
下载
bash
wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz

记得配置环境变量,添加 bin 目录即可
安装Python
一般系统自带 Python2
bash
python --version
如果需要 Python3 可以自行下载
bash
yum -y install python3
Spark 下载
此处使用的是:Spark 2.4.8
官网上下载已经预编译好的 Spark binary,直接解压即可。
Spark 官方下载链接:Downloads | Apache Spark
下载
参考
bash
wget https://mirrors.huaweicloud.com/apache/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
记得配置环境变量,添加 bin 目录即可

部署模式介绍
Spark on Mesos未尝试过,大家可以自行尝试
本文仅介绍 Standalone 模式和 Spark on Yarn模式
按照自己需求配合!
本地模式
Spark单机运行,直接解压执行start-all.sh即可,一般用于开发测试
Standalone 模式
构建一个由Master+Slave构成的Spark集群,Spark运行在集群中。
即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。
从一定程度上说,该模式是其他两种的基础。借鉴 Spark 开发模式,我们可以得到一种开发新型计算框架的一般思路:先设计出它的 standalone 模式,为了快速开发,起初不需要考虑服务(比如 master/slave)的容错性,之后再开发相应的 wrapper,将 stanlone 模式下的服务原封不动的部署到资源管理系统 yarn 或者 mesos 上,由资源管理系统负责服务本身的容错。目前 Spark 在 standalone 模式下是没有任何单点故障问题的,这是借助 zookeeper 实现的,思想类似于 Hbase master 单点故障解决方案。将 Spark standalone 与 MapReduce 比较,会发现它们两个在架构上是完全一致的:
- 都是由 master/slaves 服务组成的,且起初 master 均存在单点故障,后来均通过 zookeeper 解决(Apache MRv1 的 JobTracker 仍存在单点问题,但 CDH 版本得到了解决);
- 各个节点上的资源被抽象成粗粒度的 slot,有多少 slot 就能同时运行多少 task。不同的是,MapReduce 将 slot 分为 map slot 和 reduce slot,它们分别只能供 Map Task 和 Reduce Task 使用,而不能共享,这是 MapReduce 资源利率低效的原因之一,而 Spark 则更优化一些,它不区分 slot 类型,只有一种 slot,可以供各种类型的 Task 使用,这种方式可以提高资源利用率,但是不够灵活,不能为不同类型的 Task 定制 slot 资源。总之,这两种方式各有优缺点。
Spark on Yarn 模式
Spark客户端直接连接Yarn。不需要额外构建Spark集群。
这是一种很有前景的部署模式。但限于 YARN 自身的发展,目前仅支持粗粒度模式(Coarse-grained Mode)。
这是由于 YARN 上的 Container 资源是不可以动态伸缩的,一旦 Container 启动之后,可使用的资源不能再发生变化,不过这个已经在 YARN 计划中了。
spark on yarn 的支持两种模式:
- yarn-cluster:适用于生产环境;
- yarn-client:适用于交互、调试,希望立即看到 app 的输出
yarn-cluster 和 yarn-client 的区别在于 yarn appMaster,每个 yarn app 实例有一个 appMaster 进程,是为 app 启动的第一个 container;负责从 ResourceManager 请求资源,获取到资源后,告诉 NodeManager 为其启动 container。
yarn-cluster 和 yarn-client 模式内部实现还是有很大的区别。
如果你需要用于生产环境,那么请选择 yarn-cluster;而如果你仅仅是 Debug 程序,可以选择 yarn-client。
Spark on Mesos 模式
Spark客户端直接连接Mesos。不需要额外构建Spark集群。
这是很多公司采用的模式,官方推荐这种模式(当然,原因之一是血缘关系)。
正是由于 Spark 开发之初就考虑到支持 Mesos,因此,目前而言,Spark 运行在 Mesos 上会比运行在 YARN 上更加灵活,更加自然。
目前在 Spark On Mesos 环境中,用户可选择两种调度模式之一运行自己的应用程序(可参考 Andrew Xia 的“Mesos Scheduling Mode on Spark”):
-
粗粒度模式(Coarse-grained Mode):每个应用程序的运行环境由一个 Dirver 和若干个 Executor 组成,其中,每个 Executor 占用若干资源,内部可运行多个 Task(对应多少个“slot”)。
应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。举个例子,比如你提交应用程序时,指定使用 5 个 executor 运行你的应用程序,每个 executor 占用 5GB 内存和 5 个 CPU,每个 executor 内部设置了 5 个 slot,则 Mesos 需要先为 executor 分配资源并启动它们,之后开始调度任务。
另外,在程序运行过程中,mesos 的 master 和 slave 并不知道 executor 内部各个 task 的运行情况,executor 直接将任务状态通过内部的通信机制汇报给 Driver,从一定程度上可以认为,每个应用程序利用 mesos 搭建了一个虚拟集群自己使用。
-
细粒度模式(Fine-grained Mode):鉴于粗粒度模式会造成大量资源浪费,Spark On Mesos 还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,思想是按需分配。
与粗粒度模式一样,应用程序启动时,先会启动 executor,但每个 executor 占用资源仅仅是自己运行所需的资源,不需要考虑将来要运行的任务,之后,mesos 会为每个 executor 动态分配资源,每分配一些,便可以运行一个新任务,单个 Task 运行完之后可以马上释放对应的资源。
每个 Task 会汇报状态给 Mesos slave 和 Mesos Master,便于更加细粒度管理和容错,这种调度模式类似于 MapReduce 调度模式,每个 Task 完全独立,优点是便于资源控制和隔离,但缺点也很明显,短作业运行延迟大。
总结
这三种分布式部署方式各有利弊,通常需要根据实际情况决定采用哪种方案。
进行方案选择时,往往要考虑公司的技术路线(采用 Hadoop 生态系统还是其他生态系统)、相关技术人才储备等。上面涉及到 Spark 的许多部署模式,究竟哪种模式好这个很难说,需要根据你的需求,如果你只是测试 Spark Application,你可以选择 local 模式。而如果你数据量不是很多,Standalone 是个不错的选择。当你需要统一管理集群资源(Hadoop、Spark 等),那么你可以选择 Yarn 或者 mesos,但是这样维护成本就会变高。
- 从对比上看,mesos 似乎是 Spark 更好的选择,也是被官方推荐的
- 但如果你同时运行 hadoop 和 Spark,从兼容性上考虑,Yarn 是更好的选择。
- 如果你不仅运行了 hadoop,spark。还在资源管理上运行了 docker,Mesos 更加通用。
- Standalone 对于小规模计算集群更适合!
Standalone 模式
Standalone 另可分两种子模式:
- 单机
- 集群
当然,集群部署的前提是单机的部署完成,根据自己的需求调整即可
单机部署
Spark 虽然是大规模的计算框架,但也支持在单机上运行
修改配置文件
进入 Spark 配置目录
bash
cd $SPARK_HOME/conf
日志配置
创建/复制
bash
cp log4j.properties.template log4j.properties
我们修改 log4j.rootCategory 的 「INFO」修改为「WARN」,这一步是修改日志等级,可避免测试中输出太多信息

spark-env.sh
创建/复制
bash
cp spark-env.sh.template spark-env.sh
添加HOME 变量:JAVA_HOME、SPARK_HOME、SCALA_HOME
考虑我们已经添加至环境变量文件里了,所以我们刷新配置的环境文件即可

spark-env.sh脚本会在启动 Spark 时加载,内容包含很多配置选项及说明,在以后会用到少部分,感兴趣可以仔细阅读这个文件的注释内容。
启动Spark 服务
这一节将启动 Spark 的 master 主节点和 slave 从节点
也会介绍 spark 单机模式和集群模式的部署区别
启动主节点
前往sbin 目录
bash
cd $SPARK_HOME/sbin
启动
bash
./start-master.sh

没有报错的话表示 master 已经启动成功
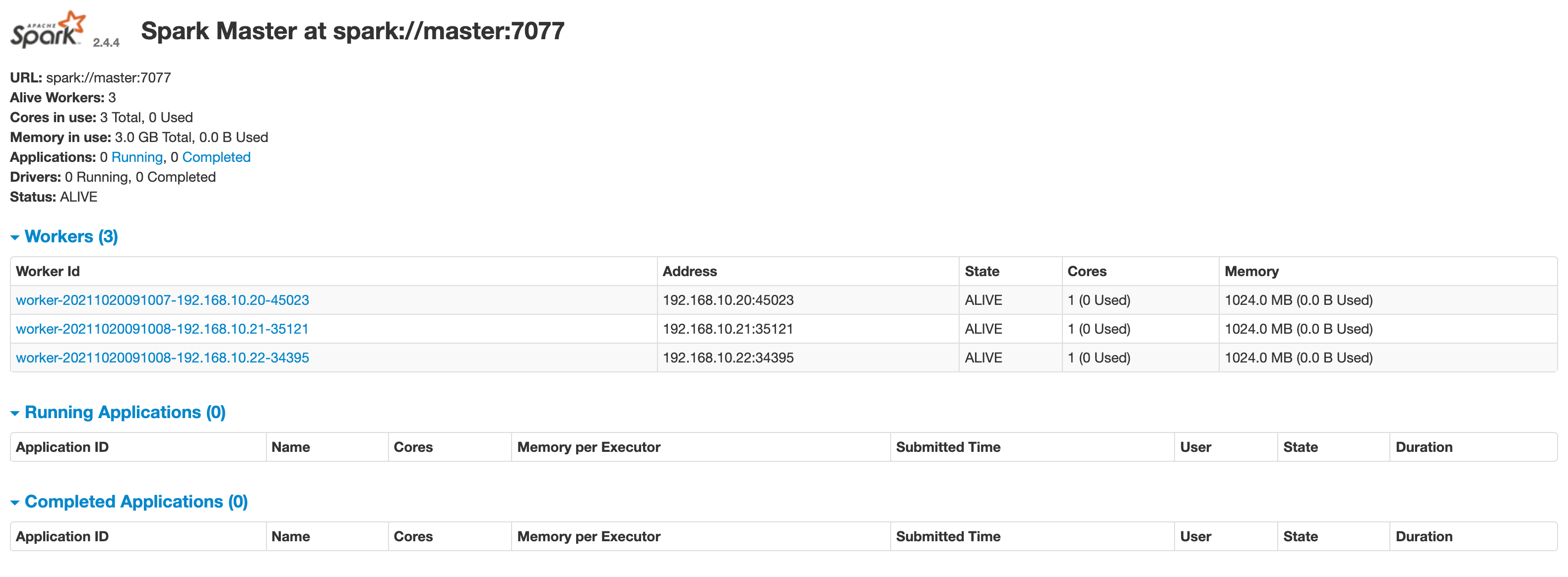
master 默认可以通过 web 访问http://localhost:8080
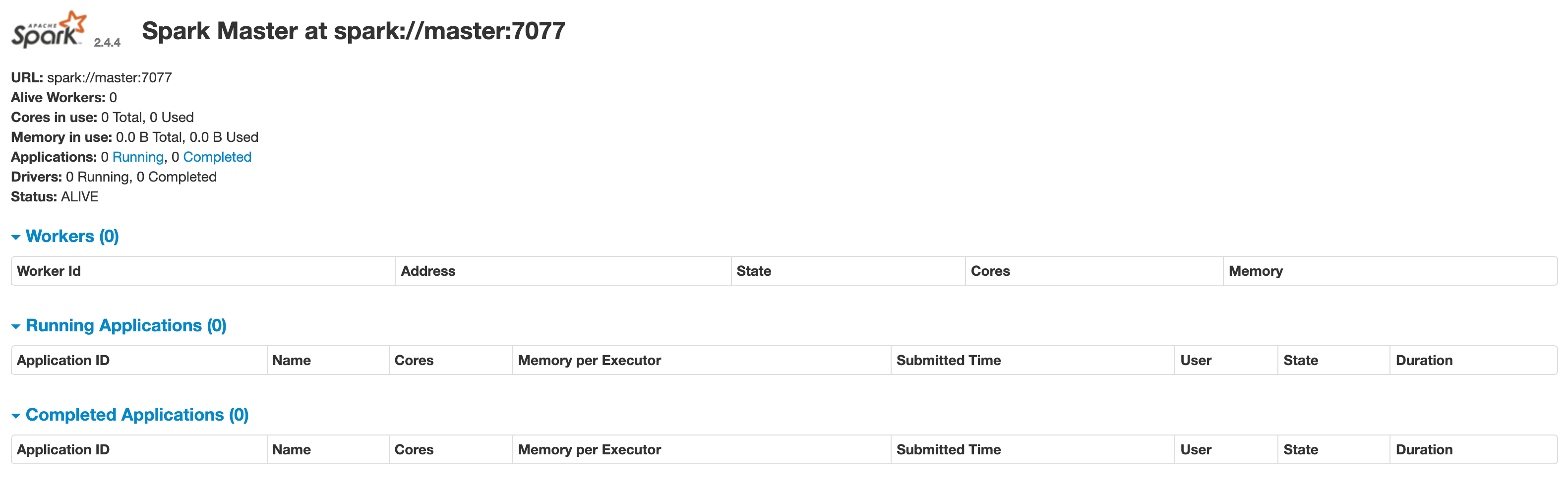
图中所示,master 中暂时还没有一个 worker ,我们启动 worker 时需要 master 的参数,该参数已经在上图中标志出来:spark://master:7077,请在执行后续命令时替换成你自己的参数。
启动从节点
启动 slave
bash
./start-slave.sh spark://master:7077

没有报错表示启动成功,再次刷新浏览器页面可以看到下图所示新的 worker 已经添加
也可以用jps命令查看启动的服务,应该会列出Master和Worker。

测试实例
使用 spark-shell 连接 master ,注意把 MASTER 参数替换成你实验环境中的实际参数
bash
MASTER=spark://master:7077 spark-shell
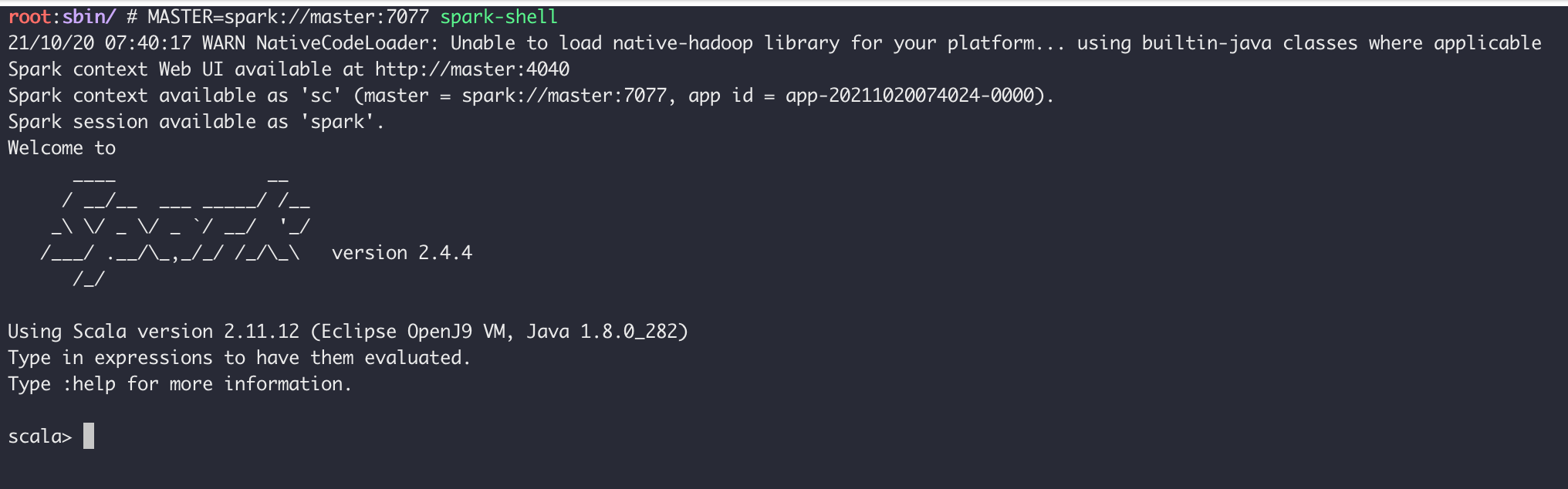
刷新 master 的 web 页面,可以看到新的Running Applications,如下图所示:
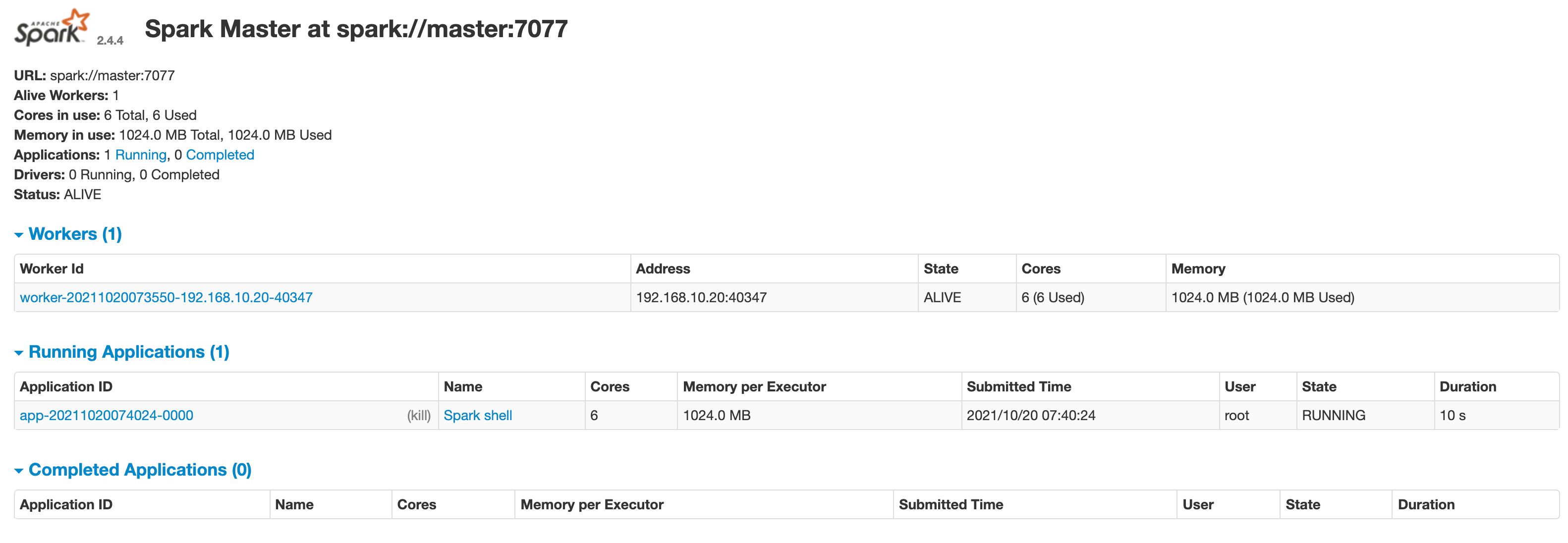
当退出 spark-shell 时,这个 application 会移动到Completed Applications一栏。
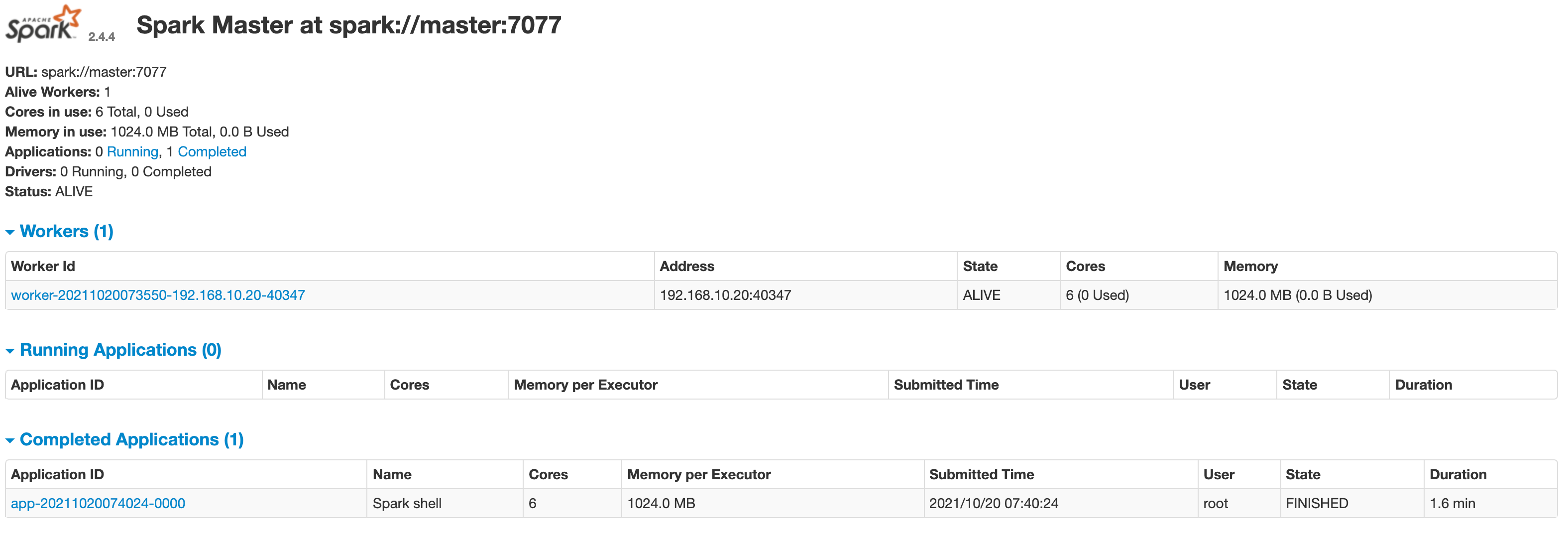
可以自己点击页面中的 Application 和 Workers 的链接查看并了解相关信息。
停止服务
停止服务的脚本为./sbin/stop-all.sh。
bash
./stop-all.sh
但我建议依次关闭
bash
./stop-master.sh ./stop-slave.sh
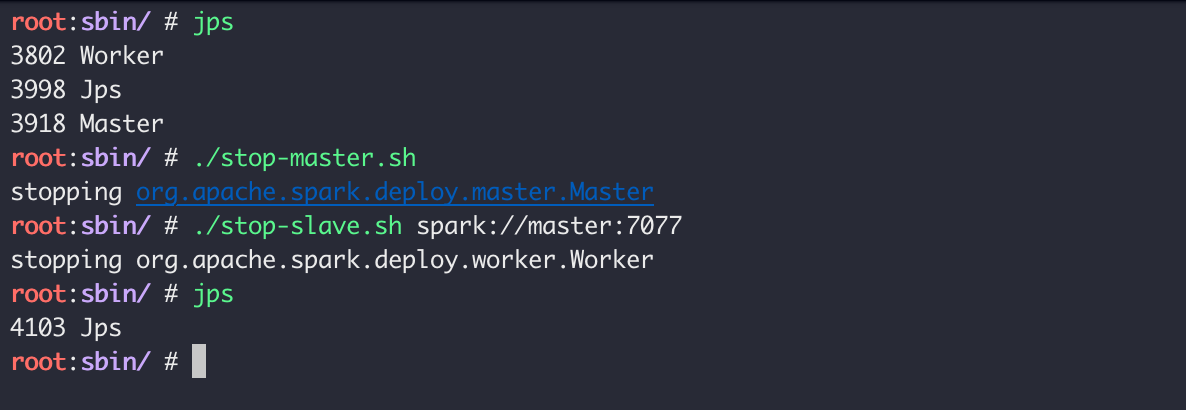
通过 jps 可以看到,master 与 worker 进程都已经停止
集群部署
修改配置
在 「单机模式」小节下的「修改配置文件」的基础上进行添加/修改
进入 Spark 配置目录
bash
cd $SPARK_HOME/conf
spark-env.sh
参数解读:
- SPARK_MASTER_HOST = Master的主机名
- SPARK_MASTER_PORT = 提交Application的端口,默认7077,可更改
- SPARK_WORKER_CORES = 每一个Worker最多可以使用的cpu核个数
- SPARK_WORKER_MEMORY = 每个Worker最多可以使用的内存
其实你完全可以参考spark-env.sh内的注释
编辑
bash
vim spark-env.sh
做出如下修改(位置非固定):

slaves
修改 slaves 配置文件,添加 Worker 的主机列表
复制/创建
bash
cp slaves.template slaves
修改localhost 为你需要的机器的 HostName
你可以参考我的:

注意需要先把所有主机名输入到 /etc/hosts 避免无法解析
同步
此处不进行赘述,具体操作大家自行搜索,或者查看我关于 「HADOOP部署」的相关文章
大致操作如下:
- ssh-keygen 命令配合 ssh-copy-id 命令实现ssh免密
- scp 命令同步所有设置(指Spark 下的 conf 文件下,或者同步 Spark 文件)
启动集群
前往 master 机器下执行
前往sbin 目录
bash
cd $SPARK_HOME/sbin
在这台机启动集群
bash
./start-all.sh
启动的步骤和「单机部署」下的「启动 Spark 服务」一致,关闭也一致
start-all.sh 和 start-master.sh、start-slave.sh 和 Hadoop 里的 start-all.sh、start-yarn.sh、start-dfs.sh 的关系大致一样
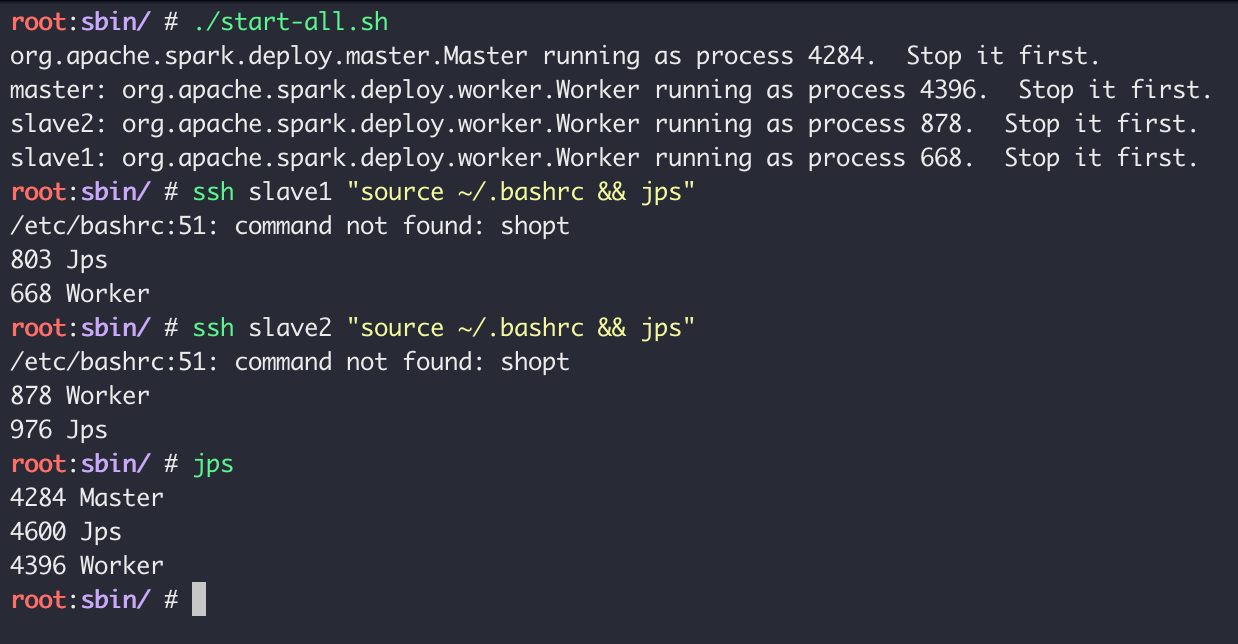
Web:
Spark 交互式执行
Spark-Shell
Spark-Shell是 Spark 自带的一个 Scala 交互 Shell ,可以以脚本方式进行交互式执行,类似直接用 Python 及其他脚本语言的 Shell 。
进入Spark-Shell只需要执行spark-shell即可:
bash
spark-shell
(前提是你配置好了 Spark 的环境变量)
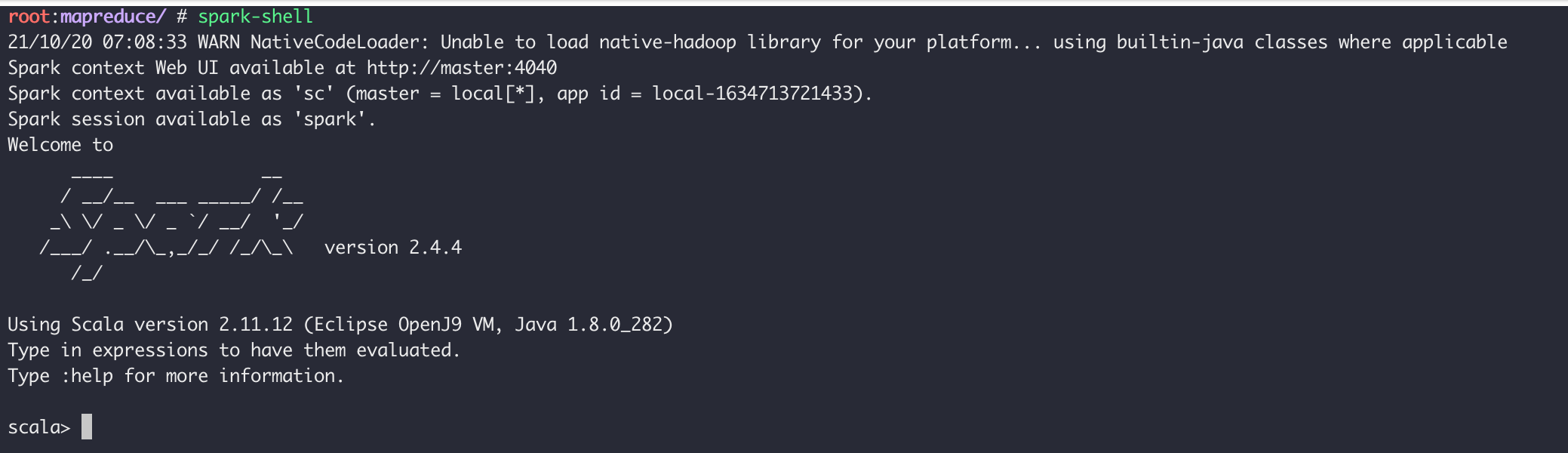
进入到Spark-Shell后可以使用Ctrl D组合键退出 Shell。
在Spark-Shell中我们可以使用 Scala 的语法进行简单的测试,比如我们运行下面几个语句获得文件/etc/protocols的行数以及第一行的内容:
scala
var f = sc.textFile("/etc/protocols")
f.count()
f.first()
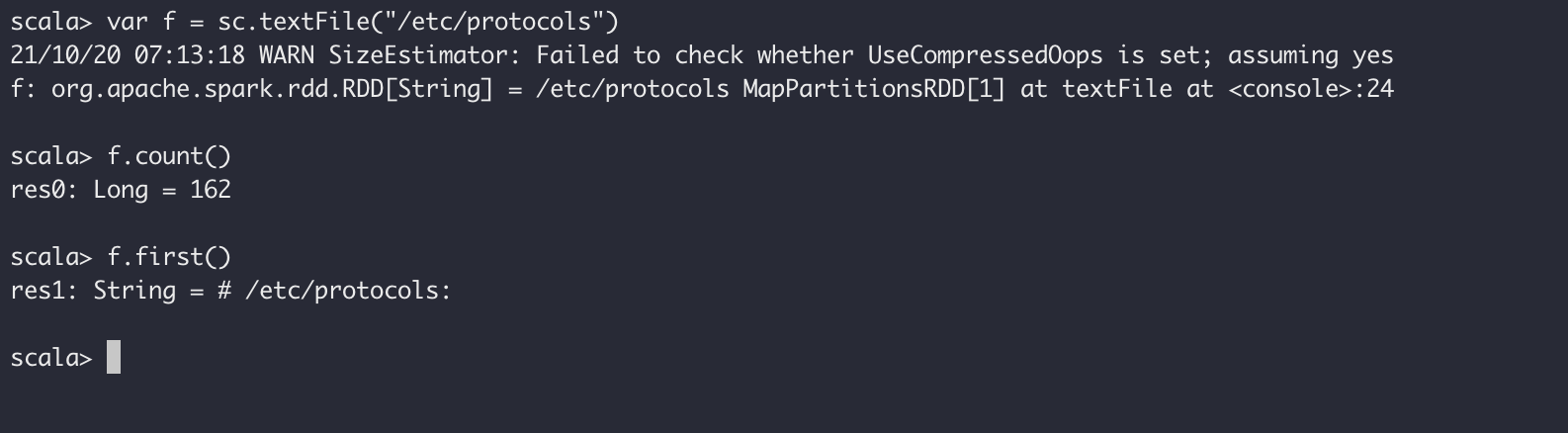
上面的操作中创建了一个 RDD file,执行了两个简单的操作:
count()获取 RDD 的行数first()获取第一行的内容
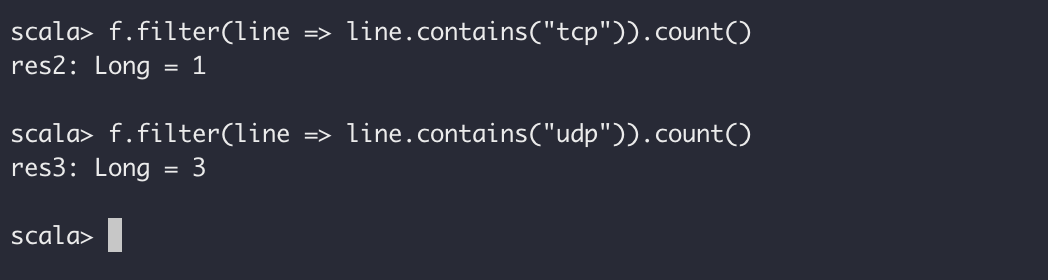
我们继续执行其他操作,比如查找有多少行含有tcp和udp字符串:
scala
f.filter(line => line.contains("tcp")).count()
f.filter(line => line.contains("udp")).count()
查看一共有多少个不同单词的方法,这里用到 Mapreduce 的思路:
scala
var wordcount = file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
wordcount.count()

上面两步骤我们发现,/etc/protocols中各有一行含有tcp与udp字符串,并且一共有 442 个不同的单词。
上面每个语句的具体含义这里不展开,可以结合你阅读的文章进行理解,这里仅仅提供一个简单的例子让大家对 Spark 运算有基本认识。
操作完成后,Ctrl D组合键退出 Shell。
Pyspark
Pyspark 类似 Spark-Shell ,是一个 Python 的交互 Shell 。
执行pyspark启动进入 Pyspark:
bash
pyspark
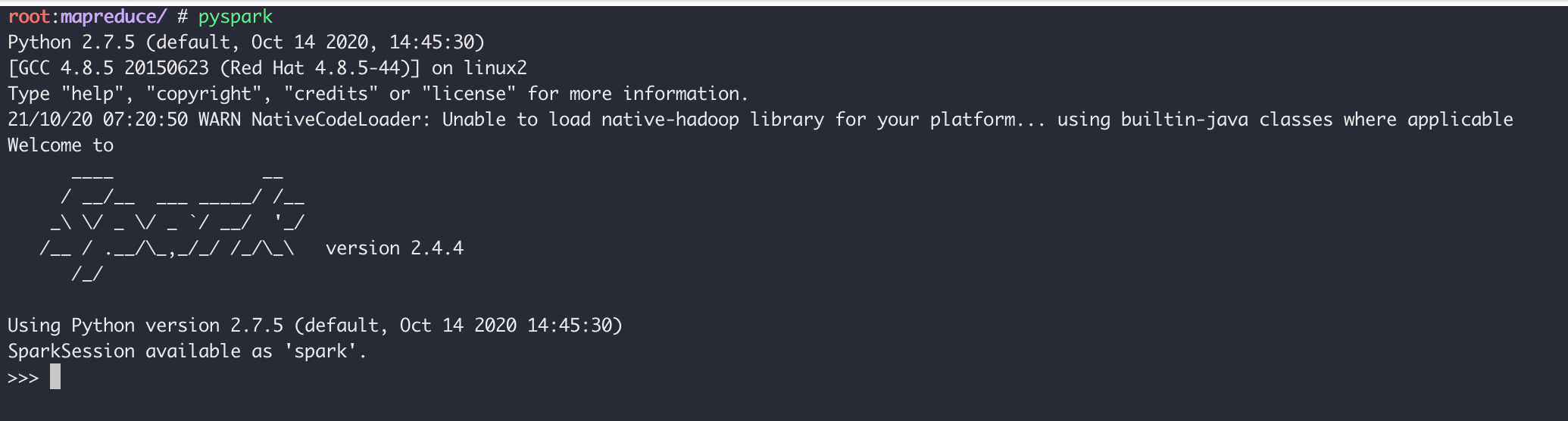
退出方法仍然是Ctrl D组合键。
在 Pyspark 中,我们可以用 Python 语法执行 Spark-Shell 中的操作,比如下面的语句获得文件/etc/protocols 的行数以及第一行的内容:
vim
file = sc.textFile("/etc/protocols")
file.count()
file.first()
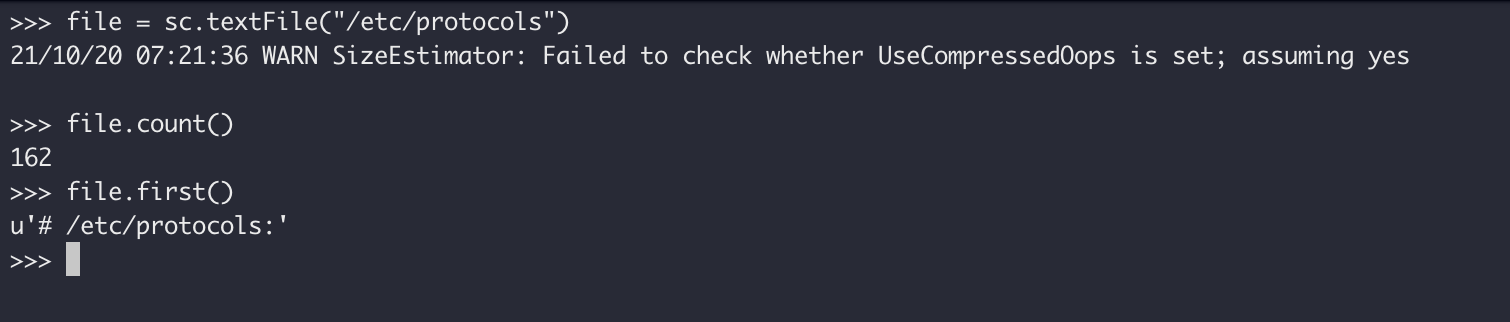
操作完成后,Ctrl D组合键退出 Shell。
对于 Pyspark 大家可以自行学习拓展,可以参考官方文档Spark Python API
提交应用程序
在Spark bin目录下的spark-submit可以用来在集群上启动应用程序。它可以通过统一的接口使用Spark支持的所有集群管理器 ,所有你不必为每一个管理器做相应的配置。
用spark-submit启动应用程序
bin/spark-submit脚本负责建立包含Spark以及其依赖的类路径(classpath),它支持不同的集群管理器以及Spark支持的加载模式。
shell
./bin/spark-submit \ --class <main-class> --master <master-url> \ --deploy-mode <deploy-mode> \ --conf <key>=<value> \ ... # other options <application-jar> \ [application-arguments]
一些常用的选项是:
--class:你的应用程序的入口点(如org.apache.spark.examples.SparkPi)--master:集群的master URL(如spark://23.195.26.187:7077)--deploy-mode:在worker节点部署你的driver(cluster)或者本地作为外部客户端(client)。默认是client。--conf:任意的Spark配置属性,格式是key=value。application-jar:包含应用程序以及其依赖的jar包的路径。这个URL必须在集群中全局可见,例如,存在于所有节点的hdfs://路径或file://路径application-arguments:传递给主类的主方法的参数
一个通用的部署策略是从网关集群提交你的应用程序,这个网关机器和你的worker集群物理上协作。在这种设置下,client模式是适合的。在client模式下,driver直接在spark-submit进程 中启动,而这个进程直接作为集群的客户端。应用程序的输入和输出都和控制台相连接。因此,这种模式特别适合涉及REPL的应用程序。
另一种选择,如果你的应用程序从一个和worker机器相距很远的机器上提交,通常情况下用cluster模式减少drivers和executors的网络迟延。注意,cluster模式目前不支持独立集群、 mesos集群以及python应用程序。
有几个我们使用的集群管理器特有的可用选项。例如,在Spark独立集群的cluster模式下,你也可以指定--supervise用来确保driver自动重启(如果它因为非零退出码失败)。 为了列举spark-submit所有的可用选项,用--help运行它。
shell
# Run application locally on 8 cores ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master local[8] \ /path/to/examples.jar \ 100 # Run on a Spark Standalone cluster in client deploy mode ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://master:7077 \ --executor-memory 20G \ --total-executor-cores 100 \ /path/to/examples.jar \ 1000 # Run on a Spark Standalone cluster in cluster deploy mode with supervise ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://master:7077 \ --deploy-mode cluster --supervise --executor-memory 20G \ --total-executor-cores 100 \ /path/to/examples.jar \ 1000 # Run on a YARN cluster export HADOOP_CONF_DIR=XXX ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn-cluster \ # can also be `yarn-client` for client mode --executor-memory 20G \ --num-executors 50 \ /path/to/examples.jar \ 1000 # Run a Python application on a Spark Standalone cluster ./bin/spark-submit \ --master spark://master:7077 \ examples/src/main/python/pi.py \ 1000
Master URLs
传递给Spark的url可以用下面的模式
| Master URL | Meaning |
|---|---|
| local | 用一个worker线程本地运行Spark |
| local[K] | 用k个worker线程本地运行Spark(理想情况下,设置这个值为你的机器的核数) |
| local[*] | 用尽可能多的worker线程本地运行Spark |
| spark://HOST:PORT | 连接到给定的Spark独立部署集群master。端口必须是master配置的端口,默认是7077 |
| mesos://HOST:PORT | 连接到给定的mesos集群 |
| yarn-client | 以client模式连接到Yarn集群。群集位置将基于通过HADOOP_CONF_DIR变量找到 |
| yarn-cluster | 以cluster模式连接到Yarn集群。群集位置将基于通过HADOOP_CONF_DIR变量找到 |
Spark Standalone扩展
手动启动集群
你能够通过下面的方式启动独立的master服务器。
shell
./sbin/start-master.sh
一旦启动,master将会为自己打印出spark://HOST:PORT URL,你能够用它连接到workers或者作为"master"参数传递给SparkContext。你也可以在master web UI上发现这个URL, master web UI默认的地址是http://localhost:8080。
相同的,你也可以启动一个或者多个workers或者将它们连接到master。
shell
./bin/spark-class org.apache.spark.deploy.worker.Worker spark://IP:PORT
一旦你启动了一个worker,查看master web UI。你可以看到新的节点列表以及节点的CPU数以及内存。
下面的配置参数可以传递给master和worker。
| Argument | Meaning |
|---|---|
| -h HOST, --host HOST | 监听的主机名 |
| -i HOST, --ip HOST | 同上,已经被淘汰 |
| -p PORT, --port PORT | 监听的服务的端口(master默认是7077,worker随机) |
| --webui-port PORT | web UI的端口(master默认是8080,worker默认是8081) |
| -c CORES, --cores CORES | Spark应用程序可以使用的CPU核数(默认是所有可用);这个选项仅在worker上可用 |
| -m MEM, --memory MEM | Spark应用程序可以使用的内存数(默认情况是你的机器内存数减去1g);这个选项仅在worker上可用 |
| -d DIR, --work-dir DIR | 用于暂存空间和工作输出日志的目录(默认是SPARK_HOME/work);这个选项仅在worker上可用 |
| --properties-file FILE | 自定义的Spark配置文件的加载目录(默认是conf/spark-defaults.conf) |
集群启动脚本
为了用启动脚本启动Spark独立集群,你应该在你的Spark目录下建立一个名为conf/slaves的文件,这个文件必须包含所有你要启动的Spark worker所在机器的主机名,一行一个。如果 conf/slaves不存在,启动脚本默认为单个机器(localhost),这台机器对于测试是有用的。注意,master机器通过ssh访问所有的worker。在默认情况下,SSH是并行运行,需要设置无密码(采用私有密钥)的访问。 如果你没有设置为无密码访问,你可以设置环境变量SPARK_SSH_FOREGROUND,为每个worker提供密码。
一旦你设置了这个文件,你就可以通过下面的shell脚本启动或者停止你的集群。
- sbin/start-master.sh:在机器上启动一个master实例
- sbin/start-slaves.sh:在每台机器上启动一个slave实例
- sbin/start-all.sh:同时启动一个master实例和所有slave实例
- sbin/stop-master.sh:停止master实例
- sbin/stop-slaves.sh:停止所有slave实例
- sbin/stop-all.sh:停止master实例和所有slave实例
注意,这些脚本必须在你的Spark master运行的机器上执行,而不是在你的本地机器上面。
你可以在conf/spark-env.sh中设置环境变量进一步配置集群。利用conf/spark-env.sh.template创建这个文件,然后将它复制到所有的worker机器上使设置有效。下面的设置可以起作用:
| Environment Variable | Meaning |
|---|---|
| SPARK_MASTER_IP | 绑定master到一个指定的ip地址 |
| SPARK_MASTER_PORT | 在不同的端口上启动master(默认是7077) |
| SPARK_MASTER_WEBUI_PORT | master web UI的端口(默认是8080) |
| SPARK_MASTER_OPTS | 应用到master的配置属性,格式是 "-Dx=y"(默认是none),查看下面的表格的选项以组成一个可能的列表 |
| SPARK_LOCAL_DIRS | Spark中暂存空间的目录。包括map的输出文件和存储在磁盘上的RDDs(including map output files and RDDs that get stored on disk)。这必须在一个快速的、你的系统的本地磁盘上。它可以是一个逗号分隔的列表,代表不同磁盘的多个目录 |
| SPARK_WORKER_CORES | Spark应用程序可以用到的核心数(默认是所有可用) |
| SPARK_WORKER_MEMORY | Spark应用程序用到的内存总数(默认是内存总数减去1G)。注意,每个应用程序个体的内存通过spark.executor.memory设置 |
| SPARK_WORKER_PORT | 在指定的端口上启动Spark worker(默认是随机) |
| SPARK_WORKER_WEBUI_PORT | worker UI的端口(默认是8081) |
| SPARK_WORKER_INSTANCES | 每台机器运行的worker实例数,默认是1。如果你有一台非常大的机器并且希望运行多个worker,你可以设置这个数大于1。如果你设置了这个环境变量,确保你也设置了SPARK_WORKER_CORES环境变量用于限制每个worker的核数或者每个worker尝试使用所有的核。 |
| SPARK_WORKER_DIR | Spark worker运行目录,该目录包括日志和暂存空间(默认是SPARK_HOME/work) |
| SPARK_WORKER_OPTS | 应用到worker的配置属性,格式是 "-Dx=y"(默认是none),查看下面表格的选项以组成一个可能的列表 |
| SPARK_DAEMON_MEMORY | 分配给Spark master和worker守护进程的内存(默认是512m) |
| SPARK_DAEMON_JAVA_OPTS | Spark master和worker守护进程的JVM选项,格式是"-Dx=y"(默认为none) |
| SPARK_PUBLIC_DNS | Spark master和worker公共的DNS名(默认是none) |
注意,启动脚本还不支持windows。为了在windows上启动Spark集群,需要手动启动master和workers。
SPARK_MASTER_OPTS支持一下的系统属性:
| Property Name | Default | Meaning |
|---|---|---|
| spark.deploy.retainedApplications | 200 | 展示完成的应用程序的最大数目。老的应用程序会被删除以满足该限制 |
| spark.deploy.retainedDrivers | 200 | 展示完成的drivers的最大数目。老的应用程序会被删除以满足该限制 |
| spark.deploy.spreadOut | true | 这个选项控制独立的集群管理器是应该跨节点传递应用程序还是应努力将程序整合到尽可能少的节点上。在HDFS中,传递程序是数据本地化更好的选择,但是,对于计算密集型的负载,整合会更有效率。 |
| spark.deploy.defaultCores | (infinite) | 在Spark独立模式下,给应用程序的默认核数(如果没有设置spark.cores.max)。如果没有设置,应用程序总数获得所有可用的核,除非设置了spark.cores.max。在共享集群上设置较低的核数,可用防止用户默认抓住整个集群。 |
| spark.worker.timeout | 60 | 独立部署的master认为worker失败(没有收到心跳信息)的间隔时间。 |
SPARK_WORKER_OPTS支持的系统属性:
| Property Name | Default | Meaning |
|---|---|---|
| spark.worker.cleanup.enabled | false | 周期性的清空worker/应用程序目录。注意,这仅仅影响独立部署模式。不管应用程序是否还在执行,用于程序目录都会被清空 |
| spark.worker.cleanup.interval | 1800 (30分) | 在本地机器上,worker清空老的应用程序工作目录的时间间隔 |
| spark.worker.cleanup.appDataTtl | 7 243600 (7天) | 每个worker中应用程序工作目录的保留时间。这个时间依赖于你可用磁盘空间的大小。应用程序日志和jar包上传到每个应用程序的工作目录。随着时间的推移,工作目录会很快的填满磁盘空间,特别是如果你运行的作业很频繁。 |
连接一个应用程序到集群中
为了在Spark集群中运行一个应用程序,简单地传递spark://IP:PORT URL到SparkContext
为了在集群上运行一个交互式的Spark shell,运行一下命令:
shell
./bin/spark-shell --master spark://IP:PORT
你也可以传递一个选项--total-executor-cores <numcores>去控制spark-shell的核数。
启动Spark应用程序
spark-submit脚本支持最直接的提交一个Spark应用程序到集群。对于独立部署的集群,Spark目前支持两种部署模式。在client模式中,driver启动进程与 客户端提交应用程序所在的进程是同一个进程。然而,在cluster模式中,driver在集群的某个worker进程中启动,只有客户端进程完成了提交任务,它不会等到应用程序完成就会退出。
如果你的应用程序通过Spark submit启动,你的应用程序jar包将会自动分发到所有的worker节点。对于你的应用程序依赖的其它jar包,你应该用--jars符号指定(如--jars jar1,jar2)。
另外,cluster模式支持自动的重启你的应用程序(如果程序一非零的退出码退出)。为了用这个特征,当启动应用程序时,你可以传递--supervise符号到spark-submit。如果你想杀死反复失败的应用, 你可以通过如下的方式:
shell
./bin/spark-class org.apache.spark.deploy.Client kill <master url=""> <driver id="">
你可以在独立部署的Master web UI(http://:8080)中找到driver ID。
资源调度
独立部署的集群模式仅仅支持简单的FIFO调度器。然而,为了允许多个并行的用户,你能够控制每个应用程序能用的最大资源数。在默认情况下,它将获得集群的所有核,这只有在某一时刻只 允许一个应用程序才有意义。你可以通过spark.cores.max在SparkConf中设置核数。
scala
val conf = new SparkConf()
.setMaster(...)
.setAppName(...)
.set("spark.cores.max", "10")
val sc = new SparkContext(conf)
另外,你可以在集群的master进程中配置spark.deploy.defaultCores来改变默认的值。在conf/spark-env.sh添加下面的行:
properties
export SPARK_MASTER_OPTS="-Dspark.deploy.defaultCores=<value>"
这在用户没有配置最大核数的共享集群中是有用的。
高可用
默认情况下,独立的调度集群对worker失败是有弹性的(在Spark本身的范围内是有弹性的,对丢失的工作通过转移它到另外的worker来解决)。然而,调度器通过master去执行调度决定, 这会造成单点故障:如果master死了,新的应用程序就无法创建。为了避免这个,我们有两个高可用的模式。
用ZooKeeper的备用master
利用ZooKeeper去支持领导选举以及一些状态存储,你能够在你的集群中启动多个master,这些master连接到同一个ZooKeeper实例上。一个被选为“领导”,其它的保持备用模式。如果当前 的领导死了,另一个master将会被选中,恢复老master的状态,然后恢复调度。整个的恢复过程大概需要1到2分钟。注意,这个恢复时间仅仅会影响调度新的应用程序-运行在失败master中的 应用程序不受影响。
配置
为了开启这个恢复模式,你可以用下面的属性在spark-env中设置SPARK_DAEMON_JAVA_OPTS。
| System property | Meaning |
|---|---|
| spark.deploy.recoveryMode | 设置ZOOKEEPER去启动备用master模式(默认为none) |
| spark.deploy.zookeeper.url | zookeeper集群url(如192.168.1.100:2181,192.168.1.101:2181) |
| spark.deploy.zookeeper.dir | zookeeper保存恢复状态的目录(默认是/spark) |
可能的陷阱:如果你在集群中有多个masters,但是没有用zookeeper正确的配置这些masters,这些masters不会发现彼此,会认为它们都是leaders。这将会造成一个不健康的集群状态(因为所有的master都会独立的调度)。
细节
zookeeper集群启动之后,开启高可用是简单的。在相同的zookeeper配置(zookeeper URL和目录)下,在不同的节点上简单地启动多个master进程。master可以随时添加和删除。
为了调度新的应用程序或者添加worker到集群,它需要知道当前leader的IP地址。这可以通过简单的传递一个master列表来完成。例如,你可能启动你的SparkContext指向spark://host1:port1,host2:port2。 这将造成你的SparkContext同时注册这两个master-如果host1死了,这个配置文件将一直是正确的,因为我们将找到新的leader-host2。
"registering with a Master"和正常操作之间有重要的区别。当启动时,一个应用程序或者worker需要能够发现和注册当前的leader master。一旦它成功注册,它就在系统中了。如果 错误发生,新的leader将会接触所有之前注册的应用程序和worker,通知他们领导关系的变化,所以它们甚至不需要事先知道新启动的leader的存在。
由于这个属性的存在,新的master可以在任何时候创建。你唯一需要担心的问题是新的应用程序和workers能够发现它并将它注册进来以防它成为leader master。
用本地文件系统做单节点恢复
zookeeper是生产环境下最好的选择,但是如果你想在master死掉后重启它,FILESYSTEM模式可以解决。当应用程序和worker注册,它们拥有足够的状态写入提供的目录,以至于在重启master 进程时它们能够恢复。
配置
为了开启这个恢复模式,你可以用下面的属性在spark-env中设置SPARK_DAEMON_JAVA_OPTS。
| System property | Meaning |
|---|---|
| spark.deploy.recoveryMode | 设置为FILESYSTEM开启单节点恢复模式(默认为none) |
| spark.deploy.recoveryDirectory | 用来恢复状态的目录 |
细节
- 这个解决方案可以和监控器/管理器(如monit)相配合,或者仅仅通过重启开启手动恢复。
- 虽然文件系统的恢复似乎比没有做任何恢复要好,但对于特定的开发或实验目的,这种模式可能是次优的。特别是,通过
stop-master.sh杀掉master不会清除它的恢复状态,所以,不管你何时启动一个新的master,它都将进入恢复模式。这可能使启动时间增加到1分钟。 - 虽然它不是官方支持的方式,你也可以创建一个NFS目录作为恢复目录。如果原始的master节点完全死掉,你可以在不同的节点启动master,它可以正确的恢复之前注册的所有应用程序和workers。未来的应用程序会发现这个新的master。
在YARN上运行Spark
配置
大部分为Spark on YARN模式提供的配置与其它部署模式提供的配置相同。下面这些是为Spark on YARN模式提供的配置。
Hadoop 配置
记得到yarn-site-xml下添加:
bash
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
xml
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
Spark属性
| Property Name | Default | Meaning |
|---|---|---|
| spark.yarn.applicationMaster.waitTries | 10 | ApplicationMaster等待Spark master的次数以及SparkContext初始化尝试的次数 |
| spark.yarn.submit.file.replication | HDFS默认的复制次数(3) | 上传到HDFS的文件的HDFS复制水平。这些文件包括Spark jar、app jar以及任何分布式缓存文件/档案 |
| spark.yarn.preserve.staging.files | false | 设置为true,则在作业结束时保留阶段性文件(Spark jar、app jar以及任何分布式缓存文件)而不是删除它们 |
| spark.yarn.scheduler.heartbeat.interval-ms | 5000 | Spark application master给YARN ResourceManager发送心跳的时间间隔(ms) |
| spark.yarn.max.executor.failures | numExecutors * 2,最小为3 | 失败应用程序之前最大的执行失败数 |
| spark.yarn.historyServer.address | (none) | Spark历史服务器(如host.com:18080)的地址。这个地址不应该包含一个模式(http://)。默认情况下没有设置值,这是因为该选项是一个可选选项。当Spark应用程序完成从ResourceManager.xn--%2C-0n6a5a4i4cx5nm9cq9fs6huv1aztnca24z1v3a0o8d42yb1ma0wy41dt1aeaa8870cga5681b.xn--sparkresourcemanager-0w75an08pwqoodr0t8owxt5j2u2a/) UI到Spark历史服务器UI的连接时,这个地址从YARN ResourceManager得到 |
| spark.yarn.dist.archives | (none) | 提取逗号分隔的档案列表到每个执行器的工作目录 |
| spark.yarn.dist.files | (none) | 放置逗号分隔的文件列表到每个执行器的工作目录 |
| spark.yarn.executor.memoryOverhead | executorMemory * 0.07,最小384 | 分配给每个执行器的堆内存大小(以MB为单位)。它是VM开销、interned字符串或者其它本地开销占用的内存。这往往随着执行器大小而增长。(典型情况下是6%-10%) |
| spark.yarn.driver.memoryOverhead | driverMemory * 0.07,最小384 | 分配给每个driver的堆内存大小(以MB为单位)。它是VM开销、interned字符串或者其它本地开销占用的内存。这往往随着执行器大小而增长。(典型情况下是6%-10%) |
| spark.yarn.queue | default | 应用程序被提交到的YARN队列的名称 |
| spark.yarn.jar | (none) | Spark jar文件的位置,覆盖默认的位置。默认情况下,Spark on YARN将会用到本地安装的Spark jar。但是Spark jar也可以HDFS中的一个公共位置。这允许YARN缓存它到节点上,而不用在每次运行应用程序时都需要分配。指向HDFS中的jar包,可以这个参数为"hdfs:///some/path" |
| spark.yarn.access.namenodes | (none) | 你的Spark应用程序访问的HDFS namenode列表。例如,spark.yarn.access.namenodes=hdfs://nn1.com:8032,hdfs://nn2.com:8032,Spark应用程序必须访问namenode列表,Kerberos必须正确配置来访问它们。Spark获得namenode的安全令牌,这样Spark应用程序就能够访问这些远程的HDFS集群。 |
| spark.yarn.containerLauncherMaxThreads | 25 | 为了启动执行者容器,应用程序master用到的最大线程数 |
| spark.yarn.appMasterEnv.[EnvironmentVariableName] | (none) | 添加通过EnvironmentVariableName指定的环境变量到Application Master处理YARN上的启动。用户可以指定多个该设置,从而设置多个环境变量。在yarn-cluster模式下,这控制Spark driver的环境。在yarn-client模式下,这仅仅控制执行器启动者的环境。 |
在YARN上启动Spark
确保HADOOP_CONF_DIR或YARN_CONF_DIR指向的目录包含Hadoop集群的(客户端)配置文件。这些配置用于写数据到dfs和连接到YARN ResourceManager。
有两种部署模式可以用来在YARN上启动Spark应用程序。在yarn-cluster模式下,Spark driver运行在application master进程中,这个进程被集群中的YARN所管理,客户端会在初始化应用程序 之后关闭。在yarn-client模式下,driver运行在客户端进程中,application master仅仅用来向YARN请求资源。
和Spark单独模式以及Mesos模式不同,在这些模式中,master的地址由"master"参数指定,而在YARN模式下,ResourceManager的地址从Hadoop配置得到。因此master参数是简单的yarn-client和yarn-cluster。
在yarn-cluster模式下启动Spark应用程序。
bash
./bin/spark-submit --class path.to.your.Class --master yarn-cluster [options] <app jar=""> [app options]
例子:
shell
$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn-cluster \
--num-executors 3 \
--driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 \
--queue thequeue \
lib/spark-examples*.jar \
10
以上启动了一个YARN客户端程序用来启动默认的 Application Master,然后SparkPi会作为Application Master的子线程运行。客户端会定期的轮询Application Master用于状态更新并将 更新显示在控制台上。一旦你的应用程序运行完毕,客户端就会退出。
在yarn-client模式下启动Spark应用程序,运行下面的shell脚本
shell
$ ./bin/spark-shell --master yarn-client
添加其它的jar
在yarn-cluster模式下,driver运行在不同的机器上,所以离开了保存在本地客户端的文件,SparkContext.addJar将不会工作。为了使SparkContext.addJar用到保存在客户端的文件, 在启动命令中加上--jars选项。
shell
$ ./bin/spark-submit --class my.main.Class \
--master yarn-cluster \
--jars my-other-jar.jar,my-other-other-jar.jar
my-main-jar.jar
app_arg1 app_arg2
注意事项
- 在Hadoop 2.2之前,YARN不支持容器核的资源请求。因此,当运行早期的版本时,通过命令行参数指定的核的数量无法传递给YARN。在调度决策中,核请求是否兑现取决于用哪个调度器以及 如何配置调度器。
- Spark executors使用的本地目录将会是YARN配置(yarn.nodemanager.local-dirs)的本地目录。如果用户指定了
spark.local.dir,它将被忽略。 --files和--archives选项支持指定带 # 号文件名。例如,你能够指定--files localtest.txt#appSees.txt,它上传你在本地命名为localtest.txt的文件到HDFS,但是将会链接为名称appSees.txt。当你的应用程序运行在YARN上时,你应该使用appSees.txt去引用该文件。- 如果你在yarn-cluster模式下运行
SparkContext.addJar,并且用到了本地文件,--jars选项允许SparkContext.addJar函数能够工作。如果你正在使用 HDFS, HTTP, HTTPS或FTP,你不需要用到该选项
Spark配置
Spark提供三个位置用来配置系统:
- Spark properties控制大部分的应用程序参数,可以用SparkConf对象或者java系统属性设置
- Environment variables可以通过每个节点的
conf/spark-env.sh脚本设置每台机器的设置。例如IP地址 - Logging可以通过log4j.properties配置
Spark属性
Spark属性控制大部分的应用程序设置,并且为每个应用程序分别配置它。这些属性可以直接在SparkConf上配置,然后传递给SparkContext。SparkConf 允许你配置一些通用的属性(如master URL、应用程序明)以及通过set()方法设置的任意键值对。例如,我们可以用如下方式创建一个拥有两个线程的应用程序。注意,我们用local[2]运行,这意味着两个线程-表示最小的 并行度,它可以帮助我们检测当在分布式环境下运行的时才出现的错误。
scala
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("CountingSheep")
.set("spark.executor.memory", "1g")
val sc = new SparkContext(conf)
注意,我们在本地模式中拥有超过1个线程。和Spark Streaming的情况一样,我们可能需要一个线程防止任何形式的饥饿问题。
动态加载Spark属性
在一些情况下,你可能想在SparkConf中避免硬编码确定的配置。例如,你想用不同的master或者不同的内存数运行相同的应用程序。Spark允许你简单地创建一个空conf。
scala
val sc = new SparkContext(new SparkConf())
然后你在运行时提供值。
shell
./bin/spark-submit --name "My app" --master local[4] --conf spark.shuffle.spill=false --conf "spark.executor.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimeStamps" myApp.jar
Spark shell和spark-submit工具支持两种方式动态加载配置。第一种方式是命令行选项,例如--master,如上面shell显示的那样。spark-submit可以接受任何Spark属性,用--conf 标记表示。但是那些参与Spark应用程序启动的属性要用特定的标记表示。运行./bin/spark-submit --help将会显示选项的整个列表。
bin/spark-submit也会从conf/spark-defaults.conf中读取配置选项,这个配置文件中,每一行都包含一对以空格分开的键和值。例如:
stylus
spark.master spark://5.6.7.8:7077 spark.executor.memory 512m spark.eventLog.enabled true spark.serializer org.apache.spark.serializer.KryoSerializer
任何标签(flags)指定的值或者在配置文件中的值将会传递给应用程序,并且通过SparkConf合并这些值。在SparkConf上设置的属性具有最高的优先级,其次是传递给spark-submit 或者spark-shell的属性值,最后是spark-defaults.conf文件中的属性值。
查看Spark属性
在http://<driver>:4040上的应用程序web UI在“Environment”标签中列出了所有的Spark属性。这对你确保设置的属性的正确性是很有用的。注意,只有通过spark-defaults.conf, SparkConf以及 命令行直接指定的值才会显示。对于其它的配置属性,你可以认为程序用到了默认的值。
可用的属性
控制内部设置的大部分属性都有合理的默认值,一些最通用的选项设置如下:
应用程序属性
| Property Name | Default | Meaning |
|---|---|---|
| spark.app.name | (none) | 你的应用程序的名字。这将在UI和日志数据中出现 |
| spark.master | (none) | 集群管理器连接的地方 |
| spark.executor.memory | 512m | 每个executor进程使用的内存数。和JVM内存串拥有相同的格式(如512m,2g) |
| spark.driver.memory | 512m | driver进程使用的内存数 |
| spark.driver.maxResultSize | 1g | 每个Spark action(如collect)所有分区的序列化结果的总大小限制。设置的值应该不小于1m,0代表没有限制。如果总大小超过这个限制,工作将会终止。大的限制值可能导致driver出现内存溢出错误(依赖于spark.driver.memory和JVM中对象的内存消耗)。设置合理的限制,可以避免出现内存溢出错误。 |
| spark.serializer | org.apache.spark.serializer.JavaSerializer | 序列化对象使用的类。默认的java序列化类可以序列化任何可序列化的java对象但是它很慢。所有我们建议用org.apache.spark.serializer.KryoSerializer |
| spark.kryo.classesToRegister | (none) | 如果你用Kryo序列化,给定的用逗号分隔的自定义类名列表表示要注册的类 |
| spark.kryo.registrator | (none) | 如果你用Kryo序列化,设置这个类去注册你的自定义类。如果你需要用自定义的方式注册你的类,那么这个属性是有用的。否则spark.kryo.classesToRegister会更简单。它应该设置一个继承自KryoRegistrator的类 |
| spark.local.dir | /tmp | Spark中暂存空间的使用目录。在Spark1.0以及更高的版本中,这个属性被SPARK_LOCAL_DIRS(Standalone, Mesos)和LOCAL_DIRS(YARN)环境变量覆盖。 |
| spark.logConf | false | 当SparkContext启动时,将有效的SparkConf记录为INFO。 |
运行环境
| Property Name | Default | Meaning |
|---|---|---|
| spark.executor.extraJavaOptions | (none) | 传递给executors的JVM选项字符串。例如GC设置或者其它日志设置。注意,在这个选项中设置Spark属性或者堆大小是不合法的。Spark属性需要用SparkConf对象或者spark-submit脚本用到的spark-defaults.conf文件设置。堆内存可以通过spark.executor.memory设置 |
| spark.executor.extraClassPath | (none) | 附加到executors的classpath的额外的classpath实体。这个设置存在的主要目的是Spark与旧版本的向后兼容问题。用户一般不用设置这个选项 |
| spark.executor.extraLibraryPath | (none) | 指定启动executor的JVM时用到的库路径 |
| spark.executor.logs.rolling.strategy | (none) | 设置executor日志的滚动(rolling)策略。默认情况下没有开启。可以配置为time(基于时间的滚动)和size(基于大小的滚动)。对于time,用spark.executor.logs.rolling.time.interval设置滚动间隔;对于size,用spark.executor.logs.rolling.size.maxBytes设置最大的滚动大小 |
| spark.executor.logs.rolling.time.interval | daily | executor日志滚动的时间间隔。默认情况下没有开启。合法的值是daily, hourly, minutely以及任意的秒。 |
| spark.executor.logs.rolling.size.maxBytes | (none) | executor日志的最大滚动大小。默认情况下没有开启。值设置为字节 |
| spark.executor.logs.rolling.maxRetainedFiles | (none) | 设置被系统保留的最近滚动日志文件的数量。更老的日志文件将被删除。默认没有开启。 |
| spark.files.userClassPathFirst | false | (实验性)当在Executors中加载类时,是否用户添加的jar比Spark自己的jar优先级高。这个属性可以降低Spark依赖和用户依赖的冲突。它现在还是一个实验性的特征。 |
| spark.python.worker.memory | 512m | 在聚合期间,每个python worker进程使用的内存数。在聚合期间,如果内存超过了这个限制,它将会将数据塞进磁盘中 |
| spark.python.profile | false | 在Python worker中开启profiling。通过sc.show_profiles()展示分析结果。或者在driver退出前展示分析结果。可以通过sc.dump_profiles(path)将结果dump到磁盘中。如果一些分析结果已经手动展示,那么在driver退出前,它们再不会自动展示 |
| spark.python.profile.dump | (none) | driver退出前保存分析结果的dump文件的目录。每个RDD都会分别dump一个文件。可以通过ptats.Stats()加载这些文件。如果指定了这个属性,分析结果不会自动展示 |
| spark.python.worker.reuse | true | 是否重用python worker。如果是,它将使用固定数量的Python workers,而不需要为每个任务fork()一个Python进程。如果有一个非常大的广播,这个设置将非常有用。因为,广播不需要为每个任务从JVM到Python worker传递一次 |
| spark.executorEnv.[EnvironmentVariableName] | (none) | 通过EnvironmentVariableName添加指定的环境变量到executor进程。用户可以指定多个EnvironmentVariableName,设置多个环境变量 |
| spark.mesos.executor.home | driver side SPARK_HOME | 设置安装在Mesos的executor上的Spark的目录。默认情况下,executors将使用driver的Spark本地(home)目录,这个目录对它们不可见。注意,如果没有通过spark.executor.uri指定Spark的二进制包,这个设置才起作用 |
| spark.mesos.executor.memoryOverhead | executor memory * 0.07, 最小384m | 这个值是spark.executor.memory的补充。它用来计算mesos任务的总内存。另外,有一个7%的硬编码设置。最后的值将选择spark.mesos.executor.memoryOverhead或者spark.executor.memory的7%二者之间的大者 |
Shuffle行为(Behavior)
| Property Name | Default | Meaning |
|---|---|---|
| spark.shuffle.consolidateFiles | false | 如果设置为"true",在shuffle期间,合并的中间文件将会被创建。创建更少的文件可以提供文件系统的shuffle的效率。这些shuffle都伴随着大量递归任务。当用ext4和dfs文件系统时,推荐设置为"true"。在ext3中,因为文件系统的限制,这个选项可能机器(大于8核)降低效率 |
| spark.shuffle.spill | true | 如果设置为"true",通过将多出的数据写入磁盘来限制内存数。通过spark.shuffle.memoryFraction来指定spilling的阈值 |
| spark.shuffle.spill.compress | true | 在shuffle时,是否将spilling的数据压缩。压缩算法通过spark.io.compression.codec指定。 |
| spark.shuffle.memoryFraction | 0.2 | 如果spark.shuffle.spill为“true”,shuffle中聚合和合并组操作使用的java堆内存占总内存的比重。在任何时候,shuffles使用的所有内存内maps的集合大小都受这个限制的约束。超过这个限制,spilling数据将会保存到磁盘上。如果spilling太过频繁,考虑增大这个值 |
| spark.shuffle.compress | true | 是否压缩map操作的输出文件。一般情况下,这是一个好的选择。 |
| spark.shuffle.file.buffer.kb | 32 | 每个shuffle文件输出流内存内缓存的大小,单位是kb。这个缓存减少了创建只中间shuffle文件中磁盘搜索和系统访问的数量 |
| spark.reducer.maxMbInFlight | 48 | 从递归任务中同时获取的map输出数据的最大大小(mb)。因为每一个输出都需要我们创建一个缓存用来接收,这个设置代表每个任务固定的内存上限,所以除非你有更大的内存,将其设置小一点 |
| spark.shuffle.manager | sort | 它的实现用于shuffle数据。有两种可用的实现:sort和hash。基于sort的shuffle有更高的内存使用率 |
| spark.shuffle.sort.bypassMergeThreshold | 200 | (Advanced) In the sort-based shuffle manager, avoid merge-sorting data if there is no map-side aggregation and there are at most this many reduce partitions |
| spark.shuffle.blockTransferService | netty | 实现用来在executor直接传递shuffle和缓存块。有两种可用的实现:netty和nio。基于netty的块传递在具有相同的效率情况下更简单 |
Spark UI
| Property Name | Default | Meaning |
|---|---|---|
| spark.ui.port | 4040 | 你的应用程序dashboard的端口。显示内存和工作量数据 |
| spark.ui.retainedStages | 1000 | 在垃圾回收之前,Spark UI和状态API记住的stage数 |
| spark.ui.retainedJobs | 1000 | 在垃圾回收之前,Spark UI和状态API记住的job数 |
| spark.ui.killEnabled | true | 运行在web UI中杀死stage和相应的job |
| spark.eventLog.enabled | false | 是否记录Spark的事件日志。这在应用程序完成后,重新构造web UI是有用的 |
| spark.eventLog.compress | false | 是否压缩事件日志。需要spark.eventLog.enabled为true |
| spark.eventLog.dir | file:///tmp/spark-events | Spark事件日志记录的基本目录。在这个基本目录下,Spark为每个应用程序创建一个子目录。各个应用程序记录日志到直到的目录。用户可能想设置这为统一的地点,像HDFS一样,所以历史文件可以通过历史服务器读取 |
压缩和序列化
| Property Name | Default | Meaning |
|---|---|---|
| spark.broadcast.compress | true | 在发送广播变量之前是否压缩它 |
| spark.rdd.compress | true | 是否压缩序列化的RDD分区。在花费一些额外的CPU时间的同时节省大量的空间 |
| spark.io.compression.codec | snappy | 压缩诸如RDD分区、广播变量、shuffle输出等内部数据的编码解码器。默认情况下,Spark提供了三种选择:lz4, lzf和snappy。你也可以用完整的类名来制定。org.apache.spark.io.LZ4CompressionCodec,org.apache.spark.io.LZFCompressionCodec,org.apache.spark.io.SnappyCompressionCodec |
| spark.io.compression.snappy.block.size | 32768 | Snappy压缩中用到的块大小。降低这个块的大小也会降低shuffle内存使用率 |
| spark.io.compression.lz4.block.size | 32768 | LZ4压缩中用到的块大小。降低这个块的大小也会降低shuffle内存使用率 |
| spark.closure.serializer | org.apache.spark.serializer.JavaSerializer | 闭包用到的序列化类。目前只支持java序列化器 |
| spark.serializer.objectStreamReset | 100 | 当用org.apache.spark.serializer.JavaSerializer序列化时,序列化器通过缓存对象防止写多余的数据,然而这会造成这些对象的垃圾回收停止。通过请求'reset',你从序列化器中flush这些信息并允许收集老的数据。为了关闭这个周期性的reset,你可以将值设为-1。默认情况下,每一百个对象reset一次 |
| spark.kryo.referenceTracking | true | 当用Kryo序列化时,跟踪是否引用同一对象。如果你的对象图有环,这是必须的设置。如果他们包含相同对象的多个副本,这个设置对效率是有用的。如果你知道不在这两个场景,那么可以禁用它以提高效率 |
| spark.kryo.registrationRequired | false | 是否需要注册为Kyro可用。如果设置为true,然后如果一个没有注册的类序列化,Kyro会抛出异常。如果设置为false,Kryo将会同时写每个对象和其非注册类名。写类名可能造成显著地性能瓶颈。 |
| spark.kryoserializer.buffer.mb | 0.064 | Kyro序列化缓存的大小。这样worker上的每个核都有一个缓存。如果有需要,缓存会涨到spark.kryoserializer.buffer.max.mb设置的值那么大。 |
| spark.kryoserializer.buffer.max.mb | 64 | Kryo序列化缓存允许的最大值。这个值必须大于你尝试序列化的对象 |
Networking
| Property Name | Default | Meaning |
|---|---|---|
| spark.driver.host | (local hostname) | driver监听的主机名或者IP地址。这用于和executors以及独立的master通信 |
| spark.driver.port | (random) | driver监听的接口。这用于和executors以及独立的master通信 |
| spark.fileserver.port | (random) | driver的文件服务器监听的端口 |
| spark.broadcast.port | (random) | driver的HTTP广播服务器监听的端口 |
| spark.replClassServer.port | (random) | driver的HTTP类服务器监听的端口 |
| spark.blockManager.port | (random) | 块管理器监听的端口。这些同时存在于driver和executors |
| spark.executor.port | (random) | executor监听的端口。用于与driver通信 |
| spark.port.maxRetries | 16 | 当绑定到一个端口,在放弃前重试的最大次数 |
| spark.akka.frameSize | 10 | 在"control plane"通信中允许的最大消息大小。如果你的任务需要发送大的结果到driver中,调大这个值 |
| spark.akka.threads | 4 | 通信的actor线程数。当driver有很多CPU核时,调大它是有用的 |
| spark.akka.timeout | 100 | Spark节点之间的通信超时。单位是s |
| spark.akka.heartbeat.pauses | 6000 | This is set to a larger value to disable failure detector that comes inbuilt akka. It can be enabled again, if you plan to use this feature (Not recommended). Acceptable heart beat pause in seconds for akka. This can be used to control sensitivity to gc pauses. Tune this in combination of spark.akka.heartbeat.interval and spark.akka.failure-detector.threshold if you need to. |
| spark.akka.failure-detector.threshold | 300.0 | This is set to a larger value to disable failure detector that comes inbuilt akka. It can be enabled again, if you plan to use this feature (Not recommended). This maps to akka's akka.remote.transport-failure-detector.threshold. Tune this in combination of spark.akka.heartbeat.pauses and spark.akka.heartbeat.interval if you need to. |
| spark.akka.heartbeat.interval | 1000 | This is set to a larger value to disable failure detector that comes inbuilt akka. It can be enabled again, if you plan to use this feature (Not recommended). A larger interval value in seconds reduces network overhead and a smaller value ( ~ 1 s) might be more informative for akka's failure detector. Tune this in combination of spark.akka.heartbeat.pauses and spark.akka.failure-detector.threshold if you need to. Only positive use case for using failure detector can be, a sensistive failure detector can help evict rogue executors really quick. However this is usually not the case as gc pauses and network lags are expected in a real Spark cluster. Apart from that enabling this leads to a lot of exchanges of heart beats between nodes leading to flooding the network with those. |
Security
| Property Name | Default | Meaning |
|---|---|---|
| spark.authenticate | false | 是否Spark验证其内部连接。如果不是运行在YARN上,请看spark.authenticate.secret |
| spark.authenticate.secret | None | 设置Spark两个组件之间的密匙验证。如果不是运行在YARN上,但是需要验证,这个选项必须设置 |
| spark.core.connection.auth.wait.timeout | 30 | 连接时等待验证的实际。单位为秒 |
| spark.core.connection.ack.wait.timeout | 60 | 连接等待回答的时间。单位为秒。为了避免不希望的超时,你可以设置更大的值 |
| spark.ui.filters | None | 应用到Spark web UI的用于过滤类名的逗号分隔的列表。过滤器必须是标准的javax servlet Filter。通过设置java系统属性也可以指定每个过滤器的参数。spark.<class name="" of="" filter="">.params='param1=value1,param2=value2'。例如-Dspark.ui.filters=com.test.filter1、-Dspark.com.test.filter1.params='param1=foo,param2=testing' |
| spark.acls.enable | false | 是否开启Spark acls。如果开启了,它检查用户是否有权限去查看或修改job。 Note this requires the user to be known, so if the user comes across as null no checks are done。UI利用使用过滤器验证和设置用户 |
| spark.ui.view.acls | empty | 逗号分隔的用户列表,列表中的用户有查看(view)Spark web UI的权限。默认情况下,只有启动Spark job的用户有查看权限 |
| spark.modify.acls | empty | 逗号分隔的用户列表,列表中的用户有修改Spark job的权限。默认情况下,只有启动Spark job的用户有修改权限 |
| spark.admin.acls | empty | 逗号分隔的用户或者管理员列表,列表中的用户或管理员有查看和修改所有Spark job的权限。如果你运行在一个共享集群,有一组管理员或开发者帮助debug,这个选项有用 |
Spark Streaming
| Property Name | Default | Meaning |
|---|---|---|
| spark.streaming.blockInterval | 200 | 在这个时间间隔(ms)内,通过Spark Streaming receivers接收的数据在保存到Spark之前,chunk为数据块。推荐的最小值为50ms |
| spark.streaming.receiver.maxRate | infinite | 每秒钟每个receiver将接收的数据的最大记录数。有效的情况下,每个流将消耗至少这个数目的记录。设置这个配置为0或者-1将会不作限制 |
| spark.streaming.receiver.writeAheadLogs.enable | false | Enable write ahead logs for receivers. All the input data received through receivers will be saved to write ahead logs that will allow it to be recovered after driver failures |
| spark.streaming.unpersist | true | 强制通过Spark Streaming生成并持久化的RDD自动从Spark内存中非持久化。通过Spark Streaming接收的原始输入数据也将清除。设置这个属性为false允许流应用程序访问原始数据和持久化RDD,因为它们没有被自动清除。但是它会造成更高的内存花费 |
环境变量
通过环境变量配置确定的Spark设置。环境变量从Spark安装目录下的conf/spark-env.sh脚本读取(或者windows的conf/spark-env.cmd)。在独立的或者Mesos模式下,这个文件可以给机器 确定的信息,如主机名。当运行本地应用程序或者提交脚本时,它也起作用。
注意,当Spark安装时,conf/spark-env.sh默认是不存在的。你可以复制conf/spark-env.sh.template创建它。
可以在spark-env.sh中设置如下变量:
| Environment Variable | Meaning |
|---|---|
| JAVA_HOME | java安装的路径 |
| PYSPARK_PYTHON | PySpark用到的Python二进制执行文件路径 |
| SPARK_LOCAL_IP | 机器绑定的IP地址 |
| SPARK_PUBLIC_DNS | 你Spark应用程序通知给其他机器的主机名 |
除了以上这些,Spark standalone cluster scripts也可以设置一些选项。例如 每台机器使用的核数以及最大内存。
因为spark-env.sh是shell脚本,其中的一些可以以编程方式设置。例如,你可以通过特定的网络接口计算SPARK_LOCAL_IP。
配置Logging
Spark用log4j logging。你可以通过在conf目录下添加log4j.properties文件来配置。一种方法是复制log4j.properties.template文件。
Spark调优
由于大部分
Spark计算都是在内存中完成的,所以Spark程序的瓶颈可能由集群中任意一种资源导致,如:CPU、网络带宽、或者内存等。最常见的情况是,数据能装进内存,而瓶颈是网络带宽;当然,有时候我们也需要做一些优化调整来减少内存占用,例如将RDD以序列化格式保存。 本文将主要涵盖两个主题:1.数据序列化(这对于优化网络性能极为重要);2.减少内存占用以及内存调优。同时,我们也会提及其他几个比较小的主题。
数据序列化
序列化在任何一种分布式应用性能优化时都扮演几位重要的角色。如果序列化格式序列化过程缓慢,或者需要占用字节很多,都会大大拖慢整体的计算效率。 通常,序列化都是Spark应用优化时首先需要关注的地方。Spark着眼于便利性(允许你在计算过程中使用任何Java类型)和性能的一个平衡。Spark主要提供了两个序列化库:
Java serialization:默认情况,Spark使用Java自带的ObjectOutputStream框架来序列化对象,这样任何实现了java.io.Serializable接口的对象,都能被序列化。同时,你还可以通过扩展java.io.Externalizable来控制序列化性能。Java序列化很灵活但性能较差,同时序列化后占用的字节数也较多。Kryo serialization:Spark还可以使用Kryo库(版本2)提供更高效的序列化格式。Kryo的序列化速度和字节占用都比Java序列化好很多(通常是10倍左右),但Kryo不支持所有实现了Serializable接口的类型,它需要你在程序中register需要序列化的类型,以得到最佳性能。
要切换使用 Kryo,你可以在 SparkConf 初始化的时候调用 conf.set(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”)。这个设置不仅控制各个worker节点之间的混洗数据序列化格式,同时还控制RDD存到磁盘上的序列化格式。 目前,Kryo不是默认的序列化格式,因为它需要你在使用前注册需要序列化的类型,不过我们还是建议在对网络敏感的应用场景下使用Kryo。
Spark对一些常用的Scala核心类型,如在Twitter chill 库的AllScalaRegistrar中,自动使用Kryo序列化格式。
如果你的自定义类型需要使用Kryo序列化,可以用 registerKryoClasses 方法先注册:
scala
val conf = new SparkConf().setMaster(...).setAppName(...) conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2])) val sc = new SparkContext(conf)
Kryo的文档中有详细描述了更多的高级选项,如:自定义序列化代码等。
如果你的对象很大,你可能需要增大 spark.kryoserializer.buffer 配置项。其值至少需要大于最大对象的序列化长度。
最后,如果你不注册需要序列化的自定义类型,Kryo也能工作,不过每一个对象实例的序列化结果都会包含一份完整的类名,这有点浪费空间。
内存调优
内存占用调优主要需要考虑3点:数据占用的总内存(你会希望整个数据集都能装进内存);访问数据集中每个对象的开销;垃圾回收的开销(如果你的数据集中对象周转速度很快的话)。
一般情况下,Java对象的访问时很快的,但同时Java对象会比原始数据(仅包含各个字段值)占用的空间多2~5倍。主要原因有:
- 每个
Java对象都有一个对象头(object header),对象头大约占用16字节,其中包含像其对应class的指针这样的信息。对于一些包含较少数据的对象(比如只包含一个Int字段),这个对象头可能比对象数据本身还大。 Java字符串(String)有大约40字节额外开销(Java String以Char数据的形式保存原始数据,所以需要一些额外的字段,如数组长度等),并且每个字符都以两字节的UTF-16编码在内部保存。因此,10个字符的String很容易就占了60字节。- 一些常见的集合类,如
HashMap、LinkedList,使用的是链表类数据结构,因此它们对每项数据都有一个包装器。这些包装器对象不仅其自身就有“对象头”,同时还有指向下一个包装器对象的链表指针(通常为8字节)。 - 原始类型的集合通常也是以“装箱”的形式包装成对象(如:
java.lang.Integer)。
本节只是Spark内存管理的一个概要,下面我们会更详细地讨论各种Spark内存调优的具体策略。特别地,我们会讨论如何评估数据的内存使用量,以及如何改进 – 要么改变你的数据结构,要么以某种序列化格式存储数据。 最后,我们还会讨论如何调整Spark的缓存大小,以及如何调优Java的垃圾回收器。
内存管理概览
Spark中内存主要用于两类目的:执行计算和数据存储。执行计算的内存主要用于Shuffle、关联(join)、排序(sort)以及聚合(aggregation),而数据存储的内存主要用于缓存和集群内部数据传播。Spark中执行计算和数据存储都是共享同一个内存区域(M)。 如果执行计算没有占用内存,那么数据存储可以申请占用所有可用的内存,反之亦然。执行计算可能会抢占数据存储使用的内存,并将存储于内存的数据逐出内存,直到数据存储占用的内存比例降低到一个指定的比例(R)。 换句话说,R是M基础上的一个子区域,这个区域的内存数据永远不会被逐出内存。然而,数据存储不会抢占执行计算的内存。
这样设计主要有这么几个需要考虑的点。首先,不需要缓存数据的应用可以把整个空间用来执行计算,从而避免频繁地把数据吐到磁盘上。其次,需要缓存数据的应用能够有一个数据存储比例(R)的最低保证,也避免这部分缓存数据被全部逐出内存。最后,这个实现方式能够在默认情况下,为大多数使用场景提供合理的性能,而不需要专家级用户来设置内存使用如何划分。
虽然有两个内存划分相关的配置参数,但一般来说,用户不需要设置,因为默认值已经能够适用于绝大部分的使用场景:
spark.memory.fraction:表示上面M的大小,其值为相对于JVM堆内存的比例(默认0.75)。剩余的25%是为其他用户的数据结构、Spark内部元数据以及避免OOM错误的安全预留空间。spark.memory.storageFraction:表示上面R的大小,其值为相对于M的一个比例(默认0.5)。R是M中专门用于缓存数据块的部分,这部分数据块永远不会因执行计算任务而逐出内存。
评估内存消耗
确定一个数据集占用内存总量最好的办法就是,创建一个RDD,并缓存到内存中,然后再到web UI上”Storage”页面查看。页面上会展示这个RDD总共占用了多少内存。
要评估一个特定对象的内存占用量,可以用 SizeEstimator.estimate 方法。这个方法对试验哪种数据结构能够裁剪内存占用量比较有用,同时,也可以帮助用户了解广播变量在每个执行器堆上占用的内存量。
数据结构调优
减少内存消耗的首要方法就是避免过多的Java封装(减少对象头和额外辅助字段),比如基于指针的数据结构和包装对象等。以下有几条建议:
- 设计数据结构的时候,优先使用对象数组和原生类型,减少对复杂集合类型(如:
HashMap)的使用。fastutil提供了一些很方便的原生类型集合,同时兼容Java标准库。 - 尽可能避免嵌套大量的小对象和指针。
- 对应键值应尽量使用数值型或枚举型,而不是字符串型。
- 如果内存小于
32GB,可以设置JVM标志参数-XX:+UseCompressdOops将指针设为4字节而不是8字节。你可以在spark-env.sh中设置这个参数。
序列化RDD存储
如果经过上面的调整后,存储的数据对象还是太大,那么你可以试试将这些对象以序列化格式存储,所需要做的只是通过 RDD persistence API 设置好存储级别,如:MEMORY_ONLY_SER。Spark会将RDD的每个分区以一个巨大的字节数组形式存储起来。以序列化格式存储的唯一缺点就是访问数据会变慢一点,因为Spark需要反序列化每个被访问的对象。 如果你需要序列化缓存数据,我们强烈建议你使用Kryo,和Java序列化相比,Kryo能大大减少序列化对象占用的空间(当然也比原始Java对象小很多)。
垃圾回收调优
JVM的垃圾回收在某些情况下可能会造成瓶颈,比如,你的RDD存储经常需要“换入换出”(新RDD抢占了老RDD内存,不过如果你的程序没有这种情况的话那JVM垃圾回收一般不是问题,比如,你的RDD只是载入一次,后续只是在这一个RDD上做操作)。当Java需要把老对象逐出内存的时候,JVM需要跟踪所有的Java对象,并找出哪些对象已经没有用了。 概括起来就是,垃圾回收的开销和对象个数成正比,所以减少对象的个数(比如用Int数组取代LinkedList),就能大大减少垃圾回收的开销。 当然,一个更好的方法就如前面所说的,以序列化形式存储数据,这时每个RDD分区都只包含有一个对象了(一个巨大的字节数组)。在尝试其他技术方案前,首先可以试试用序列化RDD的方式(serialized caching)评估一下GC是不是一个瓶颈。
如果你的作业中各个任务需要的工作内存和节点上存储的RDD缓存占用的内存产生冲突,那么GC很可能会出现问题。下面我们将讨论一下如何控制好RDD缓存使用的内存空间,以减少这种冲突。
衡量GC的影响
GC调优的第一步是统计一下,垃圾回收启动的频率以及GC所使用的总时间。给JVM设置一下这几个参数(参考Spark配置指南,查看Spark作业中的Java选项参数):-verbose:gc -XX:+PrintGCDetails,就可以在后续Spark作业的worker日志中看到每次GC花费的时间。 注意,这些日志是在集群worker节点上(在各节点的工作目录下stdout文件中),而不是你的驱动器所在节点。
高级GC调优
为了进一步调优GC,我们就需要对JVM内存管理有一个基本的了解:
Java堆内存可分配的空间有两个区域:新生代(Young generation)和老年代(Old generation)。新生代用以保存生存周期短的对象,而老年代则是保存生存周期长的对象。- 新生代区域被进一步划分为三个子区域:
Eden,Survivor1,Survivor2。 - 简要描述一下垃圾回收的过程:如果
Eden区满了,则启动一轮minor GC回收Eden中的对象,生存下来(没有被回收掉)的Eden中的对象和Survivor1区中的对象一并复制到Survivor2中。 两个Survivor区域是互相切换使用的(就是说,下次从Eden和Survivor2中复制到Survivor1中)。如果某个对象的年龄(每次GC所有生存下来的对象长一岁)超过某个阈值,或者Survivor2(下次是Survivor1)区域满了,则将对象移到老年代(Old区)。最终如果老生代也满了,就会启动full GC。
Spark GC调优的目标就是确保老年代(Old generation )只保存长生命周期RDD,而同时新生代(Young generation)的空间又能足够保存短生命周期的对象。这样就能在任务执行期间,避免启动full GC。以下是GC调优的主要步骤:
- 从
GC的统计日志中观察GC是否启动太多。如果某个任务结束前,多次启动了full GC,则意味着用以执行该任务的内存不够。 - 如果
GC统计信息中显示,老生代内存空间已经接近存满,可以通过降低spark.memory.storageFraction来减少RDD缓存占用的内存;减少缓存对象总比任务执行缓慢要强! - 如果
major GC比较少,但minor GC很多的话,可以多分配一些Eden内存。你可以把Eden的大小设为高于各个任务执行所需的工作内存。如果要把Eden大小设为E,则可以这样设置新生代区域大小:-Xmn=4/3*E。(放大4/3倍,主要是为了给Survivor区域保留空间) - 举例来说,如果你的任务会从HDFS上读取数据,那么单个任务的内存需求可以用其所读取的
HDFS数据块的大小来评估。需要特别注意的是,解压后的HDFS块是解压前的2~3倍。所以如果我们希望保留3~4个任务并行的工作内存,并且HDFS块大小为64MB,那么可以评估Eden的大小应该设为4*3*64MB。 - 最后,再观察一下垃圾回收的启动频率和总耗时有没有什么变化。
我们的很多经验表明,GC调优的效果和你的程序代码以及可用的总内存相关。网上还有不少调优的选择,但总体来说,就是控制好full GC的启动频率,就能有效减少垃圾回收开销。
其他事项
并行度
一般来说集群并不会满负荷运转,除非你把每个操作的并行度都设得足够大。Spark会自动根据对应的输入文件大小来设置“map”类算子的并行度(当然你可以通过一个SparkContext.textFile等函数的可选参数来控制并行度),而对于想 groupByKey 或reduceByKey这类 “reduce” 算子,会使用其各父RDD分区数的最大值。你可以将并行度作为构建RDD第二个参数(参考spark.PairRDDFunctions),或者设置 spark.default.parallelism 这个默认值。一般来说,评估并行度的时候,我们建议2~3个任务共享一个CPU。
Reduce任务的内存占用
如果RDD比内存要大,有时候你可能收到一个OutOfMemoryError错误,其实这是因为你的任务集中的某个任务太大了,如reduce任务groupByKey。Spark的Shuffle算子(sortByKey,groupByKey,reduceByKey,join等)会在每个任务中构建一个哈希表,以便在任务中对数据分组,这个哈希表有时会很大。最简单的修复办法就是增大并行度,以减小单个任务的输入集。Spark对于200ms以内的短任务支持非常好,因为Spark可以跨任务复用执行器JVM,任务的启动开销很小,因此把并行度增加到比集群中总CPU核数没有任何问题。
广播大变量
使用SparkContext中的广播变量相关功能(broadcast functionality)能大大减少每个任务本身序列化的大小,以及集群中启动作业的开销。如果你的Spark任务正在使用驱动程序中定义的巨大对象(比如:静态查询表),请考虑使用广播变量替代。Spark会在master上将各个任务的序列化后大小打印出来,所以你可以检查一下各个任务是否过大;通常来说,大于20KB的任务就值得优化一下。
数据本地性
数据本地性对Spark作业往往会有较大的影响。如果代码和其所操作的数据在同一节点上,那么计算速度肯定会更快一些。但如果二者不在一起,那必然需要移动其中之一。一般来说,移动序列化好的代码肯定比挪动一大堆数据要快。Spark就是基于这个一般性原则来构建数据本地性的调度。
数据本地性是指代码和其所处理的数据的距离。基于数据当前的位置,数据本地性可以划分成以下几个层次(按从近到远排序):
PROCESS_LOCAL数据和运行的代码处于同一个JVM进程内。NODE_LOCAL数据和代码处于同一节点。例如,数据处于HDFS上某个节点,而对应的执行器(executor)也在同一个机器节点上。这会比PROCESS_LOCAL稍微慢一些,因为数据需要跨进程传递。NO_PREF数据在任何地方处理都一样,没有本地性偏好。RACK_LOCAL数据和代码处于同一个机架上的不同机器。这时,数据和代码处于不同机器上,需要通过网络传递,但还是在同一个机架上,一般也就通过一个交换机传输即可。ANY数据在网络中未知,即数据和代码不在同一个机架上。
Spark倾向于让所有任务都具有最佳的数据本地性,但这并非总是可行的。某些情况下,可能会出现一些空闲的执行器(executor)没有待处理的数据,那么Spark可能就会牺牲一些数据本地性。有两种可能的选项:a)等待已经有任务的CPU,待其释放后立即在同一台机器上启动一个任务;b)立即在其他节点上启动新任务,并把所需要的数据复制过去。
通常,Spark会等待一会,看看是否有CPU会被释放出来。一旦等待超时,则立即在其他节点上启动并将所需的数据复制过去。数据本地性各个级别之间的回落超时可以单独配置,也可以在统一参数内一起设定;详细请参考 configuration page中的 spark.locality 相关参数。如果你的任务执行时间比较长并且数据本地性很差,你就应该试试调大这几个参数,不过默认值一般都能适用于大多数场景了。

