
- 1springboot项目日志通过logback+logstash同步到ES_logstash springboot
- 2Elasticsearch 高频面试题(含答案)(1),面试心慌怎么办_es 面试题
- 3智能车学习(2)---舵机学习
- 4学习日志【Gitee/Github账户创建与开源仓库的使用】_github desktop 登陆gitee账号
- 5编码如画,以梦驭马——CodeWave低代码平台全侧写
- 6Recursive function_已知f为单链表的表头指针, 链表中存储的都是整型数据,试写出实现下列运算的递归算
- 7RKNNToolkit2 推理数据输入问题_csdn knmmc
- 8 引入创新:H-GCN—为图卷积网络赋能的高效解决方案
- 9Mysql疑难报错排查 - Field ‘XXX‘ doesn‘t have a default value_mysql 8 doesn't have a default value
- 10在AndroidStudio创建Flutter项目并运行到模拟器_android studio创建flutter项目
Hive 的并行执行和优化器_hive 并行执行
赞
踩
一、并行执行
Hive 是建立在 Hadoop 之上的一个数据仓库工具,它使用了 MapReduce 框架进行数据处理。Hive 的并行执行是指在执行查询时,将查询分成多个任务并行执行,以提高查询的执行效率。
1.1 原理解说
Hive 的并行执行是通过以下几个步骤实现的:
1.查询解析:Hive 接收到用户的查询请求后,首先对查询进行解析,将查询语句解析成抽象语法树(AST)。AST 是一个树状结构,表示查询的语法结构。
2.查询优化:Hive 使用优化器对查询进行优化,包括但不限于以下几个方面:
- 列裁剪:Hive 通过分析查询中使用的列,只选择需要的列进行处理,减少数据的读取和传输量。
- 谓词下推:Hive 将过滤条件下推到数据源,减少数据的读取和传输量。
- 表连接优化:Hive 根据表的大小和连接条件选择最优的连接方式,减少数据的读取和传输量。
- 聚合推导:Hive 在查询中发现了聚合操作,并且聚合的列是有序的,可以通过部分聚合推导出最终的聚合结果,减少数据的读取和传输量。
3.任务划分:优化后的查询被划分成多个任务,每个任务处理一部分数据。任务划分的原则是将数据划分成相等大小的块,使得每个任务的负载尽量均衡。
4.并行执行:划分好的任务被提交到集群中的多个节点上并行执行,每个节点上的任务读取和处理自己负责的数据块。
5.结果合并:各个节点上任务执行完成后,将结果合并成一个最终的结果。
1.2 参数介绍
在 Hive 中,可以通过以下几个参数来控制并行执行的行为:
- hive.exec.parallel:用于开启或关闭并行执行,默认值为 true。设置为 true 时,启用并行执行;设置为 false 时,禁用并行执行。
- hive.exec.parallel.thread.number:用于指定并行执行的线程数,默认值为 8。该参数决定了同时执行的任务数,可以根据集群的硬件资源情况进行调整。
- hive.exec.parallel.thread.queue.size:用于指定并行执行的线程队列大小,默认值为 0。当并行执行线程数达到上限时,新的任务会被放入队列中等待执行。
1.3 完整代码案例
以下是一个示例代码,演示如何在 Hive 中开启并行执行:
| -- 开启并行执行 SET hive.exec.parallel=true; -- 设置并行执行的线程数 SET hive.exec.parallel.thread.number=16; -- 设置并行执行的线程队列大小 SET hive.exec.parallel.thread.queue.size=100; -- 创建表 CREATE TABLE employee ( id INT, name STRING, age INT, salary DOUBLE ); -- 插入数据 INSERT INTO TABLE employee VALUES (1, 'Alice', 25, 5000.0); INSERT INTO TABLE employee VALUES (2, 'Bob', 30, 6000.0); INSERT INTO TABLE employee VALUES (3, 'Charlie', 35, 7000.0); INSERT INTO TABLE employee VALUES (4, 'David', 40, 8000.0); -- 查询数据 SELECT * FROM employee; |
在上述代码中,通过设置 hive.exec.parallel=true 开启并行执行,设置 hive.exec.parallel.thread.number=16 和 hive.exec.parallel.thread.queue.size=100 分别指定并行执行的线程数和线程队列大小。
二、优化器
Hive 的优化器是指在查询执行之前对查询进行优化,以提高查询的执行效率。优化器通过重新组织查询计划、选择最佳的执行计划等方式来优化查询的执行过程。
2.1 原理解说
Hive 的优化器主要包括以下几个方面的优化:
- 列裁剪:Hive 通过分析查询中使用的列,只选择需要的列进行处理,减少数据的读取和传输量。
- 谓词下推:Hive 将过滤条件下推到数据源,减少数据的读取和传输量。
- 表连接优化:Hive 根据表的大小和连接条件选择最优的连接方式,减少数据的读取和传输量。
- 聚合推导:Hive 在查询中发现了聚合操作,并且聚合的列是有序的,可以通过部分聚合推导出最终的聚合结果,减少数据的读取和传输量。
2.2 参数介绍
在 Hive 中,可以通过以下几个参数来控制优化器的行为:
- hive.optimize.collapse.proj:用于控制是否折叠投影操作,默认值为 true。当该参数设置为 true 时,优化器会尽量将多个投影操作合并为一个投影操作,减少数据的读取和传输量。
- hive.optimize.reducededuplication:用于控制是否开启冗余数据删除优化,默认值为 true。当该参数设置为 true 时,优化器会尽量删除查询中的冗余数据,减少数据的读取和传输量。
- hive.optimize.index.filter:用于控制是否使用索引进行过滤,默认值为 true。当该参数设置为 true 时,优化器会尝试使用索引进行查询优化,减少数据的读取和传输量。
2.3 完整代码案例
以下是一个示例代码,演示如何在 Hive 中使用优化器进行查询优化:
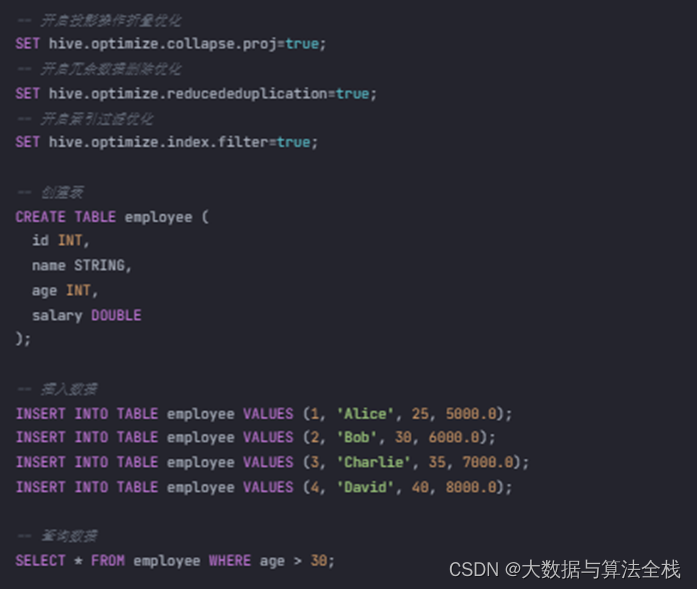
| -- 开启投影操作折叠优化 SET hive.optimize.collapse.proj=true; -- 开启冗余数据删除优化 SET hive.optimize.reducededuplication=true; -- 开启索引过滤优化 SET hive.optimize.index.filter=true; -- 创建表 CREATE TABLE employee ( id INT, name STRING, age INT, salary DOUBLE ); -- 插入数据 INSERT INTO TABLE employee VALUES (1, 'Alice', 25, 5000.0); INSERT INTO TABLE employee VALUES (2, 'Bob', 30, 6000.0); INSERT INTO TABLE employee VALUES (3, 'Charlie', 35, 7000.0); INSERT INTO TABLE employee VALUES (4, 'David', 40, 8000.0); -- 查询数据 SELECT * FROM employee WHERE age > 30; |
三、总结
在上述代码中,通过设置 hive.optimize.collapse.proj=true 开启投影操作折叠优化,设置 hive.optimize.reducededuplication=true 开启冗余数据删除优化,设置 hive.optimize.index.filter=true 开启索引过滤优化。
以上就是 Hive 的并行执行和优化器章节的详细介绍。并行执行通过将查询分成多个任务并行执行,提高查询的执行效率;优化器通过重新组织查询计划、选择最佳的执行计划等方式来优化查询的执行过程。通过合理设置参数,可以进一步提高 Hive 查询的性能。

