
- 1奖金711万!这位“山东宝妈”破解美国运算100万年才可能解开的密码!
- 2Unity Sprite Packer 问题集合_sprites can not be generated from textures with np
- 3程序员该如何确定任务(项目)的排期?_计算机做一个项目具体的排期该怎么样
- 4【初阶数据结构篇】顺序表的实现(赋源码)
- 5exe打包工具,封装exe安装程序--Inno Setup_磁盘跨越必须启用
- 6基于SpringBoot+Vue的游戏分享网站(带1w+文档)
- 730岁还在技术路上前进,软件测试是不是被严重低估了?
- 8C++11 auto关键字详解
- 9支持图片识别语音输入的LobeChat保姆级本地部署流程
- 10【JS逆向补环境】最新mtgsig参数分析与算法还原
Text2SQL
赞
踩
Text to SQL( 以下简称Text2SQL),是将自然语言文本(Text)转换成结构化查询语言SQL的过程,属于自然语言处理-语义分析(Semantic Parsing)领域中的子任务。
它的目的可以简单概括为:“打破人与结构化数据之间的壁垒”,即普通用户可以通过自然语言描述完成复杂数据库的查询工作,得到想要的结果。
Text2SQL 简单示例 (Demo)
示例
表_1-1
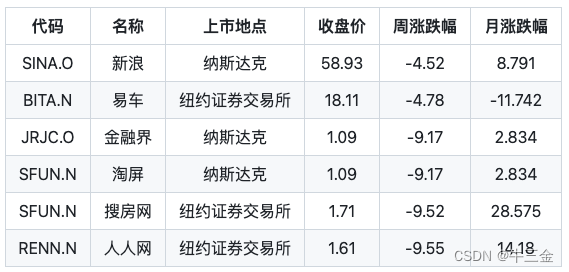
Query:新浪和人人网的周涨跌幅分别是多少?
SQL: SELECT 周涨跌幅 FROM 表_1-1 WHERE 名称=‘新浪’ OR 名称=‘人人网’
用户输入一句普通文本,模型将其转换为 SQL,查询数据库得到结果:"-4.52, -9.55"
当然实际场景或业务中,需要查询的内容可能更加复杂(例如涉及跨表、嵌套查询,group by/having 等查询条件等)。
SQL组成
SQL组成来自三部分:数据库中元素(表名、列名)、问题中的词汇、 SQL关键字
已有数据集 (Datasets)
现有Text2SQL数据集List:
1.WikiSQL
WikiSQL 标注数据集 适合入门数据集
1.WikiSQL
WikiSQL 标注数据集 适合入门数据集
- WikiSQL是一个大型的语义解析数据集,由80,654个自然语句表述和24,241张表格的sql标注构成。
- WikiSQL中每一个问句的查询范围仅限于同一张表,不包含排序、分组、子查询等复杂操作。
- 虽然数据规模大,SQL语法却非常简单;适合做NL2SQL任务入门。
2.Spider
Spider 难度最大数据集
- 耶鲁大学在2018年新提出的一个大规模的NL2SQL(Text-to-SQL)数据集。
- 该数据集包含了10,181条自然语言问句、分布在200个独立数据库中的5,693条SQL,内容覆盖了138个不同的领域。
- 涉及的SQL语法最全面,是目前难度最大的NL2SQL数据集。
3.CSpider
Cspider 中文Spider
- CSpider是Spider的中文版,西湖大学出品。对该任务感兴趣的同学可以尝试去链接中对应的榜单刷榜,目前只有2个team提交。
- 美中不足的是,数据集只是翻译了Spider的question部分,表格列名等仍是英文,需要额外处理对齐。
- 数据集已完整打包在data目录下。
4.WikitableQuestion
3.WikitableQuestion 表格问答
- WikitableQuestion是斯坦福自然语言处理小组的工作。数据集中每个问题都带有来自Wikipedia的表格。给定问题和表格,任务是根据表格回答问题。
- 数据集包含来自各种主题的2,108个表和具有不同复杂性的22,033个问题
5.天池NL2SQL中文挑战赛数据集
NL2SQL天池大赛 中文NL2SQL数据集
- 2020年之前公开的Text2SQL数据集中唯一一份高质量的中文数据集,由比赛主办方追一科技提供。数据集使用金融以及通用领域的表格数据作为数据源,提供在此基础上人工标注的自然语言和SQL语句的匹配对。
- 一共包含49,867条有标注的训练集数据,10,000条无标注数据作为测试集
6.DuSQL中文数据集
2020语言与智能技术竞赛:语义解析任务 难度接近Spider的中文数据集
- 2020语言与智能技术竞速提供的大规模开放领域的复杂中文Text-to-SQL数据集,语法覆盖了 "order by","group by","having","嵌套SQL","join" 等几乎所有SQL语法。
- 包含18602训练集,2039开发集和4868测试集
7.Sparc
Sparc 多轮交互Text2SQL
- 耶鲁大学在2019年提出的基于对话的Text-to-SQL数据集。
- SParC是一个跨域上下文语义分析的数据集,是Spider任务的上下文交互版本。SParC由4298个对话(12k+个单独的问题,每个对话平均4-5个子问题,由14个耶鲁学生标注)组成,这些问题通过用户与138个领域的200个复杂数据库进行交互获得。
8.CoSQL
CoSQL 多轮交互Text2SQL
- 耶鲁大学在2019年提出的基于对话的Text-to-SQL数据集。
- 内容和Sparc相似,但是标注风格略有不同,例如数据集中SQL各关键字的分布差异较大。
9.CHASE
CHASE 多轮交互中文Text2SQL (ACL 2021)
- 2021年,微软亚研院和北航、西安交大联合提出的首个大规模上下文依赖的Text-to-SQL中文数据集。
- 内容分为CHASE-C和CHASE-T两部分,CHASE-C从头标注实现,CHASE-T将Sparc从英文翻译为中;相比以往数据集,CHASE大幅增加了hard类型的数据规模,减少了上下文独立样本的数据量,弥补了Text2SQL多轮交互任务中文数据集的空白。
持续更新中....
比赛排名 (Rank)
截止2020年10月19号,我们实验室(浙江大学DCD实验室)所在的语义解析小组获得了Spider排行榜top2的成绩。

解决方案 (Solutions)
1.Spider榜单开源模型
(1)EditSQL:关注跨域上下文依赖的文本到sql生成任务
(3)RAT-SQL:基于关系Attention和抽象语法树的端到端SQL生成模型
(4)BRIDGE:跨域文本到SQL语义解析的文本-表格数据连接模型
(6)Graphix-T5:Spider SOTA 解决方案
2.NL2SQL中文挑战赛方案
(1)基于Bert的NL2SQL模型:一个简明的Baseline
追一科技苏剑林同学分享的baseline,强烈推荐还不熟悉nl2sql任务的同学阅读!
博客比较详细的介绍了数据集、baseline通用模型方案和trick
Tips: 因为版权问题,NL2SQL中文挑战赛数据集已经停止对外公开。有需要的同学可以联系我或者比赛主办方索要竞赛数据!
3.基于NL和SQL的预训练语言模型
(1)TaBERT:联合理解文本和表格数据的预训练
(2)GRAPPA:用于表格语义解析的语法增强的预训练
落地应用 (Applications)
“在创业阶段,比技术更重要的是寻找落地场景。”——何帆《变量》
一项技术无论新旧,无论多么酷炫,如果不能落地转变为产品,总是有很大的缺失。
针对Text2SQL,可能的落地应用:
-
数据库查询系统
不用学习SQL,直接通过自然表达与数据库交互,得到想要结果。例如企业数据库报表查询
-
问答系统/问答机器人
真实应用案例:浙江xxx公安局破案机器人项目(接触的实习项目)
具体demo可以查看下方图片。其中
question表示自然语言问句,sql_str表示模型预测、拼接的sql语句,sql_json是json格式的sql语句,方便和下游任务对齐。
-
内容编码

参考论文 (Paper)
- 1.《Editing-Based SQL Query Generation for Cross-Domain Context-Dependent Questions》
- EditSQL 模型
-
- 2.《Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation》
- IRNet 模型,Spider 数据集目前已经开源的 SOTA 模型
-
- 3.《X-SQL: reinforce schema representation with context》
- X-SQL 模型
-
- 4.《Memory Augmented Policy Optimization for Program Synthesis and Semantic Parsing》
- MAPO:用于程序综合和语义分析的内存增强策略优化
-
- 5.《SEQ2SQL- GENERATING STRUCTURED QUERIES FROM NATURAL LANGUAGE USING REINFORCEMENT LEARNING》
- WikiSQL 数据集和任务介绍
-
- 6.《RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers》
- Spider Top1 方案模型,基于关系型Attention的模型RAT-SQL
-
- 7.《GRAPPA: Grammar-Augmented Pre-Training for Table Semantic Parsing》
- 用于表格语义解析的语法增强的预训练
-
- 8.《TABERT: Pretraining for Joint Understanding of Textual and Tabular Data》
- 联合理解文本和表格数据的预训练
-
- 9.《Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing》
- 跨域文本到SQL语义解析的文本-表格数据连接模型
-
- 10.《LGESQL- Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations》
- 提出一个基于Line Graph的Text2SQL模型,用于挖掘数据底层的关系特征(曾经的Spider榜单SOTA)
-
- 11. 《CHASE: A Large-Scale and Pragmatic Chinese Dataset for Cross-Database Context-Dependent Text-to-SQL》
- CHASE 数据集论文,并测试对比了 RAT-SQL、IGSQL、EditSQL 三种模型(最好的模型效果目前只有43.7%)
-
- 12. 《Graphix-T5: Mixing Pre-Trained Transformers with Graph-Aware Layers for Text-to-SQL Parsing》
- 提出了将预训练Transformer和图感知网络共同用于Text2SQL任务的 Graphix-T5 模型,也是当前Spider榜单的SOTA模型
详见 paper 目录
参考资料 (References)
2.首届中文NL2SQL挑战赛冠军比赛攻略_不上90不改名字(pdf)
3.百度NLP:语义解析 (Text-to-SQL) 技术研究及应用
4.”想知道你家爱豆最近的演唱会?"让Text2SQL模型自动帮你回答! (A Survey)
5.万万没想到,BERT学会写SQL了 (BRIDGE顶会论文解读)

