
- 1C# message简单实现窗口间信息接收与发送_c# wm_user 消息为空
- 2【数据结构】数据结构初识
- 3微信小程序授权登录三种实现方式
- 4微信小程序入门05-用户登录注册接口开发_微信小程序实现注册登录到数据库
- 5Python pywinauto+lackey实现自动安装软件_lackey python
- 6Docker容器的可视化管理工具—DockerUI本地部署与远程访问
- 7[翻译] Unity 开发自学路线_unity 学习路线
- 8关于“Python”的核心知识点整理大全45
- 9使用cdn提高Github Pages的访问速度_github cdn
- 10解决Microsoft Visual C++ 14.0 or greater is required. Get it with “Microsoft C++ Build Tools“_error: microsoft visual c++ 14.0 or greater is req
VIT 三部曲 -1 Transformer_transformer[1]-vit
赞
踩
赵zhijian:VIT 三部曲 - 2 Vision-Transformer
赵zhijian:VIT 三部曲 - 3 vit-pytorch
目前在代表分类领域最高权威的imagenet 图片分类竞赛中, CNN的榜首位置收到了来自self attention 类的算法的的挑战,在最新的榜单上, VIT-H/14 以 88.55% Top-1 的准确率成功登顶第一的宝座,成功打败了由nas 出来的efficientNet 系列的模型,也成功打破了基于卷积和pooling 主导的网络在分类任务上面的垄断.
个人认为,这是一个具有一定跨时代意义的事件, 标志着self attention 类的网络结构也可以很好的完成由CNN 主导的分类的任务,VIT 究竟是什么网络? 它来自于哪里,具体由什么惊艳之处,为何可以在imageNet 任务上取得这么好的成绩, 下面我们就分三块来分析一下. 今天讲第一部分就是VIT的最开始的模型叫做 Transformer
Attention is all you Need -- Transformer
https://arxiv.org/pdf/1706.03762.pdf
Transformer 是一种google Brain 在2017 年nips 上面提出的一种基于self attention的用于进行NLP 任务的基础模型框架. 框架主体采用传统的 sequence to sequence 框架, 由encoder decoder 两部分组成.在transformer框架提出之前,其实已经有各种各样基于attention 机制的模型用于传统的NLP 任务,但是之前的 sequence to sequence 框架多数利用RNN LSTM 等循环网络框架来做将输入的词向量等语义的描述特征转换为 hidden state 的工作, 由于输入的 sequence 是长度不一致,因此如何捕获长时(long-term) 的语义信息就是整个encoder 模型最为困难的一点. 而且由于循环神经网络(RNN) 的计算特点导致,之前的状态会影响到后面的结果,因此虽然模型不大,但是模型推理的并行化水平比较低,无法做到很低的有延时. 正是基于这几个问题 transformer 框架摒弃了常用的RNN 结构,引入了全新的Transformer 结构来对于 sequence to sequence 进行建模.

Transformer
整个 Transformer 由一下几个部件组成: multi-head attention, position encoding, feed forward, Input/output embeding 和 add && Norm layers,下面我们就一个一个来对于这些组件进行剖析:
-
multi-head attention:
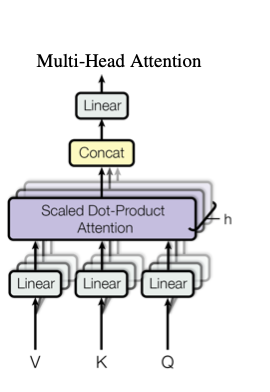

该模块是整个Transformer 框架的核心模块,该模块包括了三个用于处理 Input 的 linear layers , h (在实际模型中 h =6) 个 scale dot-product attention 和 一个由concat和linear 组成的后处理的模块组成. 这个模块是整个self attention模块的核心,基本思想是把原始的特征通过三个fc 映射成V, K,Q 通过计算V,K 的相似度对于Q 进行加权, 实际在使用中,就是通过输入的三个linear 层来控制最终的输出结果. 有了这样的一个结构, 整个算法的attention 过程就完全可以有自身的feature 决定,不用依赖于输入的前后信息,因此这样的一个结构就是一个基本的self attention 结构
-
add && Norm:
这部分结构借鉴了CNN著名的ResNet 的残差结构,将原始的特征和经过attention的特征进行加和,保留了原有的信息,方便模型收敛,通过通过layernorm 又巧妙的将attention 后的特征加入了新的特征中,构成了一个新的特征,这个部分放在multi-head attention: 前后可以最大限度的保障模型的收敛和使用上学习到self attention特征.
-
feed forward:
feed forward 在NLP 中一般很简单就是两个linear 层,中间加上一个RELU的激活. 公式如下:
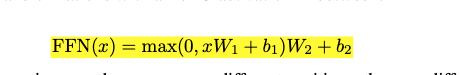
Feed forward
-
input/output embeding:
类似NLP 中的word2vec 的概念,就是一般会把一个one hot 的 Input (文中称为token) 通过一个线性投影 转换成一个向量来表示,这个在模型中就是一个linear 的层
-
position encoding && scale dot-product attention 中的mask
这个两个是 训练时候在模型中加入的类似小tricks 的东西.
position encoding是由于整个模型的设计中所有的input 都是统一对待的,而在NLP的任务中,所有的输入的顺序是很关键的,一句话如果字的顺序发生颠倒,可能会变成完全另一个意思,因此,加入一个了position encoding 的特征来表示这个input (文中用token 表示) 是输入的顺序信息.
scale dot-product attention 中的mask 则是为了防止在实时翻译任务中, 输出利用到尚未当前时刻之后的输入的信息,在全量的input上面加上一个mask 这样就可以防止模型未卜先知利用到当前时刻后的输入的信息,防止实时NLP中任务中实际无法得到这些信息造成的问题.
具体的实现中,position encoding作者试用了两种不同类型的方案,一种是直接根据计算公式得到每个位置固定的值,具体的公式如下:

position encoding
还有一种方案是作为一个变量在忙模型训练的时候可以自己学习, 固定的方案的好处是可以以任意长度作为输入, 学习的优点就是理论上可以学习到更好的位置描述,实际使用中作者采用的是固定的值,而且作者做了一个对比实验,发现两种方案其实实际的差别不大
总结一下, Transformer 为NLP 任务提供了一种新的模型框架, 框架摒弃了原有的循环网络的形式,通过引入self attention的形式解决了原有循环神经网络前后的依赖等问题,提高了框架的并行能力,设计中还借鉴了resnet 的残差结构,可以最大限度的保留原始特征的信息结合上attention 机制可以最大限度的提取到有用的信息进行NLP 等任务.
下一篇文章将继续介绍,VIT 如何借鉴Transformer 结构来解决图片分类的问题. 敬请期待

