
- 1Mysql5.7出现的服务无法启动问题_failed to start process for mysql server 5.7.44. d
- 2px4原生源码学习二--实时操作系统篇
- 3AI绘画Stable Diffusion画全身图总是人脸扭曲?ADetailer插件实现一键解决!_stable-diffusion 脸变形
- 4Django连接mysql及orm操作_django连接数据库mysql
- 5win10退出登录微软账号,亲测有效可以成功(解决没有改用本地账户;解决没有删除选项)_win10没有改用本地账户登录
- 6ajax post请求参数过长导致后台接受参数为null解决,jboss-4.2.3版本修改配置_ajax传参数到后端字符串过长最后变为三个点
- 7什么是大数据分析?定义、优点和类型
- 8Ubuntu 20.04 prometheus prometheus-process-exporter_ubuntu卸载promethues
- 9ONLYOFFICE:一个免费、开源、跨平台的办公神器_onlyoffice 免费商用
- 10php 对称加密-lzn
MiniGPT4-Video_minigpt4 video数据集
赞
踩
秒懂视频的AI诞生了!KAUST和哈佛大学研究团队提出MiniGPT4-Video框架,不仅能理解复杂视频,甚至还能作诗配文。
几天前,OpenAI官方账号发布了第一支由Sora制作的MV——Worldweight,引全网围观。
AI视频,已然成为多模态LLM发展的大趋势。
然而,除了视频生成,让LLM对复杂视频进行理解,也至关重要。
最近,来自KAUST和哈佛大学的研究人员提出了MiniGPT4-Video——专为视频理解而设计的多模态大模型。
论文地址:https://arxiv.org/pdf/2404.03413.pdf
值得一提的是,MiniGPT4-Video能够同时处理时态视觉数据和文本数据,因此善于理解视频的复杂性。
比如,上传一个宝格丽的首饰宣传视频。

MiniGPT4-Video能够为其配出标题,宣传语。
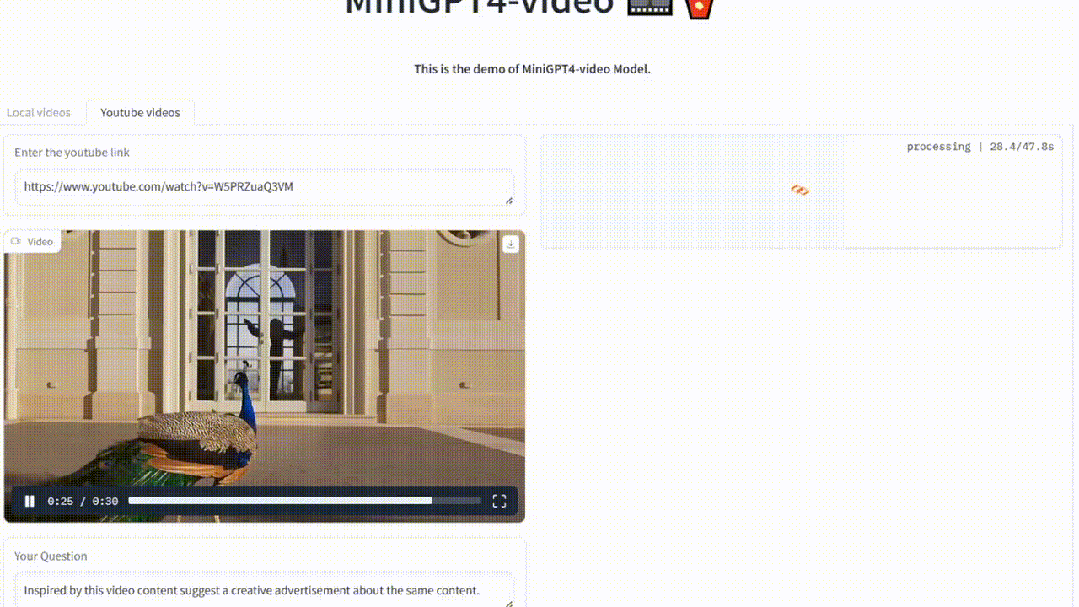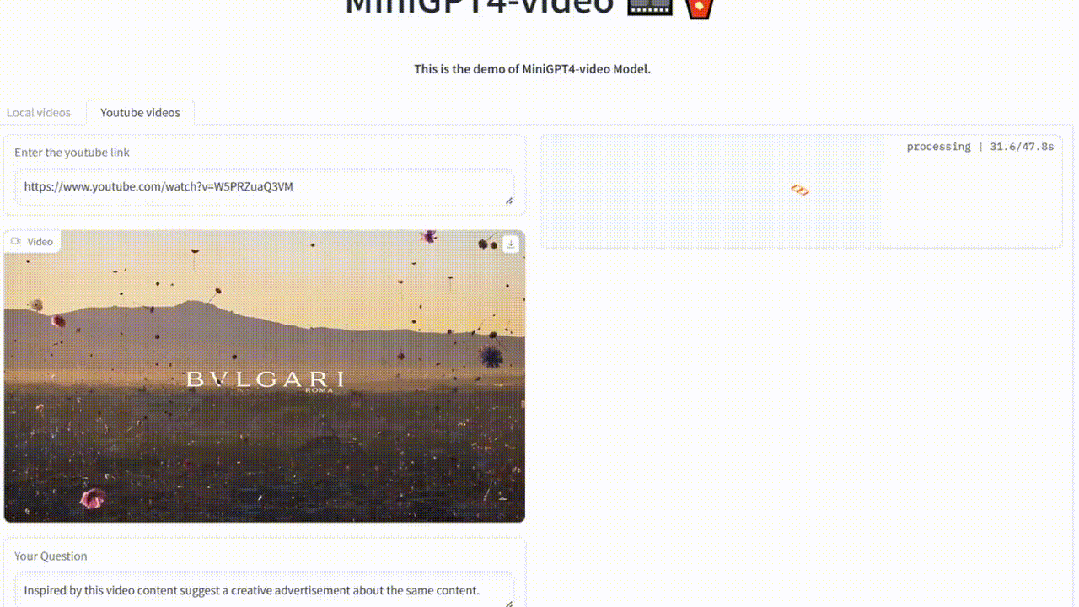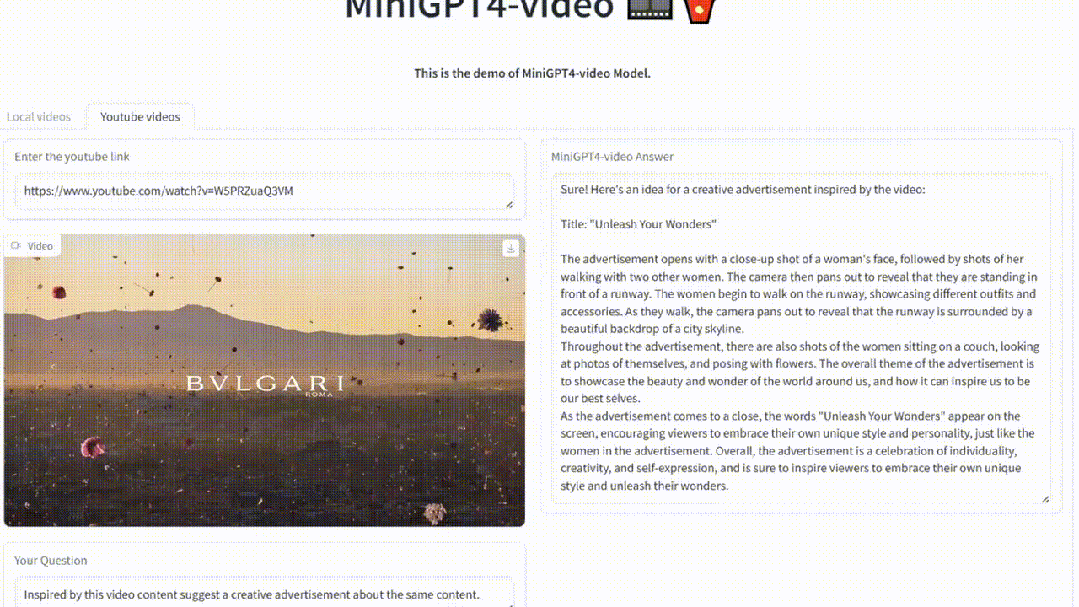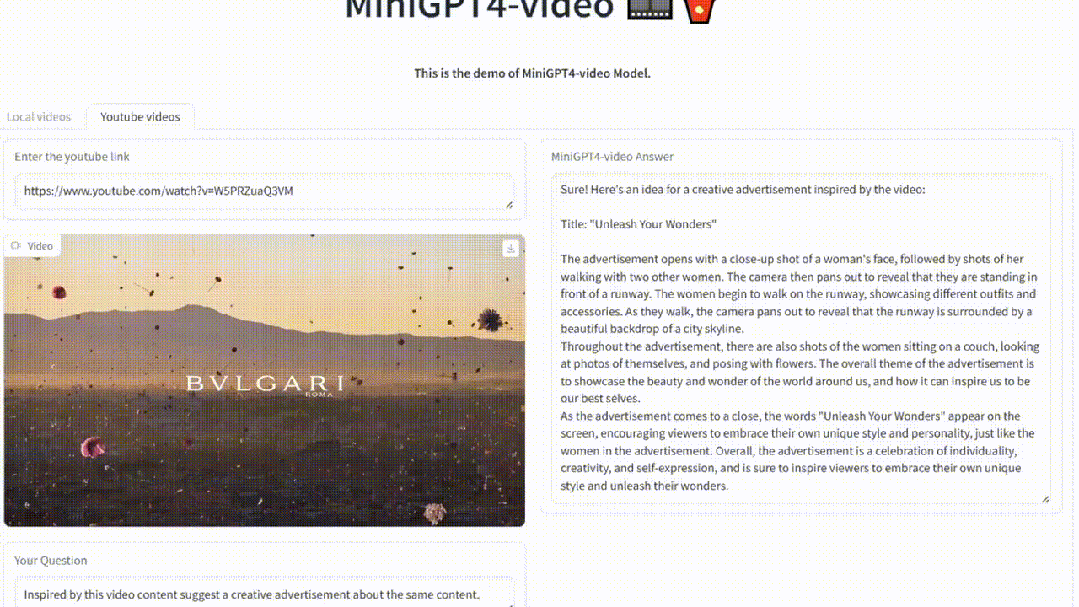
再比如,使用虚幻引擎制作的视频,新模型可以对其进行理解。

能看出这个视频使用了后期处理和特效,而不是实际拍摄出来的。

甚至,看过一簇簇花盛开的视频,MiniGPT4-video即兴作出了超美的抒情诗。
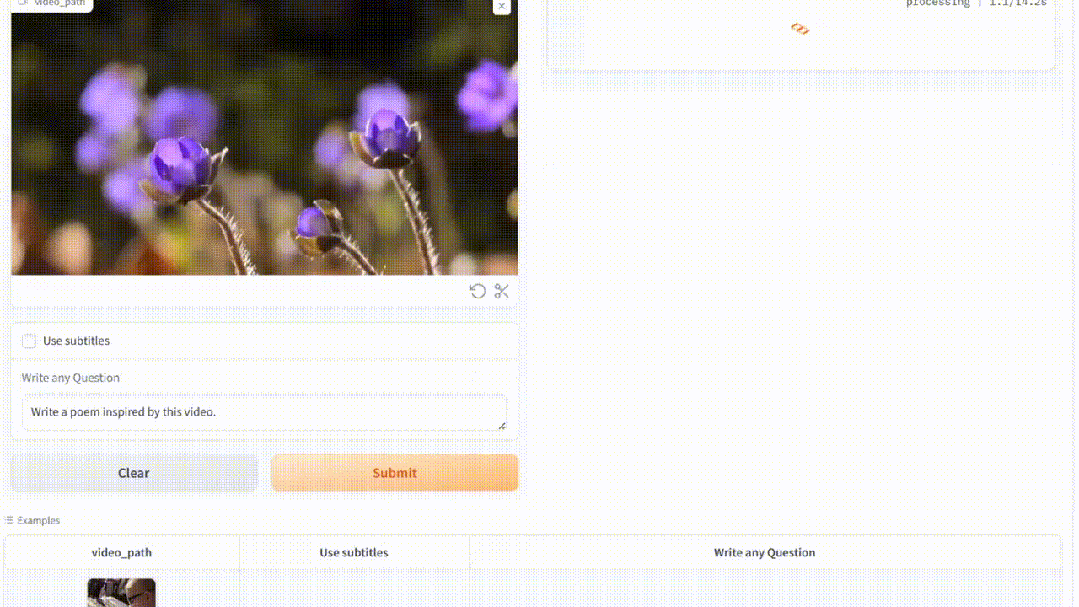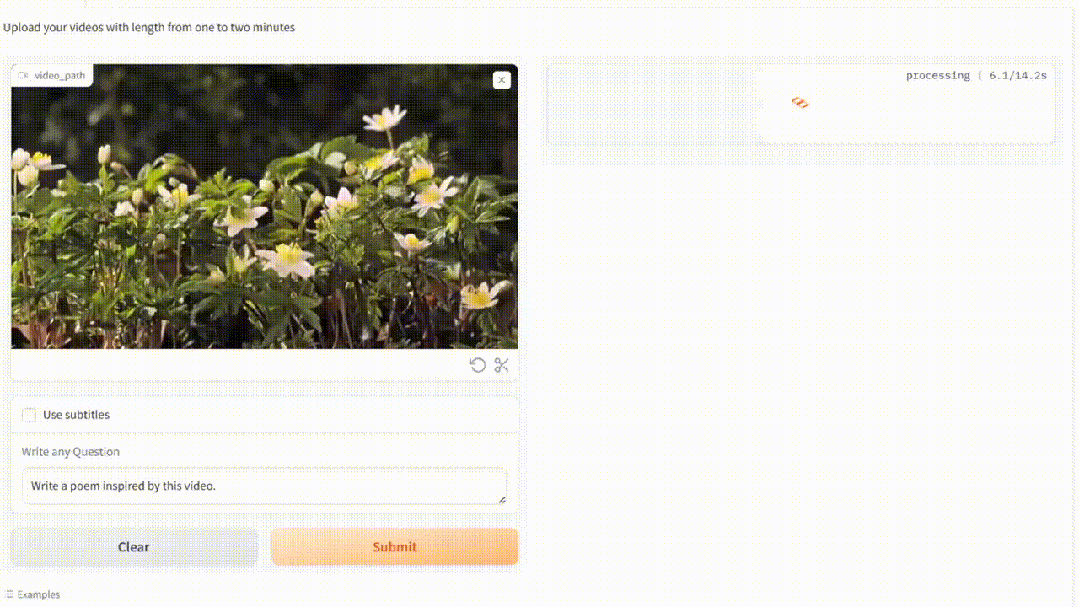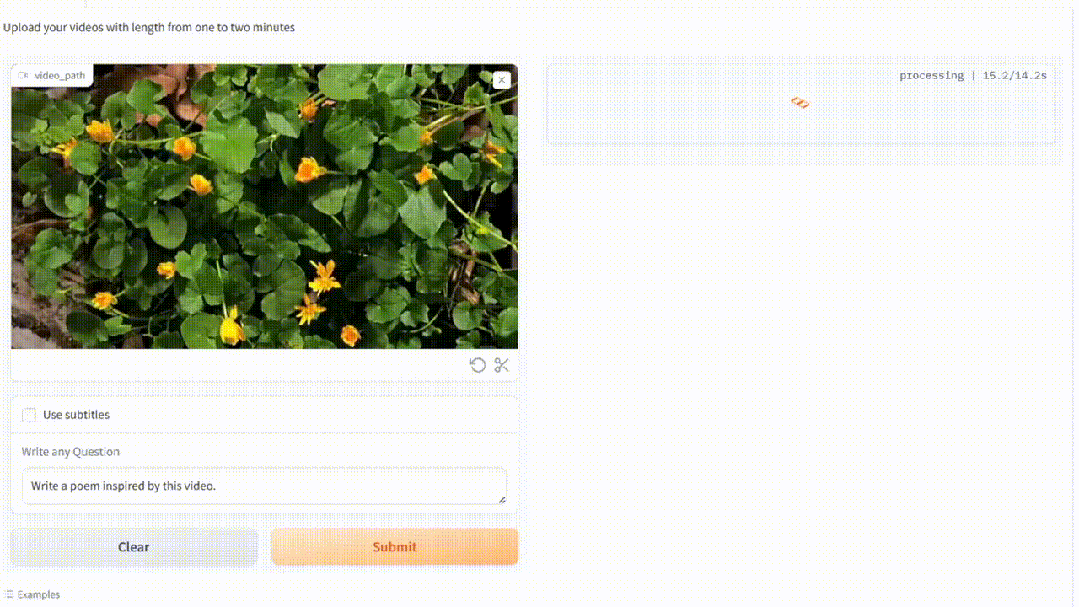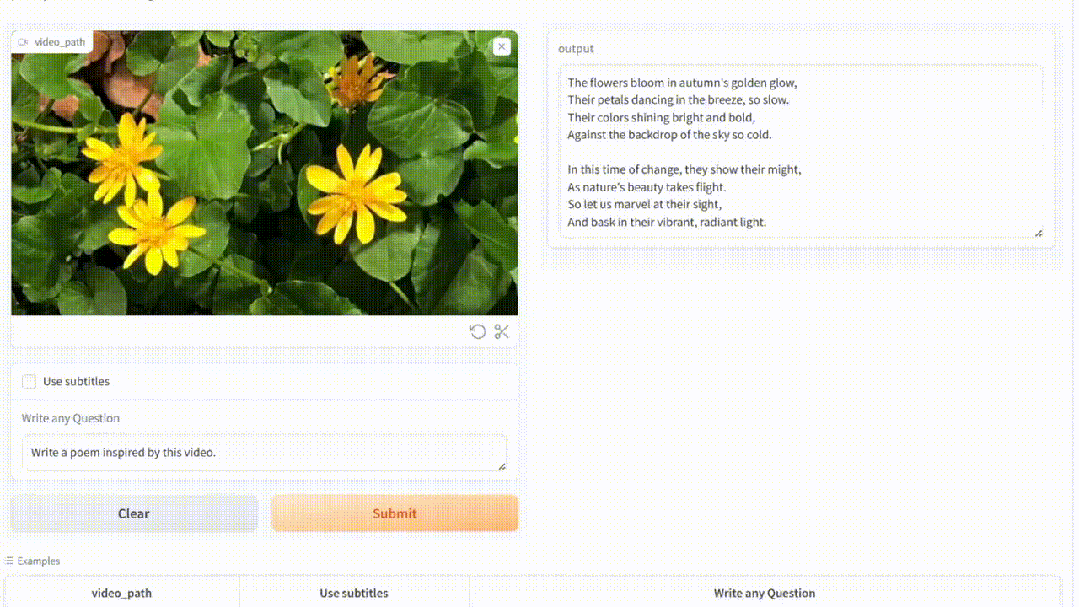
基于MiniGPT-v2,MiniGPT4-video将其能力扩展到处理帧序列,以便理解视频。
MiniGPT4-video不仅考虑了视觉内容,还纳入了文本对话,使该模型能够有效地回答涉及视觉和文本内容的查询。
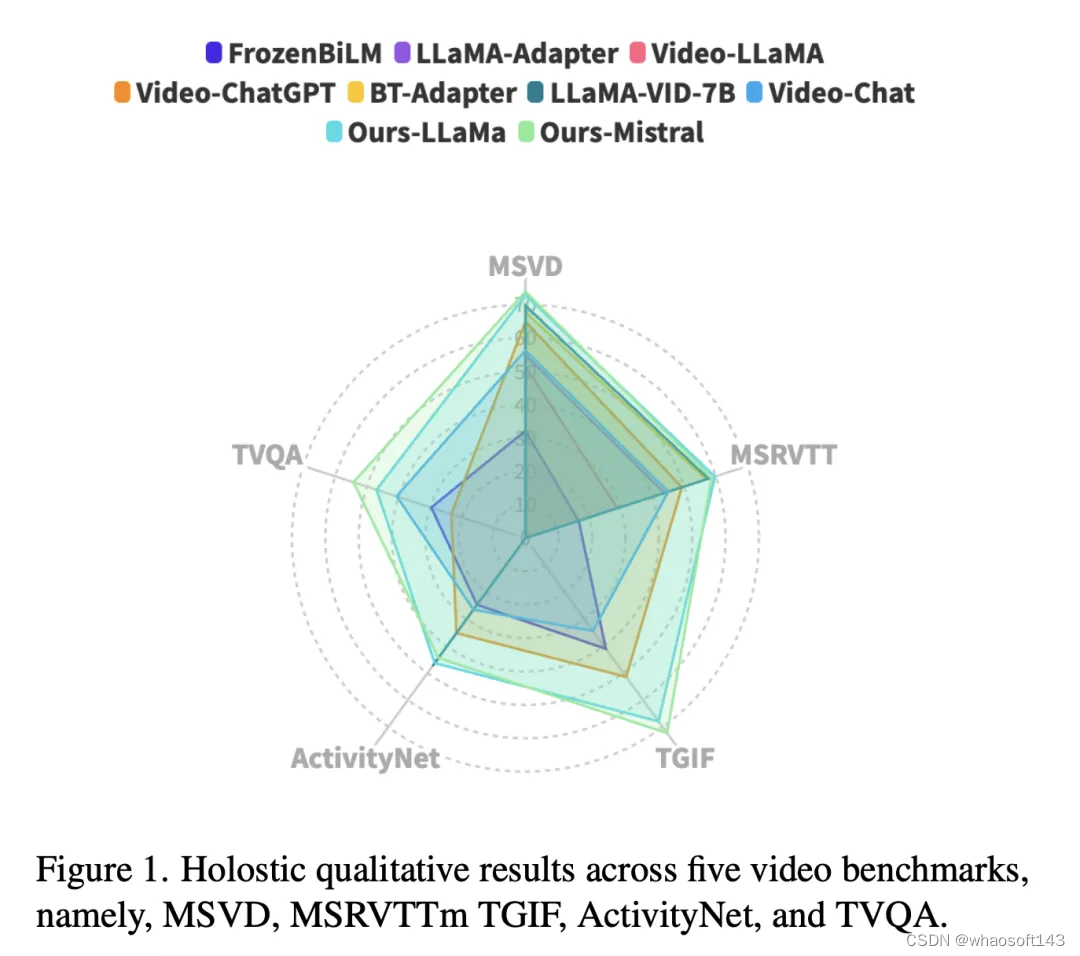
实验结果显示,新方法在MSVD、MSRVTT、TGIF和TVQA基准上分别提高了4.22%、1.13%、20.82%和13.1%。
接下来,一起看看MiniGPT4-video还能做什么?
更多演示
上传一个宝宝戴眼镜看书的视频后,MiniGPT4-video可以理解搞笑点在哪里。

提取视频中核心要义,也不在话下。

你还可以让MiniGPT4-Video生成一个创意性的广告。
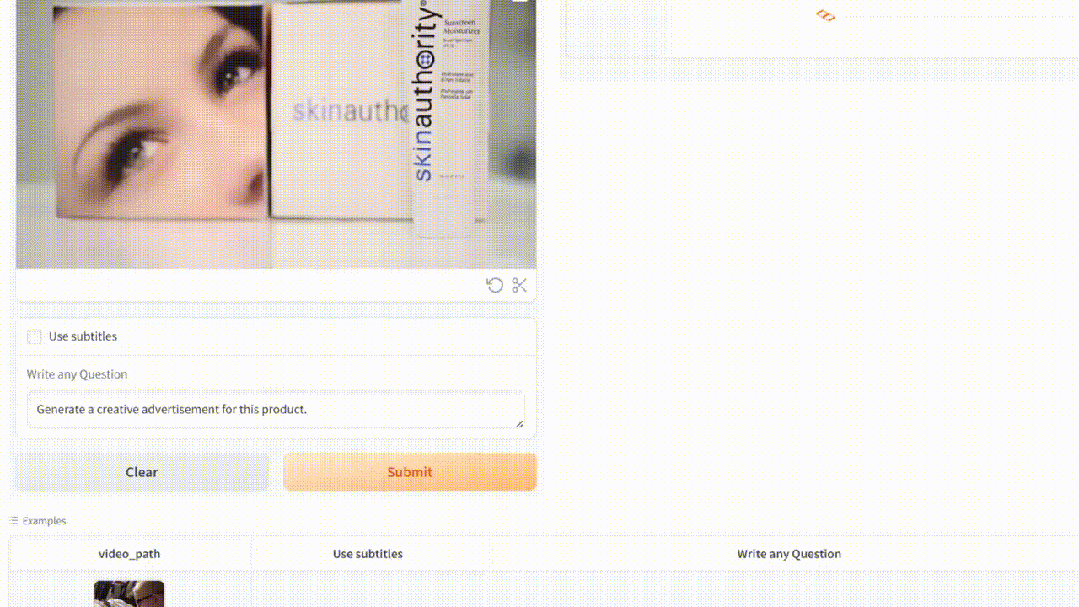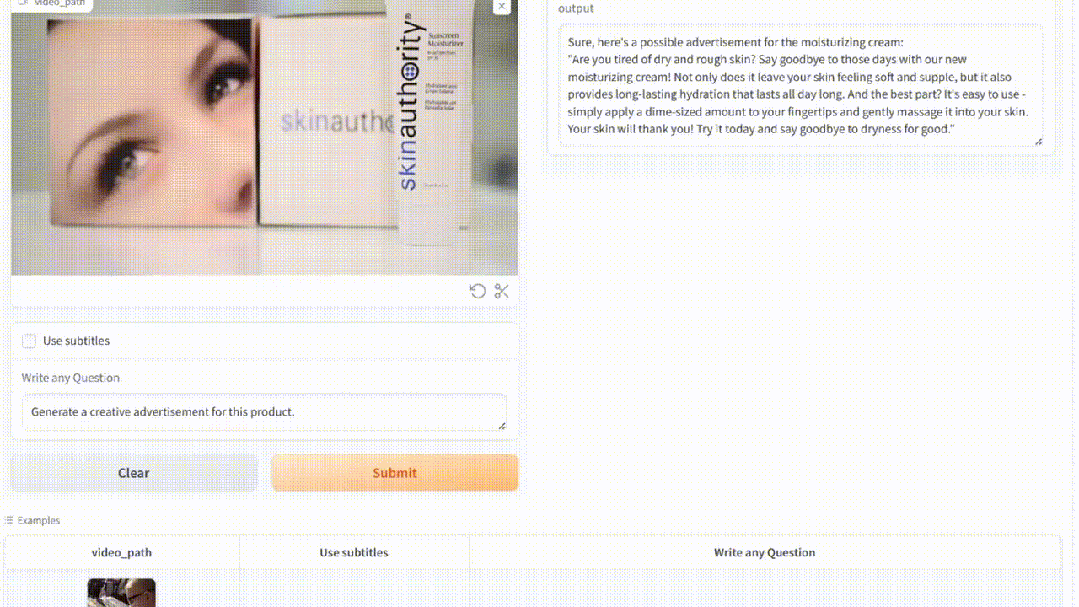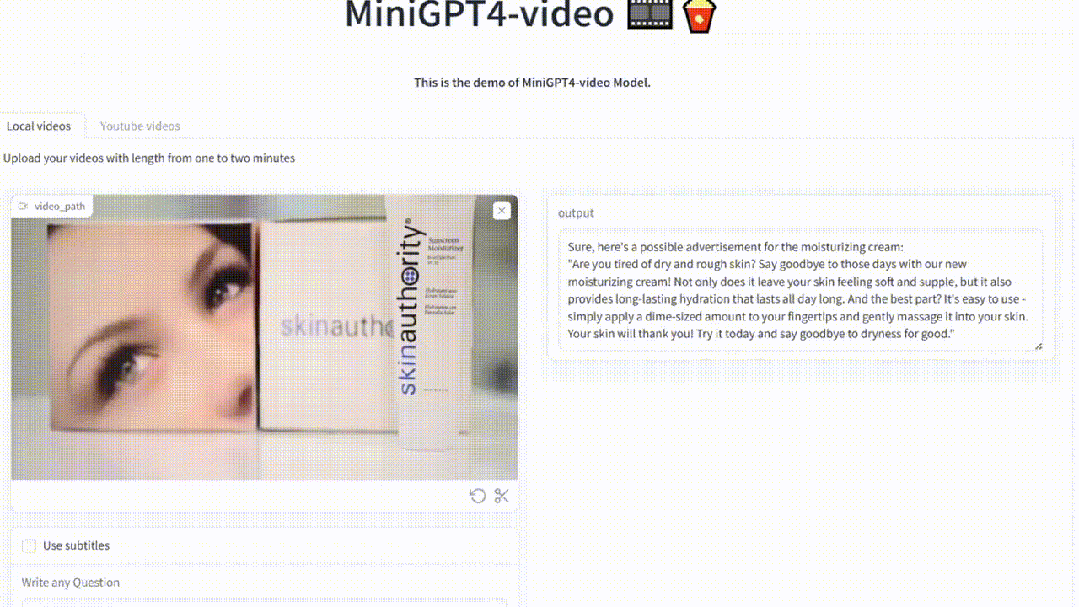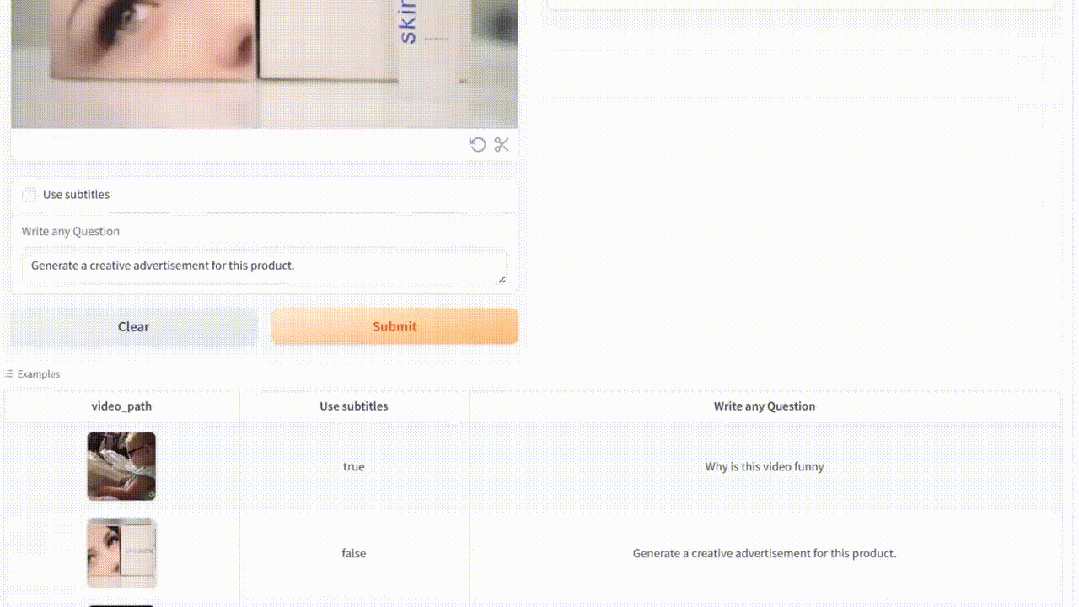
解说视频也是超级厉害。

MiniGPT4-Video能能够拥有如此强大视频解读能力,究竟是怎么做到的?
技术介绍
MiniGPT-v2通过将视觉特征转化为LLM空间,从而实现了对单幅图像的理解。
他的结构如下图2所示,由于LLM上下文窗口的限制,每段视频都要进行帧子采样,帧数(N)由LLM的上下文窗口决定。

随后,使用预先训练好的模型EVA-CLIP,将视觉帧与文本描述对齐,然后使用线性层将其映射到大型语言模型空间。
与MiniGPT-v2类似,研究人员将每幅图像中每四个相邻的视觉token浓缩为一个token,从而将每幅图像的token数减少了 75%,从256个减少到64个。
在训练过程中,研究人员会随数据集提供字幕,但在推理过程中或视频没有字幕时,研究人员会利用语音到文本模型(如 whisper)生成视频字幕。
帧字幕使用LLM tokenizer进行token化,将每个采样帧的视觉token和文本token进行连接。指令token被附加到输入序列的末尾,然后模型输出问题的答案。
训练流程
大规模图像-文本对预训练
在第一阶段,研究人员训练了一个线性层。
它将由视觉编码器编码的视觉特征(例如 EVACLIP )投影到LLM的文本空间中,并采用captioning loss。
研究人员利用了一个结合的图像描述数据集,包括来自LAION、概念性标题(Conceptual Captions)和SBU的图像,以将视觉特征与LLM的输入空间对齐。
大规模视频-文本对预训练
在第二阶段,研究人员使模型通过输入多帧来理解视频。
具体来说,研究人员从每个视频中抽取最多N帧。在此阶段,研究人员使用以下模板中的预定义提示:
<s>[INST]<Img><FrameFeature_1><Sub><Subtitle text_1>... <Img> <FrameFeature_N><Sub><Subtitle text_N><Instruction></INST>
抽取的帧数取决于每个语言模型的上下文窗口,特别是对于Llama 2,上下文窗口是4096个tokens,而Mistral的上下文窗口是8192个tokens。
在研究人员的方法中,他们用了64个tokens表示每个图像。
因此,对于Llama 2,研究人员指定N=45帧,相当于2880个tokens用于视觉内容表示。
此外,研究人员为字幕分配1000个tokens,而剩余的tokens用于模型输出。
类似地,在Mistral的情况下,上下文窗口加倍,N相应地加倍到N=90帧,以确保与扩展的上下文窗口兼容。
在此提示中,每个<FrameFeature>都由视觉主干编码的采样视频帧替换。
<Subtitle text>代表相应帧的字幕,<Instruction>代表研究人员预定义的指令集中随机采样的指令,包含多种形式的指令,如「简要描述这些视频」。
研究人员使用结合了CMD和WebVid的视频描述数据进行大规模视频描述训练。
视频问题解答指令微调
在这一阶段,研究人员采用与第二阶段相同的训练策略,但重点是利用高质量的视频答题数据集进行教学微调。
这一微调阶段有助于提高模型解释输入视频和生成精确回复的能力。
解释输入视频并生成相应的问题。模板与第二阶段模板与第二阶段的模板相同,但将 <Instruction> 替换为Video-ChatGPT数据集中提到的一般问题。
实现细节
在三个训练阶段中,研究人员保持批大小为4,并使用AdamW优化器结合余弦学习率调度器,将学习率设置为1e4。
研究人员的视觉主干是EVA-CLIP,进行了权重冻结。
值得注意的是,研究人员训练了线性投影层,并使用LoRA对语言模型进行了高效微调。
具体来说,研究人员微调了Wq和Wv组件,排名(r)为64,LoRA-alpha值为16。整个模型以一致的224×224像素的图像分辨率进行训练,确保了所有阶段的统一性。
多项基准,刷新SOTA
为了对最新提出的架构进行全面评估,研究人员评估了三种基准类型的性能:Video-ChatGPT、Open-ended Questions和Multiple-Choice Questions (MCQs)。
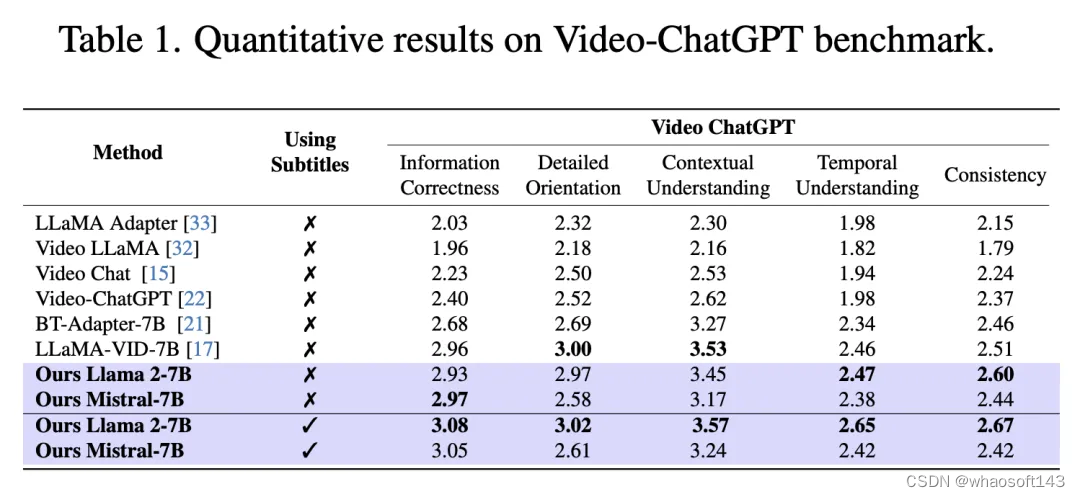
表1所示的VideoChatGPT基准测试中,最新模型在没有字幕的情况下与之前的方法不相上下。
当研究人员将字幕作为输入时,模型在所有五个维度上都取得了SOTA。
这验证了研究人员的模型可以利用字幕信息,来提高视频的理解。
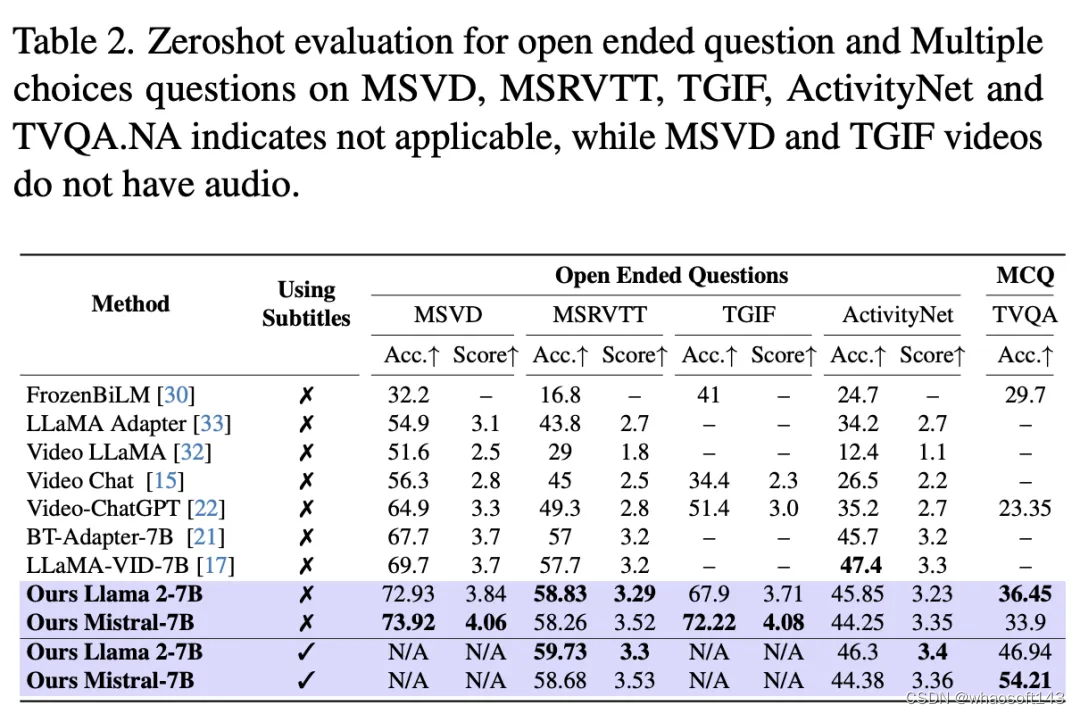
在另外两个基准测试评估中,MiniGPT4-Video明显优于最新的SOTA方法。
它在MSVD、MSRVTT、TGIF和TVQA基准上分别实现了4.22%、1.13%、20.82%和13.1%的显着改进。
带字幕和不带字幕的结果进一步表明,将字幕信息与视觉提示集成可显著提高性能,TVQA的准确率从33.9%提高到54.21%。
定性结果
更多的定性结果,如下图所示。 whaosoft aiot http://143ai.com
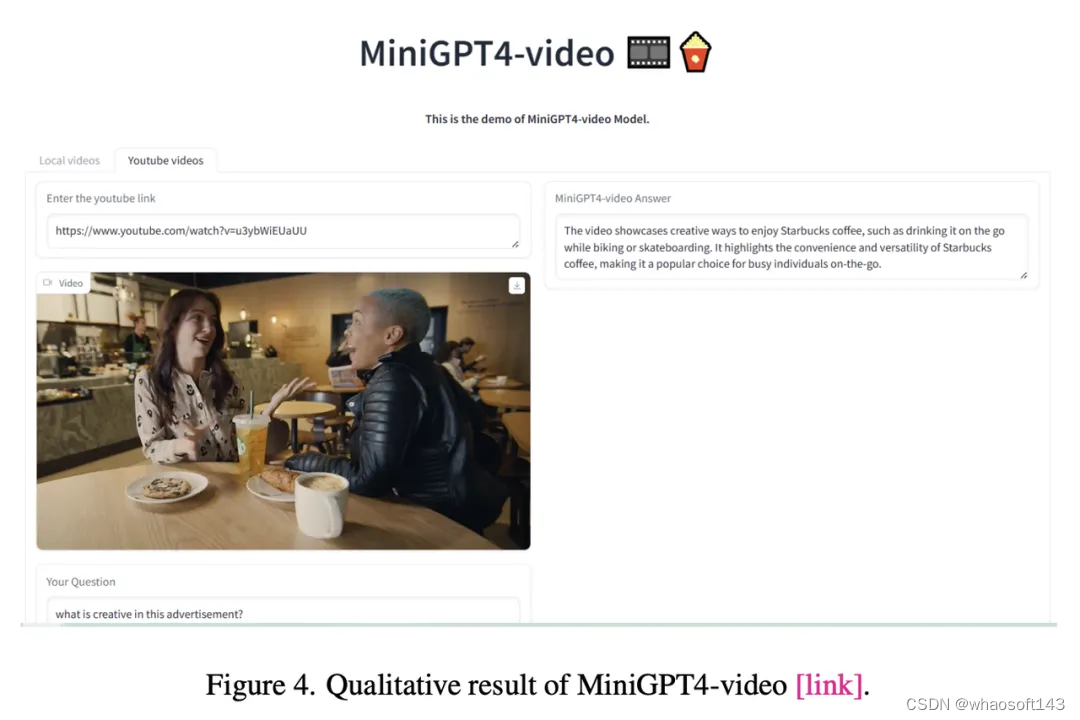

最后,研究人员还将MiniGPT4-video与VideoChatGPT相比较。
可以看出,针对一个问题,最新方法的回复更加全面。

总之,MiniGPT4-video有效地融合了视频领域内的视觉和对话理解,为视频问答提供了一个 引人注目的解决方案。
不过,缺陷在于上下文窗口限制。
具体来说,当前版本要求Llama 2视频长度为45帧(不到一分半),Mistral版本的视频长度为90帧(不到三分钟)。
因此,下一步研究将模型能力扩展到处理更长视频的能力。
参考资料:
https://arxiv.org/pdf/2404.03413.pdf

