
- 1[大模型]DeepSeek-MoE-16b-chat Transformers 部署调用_deepseek本地部署
- 2浅谈驱动开发_驱动开发是干什么的
- 3AVM 环视拼接方法介绍_avm拼接算法
- 4鸿蒙OpenHarmony【轻量系统 编译】 (基于Hi3861开发板)_openharmony hb
- 5Android 中的动态应用程序图标_android 动态更新icon
- 6概率模拟(sigmoid、softmax)
- 7开源机器学习模型管理工具DVC介绍_算法模型版本管理服务
- 8十分钟带你认识大模型和生成式AI和其常见误解_生成式ai与大模型
- 9GO语言与C++语言的区别主要体现在什么地方?可以举个简单的例子说明吗?
- 10ROS2从入门到精通5-1:详解代价地图与costmap插件编写(以距离场ESDF为例)_ros costmap
【大模型】Lora_lora模型
赞
踩
论文标题:LoRA: Low-Rank Adaptation of Large Language Models
论文链接:https://arxiv.org/abs/2106.09685
论文来源:NVIDIA
1.提出背景
自然语言处理的一个重要范式为使用领域数据对模型进行大规模的预训练 ,并适应特定的任务或领域。而随着模型不断升级,参数量变得越来越大(现在以B为单位),如果对更大的模型进行预训练,重新训练所有模型参数的完全微调代价非常昂贵。
基于以上提出了Low-Rank Adaptation(低秩适应),即LoRA。它冻结了预先训练好的模型权重,并将可训练的秩解矩阵注入到Transformer架构的每一层,大大减少了下游任务的可训练参数的数量。其实主要是不想微调模型的所有参数。
2.Lora介绍
Low-Rank Adaptation(低秩适应)是一种针对大型语言模型(如GPT-3等)在下游任务上进行的参数效率优化技术。这种方法的核心思想是,在模型适应下游任务的过程中,不是更新全部的模型参数,而是仅更新一部分参数,以此来减少需要训练的参数量,提高训练效率,并减少内存消耗。
具体而言,低秩适应通过矩阵分解的技术,将大型语言模型中的权重矩阵分解为两个更小的矩阵的乘积,这两个小矩阵是可训练的。在训练过程中,只训练这两个小矩阵,而固定住原始预训练模型的权重。这样做的好处是,相比于完全微调(即更新所有参数),低秩适应可以显著减少训练参数的数量,从而加快训练速度,减少显存占用。
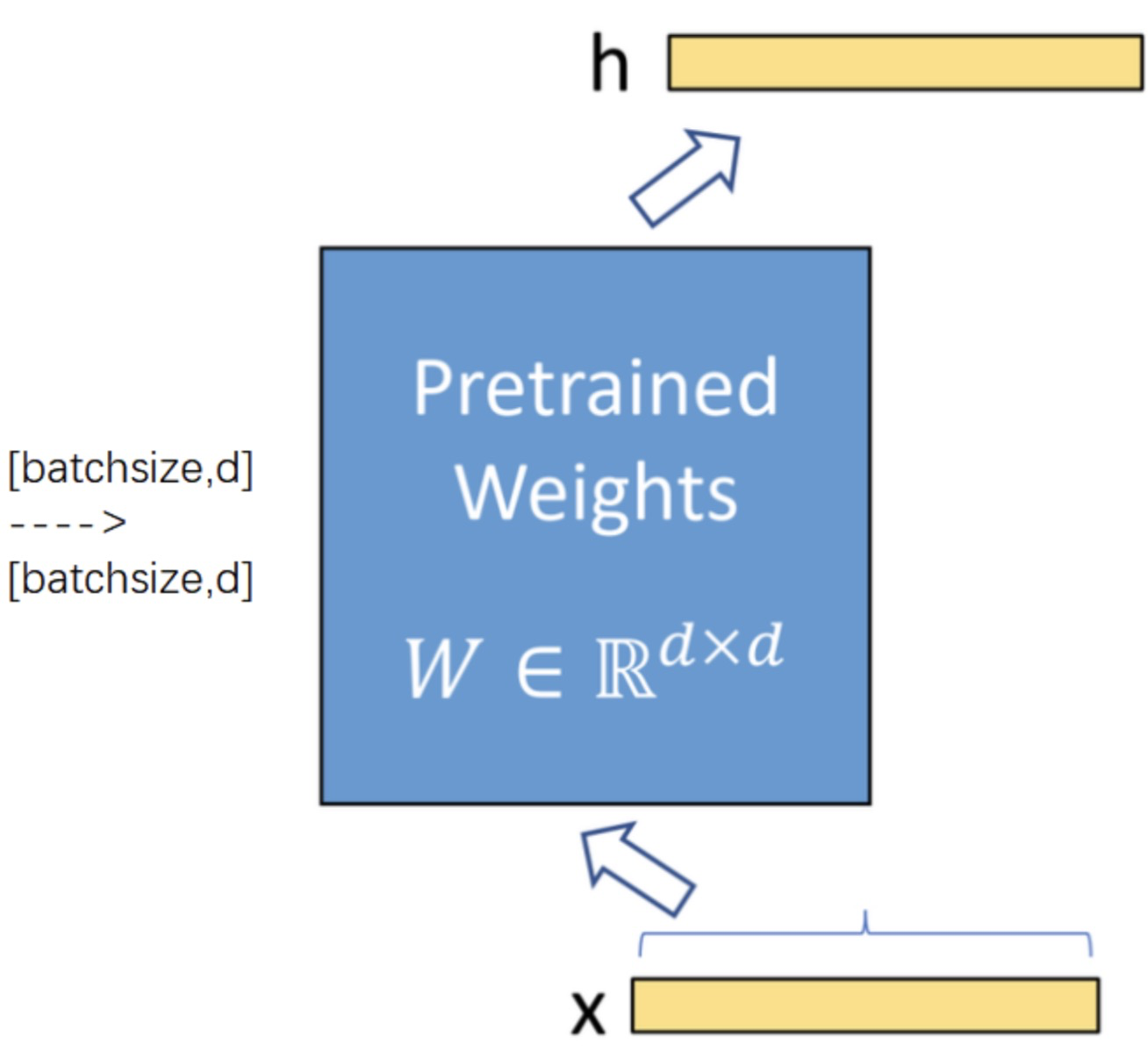
上图为加入lora之前的模型结构,模型的参数矩阵的shape是d*d。一个shape=[batchsize,d]的输入,经过这个全连接层之后,得到shape=[batchsize,d]的输出。
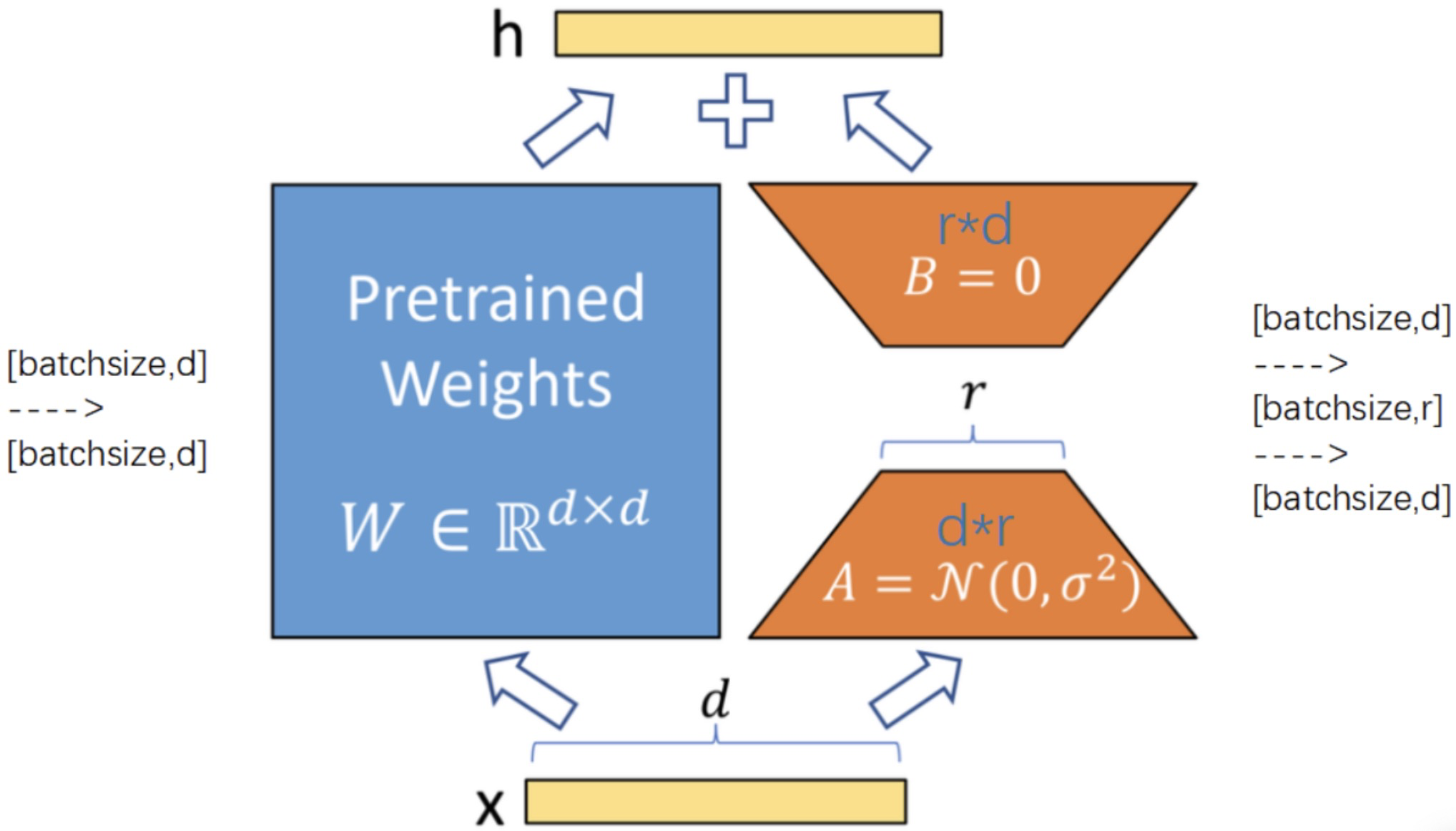
lora是加了一个旁路,相当于加了一个残差连接。这个旁路由两个参数矩阵组成,第一个是的参数矩阵,第二个是
的参数矩阵。一个
的矩阵,可以用一个
的矩阵乘以一个
的矩阵来近似。
原来模型的参数是一个的矩阵,但是在微调的时候,
的参数量太大了,需要降维,降维成一个
矩阵和一个
的矩阵。那么一个shape=[batchsize,d]的输入,经过
的矩阵后,得到
的输出,然后再经过一个
的参数矩阵,得到
的输出。最后和左边的主干加起来。
可以将新的lora权重矩阵与原始预训练权重合并,在推理中不会产生额外的开销;如上图所示,左边是预训练模型的权重,输入输出维度都是d,在训练时被冻结参数,右边对A使用随机的高斯初始化,B在训练初始为0。一个预训练的权重矩阵,使用低秩分解来表示,初始时△W=BA:
LoRA的思想也很简单,在原始PLM旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的intrinsic rank。训练的时候固定PLM的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与PLM的参数叠加。用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵依然是0矩阵。
冻结预训练模型权重,并将可训练的秩分解矩阵注入到Transformer层的每个权重中,大大减少了下游任务的可训练参数数量。实际上是增加了右侧的“旁支”,也就是先用一个Linear层A,将数据从 d维降到r,再用第二个Linear层B,将数据从r变回d维。最后再将左右两部分的结果相加融合,得到输出的hidden_state。
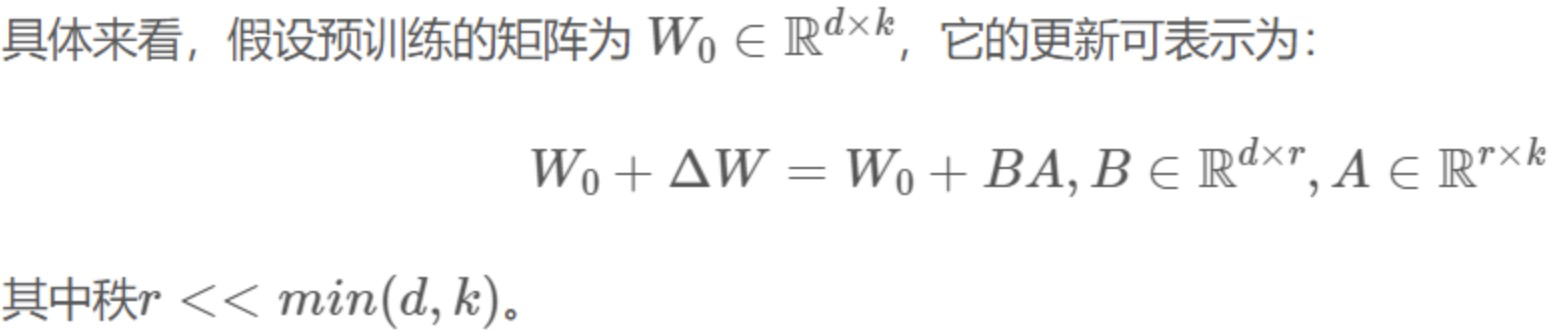
-
LoRA也几乎未引入额外的inference latency,只需要计算
 即可。
即可。 -
LoRA与Transformer的结合也很简单,仅在QKV attention的计算中增加一个旁路,而不动MLP模块。
这种思想有点类似于残差连接,同时使用这个旁路的更新来模拟full finetuning的过程。并且,full finetuning可以被看做是LoRA的特例(当r等于k时)。
3.代码
3.1
通过现有的peft库实现lora。我们先简单定义一个网络,这个网络是由只有一个linear层,为20*20的矩阵。注意在代码的输出处可以看到,第一个线性层的name是“0”。

现在第0层的线性层注入一个lora,只需要加参数target_modules=['0'],代表给名字为0的层注入lora。
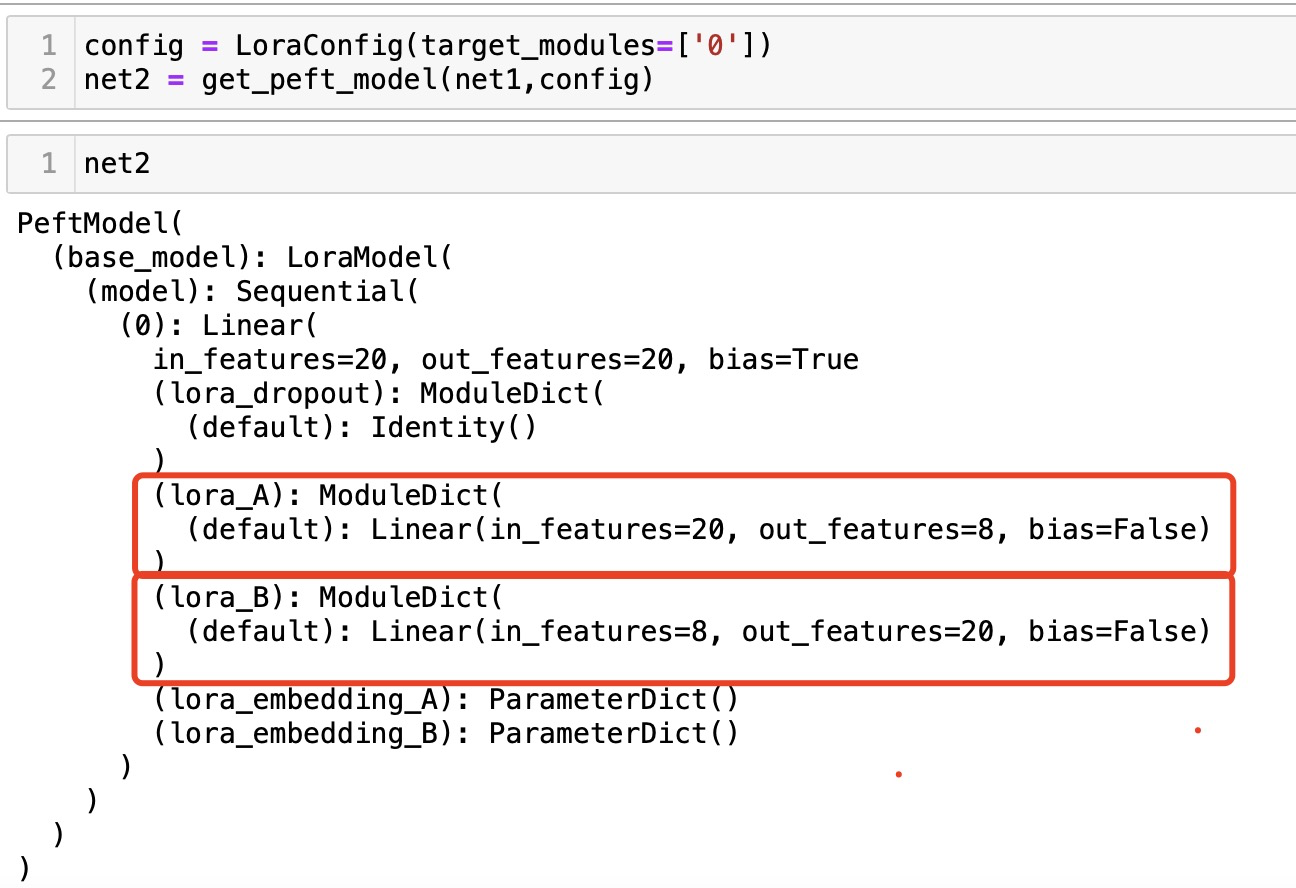
可以看到第0层多了两个线性层:lora_A和lora_B,第一个线性层的参数矩阵是20*8,这个8就是r,就是秩,它默认是8。第二个线性层的参数矩阵是8*20。所以可以看到一个20*20的矩阵,用一个20*8和8*20的矩阵来近似了。
如果我使用原来的20*20的矩阵进行微调,那需要微调的参数量为400。而现在作为lora_A和lora_B分解的可训练参数的总数变为20× 8 + 8 × 20 = 320。
3.2
使用peft时,只需要设定把lora注入到哪里,以及秩要指定为多少。理论上有全连接层的地方都可以放。我们回顾transformer有哪些地方有全连接层呢?有七个地方。一开始的embedding层,每一个transformer层的Wq/Wk/Wv/Wo四个全连接层,每一个transformer层的前馈层包括两个全连接层。一般来说,注入到q和v的效果是最好的。比如在llama中,是将lora注入到所有自注意力层的q/v矩阵,在chatglm中,则是将lora注入到所有自注意力层的q/k/v矩阵。
Hugging Face的PEFT库可以对LoRA进行调用,代码如下:
-
- from peft import get_peft_model, LoraConfig, TaskType
-
- peft_config = LoraConfig(
- task_type=TaskType.CAUSAL_LM, # 设置任务类型
- inference_mode=False, # 设置推理模式为 False
- r=8, # 设置 PEFT 模型的秩为 8
- lora_alpha=32, # 设置 LORA 的 alpha 参数为 32
- lora_dropout=0.1, # 设置 LORA 的 dropout 参数为 0.1
- target_modules=['query_key_value'] # 设置 PEFT 模型的目标模块为 ['query_key_value']
- )
-
- # 加载模型
- model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
- model = get_peft_model(model, peft_config)
-
- # 打印模型参数
- model.print_trainable_parameters()
- # output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282

结语
LoRA的核心假设:低秩有效性,增量矩阵是低秩的。针对如果微调的数据量很大,实际的秩可能会很大,如果再强行压缩到rank=8,损失的信息会很多,这个时候不如全量微调。以LoRA为代表的PEFT本质是在计算资源受限的情况下的弥补方案,并不能起到代替主菜的作用。
Reference:
1.LoRA: Low-Rank Adaptation of Large Language Models低秩自适应-CSDN博客


