
热门标签
热门文章
- 1python安装pip、numpy、scipy、statsmodels、pandas、matplotlib等
- 2ai绘画工具哪个好?看完你就知道了_ai 画画 有调谁的接口好点
- 3基于fabric的溯源项目、车辆路径数据、存证项目开发等_基于fabric的项目
- 4python输入两个字符串连接起来_python字符串连接的多种方法
- 5小程序自学教程
- 6Mybatis类型转换介绍_mapper 某个字段返回字符串数组
- 7复习笔记:数据库多选题
- 8(NXP)LS1012 LS1043 LS1046 LS1028 性能PK对比-飞凌嵌入式_nxp ls104x 芯片
- 9工作一年的java程序员薪资,纯干货_程序员工作一年后工资
- 10Flink实时数仓同步:拉链表实战详解_flink实时数仓同步 拉链表
当前位置: article > 正文
详解基于密度的聚类算法——DBSCAN_密度聚类伪代码解读
作者:盐析白兔 | 2024-07-21 08:09:16
赞
踩
密度聚类伪代码解读
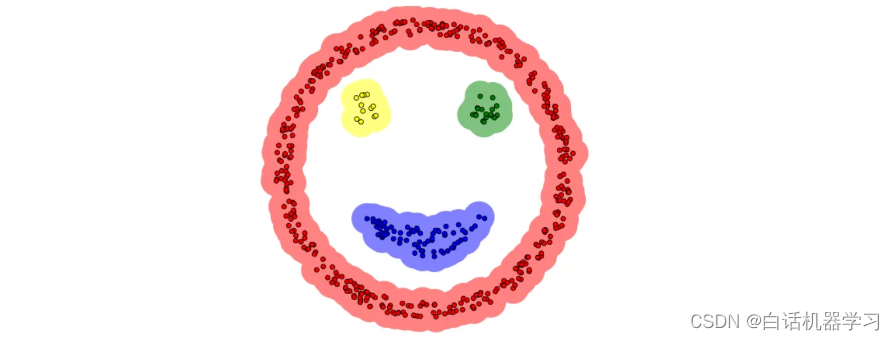
今天给大家介绍另外一种聚类算法,也是我们日常使用频率非常高的一种聚类方法——基于密度的聚类算法。
基于密度的聚类算法是通过计算样本的紧密程度来实现对样本类别的划分,在样本空间中聚集密度大的就会划分到一个类别中,理论上能够找出任何形状的聚类。
密度聚类并不需要事先设定聚类簇的数量,算法会根据数据的密度分布情况自行决定聚类簇的个数,同时,还能够有效识别明显的噪声点(离群点)。
DBSCAN是一种非常经典的基于密度的聚类算法,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇,今天我们就来一起盘一盘这个算法。
在具体学习DBSCAN算法原理前,我们先来了解一些算法相关的基本概念:
一、DBSCAN算法相关基本概念
1、关于密度的核心思想
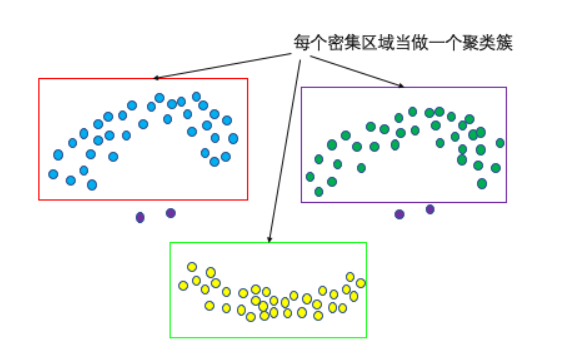
DBSCAN通过计算样本间的密度,找到样本的全部聚集区域,并把这些聚集区域作为最终的聚类簇结果。各别的离群点并不会对最终结果产生影响(如图中紫色点)。
2、算法的两个核心参数
(1)邻域半径eps
DBSCAN会以各数据点为圆心&#x
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/860165
推荐阅读
相关标签

