
- 1最全网络安全框架及模型介绍_网络安全系统体系模型
- 2【Python编程】八、Python函数详解
- 3⭐算法入门⭐《二叉树》简单07 —— LeetCode 993. 二叉树的堂兄弟节点_root = [1,2,3,4], x = 4, y = 3
- 4udev库
- 5【Django 017】Django2.2数据模型关系之多对多(ManyToMany)_drf manytomany
- 6百度网盘百度云视频倍速播放方法 亲测有用 共6种,总有一个适合你_百度网盘倍速
- 7byte数组转string乱码_彻底搞懂这烦人的编码与乱码!
- 8【毕业设计】基于spring boot的图书管理系统 -java 计算机 软件工程_设定每本书只有一本,只能同时被一个用户借阅springboot
- 9花费5个月整理的「字节跳动」面试经验《Python快速入门指南》基础知识详细PDF免费分享_python 字节跳动 面试
- 10CodeReview常见代码问题_codereview 涉及代码功能
【Java学习路线之JavaWeb】Spring Cloud教程(非常详细)_spring cloud web应用
赞
踩
文章目录
- 微服务是什么
- Spring Cloud是什么
- Eureka:Spring Cloud服务注册与发现组件(非常详细)
- Ribbon:Spring Cloud负载均衡与服务调用组件(非常详细)
- OpenFeign:Spring Cloud声明式服务调用组件(非常详细)
- Hystrix:Spring Cloud服务熔断与降级组件(非常详细)
- Gateway:Spring Cloud API网关组件(非常详细)
- Config:Spring Cloud分布式配置组件(非常详细)
- Spring Cloud Alibaba是什么
- Nacos:Spring Cloud Alibaba服务注册与配置中心(非常详细)
- Sentinel:Spring Cloud Alibaba高可用流量控制组件(非常详细)
- Seata:Spring Cloud Alibaba分布式事务组件(非常详细)
转载于: http://c.biancheng.net/springcloud/
Spring Cloud 是分布式微服务架构的一站式解决方案,它提供了一套简单易用的编程模型,使我们能在 Spring Boot 的基础上轻松地实现微服务系统的构建。
Spring Cloud 被称为构建分布式微服务系统的“全家桶”,它并不是某一门技术,而是一系列微服务解决方案或框架的有序集合。它将市面上成熟的、经过验证的微服务框架整合起来,并通过 Spring Boot 的思想进行再封装,屏蔽调其中复杂的配置和实现原理,最终为开发人员提供了一套简单易懂、易部署和易维护的分布式系统开发工具包。
Spring Cloud 中包含了 spring-cloud-config、spring-cloud-bus 等近 20 个子项目,提供了服务治理、服务网关、智能路由、负载均衡、断路器、监控跟踪、分布式消息队列、配置管理等领域的解决方案。
Spring Cloud 本身并不是一个拿来即可用的框架,它是一套微服务规范,共有两代实现。
- Spring Cloud Netflix 是 Spring Cloud 的第一代实现,主要由 Eureka、Ribbon、Feign、Hystrix 等组件组成。
- Spring Cloud Alibaba 是 Spring Cloud 的第二代实现,主要由 Nacos、Sentinel、Seata 等组件组成。
读者
这套 Spring Cloud 教程适用于开发高度可扩展、高性能分布式微服务系统的 Java 研发人员,
本教程以大量示例,讲解了 Spring Cloud 各组件的应用,让读者可以跟着笔者的思维和代码快速理解并掌握 Spring Cloud。
阅读条件
阅读本套 Spring Cloud 教程之前,您应该已经掌握了 Java 基础、Maven、Spring、Spring MVC、MyBatis、Git、RabbitMQ 以及 Spring Boot 等知识。此外,由于本教程中的所有实例都是使用 IntelliJ IDEA 编写编译的,所以您还需要对 IntelliJ IDEA 有基本的了解。
微服务是什么
微服务(MicroServices)最初是由 Martin Fowler 于 2014 年发表的论文 《MicroServices》 中提出的名词,它一经提出就成为了技术圈的热门话题。
微服务,我们可以从字面上去理解,即“微小的服务”,下面我们从“服务”和“微小”两个方面进行介绍。
-
所谓“服务”,其实指的是项目中的功能模块,它可以帮助用户解决某一个或一组问题,在开发过程中表现为 IDE(集成开发环境,例如 Eclipse 或 IntelliJ IDEA)中的一个工程或 Moudle。
-
“微小”则强调的是单个服务的大小,主要体现为以下两个方面:
- 微服务体积小,复杂度低:一个微服务通常只提供单个业务功能的服务,即一个微服务只专注于做好一件事,因此微服务通常代码较少,体积较小,复杂度也较低。
- 微服务团队所需成员少:一般情况下,一个微服务团队只需要 8 到 10 名人员(开发人员 2 到 5 名)即可完成从设计、开发、测试到运维的全部工作。
微服务架构
微服务架构是一种系统架构的设计风格。与传统的单体式架构(ALL IN ONE)不同,微服务架构提倡将一个单一的应用程序拆分成多个小型服务,这些小型服务都在各自独立的进程中运行,服务之间使用轻量级通信机制(通常是 HTTP RESTFUL API)进行通讯。
通常情况下,这些小型服务都是围绕着某个特定的业务进行构建的,每一个服务只专注于完成一项任务并把它做好 ,即“专业的人做专业的事”。
每个服务都能够独立地部署到各种环境中,例如开发环境、测试环境和生产环境等,每个服务都能独立启动或销毁而不会对其他服务造成影响。
这些服务之间的交互是使用标准的通讯技术进行的,因此不同的服务可以使用不同数据存储技术,甚至使用不同的编程语言。
微服务架构 vs 单体架构
在当今的软件开发领域中,主要有两种系统架构风格,那就是新兴的“微服务架构”和传统的“单体架构”。
单体架构是微服务架构出现之前业界最经典的软件架构类型,许多早期的项目采用的也都是单体架构。单体架构将应用程序中所有业务逻辑都编写在同一个工程中,最终经过编译、打包,部署在一台服务器上运行。
在项目的初期,单体架构无论是在开发速度还是运维难度上都具有明显的优势。但随着业务复杂度的不断提高,单体架构的许多弊端也逐渐凸显出来,主要体现在以下 3 个方面:
- 随着业务复杂度的提高,单体应用(采用单体架构的应用程序)的代码量也越来越大,导致代码的可读性、可维护性以及扩展性下降。
- 随着用户越来越多,程序所承受的并发越来越高,而单体应用处理高并发的能力有限。
- 单体应用将所有的业务都集中在同一个工程中,修改或增加业务都可能会对其他业务造成一定的影响,导致测试难度增加。
由于单体架构存在这些弊端,因此许多公司和组织都开始将将它们的项目从单体架构向微服务架构转型。
下面我们就来对比下微服务架构和单体架构到底有什么不同。
| 不同点 | 微服务架构 | 单体架构 |
|---|---|---|
| 团队规模 | 微服务架构可以将传统模式下的单个应用拆分为多个独立的服务,每个微服务都可以单独开发、部署和维护。每个服务从设计、开发到维护所需的团队规模小,团队管理成本小。 | 单体架构的应用程序通常需要一个大型团队,围绕一个庞大的应用程序工作,团队管理的成本大。 |
| 数据存储方式 | 不同的微服务可以使用不同的数据存储方式,例如有的用 Redis,有的使用 MySQL。 | 单一架构的所有模块共享同一个公共数据库,存储方式相对单一。 |
| 部署方式 | 微服务架构中每个服务都可以独立部署,也可以独立于其他服务进行扩展。如果部署得当,基于微服务的架构可以帮助企业提高应用程序的部署效率。 | 采用单体架构的应用程序的每一次功能更改或 bug 修复都必须对整个应用程序重新进行部署。 |
| 开发模式 | 在采用微服务架构的应用程序中,不同模块可以使用不同的技术或语言进行开发,开发模式更加灵活。 | 在采用单体架构的应用程序中,所有模块使用的技术和语言必须相同,开发模式受限。 |
| 故障隔离 | 在微服务架构中,故障被隔离在单个服务中,避免系统的整体崩溃。 | 在单体架构中,当一个组件出现故障时,故障很可能会在进程中蔓延,导致系统全局不可用。 |
| 项目结构 | 微服务架构将单个应用程序拆分为多个独立的小型服务,每个服务都可以独立的开发、部署和维护,每个服务都能完成一项特定的业务需求。 | 单体架构的应用程序,所有的业务逻辑都集中在同一个工程中。 |
微服务的特点
微服务具有以下特点:
- 服务按照业务来划分,每个服务通常只专注于某一个特定的业务、所需代码量小,复杂度低、易于维护。
- 每个微服都可以独立开发、部署和运行,且代码量较少,因此启动和运行速度较快。
- 每个服务从设计、开发、测试到维护所需的团队规模小,一般 8 到 10 人,团队管理成本小。
- 采用单体架构的应用程序只要有任何修改,就需要重新部署整个应用才能生效,而微服务则完美地解决了这一问题。在微服架构中,某个微服务修改后,只需要重新部署这个服务即可,而不需要重新部署整个应用程序。
- 在微服务架构中,开发人员可以结合项目业务及团队的特点,合理地选择语言和工具进行开发和部署,不同的微服务可以使用不同的语言和工具。
- 微服务具备良好的可扩展性。随着业务的不断增加,微服务的体积和代码量都会急剧膨胀,此时我们可以根据业务将微服务再次进行拆分;除此之外,当用户量和并发量的增加时,我们还可以将微服务集群化部署,从而增加系统的负载能力。
- 微服务能够与容器(Docker)配合使用,实现快速迭代、快速构建、快速部署。
- 微服务具有良好的故障隔离能力,当应用程序中的某个微服发生故障时,该故障会被隔离在当前服务中,而不会波及到其他微服务造成整个系统的瘫痪。
- 微服务系统具有链路追踪的能力。
微服务框架
微服务架构是一种系统架构风格和思想,想要真正地搭建一套微服务系统,则需要微服务框架的支持。随着微服务的流行,很多编程语言都相继推出了它们的微服务框架,下面我们就来简单列举下。
Java 微服务框架
市面上的 Java 微服务框架主要有以下 5 种:
- Spring Cloud:它能够基于 REST 服务来构建服务,帮助架构师构建出一套完整的微服务技术生态链。
- Dropwizard:用于开发高性能和 Restful 的 Web 服务,对配置、应用程序指标、日志记录和操作工具都提供了开箱即用的支持。
- Restlet: 该框架遵循 RST 架构风格,可以帮助 Java 开发人员构建微服务。
- Spark:最好的 Java 微服务框架之一,该框架支持通过 Java 8 和 Kotlin 创建微服务架构的应用程序。
- Dubbo:由阿里巴巴开源的分布式服务治理框架。
Go 语言微服务框
Go 语言中的微服务框架较少,使用的较多的是 GoMicro,它是一个 RPC 框架,具有负载均衡、服务发现、同步通信、异步通讯和消息编码等功能。
Phyton 微服务框架
Phyton 中的微服务框架主要有 Flask、Falcon、Bottle、Nameko 和 CherryPy 等。
NodeJS微服务框架
Molecular 是一种使用 NodeJS 构建的事件驱动架构,该框架内置了服务注册表、动态服务发现、负载均衡、容错功能和内置缓存等组件。
Spring Cloud是什么
Spring Cloud 是一款基于 Spring Boot 实现的微服务框架。Spring Cloud 源自 Spring 社区,主要由 Pivotal 和 Netflix 两大公司提供技术迭代和维护。
随着微服务的火爆流行,国内外各大互联网公司都相继分享了他们在微服务架构中,针对不同场景出现的各种问题的解决方案和开源框架。
- 服务治理:阿里巴巴开源的 Dubbo 和当当网在其基础上扩展出来的 DubboX、Netflix 的 Eureka 以及 Apache 的 Consul 等。
- 分布式配置管理:百度的 Disconf、Netflix 的 Archaius、360 的 QConf、携程的 Apollo 以及 Spring Cloud 的 Config 等。
- 批量任务:当当网的 Elastic-Job、LinkedIn 的 Azkaban 以及 Spring Cloud 的 Task 等。
- 服务跟踪:京东的 Hydra、Spring Cloud 的 Sleuth 以及 Twitter 的 Zipkin 等。
- ……
以上这些微服务框架或解决方案都具有以下 2 个特点:
- 对于同一个微服务问题,各互联网公司给出的解决方案各不相同。
- 一个微服务框架或解决方案都只能解决微服务中的某一个或某几个问题,对于其他问题则无能为力。
这种情况下,搭建一套微分布式微服务系统,就需要针对这些问题从诸多的解决方案中做出选择,这使得我们不得不将大量的精力花费在前期的调研、分析以及实验上。
Spring Cloud 被称为构建分布式微服务系统的“全家桶”,它并不是某一门技术,而是一系列微服务解决方案或框架的有序集合。它将市面上成熟的、经过验证的微服务框架整合起来,并通过 Spring Boot 的思想进行再封装,屏蔽调其中复杂的配置和实现原理,最终为开发人员提供了一套简单易懂、易部署和易维护的分布式系统开发工具包。
Spring Cloud 中包含了 spring-cloud-config、spring-cloud-bus 等近 20 个子项目,提供了服务治理、服务网关、智能路由、负载均衡、断路器、监控跟踪、分布式消息队列、配置管理等领域的解决方案。
Spring Cloud 并不是一个拿来即可用的框架,它是一种微服务规范,共有以下 2 代实现:
- 第一代实现:Spring Cloud Netflix
- 第二代实现:Spring Cloud Alibaba
这里我们介绍的 Spring Cloud 特指 Spring Cloud 的第一代实现。
Spring Cloud 常用组件
Spring Cloud 包括 Spring Cloud Gateway、Spring Cloud Config、Spring Cloud Bus 等近 20 个服务组件,这些组件提供了服务治理、服务网关、智能路由、负载均衡、熔断器、监控跟踪、分布式消息队列、配置管理等领域的解决方案。
Spring Cloud 的常用组件如下表所示。
| Spring Cloud 组件 | 描述 |
|---|---|
| Spring Cloud Netflix Eureka | Spring Cloud Netflix 中的服务治理组件,包含服务注册中心、服务注册与发现机制的实现。 |
| Spring Cloud Netflix Ribbon | Spring Cloud Netflix 中的服务调用和客户端负载均衡组件。 |
| Spring Cloud Netflix Hystrix | 人称“豪猪哥”,Spring Cloud Netflix 的容错管理组件,为服务中出现的延迟和故障提供强大的容错能力。 |
| Spring Cloud Netflix Feign | 基于 Ribbon 和 Hystrix 的声明式服务调用组件。 |
| Spring Cloud Netflix Zuul | Spring Cloud Netflix 中的网关组件,提供了智能路由、访问过滤等功能。 |
| Spring Cloud Gateway | 一个基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等技术开发的网关框架,它使用 Filter 链的方式提供了网关的基本功能,例如安全、监控/指标和限流等。 |
| Spring Cloud Config | Spring Cloud 的配置管理工具,支持使用 Git 存储配置内容,实现应用配置的外部化存储,并支持在客户端对配置进行刷新、加密、解密等操作。 |
| Spring Cloud Bus | Spring Cloud 的事件和消息总线,主要用于在集群中传播事件或状态变化,以触发后续的处理,例如动态刷新配置。 |
| Spring Cloud Stream | Spring Cloud 的消息中间件组件,它集成了 Apache Kafka 和 RabbitMQ 等消息中间件,并通过定义绑定器作为中间层,完美地实现了应用程序与消息中间件之间的隔离。通过向应用程序暴露统一的 Channel 通道,使得应用程序不需要再考虑各种不同的消息中间件实现,就能轻松地发送和接收消息。 |
| Spring Cloud Sleuth | Spring Cloud 分布式链路跟踪组件,能够完美的整合 Twitter 的 Zipkin。 |
注:Netflix 是美国的一个在线视频网站,它是公认的大规模生产级微服务的杰出实践者,微服务界的翘楚。Netflix 的开源组件已经在其大规模分布式微服务环境中经过了多年的生产实战验证,成熟且可靠。
Spring Boot 和 Spring Cloud 的区别与联系
Spring Boot 和 Spring Cloud 都是 Spring 大家族的一员,它们在微服务开发中都扮演着十分重要的角色,两者之间既存在区别也存在联系。
1. Spring Boot 和 Spring Cloud 分工不同
Spring Boot 是一个基于 Spring 的快速开发框架,它能够帮助开发者迅速搭 Web 工程。在微服务开发中,Spring Boot 专注于快速、方便地开发单个微服务。
Spring Cloud 是微服务架构下的一站式解决方案。Spring Cloud 专注于全局微服务的协调和治理工作。换句话说,Spring Cloud 相当于微服务的大管家,负责将 Spring Boot 开发的一个个微服务管理起来,并为它们提供配置管理、服务发现、断路器、路由、微代理、事件总线、决策竞选以及分布式会话等服务。
2. Spring Cloud 是基于 Spring Boot 实现的
Spring Cloud 是基于 Spring Boot 实现的。与 Spring Boot 类似,Spring Cloud 也为提供了一系列 Starter,这些 Starter 是 Spring Cloud 使用 Spring Boot 思想对各个微服务框架进行再封装的产物。它们屏蔽了这些微服务框架中复杂的配置和实现原理,使开发人员能够快速、方便地使用 Spring Cloud 搭建一套分布式微服务系统。
3. Spring Boot 和 Spring Cloud 依赖项数量不同
Spring Boot 属于一种轻量级的框架,构建 Spring Boot 工程所需的依赖较少。
Spring Cloud 是一系列微服务框架技术的集合体,它的每个组件都需要一个独立的依赖项(Starter POM),因此想要构建一套完整的 Spring Cloud 工程往往需要大量的依赖项。
4. Spring Cloud 不能脱离 Spring Boot 单独运行
Spring Boot 不需要 Spring Cloud,就能直接创建可独立运行的工程或模块。
Spring Cloud 是基于 Spring Boot 实现的,它不能独立创建工程或模块,更不能脱离 Spring Boot 独立运行。
注意:虽然 Spring Boot 能够用于开发单个微服务,但它并不具备管理和协调微服务的能力,因此它只能算是一个微服务快速开发框架,而非微服务框架。
Spring Cloud 版本
Spring Cloud 包含了许多子项目(组件),这些子项目都是独立进行内容更新和迭代的,各自都维护着自己的发布版本号。
为了避免 Spring Cloud 的版本号与其子项目的版本号混淆,Spring Cloud 没有采用常见的数字版本号,而是通过以下方式定义版本信息。
{version.name} .{version.number}
- 1
Spring Cloud 版本信息说明如下:
- version.name:版本名,采用英国伦敦地铁站的站名来命名,并按照字母表的顺序(即从 A 到 Z)来对应 Spring Cloud 的版本发布顺序,例如第一个版本为 Angel,第二个版本为 Brixton(英国地名),然后依次是 Camden、Dalston、Edgware、Finchley、Greenwich、Hoxton 等。
- version.number:版本号,每一个版本的 Spring Cloud 在更新内容积累到一定的量级或有重大 BUG 修复时,就会发布一个“service releases”版本,简称 SRX 版本,其中 X 为一个递增的数字,例如 Hoxton.SR8 就表示 Hoxton 的第 8 个 Release 版本。
Spring Cloud 版本选择
在使用 Spring Boot + Spring Cloud 进行微服务开发时,我们需要根据项目中 Spring Boot 的版本来决定 Spring Cloud 版本,否则会出现许多意想不到的错误。
Spring Boot 与 Spring Cloud 的版本对应关系如下表(参考自 Spring Cloud 官网)。
| Spring Cloud | Spring Boot |
|---|---|
| 2020.0.x (Ilford) | 2.4.x, 2.5.x (从 Spring Cloud 2020.0.3 开始) |
| Hoxton | 2.2.x, 2.3.x (从 Spring Cloud SR5 开始) |
| Greenwich | 2.1.x |
| Finchley | 2.0.x |
| Edgware | 1.5.x |
| Dalston | 1.5.x |
注意:Spring Cloud 官方已经停止对 Dalston、Edgware、Finchley 和 Greenwich 的版本更新。
除了上表中展示的版本对应关系之外,我们还可以使用浏览器访问 https://start.spring.io/actuator/info,获取 Spring Cloud 与 Spring Boot 的版本对应关系(JSON 版)。
{
……
"bom-ranges":{
……
"spring-cloud":{
"Hoxton.SR12":"Spring Boot >=2.2.0.RELEASE and <2.4.0.M1",
"2020.0.4":"Spring Boot >=2.4.0.M1 and <2.5.6-SNAPSHOT",
"2020.0.5-SNAPSHOT":"Spring Boot >=2.5.6-SNAPSHOT and <2.6.0-M1",
"2021.0.0-M1":"Spring Boot >=2.6.0.M1 and <2.6.0-SNAPSHOT",
"2021.0.0-SNAPSHOT":"Spring Boot >=2.6.0-SNAPSHOT"
},
……
},
……
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Eureka:Spring Cloud服务注册与发现组件(非常详细)
Eureka 一词来源于古希腊词汇,是“发现了”的意思。在软件领域,Eureka 是 Netflix 公司开发的一款开源的服务注册与发现组件。
Spring Cloud 将 Eureka 与 Netflix 中的其他开源服务组件(例如 Ribbon、Feign 以及 Hystrix 等)一起整合进 Spring Cloud Netflix 模块中,整合后的组件全称为 Spring Cloud Netflix Eureka。
Eureka 是 Spring Cloud Netflix 模块的子模块,它是 Spring Cloud 对 Netflix Eureka 的二次封装,主要负责 Spring Cloud 的服务注册与发现功能。
Spring Cloud 使用 Spring Boot 思想为 Eureka 增加了自动化配置,开发人员只需要引入相关依赖和注解,就能将 Spring Boot 构建的微服务轻松地与 Eureka 进行整合。
Eureka 两大组件
Eureka 采用 CS(Client/Server,客户端/服务器) 架构,它包括以下两大组件:
- Eureka Server:Eureka 服务注册中心,主要用于提供服务注册功能。当微服务启动时,会将自己的服务注册到 Eureka Server。Eureka Server 维护了一个可用服务列表,存储了所有注册到 Eureka Server 的可用服务的信息,这些可用服务可以在 Eureka Server 的管理界面中直观看到。
- Eureka Client:Eureka 客户端,通常指的是微服务系统中各个微服务,主要用于和 Eureka Server 进行交互。在微服务应用启动后,Eureka Client 会向 Eureka Server 发送心跳(默认周期为 30 秒)。若 Eureka Server 在多个心跳周期内没有接收到某个 Eureka Client 的心跳,Eureka Server 将它从可用服务列表中移除(默认 90 秒)。
注:“心跳”指的是一段定时发送的自定义信息,让对方知道自己“存活”,以确保连接的有效性。大部分 CS 架构的应用程序都采用了心跳机制,服务端和客户端都可以发心跳。通常情况下是客户端向服务器端发送心跳包,服务端用于判断客户端是否在线。
Eureka 服务注册与发现
Eureka 实现服务注册与发现的原理,如下图所示。
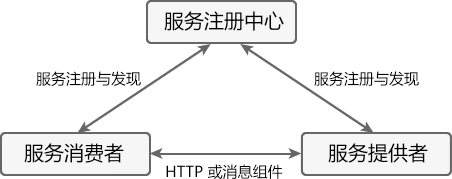
图1:Eureka 原理图
上图中共涉及到以下 3 个角色:
- 服务注册中心(Register Service):它是一个 Eureka Server,用于提供服务注册和发现功能。
- 服务提供者(Provider Service):它是一个 Eureka Client,用于提供服务。它将自己提供的服务注册到服务注册中心,以供服务消费者发现。
- 服务消费者(Consumer Service):它是一个 Eureka Client,用于消费服务。它可以从服务注册中心获取服务列表,调用所需的服务。
Eureka 实现服务注册与发现的流程如下:
- 搭建一个 Eureka Server 作为服务注册中心;
- 服务提供者 Eureka Client 启动时,会把当前服务器的信息以服务名(spring.application.name)的方式注册到服务注册中心;
- 服务消费者 Eureka Client 启动时,也会向服务注册中心注册;
- 服务消费者还会获取一份可用服务列表,该列表中包含了所有注册到服务注册中心的服务信息(包括服务提供者和自身的信息);
- 在获得了可用服务列表后,服务消费者通过 HTTP 或消息中间件远程调用服务提供者提供的服务。
服务注册中心(Eureka Server)所扮演的角色十分重要,它是服务提供者和服务消费者之间的桥梁。服务提供者只有将自己的服务注册到服务注册中心才可能被服务消费者调用,而服务消费者也只有通过服务注册中心获取可用服务列表后,才能调用所需的服务。
Ribbon:Spring Cloud负载均衡与服务调用组件(非常详细)
Spring Cloud Ribbon 是一套基于 Netflix Ribbon 实现的客户端负载均衡和服务调用工具。
Netflix Ribbon 是 Netflix 公司发布的开源组件,其主要功能是提供客户端的负载均衡算法和服务调用。Spring Cloud 将其与 Netflix 中的其他开源服务组件(例如 Eureka、Feign 以及 Hystrix 等)一起整合进 Spring Cloud Netflix 模块中,整合后全称为 Spring Cloud Netflix Ribbon。
Ribbon 是 Spring Cloud Netflix 模块的子模块,它是 Spring Cloud 对 Netflix Ribbon 的二次封装。通过它,我们可以将面向服务的 REST 模板(RestTemplate)请求转换为客户端负载均衡的服务调用。
Ribbon 是 Spring Cloud 体系中最核心、最重要的组件之一。它虽然只是一个工具类型的框架,并不像 Eureka Server(服务注册中心)那样需要独立部署,但它几乎存在于每一个使用 Spring Cloud 构建的微服务中。
Spring Cloud 微服务之间的调用,API 网关的请求转发等内容,实际上都是通过 Spring Cloud Ribbon 来实现的,包括后续我们要介绍的 OpenFeign 也是基于它实现的。
负载均衡
在任何一个系统中,负载均衡都是一个十分重要且不得不去实施的内容,它是系统处理高并发、缓解网络压力和服务端扩容的重要手段之一。
负载均衡(Load Balance) ,简单点说就是将用户的请求平摊分配到多个服务器上运行,以达到扩展服务器带宽、增强数据处理能力、增加吞吐量、提高网络的可用性和灵活性的目的。
常见的负载均衡方式有两种:
- 服务端负载均衡
- 客户端负载均衡
服务端负载均衡
服务端负载均衡是最常见的负载均衡方式,其工作原理如下图。
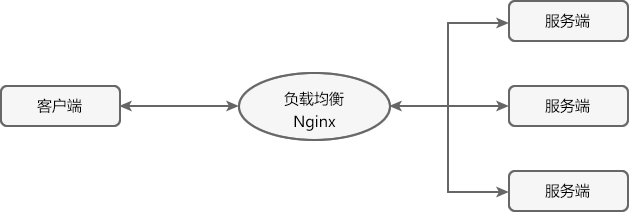
图1:服务端负载均衡工作原理
服务端负载均衡是在客户端和服务端之间建立一个独立的负载均衡服务器,该服务器既可以是硬件设备(例如 F5),也可以是软件(例如 Nginx)。这个负载均衡服务器维护了一份可用服务端清单,然后通过心跳机制来删除故障的服务端节点,以保证清单中的所有服务节点都是可以正常访问的。
当客户端发送请求时,该请求不会直接发送到服务端进行处理,而是全部交给负载均衡服务器,由负载均衡服务器按照某种算法(例如轮询、随机等),从其维护的可用服务清单中选择一个服务端,然后进行转发。
服务端负载均衡具有以下特点:
- 需要建立一个独立的负载均衡服务器。
- 负载均衡是在客户端发送请求后进行的,因此客户端并不知道到底是哪个服务端提供的服务。
- 可用服务端清单存储在负载均衡服务器上。
客户端负载均衡
相较于服务端负载均衡,客户端服务在均衡则是一个比较小众的概念。
客户端负载均衡的工作原理如下图。
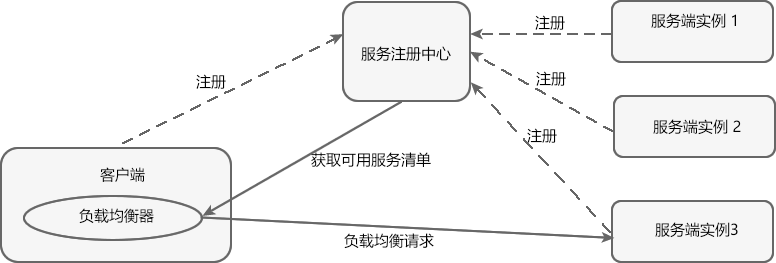
图2:客户端负载均衡工作原理
客户端负载均衡是将负载均衡逻辑以代码的形式封装到客户端上,即负载均衡器位于客户端。客户端通过服务注册中心(例如 Eureka Server)获取到一份服务端提供的可用服务清单。有了服务清单后,负载均衡器会在客户端发送请求前通过负载均衡算法选择一个服务端实例再进行访问,以达到负载均衡的目的;
客户端负载均衡也需要心跳机制去维护服务端清单的有效性,这个过程需要配合服务注册中心一起完成。
客户端负载均衡具有以下特点:
- 负载均衡器位于客户端,不需要单独搭建一个负载均衡服务器。
- 负载均衡是在客户端发送请求前进行的,因此客户端清楚地知道是哪个服务端提供的服务。
- 客户端都维护了一份可用服务清单,而这份清单都是从服务注册中心获取的。
Ribbon 就是一个基于 HTTP 和 TCP 的客户端负载均衡器,当我们将 Ribbon 和 Eureka 一起使用时,Ribbon 会从 Eureka Server(服务注册中心)中获取服务端列表,然后通过负载均衡策略将请求分摊给多个服务提供者,从而达到负载均衡的目的。
服务端负载均衡 VS 客户端负载均衡
下面我们就来对比下,服务端负载均衡和客户端负载均衡到底有什么区别,如下表。
| 不同点 | 服务端负载均衡 | 客户端负载均衡 |
|---|---|---|
| 是否需要建立负载均衡服务器 | 需要在客户端和服务端之间建立一个独立的负载均衡服务器。 | 将负载均衡的逻辑以代码的形式封装到客户端上,因此不需要单独建立负载均衡服务器。 |
| 是否需要服务注册中心 | 不需要服务注册中心。 | 需要服务注册中心。 在客户端负载均衡中,所有的客户端和服务端都需要将其提供的服务注册到服务注册中心上。 |
| 可用服务清单存储的位置 | 可用服务清单存储在位于客户端与服务器之间的负载均衡服务器上。 | 所有的客户端都维护了一份可用服务清单,这些清单都是从服务注册中心获取的。 |
| 负载均衡的时机 | 先将请求发送到负载均衡服务器,然后由负载均衡服务器通过负载均衡算法,在多个服务端之间选择一个进行访问;即在服务器端再进行负载均衡算法分配。 简单点说就是,先发送请求,再进行负载均衡。 | 在发送请求前,由位于客户端的服务负载均衡器(例如 Ribbon)通过负载均衡算法选择一个服务器,然后进行访问。 简单点说就是,先进行负载均衡,再发送请求。 |
| 客户端是否了解服务提供方信息 | 由于负载均衡是在客户端发送请求后进行的,因此客户端并不知道到底是哪个服务端提供的服务。 | 负载均衡是在客户端发送请求前进行的,因此客户端清楚的知道是哪个服务端提供的服务。 |
OpenFeign:Spring Cloud声明式服务调用组件(非常详细)
Netflix Feign 是 Netflix 公司发布的一种实现负载均衡和服务调用的开源组件。Spring Cloud 将其与 Netflix 中的其他开源服务组件(例如 Eureka、Ribbon 以及 Hystrix 等)一起整合进 Spring Cloud Netflix 模块中,整合后全称为 Spring Cloud Netflix Feign。
Feign 对 Ribbon 进行了集成,利用 Ribbon 维护了一份可用服务清单,并通过 Ribbon 实现了客户端的负载均衡。
Feign 是一种声明式服务调用组件,它在 RestTemplate 的基础上做了进一步的封装。通过 Feign,我们只需要声明一个接口并通过注解进行简单的配置(类似于 Dao 接口上面的 Mapper 注解一样)即可实现对 HTTP 接口的绑定。
通过 Feign,我们可以像调用本地方法一样来调用远程服务,而完全感觉不到这是在进行远程调用。
Feign 支持多种注解,例如 Feign 自带的注解以及 JAX-RS 注解等,但遗憾的是 Feign 本身并不支持 Spring MVC 注解,这无疑会给广大 Spring 用户带来不便。
2019 年 Netflix 公司宣布 Feign 组件正式进入停更维护状态,于是 Spring 官方便推出了一个名为 OpenFeign 的组件作为 Feign 的替代方案。
OpenFeign
OpenFeign 全称 Spring Cloud OpenFeign,它是 Spring 官方推出的一种声明式服务调用与负载均衡组件,它的出现就是为了替代进入停更维护状态的 Feign。
OpenFeign 是 Spring Cloud 对 Feign 的二次封装,它具有 Feign 的所有功能,并在 Feign 的基础上增加了对 Spring MVC 注解的支持,例如 @RequestMapping、@GetMapping 和 @PostMapping 等。
OpenFeign 常用注解
使用 OpenFegin 进行远程服务调用时,常用注解如下表。
| 注解 | 说明 |
|---|---|
| @FeignClient | 该注解用于通知 OpenFeign 组件对 @RequestMapping 注解下的接口进行解析,并通过动态代理的方式产生实现类,实现负载均衡和服务调用。 |
| @EnableFeignClients | 该注解用于开启 OpenFeign 功能,当 Spring Cloud 应用启动时,OpenFeign 会扫描标有 @FeignClient 注解的接口,生成代理并注册到 Spring 容器中。 |
| @RequestMapping | Spring MVC 注解,在 Spring MVC 中使用该注解映射请求,通过它来指定控制器(Controller)可以处理哪些 URL 请求,相当于 Servlet 中 web.xml 的配置。 |
| @GetMapping | Spring MVC 注解,用来映射 GET 请求,它是一个组合注解,相当于 @RequestMapping(method = RequestMethod.GET) 。 |
| @PostMapping | Spring MVC 注解,用来映射 POST 请求,它是一个组合注解,相当于 @RequestMapping(method = RequestMethod.POST) 。 |
Spring Cloud Finchley 及以上版本一般使用 OpenFeign 作为其服务调用组件。由于 OpenFeign 是在 2019 年 Feign 停更进入维护后推出的,因此大多数 2019 年及以后的新项目使用的都是 OpenFeign,而 2018 年以前的项目一般使用 Feign。
Feign VS OpenFeign
下面我们就来对比下 Feign 和 OpenFeign 的异同。
相同点
Feign 和 OpenFegin 具有以下相同点:
- Feign 和 OpenFeign 都是 Spring Cloud 下的远程调用和负载均衡组件。
- Feign 和 OpenFeign 作用一样,都可以实现服务的远程调用和负载均衡。
- Feign 和 OpenFeign 都对 Ribbon 进行了集成,都利用 Ribbon 维护了可用服务清单,并通过 Ribbon 实现了客户端的负载均衡。
- Feign 和 OpenFeign 都是在服务消费者(客户端)定义服务绑定接口并通过注解的方式进行配置,以实现远程服务的调用。
不同点
Feign 和 OpenFeign 具有以下不同:
- Feign 和 OpenFeign 的依赖项不同,Feign 的依赖为 spring-cloud-starter-feign,而 OpenFeign 的依赖为 spring-cloud-starter-openfeign。
- Feign 和 OpenFeign 支持的注解不同,Feign 支持 Feign 注解和 JAX-RS 注解,但不支持 Spring MVC 注解;OpenFeign 除了支持 Feign 注解和 JAX-RS 注解外,还支持 Spring MVC 注解。
Hystrix:Spring Cloud服务熔断与降级组件(非常详细)
在微服务架构中,一个应用往往由多个服务组成,这些服务之间相互依赖,依赖关系错综复杂。
例如一个微服务系统中存在 A、B、C、D、E、F 等多个服务,它们的依赖关系如下图。
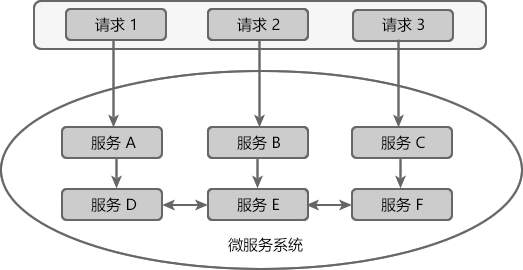
图1:服务依赖关系
通常情况下,一个用户请求往往需要多个服务配合才能完成。如图 1 所示,在所有服务都处于可用状态时,请求 1 需要调用 A、D、E、F 四个服务才能完成,请求 2 需要调用 B、E、D 三个服务才能完成,请求 3 需要调用服务 C、F、E、D 四个服务才能完成。
当服务 E 发生故障或网络延迟时,会出现以下情况:
- 即使其他所有服务都可用,由于服务 E 的不可用,那么用户请求 1、2、3 都会处于阻塞状态,等待服务 E 的响应。在高并发的场景下,会导致整个服务器的线程资源在短时间内迅速消耗殆尽。
- 所有依赖于服务 E 的其他服务,例如服务 B、D 以及 F 也都会处于线程阻塞状态,等待服务 E 的响应,导致这些服务的不可用。
- 所有依赖服务B、D 和 F 的服务,例如服务 A 和服务 C 也会处于线程阻塞状态,以等待服务 D 和服务 F 的响应,导致服务 A 和服务 C 也不可用。
从以上过程可以看出,当微服务系统的一个服务出现故障时,故障会沿着服务的调用链路在系统中疯狂蔓延,最终导致整个微服务系统的瘫痪,这就是“雪崩效应”。为了防止此类事件的发生,微服务架构引入了“熔断器”的一系列服务容错和保护机制。
熔断器
熔断器(Circuit Breaker)一词来源物理学中的电路知识,它的作用是当线路出现故障时,迅速切断电源以保护电路的安全。
在微服务领域,熔断器最早是由 Martin Fowler 在他发表的 《Circuit Breaker》一文中提出。与物理学中的熔断器作用相似,微服务架构中的熔断器能够在某个服务发生故障后,向服务调用方返回一个符合预期的、可处理的降级响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常。这样就保证了服务调用方的线程不会被长时间、不必要地占用,避免故障在微服务系统中的蔓延,防止系统雪崩效应的发生。
Spring Cloud Hystrix
Spring Cloud Hystrix 是一款优秀的服务容错与保护组件,也是 Spring Cloud 中最重要的组件之一。
Spring Cloud Hystrix 是基于 Netflix 公司的开源组件 Hystrix 实现的,它提供了熔断器功能,能够有效地阻止分布式微服务系统中出现联动故障,以提高微服务系统的弹性。Spring Cloud Hystrix 具有服务降级、服务熔断、线程隔离、请求缓存、请求合并以及实时故障监控等强大功能。
Hystrix [hɪst’rɪks],中文含义是豪猪,豪猪的背上长满了棘刺,使它拥有了强大的自我保护能力。而 Spring Cloud Hystrix 作为一个服务容错与保护组件,也可以让服务拥有自我保护的能力,因此也有人将其戏称为“豪猪哥”。
在微服务系统中,Hystrix 能够帮助我们实现以下目标:
- 保护线程资源:防止单个服务的故障耗尽系统中的所有线程资源。
- 快速失败机制:当某个服务发生了故障,不让服务调用方一直等待,而是直接返回请求失败。
- 提供降级(FallBack)方案:在请求失败后,提供一个设计好的降级方案,通常是一个兜底方法,当请求失败后即调用该方法。
- 防止故障扩散:使用熔断机制,防止故障扩散到其他服务。
- 监控功能:提供熔断器故障监控组件 Hystrix Dashboard,随时监控熔断器的状态。
Hystrix 服务降级
Hystrix 提供了服务降级功能,能够保证当前服务不受其他服务故障的影响,提高服务的健壮性。
服务降级的使用场景有以下 2 种:
- 在服务器压力剧增时,根据实际业务情况及流量,对一些不重要、不紧急的服务进行有策略地不处理或简单处理,从而释放服务器资源以保证核心服务正常运作。
- 当某些服务不可用时,为了避免长时间等待造成服务卡顿或雪崩效应,而主动执行备用的降级逻辑立刻返回一个友好的提示,以保障主体业务不受影响。
我们可以通过重写 HystrixCommand 的 getFallBack() 方法或 HystrixObservableCommand 的 resumeWithFallback() 方法,使服务支持服务降级。
Hystrix 服务降级 FallBack 既可以放在服务端进行,也可以放在客户端进行。
Hystrix 会在以下场景下进行服务降级处理:
- 程序运行异常
- 服务超时
- 熔断器处于打开状态
- 线程池资源耗尽
Gateway:Spring Cloud API网关组件(非常详细)
在微服务架构中,一个系统往往由多个微服务组成,而这些服务可能部署在不同机房、不同地区、不同域名下。这种情况下,客户端(例如浏览器、手机、软件工具等)想要直接请求这些服务,就需要知道它们具体的地址信息,例如 IP 地址、端口号等。
这种客户端直接请求服务的方式存在以下问题:
- 当服务数量众多时,客户端需要维护大量的服务地址,这对于客户端来说,是非常繁琐复杂的。
- 在某些场景下可能会存在跨域请求的问题。
- 身份认证的难度大,每个微服务需要独立认证。
我们可以通过 API 网关来解决这些问题,下面就让我们来看看什么是 API 网关。
API 网关
API 网关是一个搭建在客户端和微服务之间的服务,我们可以在 API 网关中处理一些非业务功能的逻辑,例如权限验证、监控、缓存、请求路由等。
API 网关就像整个微服务系统的门面一样,是系统对外的唯一入口。有了它,客户端会先将请求发送到 API 网关,然后由 API 网关根据请求的标识信息将请求转发到微服务实例。
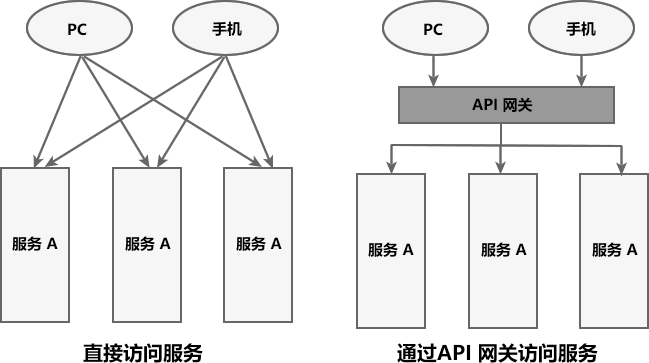
图1:两种服务访问方式对比
对于服务数量众多、复杂度较高、规模比较大的系统来说,使用 API 网关具有以下好处:
- 客户端通过 API 网关与微服务交互时,客户端只需要知道 API 网关地址即可,而不需要维护大量的服务地址,简化了客户端的开发。
- 客户端直接与 API 网关通信,能够减少客户端与各个服务的交互次数。
- 客户端与后端的服务耦合度降低。
- 节省流量,提高性能,提升用户体验。
- API 网关还提供了安全、流控、过滤、缓存、计费以及监控等 API 管理功能。
常见的 API 网关实现方案主要有以下 5 种:
- Spring Cloud Gateway
- Spring Cloud Netflix Zuul
- Kong
- Nginx+Lua
- Traefik
本节,我们就对 Spring Cloud Gateway 进行详细介绍。
Spring Cloud Gateway
Spring Cloud Gateway 是 Spring Cloud 团队基于 Spring 5.0、Spring Boot 2.0 和 Project Reactor 等技术开发的高性能 API 网关组件。
Spring Cloud Gateway 旨在提供一种简单而有效的途径来发送 API,并为它们提供横切关注点,例如:安全性,监控/指标和弹性。
Spring Cloud Gateway 是基于 WebFlux 框架实现的,而 WebFlux 框架底层则使用了高性能的 Reactor 模式通信框架 Netty。
Spring Cloud Gateway 核心概念
Spring Cloud GateWay 最主要的功能就是路由转发,而在定义转发规则时主要涉及了以下三个核心概念,如下表。
| 核心概念 | 描述 |
|---|---|
| Route(路由) | 网关最基本的模块。它由一个 ID、一个目标 URI、一组断言(Predicate)和一组过滤器(Filter)组成。 |
| Predicate(断言) | 路由转发的判断条件,我们可以通过 Predicate 对 HTTP 请求进行匹配,例如请求方式、请求路径、请求头、参数等,如果请求与断言匹配成功,则将请求转发到相应的服务。 |
| Filter(过滤器) | 过滤器,我们可以使用它对请求进行拦截和修改,还可以使用它对上文的响应进行再处理。 |
注意:其中 Route 和 Predicate 必须同时声明。
Spring Cloud Gateway 的特征
Spring Cloud Gateway 具有以下特性:
- 基于 Spring Framework 5、Project Reactor 和 Spring Boot 2.0 构建。
- 能够在任意请求属性上匹配路由。
- predicates(断言) 和 filters(过滤器)是特定于路由的。
- 集成了 Hystrix 熔断器。
- 集成了 Spring Cloud DiscoveryClient(服务发现客户端)。
- 易于编写断言和过滤器。
- 能够限制请求频率。
- 能够重写请求路径。
Gateway 的工作流程
Spring Cloud Gateway 工作流程如下图。
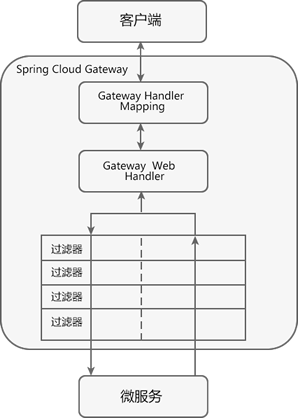
图2:Spring Cloud Gateway 工作流程
Spring Cloud Gateway 工作流程说明如下:
- 客户端将请求发送到 Spring Cloud Gateway 上。
- Spring Cloud Gateway 通过 Gateway Handler Mapping 找到与请求相匹配的路由,将其发送给 Gateway Web Handler。
- Gateway Web Handler 通过指定的过滤器链(Filter Chain),将请求转发到实际的服务节点中,执行业务逻辑返回响应结果。
- 过滤器之间用虚线分开是因为过滤器可能会在转发请求之前(pre)或之后(post)执行业务逻辑。
- 过滤器(Filter)可以在请求被转发到服务端前,对请求进行拦截和修改,例如参数校验、权限校验、流量监控、日志输出以及协议转换等。
- 过滤器可以在响应返回客户端之前,对响应进行拦截和再处理,例如修改响应内容或响应头、日志输出、流量监控等。
- 响应原路返回给客户端。
总而言之,客户端发送到 Spring Cloud Gateway 的请求需要通过一定的匹配条件,才能定位到真正的服务节点。在将请求转发到服务进行处理的过程前后(pre 和 post),我们还可以对请求和响应进行一些精细化控制。
Predicate 就是路由的匹配条件,而 Filter 就是对请求和响应进行精细化控制的工具。有了这两个元素,再加上目标 URI,就可以实现一个具体的路由了。
Predicate 断言
Spring Cloud Gateway 通过 Predicate 断言来实现 Route 路由的匹配规则。简单点说,Predicate 是路由转发的判断条件,请求只有满足了 Predicate 的条件,才会被转发到指定的服务上进行处理。
使用 Predicate 断言需要注意以下 3 点:
- Route 路由与 Predicate 断言的对应关系为“一对多”,一个路由可以包含多个不同断言。
- 一个请求想要转发到指定的路由上,就必须同时匹配路由上的所有断言。
- 当一个请求同时满足多个路由的断言条件时,请求只会被首个成功匹配的路由转发。
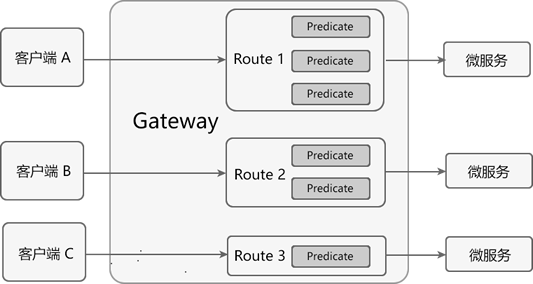
图3:Predicate 断言匹配
常见的 Predicate 断言如下表(假设转发的 URI 为 http://localhost:8001)。
| 断言 | 示例 | 说明 |
|---|---|---|
| Path | - Path=/dept/list/** | 当请求路径与 /dept/list/** 匹配时,该请求才能被转发到 http://localhost:8001 上。 |
| Before | - Before=2021-10-20T11:47:34.255+08:00[Asia/Shanghai] | 在 2021 年 10 月 20 日 11 时 47 分 34.255 秒之前的请求,才会被转发到 http://localhost:8001 上。 |
| After | - After=2021-10-20T11:47:34.255+08:00[Asia/Shanghai] | 在 2021 年 10 月 20 日 11 时 47 分 34.255 秒之后的请求,才会被转发到 http://localhost:8001 上。 |
| Between | - Between=2021-10-20T15:18:33.226+08:00[Asia/Shanghai],2021-10-20T15:23:33.226+08:00[Asia/Shanghai] | 在 2021 年 10 月 20 日 15 时 18 分 33.226 秒 到 2021 年 10 月 20 日 15 时 23 分 33.226 秒之间的请求,才会被转发到 http://localhost:8001 服务器上。 |
| Cookie | - Cookie=name,c.biancheng.net | 携带 Cookie 且 Cookie 的内容为 name=c.biancheng.net 的请求,才会被转发到 http://localhost:8001 上。 |
| Header | - Header=X-Request-Id,\d+ | 请求头上携带属性 X-Request-Id 且属性值为整数的请求,才会被转发到 http://localhost:8001 上。 |
| Method | - Method=GET | 只有 GET 请求才会被转发到 http://localhost:8001 上。 |
Config:Spring Cloud分布式配置组件(非常详细)
在分布式微服务系统中,几乎所有服务的运行都离不开配置文件的支持,这些配置文件通常由各个服务自行管理,以 properties 或 yml 格式保存在各个微服务的类路径下,例如 application.properties 或 application.yml 等。
这种将配置文件散落在各个服务中的管理方式,存在以下问题:
- 管理难度大:配置文件散落在各个微服务中,难以管理。
- 安全性低:配置跟随源代码保存在代码库中,容易造成配置泄漏。
- 时效性差:微服务中的配置修改后,必须重启服务,否则无法生效。
- 局限性明显:无法支持动态调整,例如日志开关、功能开关。
为了解决这些问题,通常我们都会使用配置中心对配置进行统一管理。市面上开源的配置中心有很多,例如百度的 Disconf、淘宝的 diamond、360 的 QConf、携程的 Apollo 等都是解决这类问题的。Spring Cloud 也有自己的分布式配置中心,那就是 Spring Cloud Config。
Spring Cloud Config
Spring Cloud Config 是由 Spring Cloud 团队开发的项目,它可以为微服务架构中各个微服务提供集中化的外部配置支持。
简单点说就是,Spring Cloud Config 可以将各个微服务的配置文件集中存储在一个外部的存储仓库或系统(例如 Git 、SVN 等)中,对配置的统一管理,以支持各个微服务的运行。
Spring Cloud Config 包含以下两个部分:
- Config Server:也被称为分布式配置中心,它是一个独立运行的微服务应用,用来连接配置仓库并为客户端提供获取配置信息、加密信息和解密信息的访问接口。
- Config Client:指的是微服务架构中的各个微服务,它们通过 Config Server 对配置进行管理,并从 Config Sever 中获取和加载配置信息。
Spring Cloud Config 默认使用 Git 存储配置信息,因此使用 Spirng Cloud Config 构建的配置服务器天然就支持对微服务配置的版本管理。我们可以使用 Git 客户端工具方便地对配置内容进行管理和访问。除了 Git 外,Spring Cloud Config 还提供了对其他存储方式的支持,例如 SVN、本地化文件系统等。
Spring Cloud Config 工作原理
Spring Cloud Config 工作原理如下图。
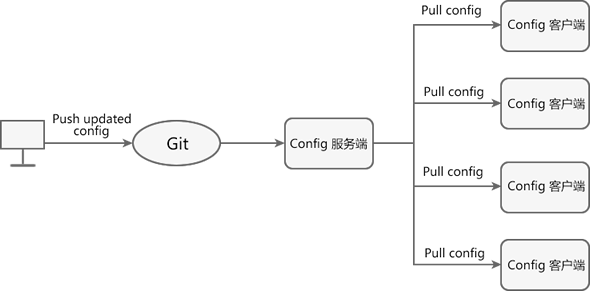
图1:Spring Cloud Config 工作原理
Spring Cloud Config 工作流程如下:
- 开发或运维人员提交配置文件到远程的 Git 仓库。
- Config 服务端(分布式配置中心)负责连接配置仓库 Git,并对 Config 客户端暴露获取配置的接口。
- Config 客户端通过 Config 服务端暴露出来的接口,拉取配置仓库中的配置。
- Config 客户端获取到配置信息,以支持服务的运行。
Spring Cloud Config 的特点
Spring Cloud Config 具有以下特点:
- Spring Cloud Config 由 Spring Cloud 团队开发,可以说是 Spring 的亲儿子,能够与 Spring 的生态体系无缝集成。
- Spring Cloud Config 将所有微服务的配置文件集中存储在一个外部的存储仓库或系统(例如 Git)中,统一管理。
- Spring Cloud Config 配置中心将配置以 REST 接口的形式暴露给各个微服务,以方便各个微服务获取。
- 微服务可以通过 Spring Cloud Config 向配置中心统一拉取属于它们自己的配置信息。
- 当配置发生变化时,微服务不需要重启即可感知到配置的变化,并自动获取和应用最新配置。
- 一个应用可能有多个环境,例如开发(dev)环境、测试(test)环境、生产(prod)环境等等,开发人员可以通过 Spring Cloud Config 对不同环境的各配置进行管理,且能够确保应用在环境迁移后仍然有完整的配置支持其正常运行。
Spring Cloud Alibaba是什么
Spring Cloud 本身并不是一个拿来即可用的框架,它是一套微服务规范,这套规范共有两代实现。
- 第一代实现: Spring Cloud Netflix,
- 第二代实现: Spring Cloud Alibaba。
2018 年 12 月12 日,Netflix 公司宣布 Spring Cloud Netflix 系列大部分组件都进入维护模式,不再添加新特性。这严重地限制了 Spring Cloud 的高速发展,于是各大互联网公司和组织开始把目光转向 Spring Cloud 的第二代实现:Spring Cloud Alibaba。
Spring Cloud Alibaba
Spring Cloud Alibaba 是阿里巴巴结合自身丰富的微服务实践而推出的微服务开发的一站式解决方案,是 Spring Cloud 第二代实现的主要组成部分。
Spring Cloud Alibaba 吸收了 Spring Cloud Netflix 的核心架构思想,并进行了高性能改进。自 Spring Cloud Netflix 进入停更维护后,Spring Cloud Alibaba 逐渐代替它成为主流的微服务框架。
Spring Cloud Alibaba 是国内首个进入 Spring 社区的开源项目。2018 年 7 月,Spring Cloud Alibaba 正式开源,并进入 Spring Cloud 孵化器中孵化;2019 年 7 月,Spring Cloud 官方宣布 Spring Cloud Alibaba 毕业,并将仓库迁移到 Alibaba Github OSS 下。
虽然 Spring Cloud Alibaba 诞生时间不久,但俗话说的好“大树底下好乘凉”,依赖于阿里巴巴强大的技术影响力,Spring Cloud Alibaba 在业界得到了广泛的使用,成功案例也越来越多。
Spring Cloud Alibaba 组件
Spring Cloud Alibaba 包含了多种开发分布式微服务系统的必需组件
- Nacos:阿里巴巴开源产品,一个更易于构建云原生应用的动态服务发现,配置管理和服务管理平台。
- Sentinel:阿里巴巴开源产品,把流量作为切入点,从流量控制,熔断降级,系统负载保护等多个维度保护服务的稳定性。
- RocketMQ:Apache RocketMQ 是一款基于Java 的高性能、高吞吐量的分布式消息和流计算平台。
- Dubbo:Apache Dubbo 是一款高性能的 Java RPC 框架。
- Seata:阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。
- Alibaba Cloud OSS:阿里云对象存储服务器(Object Storage Service,简称OSS),是阿里云提供的海量、安全、低成本、高可靠的云存储服务。
- Alibaba Cloud Schedulerx:阿里中间件团队开发的一款分布式调度产品,支持周期性的任务与固定时间点触发任务。
通过 Spring Cloud Alibaba 的这些组件,我们只需要添加一些注解和少量配置,就可以将 Spring Cloud 应用接入阿里微服务解决方案,通过阿里中间件来迅速搭建分布式应用系统。
Spring Cloud Alibaba 的应用场景
Spring Cloud Alibaba 的应用场景如下:
- 大型复杂的系统,例如大型电商系统。
- 高并发系统,例如大型门户网站、商品秒杀系统。
- 需求不明确,且变更很快的系统,例如创业公司业务系统。
Spring Cloud 两代实现组件对比
下表展示了 Spring Cloud 两代实现的组件对比情况。
| Spring Cloud 第一代实现(Netflix) | 状态 | Spring Cloud 第二代实现(Alibaba) | 状态 |
|---|---|---|---|
| Ereka | 2.0 孵化失败 | Nacos Discovery | 性能更好,感知力更强 |
| Ribbon | 停更进维 | Spring Cloud Loadbalancer | Spring Cloud 原生组件,用于代替 Ribbon |
| Hystrix | 停更进维 | Sentinel | 可视化配置,上手简单 |
| Zuul | 停更进维 | Spring Cloud Gateway | 性能为 Zuul 的 1.6 倍 |
| Spring Cloud Config | 搭建过程复杂,约定过多,无可视化界面,上手难点大 | Nacos Config | 搭建过程简单,有可视化界面,配置管理更简单,容易上手 |
Spring Cloud Alibaba 版本依赖
Spring Cloud、Spring Cloud Alibaba 以及 Spring Boot 之间版本依赖关系如下。
| Spring Cloud 版本 | Spring Cloud Alibaba 版本 | Spring Boot 版本 |
|---|---|---|
| Spring Cloud 2020.0.1 | 2021.1 | 2.4.2 |
| Spring Cloud Hoxton.SR12 | 2.2.7.RELEASE | 2.3.12.RELEASE |
| Spring Cloud Hoxton.SR9 | 2.2.6.RELEASE | 2.3.2.RELEASE |
| Spring Cloud Greenwich.SR6 | 2.1.4.RELEASE | 2.1.13.RELEASE |
| Spring Cloud Hoxton.SR3 | 2.2.1.RELEASE | 2.2.5.RELEASE |
| Spring Cloud Hoxton.RELEASE | 2.2.0.RELEASE | 2.2.X.RELEASE |
| Spring Cloud Greenwich | 2.1.2.RELEASE | 2.1.X.RELEASE |
| Spring Cloud Finchley | 2.0.4.RELEASE(停止维护,建议升级) | 2.0.X.RELEASE |
| Spring Cloud Edgware | 1.5.1.RELEASE(停止维护,建议升级) | 1.5.X.RELEASE |
Spring Cloud Alibaba 组件版本关系
Spring Cloud Alibaba 下各组件版本关系如下表。
| Spring Cloud Alibaba 版本 | Sentinel 版本 | Nacos 版本 | RocketMQ 版本 | Dubbo 版本 | Seata 版本 |
|---|---|---|---|---|---|
| 2.2.7.RELEASE | 1.8.1 | 2.0.3 | 4.6.1 | 2.7.13 | 1.3.0 |
| 2.2.6.RELEASE | 1.8.1 | 1.4.2 | 4.4.0 | 2.7.8 | 1.3.0 |
| 2021.1 or 2.2.5.RELEASE or 2.1.4.RELEASE or 2.0.4.RELEASE | 1.8.0 | 1.4.1 | 4.4.0 | 2.7.8 | 1.3.0 |
| 2.2.3.RELEASE or 2.1.3.RELEASE or 2.0.3.RELEASE | 1.8.0 | 1.3.3 | 4.4.0 | 2.7.8 | 1.3.0 |
| 2.2.1.RELEASE or 2.1.2.RELEASE or 2.0.2.RELEASE | 1.7.1 | 1.2.1 | 4.4.0 | 2.7.6 | 1.2.0 |
| 2.2.0.RELEASE | 1.7.1 | 1.1.4 | 4.4.0 | 2.7.4.1 | 1.0.0 |
| 2.1.1.RELEASE or 2.0.1.RELEASE or 1.5.1.RELEASE | 1.7.0 | 1.1.4 | 4.4.0 | 2.7.3 | 0.9.0 |
| 2.1.0.RELEASE or 2.0.0.RELEASE or 1.5.0.RELEASE | 1.6.3 | 1.1.1 | 4.4.0 | 2.7.3 | 0.7.1 |
Nacos:Spring Cloud Alibaba服务注册与配置中心(非常详细)
Nacos 英文全称为 Dynamic Naming and Configuration Service,是一个由阿里巴巴团队使用 Java 语言开发的开源项目。
Nacos 是一个更易于帮助构建云原生应用的动态服务发现、配置和服务管理平台(参考自 Nacos 官网)。
Nacos 的命名是由 3 部分组成:
| 组成部分 | 全称 | 描述 |
|---|---|---|
| Na | naming/nameServer | 即服务注册中心,与 Spring Cloud Eureka 的功能类似。 |
| co | configuration | 即配置中心,与 Spring Cloud Config+Spring Cloud Bus 的功能类似。 |
| s | service | 即服务,表示 Nacos 实现的服务注册中心和配置中心都是以服务为核心的。 |
我们可以将 Nacos 理解成服务注册中心和配置中心的组合体,它可以替换 Eureka 作为服务注册中心,实现服务的注册与发现;还可以替换 Spring Cloud Config 作为配置中心,实现配置的动态刷新。
Nacos 作为服务注册中心经历了十年“双十一”的洪峰考验,具有简单易用、稳定可靠、性能卓越等优点,可以帮助用户更敏捷、容易地构建和管理微服务应用。
Nacos 支持几乎所有主流类型“服务”的发现、配置和管理:
- Kubernetes Service
- gRPC & Dubbo RPC Service
- Spring Cloud RESTful Service
Nacos 的特性
Nacos 提供了一系列简单易用的特性,能够帮助我们快速地实现动态服务发现、服务配置等功能。
服务发现
Nacos 支持基于 DNS 和 RPC 的服务发现。当服务提供者使用原生 SDK、OpenAPI 或一个独立的 Agent TODO 向 Nacos 注册服务后,服务消费者可以在 Nacos 上通过 DNS TODO 或 HTTP&API 查找、发现服务。
服务健康监测
Nacos 提供对服务的实时健康检查,能够阻止请求发送到不健康主机或服务实例上。Nacos 还提供了一个健康检查仪表盘,能够帮助我们根据健康状态管理服务的可用性及流量。
动态配置服务
动态配置服务可以让我们以中心化、外部化和动态化的方式,管理所有环境的应用配置和服务配置。
动态配置消除了配置变更时重新部署应用和服务的需要,让配置管理变得更加高效、敏捷。
配置中心化管理让实现无状态服务变得更简单,让服务按需弹性扩展变得更容易。
Nacos 提供了一个简洁易用的 UI 帮助我们管理所有服务和应用的配置。Nacos 还提供包括配置版本跟踪、金丝雀发布、一键回滚配置以及客户端配置更新状态跟踪在内的一系列开箱即用的配置管理特性,帮助我们更安全地在生产环境中管理配置变更和降低配置变更带来的风险。
动态 DNS 服务
Nacos 提供了动态 DNS 服务,能够让我们更容易地实现负载均衡、流量控制以及数据中心内网的简单 DNS 解析服务。
Nacos 提供了一些简单的 DNS APIs TODO,可以帮助我们管理服务的关联域名和可用的 IP:PORT 列表。
服务及其元数据管理
Nacos 能让我们从微服务平台建设的视角管理数据中心的所有服务及元数据,包括管理服务的描述、生命周期、服务的静态依赖分析、服务的健康状态、服务的流量管理、路由及安全策略、服务的 SLA 以及 metrics 统计数据。
Nacos 两大组件
与 Eureka 类似,Nacos 也采用 CS(Client/Server,客户端/服务器)架构,它包含两大组件,如下表。
、
| 组件 | 描述 | 功能 |
|---|---|---|
| Nacos Server | Nacos 服务端,与 Eureka Server 不同,Nacos Server 由阿里巴巴团队使用 Java 语言编写并将 Nacos Server 的下载地址给用户,用户只需要直接下载并运行即可。 | Nacos Server 可以作为服务注册中心,帮助 Nacos Client 实现服务的注册与发现。 |
| Nacos Server 可以作为配置中心,帮助 Nacos Client 在不重启的情况下,实现配置的动态刷新。 | ||
| Nacos Client | Nacos 客户端,通常指的是微服务架构中的各个服务,由用户自己搭建,可以使用多种语言编写。 | Nacos Client 通过添加依赖 spring-cloud-starter-alibaba-nacos-discovery,在服务注册中心(Nacos Server)中实现服务的注册与发现。 |
| Nacos Client 通过添加依赖 spring-cloud-starter-alibaba-nacos-config,在配置中心(Nacos Server)中实现配置的动态刷新。 |
Nacos 服务注册中心
Nacos 作为服务注册中心可以实现服务的注册与发现,流程如下图。
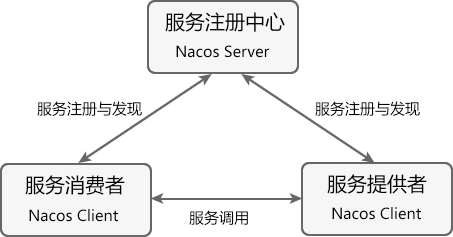
图1:Nacos 服务注册与发现
在图 1 中共涉及到以下 3 个角色:
- 服务注册中心(Register Service):它是一个 Nacos Server,可以为服务提供者和服务消费者提供服务注册和发现功能。
- 服务提供者(Provider Service):它是一个 Nacos Client,用于对外服务。它将自己提供的服务注册到服务注册中心,以供服务消费者发现和调用。
- 服务消费者(Consumer Service):它是一个 Nacos Client,用于消费服务。它可以从服务注册中心获取服务列表,调用所需的服务。
Nacos 实现服务注册与发现的流程如下:
- 从 Nacos 官方提供的下载页面中,下载 Nacos Server 并运行。
- 服务提供者 Nacos Client 启动时,会把服务以服务名(spring.application.name)的方式注册到服务注册中心(Nacos Server);
- 服务消费者 Nacos Client 启动时,也会将自己的服务注册到服务注册中心;
- 服务消费者在注册服务的同时,它还会从服务注册中心获取一份服务注册列表信息,该列表中包含了所有注册到服务注册中心上的服务的信息(包括服务提供者和自身的信息);
- 在获取了服务提供者的信息后,服务消费者通过 HTTP 或消息中间件远程调用服务提供者提供的服务。
安装和运行 Nacos Server
下面我们以 Nacos 2.0.3 为例,演示下如何安装和运行 Nacos Server,步骤如下。
\1. 使用浏览器访问 Nacos Server 下载页面,并在页面最下方点击链接 nacos-server-2.0.3.zip,如下图。
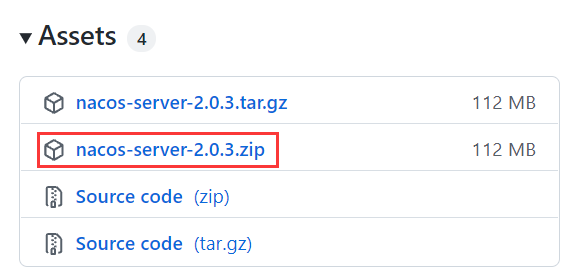
图2:Nacos Server 下载
\2. 下载完成后,解压 nacos-server-2.0.3.zip,目录结构如下。
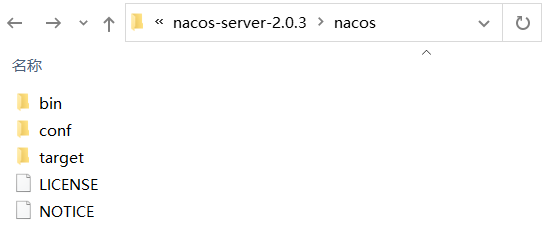
图3:Nacos Server 目录结构
Nacos Server 下各目录说明如下:
- bin:用于存放 Nacos 的可执行命令。
- conf:用于存放 Nacos 配置文件。
- target:用于存放 Nacos 应用的 jar 包。
\3. 打开命令行窗口,跳转到 Nacos Server 安装目录的 bin 下,执行以下命令,以单机模式启动 Nacos Server。
startup.cmd -m standalone
- 1
\4. Nacos Server 启动日志如下。
"nacos is starting with standalone" ,--. ,--.'| ,--,: : | Nacos 2.0.3 ,`--.'`| ' : ,---. Running in stand alone mode, All function modules | : : | | ' ,'\ .--.--. Port: 8848 : | \ | : ,--.--. ,---. / / | / / ' Pid: 27512 | : ' '; | / \ / \. ; ,. :| : /`./ Console: http://192.168.3.138:8848/nacos/index.html ' ' ;. ;.--. .-. | / / '' | |: :| : ;_ | | | \ | \__\/: . .. ' / ' | .; : \ \ `. https://nacos.io ' : | ; .' ," .--.; |' ; :__| : | `----. \ | | '`--' / / ,. |' | '.'|\ \ / / /`--' / ' : | ; : .' \ : : `----' '--'. / ; |.' | , .-./\ \ / `--'---' '---' `--`---' `----' 2021-11-08 16:16:38,877 INFO Bean 'org.springframework.security.access.expression.method.DefaultMethodSecurityExpressionHandler@5ab9b447' of type [org.springframework.security.access.expression.method .DefaultMethodSecurityExpressionHandler] is not eligible for getting processed by all BeanPostProcessors (for example: not eligible for auto-proxying) 2021-11-08 16:16:38,884 INFO Bean 'methodSecurityMetadataSource' of type [org.springframework.security.access.method.DelegatingMethodSecurityMetadataSource] is not eligible for getting processed by al l BeanPostProcessors (for example: not eligible for auto-proxying) 2021-11-08 16:16:40,001 INFO Tomcat initialized with port(s): 8848 (http) 2021-11-08 16:16:40,713 INFO Root WebApplicationContext: initialization completed in 14868 ms 2021-11-08 16:16:52,351 INFO Initializing ExecutorService 'applicationTaskExecutor' 2021-11-08 16:16:52,560 INFO Adding welcome page: class path resource [static/index.html] 2021-11-08 16:16:54,239 INFO Creating filter chain: Ant [pattern='/**'], [] 2021-11-08 16:16:54,344 INFO Creating filter chain: any request, [org.springframework.security.web.context.request.async.WebAsyncManagerIntegrationFilter@7dd611c8, org.springframework.security.web.con text.SecurityContextPersistenceFilter@5c7668ba, org.springframework.security.web.header.HeaderWriterFilter@fb713e7, org.springframework.security.web.csrf.CsrfFilter@6ec7bce0, org.springframework.secur ity.web.authentication.logout.LogoutFilter@7d9ba6c, org.springframework.security.web.savedrequest.RequestCacheAwareFilter@158f4cfe, org.springframework.security.web.servletapi.SecurityContextHolderAwa reRequestFilter@6c6333cd, org.springframework.security.web.authentication.AnonymousAuthenticationFilter@5d425813, org.springframework.security.web.session.SessionManagementFilter@13741d5a, org.springf ramework.security.web.access.ExceptionTranslationFilter@3727f0ee] 2021-11-08 16:16:54,948 INFO Initializing ExecutorService 'taskScheduler' 2021-11-08 16:16:54,977 INFO Exposing 16 endpoint(s) beneath base path '/actuator' 2021-11-08 16:16:55,309 INFO Tomcat started on port(s): 8848 (http) with context path '/nacos' 2021-11-08 16:16:55,319 INFO Nacos started successfully in stand alone mode. use embedded storage

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
\5. 使用浏览器访问“http://localhost:8848/nacos”,跳转到 Nacos Server 登陆页面,如下图。
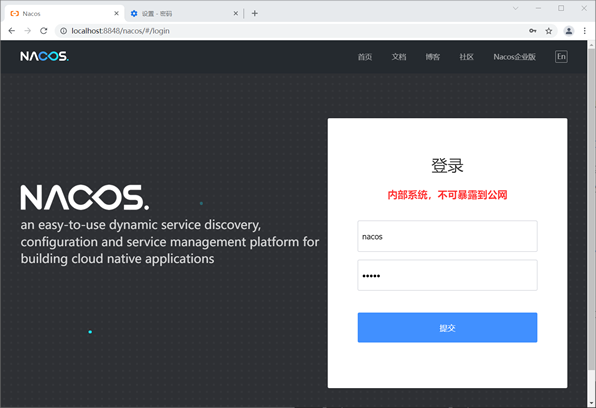
图4:Nacos Server 登陆页面
\6. 在登陆页输入登录名和密码(默认都是 nacos),点击提交按钮,跳转到 Nacos Server 控制台主页,如下图。
图5:Nacos Server 控制台
自此,我们就完成了 Nacos Server 的下载、安装和运行工作。
搭建服务提供者
接下来,我们来搭建一个服务提供者,步骤如下。
Sentinel:Spring Cloud Alibaba高可用流量控制组件(非常详细)
Sentinel 是由阿里巴巴中间件团队开发的开源项目,是一种面向分布式微服务架构的轻量级高可用流量控制组件。
Sentinel 主要以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度帮助用户保护服务的稳定性。
Sentinel 具有以下优势:
- 丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的“双十一”大促流量的核心场景,例如秒杀(将突发流量控制在系统可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用服务等。
- 完备的实时监控:Sentinel 提供了实时监控功能。用户可以在控制台中看到接入应用的单台机器的秒级数据,甚至是 500 台以下规模集群的汇总运行情况。
- 广泛的开源生态:Sentinel 提供了开箱即用的与其它开源框架或库(例如 Spring Cloud、Apache Dubbo、gRPC、Quarkus)的整合模块。我们只要在项目中引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。此外,Sentinel 还提供 Java、Go 以及 C++ 等多语言的原生实现。
- 完善的 SPI 扩展机制:Sentinel 提供简单易、完善的 SPI 扩展接口,我们可以通过实现这些扩展接口快速地定制逻辑,例如定制规则管理、适配动态数据源等。
SPI ,全称为 Service Provider Interface,是一种服务发现机制。它可以在 ClassPath 路径下的 META-INF/services 文件夹查找文件,并自动加载文件中定义的类。
从功能上来说,Sentinel 与 Spring Cloud Netfilx Hystrix 类似,但 Sentinel 要比 Hystrix 更加强大,例如 Sentinel 提供了流量控制功能、比 Hystrix 更加完善的实时监控功能等等。
Sentinel 的组成
Sentinel 主要由以下两个部分组成:
- Sentinel 核心库:Sentinel 的核心库不依赖任何框架或库,能够运行于 Java 8 及以上的版本的运行时环境中,同时对 Spring Cloud、Dubbo 等微服务框架提供了很好的支持。
- Sentinel 控制台(Dashboard):Sentinel 提供的一个轻量级的开源控制台,它为用户提供了机器自发现、簇点链路自发现、监控、规则配置等功能。
Sentinel 核心库不依赖 Sentinel Dashboard,但两者结合使用可以有效的提高效率,让 Sentinel 发挥它最大的作用。
Sentinel 的基本概念
Sentinel 的基本概念有两个,它们分别是:资源和规则。
| 基本概念 | 描述 |
|---|---|
| 资源 | 资源是 Sentinel 的关键概念。它可以是 Java 应用程序中的任何内容,例如由应用程序提供的服务或者是服务里的方法,甚至可以是一段代码。 我们可以通过 Sentinel 提供的 API 来定义一个资源,使其能够被 Sentinel 保护起来。通常情况下,我们可以使用方法名、URL 甚至是服务名来作为资源名来描述某个资源。 |
| 规则 | 围绕资源而设定的规则。Sentinel 支持流量控制、熔断降级、系统保护、来源访问控制和热点参数等多种规则,所有这些规则都可以动态实时调整。 |
@SentinelResource 注解
@SentinelResource 注解是 Sentinel 提供的最重要的注解之一,它还包含了多个属性,如下表。
| 属性 | 说明 | 必填与否 | 使用要求 |
|---|---|---|---|
| value | 用于指定资源的名称 | 必填 | - |
| entryType | entry 类型 | 可选项(默认为 EntryType.OUT) | - |
| blockHandler | 服务限流后会抛出 BlockException 异常,而 blockHandler 则是用来指定一个函数来处理 BlockException 异常的。 简单点说,该属性用于指定服务限流后的后续处理逻辑。 | 可选项 | blockHandler 函数访问范围需要是 public;返回类型需要与原方法相匹配;参数类型需要和原方法相匹配并且最后加一个额外的参数,类型为 BlockException;blockHandler 函数默认需要和原方法在同一个类中,若希望使用其他类的函数,则可以指定 blockHandler 为对应的类的 Class 对象,注意对应的函数必需为 static 函数,否则无法解析。 |
| blockHandlerClass | 若 blockHandler 函数与原方法不在同一个类中,则需要使用该属性指定 blockHandler 函数所在的类。 | 可选项 | 不能单独使用,必须与 blockHandler 属性配合使用;该属性指定的类中的 blockHandler 函数必须为 static 函数,否则无法解析。 |
| fallback | 用于在抛出异常(包括 BlockException)时,提供 fallback 处理逻辑。 fallback 函数可以针对所有类型的异常(除了 exceptionsToIgnore 里面排除掉的异常类型)进行处理。 | 可选项 | 返回值类型必须与原函数返回值类型一致;方法参数列表需要和原函数一致,或者可以额外多一个 Throwable 类型的参数用于接收对应的异常;fallback 函数默认需要和原方法在同一个类中,若希望使用其他类的函数,则可以指定 fallbackClass 为对应的类的 Class 对象,注意对应的函数必需为 static 函数,否则无法解析。 |
| fallbackClass | 若 fallback 函数与原方法不在同一个类中,则需要使用该属性指定 blockHandler 函数所在的类。 | 可选项 | 不能单独使用,必须与 fallback 或 defaultFallback 属性配合使用;该属性指定的类中的 fallback 函数必须为 static 函数,否则无法解析。 |
| defaultFallback | 默认的 fallback 函数名称,通常用于通用的 fallback 逻辑(即可以用于很多服务或方法)。 默认 fallback 函数可以针对所以类型的异常(除了 exceptionsToIgnore 里面排除掉的异常类型)进行处理。 | 可选项 | 返回值类型必须与原函数返回值类型一致;方法参数列表需要为空,或者可以额外多一个 Throwable 类型的参数用于接收对应的异常;defaultFallback 函数默认需要和原方法在同一个类中。若希望使用其他类的函数,则可以指定 fallbackClass 为对应的类的 Class 对象,注意对应的函数必需为 static 函数,否则无法解析。 |
| exceptionsToIgnore | 用于指定哪些异常被排除掉,不会计入异常统计中,也不会进入 fallback 逻辑中,而是会原样抛出。 | 可选项 | - |
注:在 Sentinel 1.6.0 之前,fallback 函数只针对降级异常(DegradeException)进行处理,不能处理业务异常。
Sentinel 控制台
Sentinel 提供了一个轻量级的开源控制台 Sentinel Dashboard,它提供了机器发现与健康情况管理、监控(单机和集群)、规则管理与推送等多种功能。
Sentinel 控制台提供的功能如下:
- 查看机器列表以及健康情况:Sentinel 控制台能够收集 Sentinel 客户端发送的心跳包,判断机器是否在线。
- 监控(单机和集群聚合):Sentinel 控制台通过 Sentinel 客户端暴露的监控 API,可以实现秒级的实时监控。
- 规则管理和推送:通过 Sentinel 控制台,我们还能够针对资源定义和推送规则。
- 鉴权:从 Sentinel 1.6.0 起,Sentinel 控制台引入基本的登录功能,默认用户名和密码都是 sentinel。
Sentinel Dashboard 是我们配置和管理规则(例如流控规则、熔断降级规则等)的重要入口之一。通过它,我们不仅可以对规则进行配置和管理,还能实时查看规则的效果。
安装 Sentinel 控制台
下面我们就来演示下,如何下载和安装 Sentinel 控制台,具体步骤如下。
\1. 使用浏览器访问 Sentinel Dashboard 下载页面下载 Sentinel 控制台的 jar 包,如下图。
图1:Sentinel 控制台下载
\2. 打开命令行窗口,跳转到 Sentinel Dashboard jar 包所在的目录,执行以下命令,启动 Sentinel Dashboard。
java -jar sentinel-dashboard-1.8.2.jar
- 1
\3. 启动完成后,使用浏览器访问“http://localhost:8080/”,跳转到 Sentinel 控制台登陆页面,如下图。

图2:Sentinel 控制台登录页
\4. 分别输入用户名和密码(默认都是 sentinel),点击下方的登录按钮,结果如下图。
图3:Sentinel 控制台主页
Sentinel 的开发流程
Sentinel 的开发流程如下:
- 引入 Sentinel 依赖:在项目中引入 Sentinel 的依赖,将 Sentinel 整合到项目中;
- 定义资源:通过对主流框架提供适配或 Sentinel 提供的显式 API 和注解,可以定义需要保护的资源,此外 Sentinel 还提供了资源的实时统计和调用链路分析;
- 定义规则:根据实时统计信息,对资源定义规则,例如流控规则、熔断规则、热点规则、系统规则以及授权规则等。
- 检验规则是否在生效:运行程序,检验规则是否生效,查看效果。
引入 Sentinel 依赖
为了减少开发的复杂程度,Sentinel 对大部分的主流框架都进行了适配,例如 Web Servlet、Dubbo、Spring Cloud、gRPC、Spring WebFlux 和 Reactor 等。以 Spring Cloud 为例,我们只需要引入 spring-cloud-starter-alibaba-sentinel 的依赖,就可以方便地将 Sentinel 整合到项目中。
下面我们就通过一个简单的实例,演示如何将 Sentinel 整合到 Spring Cloud 项目中,步骤如下。
Seata:Spring Cloud Alibaba分布式事务组件(非常详细)
随着业务的不断发展,单体架构已经无法满足我们的需求,分布式微服务架构逐渐成为大型互联网平台的首选,但所有使用分布式微服务架构的应用都必须面临一个十分棘手的问题,那就是“分布式事务”问题。
在分布式微服务架构中,几乎所有业务操作都需要多个服务协作才能完成。对于其中的某个服务而言,它的数据一致性可以交由其自身数据库事务来保证,但从整个分布式微服务架构来看,其全局数据的一致性却是无法保证的。
例如,用户在某电商系统下单购买了一件商品后,电商系统会执行下 4 步:
- 调用订单服务创建订单数据
- 调用库存服务扣减库存
- 调用账户服务扣减账户金额
- 最后调用订单服务修改订单状态
为了保证数据的正确性和一致性,我们必须保证所有这些操作要么全部成功,要么全部失败,否则就可能出现类似于商品库存已扣减,但用户账户资金尚未扣减的情况。各服务自身的事务特性显然是无法实现这一目标的,此时,我们可以通过分布式事务框架来解决这个问题。
Seata 就是这样一个分布式事务处理框架,它是由阿里巴巴和蚂蚁金服共同开源的分布式事务解决方案,能够在微服务架构下提供高性能且简单易用的分布式事务服务。
Seata 的发展历程
阿里巴巴作为国内最早一批进行应用分布式(微服务化)改造的企业,很早就遇到微服务架构下的分布式事务问题。
阿里巴巴对于分布式事务问题先后发布了以下解决方案:
- 2014 年,阿里中间件团队发布 TXC(Taobao Transaction Constructor),为集团内应用提供分布式事务服务。
- 2016 年,TXC 在经过产品化改造后,以 GTS(Global Transaction Service) 的身份登陆阿里云,成为当时业界唯一一款云上分布式事务产品。在阿云里的公有云、专有云解决方案中,开始服务于众多外部客户。
- 2019 年起,基于 TXC 和 GTS 的技术积累,阿里中间件团队发起了开源项目 Fescar(Fast & EaSy Commit And Rollback, FESCAR),和社区一起建设这个分布式事务解决方案。
- 2019 年 fescar 被重命名为了seata(simple extensiable autonomous transaction architecture)。
- TXC、GTS、Fescar 以及 seata 一脉相承,为解决微服务架构下的分布式事务问题交出了一份与众不同的答卷。
分布式事务相关概念
分布式事务主要涉及以下概念:
- 事务:由一组操作构成的可靠、独立的工作单元,事务具备 ACID 的特性,即原子性、一致性、隔离性和持久性。
- 本地事务:本地事务由本地资源管理器(通常指数据库管理系统 DBMS,例如 MySQL、Oracle 等)管理,严格地支持 ACID 特性,高效可靠。本地事务不具备分布式事务的处理能力,隔离的最小单位受限于资源管理器,即本地事务只能对自己数据库的操作进行控制,对于其他数据库的操作则无能为力。
- 全局事务:全局事务指的是一次性操作多个资源管理器完成的事务,由一组分支事务组成。
- 分支事务:在分布式事务中,就是一个个受全局事务管辖和协调的本地事务。
我们可以将分布式事务理解成一个包含了若干个分支事务的全局事务。全局事务的职责是协调其管辖的各个分支事务达成一致,要么一起成功提交,要么一起失败回滚。此外,通常分支事务本身就是一个满足 ACID 特性的本地事务。
Seata 整体工作流程
Seata 对分布式事务的协调和控制,主要是通过 XID 和 3 个核心组件实现的。
XID
XID 是全局事务的唯一标识,它可以在服务的调用链路中传递,绑定到服务的事务上下文中。
核心组件
Seata 定义了 3 个核心组件:
- TC(Transaction Coordinator):事务协调器,它是事务的协调者(这里指的是 Seata 服务器),主要负责维护全局事务和分支事务的状态,驱动全局事务提交或回滚。
- TM(Transaction Manager):事务管理器,它是事务的发起者,负责定义全局事务的范围,并根据 TC 维护的全局事务和分支事务状态,做出开始事务、提交事务、回滚事务的决议。
- RM(Resource Manager):资源管理器,它是资源的管理者(这里可以将其理解为各服务使用的数据库)。它负责管理分支事务上的资源,向 TC 注册分支事务,汇报分支事务状态,驱动分支事务的提交或回滚。
以上三个组件相互协作,TC 以 Seata 服务器(Server)形式独立部署,TM 和 RM 则是以 Seata Client 的形式集成在微服务中运行,其整体工作流程如下图。
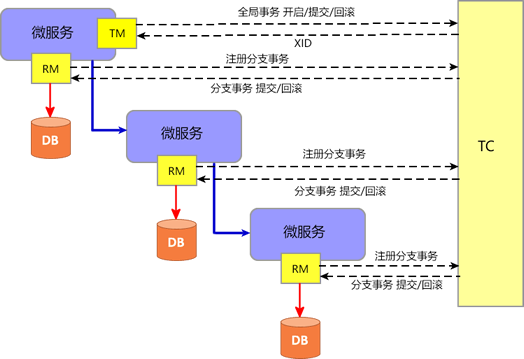
图1:Sentinel 的工作流程
Seata 的整体工作流程如下:
- TM 向 TC 申请开启一个全局事务,全局事务创建成功后,TC 会针对这个全局事务生成一个全局唯一的 XID;
- XID 通过服务的调用链传递到其他服务;
- RM 向 TC 注册一个分支事务,并将其纳入 XID 对应全局事务的管辖;
- TM 根据 TC 收集的各个分支事务的执行结果,向 TC 发起全局事务提交或回滚决议;
- TC 调度 XID 下管辖的所有分支事务完成提交或回滚操作。
Seata AT 模式
Seata 提供了 AT、TCC、SAGA 和 XA 四种事务模式,可以快速有效地对分布式事务进行控制。
在这四种事务模式中使用最多,最方便的就是 AT 模式。与其他事务模式相比,AT 模式可以应对大多数的业务场景,且基本可以做到无业务入侵,开发人员能够有更多的精力关注于业务逻辑开发。
AT 模式的前提
任何应用想要使用 Seata 的 AT 模式对分布式事务进行控制,必须满足以下 2 个前提:
- 必须使用支持本地 ACID 事务特性的关系型数据库,例如 MySQL、Oracle 等;
- 应用程序必须是使用 JDBC 对数据库进行访问的 JAVA 应用。
此外,我们还需要针对业务中涉及的各个数据库表,分别创建一个 UNDO_LOG(回滚日志)表。不同数据库在创建 UNDO_LOG 表时会略有不同,以 MySQL 为例,其 UNDO_LOG 表的创表语句如下:
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
AT 模式的工作机制
Seata 的 AT 模式工作时大致可以分为以两个阶段,下面我们就结合一个实例来对 AT 模式的工作机制进行介绍。
假设某数据库中存在一张名为 webset 的表,表结构如下。
| 列名 | 类型 | 主键 |
|---|---|---|
| id | bigint(20) | √ |
| name | varchar(255) | |
| url | varchar(255) |
在某次分支事务中,我们需要在 webset 表中执行以下操作。
update webset set url = 'c.biancheng.net' where name = 'C语言中文网';
- 1
一阶段
Seata AT 模式一阶段的工作流程如下图所示。
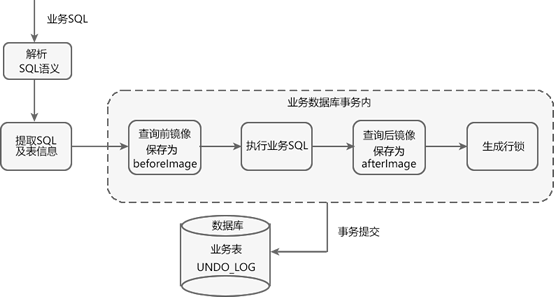
图2:Seata AT 模式一阶段
Seata AT 模式一阶段工作流程如下。
\1. 获取 SQL 的基本信息:Seata 拦截并解析业务 SQL,得到 SQL 的操作类型(UPDATE)、表名(webset)、判断条件(where name = ‘C语言中文网’)等相关信息。
\2. 查询前镜像:根据得到的业务 SQL 信息,生成“前镜像查询语句”。
select id,name,url from webset where name='C语言中文网';
- 1
执行“前镜像查询语句”,得到即将执行操作的数据,并将其保存为“前镜像数据(beforeImage)”。
| id | name | url |
|---|---|---|
| 1 | C语言中文网 | biancheng.net |
\3. 执行业务 SQL(update webset set url = ‘c.biancheng.net’ where name = ‘C语言中文网’;),将这条记录的 url 修改为 c.biancheng.net。
\4. 查询后镜像:根据“前镜像数据”的主键(id : 1),生成“后镜像查询语句”。
select id,name,url from webset where id= 1;
- 1
执行“后镜像查询语句”,得到执行业务操作后的数据,并将其保存为“后镜像数据(afterImage)”。
| id | name | url |
|---|---|---|
| 1 | C语言中文网 | c.biancheng.net |
\5. 插入回滚日志:将前后镜像数据和业务 SQL 的信息组成一条回滚日志记录,插入到 UNDO_LOG 表中,示例回滚日志如下。

