
- 1栈以及栈的应用_(3.2) ds:栈->栈的应用 东华oj
- 2计算机毕业设计题目大全(论文+源码)_kaic_基于java的小额支付管理平台的设计与实现论文
- 3Windows基础命令_组策略开启80瑞口_windows策略如何用命令打开
- 4Python 批量将文件夹中的pdf文件转换为图片 fitz
- 5如何用STM32驱动小喇叭或者蜂鸣器来演奏菊次郎的夏天_stm32扬声器如何控制
- 6【组件-工具】小程序ui组件Color UI快速入门_colorui官网
- 7从零开始学习PX4源码3(如何上传官网源码到自己的仓库中)
- 8CSS3动画巧妙实现轮播图效果_动画轮播图
- 9数学建模——欧拉算法(求解常微分方程)
- 10文件 —— 写操作_ofs文件夹在哪
最新的混合专家大语言模型DeepSeek-V2_deepseek-v2 is a a strong mixture-of-experts (moe)
赞
踩
最近Deepseek团队(北大、清华和南京大学)刚刚公布开源MOE模型DeepSeek-V2,其技术细节见论文“DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model”。
DeepSeek-V2是一个混合专家 (MoE) 语言模型,具有训练经济、推理高效的特点。它包含 236B 总参数,其中每个 token 激活 21B,支持 128K tokens 的上下文长度。DeepSeek-V2 采用包括多头潜注意(MLA) 和 DeepSeek MoE 在内的创新架构。MLA 通过将KV缓存显著压缩为潜向量来保证高效推理,而 DeepSeek MoE 通过稀疏计算以经济的成本训练强大的模型。与 DeepSeek 67B 相比,DeepSeek-V2 实现了显著增强的性能,同时节省了 42.5% 的训练成本、减少了 93.3% 的 KV 缓存、并将最大生成吞吐量提升至 5.76 倍。在由 8.1T tokens组成的高质量多源语料库上对 DeepSeek-V2 进行预训练,并进一步执行有监督微调 (SFT) 和强化学习 (RL) 以充分发挥其潜力。评估结果表明,即使只有 21B 激活参数,DeepSeek-V2 及其聊天版本仍然在开源模型中实现了顶级性能。模型检查点可在 GitHub - deepseek-ai/DeepSeek-V2上找到。
下面介绍其细节。
架构
总体而言,DeepSeek-V2 仍然采用 Transformer 架构(Vaswani et al., 2017),其中每个 Transformer 块由一个注意模块和一个前馈网络 (FFN) 组成。然而,对于注意模块和 FFN,都设计和采用了创新架构。对于注意,设计MLA,它利用低秩K-V联合压缩来消除推理时间K-V缓存的瓶颈,从而支持高效推理。对于 FFN,采用 DeepSeek MoE 架构(Dai et al., 2024),这是一种高性能的 MoE 架构,能够以经济的成本训练出强大的模型。如图展示 DeepSeek-V2 的架构:其中MLA 通过显著减少生成的 KV 缓存来确保高效推理,而 DeepSeek MoE 通过稀疏架构以经济的成本训练出强大的模型。
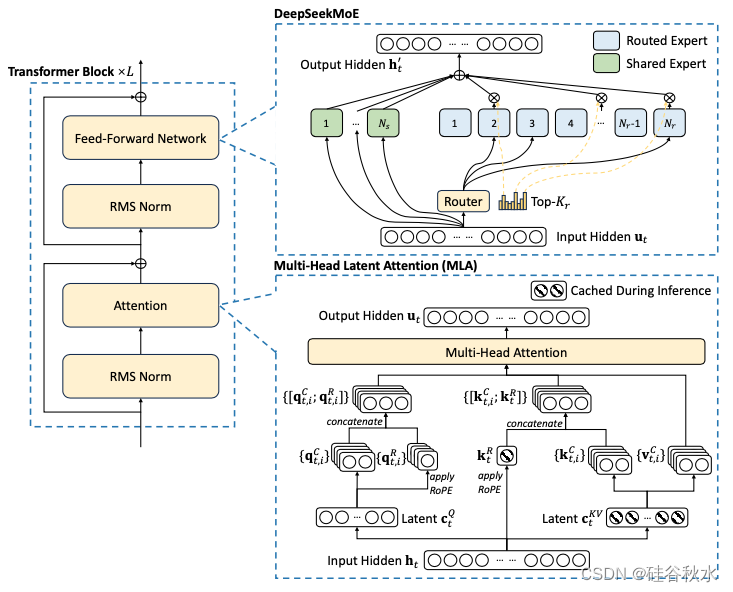
MLA
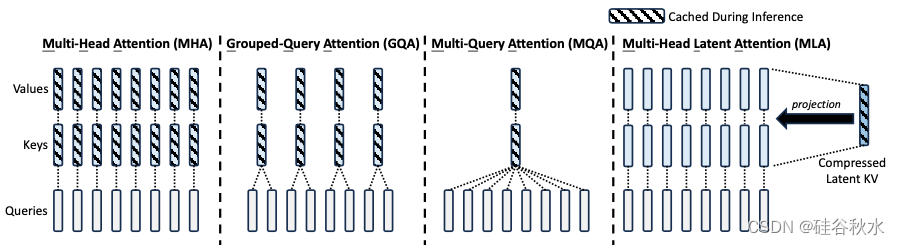
传统的 Transformer 模型通常采用多头注意机制 (MHA) (Vaswani et al., 2017),但在生成过程中,其繁重的KV缓存会成为限制推理效率的瓶颈。为了减少 KV 缓存,提出了多查询注意机制 (MQA) (Shazeer, 2019) 和分组查询注意机制 (GQA) (Ainslie et al., 2023)。它们需要的 KV 缓存量级较小,但性能不如 MHA。
对于 DeepSeek-V2,设计了一种创新的注意机制,称为多头潜注意机制 (MLA)。MLA 配备低秩KV联合压缩,性能优于 MHA,但需要的 KV 缓存量明显较少。
如图所示是多头注意 (MHA)、分组查询注意 (GQA)、多查询注意 (MQA) 和多头潜注意 (MLA) 的简化说明。通过将KV联合压缩为潜向量,MLA 显著减少推理过程中的 KV 缓存。
如 DeepSeek 67B (DeepSeek-AI, 2024) 那样,将旋转位置嵌入 (RoPE) (Su et al., 2024) 用于 DeepSeek-V2。但是,RoPE 与低秩 KV 压缩不兼容。具体来说,RoPE 对K和Q都是位置敏感的。如果将 RoPE 应用于K,则将与位置敏感的 RoPE 矩阵耦合。因此,必须在推理过程中重计算所有前缀tokens的K,这将严重阻碍推理效率。作为一种解决方案,提出解耦的 RoPE 策略,该策略使用额外的多头 Q 和共享 K 来承载 RoPE。
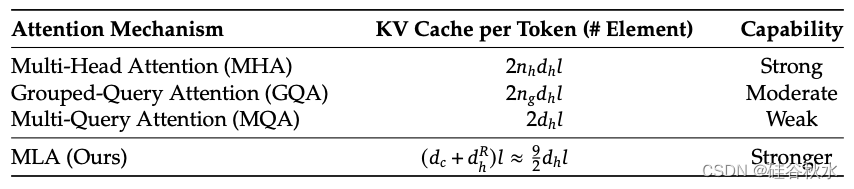
在下表 1 中展示不同注意机制中每个 token 的 KV 缓存比较。MLA 只需要少量的 KV 缓存,相当于只有 2.25 个组的 GQA,但可以获得比 MHA 更强的性能。
DeepSeek MoE
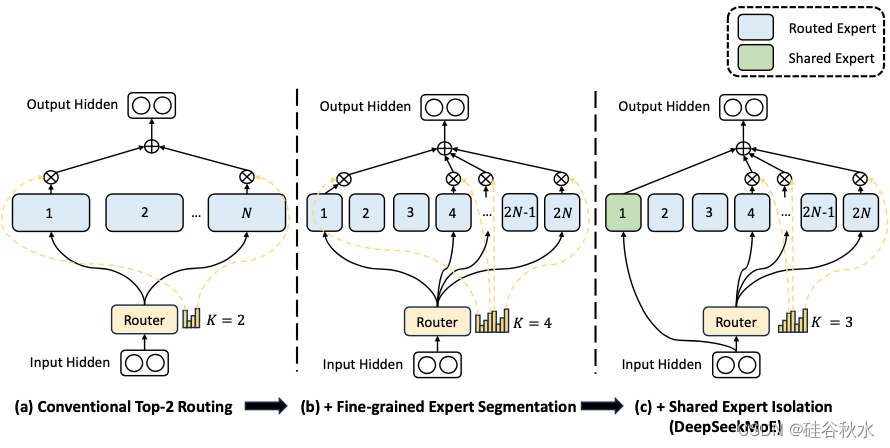
对于 FFN,采用 DeepSeekMoE 架构(Dai ,2024)。DeepSeekMoE 有两个关键思想:将专家细分为更细的粒度,以提高专家的专业化程度和更准确的知识获取,并隔离一些共享专家以减轻路由专家之间的知识冗余。在激活和总专家参数量相同的情况下,DeepSeekMoE 可以大大优于传统的 MoE 架构,例如 GShard(Lepikhin,2021)。
如图是DeepSeek MoE的示意图: (a) 展示具有传统 top-2 路由策略的 MoE 层;(b) 说明细粒度专家分割策略;随后 © 演示共享专家隔离策略的集成,构成了完整的 DeepSeek MoE 架构。值得注意的是,在这三种架构中,专家参数量和计算成本保持不变。
设计了一种设备受限的路由机制来限制与 MoE 相关的通信成本。当采用专家并行时,路由的专家将分布在多个设备上。对于每个 token,其与 MoE 相关的通信频率与其目标(targeted)专家覆盖的设备数成正比。由于 DeepSeek MoE 中的专家细分度分割,激活的专家数量可能很大,因此如果应用专家并行,与 MoE 相关的通信成本将更高。
对于 DeepSeek-V2,除了简单的 top-K 路由专家选择之外,还确保每个 token 的目标专家将分布在最多
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

