
- 1Arm汇编学习笔记(七)——ARM9五级流水及流水线互锁
- 2linux系统非root用户安装cuda和cudnn,不同版本cuda切换_安装多版本cudnn
- 3element-plus的安装_npm install element-plus --save
- 4智能合约(4)智能合约、DAPP、Ethereum Studio
- 5mysql 高级面试题_mysql面试中高级
- 6Windows系统快速部署开箱即用的智能AI聊天服务LobeChat
- 7Nodejs安装及配置方法_nodejs安装配置
- 8MacOS系统安装Docker(非常详细)从零基础入门到精通,看完这一篇就够了_mac安装docker_mac安装docker desktop
- 9OpenWrt 23.05 安装中文语言包 教程 软路由实测 系列三_openwrt中文语言包
- 10OpenCV从入门到精通实战(三)——全景图像拼接_opencv 全景拼接
基于开源AI数据框架LlamaIndex构建上下文增强型LLA应用_llamacloud 注册使用免费吗
赞
踩
引言

“将你的企业数据转化为可用于实际生产环境的LLM应用程序,”LlamaIndex主页用60号字体这样高亮显示。其副标题是“LlamaIndex是构建LLM应用程序的领先数据框架。”我不太确定它是否是业内领先的数据框架,但我认为它是一个与LangChain和Semantic Kernel一起构建大型语言模型应用的领先数据框架。
LlamaIndex目前提供两种开源语言框架和一个云端支持。一种开源语言是Python;另一种开源语言是TypeScript。LlamaCloud(目前处于个人预览版本)通过LlamaHub提供存储、检索、数据源链接,以及针对复杂文档的付费方式的专有解析服务LlamaParse,该服务也可作为独立服务提供。
LlamaIndex在加载数据、存储和索引数据、通过编排LLM工作流进行查询以及评估LLM应用程序的性能方面都具有优势。当前,LlamaIndex集成了40多个向量存储、40多个LLM和160多个数据源。其中,LlamaIndex Python代码存储库已获得超过30K的星级好评。
典型的LlamaIndex应用程序会执行问答、结构化提取、聊天或语义搜索,和/或充当代理。它们可以使用检索增强生成(RAG)技术将LLM与特定的数据源联系起来,这些源通常不包括在模型的原始训练集中。
显然,LlamaIndex框架将会与LangChain、Semantic Kernel和Haystack等框架展开市场竞争。不过,并非所有这些框架都有完全相同的应用范围和功能支持,但就流行程度而言,LangChain的Python代码仓库有超过80K的星级好评,几乎是LlamaIndex(超过30K的星级好评)的三倍,而相对最晚出现的Semantic Kernel已经获得超过18K的星级好评,略高于LlamaIndex的一半,Haystack的代码仓库有超过13K的星级好评。
上述好评结果是与代码仓库的年龄密切相关的,因为星级好评会随着时间的推移而积累;这也是为什么我用“超过”来修饰星级好评数的原因。GitHub上的星级好评数与历史进程中的流行度存在松散的相关性。
LlamaIndex、LangChain和Haystack都拥有许多大公司作为用户,其中一些公司使用了不止一个这样的框架。Semantic Kernel来自微软,除了案例研究之外,微软通常不会公布用户数据。
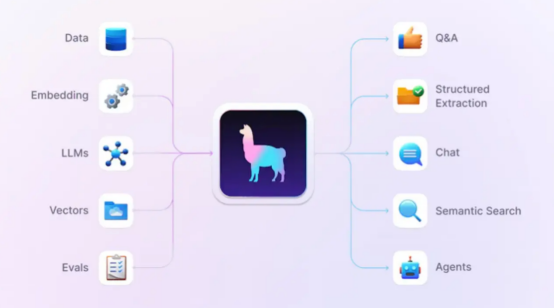
LlamaIndex框架可帮助你将数据、嵌入、LLM、向量数据库和求值连接到应用程序中。这些支持可以用于问答、结构化提取、聊天、语义搜索和代理等环境。
LlamaIndex框架的功能
从高层面来看,LlamaIndex框架的开发主旨在帮助你构建上下文增强的LLM应用程序,意味着你可以将自己的私有数据与大型语言模型相结合。上下文增强LLM应用程序的示例包括问答聊天机器人、文档理解和提取以及自动化代理等领域。
LlamaIndex提供的工具可执行数据加载、数据索引和存储、使用LLM查询数据以及评估LLM应用程序的性能:
- 数据连接器从其本机源和格式中获取现有数据。
- 数据索引,也称为嵌入,以中间表示形式构建数据。
- 引擎提供对数据的自然语言访问。其中包括用于回答问题的查询引擎,以及用于与你的数据进行多消息对话的聊天引擎。
- 代理是LLM驱动的知识工具,结合其他软件工具增强性能。
- 可观察性/评估集成使你能够对应用程序进行实验、评估和监控。
上下文增强
LLM受过大量文本的训练,但不一定是关于你的领域的文本信息。当前,存在三种主要方法可以执行上下文增强并添加有关域的信息,即提供文档、执行RAG和微调模型。
首先,最简单的上下文扩充方法是将文档与查询一起提供给模型,为此你可能不需要LlamaIndex。除非文档的总大小大于你正在使用的模型的上下文窗口;否则,提供文档是可以正常工作的,这在最近还是一个常见的问题。现在,有了具有百万个标记上下文窗口的LLM,这可以使你在执行许多任务时避免继续下一步操作。如果你计划对一百万个标记语料库执行许多查询,那么需要对文档进行缓存处理;但是,这是另外一个待讨论的话题了。
检索增强生成在推理时将上下文与LLM相结合,通常与向量数据库相结合。RAG过程通常使用嵌入来限制长度并提高检索到的上下文的相关性,这既绕过了上下文窗口的限制,又增加了模型看到回答问题所需信息的概率。
从本质上讲,嵌入函数获取一个单词或短语,并将其映射到浮点数的向量;这些向量通常存储在支持向量搜索索引的数据库中。然后,检索步骤使用语义相似性搜索,通常使用查询嵌入和存储向量之间的角度的余弦,来找到“附近”的信息,以便在增强提示中使用。
微调LLM是一个有监督的学习过程,涉及到根据特定任务调整模型的参数。这是通过在一个较小的、特定于任务或特定于领域的数据集上训练模型来完成的,该数据集标有与目标任务相关的样本。使用许多服务器级GPU进行微调通常需要数小时或数天时间,并且需要数百或数千个标记的样本。
安装LlamaIndex
你可以通过三种方式安装Python版本的LlamaIndex:从GitHub存储库中的源代码,使用llama index starter安装,或者使用llama-index-core结合选定的集成组件。starter方式的安装如下所示:
pip install llama-index除了LlamaIndex核心之外,这种安装方式还将安装OpenAI LLM和嵌入。注意,你需要提供OpenAI API密钥(请参阅链接https://platform.openai.com/docs/quickstart),然后才能运行使用这种安装方式的示例。LlamaIndex starter程序示例非常简单,基本上仅包含经过几个简单的设置步骤后的五行代码。在官方的代码仓库中还提供了更多的例子和有关参考文档。
进行自定义安装可能看起来像下面这样:
pip install llama-index-core llama-index-readers-file llama-index-llms-ollama llama-index-embeddings-huggingface这将安装一个Ollama和Hugging Face嵌入的接口。此安装还提供一个本地starter级的示例。无论从哪种方式开始,你都可以使用pip添加更多的接口模块。
如果你更喜欢用JavaScript或TypeScript编写代码,那么你可以使用LlamaIndex.TS。TypeScript版本的一个优点是,你可以在StackBlitz上在线运行示例,而无需任何本地设置。不过,你仍然需要提供一个OpenAI API密钥。
LlamaCloud和LlamaParse
LlamaCloud是一个云服务,允许你上传、解析和索引文档,并使用LlamaIndex进行搜索。当前,该项服务仍处于个人alpha测试阶段,我无法访问它。
LlamaParse作为LlamaCloud的一个组件,允许你将PDF解析为结构化数据;它可以通过REST API、Python包和Web UI获得。这个组件目前处于公测阶段。在每周前7K页的免费试用之后,你可以注册使用LlamaParse,只需支付少量的使用费。官网上提供的有关针对苹果10K大小文件基础上的对于LlamaParse和PyPDF比较的例子令人印象深刻,但我自己没有测试过。
LlamaHub
LlamaHub让你可以访问LlamaIndex的大量集成,其中包括代理、回调、数据加载程序、嵌入以及大约17个其他类别。通常,这些集成内容位于LlamaIndex存储库、PyPI和NPM中,你可以使用pip-install或NPM-install加载使用。
create-llama CLI
create-lama是一个命令行工具,用于生成LlamaIndex应用程序。这是开始使用LlamaIndex的快速方法。生成的应用程序中包含一个Next.js驱动的前端和三种后端方案可供选择。
RAG-CLI
RAG CLI也是一个命令行工具,用于与LLM交流你在计算机上本地保存的文件。这只是LlamaIndex的众多使用场景案例之一,不过这种情况非常普遍。
LlamaIndex组件
LlamaIndex组件指南会为你提供有关LlamaIndex各个部分的具体帮助。下面的第一个屏幕截图显示了组件指南菜单。第二个显示了提示的组件指南,滚动到关于自定义提示的部分。
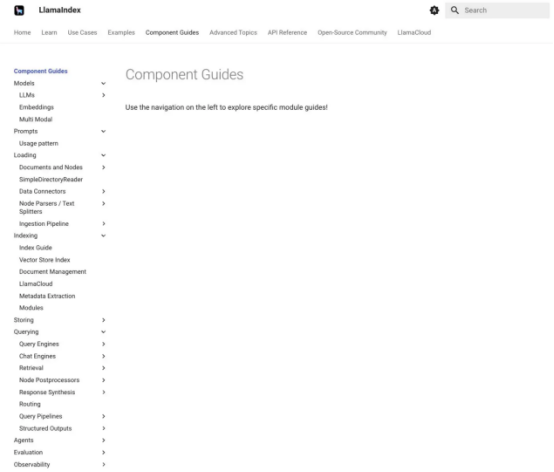
LlamaIndex组件指南记录了构成框架的不同部分,其中介绍了相当多的组件。
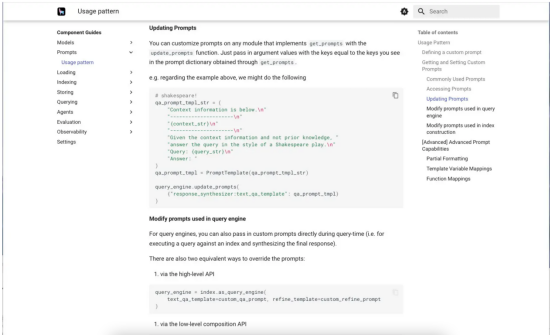
我们正在研究这种提示词的使用模式。这个特殊的例子展示了如何自定义问答提示,以莎士比亚戏剧的风格回答问题。值得注意的是,这是一个零样本提示,因为它没有提供任何示例。
学习LlamaIndex
一旦你阅读、理解并用你喜欢的编程语言(Python或TypeScript)运行了入门示例,我建议你尽可能多地阅读、理解和尝试其他看起来更有趣的一些示例。下面的屏幕截图显示了通过运行essay.ts并使用chatEngine.ts询问相关问题来生成一个名为essay的文件的结果。这是一个使用RAG进行问答的示例。
其中,chatEngine.ts程序使用LlamaIndex的ContextChatEngine、Document、Settings和VectorStoreIndex等组件。当我分析其源代码时,我看到它依赖于OpenAI gpt-3.5-turb-16k模型;这种情况可能会随着时间的推移而改变。如果我对文档的分析是正确的话,那么VectorStoreIndex模块使用了开源的、基于Rust的Qdrant向量数据库。
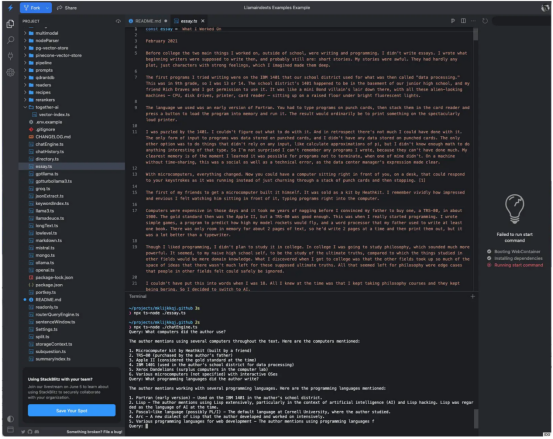
在用我的OpenAI密钥设置了终端环境后,我运行essay.ts来生成一个散文题材的文件,并运行chatEngine.ts来实现有关此文章的查询。
为LLM提供上下文
正如你所看到的,LlamaIndex非常容易用于创建LLM应用程序。我能够针对OpenAI LLM和RAG Q&A应用程序的文件数据源进行测试。值得注意的是,LlamaIndex集成了40多个向量存储、40多个LLM和160多个数据源;它适用于几种使用场景,包括Q&A问答、结构化提取、聊天、语义搜索和代理应用等。
最后,我建议你认真评估LlamaIndex与LangChain、Semantic Kernel和Haystack等框架。这其中的一个或多个很可能会满足你的需求。当然,我不能笼统地推荐其中某一个,因为不同的应用程序会有不同的要求。
LlamaIndex优点
- 帮助创建问答、结构化提取、聊天、语义搜索和代理等类型的LLM应用程序
- 支持Python和TypeScript
- 框架是免费和开源的
- 提供大量示例和集成组件
LlamaIndex不足
- 云环境仅限于私人预览
- 营销有点言过其实
LlamaIndex费用
开源:免费。
LlamaParse导入服务:每周免费支持7K页的文档,然后每1000页需要支付3美元。
平台支持
支持Python和TypeScript,以及云端SaaS(目前处于私人预览状态)。

