
- 1【LVS】部署DR模式集群
- 2Opencv_Python_7_高斯模糊_cv.gaussianblur()
- 3【TS】TypeScript声明文件:打通JavaScript和TypeScript的桥梁_typescript 声明文件
- 4如何安装ik分词器_在线安装ik
- 5【ChatGLM3】微调指南
- 6Arduino_ESP32_控制舵机运行【2024年】版_esp32控制舵机代码
- 7centos7中安装mysql教程_Centos7上安装mysql 详细教程
- 8软件测试理论知识_4.bug的多少通常可以用来评价软件的哪些特性?
- 9rabbitMQ重复消费的问题_rabbitmq被重复消费还是同一个线程吗
- 10 如何使用PostMan?
数字ic设计笔试知识点(自用)_数字ic基础知识
赞
踩
转载过多位博主文章,也有作者自己的理解在其中。
欢迎各位指正。
1. 基础知识
具体说说FPGA的组成及开发流程?
1. 概念区别
- ASIC(Application Specific Integrated Circuit, 专用集成电路)是一种在设计时就考虑了设计用途的IC。
- FPGA(Field Programmable Gate Array, 现场可编程门阵列)也是一种IC。顾名思义,只要有合适的工具和适当的专业基础,工程师就可以对FPGA进行重新编程。
2. 开发流程区别
FPGA开发是利用HDL和quartus、vivado等EDA工具,重新配置(configure)芯片的功能,而ASIC通常都具有较少的可重配置能力。FPGA是一大堆预制的门和触发器,具有可编程互连的特性。可以使用这些基本模块配置成你想要的任何逻辑功能。如果有错误,可以在几秒钟内重新编程,而不需要数月才能知道结果。然而,在FPGA中,有时候需要额外的硬件开销来进行正确的连接。
ASIC基本都是基于标准单元开始设计的,还需要进行Place&Route(布局&布线)。当芯片存在任何问题时,必须再次重新投片,直到达到你想要的功能和性能。ASIC设计流程非常昂贵,至少需要几个月的时间才能完成。ASIC在离开生产线后再也无法改变。这就是为什么设计师在大规模量产之前需要完全确保设计正确无误。工程师可以利用FPGA的可重配置这一优势,进行ASIC的原型验证,以便在将设计发送到代工厂之前,可以在实际世界中对其进行全面的测试。
3、成本区别
ASIC在重复成本方面具有很大的优势,因为在设计中浪费的材料非常少。对于FPGA,总是有很多的硬件资源被浪费。这意味着FPGA的重复成本通常高于同类ASIC的重复成本。
尽管ASIC的重复成本非常低,但其非重复成本相对较高且通常达到数百万。由于它是非重复性的,因此每个IC的成本随着量的增加而减少。
所以,在ASIC量产到一定量之后,使用ASIC可以比使用FPGA更便宜。与FPGA相比,ASIC在功耗,性能,尺寸和成本方面具有很大优势。
FPGA组成结构及功能
以CycloneⅡ为例介绍FPGA器件
FPGA开发流程
原文链接:https://blog.csdn.net/qq_36045093/article/details/119741748
1. FPGA分频:
FPGA 芯片有固定的时钟路由,这些路由能有减少时钟抖动和偏差。需要对时钟 进行相位移动或变频的时候,一般不允许对时钟进行逻辑操作,这样不仅会增加 时钟的偏差和抖动,还会使时钟带上毛刺。
一般的处理方法是采用 FPGA 芯片自 带的时钟管理器如 PLL,DLL 或 DCM,或者把逻辑转换到触发器的 D 输入(这些也 是对时钟逻辑操作的替代方案)。
2. 实现同步时序电路的延时
在同步电路中,对于比较大的和特殊要求的延时,一半通过高速时钟产生计数器, 通过计数器来控制延时;对于比较小的延时,可以通过触发器打一拍,不过这样 只能延迟一个时钟周期。
异步电路的延时实现:异步电路一半是通过加 buffer、两级与非门等来实现延时。
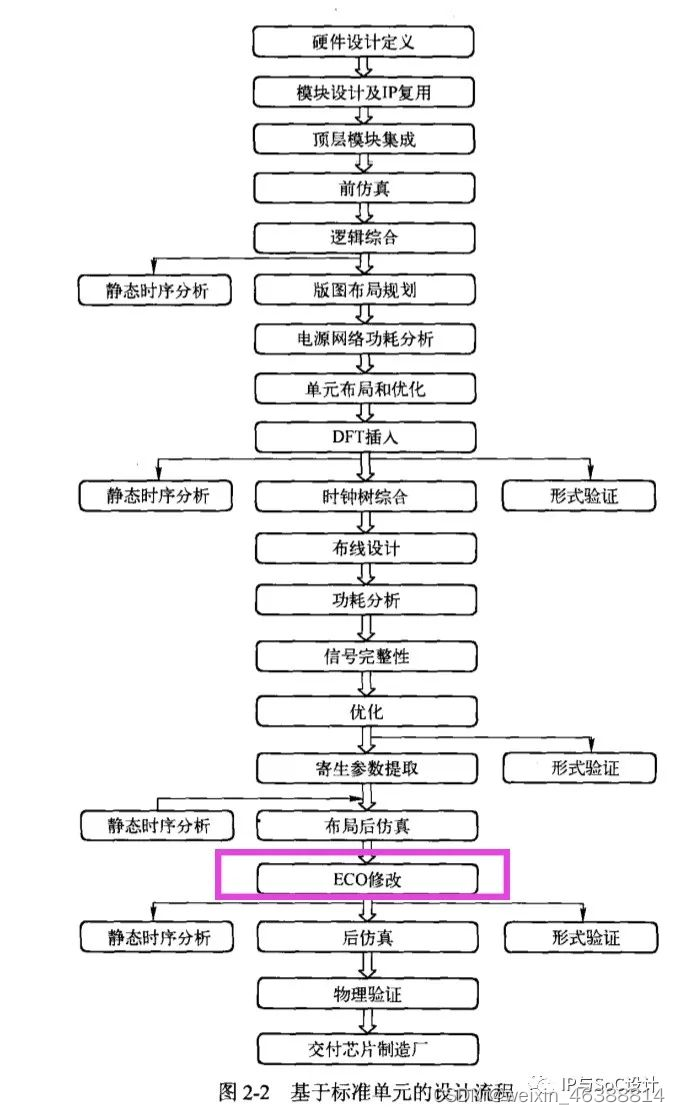
前仿(功能仿真、行为级仿真、RTL级仿真):针对不带任何延迟信息的RTL代码进行的功能验证。
后仿(时序仿真):采用后端工具生成的SDF文件对布局布线后的门级网表进行的时序和功能验证。 后仿也叫动态时序仿真,相比于静态时序分析STA(针对同步电路设计中时序分析),它主要应用在异步逻辑、多周期路径、错误路径的时序验证中。
什么是综合? SDF?

不懂?
时序约束:周期约束,偏移约束,静态时序;
通过附加时序约束可以综合布线工具调整映射和布局布线,使设计达到时序要求。
附加约束的作用:
1:提高设计的工作频率(减少了逻辑和布线延时); 2:获得正确的时序分析报告;(静态时序分析工具以约束作为判断时序是否满 足设计要求的标准,因此要求设计者正确输入约束,以便静态时序分析工具可以 正确的输出时序报告)3:指定 FPGA/CPLD 的电气标准和引脚位置。
附加时序约束的一般策略:
1.先附加全局约束,然后对快速和慢速例外路径附加专门约束。
2.附加全约束时,首先定义设计的所有时钟,对各时钟域内的同步元件进行分组,对分组附加周期约束,然后对 FPGA/CPLD 输入输出 PAD 附加偏移约束、 对全组合逻辑的 PAD TO PAD 路径附加约束。
3.附加专门约束时,首先约束分组之间的路径,然后约束快、慢速例外路径和多周期路径,以及其他特殊路径。
添加约束:

- 一个设计的时序约束是怎么写出来的?
clock 和 generated clock 一般由设计 spec 决定。除非有些个别的 local generated clock 可以有前端工程师自己添加。
- 请大略说明时钟,IO delay,false path, multicyclepath 是如何得到的?
IO timing 与系统设计有关,应该参考/兼顾其他芯片的 IO 时序,由前端工程师作出。
- 在完成时序约束的过程中,后端可以给予什 么样的帮助?
exception(false path, multicycle path)一般是由前端工程师在做设计时决定的后端可以提供 clock network delay/skew,DRV,以及帮助检查 SDC 是否合格。
时钟周期约束
对于时钟约束,有三个要素描述:时钟源,占空比和时钟周期。

FPGA偶数分频
分频电路是数字电路中常见的逻辑电路类型。在时序逻辑电路中,时钟是必不可少的,但对于时钟要求不高的基本设计,自行设计的分频电路,也就是时钟分频器,有时候比采用外部PLL更为简单、有效、快速。
分频器一般可以分为:偶数分频、奇数分频、小数分频。
1. 偶数分频
将主时钟以2为幂次进行分割可以得到同步偶数分频时钟,即21,22,23…分频。电路上可采用D触发器实现,n个触发器可以构成2n次偶数分频。如图1所示,为2分频、4分频电路设计及波形。

(2)用计数器实现
用D触发器级联搭建分频电路只能实现2,4,8,16等分频,对于一般的偶数分频,可以通过计数器实现:若要实现N分频(N为偶数),只需将计数器在待分频时钟上升沿触发下循环计数,从0计数到(N/2 -1)后将输出时钟翻转即可实现。

1. EDA工具
EDA工具是芯片设计的核心,它包括原理图绘制、逻辑综合、门级仿真工具和物理版图编辑等,可以帮助设计师设计出电路的物理结构和电气行为以及特定规则的芯片功能。市场上最常用的EDA工具厂商有Cadence、Mentor Graphics、Synopsys等。其中,每个厂商都有着自己独特的产品优势。
- Synopsys
- 对功耗和时钟分析有较突出的表现
- 设计逻辑清晰明确
- 提供高质量的培训教材
- 逻辑综合:Design Compiler(DC)是Synopsys公司用于做电路综合的核心工具,可以将HDL描述的电路转换为基于工艺库的门级网表。
- 对功耗和时钟分析有较突出的表现
- Cadence
- 集成度高
- 支持不同层次的设计流程
- 套件内部设计逻辑清晰
- 设计环境友好易学易用
2. 模拟仿真工具
主要用于验证芯片设计的正确性和性能,并可以提前发现设计缺陷。它们可以模拟电路的各种行为和参数,并可以评估元器件的电气性能,帮助设计人员预测芯片的电性能和稳定性能。
HDL的仿真软件有很多种,如VCS、VSS、NC-Verilog、NC-VHDL、ModelSim等,对于开发FPGA来说,一般是使用FPGA厂家提供的集成开发环境,他们都有自己的仿真器,如Xilinx公司的ISE,Altera公司的Quartus II等,但是这些厂家开发的仿真器的仿真功能往往比不上专业的EDA公司的仿真工具,如ModelSim AE(Altera Edition)、ModelSim XE(Xilinx Edition)等。Quartus II设有第三方仿真工具的接口,可以直接调用其他EDA公司的仿真工具,这极大地提高了EDA设计的水平和质量----Quartus II联合Modelsim。
3. 布局工具
布局工具是芯片物理版图的设计和布局规划,市面上比较流行的有Tanner EDA、Mentor Graphics的Calibre、Cadence的Virtuoso等。这些工具可以为工程师提供一个强大的物理版图编辑环境,以实现芯片电路的详细设计和最终的版图。并且能够优化所有的物理要素以达到更好的性能,同时也提高了芯片设计的效率和质量。
- Calibre提供了快速准确的设计规则检查(DRC)、电气规则(ERC)以及版图与原理图对照(LVS)功能。
RTL设计(Modelsim、Quartus)---- 前仿(Cadence的NC-Verilog、Modelsim)---- 逻辑综合(Synopsys的Design Compiler) ---- STA(Synopsys的Prime Time)---- 形式验证(Synopsys的Formality)---- DFT设计(Synopsys的DFT Compiler)---- 布局布线(Calibre、Virtuoso)---- 流片
HDL 语言是分层次的、类型的:系统级,算法级,RTL 级(行为级),门级,开关级
Magic是一个制作VLSI电路版图的工具。使用彩色图标、鼠标、图表可以设计出基础单元来组合成层级结构。它的特点是彩色制图,方便用户理解原生电路,用这些基础信息可以进行更多的操作。例如,magic有内置的布局规则。当你正在画图时,可以实时检查、提醒是否违反规则。
Magic也有一个犁操作,你可以用它来拉伸或压缩细胞。最后,Magic有路由工具,您可以使用它在电路中进行全局互连。
Magic是基于Mead-Conway风格的设计。这意味着它使用简化的设计规则和电路结构。简化使您更容易设计电路,并允许Magic提供强大的帮助,否则将不可能。
| 运算符 | |
|---|---|
| ! 、 ~ | 逻辑、位 |
| * 、 / 、% | 算术 |
| + 、 - | 算术 |
| << 、 >> | 移位 |
| < 、 <= 、 > 、 >= | 关系 |
| == 、 != 、 === 、 !== | 关系 |
| & | 位 |
| ^ 、 ^~ | 位 |
| | | 位 |
| && | 逻辑 |
| || | 逻辑 |
| ? | 选择 |
Latch对电平信号敏感,在输入脉冲的电平作用下改变状态。
DFF对时钟边沿敏感,检测到上升沿或下降沿触发瞬间时改变状态。
Latch代码:
- module latch(
- input d,
- input ena,
- output q);
-
- always@(ena)begin
- if(ena)
- q = d;
- end
-
- endmodule
DFF代码:
- module DFF(
- input clk,
- input reset,
- input d,
- output q
- );
- always@(posedge clk)begin
- if(reset)
- q = 0;
- else
- q = d;
- end
-
- endmodule
电平敏感的存储器件称为锁存器。可分为高电平锁存器和低电平锁存器,用于不 同时钟之间的信号同步。 有交叉耦合的门构成的双稳态的存储原件称为触发器。分为上升沿触发和下降沿 触发。可以认为是两个不同电平敏感的锁存器串连而成。前一个锁存器决定了触 发器的建立时间,后一个锁存器则决定了保持时间。
register 在同一时钟边沿触发下动作,符 合同步电路的设计思想,而 latch 则属于异步电路设计,往往会导致时序分析困 难,不适当的应用 latch 则会大量浪费芯片资源。
同步逻辑:所有dff的时钟端全部连在系统时钟端。只有时钟脉冲到来时,电路状态才发生改变。
异步逻辑:可以使用不带时钟的dff和延迟元件作为存储元件。电路中没有统一的时钟,电路状态改变由外部输入直接引起。
1) 简述两种reset方式的区别。
同步复位:复位信号只在时钟上升沿到来时才有效。
- always@(posegde clk)
- begin
- if(!rst)
- out <= 0;
- else
- out <= in;
- end
异步复位:无论时钟沿是否到来,只要复位信号有效,就对系统进行复位。
- always@(posedge clk or negedge rst)
- begin
- if(!rst)
- out <= 0;
- else
- out <= in;
- end
2) 异步reset的主要缺点是什么?
异步reset的主要缺点是复位信号的随机性会导致亚稳态,而且对电路内的毛刺敏感,容易造成复位错误。
毛刺问题?
3) 设计中如何规避异步reset的缺点?
可以采用异步复位同步释放的方法来解决这个问题,即复位与clk无关,复位信号在第二级触发器的clk边沿到来后释放,第二级输出是稳定且被同步的。多打一拍,消除亚稳态,从而触发器会在一个或两个时钟周期内返回稳态。

- always@(posedge clk or negedge rst_n)//原始的复位信号触发,一级缓冲
- begin
- if(!rst_n)
- begin
- q1 <= 1'b0;
- q2 <= 1'b0;
- end
- else
- begin
- q1 <= 1'b1;
- q2 <= q1;
- end
- end
- assign rst_syn = q2;
- always@(posedge clk or negedge q2)//利用一级缓冲的延迟复位信号作为异步复位信号
- begin
- if(!q2)
- q3 <= 0;
- else
- q3 <= data_in;
- end

建立时间:数据在时钟上升沿到来之前,必须保持稳定的时间
保持时间:数据在时钟上升沿到来之后,必须保持稳定的时间
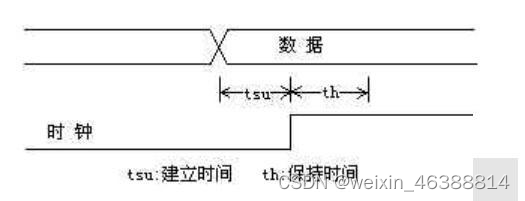
时序设计的实质就是满足每一个触发器的建立/保持时间的要求。
那么为什么触发器要满足setup+hold?
答:触发器内部数据的形成是需要一定的时间的。不满足建立时间和保持时间的电路,触发器在数据变化时无法采到真实的高低电平信号,并会将这种不确定性(亚稳态)往下传播。
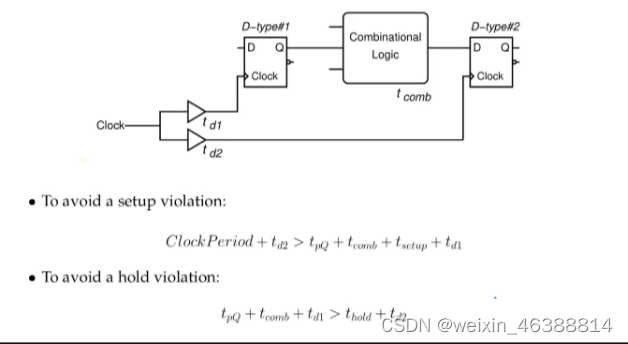
建立时间约束:Tsetup < Tclk - Tclkq - Tlogic + Tskew
保持时间约束:Thold < Tclkq + Tlogic - Tskew
解决setup time violation 违例:
添加缓冲区,而不是减慢整个系统时钟。在最快路径中添加一些延迟以消除.
解决hold time violation违例:
减少时钟频率,增加时间周期。如果降低时钟频率,则可以修复设置违规。
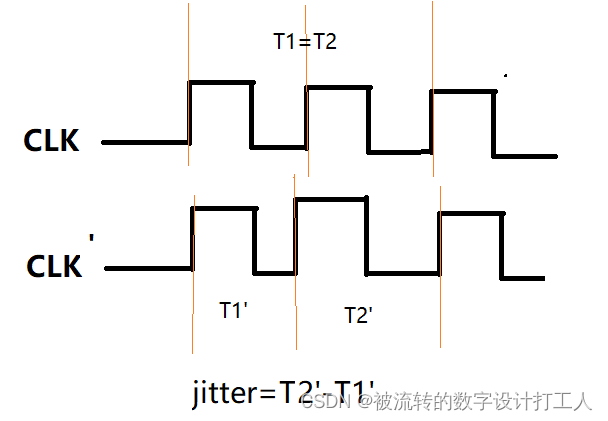
时钟抖动:指的是某一时刻时钟周期会发生短暂性变化(向左或向右偏移),造成时钟周期在不同的周期上可能加长或缩短。
产生原因:一般发生在时钟发生器内部,和晶振和PLL内部电路有关,与布线无关。是频率上的不确定。
它的计算:jitter=Tmax-Tmin,如下图所示:
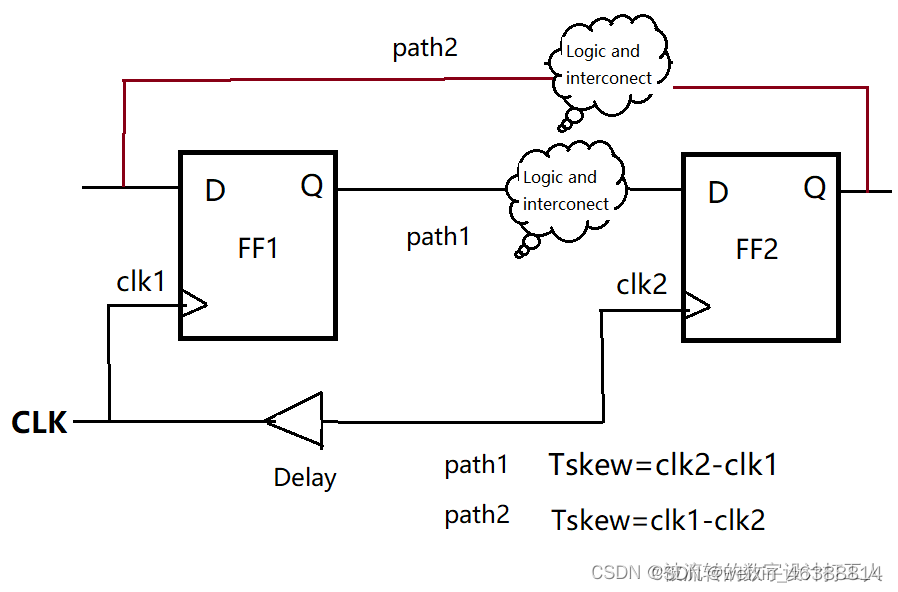
时钟偏移:是指同一时钟由于布线长度不同导致时钟到达不同寄存器的时间不同,存在一定差值。时钟偏移是永远存在的,它的大小和电路布线有关。是相位上的不确定。
它的计算:Tskew=clk2-clk1
注意这里结果可能是正,也可能是负。正常来说,时钟到达clk1的时间肯定比到达clk2的时间短,但是我们在进行时序分析的时候,看的是源端触发器到目的端触发器之间的时序路径,
原文链接:https://blog.csdn.net/the_old_ghost/article/details/126782982

时钟周期为 T,触发器 D1 的寄存器到输出时间(触发器延时 Tco)最大为 T1max,最小为 T1min。组合逻辑电路最大延迟为 T2max,最小为 T2min。 问,触发器 D2 的建立时间 T3 和保持时间应满足什么条件?
- T3setup>T+T2max 时钟沿到来之前数据稳定的时间(越大越好),一个时钟周期 T 加上最大的逻辑延时。
- T3hold>T1min+T2min 时钟沿到来之后数据保持的最短时间,一定要大于最小的 延时也就是 T1min+T2min。
假设在 pre-CTS 的时序约束中,setup 的 clock uncertainty 是由 PLL jitter 和 clock tree skew 两部分组成,那么
1)pre-CTS 的时序约束中,hold 的 clock uncertainty 是什么?
2)post-CTS 的时序约束中,setup 和 hold 的 clock uncertainty 要做什么样的修 改?
答案:
1) pre-CTS,
setup 的 clock uncertainty = PLL jitter + clock tree skew
hold 的 clock uncertainty = clock tree skew
2) post-CTS,
setup 的 clock uncertainty = PLL jitter
hold 的 clock uncertainty = 0
CTS 中使用 buffer 和 inverter 的优缺点是什么?
| buffer | inverter | |
| 优点 | 逻辑简单,便于 post-CTS 对时钟树的修改 | 面积小,功耗小,insertion delay 小,对时钟 duty cycle 有利 |
| 缺点 | 面积大,功耗大,insertion delay 大 | 不易做时钟树的修改 |
亚稳态:触发器无法在某个规定的时间内达到一个可以确认的状态。触发器进入亚稳态后,无法预测其输出电平,也无法预测输出何时能稳定。
原因:触发器的 Tsetup 和 Thold 不满足,使得输出端 Q 在时钟边沿到来后比较长的一段时间内处于不确定的状态,并且Q稳定后的值是随机的,与输入D无关;
为什么两级触发器可以解决亚稳态?
答:使用两级触发器来使异步电路同步化的电路其实叫 做“一位同步器”,他只能用来对一位异步信号进行同步。第一级不满足建立保持时间产生亚稳态,经过一段恢复时间后稳定下来,第二级必须满足建立保持时间,第二级不会出现亚稳态。此时需要满足的条件:第一级触发器进入亚稳态后的恢复时间 + 第二级触发器的建立时间 < = 时钟周期T. (看不懂:更确切地说,输入脉冲宽度必须大于同步时钟周期与第一级触发器所需的保持时 间之和。最保险的脉冲宽度是两倍同步时钟周期。所以,这样的同步电路对于从 较慢的时钟域来的异步信号进入较快的时钟域比较有效,对于进入一个较慢的时 钟域,则没有作用。)
解决亚稳态:
1 降低系统时钟频率
2 用反应更快的 FF
3 引入同步机制,防止亚稳态传播(可以采用前面说的加两级触发器)。
4 改善时钟质量,用边沿变化快速的时钟信号
解决方法:在跨时钟域传输时,对于
- 单bit信号:双锁存器法同步、边沿检测同步器、脉冲检测同步器。
- 多bit信号:握手协议、异步FIFO+双端口RAM。
功耗
来源:
- 动态功耗,逻辑转换导致逻辑门负载电容充电/放电。
- 短路电流,在逻辑转换期间短路(一段时间)时发生。
- 泄露功耗,由泄漏电流引起的
影响 CMOS 电路动态功耗的因素有哪些: 工艺、翻转率、供电电压、温度
1. 系统最高速度计算(最快时钟频率)
同步电路的速度是指同步系统时钟的速度,同步时钟愈快,电路处理数据的时间 间隔越短,电路在单位时间内处理的数据量就愈大。 假设 Tco 是触发器的输入数据被时钟打入到触发器到数据到达触发器输出端的 延时时间(Tco=Tsetpup+Thold);Tdelay 是组合逻辑的延时;Tsetup 是D触发器 的建立时间。假设数据已被时钟打入 D 触发器,那么数据到达第一个触发器的Q 输出端需要的延时时间是 Tco,经过组合逻辑的延时时间为 Tdelay,然后到达第 二个触发器的D端,要希望时钟能在第二个触发器再次被稳定地打入触发器,则 时钟的延迟必须大于 Tco+Tdelay+Tsetup,也就是说最小的时钟周期 Tmin =Tco +Tdelay+Tsetup,即最快的时钟频率 Fmax =1/Tmin。
2. 流水线设计:分解N块(适当均分组合逻辑)
FPGA 开发软件也是通过这种方法来计算系统最高运行速度 Fmax。因为 Tco 和 Tsetup 是由具体的器件工艺决定的,故设计电路时只能改变组合逻辑的延迟时 间 Tdelay,所以说缩短触发器间组合逻辑的延时时间是提高同步电路速度的关 键所在。由于一般同步电路都大于一级锁存,而要使电路稳定工作,时钟周期必 须满足最大延时要求。故只有缩短最长延时路径,才能提高电路的工作频率。可 以将较大的组合逻辑分解为较小的 N 块,通过适当的方法平均分配组合逻辑,然 后在中间插入触发器,并和原触发器使用相同的时钟,就可以避免在两个触发器 之间出现过大的延时,消除速度瓶颈,这样可以提高电路的工作频率。 这就是所谓"流水线"技术的基本设计思想,即原设计速度受限部分用一个时钟周 期实现,采用流水线技术插入触发器后,可用 N 个时钟周期实现,因此系统的工 作速度可以加快,吞吐量加大。注意,流水线设计会在原数据通路上加入延时, 另外硬件面积也会稍有增加。
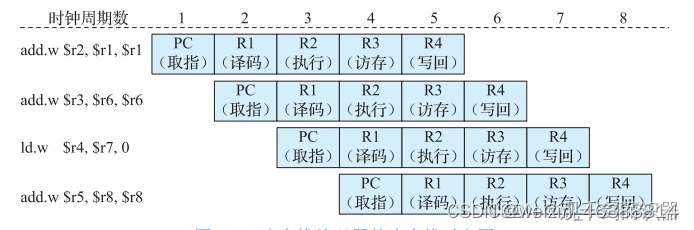
流水线的体现:处理器的工作方式就像一个 5 人分工合作的加工厂, 每个工人做完自己的部分, 将自己手头的工作交给下一个工人, 并取得一个新的工作, 这样可以让每个工人都一直处于工作状态
静态时序分析是采用穷尽分析方法来提取出整个电路存在的所有时序路径, 计 算信号在这些路径上的传播延时,检查信号的建立和保持时间是否满足时序要求, 通过对最大路径延时和最小路径延时的分析,找出违背时序约束的错误。它不需 要输入向量就能穷尽所有的路径,且运行速度很快、占用内存较少,不仅可以对 芯片设计进行全面的时序功能检查,而且还可利用时序分析的结果来优化设计, 因此 静态时序分析已经越来越多地被用到数字集成电路设计的验证中。只适用于同步电路。
动态时序模拟就是通常的仿真,因为不可能产生完备的测试向量,覆盖门级网表中的每一条路径。因此在动态时序分析中,无法暴露一些路径上可能存在的时序问题。适用于所有电路(同步、异步、latch)。
1、静态时序分析
静态时序分析(static timing analysis,STA)是遍历电路存在的所有时序路径,根据给定工作条件(PVT)下的时序库.lib文件计算信号在这些路径上的传播延时,检查信号的建立和保持时间是否满足约束要求,根据最大路径延时和最小路径延时找出违背时序约束的错误。
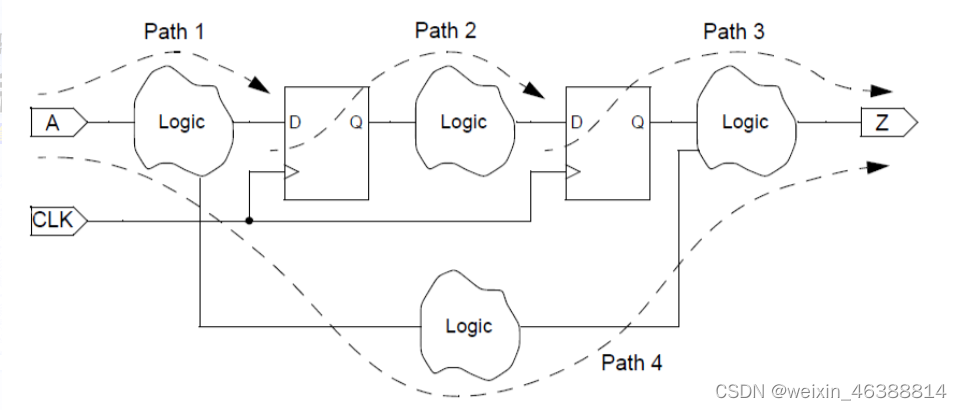
静态时序分析的优点:
- 不需要给输入激励;
- 几乎能找到所有的关键路径(critical path);
- 运行速度快,占用内存较少,不仅可以对芯片设计进行全面的时序功能检查,而且还可利用时序分析的结果来优化设计。因此静态时序分析已经越来越多地被用到数字集成电路设计的验证中;
静态时序分析的缺点:
- 只适用同步电路;
- 无法验证电路的功能;
- 需要比较贵的工具支持;
- 对于新工艺可能还需要建立一套特征库,建库的代价可能要几百万。
静态时序分析的工具:
- Synopsys的prime time,
- Cadence的Encounter Timing System等
关键路径:
给出一个门级的图,又给了各个门的传输延时,问关键路径是什么,还问给出 输入, 使得输出依赖于关键路径?关键路径就是输入到输出延时最大的路径,找到了关键路径便能求得最大时钟频 率。
2、动态时序分析
动态时序分析(dynamic timing analysis,DTA)通常是所有的输入信号都会给一个不同时刻的激励,在testbench(.sp或者.v)中设置一段仿真时间,最后对仿真结果进行时序和功能分析。 这里的仿真可以是门级或者晶体管级,包括spice格式和RTL格式的网表。(可以理解为仿真)
如下图所示的spice中给激励的语句和波形:
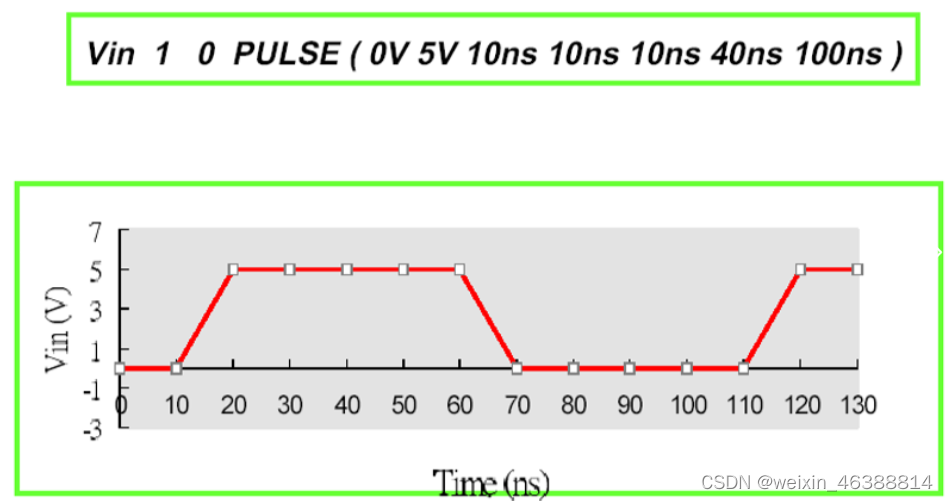
动态时序分析的优点
- 晶体管级的仿真比较精确,直接基于工厂提供的spice 工艺库计算得到;
- 适用于任何电路,包括同步、异步、latch等等;
- 不需要额外搞一套特征库;
- 不需要很贵的时序分析工具。
动态时序分析的缺点:
- 需要给不同的测试激励,这使得在分析的过程中关键路径无法检查全 (致命性的);随着规模增大,所需要的向量数量以指数增长,且这种方法难以保证足够的覆盖率。
- 规模大的电路spice仿真特别慢 (致命性的)。
动态时序的工具 :
- spice仿真器: hspice, finesim, hsim, spectre等;
- verilog仿真器: ModelSim,VCS,NC-Verilog,Verilog-XL等。
而动态时序分析有2个致命性的缺点:关键路径无法检查全意味着里面可能有fail的path,芯片流片出来无法工作;仿真特别慢意味着你的schedule可能受到影响,无法按时交货。所以动态时序分析只适用于小规模的电路,通过给激励就能完成时序的检查,同时仿真的时间还能接受。
竞争:在组合电路中,某一输入变量经过不同途径传输后,到达电路中某一汇合点的时间有先有后,这种现象称竞争;
冒险:由于竞争而使电路输出发生瞬时错误的现象叫做 冒险。(也就是由于竞争产生的毛刺叫做冒险)。
判断方法:
- 代数法:如果布尔式中有相反的信号则可能产生竞争和冒险现象;
故对于输出端的逻辑函数在一定条件下能化简成:
Y=A+A’ , 存在 “0” 型竞争;
Y=AA’ ,存在 “1” 型竞争;
的情况下,则判定一定有竞争冒险现象。
- 卡诺图:有两个相切的卡诺圈并且相切处没有被其他卡诺圈包围,就有可能出现竞争冒险;
即如果一个逻辑函数的表达式的卡洛图中所画圈没有重叠并且相切,则判定有竞争冒险。(本质上还是利用上面的方法,只是比较直观形象的判断)
对于以下卡洛图,左图存在竞争冒险,而由图不存在竞争冒险。
- 实验法:示波器观测;
解决方法:
- 加滤波电容,消除毛刺的影响;
- 加选通信号,避开毛刺;
- 增加冗余项消除逻辑冒险。
门电路两个输入信号同时向相反的逻辑电平跳变称为竞争;
由于竞争而在电路的输出端可能产生尖峰脉冲的现象称为竞争冒险。
如果逻辑函数在一定条件下可以化简成 Y=A+A’或 Y=AA’则可以判断存在竞争冒险现象(只是一个变量变化的情况)。
消除方法,接入滤波电容,引入选通脉冲,增加冗余逻辑。
形式验证
形式验证指从数学上完备地证明或验证电路的实现方案是否确实实现了电路设 计所描述的功能。形式验证方法分为等价性验证、模型检验和定理证明等。
形式验证主要验证数字 IC 设计流程中的各个阶段的代码功能是否一致,包括综 合前 RTL 代码和综合后网表的验证,因为如今 IC 设计的规模越来越大,如果对 门级网表进行动态仿真,会花费较长的时间,而形式验证只用几个小时即可完成 一个大型的验证。另外,因为版图后做了时钟树综合,时钟树的插入意味着进入 布图工具的原来的网表已经被修改了,所以有必要验证与原来的网表是逻辑等价 的
常用逻辑电平:TTL、CMOS、LVTTL、LVCMOS、ECL(Emitter Coupled Logic)、PECL (Pseudo/Positive Emitter Coupled Logic)、LVDS(Low Voltage Differential Signaling)、 GTL(Gunning Transceiver Logic)、BTL(Backplane Transceiver Logic)、ETL(enhanced transceiver logic)、GTLP(Gunning Transceiver Logic Plus);RS232、RS422、RS485 (12V,5V,3.3V);
也有一种答案是:常用逻辑电平:12V,5V,3.3V。
TTL 与 COMS 电平可以直接互连吗?
答: TTL 和 CMOS 不可以直接互连。
由于 TTL 是在 0.3-3.6V 之间,而 CMOS 则是有在 12V 的有在 5V 的。
CMOS 输出接到 TTL 是可以直接互连。
TTL 接到 CMOS 需要在 输出端口加一上拉电阻接到 5V 或者 12V。
用 CMOS 可直接驱动 TTL。TTL 加上拉电阻后,可驱动 CMOS.
上拉电阻的用途:
1、当 TTL 电路驱动 COMS 电路时,如果 TTL 电路输出的高电平低于 COMS 电路 的最低高电平(一般为 3.5V),这时就需要在 TTL 的输出端接上拉电阻,以提高 输出高电平的值。
2、OC 门电路必须加上拉电阻,以提高输出的高电平值。
3、为加大输出引脚的驱动能力,有的单片机管脚上也常使用上拉电阻。
4、在 COMS 芯片上,为了防止静电造成损坏,不用的管脚不能悬空,一般接上 拉电阻产生降低输入阻抗,提供泄荷通路。
5、芯片的管脚加上拉电阻来提高输出电平,从而提高芯片输入信号的噪声容限 增强抗干扰能力。
6、提高总线的抗电磁干扰能力。管脚悬空就比较容易接受外界的电磁干扰。
7、长线传输中电阻不匹配容易引起反射波干扰,加上下拉电阻是电阻匹配,有 效的抑制反射波干扰。
上拉电阻阻值的选择原则包括:
1、从节约功耗及芯片的灌电流能力考虑应当足够大;电阻大,电流小。
2、从确保足够的驱动电流考虑应当足够小;电阻小,电流大。
3、对于高速电路,过大的上拉电阻可能边沿变平缓。
综合考虑以上三点,通常在 1k 到 10k 之间选取。对下拉电阻也有类似道理。
寄生效应就是那些溜进你的 PCB 并在电路中大施破坏、令人头痛、原因不明 的小故障。它们就是渗入高速电路中隐藏的寄生电容和寄生电感。
来源: 其中包括由封装引脚和印制线过长形成的寄生电感;焊盘到地、焊盘到电源平面和焊盘到印制线之间形成的寄生电容;通孔之间的相互影响,以及许多其它可能的寄生效应。
原因: 理想状态下,导线是没有电阻,电容和电感的。而在实际中,导线用到了金属铜, 它有一定的电阻率,如果导线足够长,积累的电阻也相当可观。两条平行的导线, 如 果互相之间有电压差异,就相当于形成了一个平行板电容器。 通电的导线周围会形成磁场(特别是电流变化时),磁场会产生感生电场,会对电子的移动产生影响,可以说每条实际的导线包括元器件的管脚都会产生感生 电动势,这也就是寄生电感。
解决: 这种寄生效应很难克服,只能通过优化线路,尽量使用管脚短的 SMT 元器件来减少其影响,要完全消除是不可能的。
Moore型状态机:输出信号只取决于当前状态。
Mealy型状态机:输出信号不仅取决于当前状态,还取决于输入信号的值。
它们的区别就在于输出信号是否与输入信号有关,造成的结果是:实现相同功能时,Moore型状态机需要比Mealy型状态机多一个状态,且Moore型状态机的输出比Mealy型延后一个时钟周期。
Moore型状态机的输出信号是直接由状态寄存器译码得到,
Mealy型状态机则是以现时的输入信号结合即将变成次态的现态,编码成输出信号。

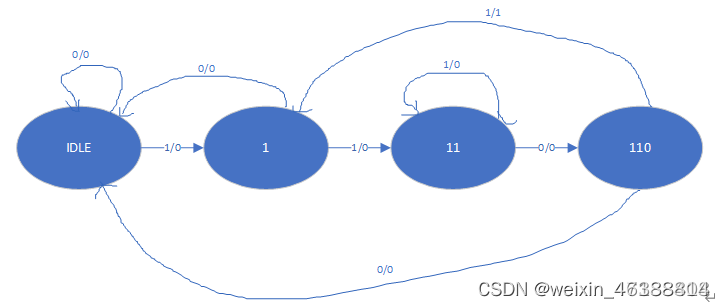
左图是moore,右图是mearly
直接看最后一个状态:moore机输出与输入无关,所以无论最后输入是1还是0,输出都是1;mearly机输出与输入有关,所以输入0输出0,输入1输出1.
个人用米勒机比较多。
什么是状态图?以几何图形的方式来描述时序逻辑电路的状态转移规律以及输出与输 入的关系。
有限状态机Finite State Machine
二段式:
有两个always block,把时序逻辑always_ff和组合逻辑always_comb分隔开来。时序逻辑里进行当前状态和下一状态的切换,组合逻辑实现各个输入、输出以及状态判断。这种写法不仅便于阅读、理解、维护,而且利于综合器优化代码,利于用户添加合适的时序约束条件,利于布局布线器实现设计。在两段式描述中,当前状态的输出用组合逻辑实现,可能存在竞争和冒险,产生毛刺。
要求对状态机的输出用寄存器打一拍,但很多情况不允许插入寄存器节拍,此时使用三段式描述。其优势在于能够根据状态转移规律,在上一状态根据输入条件判断出当前状态的输出,从而不需要额外插入时钟节拍。
三段式:
有三个always block,一个时序逻辑采用同步时序的方式描述状态转移,一个采用组合逻辑的方式判断状态转移条件、描述状态转移规律,第三个模块使用同步时序的方式描述每个状态的输出。代码容易维护,时序逻辑的输出解决了两段式组合逻辑的毛刺问题,但是从资源消耗的角度上看,三段式的资源消耗多一些。
优点:
1.将组合逻辑和时序逻辑分开,利于综合器分析优化和程序维护;
2.更符合设计的思维习惯;
3.代码少,比一段式状态机更简洁。
- //1st, 时序逻辑,描述现态。NS=nextstate
- always @ ( posedge clk or negedge rst_n )
- begin
- if ( !rst_n )
- CS <= IDLE;
- else
- CS <= NS;
- end
-
- // 2nd,组合逻辑,描述状态转换
- always @*
- begin
- NS = 'b0; //初始化寄存器,避免生成latch
- case (CS) //注意为CS
- IDLE: begin
- end;
- S1: begin
- end;
- default:
- NS = 'b0; //与硬件电路一致
- endcase
- end
-
- //3rd, 时序逻辑,描述输出(moore/mealy)
- always @ (posedge clk or negedge rst_n)
- begin
- if(!rst_n) begin
- end
- else begin
- case (CS/NS) //这里有2种写法,推荐NS写法(moore型写法)
- ...
- default: ;
- endcase
- end
- end
note:
always @(敏感电平信号)需要列举完全,可以用“@*”或者“@(*)”代替;
初始值设置避免组合逻辑条件不全生成latch,但不一定符合设计。
case(表达式)中的表达式为“cstate”,即现态current state;
阻塞赋值“=”;非阻塞赋值“<=”;
default项必须设置,与实际电路一致。
DFT
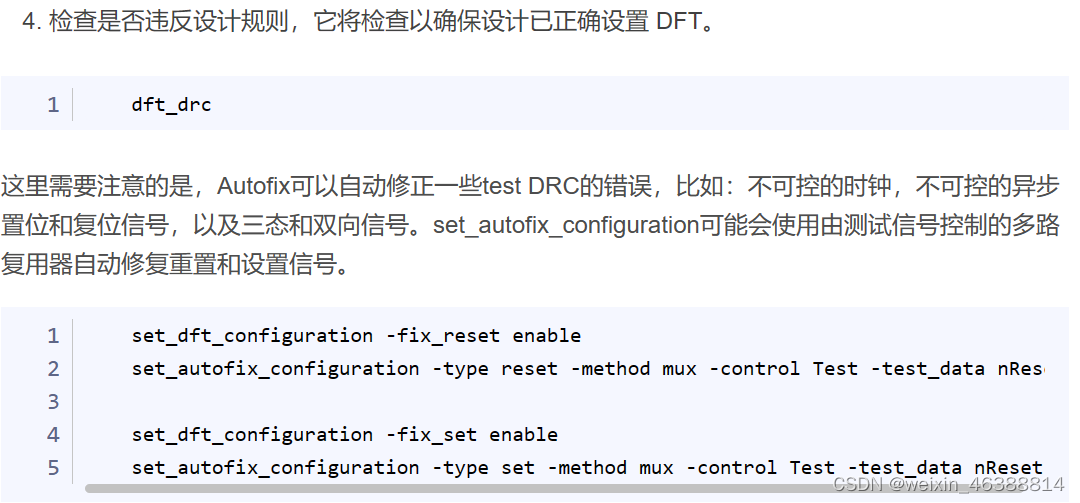
DFT(Design for Testability )该设计有助于提高可测试性,从而促进制造过程中的测试和调试,提高了芯片的可测试性和可靠性。
DFT的特点
DFT的主要优势包括:
- 提高测试效率: DFT能够简化测试过程,使设计在更高的抽象级别上可以进行测试。这降低了手动测试的工作量,使测试自动化更加可行。
- 提高测试覆盖率: 通过在设计初期就引入DFT,设计师可以确保所有的逻辑都能被适当地测试到。这提高了测试覆盖率,从而减少了制造过程中的缺陷和错误。
- 提高可靠性和质量: 通过提高测试的精度和覆盖率,DFT能够在产品发布之前找出和修复更多的设计缺陷。这可以提高产品的可靠性和质量,从而减少产品退货和售后维修的成本。
- 降低测试成本: 虽然引入DFT可能会增加设计的复杂性和成本,但是它可以降低测试阶段的成本,因为它使得测试能够更有效率地进行。
虽然DFT(Design for Testability)的方法能够提升芯片的测试效率和覆盖率,但是它也有一些潜在的缺点:
- 设计复杂性增加: 在集成电路设计中引入DFT会增加设计的复杂性。设计人员需要在设计初期就计划并实现DFT策略,这需要额外的设计时间和资源。
- 面积和功耗增加: DFT技术如扫描链、内置自测试(BIST)等会引入额外的硬件,例如更多的触发器、测试逻辑电路等。这会导致集成电路的面积增大,同时也可能会增加功耗。
- 性能影响: DFT技术可能对集成电路的性能产生影响。例如,引入扫描链可能会导致时钟路线变长,增加时钟偏斜,这可能影响集成电路的最大工作频率。
- 测试时间和成本: 虽然DFT可以提高测试的效率和覆盖率,但是如果要对每一个晶体管都进行全面的测试,所需的时间和成本可能会非常高。为了克服这个问题,设计人员需要在测试计划中制定出一个合理的折衷方案。
功能测试:
功能测试针对的是芯片设计规格书中的功能规格,检测芯片是否能够按照设计需求进行工作。这种测试主要关注的是芯片的行为,包括数据处理,通信接口,功耗等等。功能测试的目标是确保芯片的所有功能都正常工作。在硬件的设计阶段需要充分的功能测试和设计验证。
结构测试:
结构测试是基于硬件实现的详细信息的。在这种测试中,测试人员会根据硬件设计(如逻辑门,电路等)生成特定的测试用例,以查找可能的缺陷和错误。这种测试更多的是针对物理级别的细节,包括对芯片内部结构的评估,比如晶体管,电路互连,逻辑门等。结构测试的目标是确保芯片在物理和电气层面上没有问题。
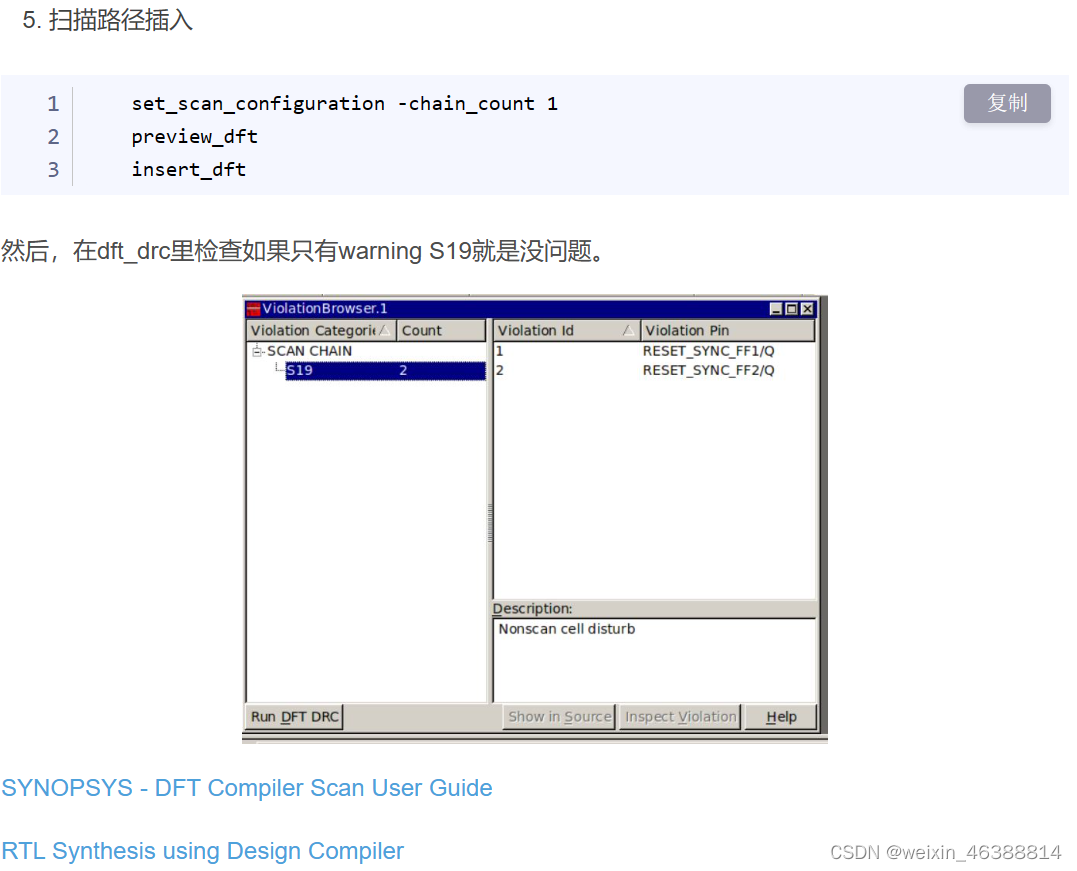
DFT的扫描链设计
- 测试点插入(Test Point Insertion):在硬件设计中,插入额外的测试点,例如观察点和控制点,可以帮助更容易地访问和控制硬件的内部状态。这种方法可以提高硬件的可观察性和可控制性,从而提高测试的效率和有效性。
- 扫描设计(Scan Chain Design ):扫描设计是一种常用的DFT方法,其中所有的触发器(flip-flops)都被连接成一个或多个长的移位寄存器,称为扫描链(scan chain)。通过扫描链,我们可以直接设置和读取硬件的内部状态,从而极大地提高了硬件的可测试性。
- 内置自测试(Built-In Self-Test,BIST):在BIST方法中,硬件被设计为能够执行自我测试。这种方法可以在硬件的运行过程中检测出潜在的故障,并且可以大大减少外部测试设备的需求。
- 测试压缩技术(Test Compression Techniques):测试压缩技术是一种降低测试数据量和测试时间的方法。例如,Xilinx公司的3D IC设计中使用了测试压缩技术,以降低测试成本。
- 故障模型(Fault Models):DFT设计也需要考虑故障模型。一个故障模型是一个假设,它描述了硬件可能出现的故障类型。故障模型的选择可以影响测试的覆盖率和效率。
- 测试策略和计划(Test Strategies and Plans):一个好的DFT设计也需要一个全面的测试策略和计划。这个策略应该详细描述如何,何时,以及在哪里进行测试,包括在制造过程中的测试和在硬件生命周期中的测试。
扫描链(Scan Chain)的设计
在硬件设计中,将触发器 (flip-flops) 替换为可扫描的触发器并以链的形式连接在一起就形成了“扫描链”。在测试模式下,这个扫描链就像是一个移位寄存器,可以通过改变扫描使能信号 (Scan Enable, SE) 的状态,来在正常操作模式和测试模式之间切换。在测试模式下,可以通过扫描输入端口 (Scan Input) 向扫描链中输入数据,然后通过扫描输出端口 (Scan Output) 从扫描链中读出数据。
扫描链,所有的触发器必须连接成一条链,单链或多链。 如果您在一端推送一些数据,而在另一端获得相同的数据,那么它在制造过程中没有错误。使用扫描链进行测试的目的:进行扫描测试的原因有多种,其中最突出的两个是:
- 测试制造设备中的固定故障(stuck-at faults) ;
- 测试制造设备中的路径的延迟,测试每条路径是否工作在功能频率下;
这种方法的优点在于,它允许我们直接访问和控制硬件的内部状态,极大地提高了硬件的可测试性。通过向扫描链输入一个已知的数据模式,然后读出硬件的输出,我们可以检查这个输出是否与预期的结果相匹配。如果输出与预期的结果不匹配,那么说明在制造过程中可能发生了一些错误。这种方法可以帮助我们在硬件生产的早期阶段就发现和修复问题,从而提高硬件的质量和可靠性。
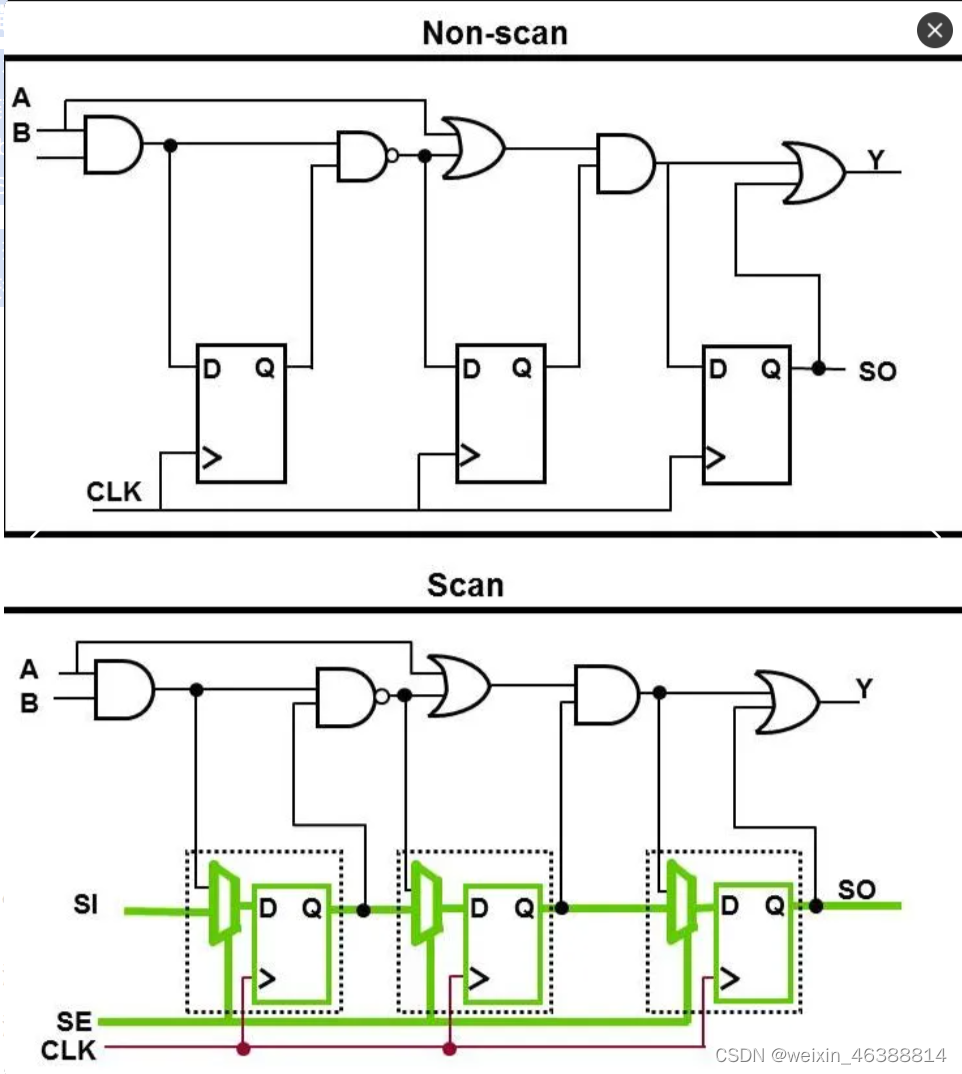
扫描触发器:扫描链的基本构建块
在触发器的输入处添加多路复用器,多路复用器的一个输入充当功能输入D,而另一个输入充当扫描输入(SI)。D 和 SI 之间的选择由扫描使能 (SE) 信号控制。

存在异步复位同步化触发器时的扫描链设计
为了实现有效的DFT设计,将flip-flops for reset synchronization 隔离出来,即不被包含到scan chain,这样做的目的是不干扰扫描模式下的复位信号的时序。假设如果被包含进去了,则需要仔细控制Scan-Enable信号的时序,这会使得分析DFT的测试结果变得更加困难。“Input synchronizer is contained in scan path, reset synchronization is not.”
如果用于复位信号同步化(reset synchronization)的触发器包含在扫描链(scan chain)中,则有必要仔细控制扫描使能(Scan-Enable)信号的时序,以确保它们不会干扰扫描模式下的复位信号的时序(扫描模式下用的是pin脚上的,而不是同步后的复位信号)。 这可能会使生成提供良好覆盖率的测试模式和分析测试结果变得更加困难。
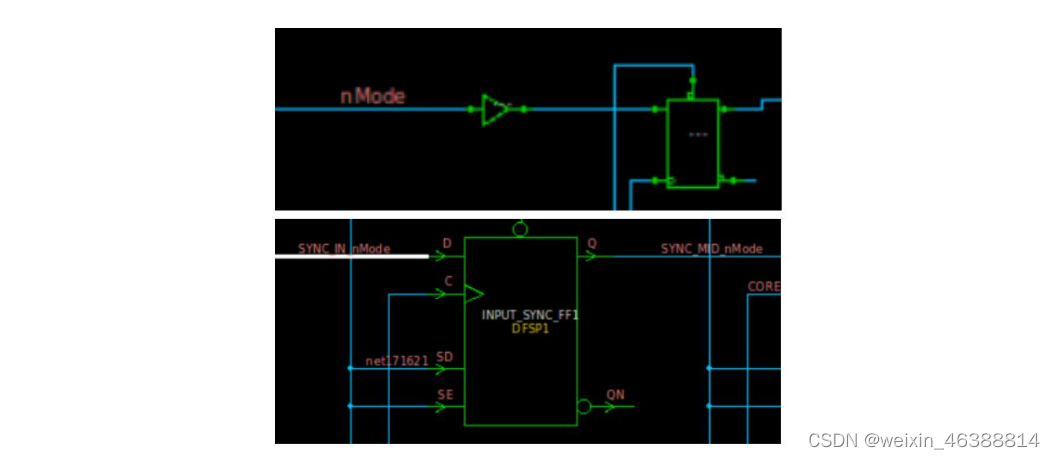


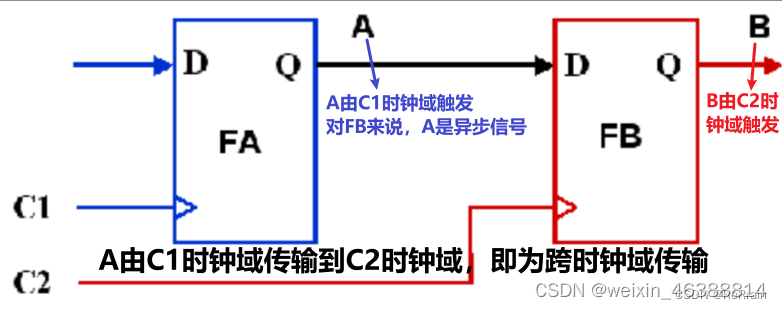
CDC, clock domain crossing数据从一个时钟域传输到另一个时钟域。
- 单bit信号,用:打两拍
- 多bit信号,用:异步FIFO
- 多bit信号,用:格雷码
- 多bit信号,用:握手+保持寄存器(多数据、控制、地址)
- 第一种:打两拍(慢时钟到快时钟)
- 第二种:格雷码转换
 https://blog.csdn.net/wczzmmp2/article/details/125356354?ops_request_misc=&request_id=&biz_id=102&utm_term=%E8%B7%A8%E6%97%B6%E9%92%9F%E5%9F%9F%E4%B8%BA%E4%BB%80%E4%B9%88%E6%89%93%E4%B8%A4%E6%8B%8D&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-125356354.142%5Ev100%5Epc_search_result_base6&spm=1018.2226.3001.4187#_14
https://blog.csdn.net/wczzmmp2/article/details/125356354?ops_request_misc=&request_id=&biz_id=102&utm_term=%E8%B7%A8%E6%97%B6%E9%92%9F%E5%9F%9F%E4%B8%BA%E4%BB%80%E4%B9%88%E6%89%93%E4%B8%A4%E6%8B%8D&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-125356354.142%5Ev100%5Epc_search_result_base6&spm=1018.2226.3001.4187#_14 - 第三种:异步fifo/异步双端口RAM
1. 单bit:打两拍
打两拍的方式,其实说白了,就是定义两级寄存器,对输入的数据进行延拍,如下图所示:
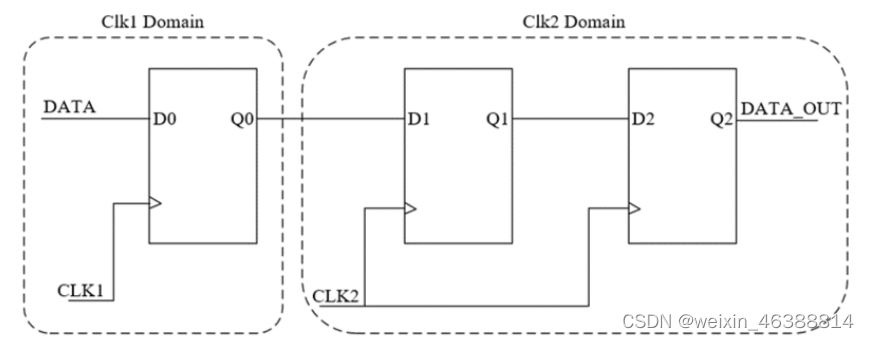
两级寄存器的原理:两级寄存是一级寄存的平方,两级并不能完全消除亚稳态的影响,但是提高了可靠性减少其发生概率。
DATA传给D1的时候,输出的Q1不能确定,可能是1也能是0 。 但是第二级寄存器Q2的输出一定是稳定的1或者0。(不能保证正确定,但一定能保证稳定性)
note:时钟域A的组合逻辑信号必须经过一级DFF,等数据稳定后,再打两拍。
2. 多bit
- 格雷码+双DFF(异步FIFO)
看不懂?
定义:First In First Out是一种先进先出的数据缓存器,他与普通存储器的区别是没有外部读写地址线,这样使用起来非常简单,但缺点就是只能顺序写入数据,顺序的读出数据,其数据地址由内部读写指针自动加1完成,不能像普通存储器那样可以由地址线决定读取或写入某个指定的地址。
FIFO 包括同步 FIFO 和异步 FIFO 两种,同步 FIFO 有一个时钟信号,读和写逻辑全部使用这一个时钟 信号,异步 FIFO 有两个时钟信号,读和写逻辑用的各种的读写时钟。 FIFO 与普通存储器 RAM 的区别是没有外部读写地址线,使用起来非常简单,但缺点就是只能顺序写 入数据,顺序的读出数据,其数据地址由内部读写指针自动加 1 完成,不能像普通存储器那样可以由地址线决定读取或写入某个指定的地址。 FIFO 本质上是由 RAM 加读写控制逻辑构成的一种先进先出的数据缓冲器。


功能:对连续的数据流进行缓存,防止数据丢失。减轻CPU负担。
为什么用fifo: 不同时钟域之间的数据传输 / 不同宽度的数据传输。
FIFO的分类:
按照时钟域分为:
-
同步FIFO: 读时钟和写时钟为同一个时钟。在时钟沿来临时同时发生读写操作。
-
异步FIFO: 读写时钟不一致,读写时钟是互相独立的。
FIFO参数:

写指针:总是指向下一个将要被写入的地址,复位时指向编号0的地址;
读指针:总是指向下一个将要被读出的数据地址,复位时也指向编号0的地址且此时数据无效;
FIFO应用:
1. 多bit跨时钟
同步FIFO:
同步时钟主要应用于速率匹配(数据缓冲),类似于乒乓存储提高性能的思想,可以让后级不必等待前级过多时间; 异步 FIFO 主要用于多 bit 信号的跨时钟域处理。

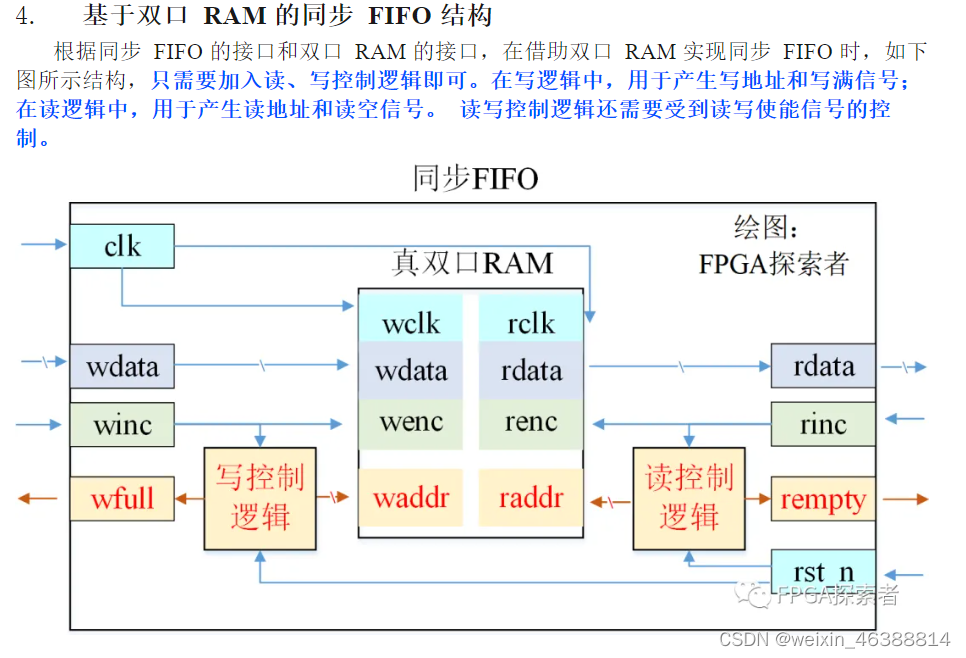
写地址
- always @ (posedge clk or negedge rst_n)
- begin
- if(~rst_n) begin
- waddr <= 'b0;
- end
- else begin
- if( winc && ~wfull ) begin //写使能有效(要写入); 没写满(能写入);
- waddr <= waddr + 1'b1;
- end
- else begin
- waddr <= waddr;
- end
- end
- end
读地址:逻辑同写地址
- always @ (posedge clk or negedge rst_n)
- begin
- if(~rst_n) begin
- raddr <= 'b0;
- end
- else begin
- if( rinc && ~rempty ) begin // 读使能有效(要读出); 没读空(能读出);
- raddr <= raddr + 1'b1;
- end
- else begin
- raddr <= raddr;
- end
- end
- end
空/满信号判断
读使能有效(要读出);
没读空(能读出);
扩展 1 bit 的读写地址方法,也就是说,将前面提到的 flag 指示信号和原本 N 位的读写地址结合,使用 N+1 位的读写地址,其中最高位用于判断空满信号,其余低位还是正常用于读写地址索引。
读写地址后两位相同时,通过判断首位来决定是读空还是写满。地址一定是先写后读,所以数据先写进地址之后才会产生被读取的可能性。一旦数据被写满(写领先读),写数据的最高位置1,此时读写地址位相同最高位相反(写1读0)。一旦数据被读空(读追上写),
- raddr[N] = = ~waddr[N]
- raddr[N-1:0] = = waddr[N-1:0]
- //高位相反,低位相同
等价于
raddr == {~waddr[N], waddr[N-1:0]}全部代码
(这里有一个问题我没有明白:一旦地址被写满,下一新数据写到哪里?
问过朋友的一个解答是:加到溢出时,自动舍去高位,相当于回到0)
- module sync_fifo_ptr
- #(
- parameter DATA_WIDTH = 'd8 , //FIFO位宽
- parameter DATA_DEPTH = 'd16 //FIFO深度
- )
- (
- input clk , //系统时钟
- input rst_n , //低电平有效的复位信号
- input [DATA_WIDTH-1:0] data_in , //写入的数据
- input rd_en , //读使能信号,高电平有效
- input wr_en , //写使能信号,高电平有效
-
- output reg [DATA_WIDTH-1:0] data_out, //输出的数据
- output empty , //空标志,高电平表示当前FIFO已被写满
- output full //满标志,高电平表示当前FIFO已被读空
- );
-
- //reg define
- //用二维数组实现RAM
- reg [DATA_WIDTH - 1 : 0] fifo_buffer[DATA_DEPTH - 1 : 0];
- reg [$clog2(DATA_DEPTH) : 0] wr_ptr; //写地址指针,位宽多一位
- reg [$clog2(DATA_DEPTH) : 0] rd_ptr; //读地址指针,位宽多一位
-
- //wire define
- wire [$clog2(DATA_DEPTH) - 1 : 0] wr_ptr_true; //真实写地址指针
- wire [$clog2(DATA_DEPTH) - 1 : 0] rd_ptr_true; //真实读地址指针
- wire wr_ptr_msb; //写地址指针地址最高位
- wire rd_ptr_msb; //读地址指针地址最高位
-
- assign {wr_ptr_msb,wr_ptr_true} = wr_ptr; //将最高位与其他位拼接
- assign {rd_ptr_msb,rd_ptr_true} = rd_ptr; //将最高位与其他位拼接
-
- //读操作,更新读地址
- always @ (posedge clk or negedge rst_n) begin
- if (rst_n == 1'b0)
- rd_ptr <= 'd0;
- else if (rd_en && !empty)begin //读使能有效且非空
- data_out <= fifo_buffer[rd_ptr_true];
- rd_ptr <= rd_ptr + 1'd1;
- end
- end
- //写操作,更新写地址
- always @ (posedge clk or negedge rst_n) begin
- if (!rst_n)
- wr_ptr <= 0;
- else if (!full && wr_en)begin //写使能有效且非满
- wr_ptr <= wr_ptr + 1'd1;
- fifo_buffer[wr_ptr_true] <= data_in;
- end
- end
-
- //更新指示信号
- //当所有位相等时,读指针追到到了写指针,FIFO被读空
- assign empty = ( wr_ptr == rd_ptr ) ? 1'b1 : 1'b0;
- //当最高位不同但是其他位相等时,写指针超过读指针一圈,FIFO被写满
- assign full = ( (wr_ptr_msb != rd_ptr_msb ) && ( wr_ptr_true == rd_ptr_true ) )? 1'b1 : 1'b0;
-
- endmodule
线与逻辑是两个输出信号相连可以实现与的功能。在硬件上,要用 oc 门来实现, 由于不用 oc 门可能使灌电流过大,而烧坏逻辑门. 同时在输出端口应加一个上拉 电阻。oc 门就是集电极开路门。od 门是漏极开路门。
与非门:上并下串 或非门:上串下并
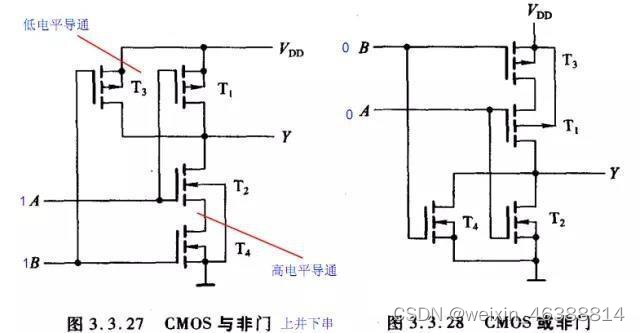

逻辑表达式:Z = AB' + A'B
verilog代码:assign Z = B ? ( !A):A;

D触发器
图中的与非门和反相器用 CMOS 电路

RAM
| SRAM | 静态随机存储器 | 存取速度快,但容量小,掉电后数据会丢失,不像 DRAM 需要不停的 REFRESH,制造成本较高,通常用来作为快取(CACHE) 记忆体使用。 |
| DRAM | 动态随机存储器 | 必须不断的重新的加强(REFRESHED) 电位差量,否则 电位差将降低至无法有足够的能量表现每一个记忆单位处于何种状态。价格比 SRAM 便宜,但访问速度较慢,耗电量较大,常用作计算机的内存使用。 |
| FLASH | 闪存 | 存取速度慢,容量大,掉电后数据不会丢失。 |
| SSRAM | 同步静态随机存取存储器 | 对于 SSRAM 的所有访问都在时钟的上升/ 下降沿启动。地址、数据输入和其它控制信号均于时钟信号相关。 |
| SDRAM | 同步动态随机存取存储器 |
function 和 task
| function函数 | task任务 |
| 可以调用其他function 不能调用task | 可以调用其他function 可以调用其他task |
| 消耗 0 仿真时间 | 消耗 非0 仿真时间 |
| 不得包含任何延迟和时序控制语句 | 可以包含任何延迟和时序控制语句 |
| 必须至少有一个输入参数 | 可以有零个或多个类型为 input,output 或 inout 参数。 |
| 函数始终返回单个值。 他们不能有 output 或 inout参数 | 任务不返回值. 但可以通过 output 或 inout 参数传递多个值 |
AMBA2.0/4.0 AHB/AXI/AXI Stream(ARM spec)
自动布局布线
是否接触过自动布局布线?请说出一两种工具软件。自动布局布线需要哪些 基本元素?
自动布局布线其基本流程如下:
1、读入网表,跟 foundry 提供的标准单元库和 Pad 库以及宏模块库进行映射;
2、整体布局,规定了芯片的大致面积和管脚位置以及宏单元位置等粗略的信息;
3、读入时序约束文件,设置好 timing setup 菜单,为后面进行时序驱动的布局布 线做准备;
4、详细布局,力求使后面布线能顺利满足布线布通率 100%的要求和时序的要求;
5、时钟树综合,为了降低 clock skew 而产生由许多 buffer 单元组成的“时钟树”;
6、布线,先对电源线和时钟信号布线,然后对信号线布线,目标是最大程度地 满足时序;
7、为满足 design rule 从而 foundry 能成功制造出该芯片而做的修补工作,如填 充一些 dummy 等。常用的工具有 Synopsys 的 ASTRO,Cadence 的 SE,ISE,Quartus II 也可实现布局布线。
验证方法学
UVM ,验证环境搭建,组成部分,
名词解释
| CMOS | (Complementary Metal Oxide Semiconductor),互补金属氧化物半导体, 电压控制的一种放大器件。是组成 CMOS 数字集成电路的基本单元。 |
| MCU | (Micro Controller Unit)中文名称为微控制单元,又称单片微型计算机(Single Chip Microcomputer)或者单片机,是指随着大规模集成电路的出现及其发展,将 计算机的 CPU、RAM、ROM、定时数计器和多种 I/O 接口集成在一片芯片上,形 成芯片级的计算机,为不同的应用场合做不同组合控制。 |
| RISC | |
| FPGA | (Field-Programmable GateArray),即现场可编程门阵列,它是在 PAL、GAL、CPLD 等可编程器件的基础上进一步发展的产物。它是作为专用集成电路 (ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服 了原有可编程器件门电路数有限的缺点。 |
| ASIC | 专用集成电路,它是面向专门用途的电路,专门为一个用户设计和制造的。 根据一个用户的特定要求,能以低研制成本,短、交货周期供货的全定制,半定 制集成电路。与门阵列等其它 ASIC(ApplicationSpecific IC)相比,它们又具有设计 开发周期短、设计制造成本低、开发工具先进、标准产品无需测试、质量稳定以 及可实时在线检验等优点. |
| BIOS | Basic Input Output System基 本输入输出系统。其实,它是一组固化到计算机内主板上一个 ROM 芯片上的程序,它保存着计算机最重要的基本输入输出的程序、系统设置信息、开机后自检 程序和系统自启动程序。其主要功能是为计算机提供最底层的、最直接的硬件设 置和控制。 |
| USB | Universal Serial BUS(通用串行总线)的缩写,而其中文简称为“通 串线,是一个外部总线标准,用于规范电脑与外部设备的连接和通讯。 |
| DSP | (digital signal processor)是一种独特的微处理器,是以数字信号来处理大量 信息的器件。其工作原理是接收模拟信号,转换为 0 或 1 的数字信号。再对数字 信号进行修改、删除、强化,并在其他系统芯片中把数字数据解译回模拟数据或 实际环境格式。它不仅具有可编程性,而且其实时运行速度可达每秒数以千 万 条复杂指令程序,远远超过通用微处理器,是数字化电子世界中日益重要的电脑 芯片。它的强大数据处理能力和高运行速度,是最值得称道的两大特色。 |
要实现它,在硬件特性上有什么具体要求?
线与逻辑是两个输出信号相连可以实现与的功能。在硬件上,要用oc门来实现,由于不用oc门可能使灌电流过大,而烧坏逻辑门. 同时在输出端口应加一个上拉电阻。oc门就是集电极开路门。od门是漏极开路门。
分析组合逻辑电路的逻辑功能
所谓组合逻辑电路的分析,就是找出给定逻辑电路输出和输入之间的关系,并指出电路的逻辑功能。
分析过程一般按下列步骤进行:
1:根据给定的逻辑电路,从输入端开始,逐级推导出输出端的逻辑函数表达式。
2:根据输出函数表达式列出真值表;
3:用文字概括处电路的逻辑功能;
SPI(Serial peripheral interface):串行外设接口
SD(Secure Digital):SD卡/TF卡
USB(Universal Serial Bus):通用串行总线
LVDS(Low - Voltage Differential Signal):低电压差分总线
SerDes(Serializer / Deserializer):串行器/解串器
DDR(Double Data Rate):双倍数据速率
PCIe(Peripheral Component Interconnect Express):高速串行扩展总线
MAC(Media Access Control):以太网数据链路层
SATA(Serial Advanced Technology Attachment):串行ATA接口
3. 手撕
将传输过来的信号经过两级触发器就可以消除毛刺。
- module(
-
- input clk,data;
- output reg q_out
- );
-
- reg q1;
-
- always@(posedge clk)
- begin
- q1 <= data;
- q_out <= q1;
- end
-
- endmodule
- module div2(
- input clk,
- input rst,
- output clk_out
- );
-
- always@(posedge clk or negedge rst)
- begin
- if(!rst)
- clk_out <=0;
- else
- clk_out <=~ clk_out;
- end
-
- endmodule
现实工程设计中一般不采用这样的方式来设计,二分频一般通过 DCM 来实现。 通过 DCM 得到的分频信号没有相位差。
或者是从 Q 端引出加一个反相器。
可预置初值的7进制循环计数器
- module counter7(
- input clk,rst,load;
- input [2:0] data;
- output reg [2:0] cout
- );
- always@(posedge clk, negedge rst)
- begin
- if(!rst)
- cout<=3’d0;
- else if(load)
- cout<=data;
- else if(cout>=3’d6)
- cout<=3’d0;
- else
- cout<=cout+3’d1;
- end
- endmodule
D 触发器做 4 进制计数
按照时序逻辑电路的设计步骤来:
1、写出状态转换表
2、寄存器的个数确定
3、状态编码
4、卡诺图化简
5、状态方程,驱动方程等
阎石《数字电路》 P314
IC 设计流程和 eda 工具
逻辑设计→子功能分解→详细时序框图→分块逻辑仿真→电路设计(RTL 级描述) →功能仿真→综合(加时序约束和设计库)→电路网表→网表仿真)-预布局布线 (SDF 文件)→网表仿真(带延时文件)→静态时序分析→布局布线→参数提取→SDF 文件→后仿真→静态时序分析→测试向量生成→工艺设计与生产→芯片测试→ 芯片应用,在验证过程中出现的时序收敛,功耗,面积问题,应返回前端的代码 输入进行重新修改,再仿真,再综合,再验证,一般都要反复好几次才能最后送 去 foundry 厂流片。
4. 验证
验证的思想
验证就是在设计规范的要求下,对已知功能目标下的 DUT (design under test)进行检查,然而实际的使用场景是设计规范无法全面覆盖的,验证工程师只能在有限的资源与时间下对设计代码进行最大限度的检查以尽可能多地消除流片之后的 bug。
代码覆盖率和功能覆盖率
代码覆盖率 100% 不代表功能没问题。
(1)功能覆盖率高但是代码覆盖率低
分析未覆盖到的代码,推断仿真是否有遗漏的功能点,代码是否为冗余或不可达代码;
(2)功能覆盖率低但是代码覆盖率高
仿真用例没有关注到一些功能点,需要修改测试用例。
- 代码覆盖率
代码覆盖率 100%不代表代码中没有错误bug/error,知道表代码经过了充分的执行。
(1)分支覆盖率;
针对 if…else、case 等分支语句,看代码中设计的分支是否都被测试到了。
针对 if(条件1),只要条件 1 取 true 和 false 都执行过,则这个分支就完全覆盖了。
(2)语句覆盖率
语句覆盖率上不去时,可以查看未覆盖处的代码是测试用例的疏忽、冗余代码或是保护用途的代码,比如case的default(如果出现此类,一般是case的条件已经全部列出,可以将最后一个条件改为default);
(3)翻转覆盖率
包括两态翻转(0/1)和三态翻转(0/1/Z),常用的是两态翻转。对于单比特信号而言,若仿真用例使得该信号从0到1和从1到0的翻转均发生,则认为这里的翻转覆盖率是全面的(100%)。
即使翻转覆盖率达到 100%,分支覆盖率和语句覆盖率也不一定达到 100%。
(4)条件覆盖率;
条件覆盖率可以看作是对分支覆盖率的补充。每一个分支条件表达式中,所有条件的覆盖。
分支覆盖率100%不等于条件100%。
(5)状态机覆盖率;
状态机覆盖率主要检查当前状态到下一个状态的跳转是否都跳转过。
- 功能覆盖率
又称黑盒测试覆盖率,只关心功能,不关心具体的代码是如何实现的。与 spec 比较来发现,design 是否行为正确,需要按 verification plan 来比较进度。
如果想要统计功能覆盖率,需要在 SystemVerilog 编写的测试用例中添加覆盖组(需要根据功能写测试变量的覆盖率,工具按照覆盖率统计覆盖率),仿真器基于它来统计功能覆盖率。
实现方式主要分为覆盖点(coverage points)和断言(arrertion)。
不可以被综合的语句
产生的代码所有综合工具都不支持的结构 time,defparam,$finish,fork,join,initial,delays,UDP,wait
UVM 的优势
UVM 其实就是 SV 的一个封装,将我们在搭建测试平台过程中的一些重复性和重 要的工作进行封装,从而使我们能够快速的搭建一个需要的测试平台,并且可重 用性还高。但是 UVM 又不仅仅是封装。
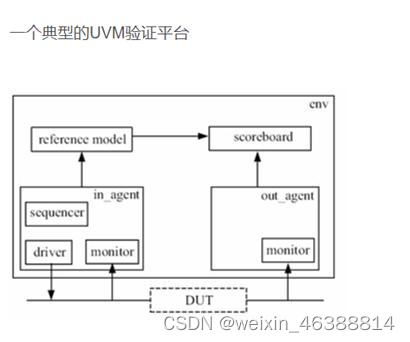
UVM 的工厂机制
Factory 机制也叫工厂机制,其存在的意义就是为了能够方便的替换 TB 中的实例 或者已注册的类型。一般而言,在搭建完 TB 后,我们如果需要对 TB 进行更改配 置或者相关的类信息,我们可以通过使用 factory 机制进行覆盖,达到替换的效 果,从而大大提高 TB 的可重用性和灵活性。
要使用 factory 机制先要进行:
- 将类注册到 factory 表中
- 创建对象,使用对应的语句 (type_id::create)
- 编写相应的类对基类进行覆盖。
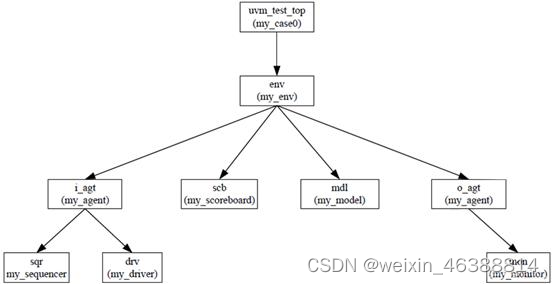
UVM的树形结构
OPP(面向对象)的特性
封装:通过将一些数据和使用这些数据的方法封装在一个集合里,成为一个类。
继承:允许通过现有类去得到一个新的类,且其可以共享现有类的属性和方法。 现有类叫做基类,新类叫做派生类或扩展类。
多态:得到扩展类后,有时我们会使用基类句柄去调用扩展类对象,这时候调用 的方法如何准确去判断是想要调用的方法呢?通过对类中方法进行 virtual 声明, 这样当调用基类句柄指向扩展类时,方法会根据对象去识别,调用扩展类的方法, 而不是基类中的。而基类和扩展类中方法有着同样的名字,但能够准确调用,叫 做多态。
优势:
易维护:采用面向对象思想设计的结构,可读性高,由于继承的存在,即使改变 需求,那么维护也只是在局部模块,所以维护起来是非常方便和较低成本的。
质量高:在设计时,可重用现有的,在以前的项目的领域中已被测试过的类使系 统满足业务需求并具有较高的质量。
效率高:在软件开发时,根据设计的需要对现实世界的事物进行抽象,产生类。 使用这样的方法解决问题,接近于日常生活和自然的思考方式,势必提高软件开 发的效率和质量。
易扩展:由于继承、封装、多态的特性,自然设计出高内聚、低耦合的系统结构, 使得系统更灵活、更容易扩展,而且成本较低。
动态数组和联合数组
动态数组:其内存空间在运行时才能够确定,使用前需要用 new[]进行空间分配。
关联数组:其主要针对需要超大空间但又不是全部需要所有数据的时候使用,类 似于 hash,通过一个索引值和一个数据组成: bit [63:0] name[bit[63:0]];索引值必 须是唯一的。
关联数组可以用来保存稀疏矩阵的元素。当你对一个非常大的地址空间寻址时, 该数组只为实际写入的元素分配空间,这种实现方法所需要的空间要小得多。
此外,关联数组有其它灵活的应用,在其它软件语言也有类似的数据存储结构, 被称为哈希(Hash)或者词典(Dictionary),可以灵活赋予键值(key)和数值 (value)
SV 中的 interface 的 clock blocking 的功能
Interface 是一组接口,用于对信号进行一个封装,捆扎起来。如果像 verilog 中 对各个信号进行连接,每一层我们都需要对接口信号进行定义,若信号过多,很 容易出现人为错误,而且后期的可重用性不高。因此使用 interface 接口进行连接, 不仅可以简化代码,而且提高可重用性,除此之外,interface 内部提供了其他一 些功能,用于测试平台与 DUT 之间的同步和避免竞争。
Clocking block:在 interface 内部我们可以定义 clocking 块,可以使得信号保持同步, 对于接口的采样和驱动有详细的设置操作,从而避免 TB 与 DUT 的接口竞争,减 少我们由于信号竞争导致的错误。采样提前,驱动落后,保证信号不会出现竞争。
编写测试用例
主要是编写 sequence,然后在 body 里面根据测试功能要求写相应的激励,然后再通过 ref_model 和 checker 判断功能是否实现?
自动执行很多测试用例
可以写脚本让它们自动执行,例如 makefile...
makefile:
一个工程中的源文件不计其数,其按类型、功能、模块分别放在若干个目录中, Makefile 文件定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为 Makefile 文件就像一个 Shell 脚本一样,也可以执行操作系统的命令。
Makefile 带来的好处就是自动化编译,一旦写好,只需要一个 make 命令,整 个工程完全自动编译,极大的提高了软件开发的效率。make 是一个命令工具,是一个 解释 Makefile 文件中指令的命令工具,一般来说,大多数的 IDE 都有这个命令, 比如 Delphi 的 make,Visual C++ 的 nmake,Linux 下 GNU 的 make。
soc/ip 验证之间的区别和侧重点
SoC 和 IP 从独立性来看,前者较后者更为独立,往往具备更加完整的功能。
SoC 会由多个 IP、子系统和其它系统模块构成,从层次来看,IP 是构成 SoC 的重要 组成部分。 在验证 SoC 时,首先需要确保其 IP 级别都完成了验证,而在系统级别需要验证 各个模块之间的交互和协调情况、集成连线情况,测试用例会更加真实,当然, 仿真速度也下降很快,一般需要做门级仿真。
在 IP 级验证时,如果是内部 IP,那么需要就接下来的运用场景(配置情况), 展开重点性的验证,如果是向外部提供的 IP,那么需要针对其参数配置展开更 为全面细致的验证工作,所以其特点不但是要求验证每一项功能,而且是每一项 功能在不同配置下的行为是否是正确的。
5. 面试问过的
按键防抖怎么实现的?计数多少个周期?
计数器,1/(2^15)*830=25ms
RTL输入的是数字信号还是模拟信号?
数字信号。FPGA按键模拟霍尔传感器输入低电平信号。
c语言用过指针吗?知道void型指针?
指针:一种变量类型,它存储了一个内存地址,这个地址指向计算机内存中的某个特定位置。C语言中的指针可以指向不同类型的数据,例如整数、浮点数、字符等。
而void指针(void *)是一种特殊类型的指针,它可以指向任何类型的数据。换句话说,void指针是一种泛型指针,因为它不关心所指向数据的具体类型。这种特性使得void指针在某些情况下非常有用。
综合工具?对模块里的时钟有约束吗?时钟约束是多少,占多少个周期?
Design compiler。有约束。时钟周期是20ns。
一个clock cycle是30
RTL设计有用到第三方库,designfile这些?
(问题都没听懂,没答上来)
rtl设计 第三方库水现成ip
Cpu实现哪些指令?什么架构?指令loadword?访存过程?
picomips项目里,有哪些指令?我设计的7种指令(WAIT0,IN,OUT,ADD,ADDI,SUB,MUL)
MIPS架构,五级流水线(取指、解码、访存、操作、回写)

二进制补码
![]()

MIPS里访存是一个周期就能拿到数据吗?
是
怎么验证处理器?FPGA验证?
验证cpu结果?用TB,FPGA
Pc是什么?为什么总是+4?

+1比特还是字节?
byte,加的是地址
8bit除法器算法是什么样的?
布什算法?G2T4除法器?(听都没听过)
HSPICE最优性能仿真是什么意思?性能还是面积?
设计过不同电压器件?相当于用统一工具生成的?
浮点数相对误差还绝对误差?

16位的浮点数构成?
IEEE格式
1bit符号位+8bit指数位+7bit尾数位

加法器项目中bias偏阶是127
16bit: 0 / 0000 0000 / 0000 000
S / EEEE EEEE / MMMM MMM
Bit15(符号位): 0代表正数,1代表负数
Bit14-7(指数位):指出小数点的位置:E= x+127 (x是个负数,十进制)
Bit6-0(尾数):
example:0.15625(十进制) - 0.00101(二进制) - 0 0111 1111 101 0000(IEEE)
非数代表什么?NAN
Not a Number
特殊数:
| 数值 | Sign(bit15) | Exponent(14-7) | Mantissa(6-0) |
| 0 | 0/1 | 0 | 0 |
| 正无穷 | 0 | 255 | 0 |
| 负无穷 | 1 | 255 | 0 |
| NaN | 0/1 | 255 | ≠0 |
| 随机数 | 0/1 | 1-254 | 任意 |
非数和正常数计算流程?
不计算,直接输出NaN
怎么验证这个项目正确性?
有没有考虑用遍历的方法验证?
517.57ns

