
- 1中台的前世今生及价值与方案【推荐】_算法中台的主要价值
- 2大模型应用系列——智能体(Agent)_大模型agent
- 3ora-01720 授权选项对于xxxx不存在_grant select on a to b 报错
- 4Spark Streaming+Kafka整合+offset管理_spark.streaming.kafka.allownonconsecutiveoffsets
- 5kafka初识 之 Topic、Partition、生产者、消费者、Broker、Cluster概念分析_kafka topic partition broker
- 6AD534KDZ 模拟IC乘法器除法器_ad534乘法器仿真
- 72017年上海交通大学软件学院暑期夏令营机试题目_上海交通大学软件学院 夏令营 机考题
- 8探索高效UI开发:jh_flutter_demo项目全面解析
- 9锅总详解Jenkins应用
- 10(附源码)python+mysql+基于springboot小型车队管理系统 毕业设计061709_python车队管理系统
faiss向量数据库测试《三体》全集,这家国产AI加速卡,把性能提了7倍!
赞
踩
在人工智能和机器学习技术的飞速发展中,向量数据库在处理高维数据方面扮演着日益重要的角色。近年来,随着大型模型的流行,向量数据库技术也得到了进一步的发展和完善。
向量数据库为大型模型提供了一个高效的数据管理和检索平台,使得这些模型能够更加高效地处理非结构化数据,并在各种应用场景中发挥其潜力,执行复杂的查询和分析任务。
Faiss(Facebook AI Similarity Search)是一个用于高效相似性搜索和密集向量聚类的库,它广泛应用于图像检索、推荐系统和自然语言处理等领域。然而,随着数据规模的不断扩大和维度的增加,如何在保证搜索质量的同时提升搜索速度成为了一个挑战。海光DCU(Data Center Unit)作为一种高性能的计算加速解决方案,能够有效提升Faiss向量数据库的搜索性能。
Faiss向量数据库简介
Faiss是由Facebook AI Research团队开发的一个开源库,专门用于高效地进行大规模向量的相似性搜索和聚类。它支持对十亿级别的向量进行搜索,是目前较为成熟的近似近邻搜索库之一。Faiss用C++编写,并提供了与Numpy紧密结合的Python接口,不仅支持CPU计算,对一些核心算法还支持GPU计算。
海光DCU简介
海光DCU(Data Center Unit)是一款高效通用的GPGPU加速卡,专为人工智能和科学计算任务设计。它在兼容性、软件生态和市场应用方面展现出卓越的价值。海光DCU全面兼容“类 CUDA”环境。这种强大的兼容性为用户提供了在AI和大数据处理领域的强大计算服务能力,其在国产加速卡领域中的生态兼容性处于领先地位。
DCU环境部署
本次测试使用了一台装备有两张海光Z100L加速卡的服务器X7840H0,服务器操作系统为Ubuntu 22.04.1 LTS。
准备开发测试环境,相关的程序和文档可以通过光和开发者社区获取,地址是https://developer.hpccube.com。

在服务器系统上部署开发测试环境,用户可以通过点击页面上的资源工具访问驱动、DTK、DAS、镜像等资源的下载界面。

《开发环境安装部署手册》可以通过点击DTK Toolkit下载地址,然后选择最新的latest,然后选择Document目录获取。除了开发环境安装部署手册外,还有开发环境使用手册、兼容性手册等常用的说明文档。

《开发环境安装部署手册》中包含了多个常用系统下的基础环境部署,可以根据使用的系统选择对应的环境部署流程:

根据测试机服务器的操作系统版本,本次测试选择Ubuntu20.04.1操作系统基础环境部署。

按照手册中要求的首先安装驱动以及DTK的依赖包,然后安装驱动程序和DTK,设备的DCU开发测试环境即可部署完成。环境部署完成后输入hy-smi指令即可查询DCU的使用信息:

除了使用物理机的系统环境开发测试外,还可以使用官方提供的基础环境镜像,镜像下载地址:https://sourcefind.cn/#/main-page。

使用官方提供的镜像可以节省大量基础环境的部署工作。本次测试就使用到了名称为1.13.1-centos7.6-dtk-23.04.1-py38-latest的镜像,镜像内已部署好了pytorch等相关的第三方包。然后安装光和开发者社区中提供的faiss安装包以及测试代码所需的pandas等三方包就可以进入下一步准备faiss的测试程序。
搜索性能测试
为了测试faiss的搜索效率,本次测试以文本相似度搜索为例,分别在CPU和GPU场景下进行测试。测试流程包括将批量文本数据导入faiss向量数据库,然后搜索一段文本中不存在的数据,并取多次测试的平均值进行对比。
将文本数据转换为向量数据需要用到Embedding嵌入模型,本次测试中选择了效果出色的shibing624/text2vec-base-chinese。

文本内容本次测试选择了《三体》全集,文本存储在三体.txt文件中。由于Embedding嵌入模型的输入长度限制,首先需要将文本内容进行分段再传入嵌入模型。然后将嵌入模型转换完成的向量数据使用numpy存储在本地data.npy文件中,用来方便后续测试。代码如下:
- import warnings
- warnings.simplefilter(action='ignore', category=FutureWarning)
- import pandas as pd
- df=pd.read_csv("三体.txt",encoding='utf-8',sep="#",header=None, names=["sentence"])
- print(df)
- from sentence_transformers import SentenceTransformer
- model=SentenceTransformer('shibing624/text2vec-base-chinese')
- sentences =df['sentence'].tolist()
- sentence_embeddings=model.encode(sentences)
- print("数据向最维度:")
- print(sentence_embeddings.shape)
- save_file = "data.npy"
- import numpy as np
- np.save(save_file,sentence_embeddings)
- import os
- file_size = os.path.getsize(save_file)
- print("保存数据文件:%7.3f MB"%(file_size/1024/1024))

运行代码之后打印信息如下:

向量数据准备好之后使用faiss分别加载三体全集和data.npy向量数据,然后使用faiss中提供的IndexFlatL2索引方式加载这些向量数据,然后在搜索“大史喜欢抽烟”这几个原文中没有的文本。faiss_test.py测试代码如下:
- import faiss
- import numpy as np
- import pandas as pd
- import warnings
- warnings.simplefilter(action='ignore', category=FutureWarning)
- print("load 三体.txt...")
- df = pd.read_csv("三体.txt", encoding='utf-8', sep="#", header=None, names=["sentence"])
- print("load vector data...")
- sentence_embeddings = np.load("data.npy")
- dimension = sentence_embeddings.shape[1]
- index = faiss.IndexFlatL2(dimension)
- index.add(sentence_embeddings)
- import time
- from sentence_transformers import SentenceTransformer
- model = SentenceTransformer('shibing624/text2vec-base-chinese')
- topk = 5
- words = ["大史喜欢抽烟"]
- search = model.encode(words)
- print("search: " + str(words))
- costs = []
- for i in range(10):
- to = time.time()
- D, I = index.search(search, topk)
- ti = time.time()
- costs.append(ti - to)
- print(D)
- print(I)
- print(df['sentence'].iloc[I[0]])
- print("平均耗时 %7.3f ms" % ((sum(costs) / len(costs)) * 1000.0))
使用GPU的方式搜索可以将上面代码中的index使用index_cpu_to_all_gpus的方法将索引数据创建在GPU中,然后构建索引数据。faiss_gpu_test.py代码如下:
- import faiss time warnings
- import numpy as np
- import pandas as pd
- warnings.simplefilter(action='ignore', category=FutureWarning)
- print("load 三体.txt...")
- df = pd.read_csv("三体.txt", encoding='utf-8', sep="#", header=None, names=["sentence"])
- print("load vector data...")
- sentence_embeddings = np.load("data.npy")
- dimension = sentence_embeddings.shape[1]
- index = faiss.IndexFlatL2(dimension)
- ngpus = faiss.get_num_gpus()
- print("number of GPU:", ngpus)
- gpu_index = faiss.index_cpu_to_all_gpus(index)
- gpu_index.add(sentence_embeddings)
- from sentence_transformers import SentenceTransformer
- model = SentenceTransformer('shibing624/text2vec-base-chinese')
- topk = 5
- words = ["大史喜欢抽烟"]
- search = model.encode(words)
- print("search: " + str(words))
- costs = []
- for i in range(10):
- to = time.time()
- D, I = gpu_index.search(search, topk)
- ti = time.time()
- costs.append(ti - to)
- print(D)
- print(I)
- print(df['sentence'].iloc[I[0]])
- print("平均耗时 %7.3f ms" % ((sum(costs) / len(costs)) * 1000.0))
在服务器环境中分别运行faiss_test.py和faiss_gpu_test.py即可获取到faiss的搜索结果:

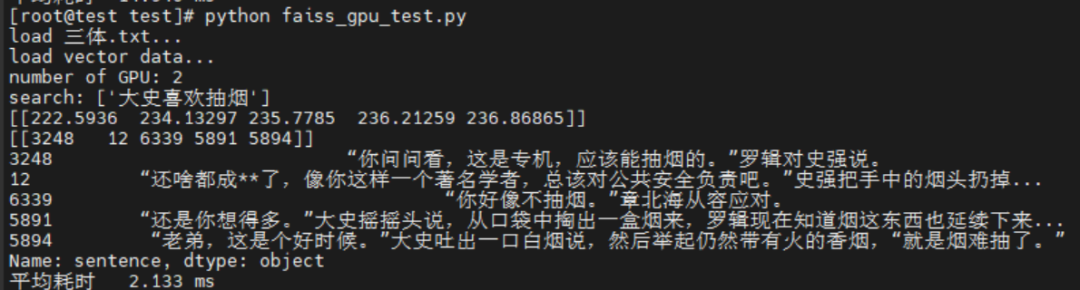
分析汇总
对两份代码的运行结果进行对比可以明显看到海光DCU的加速效果明显,较CPU索引的方式提高了7倍左右的性能。
本次测试使用到的文本数据量较低,随着数据量的增加,DCU的加速效果会更加明显。测试代码中的索引方式使用到了faiss中最基本的IndexFlatL2,它使用 L2 距离(欧氏距离)进行暴力搜索(brute-force search),适用于向量数量较小的情况。由于它在内存中存储所有向量,因此当向量数量较大时,内存开销会很大。除此之外faiss中常用的还有IndexIVFFlat、IndexIVFPQ等索引方式可以显著减少索引的内存资源占用。

