
【OGG】OGG基础知识整理_ogg setenv nls_lang
赞
踩
一、GoldenGate介绍
GoldenGate软件是一种基于日志的结构化数据复制软件。GoldenGate 能够实现大量交易数据的实时捕捉、变换和投递,实现源数据库与目标数据库的数据同步,保持亚秒级的数据延迟。
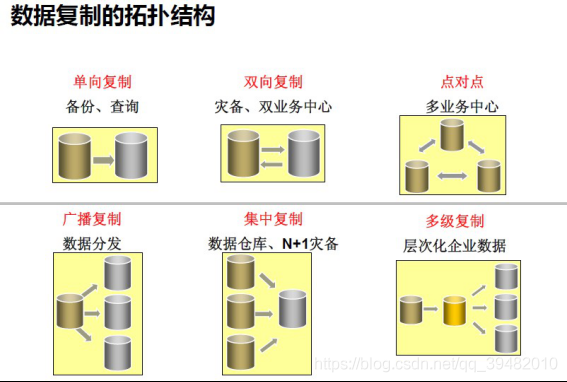
GoldenGate能够支持多种拓扑结构,包括一对一,一对多,多对一,层叠和双向复制等等。
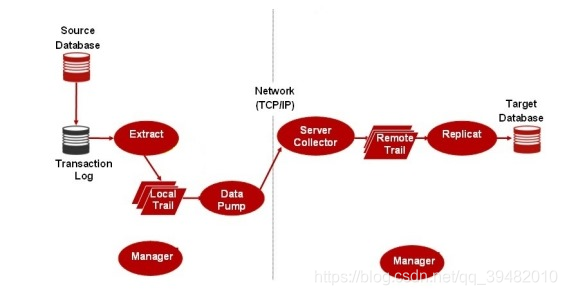
GoldenGate基本架构
Oracle GoldenGate主要由如下组件组成
● Extract
● Data pump
● Trails
● Collector
● Replicat
● Manager
Oracle GoldenGate 数据复制过程如下:
利用抽取进程(Extract Process)在源端数据库中读取Online Redo Log或者Archive Log,然后进行解析,只提取其中数据的变化信息,比如DML操作——增、删、改操作,将抽取的信息转换为GoldenGate自定义的中间格式存放在队列文件(trail file)中。再利用传输进程将队列文件(trail file)通过TCP/IP传送到目标系统。
目标端有一个进程叫Server Collector,这个进程接受了从源端传输过来的数据变化信息,把信息缓存到GoldenGate 队列文件(trail file)当中,等待目标端的复制进程读取数据。
GoldenGate 复制进程(replicat process)从队列文件(trail file)中读取数据变化信息,并创建对应的SQL语句,通过数据库的本地接口执行,提交到目标端数据库,提交成功后更新自己的检查点,记录已经完成复制的位置,数据的复制过程最终完成。
Oracle GoldenGate(OGG)可以在多样化和复杂的 IT 架构中实现实时事务更改数据捕获、转换和发送;其中,数据处理与交换以事务为单位,并支持异构平台,例如:DB2,MSSQL等
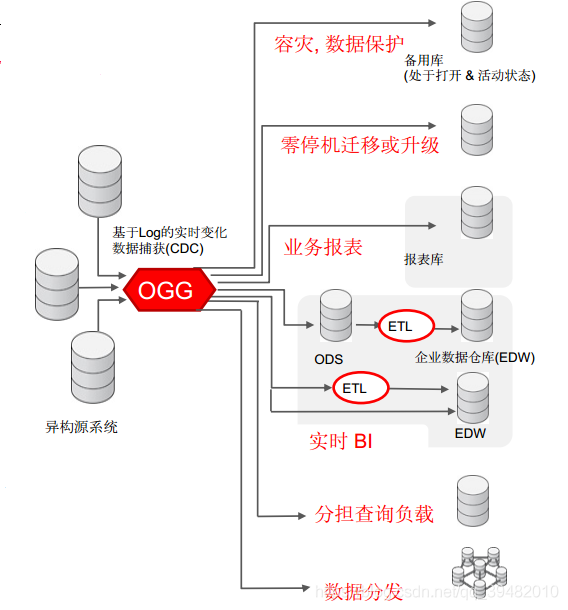
Golden Gate 所支持的方案主要有两大类,用于不同的业务需求:
● 高可用和容灾解决方案
● 实时数据整合解决方案
其中,高可用和容灾解决方案 主要用于消除计划外和计划内停机时间,它包含以下三个子方案:
1. 容灾与应急备份
2. 消除计划内停机
3. 双业务中心(也称:双活)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

实时数据整合解决方案 主要为 DSS 或 OLTP 数据库提供实时数据,实现数据集成和整合,它包含以下两个子方案:
1. 数据仓库实时供给
2. 实时报表
- 1
- 2
- 3
灵活拓扑结构实现用户的灵活方案:
- 1

下图是一个典型的 Golden Gate 配置逻辑结构图:
- 1
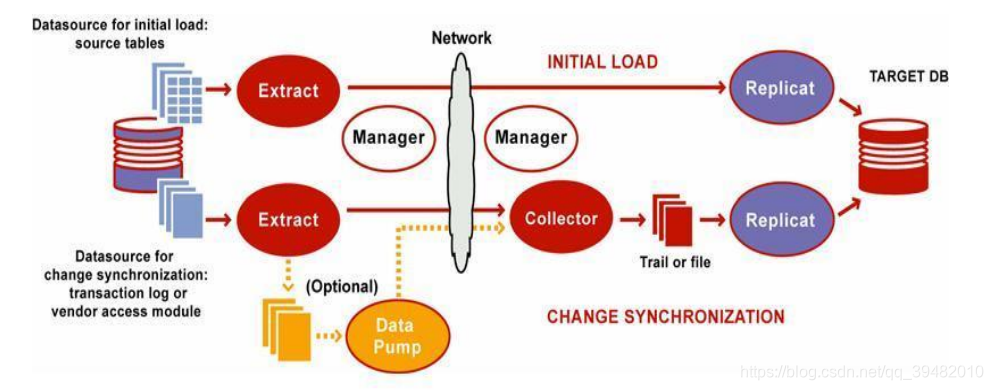
① Manager 顾名思义、Manager进程是Golden Gate中进程的控制进程,用于管理 Extract,Data Pump,Replicat等进程 在 Extract、Data Pump、Replicat 进程启动之前,Manager 进程必须先要在源端和目标端启动 在整个 Golden Gate 运行期间,它必须保持运行状态 ⒈ 监控与启动 GoldenGate 的其它进程 ⒉ 管理 trail 文件及 Reporting 在 Windows 系统上,Manager 进程是作为一个服务来启动的,在 Unix 系统下是一个进程 ② Extract Extract 进程运行在数据库源端上,它是Golden Gate的捕获机制,可以配置Extract 进程来做如下工作: ⒈ 初始数据装载:对于初始数据装载,Extract 进程直接从源对象中提取数据 ⒉ 同步变化捕获:保持源数据与其它数据集的同步。初始数据同步完成后,Extract 进程捕获源数据的变化;如DML变化、 DDL变化等 ③ Replicat Replicat 进程是运行在目标端系统的一个进程,负责读取 Extract 进程提取到的数据(变更的事务或 DDL 变化)并应用到目标数据库 就像 Extract 进程一样,也可以配置 Replicat 进程来完成如下工作: ⒈ 初始化数据装载:对于初始化数据装载,Replicat 进程应用数据到目标对象或者路由它们到一个高速的 Bulk-load 工具上 ⒉ 数据同步,将 Extract 进程捕获到的提交了的事务应用到目标数据库中 ④ Collector Collector 是运行在目标端的一个后台进程 接收从 TCP/IP 网络传输过来的数据库变化,并写到 Trail 文件里 动态 collector:由管理进程自动启动的 collector 叫做动态 collector,用户不能与动态 collector 交互 静态 collector:可以配置成手工运行 collector,这个 collector 就称之为静态 collector ⑤ Trails 为了持续地提取与复制数据库变化,GoldenGate 将捕获到的数据变化临时存放在磁盘上的一系列文件中,这些文件就叫做 Trail 文件 这些文件可以在 source DB 上也可以在目标 DB 上,也可以在中间系统上,这依赖于选择哪种配置情况 在数据库源端上的叫做 Local Trail 或者 Extract Trail;在目标端的叫做 Remote Trail ⑥ Data Pumps Data Pump 是一个配置在源端的辅助的 Extract 机制 Data Pump 是一个可选组件,如果不配置 Data Pump,那么由 Extract 主进程将数据发送到目标端的 Remote Trail 文件中 如果配置了 Data Pump,会由 Data Pump将Extract 主进程写好的本地 Trail 文件通过网络发送到目标端的 Remote Trail 文件中 使用 Data Pump 的好处是: ⒈ 如果目标端或者网络失败,源端的 Extract 进程不会意外终止 ⒉ 需要在不同的阶段实现数据的过滤或者转换 ⒊ 多个源数据库复制到数据中心 ⒋ 数据需要复制到多个目标数据库 ⑦ Data source 当处理事务的变更数据时,Extract 进程可以从数据库(Oracle, DB2, SQL Server, MySQL等)的事务日志中直接获取 或从 GoldenGate VAM中获取。通过 VAM,数据库厂商将提供所需的组件,用于 Extract 进程抽取数据的变更 ⑧ Groups 为了区分一个系统上的多个 Extract 和 Replicat 进程,我们可以定义进程组 例如:要并行复制不同的数据集,我们可以创建两个 Replicat 组 一个进程组由一个进程组成(Extract 进程或者 Replicat 进程),一个相应的参数文件,一个 Checkpoint 文件,以及其它与之相关的文件 如果处理组中的进程是 Replicat 进程,那么处理组还要包含一个 Checkpoint 表

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
GoldenGate简介
Oracle Golden Gate软件是一种基于日志的结构化数据复制备份软件,它通过解析源数据库在线日志或归档日志获得数据的增量变化,再将这些变化应用到目标数据库,从而实现源数据库与目标数据库同步。Oracle Golden Gate可以在异构的IT基础结构(包括几乎所有常用操作系统平台和数据库平台)之间实现大量数据亚秒一级的实时复制,从而在可以在应急系统、在线报表、 实时数据仓库供应、交易跟踪、数据同步、集中/分发、容灾、数据库升级和移植、双业务中心等多个场景下应用。同时,Oracle Golden Gate可以实现一对一、广播(一对多)、聚合(多对一)、双向、点对点、级联等多种灵活的拓扑结构。
GoldenGate技术架构
和传统的逻辑复制一样,Oracle GoldenGate实现原理是通过抽取源端的redo log或者archive log,然后通过TCP/IP投递到目标端,最后解析还原应用到目标端,使目标端实现同源端数据同步。以下是OracleGoldenGate的技术架构:
Manager进程
Manager进程是GoldenGate的控制进程,运行在源端和目标端上。它主要作用有以下几个方面:启动、监控、重启Goldengate的其他进程,报告错误及事件,分配数据存储空间,发布阀值报告等。在目标端和源端有且只有一个manager进程,其运行状态为running好stopped。 在windows系统上,manager进程作为一个服务来启动,二在Linux/Unix系统上则是一个系统进程。
Extract进程
Extract运行在数据库源端,负责从源端数据表或者日志中捕获数据。Extract的作用可以按照表来时间来划分:
初始时间装载阶段:在初始数据装载阶段,Extract进程直接从源端的数据表中抽取数据。
同步变化捕获阶段:初始数据同步完成以后,Extract进程负责捕获源端数据的变化(DML和DDL)
GoldenGate并不是对所有的数据库都支持ddl操作
Extract进程会捕获所有已配置的需要同步的对象变化,但只会将已提交的事务发送到远程的trail文件用于同步。当事务提交时,所有和该事务相关的 日志记录被以事务为单元顺序的记录到trail文件中。Extract进程利用其内在的checkpoint机制,周期性的记录其读写的位置,这种机制是 为了保证Extract进程终止或操作系统当机,重新启动Extract后,GoldenGate可以恢复到之前的状态,从上一个断点继续往下运行。通过 上面的两个机制,就可以保证数据的完整性了。
多 个Extract 进程可以同时对不同对象进行操作。例如,可以在一个extract进程抽取并向目标端发生事务数据的同时,利用另一个extract进程抽取的数据做报 表。或者,两个extract进程可以利用两个trail文件,同时抽取并并行传输给两个replicat进程以减少数据同步的延时。
在进行初始化转载,或者批量同步数据时, GoldenGate会生成extract文件来存储数据而不是trail文件。默认情况下, 只会生成一个 extract文件,但如果出于操作系统对单个文件大小限制或者其他因素的考虑,也可以通过配置生成多个 extract文件。 extract文件不记录检查点。
Extract进程的状态包括Stopped(正常停止),Starting(正在启动),Running(正在运行),Abended(Abnomal End的缩写,标示异常结束)。
Pump进程
pump进程运行在数据库源端,其作用是将源端产生的本地trail文件,把trail以数据块的形式通过TCP/IP 协议发送到目标端,这通常也是推荐的方式。pump进程本质是extract进程的一种特殊形式,如果不使用trail文件,那么extract进程在抽取完数据以后,直接投递到目标端,生成远程trail文件。
与 Pump进程对应 的叫Server Collector进程,这个进程不需要引起我的关注,因为在实际操作过程中,无需我们对其进行任何配置,所以对我们来说它是透明的。它运行在目标端,其 任务就是把Extract/Pump投递过来的数据重新组装成远程ttrail文件。
注意:无论是否使用pump进程,在目标端都会生成trail文件
pump进程可以在线或者批量配置,他可以进行数据过滤,映射和转换,同时他还可以配置为“直通模式”,这样数据被传输到目标端时就可以直接生成所需的格式,无需另外操作。 直通模式提高了data pump的效率,因为生成后的对象 不需要继续进行检索。
在大多数情况下,oracle都建议采用data pump,原因如下:
1、为目标端或网络问题提供保障 :如果只在目标端配置trail文件,由于源端会将extract进程抽取的内容不断的保存在内存中,并及时的发送到目标端。当网络或者目标端出现故障时, 由于extract进程无法及时的将数据发送到目标, extract进程将耗尽内存然后异常终止。 如果在源端配置了data pump进程,捕获的数据会被转移到硬盘上,预防了 异常终止的情况。当故障修复,源端和目标端 恢复连通性时,data pump进程发送源端的trail文件到目标端。
2、 可以支持复杂的数据过滤或者转换: 当使用数据过滤或者转换时,可以先配置一个data pump进程在目标端或者源端进行第一步的转换,利用另一个data pump进程或者 Replicat组进行第二部的转换。
3、有效的规划存储资源 :当从多个数据源同步到一个数据中心时,采用data pump的方式,可以在源端保存抽取的数据,目标端保存trail文件,从而节约存储空间。
4、解决单数据源向多个目标端传输数据的单点故障: 当从一个数据源发送数据到多个目标端时,可以为每个目标端分别配置不同的data pump进程。这样如果某个目标端失效或者网络故障时,其他的目标端不会受到影响可以继续同步数据。
Replicat进程
Replicat进程,通常我们也把它叫做应用进程。运行在目标端,是数据传递的最后一站,负责读取目标端trail文件中的内容,并将其解析为DML或 DDL语句,然后应用到目标数据库中。
和Extract进程一样,Replicat也有其内部的checkpoint机制,保证重启后可以从上次记录的位置开始恢复而无数据损失的风险。
Replicat 进程的状态包括Stopped(正常停止),Starting(正在启动),Running(正在运行),Abended(Abnomal End的缩写,标示异常结束)。
Trail文件
为了更有效、更安全的把数据库事务信息从源端投递到目标端。GoldenGate引进trail文件的概念。前面提到extract抽取完数据以后 Goldengate会将抽取的事务信息转化为一种GoldenGate专有格式的文件。然后pump负责把源端的trail文件投递到目标端,所以源、 目标两端都会存在这种文件。 trail文件存在的目的旨在防止单点故障,将事务信息持久化,并且使用checkpoint机制来记录其读写位置,如果故障发生,则数据可以根据checkpoint记录的位置来重传 。 当然,也可以通过extract通过TCP/IP协议直接发送到目标端,生成远程trail文件。但这种方式可能造成数据丢失,前面已经提到过了,这里不再赘述。
Trail文件默认为10MB,以两个字符开始加上000000~999999的数字作为文件名。如c:\directory/tr000001.默认情况下存储在GoldenGate的dirdat子目录中。可以为不同应用或者对象创建不同的trail文件。同一时刻,只会有一个extract进程处理一个trail文件。
10.0版本以后的GoldenGate,会在trail文件头部存储包含trail文件信息的记录,而10.0之前的版本不会存储该信息。每个trail文件中的数据记录包含了数据头区域和数据区域。在 数据头区域中包含事务信息,数据区域包含实际抽取的数据
进程如何写trail文件
为了减小系统的I/O负载,抽取的数据通过大字节块的方式存储到trail文件中。同时为了提高兼容性,存储在trail文件中的数据以通用数据模式(一种可以在异构数据库之间进行快速而准确转换的模式)存储。 当然,根据不同应用的需求,数据也可以存储为不同的模式。
默认情况下,extract进程以追加的方式写入trail文件。当extract进程异常终止时,trail文件会被标记为需要恢复。当extract重新启动时会追加checkpoint之后的数据追加到该trail文件中。在 GoldenGate 10.0之前的版本, extract进程采用的是覆盖模式。即当 extract进程异常终止,则会将至上次完整写入的事务数据之后的数据覆盖现有trail文件中的内容。
这里是笔者理解不是很透彻,原文如下,望读者给予建议
By default, Extract operates in append mode, where if there is a process failure, a recovery marker is written to the trail and Extract appends recovery data to the file so that a history of all prior data is retained for recovery purposes.
In append mode, the Extract initialization determines the identity of the last complete transaction that was written to the trail at startup time. With that information, Extract ends recovery when the commit record for that transaction is encountered in the data source; then it begins new data capture with the next committed transaction that qualifies for extraction and begins appending the new data to the trail. A data pump or Replicat starts reading again from that recovery point.
Overwrite mode is another version of Extract recovery that was used in versions of GoldenGate prior to version 10.0. In these versions, Extract overwrites the existing transaction data in the trail after the last write-checkpoint position, instead of appending the new data. The first transaction that is written is the first one that qualifies for extraction after the last read checkpoint position in the data source.
checkpoint
checkpoint用于抽取或复制失败后(如系统宕机、网络故障灯),抽取、复制进程重新定位抽取或者复制的起点。在高级的同步配置中,可以通过配置checkpoint另多个extract或者replicat进程读取同个trail文件集。
extract进程在数据源和trail文件中都会标识checkpoint,Replicat只会在trail文件中标示checkpoint。
在批处理模式中,extract和replicat进程都不会记录checkpoint。如果批处理失败,则整改批处理会重新进行。
checkpoint信息会默认存储在goldengate的子目录dirchk中。在目标端除了checkpoint文件外,我们也可以通过配置通过额外checkpoint table来存储replicat的checkpoint信息。
Group
我们可以通过为不同的extract和replicat进程进行分组来去区分不同进程之间的作用。例如,当需要并行的复制不同的数据集时,我们则可以创建两个或者多个复制进程。
进程组中包含进程,进程文件,checkpoint文件和其他与进程相关的文件。对于replicat进程来说,如果配置了checkpoint table,则不同组的都会包含checkpoint table。
组的命名规则如下
GGSCI
GGSCI是GoldenGate Software Command Interface 的缩写,它提供了十分丰富的命令来对Goldengate进行各种操作,如创建、修改、监控GoldenGate进程等等。
Commit Sequence Number
前文已经多次提到,Goldengate是以事务为单位来保证数据的完整性的,那么 GoldenGate又是怎么识别事务的呢? 这里用到的是Commit Sequence Number(CSN)。CSN存储在事务日志中和trail文件中 ,用于数据的抽取和复制。CSN作为事务开始的标志被记录在trail文件中,可以通过@GETENV字段转换函数或者logdump工具来查看。不同的数据库平台的CSN显示如下
GoldenGate对不同数据库的支持情况
*只能作为目标端,不能作为源端。但Goldengate可以从mysql直接装载的原表中抽取数据。(由于笔者不了解mysql,这里只是在字面意思翻译,原文如下
the exception being that GoldenGate can extract records from MySQL source tables as part of a GoldenGate direct load.
** GoldenGate进行事务数据管理的API工具
*** 只支持镜像复制,不支持数据操作、过滤,字段映射等。
参考至:《Oracle GoldenGate Administrator Guide》
《企业级IT运维宝典之GoldenGate实战_第1章》联动北方著
二、GoldenGate安装实施
2.1创建GoldenGate软件安装目录
在数据库服务器上创建文件系统:/u01/gg,作为GoldenGate的安装目录。
2.2 GoldenGate的管理用户
安装GoldenGate软件和维护GoldenGate软件时,可以使用系统上的oracle用户。GoldenGate安装目录的所有者必须是GoldenGate管理用户,本次实施过程中使用oracle用户作为GoldenGate管理用户,添加oracle用户的环境变量(在生产端和容灾端均要进行以下操作):
export GG_HOME=/u01/gg
export LD_LIBRARY_PATH= G G H O M E : GG_HOME: GGHOME:ORACLE_HOME/lib:/usr/bin:/lib
export PATH=
G
G
H
O
M
E
:
GG_HOME:
GGHOME:PATH
2.3安装GoldenGate软件
切换到oracle用户,将GG软件的压缩包存放到GoldenGate安装目录下,即/u01/gg,将这个压缩包进行解压到GoldenGate安装目录下(在生产端和容灾端均要进行以下操作):
tar -zxvf *.gz
进入到GoldenGate安装目录,运行GGSCI命令以进入GG界面(在生产端和容灾端均要进行以下操作):
cd /u01/gg
./ggsci
在GGSCI界面下创建子目录(在生产端和容灾端均要进行以下操作):
GGSCI>create subdirs
至此,GoldenGate软件安装完毕。
2.4设置数据库归档模式
查看数据库的归档模式:
SQL>archive log list;
如果是非归档模式,需要开启归档模式:
shutdown immediate;
startup mount;
alter database archivelog;
alter database open;
2.5打开数据库的附加日志
打开附加日志并切换日志(保证Online redo log和Archive log一致)
alter database add supplemental log data ;
alter database add supplemental log data (primary key, unique,foreign key) columns;
alter system switch logfile;
2.6开启数据库强制日志模式
alter database force logging;
2.7创建GoldenGate管理用户
在生产端和容灾端均要进行以下操作:
–create tablespace
SQL>create tablespace ogg datafile ‘$ORACLE_BASE/oradata/test/ogg01.dbf’ size 300M ;
– create the user
SQL>create user ogg identified by ogg default tablespace ogg;
– grant role privileges
SQL>grant resource, connect, dba to ogg;
2.8编辑GLOBALS参数文件
切换到GoldenGate安装目录下,执行命令:
cd /u01/gg
./ggsci
GGSCI>EDIT PARAMS ./GLOBALS
在文件中添加以下内容:
GGSCHEMA ogg --指定的进行DDL复制的数据库用户
利用默认的密钥,生成密文:
GGSCI>encrypt password ogg encryptkey default
Encrypted password: AACAAAAAAAAAAADAHBLDCCIIOIRFNEPB
记录这个密文,将在以下进程参数的配置中使用。
- 1
2.9管理进程MGR参数配置
PORT 7839
DYNAMICPORTLIST 7840-7860
–AUTOSTART ER *
–AUTORESTART EXTRACT *,RETRIES 5,WAITMINUTES 3
PURGEOLDEXTRACTS ./dirdat/*,usecheckpoints, minkeepdays 2
userid ogg, password AACAAAAAAAAAAADAHBLDCCIIOIRFNEPB, ENCRYPTKY default
PURGEDDLHISTORY MINKEEPDAYS 11,MAXKEEPDAYS 14
PURGEMARKERHISTORY MINKEEPDAYS 11, MAXKEEPDAYS 14
2.10抽取进程EXTN参数配置
EXTRACT extn
setenv (NLS_LANG=AMERICAN_AMERICA.WE8MSWIN1252)
userid ogg, password AACAAAAAAAAAAADAHBLDCCIIOIRFNEPB, ENCRYPTKEY default
REPORTCOUNT EVERY 1 MINUTES, RATE
DISCARDFILE ./dirrpt/discard_extn.dsc,APPEND,MEGABYTES 1024
DBOPTIONS ALLOWUNUSEDCOLUMN
WARNLONGTRANS 2h,CHECKINTERVAL 3m
EXTTRAIL ./dirdat/na
TRANLOGOPTIONS EXCLUDEUSER OGG
TRANLOGOPTIONS ALTARCHIVEDLOGFORMAT %t_%s_%r.dbf
FETCHOPTIONS NOUSESNAPSHOT
TRANLOGOPTIONS CONVERTUCS2CLOBS
TRANLOGOPTIONS altarchivelogdest primary instance test /oradata/arch
–TRANLOGOPTIONS RAWDEVICEOFFSET 0
DYNAMICRESOLUTION
DDL INCLUDE ALL
DDLOPTIONS addtrandata, NOCROSSRENAME, REPORT
table QQQ.*;
table CUI.*;
2.11 传输进程DPEN参数配置
EXTRACT dpen
RMTHOST 192.168.4.171 , MGRPORT 7839, compress
PASSTHRU
numfiles 50000
RMTTRAIL ./dirdat/na
TABLE QQQ.*;
TABLE CUI.*;
2.12建立OGG的DDL对象
$ cd /u01/gg
$ sqlplus “/ as sysdba”
SQL> @marker_setup.sql
Enter GoldenGate schema name:ogg
alter system set recyclebin=off;
SQL> @ddl_setup.sql
Enter GoldenGate schema name: ogg
SQL> @role_setup.sql
Grant this role to each user assigned to the Extract, Replicat, GGSCI, and Manager processes, by using the following SQL command:
SQL>GRANT GGS_GGSUSER_ROLE TO
where is the user assigned to the GoldenGate processes.
注意这里的提示:需要手工将这个GGS_GGSUSER_ROLE指定给extract所使用的数据库用户(即参数文件里面通过userid指定的用户),可以到sqlplus下执行类似的sql:
SQL>GRANT GGS_GGSUSER_ROLE TO ogg;
注:这里的ogg是extract使用的用户。如果你有多个extract,使用不同的数据库用户,则需要重述以上过程全部赋予GGS_GGSUSER_ROLE权限。
运行以下脚本,使触发器生效:
SQL> @ ddl_enable.sql
注:在生产端开启抽取前,先禁用DDL捕获触发器,调用ddl_disable.sql。
2.13 数据初始化
在初始化过程中,源数据库不需要停机,初始化过程分为三个部分:
生产端开启抽取进程;
生产端导出数据;
容灾端导入数据;
在生产端添加抽取进程、传输进程以及相应的队列文件,执行命令如下:
//创建进程 EXTN
GGSCI>add extract extn,tranlog,begin now
GGSCI>add exttrail ./dirdat/na,extract extn,megabytes 500
//创建进程 DPEN
GGSCI>add extract dpen,exttrailsource ./dirdat/na
GGSCI>add rmttrail ./dirdat/na,extract dpen,megabytes 500
在生产端启动管理进程:
GGSCI> start mgr
启用DDL 捕获trigger:
$ cd /u01/gg
$ sqlplus “/as sysdba”
SQL> @ddl_enable.sql
在生产端启动抽取进程:
GGSCI> start EXTN
在数据库中,获取当前的SCN号,并且记录这个SCN号:
SQL>select to_char(dbms_flashback.get_system_change_number) from dual;
603809
在数据库中,创建数据泵所需目录并赋予权限:
SQL>CREATE OR REPLACE DIRECTORY DATA_PUMP AS ‘/u01’;
SQL>grant read ,write on DIRECTORY DATA_PUMP to ogg;
在生产端利用数据泵导出数据:
expdp ogg/ogg schemas=‘QQQ’ directory=DATA_PUMP dumpfile=QQQ_bak_%U flashback_scn=123456789 logfile=expdp_QQQ.log filesize=4096m
expdp ogg/ogg schemas=‘CUI’ directory=DATA_PUMP dumpfile=CUI_bak_%U flashback_scn=123456789 logfile=expdp_ CUI.log filesize=4096m
expdp ogg/ogg schemas=‘test1’ directory=DATA_PUMP dumpfile=test1_bak_%U flashback_scn=603809 logfile=expdp_QQQ.log filesize=4096m
把导出的文件传输到容灾端,利用数据泵将数据导入:
Impdp ogg/ogg DIRECTORY=DATA_PUMP DUMPFILE=QQQ_bak_%U logfile=impdp_ QQQ.log
Impdp ogg/ogg DIRECTORY=DATA_PUMP DUMPFILE=CUI_bak_%U logfile=impdp_CUI.log
2.14 容灾端管理进程MGR参数配置
PORT 7839
DYNAMICPORTLIST 7840-7860
–AUTOSTART ER *
–AUTORESTART EXTRACT *,RETRIES 5,WAITMINUTES 3
PURGEOLDEXTRACTS ./dirdat/*,usecheckpoints, minkeepdays 2
userid ogg, password AACAAAAAAAAAAADAHBLDCCIIOIRFNEPB, ENCRYPTKEY default
2.15编辑GLOBALS参数文件
切换到GoldenGate安装目录下,执行命令:
cd /u01/gg
./ggsci
ggsci>EDIT PARAMS ./GLOBALS
在文件中添加以下内容:
GGSCHEMA ogg --指定的进行DDL复制的数据库用户
2.16 容灾端复制进程REPN参数配置
REPLICAT repn
setenv (NLS_LANG=AMERICAN_AMERICA.WE8MSWIN1252)
userid ogg, password AACAAAAAAAAAAADAHBLDCCIIOIRFNEPB, ENCRYPTKEY default
SQLEXEC “ALTER SESSION SET CONSTRAINTS=DEFERRED”
REPORT AT 01:59
REPORTCOUNT EVERY 30 MINUTES, RATE
REPERROR DEFAULT, ABEND
assumetargetdefs
DISCARDFILE ./dirrpt/repna.dsc, APPEND, MEGABYTES 1024
DISCARDROLLOVER AT 02:30
ALLOWNOOPUPDATES
REPERROR (1403, discard)
DDL INCLUDE MAPPED
DDLOPTIONS REPORT
MAPEXCLUDE QQQ.T0417
MAP QQQ., TARGET QQQ.;
MAP CUI., TARGET CUI.;
2.17创建复制进程repn
执行以下命令创建复制进程repn:
- 1
GGSCI>add replicat repn, exttrail ./dirdat/na, nodbcheckpoint
2.18启动生产端传输进程和容灾端复制进程
GGSCI>start dpen
GGSCI>start REPLICAT repn aftercsn 123456789
2.19测试场景
(1)在生产端数据库上,创建一张表。
(2)在生产端数据库上,修改这个张表的数据。
(3)在生产端数据库上,删除这张表。
三.GoldenGate基本运维命令
(1)查看进程状态
GGSCI>info all
——查看GG整体运行情况,比如进程Lag延时,检查点延时。
GGSCI>info <进程名>
——查看某个进程的运行状况,比如抽取进程正在读取哪个归档日志或者联机重做日志,传输进程正在传送哪一个队列文件,复制进程正在使用哪一个队列文件。
GGSCI>info <进程名> showch
——查看某个进程运行的详细信息。
(2)查看进程报告
GGSCI>view report <进程名>
——报错时,从进程报告里获取错误信息。
(3)在操作系统上,查看GoldenGate安装目录的使用率
$ df -h
——查看ogg目录是否撑满。
四.Logdump工具使用
五.Goldengate初级的性能优化
Batchsql
Insert abend
限制内存使用
颗粒度拆分
六、goldengate版本升级
七、goldengate双向复制
八、生产库与容灾库之间的回切
八、异构数据库之间的数据转换,数据过滤筛选
四、常见故障排除
故障(1)
错误信息:
OGG-00446 Could not find archived log for sequence 53586 thread 1 under alternative destinations. SQL . Last alternative log tried /arch_cx/1_53586_776148274.arc., error retri eving redo file name for sequence 53586, archived = 1, use_alternate = 0Not able to establish initial position for sequence 53586, rba 44286992. 处理办法: 将缺失的归档日志从备份中恢复出来。如果依旧找不到所需归档日志,那么只能重新实施数据初始化。 故障(2) 错误信息: OGG-01154 Oracle GoldenGate Delivery for Oracle, repn.prm: SQL error 1691 mapping DATA_USER.DMH_WJXXB to DATA_USER.DMH_WJXXB OCI Error ORA-01691: unable to extend lob segment DATA_USER.SYS_LOB0000083691C00014$$ by 16384 in tablespace DATA_USER_LOB_U128M_1 (status = 1691), SQL . 处理办法: 数据库中该表空间已满,需要对该表空间进行扩容。 故障(3) 错误信息: OGG-00664 OCI Error during OCIServerAttach (status = 12541-ORA-12541: TNS:no listener). 处理方法: 启动数据库的监听器。 故障(4) 错误信息: OGG-00665 OCI Error describe for query (status = 3135-ORA-03135: connection lost contact Process ID: 8859 Session ID: 131 Serial number: 31), SQL.
处理方法:
在没有关闭OGG进程的情况下,提前关闭了数据库,导致OGG进程出现异常。如果是发现了这个错误提示,应该马上关闭OGG进程,注意数据库的归档日志情况,保证归档日志不会缺失,然后等待数据库启动成功后,马上启动OGG进程。
故障(5)
错误信息:
OGG-01161 Bad column index (4) specified for table QQQ.TIANSHI, max columns = 4.
处理方法:
对照一下生产端与容灾端的这一张表的表结构,如果容灾端的表缺少一列,则在容灾端,登陆数据库,增加这一列,然后启动复制进程。
故障(6)
错误信息:
ERROR OGG-00199 Table QQQ.T0417 does not exist in target database.
处理方法:
查看源端抽取进程的参数,DDL复制参数是否配置,针对这张表,重新实施数据初始化。
GOLDENGATE运维手册
OGG常用监控命令
说明
对GoldenGate实例进行监控,最简单的办法是通过GGSCI命令行的方式进行。通过在命令行输入一系列命令,并查看返回信息,来判断GoldenGate运行情况是否正常。命令行返回的信息包括整体概况、进程运行状态、检查点信息、参数文件配置、延时等。
除了直接通过主机登录GGSCI界面之外,也可以通过GoldenGate Director Web界面登录到每个GoldenGate实例,并运行GGSCI命令。假如客户部署了很多GoldenGate实例,如果单独登录到每个实例的GGSCI界面,会很不方便,此时建议通过GoldenGate Director Web界面,登录到每个实例,并运行命令行命令。
启动GoldenGate进程
-
首先以启动GoldenGate进程的系统用户(一般为oracle)登录源系统。
-
进入GoldenGate安装目录,执行./ggsci进入命令行模式。
-
启动源端管理进程GGSCI > start mgr
-
同样登陆到目标端GoldenGate安装目录,执行./ggsci,然后执行GGSCI > start mgr启动管理进程。
-
在源端执行GGSCI > start er *启动所有进程
-
同样登录到备份端执行GGSCI > start er *启动所有进程
-
使用GGSCI > info er * 或者 GGSCI > info <进程名>察看进程状态是否为Running(表示已经启动)。注意有的进程需要几分钟起来,请重复命令观察其启动状态。
说明:无论源还是目标,启动各extract/replicat进程前需要启动mgr进程。
start 命令的一般用法是:start <进程名称>
如:
GGSCI> start extdm 启动一个名叫extdm的进程
也可以使用通配符,如:
GGSCI> start er * 启动所有的extract和replicat进程
GGSCI> start extract d 启动所有的包含字符‘d’extract进程
GGSCI> start replicat rep* 启动所有以“rep“开头的replicat进程
停止GoldenGate进程
依照以下步骤停止GoldenGate进程:
-
以启动GoldenGate进程的系统用户(一般为oracle)登录源主机,进入GoldenGate安装目录执行./ggsci进入命令行管理界面
-
(本步骤仅针对抽取日志的主extract进程, data pump进程和replicat进程不需要本步骤)验证GoldenGate的抽取进程重起所需的日志存在,对各个主extXX进程,执行如下命令:
ggsci> info extXX, showch
……
Read Checkpoint #1
….
Recovery Checkpoint (position of oldest unprocessed transaction in the data source):
Thread #: 1
Sequence #: 9671
RBA: 239077904
Timestamp: 2008-05-20 11:39:07.000000
SCN: 2195.1048654191
Redo File: Not available
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Current Checkpoint (position of last record read in the data source):
Thread #: 1
Sequence #: 9671
RBA: 239377476
Timestamp: 2008-05-20 11:39:10.000000
SCN: 2195.1048654339
Redo File: Not Available
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Read Checkpoint #2
……
Recovery Checkpoint (position of oldest unprocessed transaction in the data source):
Thread #: 2
Sequence #: 5287
RBA: 131154160
Timestamp: 2008-05-20 11:37:42.000000
SCN: 2195.1048640151
Redo File: /dev/rredo07
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Current Checkpoint (position of last record read in the data source):
Thread #: 2
Sequence #: 5287
RBA: 138594492
Timestamp: 2008-05-20 11:39:14.000000
SCN: 2195.1048654739
Redo File: /dev/rredo07
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
……
首先察看Recovery Checkpoint所需要读取的最古老日志序列号,如举例中的实例1需要日志9671及其以后所有归档日志,实例2需要序列号为5287及以后所有归档日志,确认这些归档日志存在于归档日志目录后才可以执行下一步重起。如果这些日志已经被删除,则下次重新启动需要先恢复归档日志。
注意:对于OGG 11及以后版本新增了自动缓存长交易的功能,缺省每隔4小时自动对未提交交易缓存到本地硬盘,这样只需要最多8个小时归档日志即可。但是缓存长交易操作只在extract运行时有效,停止后不会再缓存,此时所需归档日志最少为8个小时加上停机时间,一般为了保险起见建议确保重启时要保留有12个小时加上停机时间的归档日志。
-
执行GGSCI >stop er *停止所有源进程,或者分别对各个进程执行stop <进程名>单独停止。
-
以oracle用户登录目标系统,进入安装目录/oraclelog1/goldengate,执行./ggsci进入命令行。
-
在目标系统执行stop er *停止复制
-
在两端进程都已停止的情况下,如需要可通过stop mgr停止各系统内的管理进程。
类似的,stop命令具有跟start命令一样的用法。这里不再赘述。
注意,如果是只修改抽取或者复制进程参数,则不需要停止MGR。不要轻易停止MGR进程,并且慎重使用通配符er *, 以免对其他复制进程造成不利影响。
查看整体运行情况
进入到GoldenGate安装目录,运行GGSCI,然后使用info all命令查看整体运行情况。如下图示:
wpsBA38.tmp
Group表示进程的名称(MGR进程不显示名字);Lag表示进程的延时;Status表示进程的状态。有四种状态:
STARTING: 表示正在启动过程中
RUNNING:表示进程正常运行
STOPPED:表示进程被正常关闭
ABENDED:表示进程非正常关闭,需要进一步调查原因
正常情况下,所有进程的状态应该为RUNNING,且Lag应该在一个合理的范围内。
查看参数设置
使用view params <进程名> 可以查看进程的参数设置。该命令同样支持通配符*。
wpsBA39.tmp
查看进程状态
使用info <进程名称> 命令可以查看进程信息。可以查看到的信息包括进程状态、checkpoint信息、延时等。如:
wpsBA3A.tmp
还可以使用info <进程名称> detail 命令查看更详细的信息。包括所使用的trail文件,参数文件、报告文件、警告日志的位置等。如:
wpsBA4B.tmp
使用info <进程名称> showch 命令可以查看到详细的关于checkpoint的信息,用于查看GoldenGate进程处理过的事务记录。其中比较重要的是extract进程的recovery checkpoint,它表示源数据中最早的未被处理的事务;通过recovery checkpoint可以查看到该事务的redo log位于哪个日志文件以及该日志文件的序列号。所有序列号比它大的日志文件,均需要保留。
wpsBA4C.tmp
查看延时
GGSCI> lag <进程名称> 可以查看详细的延时信息。如:
wpsBA4D.tmp
此命令比用info命令查看到的延时信息更加精确。
注意,此命令只能够查看到最后一条处理过的记录的延时信息。
此命令支持通配符 *。
查看统计信息
GGSCI> stats <进程名称>,<时间频度>,table . 可以查看进程处理的记录数。该报告会详细的列出处理的类型和记录数。如:
wpsBA4E.tmp
GGSCI> stats edr, total列出自进程启动以来处理的所有记录数。
GGSCI> stats edr, daily, table gg.test列出当天以来处理的有关gg.test表的所有记录数。
查看运行报告
GGSCI> view report <进程名称> 可以查看运行报告。如:
wpsBA4F.tmp
也可以进入到/dirrpt/目录下,查看对应的报告文件。最新的报告总是以<进程名称>.rpt命名的。加后缀数字的报告是历史报告,数字越大对应的时间越久。如下图示:
wpsBA60.tmp
如果进程运行时有错误,则报告文件中会包括错误代码和详细的错误诊断信息。通过查找错误代码,可以帮助定位错误原因,解决问题。
OGG的常见运维任务指南
配置自动删除队列
-
进入安装目录执行./ggsci;
-
执行edit param mgr编辑管理进程参数,加入或修改以下行
purgeoldextracts //dirdat/*, usecheckpoint, minkeepdays 7
其中,第一个参数为队列位置,*可匹配备份中心所有队列文件;
第二个参数表示是首先要保证满足检查点需要,不能删除未处理队列;
第三个参数表示最小保留多少天,后面的数字为天数。例如,如果希望只保留队列/ggs/dirdat/xm文件3天,可以配置如下:
purgeoldextracts /ggs/dirdat/xm, usecheckpoint, minkeepdays 3
- 停止MGR进程,修改好参数后重启该进程
GGSCI > stop mgr
输入y确认停止
GGSCI > start mgr
注:临时停止mgr进程并不影响数据复制。
配置启动MGR时自动启动Extract和Replicat进程
-
进入安装目录执行./ggsci;
-
执行edit param mgr编辑管理进程参数,加入以下行
AUTOSTART ER *
- 停止MGR进程,修改好参数后重启该进程
GGSCI > stop mgr
GGSCI > start mgr
注意:一般建议不用自动启动,而是手工启动,便于观察状态验证启动是否成功,同时也便于手工修改参数。
配置MGR自动重新启动Extract和Replicat进程
GoldenGate具有自动重起extract或者replicat进程的功能,能够自动恢复如网络中断、数据库临时挂起等引起的错误,在系统恢复后自动重起相关进程,无需人工介入。
-
进入安装目录执行ggsci进入命令行界面;
-
执行edit param mgr编辑管理进程参数,加入以下行
AUTORESTART ER *, RETRIES 3, WAITMINUTES 5, RESETMINUTES 60
以上参数表示每5分钟尝试重新启动所有进程,共尝试三次。以后每60分钟清零,再按照每5分钟尝试一次共试3次。
- 停止MGR进程,修改好参数后重启该进程,使修改后的参数文件生效
GGSCI > stop mgr
GGSCI > start mgr
长事务管理
在停止抽取进程前需要通过命令检查是否存在长交易,以防止下次启动无法找到归档日志:
ggsci> info extXX, showch
……
Read Checkpoint #1
….
Recovery Checkpoint (position of oldest unprocessed transaction in the data source):
Thread #: 1
Sequence #: 9671
RBA: 239077904
Timestamp: 2008-05-20 11:39:07.000000
SCN: 2195.1048654191
Redo File: Not available
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Current Checkpoint (position of last record read in the data source):
Thread #: 1
Sequence #: 9671
RBA: 239377476
Timestamp: 2008-05-20 11:39:10.000000
SCN: 2195.1048654339
Redo File: Not Available
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Read Checkpoint #2
……
Recovery Checkpoint (position of oldest unprocessed transaction in the data source):
Thread #: 2
Sequence #: 5287
RBA: 131154160
Timestamp: 2008-05-20 11:37:42.000000
SCN: 2195.1048640151
Redo File: /dev/rredo07
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Current Checkpoint (position of last record read in the data source):
Thread #: 2
Sequence #: 5287
RBA: 138594492
Timestamp: 2008-05-20 11:39:14.000000
SCN: 2195.1048654739
Redo File: /dev/rredo07
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
……
为了方便长交易的管理,GoldenGate提供了一些命令来查看这些长交易,可以帮助客户和应用开发商查找到对应长交易,并在GoldenGate中予以提交或者回滚。
(一) 查看长交易的方法
Ggsci> send extract <进程名> , showtrans [thread n] [count n]
其中,<进程名>为所要察看的进程名,如extsz/extxm/extjx等;
Thread n是可选的,表示只查看其中一个节点上的未提交交易;
Count n也是可选的,表示只显示n条记录。例如,查看extsz进程中节点1上最长的10个交易,可以通过下列命令:
Ggsci> send extract extsz , showtrans thread 1 count 10
输出结果是以时间降序排列的所有未提交交易列表,通过xid可以查找到对应的事务,请应用开发商和DBA帮助可以查找出未提交原因,通过数据库予以提交或者回滚后GoldenGate的checkpoint会自动向前滚动。
(二) 使用GoldenGate命令跳过或接受长交易的方法
在GoldenGate中强制提交或者回滚指定事务,可以通过以下命令(<>中的为参数):
Ggsci> SEND EXTRACT <进程名>, SKIPTRANS <5.17.27634> THREAD <2> //跳过交易
Ggsci>SEND EXTRACT <进程名>, FORCETRANS <5.17.27634> THREAD <1> //强制认为该交易已经提交
说明:使用这些命令只会让GoldenGate进程跳过或者认为该交易已经提交,但并不改变数据库中的交易,他们依旧存在于数据库中。因此,强烈建议使用数据库中提交或者回滚交易而不是使用GoldenGate处理。
(三) 配置长交易告警
可以在extract进程中配置长交易告警,参数如下所示:
extract extsz
……
warnlongtrans 12h, checkintervals 10m
exttrail /backup/goldengate/dirdat/sz
….
以上表示GoldenGate会每隔10分钟检查一下长交易,如果有超过12个小时的长交易,GoldenGate会在根目录下的ggserr.log里面加入一条告警信息。可以通过察看ggserr.log或者在ggsci中执行view ggsevt命令查看这些告警信息。以上配置可以有助于及时发现长交易并予以处理。
说明:在OGG 11g中,extract提供了BR参数可以设置每隔一段时间(默认4小时)将长交易缓存到本地硬盘(默认dirtmp目录下),因此extract只要不停止一般需要的归档日志不超过8个小时(极限情况)。但是如果extract停掉后,便无法再自动缓存长交易,需要的归档日志就会依赖于停机时间变长。
表的重新再同步(需时间窗口)
如果是某些表由于各种原因造成两边数据不一致,需要重新进行同步,可以参照以下步骤。
-
确认需要修改的表无数据变化(如果有条件建议停止应用系统并锁定除去sys和goldengate以外的其它所有用户防止升级期间数据变化,或者锁定所要再同步的表);
-
重启dpe进程(为了能够对统计信息清零);
-
停止目标端的rep进程;
注意:步骤4-6为将源端数据通过exp/imp导入到目标端,客户也可以选择其它初始化方式,比如在目标端为源端表建立dblink,然后通过create table as select from的方式初始化目标端表。
- 在源端使用exp导出该表或者几张表数据。例如:
exp goldengate/XXXX file=nanhai.dmp tables=ctais2.SB_ZSXX grants=y
-
通过ftp传输到目标端;
-
在目标端,使用imp导入数据;
nohup imp goldengate/XXXXX file=nanhai.dmp fromuser=ctais2 touser=ctais2 ignore=y &
-
如果这些表有外键,在目标端检查这些外键并禁止它们(记得维护dirsql下的禁止和启用外键的脚本SQL);
-
启动目标端的rep进程;
-
使用stats mydpe命令观察data pump的统计信息,观察里面是否包含了本次重新同步表的数据变化,如确认该时段内这些表无数据变化,则重新初始化成功;否则中间可能产生重复数据,目标replicat会报错,将错误处理机制设置为reperror default,discard,等待replicat跟上后对discard中的记录进行再次验证,如果全部一致则重新初始化也算成功完成,当然也可以另择时段对这些表重新执行初始化。
表的重新再同步(无需时间窗口)
如果是某些表由于各种原因造成两边数据不一致,需要重新进行同步,但实际业务始终24小时可用,不能提供时间窗口,则可以参照以下步骤。(因较为复杂,使用需谨慎!)
-
确认ext/dpe/rep进程均无较大延迟,否则等待追平再执行操作;
-
停止目标端的rep进程;
注意:步骤3-5为将源端数据通过exp/imp导入到目标端,客户也可以选择其它初始化方式,比如expdp/impdp。
- 在源端获得当前的scn号。例如:
select dbms_flashback.get_system_change_number from dual;
以下以获得的scn号为1176681为例
- 在源端使用exp导出所需重新初始化的表或者几张表数据,并且指定到刚才记下的scn号。例如:
exp / tables=ctais2.SB_ZSXX grants=n statistics=none triggers=n compress=n FLASHBACK_SCN=1176681
-
通过ftp传输到目标端;
-
在目标端,使用imp导入数据;
nohup imp goldengate/XXXXX file=nanhai.dmp fromuser=ctais2 touser=ctais2 ignore=y &
-
如果这些表有外键,在目标端检查这些外键并禁止它们(记得维护dirsql下的禁止和启用外键的脚本SQL);
-
编辑目标端对应的rep参数文件,在其map里面加入一个过滤条件,只对这些重新初始化的表应用指定scn号之后的记录(一定要注意不要修改本次初始化之外的其它表,会造成数据丢失!):
map source.mytab, target target.mytab, filter ( @GETENV (“TRANSACTION”, “CSN”) > 1176681 ) ;
-
确认参数无误后,启动目标端的rep进程;
-
使用info repxx或者lag repxx直到该进程追上,停止该进程去掉filter即可进入正常复制。
数据结构变更和应用升级
(仅复制DML时)源端和目标端数据库增减复制表
(一) 增加复制表
在GoldenGate的进程参数中,如果通过来匹配所有表,因此只要符合所匹配的条件,那么只要在源端建立了表之后GoldenGate就能自动复制,无需修改配置文件,但是需要为新增的表添加附加日志。
步骤如下:
GGSCI 〉dblogin userid goldengate, password XXXXXXX
GGSCI > info trandata .
如果不是enable则需要手动加入:
GGSCI > add trandata .
注:(仅对Oracle 9i)如果该表有主键或者该表不超过32列,则显示enabled表示添加成功;如果无主键并且列超过32列,则可能出现错误显示无法添加则需要手工处理,此时请根据附录二中方法手工处理。
如果没有使用统配符,则需要在主Extract、Data Pump里面最后的table列表里加入新的复制表;在目标端replicat的map列表同样也加入该表的映射。
然后,新增表请首先在目标端建立表结构。
如果有外键和trigger,需要在目标表临时禁止该外键和trigger,并维护在dirsql下的禁止和启用这些对象的对应脚本文件。
对于修改了文件的所有源和目标进程,均需重启进程使新的参数生效。
(二) 减少复制表
GoldenGate缺省复制所有符合通配符条件的表,如果有的表不再需要,可以在源端drop掉,然后到目标drop掉,无需对复制做任何修改。
如果其中几个表依然存在,只是无需GoldenGate复制,则可以通过以下步骤排除:
-
在源端系统上首先验证所需归档日志存在后通过stop extXX停止对应的extXX进程;
-
在目标端系统上ggsci中执行stop repXX停止目标端的复制进程;
-
在源端修改ext进程的参数文件排除所不复制的表:
Ggsci> edit param extXX
……
tableexclude ctais2.TMP_*;
tableexclude ctais2.BAK_*;
tableexclude ctais2.MLOG$_*;
tableexclude ctais2.RUPD$_*;
tableexclude ctais2.KJ_*;
tableexclude myschema.mytable;
table ctais2.*;
…….
在文件定义table的行前面加入一行“tableexclude .;” 注意写全schema和表的名称。
注:如果是没有使用通配符,则直接注释掉该表所在的table行即可。
- 在目标端修改rep进程参数,同样排除该表:
GGSCI>edit param repXX
在map前面加入一行:
–mapexclude CTAIS2.SHOULIXINXI
mapexclude myschema.mytable
MAP ctais2.* ,TARGET ctais2.*;
注:如果是没有使用通配符,则直接注释掉该表所在的map行即可。
- 在目标端系统上启动复制进程 repXX
GGSCI > start repXX
- 在源端系统上启动源端的抓取进程extXX
GGSCI > start extXX
即可进入正常复制状态。
(仅复制DML时)修改表结构
当数据库需要复制的表结构有所改变,如增加列,改变某些列的属性如长度等表结构改变后,可以按照下列步骤执行:
-
按照本文前面所述操作顺序停止源和目标端各抽取及投递进程(注意停源端抽取要验证一下归档日志是否存在防止无法重起),无需停止manager进程;
-
修改目标表结构;
-
修改源表结构;
-
如果表有主键,并且本次修改未修改主键,则可以直接启动源和目标所有进程继续复制,完成本次修改;否则,如果表无主键或者本次修改了主键则需继续执行下列步骤;
ggsci> dblogin userid goldengate, password XXXXXX
ggsci> delete trandata schema.mytable
ggsci> add trandata schema.mytable
(仅对Oracle 9i)如果表超过了32列则上述操作可能会报错,此时需要手工进行处理,请参考附录二如何手动为表删除和增加附加日志。
- 重新启动源端和目标端的抓取和复制进程。
(仅复制DML时)客户应用的升级
如果是客户的应用进行了升级,导致了源系统表的变化,在不配置DDL复制到情况下,需要对GoldenGate同步进程进行修改,可以参照以下步骤。
-
停止源和目标端各抽取及投递进程(注意停源端抽取要验证一下归档日志是否存在防止无法重起),无需停止manager进程;
-
对源系统进行升级;
-
在目标端将客户升级应用所创立的存储过程、表、function等操作再重新构建一遍。对业务表的增删改等DML操作不必在目标端再执行,它们会被OGG复制过去;
-
在目标端手工禁止建立的trigger和外键,并将这些sql以及反向维护的(即重新启用trigger和外键)SQL添加到目标端OGG dirsql目录下对应的脚本文件里;
注意:在安装实施时,应当将执行的禁止trigger和外键的表放到目标dirsql下,文件名建议为disableTrigger.sql和disableFK.sql。同时,需要准备一个反向维护(即重新启用trigger和外键,建议为enableTrigger.sql和enableFK.sql)SQL,同样放置到目标端OGG的dirsql目录下,以备将来接管应用时重新启用。
- 对于升级过程中在源端增加的表,需要为新增的表添加附加日志。步骤如下:
GGSCI 〉dblogin userid goldengate, password XXXXXXX
GGSCI > info trandata .
如果不是enable则需要手动加入:
GGSCI > add trandata .
注:(仅对Oracle 9i)如果该表有主键或者该表不超过32列,则显示enabled表示添加成功;如果无主键并且列超过32列,则可能出现错误显示无法添加则需要手工处理,此时请根据附录二中方法手工处理。
-
对于升级过程中在源端drop掉的表,GoldenGate缺省复制所有符合通配符条件的表,可以直接在目标端drop掉,无需对复制做任何修改;
-
如果升级过程中修改了主键的表则需继续执行下列步骤;
ggsci> dblogin userid goldengate, password XXXXXX
ggsci> delete trandata schema.mytable
ggsci> add trandata schema.mytable
(仅对Oracle 9i)如果表超过了32列则上述操作可能会报错,此时需要手工进行处理,请参考附录二如何手动为表删除和增加附加日志。
- 重新启动源端和目标端的抓取和复制进程。
配置DDL复制自动同步数据结构变更
是否打开DDL复制
对于OGG的DDL复制具体限制请参考附录。鉴于这些限制,另外一个重要因素是DDL的trigger会对源库性能带来一定的影响,在国网原则上并不推荐DDL复制。如果有特殊理由需要打开DDL复制,可以与Oracle工程师予以协商。
打开DDL复制的步骤
以下内容为配置DDL复制的步骤,仅作参考,具体请参照GoldenGate的官方安装文档。
? (可选,但强烈建议)定期收集统计信息,提高数据字典访问速度
OGG的DDL复制需要大量访问数据字典信息,通过数据库定期收集统计信息(例如,每月一次),可以有效提高OGG DDL复制的性能。以下为一个例子:
sqlplus /nolog <<eof</eof<>
connect / as sysdba
alter session enable parallel dml;
execute dbms_stats.gather_schema_stats(‘CTAIS2’,cascade=> TRUE);
execute dbms_stats.gather_schema_stats(‘SYS’,cascade=> TRUE);
execute dbms_stats.gather_schema_stats(‘SYSTEM’,cascade=> TRUE);
exit
EOF
? 建立OGG复制用户,或给现有用户赋权限:
CREATE USER goldengate IDENTIFIED BY goldengate DEFAULT TABLESPACE ts_ogg;
GRANT CONNECT TO goldengate;
GRANT RESOURCE TO goldengate;
grant dba to goldengate;
? 指定DDL对象所在的schema,这里直接建立在goldengate用户下:
Ggsci>EDIT PARAMS ./GLOBALS
GGSCHEMA goldengate
? 检查数据库的recyclebin参数是否已关闭:
SQL> show parameter recyclebin
NAME TYPE
VALUE
recyclebin string
on
如不是off,需要关闭recyclebin:
alter system set recyclebin=off
? 建立OGG的DDL对象:
sqlplus “/ as sysdba”
SQL> @marker_setup.sql
Enter GoldenGate schema name:goldengate
SQL> @ddl_setup.sql
Enter GoldenGate schema name:goldengate
SQL> @role_setup.sql
Grant this role to each user assigned to the Extract, Replicat, GGSCI, and Manager processes, by using the following SQL command:
GRANT GGS_GGSUSER_ROLE TO
where is the user assigned to the GoldenGate processes.
注意这里的提示:它需要你手工将这个GGS_GGSUSER_ROLE指定给你的extract所使用的数据库用户(即参数文件里面通过userid指定的用户),可以到sqlplus下执行类似的sql:
GRANT GGS_GGSUSER_ROLE TO ggs1;
这里的ggs1是extract使用的用户。如果你有多个extract,使用不同的数据库用户,则需要重述以上过程全部赋予GGS_GGSUSER_ROLE权限。
? 启动OGG DDL捕捉的trigger
在sqlplus里面执行ddl_enable.sql脚本启用ddl捕捉的trigger。
说明:ddl捕捉的trigger与OGG的extract进程是相互独立的,它并不依赖于extract进程存在。即使OGG的extract进程不存在或者没有启动,但是trigger已经启用了,那么捕捉ddl的动作就一直延续下去。如想彻底停止捕捉DDL捕捉,需要执行下步禁用ddl的trigger。
? (可选)安装提高OGG DDL复制性能的工具
为了提供OGG的DDL复制的性能,可以将ddl_pin脚本加入到数据库启动的脚本后面,该脚本需要带一个OGG的DDL用户(即安装DDL对象的用户,本例中是goldengate)的参数:
SQL> @ddl_pin
? (如果不再需要DDL复制时)停止OGG DDL捕捉的trigger
在sqlplus里面执行ddl_disable.sql脚本启用ddl捕捉的trigger。
DDL复制的典型配置
GoldenGate的data pump进程和replicat的ddl开关默认是打开的,只有主extract是默认关闭的,所以DDL的配置一般只在主extract进行。 结合附录所述的OGG的各种限制,如果需要打开DDL复制,则建议只打开跟数据有密切关系的表和index的DDL复制,参数如下:
DDL &
INCLUDE MAPPED OBJTYPE ‘table’ &
INCLUDE MAPPED OBJTYPE ‘index’
DDLOPTIONS ADDTRANDATA, NOCROSSRENAME
另外,在mgr里面加入自动purge ddl中间表的参数:
userid goldengate,password XXXXX
PURGEDDLHISTORY MINKEEPDAYS 3, MAXKEEPDAYS 7
PURGEMARKERHISTORY MINKEEPDAYS 3, MAXKEEPDAYS 7
对于其它对象,依然建议使用手工维护的方式在两端同时升级。要注意的是级联删除和trigger,在目标端建立后应当立即禁用。
异常处理预案
网络故障
如果MGR进程参数文件里面设置了autorestart参数,GoldenGate可以自动重启,无需人工干预。
当网络发生故障时, GoldenGate负责产生远地队列的Datapump进程会自动停止. 此时, MGR进程会定期根据mgr.prm里面autorestart设置自动启动Datapump进程以试探网络是否恢复。在网络恢复后, 负责产生远程队列的Datapump进程会被重新启动,GoldenGate的检查点机制可以保证进程继续从上次中止复制的日志位置继续复制。
需要注意的是,因为源端的抽取进程(Capture)仍然在不断的抓取日志并写入本地队列文件,但是Datapump进程不能及时把本地队列搬动到远地,所以本地队列文件无法被自动清除而堆积下来。需要保证足够容量的存储空间来存储堆积的队列文件。计算公式如下:
存储容量≥单位时间产生的队列大小×网络故障恢复时间
MGR定期启动抓取和复制进程参数配置参考:
GGSCI > edit param mgr
port 7809
autorestart er *,waitminutes 3,retries 5,RESETMINUTES 60
每3分钟重试一次,5次重试失败以后等待60分钟,然后重新试三次。
RAC环境下单节点失败
在RAC环境下,GoldenGate软件安装在共享目录下。可以通过任一个节点连接到共享目录,启动GoldenGate运行界面。如果其中一个节点失败,导致GoldenGate进程中止,可直接切换到另外一个节点继续运行。建议在Oracle技术支持协助下进行以下操作:
-
以oracle用户登录源系统(通过另一完好节点);
-
确认将GoldenGate安装所在文件系统装载到另一节点相同目录;
-
确认GoldenGate安装目录属于oracle用户及其所在组;
-
确认oracle用户及其所在组对GoldenGate安装目录拥有读写权限;
-
进入goldengate安装目录;
-
执行./ggsci进入命令行界面;
-
执行start mgr启动mgr;
-
执行start er *启动所有进程;
检查各进程是否正常启动,即可进入正常复制。以上过程可以通过集成到CRS或HACMP等集群软件实现自动的切换,具体步骤请参照国网测试文档。
Extract进程常见异常
对于源数据库,抽取进程extxm如果变为abended,则可以通过在ggsci中使用view report命令察看报告,可以通过搜索ERROR快速定位错误。
一般情况下,抽取异常的原因是因为其无法找到对应的归档日志,可以通过到归档日志目录命令行下执行
ls –lt arch_X_XXXXX.arc
察看该日志是否存在,如不存在则可能的原因是:
§ 日志已经被压缩
GoldenGate无法自动解压缩,需要人工解压缩后才能读取。
§ 日志已经被删除
如果日志已经被删除,需要进行恢复才能继续复制,请联系本单位DBA执行恢复归档日志操作。
一般需要定期备份归档日志,并清除旧的归档日志。需要保证归档日志在归档目录中保留足够长时间之后,才能被备份和清除。即:定期备份清除若干小时之前的归档,而不是全部归档。保留时间计算如下:
某归档文件保留时间≥抽取进程处理完该文件中所有日志所需的时间
可以通过命令行或者GoldenGate Director Web界面,运行info exXX showch命令查看抓取进程exXX处理到哪条日志序列号。在此序列号之前的归档,都可以被安全的清除。如下图所示:
wpsBA61.tmp
Replicat进程常见异常
对于目标数据库,投递进程repXX如果变为abended,则可以通过在ggsci中使用view report命令察看报告,可以通过搜索ERROR快速定位错误。
复制进程的错误通常为目标数据库错误,比如:
-
数据库临时停机;
-
目标表空间存储空间不够;
-
目标表出现不一致。
可以根据报告查看错误原因,排除后重新启动rep进程即可。
需要注意一点:往往容易忽略UNDO表空间。如果DML语句中包含了大量的update和delete操作,则目标端undo的生成速度会很快,有可能填满UNDO表空间。因此需要经常检查UNDO表空间的大小。
异常处理一般步骤
如果GoldenGate复制出现异常,可以通过以下步骤尝试解决问题:
-
通过ggsci>view report命令查找ERROR字样,确定错误原因并根据其信息进行排除;
-
通过ggsci>view ggsevt查看告警日志信息;
-
检查两端数据库是否正常运行,网络是否连通;
-
如不能确定错误原因,则可以寻求Oracle技术支持。在寻求技术支持时一般需要提供以下信息:
a) 错误描述
b) 进程报告,位于dirrpt下以大写进程名字开头,以.rpt结尾,如进程名叫extsz,则报告名字叫EXTSZ.rpt;
c) GGS日志ggserr.log,位于GGS主目录下;
d) 丢失数据报告,在复制进程的参数disardfile中定义,一般结尾为.dsc;
e) 当前队列,位于dirdat下。
附录
Oracle GoldenGate V11.1数据复制限制
不支持文件等非结构化数据复制
GoldenGate依赖对于数据库日志的解析获取数据变化,因此只能支持数据库中的数据变化复制,无法支持文件等非结构化数据的复制。
Oracle数据类型限制
GoldenGate支持Oralce常见数据类型的复制。
l GoldenGate不支持的数据类型
a) ANYDATA
b) ANYDATASET
c) ANYTYPE
d) BFILE
e) BINARY_INTEGER
f) MLSLABEL
g) PLS_INTEGER
h) TIMEZONE_ABBR
i) TIMEZONE_REGION
j) URITYPE
k) UROWID
l GoldenGate有限制支持XML Type复制
? 仅限于Oracle 9i及以后版本
? 表必须有主键或者唯一索引
l GoldenGate有限制支持UDT用户自定义类型复制
? 如有该类型数据请联系技术支持人员并提供脚本。
Oracle DML操作支持
GoldenGate当前支持普通表的所有DML操作和有限制支持部分特殊对象的DML操作,对于特殊表或对象请参照后面特殊对象一节的说明。
l GoldenGate不支持nologging的表等对象
当表或表空间被设置为nologging后,使用sqlloader或者append等非常规模式插入数据将不会被写入到数据库日志,因此GoldenGate无法获取这些数据变化。建议将所有需要的业务表设置为logging状态,对于nologging的表不予以复制。
l GoldenGate暂不支持对象和操作如下
a) REF
b) 使用COMPRESS 选项建立的表空间和表
c) Database Replay
l GoldenGate支持Sequence序列的复制
l GoldenGate可以通过复制源表支持对于同义词或者DBLink的复制。
由于对于这些对象本身的操作发生于其所链接的源数据库对象,数据库日志中并不记录对这些链接目标对象的操作,因此GoldenGate不复制对同义词或者DBLink本身的操作,但这些操作会应用在源表上并产生日志,因此可以通过复制源表复制变化。
l GoldenGate有限制支持IOT索引组织表复制
? 仅限于Oracle 10.2及以后版本
? 能够支持使用MAPPING TABLE创建的IOT,但是只抽取基表的数据变化,而不是MAPPING TABLE。
? 不支持以compress模式存储的IOT。例如,不支持存储在一个使用compress选项的表空间里的IOT。
l GoldenGate有限制支持Clustered Table复制
? 仅限于Oracle 9i及以后版本
? 不支持Encrypted加密和compressed压缩的clustered tables
l GoldenGate有限制支持物化视图复制
? 不支持使用WITH ROWID选项创建的物化视图
? 源表必须有主键
? 不支持物化视图的Truncate但支持DELETE FROM
? 目标物化视图必须是可更新的
? 只在Oracle 10g或以后的版本支持物化视图的Full refresh
Oracle DDL复制限制
GoldenGateDDL复制的原理是通过Trigger从源数据库获取sql,到目标端进行重现,在实际使用中有较多限制,即源端能够执行的sql到了目标端未必能够执行成功。以下为常见的一些问题:
? 当SQL语句里面设计的对象在目标不存在时,DDL无法执行成功。例如,源建立了一个DBLINk或create table as select * from mydblink,此时目标端可能并没有这个dblink指向的库或对象,所以sql语句会报错;
? 当两端的物理位置不同时,建立data file或tablespace等与物理位置相关的语句需要在目标端替换为目标的物理位置;
? 当创建约束没有指定名称时,在源和目标会生成不同名称的对象,这样以后对这些对象再进行修改时就无法正确映射到目标端;
? 当复制带有LOB的表时,ddl操作必须等待DML操作全部完成以后再复制;
? 不能复制表明和列名带有中文的表;
? 表或其它对象的定义里面不能加入中文注释;
? 不能复制带有编译错误的CREATE trigger/procedure/function/package等对象;
? 不能复制结尾带有‘/’的sql语句.
此外,GoldenGate DDL复制需要关闭Oracle的_RECYCLEBIN参数(Oracle 10.1)或者RECYCLEBIN参数(Oracle 10.2及以后版本)。
还有一个比较重要的是:由于是Trigger based,GoldenGate的DDL复制可能会降低源数据库的性能,所以不推荐使用DDL复制,具体请参照国网OGG实施原则。
说明:更多详细信息请参照OGG的官方参考手册。
Oracle 9i中如何为超过32列的无主键表添加附加日志
为数据库表添加附加日志操作的本质是执行如下的SQL语句:
Alter table
add supplemental log group (column,…) always;
Oracle GoldenGate的add trandata 也是调用这个语句执行:
-
当表有主键时,会将所有作为主键的列放到columns子句里面添加到附加日志组里;
-
如果没有主键,则会找唯一索引,将唯一索引列放到columns子句里面添加到附加日志组里;
-
如果没有主键和唯一索引,则会将所有列添加到附加日志组中去。
在对于无主键和唯一索引表添加附加日志时,Oracle 9i有个限制: 即每个附加日志组不可以超过32个列(大致数字,与实际列定义长度有关).此时调用GoldenGate的add Trandata命令会失败,其处理方法是将该表的所有列拆分为若干组,每组不超过32各列,然后分别添加附加日志组(对不同组合设置不同附加日志组名)。以下为一个超过32列表添加附加日志例子:
ALTER TABLE SIEBEL.XYZ_SQL ADD SUPPLEMENTAL LOG GROUP GGS_XYZ_SQL_649101_1(ACTION ,ACTION_HASH ,ADDRESS ,BUFFER_GETS ,CHILD_ADDRESS ,CHILD_LATCH ,CHILD_NUMBER ,COMMAND_TYPE ,CPU_TIME ,DISK_READS ,ELAPSED_TIME ,EXECUTIONS ,FETCHES ,FIRST_LOAD_TIME ,HASH_VALUE ,INSTANCE_ID ,INVALIDATIONS ,IS_OBSOLETE ,KEPT_VERSIONS ,LAST_LOAD_TIME ,LITERAL_HASH_VALUE ,LOADED_VERSIONS ,LOADS ,MODULE ,MODULE_HASH ,OBJECT_STATUS ,OPEN_VERSIONS ,OPTIMIZER_COST ,OPTIMIZER_MODE ,OUTLINE_CATEGORY ,OUTLINE_SID ,PARSE_CALLS) always;
ALTER TABLE SIEBEL.XYZ_SQL ADD SUPPLEMENTAL LOG GROUP GGS_XYZ_SQL_649101_2(PARSING_SCHEMA_ID ,PARSING_USER_ID ,PERSISTENT_MEM ,PLAN_HASH_VALUE ,REMOTE ,ROWS_PROCESSED ,RUNTIME_MEM ,SERIALIZABLE_ABORTS ,SHARABLE_MEM ,SNAP_ID ,SORTS ,SQLTYPE ,SQL_TEXT ,TYPE_CHK_HEAP ,USERS_EXECUTING ,USERS_OPENING) always;
说明:通过手工方式加入附加日志后,不能在ggsci中使用info trandata查看到附加日志,此时可以通过下列语句查询是否有表没有加入到附加日志:
SQL> select * from dba_log_groups where owner=‘SIEBEL’ and table_name=’XXX’;
如想验证是否所需的列均在附加日志中,可以再查询dba_log_group_columns。
如需将附加日志组drop掉,可以采用如下格式:
Alter table
drop supplemental log group ;
ogg的字符集分析浅谈
我们所熟知oracle的字符集一旦创建完毕后最好不要修改,关于oracle goldengate的字符集问题还是需要注意的,因为如果目标端和源端字符集不一致,而有些字符无法在目标端表示ogg可能无法保证数据一致性。
源库字符集:
SQL> select value from v$nls_parameters where parameter=‘NLS_CHARACTERSET’;
VALUE
AL32UTF8
如果这里小鱼在源端设置SETENV(NLS_LANG=“AMERICAN_AMERICA.ZHS16GBK”)去指定源端客户端的字符集
GGSCI (dg01) 21> view params exiaoyu
extract exiaoyu
SETENV (NLS_LANG=“AMERICAN_AMERICA.ZHS16GBK”)
SETENV (ORACLE_SID=“xiaoyu”)
userid ogg,password ogg
dynamicresolution
gettruncates
report at 2:00
reportrollover at 3:00
warnlongtrans 3h,checkinterval 10m
exttrail ./dirdat/dd
table xiaoyu.;
table xiaoyugg.;
来看看对应的extract进程的报告,发现此时ogg发觉源端客户端的NLS_LANG变量和源端数据库字符集不一致,从而选择源端数据库字符集,并没有根据extract进程参数中的SETENV指定。
GGSCI (dg01) 52> view report exiaoyu
** Running with the following parameters **
2013-06-04 04:50:27 INFO OGG-03035 Operating system character set identified as UTF-8. Locale: en_US, LC_ALL:.
extract exiaoyu
SETENV (NLS_LANG=“AMERICAN_AMERICA.ZHS16GBK”)
Set environment variable (NLS_LANG=AMERICAN_AMERICA.ZHS16GBK)
SETENV (ORACLE_SID=“xiaoyu”)
Set environment variable (ORACLE_SID=xiaoyu)
userid ogg,password ***
2013-06-04 04:50:28 INFO OGG-03500 WARNING: NLS_LANG environment variable does not match database character set, or not set. Using database character set value of AL32UTF8.
[oracle@ogg 11.2]$ oggerr 3500
03500, 00000, “WARNING: NLS_LANG environment variable does not match database character set, or not set. Using database character set value of {0}”
// *{0}: nls_charset (String)
// *Cause: The NLS_LANG environment variable is not set to the same as the
// database character set. Oracle GoldenGate is using the database
// character set.
// *Action: None
看来源端设置NLS_LANG跟oracle database的字符集不一致时,ogg还是会选择oracle database的字符集,而忽略掉extract的进程参数SETEVN NLS_LANG
接下来测试目标端:
这里也指定SETENV(NLS_LANG=”AMERICAN_AMERICA.ZHS16GBK”)
GGSCI (ogg.single) 15> view params rxiaoyu
replicat rxiaoyu
SETENV (NLS_LANG=“AMERICAN_AMERICA.ZHS16GBK”)
SETENV (ORACLE_SID=“xiaoyu”)
userid ogg,password ogg
assumetargetdefs
gettruncates
report at 2:00
reportrollover at 3:00
discardfile ./dirrpt/discard_rxiaoyu.dsc,append,megabytes 100
map xiaoyu.xiaoyu10,target xiaoyu.xiaoyu10,filter(@getenv(“transaction”,“csn”)>1074454806);
map xiaoyu.,target xiaoyu.;
map xiaoyugg.,target ogg.;
观察目标端的replicat进程,发现ogg选择了进程参数中SETENV(NLS_LANG=“AMERICAN_AMERICA.ZHS16GBK”)
GGSCI (ogg.single) 17> view report rxiaoyu
。。。
2013-06-05 03:14:14 WARNING OGG-03504 NLS_LANG character set ZHS16GBK on the target is different from the source database character set AL32UTF8. Replication may not be valid if the source data has an incompatible character for the target NLS_LANG character set
此时ogg给出的提示需要在replicat进程中正确设置SETENV NLS_LANG变量,这里源端传递的是AL32UTF8字符集,目标端通过replicat进程参数SETENV NLS_LANG指定的是ZHS16GBK,而ogg也采用了replicat进程的参数,并没有选择源端的字符集。
[oracle@ogg 11.2]$ oggerr 3504
03504, 00000, “NLS_LANG character set {0} on the target is different from the source database character set {1}. Replication may not be valid if the source data has an incompatible character for the target NLS_LANG character set.”
// *{0}: nls_lang_charset (String)
// *{1}: src_db_charset (String)
// *Cause: The NLS_LANG environment variable on the target is set to a
// different character set than the character set of the source
// database.
// *Action: Set the NLS_LANG environment variable on the target to the
// character set of the source database that is shown in the message.
// You can use the SETENV parameter in the Replicat parameter file to
// set it for the Replicat session.
而ogg报出的3504警告是为了提醒目标端字符集和源端不一致,可能会引起replicat进程异常,这里ogg也推荐在replicat进程中设置NLS_LANG使目标端和源端一致。
那么对于字符集对ogg的影响就是源端和目标端,如果源端和目标端database字符集一直,这里在进程中直接采用一致的SETENV NLS_LANG都等于缺省的数据库字符集即可,而对于源端和目标端字符集不一致的,则需要在目标端手动指定replicat进程参数SETENV NLS_LANG等于源端字符集,当然对于最后在数据库中数据行小鱼认为还是需要再次转化成目标端oracle database的字符集。(ogg也是一个同步复制产品,其技术原理依然不能脱离oracle database)

