
- 1神经网络系列---回归问题和分类问题
- 2使用python中的SVM进行数据回归预测_python svm回归
- 32024 年软件工程将如何发展_2024年平台工程的技术发展
- 4Google Guava Hash(散列)
- 5java实现UDP传输系统源码(附完整源码)_java udp通信编程源码
- 6手把手实现vue响应式 - Reflect(四)_reflect vue
- 7微信小程序引入Vant Weapp修改样式不起作用,使用外部样式类进行覆盖_微信小程序修改vant样式
- 8PP-Structure—表格数据提取_ch_ppstructure_mobile_v2.0_slanet
- 9Java.lang.UnsatisfiedLinkError: dalvik.system.PathClassLoader解决方法
- 10到店上门服务源码:同城生活新风尚
Streamlit项目:基于讯飞星火认知大模型开发Web智能对话应用_streamlit 讯飞星火
赞
踩

1 前言
科大讯飞公司于2023年8月15日发布了讯飞认知大模型V2.0,这是一款集跨领域知识和语言理解能力于一体的新一代认知智能大模型。前日,博主对讯飞认知大模型进行了详细的分析,详情请至博文《星星之火:国产讯飞星火大模型的实际使用体验(与GPT对比)》了解。
总的来说,讯飞星火认知大模型表现出卓越的整体性能,在多个领域展现出优秀水平,并且独具多模交互的能力,使其适用的领域更为广泛。特别值得关注的是其中的语义测试、常识性测试以及事件分类测试,这些测试项目揭示了讯飞认知大模型与GPT之间的差异。在常识和事件分类测试中,讯飞认知大模型展示出更出色的表现,而在语义测试中,GPT在准确识别讽刺意味方面更为优秀!
本篇博文聚焦于利用讯飞星火认知大模型的API,基于Streamlit构建个人Web智能对话应用的实践案例。
在本文中,我们将深入探讨如何利用讯飞星火认知大模型的强大功能,为个人Web应用赋予智能对话的能力。我们将介绍整个开发过程的步骤和技术细节,并分享一些关键的使用经验和优化策略。无论您是对智能对话应用开发感兴趣的开发者,还是想要了解讯飞星火认知大模型在实际应用中的表现的研究者,本文都将为您提供宝贵的参考和实践经验。
如果您对Streamlit感兴趣,并且希望深入了解更多相关知识,我强烈推荐您关注我的专栏——《最全Streamlit教程》。
在这个专栏中,我将分享一系列深入而详尽的Streamlit教程和实战案例。我们将探索Streamlit在Web应用开发中的广泛应用,从基本概念到高级功能的全方位覆盖。
通过这些教程,您将深入了解Streamlit的核心原理、工作流程和常见用法。我将解析Streamlit的各个组件和功能,并提供实用的示例代码和技巧,助您快速上手并构建出令人惊叹的交互式应用程序。

2 API获取
要使用讯飞星火认知大模型的功能,您需要向讯飞官方提交申请表单(官网地址)。

在页面上点击"API测试申请",按照指示填写并创建应用,填写正确的信息后,您只需稍等一两天,便可收到讯飞发来的短信通知。随后,您可以登录到开发者工作台,获取所需的appid、api_secret、api_key等关键信息。
3 官方文档的调用代码
为了在Python环境下使用Streamlit工具,博主下载了讯飞官方文档中的Python调用示例,以便更好地理解和应用该工具。您可以通过以下链接下载官方文档:下载链接
在解压后的文件夹中,您将找到两个Python文件:SparkApi.py和test.py。其中,SparkApi.py是讯飞官方提供的库文件,无需进行任何修改。而我们的重点将放在对test.py文件的研究和修改上。

在您的环境中,为了确保能够成功搭建本篇博文所介绍的项目,您至少需要安装以下必要的库:
pip install streamlit
pip install websocket-client
pip install streamlit_chat
- 1
- 2
- 3
我们来看看test.py文件中的代码:
import SparkApi #以下密钥信息从控制台获取 appid = "XXXXXXXX" #填写控制台中获取的 APPID 信息 api_secret = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" #填写控制台中获取的 APISecret 信息 api_key ="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" #填写控制台中获取的 APIKey 信息 #用于配置大模型版本,默认“general/generalv2” domain = "general" # v1.5版本 # domain = "generalv2" # v2.0版本 #云端环境的服务地址 Spark_url = "ws://spark-api.xf-yun.com/v1.1/chat" # v1.5环境的地址 # Spark_url = "ws://spark-api.xf-yun.com/v2.1/chat" # v2.0环境的地址 text =[] # length = 0 def getText(role,content): jsoncon = {} jsoncon["role"] = role jsoncon["content"] = content text.append(jsoncon) return text def getlength(text): length = 0 for content in text: temp = content["content"] leng = len(temp) length += leng return length def checklen(text): while (getlength(text) > 8000): del text[0] return text if __name__ == '__main__': text.clear while(1): Input = input("\n" +"我:") question = checklen(getText("user",Input)) SparkApi.answer ="" print("星火:",end = "") SparkApi.main(appid,api_key,api_secret,Spark_url,domain,question) getText("assistant",SparkApi.answer) # print(str(text))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
在上述代码中,我们需要从控制台获取以下信息:appid、api_secret、api_key。为了确保代码顺利运行,我们需要将 domain 和 Spark_url 更改为 V2.0 版本。
此外,确保 SparkApi.py 文件与 test.py 文件在同一目录下,以便能够轻松地进行导入操作。同样,在将此功能嵌入到 Streamlit 网页项目时,也需要遵循同样的文件路径规则和导入方式。
这些信息是访问讯飞API所必需的凭证和身份验证信息。您可以在讯飞的开发者控制台中获取这些信息。确保您输入的凭证信息正确无误,这样才能够正常连接到讯飞API并获取所需的数据和结果。
以下是运行结果:

很好!已经成功地调用了讯飞API并获得所需的结果。现在,我们可以将这个功能嵌入到一个 Streamlit 网页中,以方便用户使用和体验。
4 Streamlit 网页的搭建
4.1 代码及效果展示
在基于官方提供的示例代码的基础上,我们成功搭建了一个使用 Streamlit 的网页。以下是完整的网页源码(注释很详细):
import streamlit as st from streamlit_chat import message import SparkApi # 以下密钥信息从控制台获取 appid = "XXXXXXXX" # 填写控制台中获取的 APPID 信息 api_secret = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" # 填写控制台中获取的 APISecret 信息 api_key = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" # 填写控制台中获取的 APIKey 信息 # 用于配置大模型版本,默认“general/generalv2” # domain = "general" # v1.5版本 domain = "generalv2" # v2.0版本 # 云端环境的服务地址 # Spark_url = "ws://spark-api.xf-yun.com/v1.1/chat" # v1.5环境的地址 Spark_url = "ws://spark-api.xf-yun.com/v2.1/chat" # v2.0环境的地址 text = [] # 用于存储对话内容的列表 def getText(role, content): """ 构造包含角色和内容的对话信息,并添加到对话列表中 参数: role (str): 对话角色,可以是 "user"(用户)或 "assistant"(助手) content (str): 对话内容 返回值: text (list): 更新后的对话列表 """ jsoncon = {} jsoncon["role"] = role jsoncon["content"] = content text.append(jsoncon) return text def getlength(text): """ 计算对话列表中所有对话内容的字符长度之和 参数: text (list): 对话列表 返回值: length (int): 对话内容的字符长度之和 """ length = 0 for content in text: temp = content["content"] leng = len(temp) length += leng return length def checklen(text): """ 检查对话列表中的对话内容字符长度是否超过限制(8000个字符) 如果超过限制,删除最早的对话内容,直到满足字符长度限制 参数: text (list): 对话列表 返回值: text (list): 更新后满足字符长度限制的对话列表 """ while getlength(text) > 8000: del text[0] return text if __name__ == '__main__': # 在 Streamlit 网页上显示欢迎文本 st.markdown("#### 我是讯飞星火认知模型机器人,我可以回答您的任何问题!") # 初始化对话历史和生成的响应列表 if 'generated' not in st.session_state: st.session_state['generated'] = [] if 'past' not in st.session_state: st.session_state['past'] = [] # 获取用户输入的问题 user_input = st.text_input("请输入您的问题:", key='input') if user_input: # 构造用户输入的对话信息 question = checklen(getText("user", user_input)) # 调用 SparkApi 中的函数进行问题回答 SparkApi.answer = "" print("星火:", end="") SparkApi.main(appid, api_key, api_secret, Spark_url, domain, question) output = getText("assistant", SparkApi.answer) # 将用户输入和生成的响应添加到对话历史和生成的响应列表中 st.session_state['past'].append(user_input) st.session_state['generated'].append(str(output[1]['content'])) if st.session_state['generated']: # 在网页上显示对话历史和生成的响应 for i in range(len(st.session_state['generated']) - 1, -1, -1): message(st.session_state["generated"][i], key=str(i)) message(st.session_state['past'][i], is_user=True, key=str(i) + '_user')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
在代码中,将以下变量替换为您从讯飞开放平台获得的信息:
- appid:替换为您的APPID。
- api_secret:替换为您的APISecret。
- api_key:替换为您的APIKey。
终端运行 Streamlit 应用程序:
streamlit run your_app.py
- 1
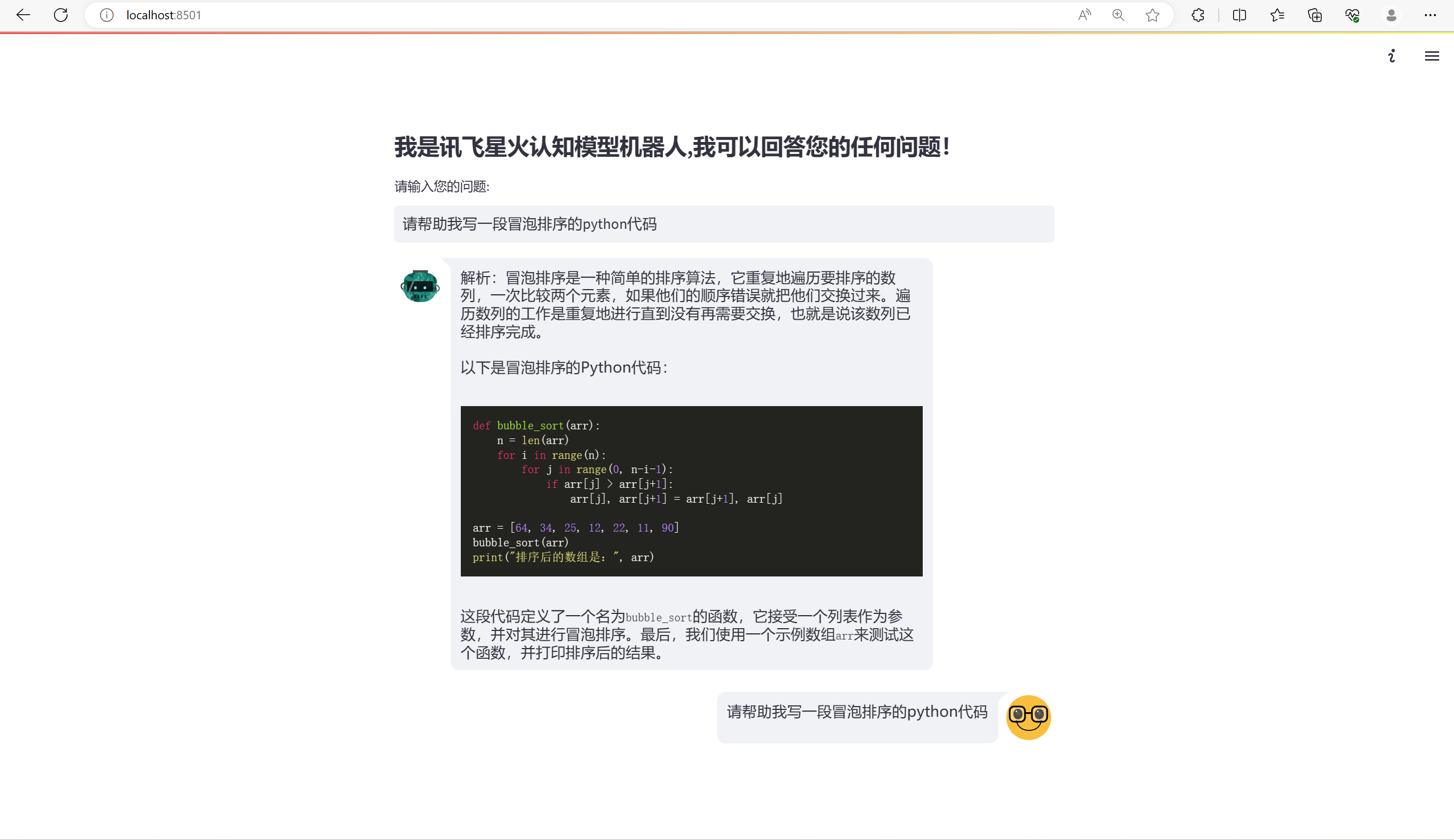
4.2 Streamlit相关知识点
- st.markdown():用于在Streamlit应用程序中显示Markdown格式的文本。
- st.text_input():用于在Streamlit应用程序中创建一个文本输入框,用来获取用户的输入。
- st.session_state:用于在Streamlit应用程序中存储和访问会话状态,可以在不同的函数之间传递数据。在这段代码中,使用st.session_state来保存和获取对话历史和生成的响应。
- st.session_state[‘generated’]和st.session_state[‘past’]:这些变量用于存储对话历史和生成的响应的列表。
- message()函数:这是一个自定义的Streamlit组件,用于显示消息。在这段代码中,使用message()函数来显示对话历史和生成的响应。
如果您对Streamlit感兴趣,并且希望深入了解更多相关知识,我强烈推荐您关注我的专栏——《最全Streamlit教程》。
5 结语
本博文介绍了如何使用Streamlit和讯飞星火认知模型机器人构建一个问答应用程序。通过集成讯飞开放平台的API和自定义的Streamlit组件,我们可以实现实时的问答功能,并在网页上显示对话历史和生成的响应。
在使用这段代码前,需要完成一些准备工作,包括在讯飞开放平台注册账号、创建应用程序并获取相关信息。然后,需要安装所需的Python库,并将提供的源代码修改为适用于自己的API密钥和地址信息。最后,运行Streamlit应用程序并在浏览器中访问生成的URL即可。
在实现问答功能的过程中,我们学习了一些与Streamlit相关的知识点,包括显示Markdown文本、创建文本输入框、存储会话状态等。这些功能使得构建交互式的Web应用程序变得简单易用。
通过本博文的介绍,您现在可以开始使用讯飞星火认知模型机器人构建自己的问答应用程序了。希望这对您有帮助,祝您在开发过程中顺利前进!


