
- 1linux下的opencv-4.5.5 及 opencv_contrib 扩展模块安装_linux opencv4和opencv contribute
- 220180824 SOLA算法实现_sola algorithm
- 3Linux下QT程序打包_qt linux 打包
- 4[seaborn] seaborn学习笔记4-核密度图DENSITYPLOT_python seaborn 图 纵坐标
- 5ios应用程序的两种启动方式_ios app 启动页 xib
- 6perfetto命令 抓取 trace_perfetto抓取trace
- 7react echarts 绘制图表 EchartsLine_react klinecharts
- 8java pgp加密_GPG(pgp)加解密中文完整教程
- 9UE4 C++ 对结构体数组内元素进行排序_ue4 数组排序
- 10linalg模块函数介绍_linalg函数
路径优化丨复现论文-带时间窗和载重约束的外卖路径优化问题丨改进遗传算法:以算例RC101为例_带有时间窗约束的路径优化
赞
踩

引言
本系列文章是路径优化问题学习过程中一个完整的学习路线。问题从简单的单车场容量约束CVRP问题到多车场容量约束MDCVRP问题,再到多车场容量+时间窗口复杂约束MDCVRPTW问题,复杂度是逐渐提升的。
如果大家想学习某一个算法,建议从最简单的TSP问题开始学习,一个阶梯一个阶梯走。
如果不是奔着学习算法源码的思路,只想求解出个结果,请看历史文章,有ortools、geatpy、scikit-opt等求解器相关文章,点击→路径优化历史文章,可直接跳转。
路径优化系列文章:
- 1、路径优化历史文章
- 2、路径优化丨带时间窗和载重约束的CVRPTW问题-改进遗传算法:算例RC108
- 3、路径优化丨带时间窗和载重约束的CVRPTW问题-改进和声搜索算法:算例RC108
- 4、路径优化丨复现论文-网约拼车出行的乘客车辆匹配及路径优化
- 5、多车场路径优化丨遗传算法求解MDCVRP问题
- 6、多车场路径优化丨复现论文-多粒子群+模拟退火算法求解MDCVRP问题
- 7、路径优化丨复现论文-带时间窗和载重约束的外卖路径优化问题丨改进遗传算法:以算例RC101为例
问题描述
带时间窗和载重约束的外卖配送问题可描述为:1个配送中心、每个中心有若干配送车辆、存在若干需求点、配送中心往需求点配送外卖。其中:车辆存在载重约束,需求点存在时间窗约束。本文假设:
- (1)需求点所需外卖量已知,且配送中心能满足所有需求点的外卖需求;
- (2)需求点时间窗已知,过晚到达会受到惩罚;
- (3)需求点位置已知,不考虑外卖在需求点的配送时间;
- (4)所有车辆型号和载重相同;
- (5)配送车辆从外卖配送中心出发,最终返回配送中心。一个站点在配送任务中只能服务 一次。
数学模型
具体模型见参考文献,目标函数是车辆总运行距离。

求解结果如下:

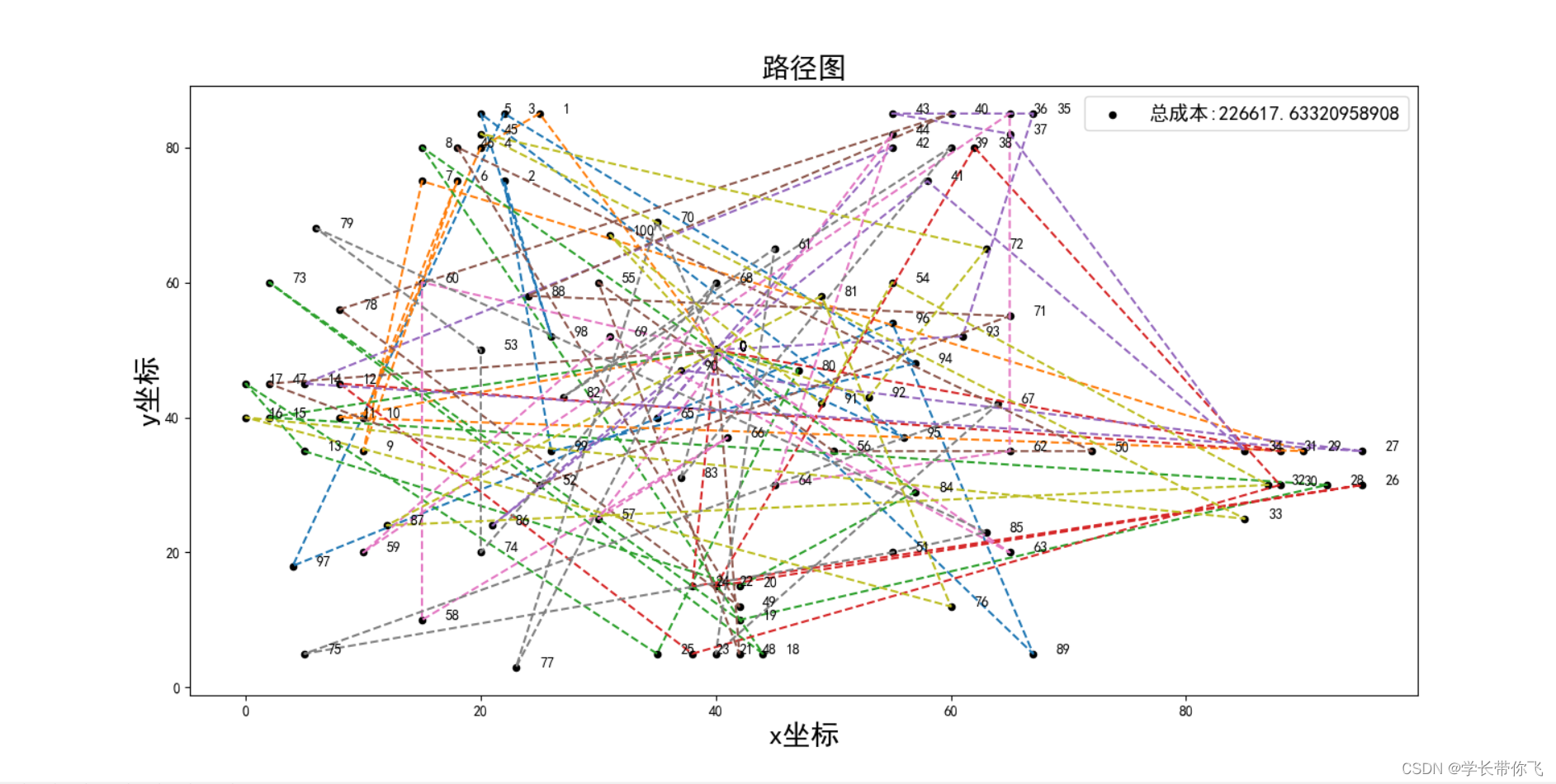
路线图如下:
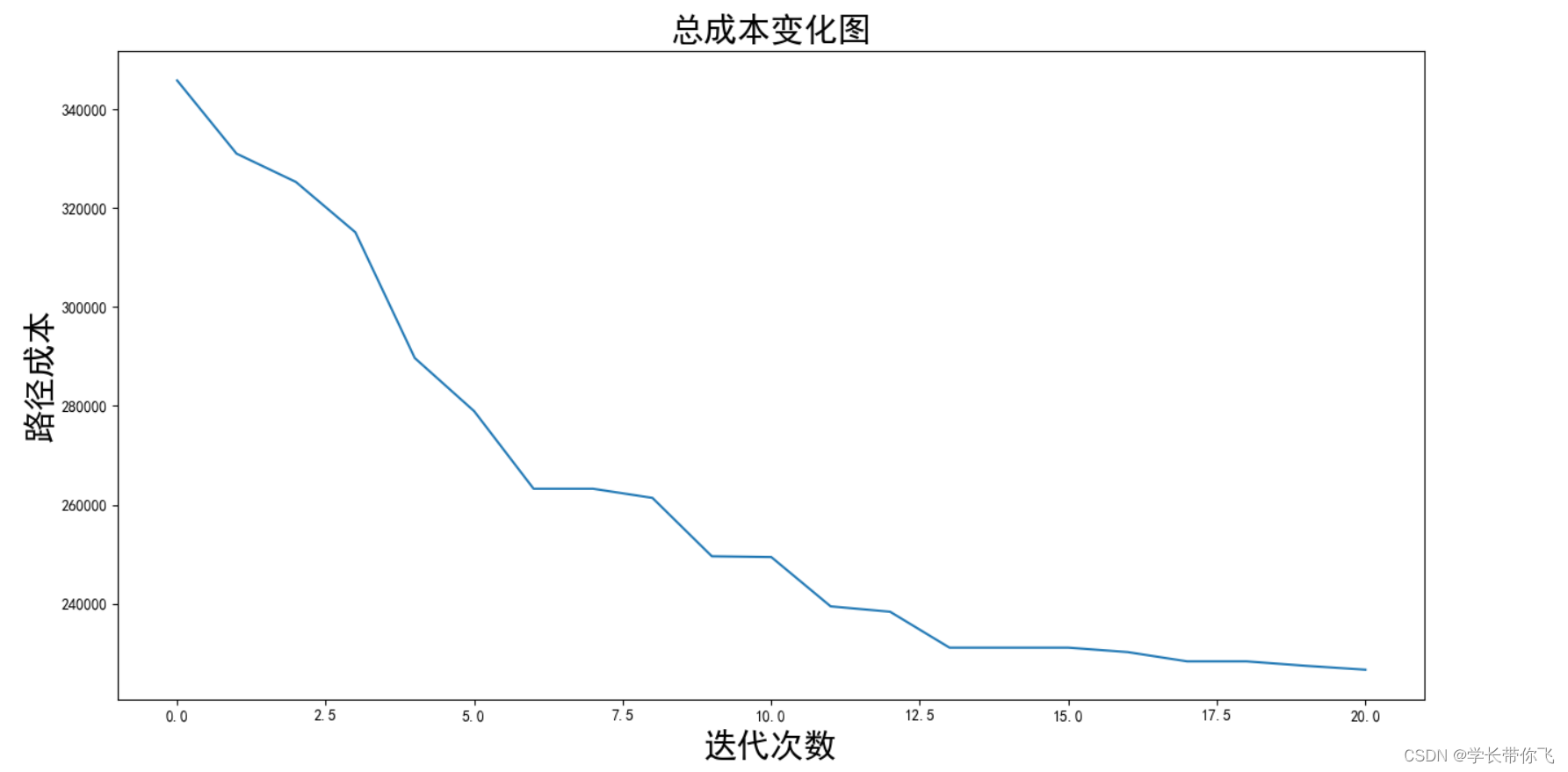
成本随迭代次数的变化图如下:
代码运行环境
windows系统,python3.6.0,第三方库及版本号如下:
numpy==1.18.5
matplotlib==3.2.1
- 1
- 2
第三方库需要在安装完python之后,额外安装,以前文章有讲述过安装第三方库的解决办法。
数据
数据是RC101,文件里的text格式,截图如下:
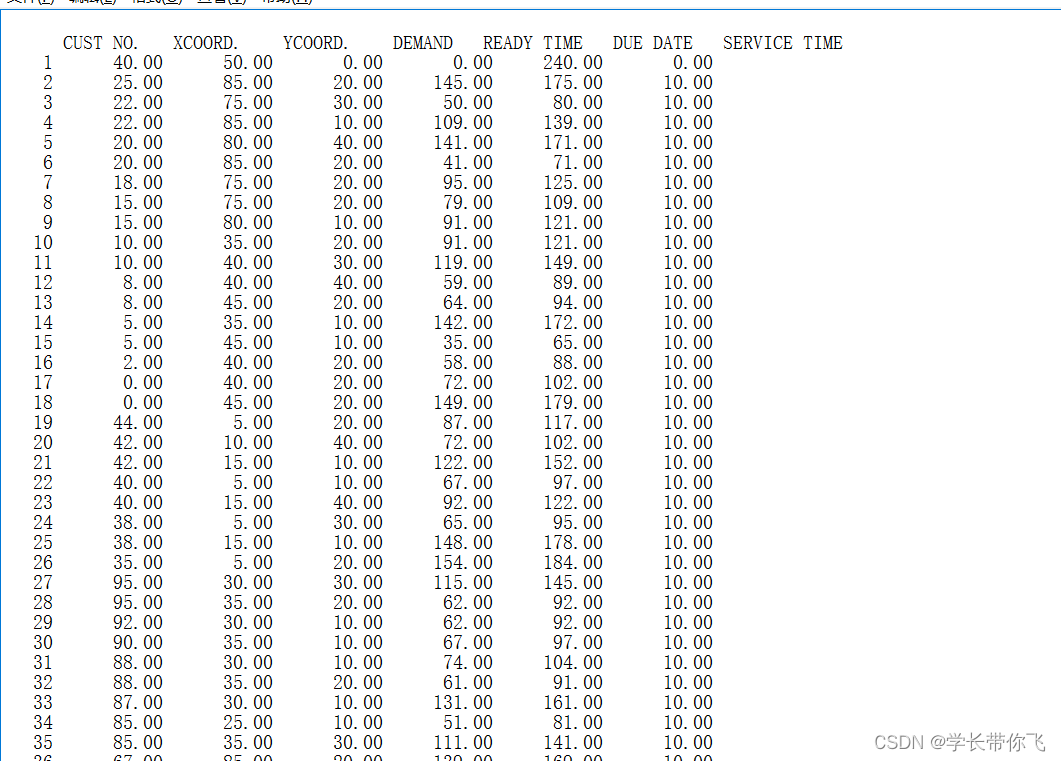
第一行是配送中心,第二第三列是坐标,第4列是需求量,第五第六列是时间窗,最后一列是各个需求点的服务时间,文章不需要。数据是1个配送中心,100个需求点。
数据见网站:http://web.cba.neu.edu/~msolomon/rc101.htm
数据处理
1、 从网站复制数据到txt,用python提取具体数据,主要用到正则模块re;
def txt_to_xlsx(self): f=open('./数据.txt') f1=f.readlines() A = [] count=0 for f2 in f1: if count < 2: a = re.findall('[a-zA-Z]+ [a-zA-Z]+',f2) else: a = re.findall('[0-9.]+',f2) aa = [float(ai) for ai in a] A.append(aa) count += 1 f.close() name = ['CUST NO', 'XCOORD', 'YCOORD', 'DEMAND', 'READY TIME', 'DUE DATE', 'SERVICE TIME'] df = pd.DataFrame(A, columns = name) df.to_excel('数据1.xlsx')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2、 提取出坐标,时间窗,并计算距离矩阵。
def deal(self, df):
x_code = df.iloc[:, 2].tolist()
y_code = df.iloc[:, 3].tolist()
demand = df.iloc[:, 4].tolist()
window_time = np.array(df.iloc[:, 5:7]).tolist()
dis = np.zeros((len(x_code), len(x_code)))
for i in range(len(x_code)):
for j in range(i+1, len(x_code)):
di = np.sqrt((x_code[i] - x_code[j])**2 + (y_code[i] - y_code[j])**2)
dis[i, j] = di
dis[j, i] = di
return x_code, y_code, demand, window_time, dis
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
编码解码及结果可视化
编码和解码
论文的编码是用1到100的数表示100个点的位置,按照论文的编码生成方法:

随机的j为17,一个可行编码如下:
[17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]
1、 根据位置读出各个点的需求;
2、 用车的载重去匹配需求量,车的载重不能满足需求点时,车回到配送中心,换下一辆车;
3、每辆车各个需求点的遍历顺序:1个点时直接添加,多个点时按左时间窗排序添加:
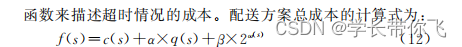
推文的q(s)为0,(载重违反约束成本为0), 推文的时间窗较大,2的w次方改为2乘w
q = c + self.β* 2*w
代码如下:
def car_select_decode(self, road): k = 0 way_all = [[]] win_car = [] win_car_right = [] c = 0 w = 0 load = self.load_max DE = [[]] for i in range(len(road)): point = road[i] load = load - self.demand[point] if i>0 and load >= 0: if len(way_all[-1]) > 0: # 如果某辆车添加的需求点大于0 road_test = way_all[-1] + [point] win_car_test = win_car + [self.window_time[point][0]] win_car_right_test = win_car_right + [self.window_time[point][1]] idx = np.array(win_car_test).argsort() # 按左时间排序的索引 win_car = np.array(win_car_test)[idx].tolist() road_real = np.array(road_test)[idx].tolist() win_car_right = np.array(win_car_right_test)[idx].tolist() way_all[-1] = road_real # 某辆车的需求点按左时间窗排序 if load < 0 : # 如果违反载重约束 load = self.load_max # 换一辆车后,载重回归200 load = load - self.demand[point] rod = way_all[-1] # 取上一辆车的路径 win_car_right += [self.window_time[0][1]] cx, tx = self.c_w_caculate(rod) # 计算运输距离和到达时间点 tw = self.Win_caculte(win_car_right, tx) # 违反时间窗计算 w += tw c += cx way_all.append([]) # 新增车 win_car = [] win_car_right = [] DE.append([]) DE[-1].append(self.demand[point]) if len(way_all[-1]) == 0: # 某辆车添加的需求点为0 way_all[-1].append(point) win_car.append(self.window_time[point][0]) win_car_right.append(self.window_time[point][1]) if i == len(road)-1 : # 如果遍历到最后一个需求点 load = self.load_max # 换一辆车后,载重回归200 load = load - self.demand[point] rod = way_all[-1] # 取上一辆车的路径 cx, tx = self.c_w_caculate(rod) # 计算运输距离和到达时间点 win_car_right += [self.window_time[0][1]] tw = self.Win_caculte(win_car_right, tx) # 违反时间窗计算 w += tw c += cx q = c + self.β*2*w return q, way_all, DE
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
遗传算法设计
介绍参考文献的轮盘赌选择、均匀交叉、两点交换变异、局部搜索:
1、轮盘赌选择
轮盘赌法是模拟博彩游戏的轮盘赌,扇形的面积对应它所表示的染色体的适应值的大小,适应度值被选择的可能性也就越大。轮盘赌法的关键部分是概率和累计概率的计算,具体的步骤如下:
步骤一:计算出群体中每个个体的适应度f(i=1,2,…,M),M为群体大小;计算出每个个体被遗传到下一代群体中的概率
步骤二:累加计算累积概率,如步骤1有概率为[0.2,0.3,0.5],累积概率是[0.2,0.5,1]
步骤三:随机在0,1之间产生一个数r,如果若r<q[1],则选择个体1,否则,选择个体k,使得:q[k-1]<r≤q[k]成立。
代码:
def rand_choose(self, p): #轮盘赌选择
x = np.random.rand()
q = 0
for i, px in enumerate(p):
q += px # 累计概率
if x <= q:
break
return i
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2、路径均匀交叉
为了解可行:两个父代生成一个子代,小于交叉概率时继承一个父代,否则继承另一个父代。
代码:
def road_cross(self,road1,road2): #路径均匀交叉
road3=[]
while len(road1)>0:
index=np.random.randint(0,2,1)[0]
if np.random.rand()<self.p1: #小于交叉概率时子代继承父代的路径基因
road3.append(road1[0])
ro = road3[-1]
road1.remove(ro) #删除两个父代的对应基因
road2.remove(ro)
else: #否则继承另一个父代的路径基因
road3.append(road2[0])
ro = road3[-1]
road1.remove(ro) #删除两个父代的对应基因
road2.remove(ro)
return road3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3、两点交叉变异
随机生成不重复的两个位置,交换基因。
代码:
def road_mul(self,road):
location=random.sample(range(len(road)),2) # 生成两个不重复的位置
road[0,location[0]],road[0,location[1]]=road[0,location[1]],road[0,location[0]]
return road
- 1
- 2
- 3
- 4
4、局部搜索
因为推文的各个车辆的满足载重约束,不适合参考文献的破坏修复算子,设计新的局部搜索如下:
破坏:随机取出一个车辆的某个需求点;
修复:寻找需求点插入该车辆的位置,该位置使得总成本最小。
代码:
def part_search(self, way_all, fi, road): idx = np.random.randint(len(way_all)) idx1 = np.random.randint(len(way_all[idx])) # 车辆随机选择需求点 way = way_all[idx] start = sum([len(way_all[ix]) for ix in range(idx)]) j = idx1 for i in range(len(way)): if i != j: # way[i], way[j] = way[j], way[i] # way_all[idx] = way road[start + i], road[start + j] = road[start + j], road[start + i] fit, way_all, de = self.rd.car_select_decode(road) # 成本计算 if fit > fi: # 成本高于原成本时,不更新最优编码 road[start + i], road[start + j] = road[start + j], road[start + i] # 交换回来,不更新编码 else: # 成本低于原成本时,更新最优编码 fi = fit return road, fi
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
5、算法步骤:
- 步骤1:随机初始多个路径编码
- 步骤2:解码得到每个车辆的成本,求和是总成本
- 步骤3:轮盘选择多个个体、交叉概率下对路径编码进行交叉、变异概率下对路径编码进行变异、局部搜索,父代和子代合并取最优的n(种群规模)个个体。
- 步骤4:判断是否达到最大迭代次数,是的话输出结果,否则转到步骤2
结果
设计主函数如下:
import pandas as pd from decode import data_collect from decode import road_decode from ga import GA # data_collect().txt_to_xlsx() # txt数据处理保存为xlsx path = './数据1.xlsx' df = pd.read_excel(path, sheet_name = 'Sheet1') x_code, y_code, demand, window_time, dist = data_collect().deal(df) #数据提取 customer = [i for i in range(1,101)] # 1到100是需求点 parm_data = [demand, window_time, dist] parm_de = [40, 10, 200] # 40是论文文献的β,10是速度,20是载重 rd = road_decode(parm_data, parm_de) # 解码模块 w = [50, 500, .9, .05] parm_ga = [20, 50, 1, 1] #依次是迭代次数,种群规模,交叉概率,变异概率 g_a = GA(parm_ga, rd, customer) road, answer, result = g_a.ga_total() # 遗传算法结果 q, way_all, de = rd.car_select_decode(road) # 最优路径解码 print('*'*10) print('验证结果:',q) rd.draw(way_all, x_code, y_code, q) # 画路径图 rd.draw_change(result) # 画成本变化图
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
本推文主要是对参考论文进行复现,也有自己的改进,但基本是复现原文,具体算法步骤见文献,不做过多介绍。数据采用rc101,可进行修改数据使用。
代码
为了方便,把代码浓缩在3个代码里,excel数据生成后每次运行main.py无需再运行data_collect().txt_to_xlsx() 。
演示视频:
论文复现丨遗传算法求解外卖路径优化问题
完整算法+数据:
完整算法源码+数据:见下方微信公众号:关注后回复:车间调度

# 微信公众号:学长带你飞
# 主要更新方向:1、柔性车间调度问题求解算法
# 2、学术写作技巧
# 3、读书感悟
# @Author : Jack Hao
- 1
- 2
- 3
- 4
- 5

