
- 1基于微信小程序的垃圾分类管理系统的设计与实现_基于微信小程序的垃圾分类系统
- 2集合框架Map_map(e -> {
- 3mysql 模糊查询带逗号间隔字符(数组字符1,2,3)_模糊搜索 间隔
- 4CentOS6.5 64位GCC从4.4.2升级到4.8.5实录_centos gcc4.2
- 5纯娱乐,教你用AI花10分钟为自己定做理想女友_云服务器下载chilloutmix_niprunedfp32fi
- 6Vue element-ui form 表单 前端提交和后端的接收_el formdata与后台接收
- 7基于Spring Boot技术的幼儿园管理系统
- 8android 9.0 startService启动Servcie的过程分析_android9.0 使用startservice
- 9C# 移动鼠标获取chart控件上的任意位置的值,包括曲线上的数据点的值_c# chart 鼠标
- 10MMLab
【秋招】京东_数据分析岗_面试题整理
赞
踩
1. 怎么做恶意刷单检测
分类问题用机器学习方法建模解决,我想到的特征有:
1)商家特征:商家历史销量、信用、产品类别、发货快递公司等
2)用户行为特征:用户信用、下单量、转化率、下单路径、浏览店铺行为、支付账号
3)环境特征(主要是避免机器刷单):地区、ip、手机型号等
4)异常检测:ip地址经常变动、经常清空cookie信息、账号近期交易成功率上升等
5)评论文本检测:刷单的评论文本可能套路较为一致,计算与已标注评论文本的相似度作为特征
6)图片相似度检测:同理,刷单可能重复利用图片进行评论
2. 你系统的学习过机器学习算法吗?
略。
3. 选个讲下原理吧 K-Means算法及改进,遇到异常值怎么办?评估算法的指标有哪些?
1)k-means原理
2)改进:
a. kmeans++:初始随机点选择尽可能远,避免陷入局部解。方法是n+1个中心点选择时,对于离前n个点选择到的概率更大
b. mini batch kmeans:每次只用一个子集做重入类并找到类心(提高训练速度)
c. ISODATA:对于难以确定k的时候,使用该方法。思路是当类下的样本小时,剔除;类下样本数量多时,拆分
d. kernel kmeans:kmeans用欧氏距离计算相似度,也可以使用kernel映射到高维空间再聚类
3)遇到异常值
a. 有条件的话使用密度聚类或者一些软聚类的方式先聚类,剔除异常值。不过本来用kmeans就是为了快,这么做有些南辕北辙了
b. 局部异常因子LOF:如果点p的密度明显小于其邻域点的密度,那么点p可能是异常值(参考:https://blog.csdn.net/wangyibo0201/article/details/51705966)
c. 多元高斯分布异常点检测
d. 使用PCA或自动编码机进行异常点检测:使用降维后的维度作为新的特征空间,其降维结果可以认为剔除了异常值的影响(因为过程是保留使投影后方差最大的投影方向)
e. isolation forest:基本思路是建立树模型,一个节点所在的树深度越低,说明将其从样本空间划分出去越容易,因此越可能是异常值。是一种无监督的方法,随机选择n个sumsampe,随机选择一个特征一个值。(参考:https://blog.csdn.net/u013709270/article/details/73436588)
f. winsorize:对于简单的,可以对单一维度做上下截取
4)评估聚类算法的指标:
a. 外部法(基于有标注):Jaccard系数、纯度
b. 内部法(无标注):内平方和WSS和外平方和BSS
c. 此外还要考虑到算法的时间空间复杂度、聚类稳定性等
4. 数据预处理过程有哪些?
1)缺失值处理:删、插
2)异常值处理
3)特征转换:时间特征sin化表示
4)标准化:最大最小标准化、z标准化等
5)归一化:对于文本或评分特征,不同样本之间可能有整体上的差异,如a文本共20个词,b文本30000个词,b文本中各个维度上的频次都很可能远远高于a文本
6)离散化:onehot、分箱等
5. 随机森林原理?有哪些随机方法?
1)随机森林原理:通过构造多个决策树,做bagging以提高泛化能力
2)subsample(有放回抽样)、subfeature、低维空间投影(特征做组合,参考林轩田的《机器学习基石》)
6. PCA
1)主成分分析是一种降维的方法
2)思想是将样本从原来的特征空间转化到新的特征空间,并且样本在新特征空间坐标轴上的投影方差尽可能大,这样就能涵盖样本最主要的信息
3)方法:
a. 特征归一化
b. 求样本特征的协方差矩阵A
c. 求A的特征值和特征向量,即AX=λX
d. 将特征值从大到小排列,选择topK,对应的特征向量就是新的坐标轴(采用最大方差理论解释,参考:https://blog.csdn.net/huang1024rui/article/details/46662195)
4)PCA也可以看成激活函数为线性函数的自动编码机(参考林轩田的《机器学习基石》第13课,深度学习)
7. 还有一些围绕着项目问的具体问题
略。
8. 参加过哪些活动?
略。
9. hive?spark?sql? nlp?
1)Hive允许使用类SQL语句在hadoop集群上进行读、写、管理等操作
2)Spark是一种与hadoop相似的开源集群计算环境,将数据集缓存在分布式内存中的计算平台,每轮迭代不需要读取磁盘的IO操作,从而答复降低了单轮迭代时间
10. XGBOOST
xgb也是一种梯度提升树,是gbdt高效实现,差异是:
1)gbdt优化时只用到了一阶导数信息,xgb对代价函数做了二阶泰勒展开。(为什么使用二阶泰勒展开?我这里认为是使精度更高收敛速度更快,参考李宏毅的《机器学习》课程,对损失函数使用泰勒一次展开是梯度下降,而进行更多次展开能有更高的精度。但感觉还不完全正确,比如为什么不三次四次,比如引进二次导会不会带来计算开销的增加,欢迎大家讨论指正。)



2)xgb加入了正则项
3)xgb运行完一次迭代后,会对叶子节点的权重乘上shrinkage(缩减)系数,削弱当前树的影响,让后面有更大的学习空间
4)支持列抽样等特性
5)支持并行:决策树中对特征值进行排序以选择分割点是耗时操作,xgb训练之前就先对数据进行排序,保存为block结构,后续迭代中重复用该结构,大大减少计算量。同时各个特征增益的计算也可以开多线程进行
6)寻找最佳分割点时,实现了一种近似贪心法,同时优化了对稀疏数据、缺失值的处理,提高了算法效率
7)剪枝:GBDT遇到负损失时回停止分裂,是贪心算法。xgb会分裂到指定最大深度,然后再剪枝
11. 还问了数据库,spark,爬虫(简历中有)
略。
12. 具体案例分析,关于京东商城销售的
略。
13. Linux基本命令
1)目录操作:ls、cd、mkdir、find、locate、whereis等
2)文件操作:mv、cp、rm、touch、cat、more、less
3)权限操作:chmod+rwx421
4)账号操作:su、whoami、last、who、w、id、groups等
5)查看系统:history、top
6)关机重启:shutdown、reboot
7)vim操作:i、w、w!、q、q!、wq等
14. NVL函数
1)是oracle的一个函数
2)NVL( string1, replace_with),如果string1为NULL,则NVL函数返回replace_with的值,否则返回原来的值
15. LR
1)用于分类问题的线性回归
2)采用sigmoid对输出值进行01转换
3)采用似然法求解
4)手推
5)优缺点局限性
6)改进空间
16. sql中null与‘ ’的区别
1)null表示空,用is null判断
2)''表示空字符串,用=''判断
17. 数据库与数据仓库的区别
1)简单理解下数据仓库是多个数据库以一种方式组织起来
2)数据库强调范式,尽可能减少冗余
3)数据仓库强调查询分析的速度,优化读取操作,主要目的是快速做大量数据的查询
4)数据仓库定期写入新数据,但不覆盖原有数据,而是给数据加上时间戳标签
5)数据库采用行存储,数据仓库一般采用列存储
6)数据仓库的特征是面向主题、集成、相对稳定、反映历史变化,存储数历史数据;数据库是面向事务的,存储在线交易数据
7)数据仓库的两个基本元素是维表和事实表,维是看待问题的角度,比如时间、部门等,事实表放着要查询的数据
18. 手写SQL
略。
19. SQL的数据类型
1)字符串:char、varchar、text
2)二进制串:binary、varbinary
3)布尔类型:boolean
4)数值类型:integer、smallint、bigint、decimal、numeric、float、real、double
5)时间类型:date、time、timestamp、interval
20. C的数据类型
1)基本类型:
a. 整数类型:char、unsigned char、signed char、int、unsigned int、short、unsigned short、long、unsigned long
b. 浮点类型:float、double、long double
2)void类型
3)指针类型
4)构造类型:数组、结构体struct、共用体union、枚举类型enum
21. 分类算法性能的主要评价指标
1)查准率、查全率、F1
2)AUC
3)LOSS
4)Gain和Lift
5)WOE和IV
22. roc图
1)以真阳(TP)为横轴,假阳为纵轴(FP),按照样本预测为真的概率排序,绘制曲线
2)ROC曲线下的面积为AUC的值
23. 查准率查全率
1)查准率:TP/(TP+FP)
2)查全率:TP/(TP+FN)
24. 数据缺失怎么办
1)删除样本或删除字段
2)用中位数、平均值、众数等填充
3)插补:同类均值插补、多重插补、极大似然估计
4)用其它字段构建模型,预测该字段的值,从而填充缺失值(注意:如果该字段也是用于预测模型中作为特征,那么用其它字段建模填充缺失值的方式,并没有给最终的预测模型引入新信息)
5)onehot,将缺失值也认为一种取值
6)压缩感知及矩阵补全
25. 内连接与外连接的区别
1)内连接:左右表取匹配行
2)外连接:分为左连接、右连接和全连接
26. 欧式距离
1)字段取值平方和取开根号
2)表示m维空间中两个点的真实距离
27. 普通统计分析方法与机器学习的区别
这里不清楚普通统计分析方法指的是什么。
如果是简单的统计分析指标做预测,那模型的表达能力是落后于机器学习的。
如果是指统计学方法,那么统计学关心的假设检验,机器学习关心的是建模,两者的评估不同。
28. BOSS面:关于京东的想法,哪里人,什么学校,多大了,想在京东获得什么,你能为京东提供什么,关于转正的解释,工作内容,拿到offer
略。
29. 先问了一个项目,然后问了工作意向,对工作是怎么看待的
略。
30. 问了一点Java很基础的东西,像set、list啥的
略。
31. 感觉一二面的面试官比较在意你会不会hive、sql
略。
32. 怎么判断一个账号不安全不正常了,比如被盗号了,恶意刷单之类的
分类问题用机器学习方法建模解决,我想到的特征有:
1)商家特征:商家历史销量、信用、产品类别、发货快递公司等
2)用户行为特征:用户信用、下单量、转化率、下单路径、浏览店铺行为、支付账号
3)环境特征(主要是避免机器刷单):地区、ip、手机型号等
4)异常检测:ip地址变动、经常清空cookie信息、账号近期交易成功率上升等
5)评论文本检测:刷单的评论文本可能套路较为一致,计算与已标注评论文本的相似度作为特征
6)图片相似度检测:同理,刷单可能重复利用图片进行评论
33. 只是岗位名称一样,我一面问的都是围绕海量数据的推荐系统,二面就十几分钟,都是自己再说……感觉凉的不能再凉了
1)基于内容
2)协同过滤
3)基于矩阵分解
4)基于图
其它包括冷启动、评估方法等
34. 项目写的是天池比赛,只是大概描述了一下,特征工程和模型的选择
1)数据预处理
2)时间特征处理(sin化等)
3)连续特征处理(分箱等)
4)类别特征处理(onehot等)
5)交叉特征
6)特征hash化
7)gbdt构造特征
8)tfidf等对文本(或类似文本)的特征处理
9)统计特征
10)embedding方法作用于样本
11)聚类、SVD、PCA等
12)NN抽取特征
13)自动编码机抽取特征
35. GBDT原理介绍下
1)首先介绍Adaboost Tree,是一种boosting的树集成方法。基本思路是依次训练多棵树,每棵树训练时对分错的样本进行加权。树模型中对样本的加权实际是对样本采样几率的加权,在进行有放回抽样时,分错的样本更有可能被抽到
2)GBDT是Adaboost Tree的改进,每棵树都是CART(分类回归树),树在叶节点输出的是一个数值,分类误差就是真实值减去叶节点的输出值,得到残差。GBDT要做的就是使用梯度下降的方法减少分类误差值
在GBDT的迭代中,假设我们前一轮迭代得到的强学习器是ft−1(x), 损失函数是L(y,ft−1(x)), 我们本轮迭代的目标是找到一个CART回归树模型的弱学习器ht(x),让本轮的损失损失L(y,ft(x)=L(y,ft−1(x)+ht(x))最小。也就是说,本轮迭代找到决策树,要让样本的损失尽量变得更小。
GBDT的思想可以用一个通俗的例子解释,假如有个人30岁,我们首先用20岁去拟合,发现损失有10岁,这时我们用6岁去拟合剩下的损失,发现差距还有4岁,第三轮我们用3岁拟合剩下的差距,差距就只有一岁了。如果我们的迭代轮数还没有完,可以继续迭代下面,每一轮迭代,拟合的岁数误差都会减小。
(参考:https://www.cnblogs.com/pinard/p/6140514.html)
3)得到多棵树后,根据每颗树的分类误差进行加权投票
36. XGBoost原理介绍下
见前文。
37. 用滑动窗口是怎样构造特征的
文本和图像数据中,设置窗口大小与滑动步长,以窗口为片段抽取特征。
38. 简单的介绍随机森林,以及一些细节
1)随机森林原理:通过构造多个决策树,做bagging以提高泛化能力
2)随机方法包括:subsample(有放回抽样)、subfeature、低维空间投影(特征做组合,参考林轩田的《机器学习基石》)
3)有放回抽样,可以用包外样本做检验
4)也可以用OOB做特征选择,思路:
a. 如果一个特征有效,那么这个特征引入杂质会明显影响模型效果
b. 引入杂质会影响分布,所以更好的方式是对特征中的取值进行洗牌,然后计算前后模型的差异
c. 但是我们不想训练两个模型,可以利用OOB进行偷懒。把OOB中的数据该特征取值洗牌,然后扔进训练好的模型中,用输出的结果进行误差检验
39. 一个网站销售额变低,你从哪几个方面去考量?
1)首先要定位到现象真正发生的位置,到底是谁的销售额变低了?这里划分的维度有:
a. 用户(画像、来源地区、新老、渠道等)
b. 产品或栏目
c. 访问时段
2)定位到发生未知后,进行问题拆解,关注目标群体中哪个指标下降导致网站销售额下降:
a. 销售额=入站流量*下单率*客单价
b. 入站流量 = Σ各来源流量*转化率
c. 下单率 = 页面访问量*转化率
d. 客单价 = 商品数量*商品价格
3)确定问题源头后,对问题原因进行分析,如采用内外部框架:
a. 内部:网站改版、产品更新、广告投放
b. 外部:用户偏好变化、媒体新闻、经济坏境、竞品行为等
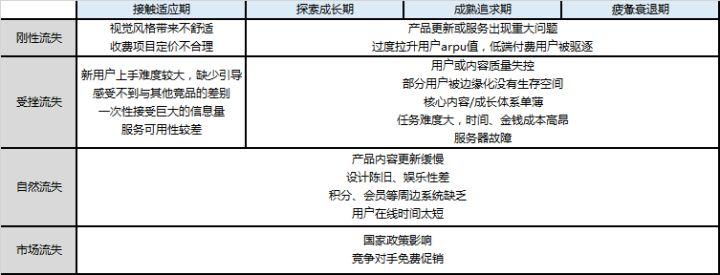
40. 还有用户流失的分析,新用户流失和老用户流失有什么不同?
1)用户流失分析:
a. 两层模型:细分用户、产品、渠道,看到底是哪里用户流失了。注意由于是用户流失问题,所以这里细分用户时可以细分用户处在生命周期的哪个阶段。
b. 指标拆解:用户流失数量 = 该群体用户数量*流失率。拆解,看是因为到了这个阶段的用户数量多了(比如说大部分用户到了衰退期),还是这个用户群体的流失率比较高
c. 内外部分析:
a. 内部:新手上手难度大、收费不合理、产品服务出现重大问题、活动质量低、缺少留存手段、用户参与度低等
b. 外部:市场、竞争对手、社会环境、节假日等
2)新用户流失和老用户流失有什么不同:
a. 新用户流失:原因可能有非目标用户(刚性流失)、产品不满足需求(自然流失)、产品难以上手(受挫流失)和竞争产品影响(市场流失)。
新用户要考虑如何在较少的数据支撑下做流失用户识别,提前防止用户流失,并如何对有效的新用户进行挽回。
b. 老用户流失:原因可能有到达用户生命周期衰退期(自然流失)、过度拉升arpu导致低端用户驱逐(刚性流失)、社交蒸发难以满足前期用户需求(受挫流失)和竞争产品影响(市场流失)。
老用户有较多的数据,更容易进行流失用户识别,做好防止用户流失更重要。当用户流失后,要考虑用户生命周期剩余价值,是否需要进行挽回。
(参考@王玮 的回答:https://www.zhihu.com/question/26225801)
41. 京东商城要打5-6线渠道,PPT上放什么怎么放?对接人是CXO
(我刚准备开口讲面试官让我先思考一下)
1)根据到底是CXO再决定
2)重点是了解CXO在这个打渠道行为中的角色,CXO关心的业绩指标是什么,然后针对性地展示 为了达成这个业绩指标 所相关的数据
42. GMV升了20%怎么分析
(我噼里啪啦分析了一通面试官笑嘻嘻地告诉我是数据错了,因为面试较紧张没有意识到这个问题,现在想想真是个大坑啊)
1)参考该面试者经验,应该先估算一下数字有没有问题
2)同样的套路:
a. 两层模型:进行用户群体、产品、渠道细分,发现到底是谁的GMV提升了
b. 指标拆解:将GMV拆解成乘法模型,如GMV=广告投放数量*广告点击率*产品浏览量*放入购物车率*交易成功率*客单价,检查哪一步有显著变化导致了GMV上升
c. 内外部分析:
a. 内部:网站、产品、广告投放、活动等
b. 外部:套PEST等框架也行,或者直接分析也行,注意MEMC即可
这一题要注意,GMV流水包括取消的订单金额和退货/拒收的订单金额,还有一种原因是商家刷单然后退货,虽然GMV上去了,但是实际成交量并没有那么多。
43. 怎么向小孩子解释正态分布
(随口追问了一句小孩子的智力水平,面试官说七八岁,能数数)
1)拿出小朋友班级的成绩表,每隔2分统计一下人数(因为小学一年级大家成绩很接近),画出钟形。然后说这就是正态分布,大多数的人都集中在中间,只有少数特别好和不够好
2)拿出隔壁班的成绩表,让小朋友自己画画看,发现也是这样的现象
3)然后拿出班级的身高表,发现也是这个样子的
4)大部分人之间是没有太大差别的,只有少数人特别好和不够好,这是生活里普遍看到的现象,这就是正态分布
44. 有一份分析报告,周一已定好框架,周五给老板,因为种种原因没能按时完成,怎么办?
略。


