
- 1简单介绍Hadoop实操_fayson hadoop实操
- 2微博舆情分析系统
- 3vue3为什么使用带有 .value 的 ref,而不是普通的变量_vue中ref使用时为什么要加value
- 4Corrupt JPEG data: premature end of data segment
- 5基于java springboot框架+微信小程序原生开发框架+mysql数据库的养老服务系统 计算机毕业设计 微信小程序开发_微信小程序+springboot+mysql项目
- 6Android面试官爱问的12个自定义View的问题
- 7[No000012D]WPF(5/7)依赖属性
- 8安卓开发学习之SystemServer启动过程_initbeforestartservices
- 9php在线解密工具,zend5.2,zend5.3,zend5.4,支持ioncube,魔方,sourceguardian,goto,微擎加密,混淆eval等解密_sourceguardian解密
- 10公众号文章目录整理_公众号文章目录索引
使用 Python、Elasticsearch 和 Kibana 分析波士顿凯尔特人队_python能模拟kibana获取数据
赞
踩
作者:来自 Jessica Garson
大约一年前,我经历了一段压力很大的时期,最后参加了一场篮球比赛。 在整个过程中,我可以以一种我以前无法做到的方式断开连接并找到焦点。 我加入的第一支球队是波士顿凯尔特人队。 波士顿凯尔特人队是一支不同寻常的球队,虽然他们本赛季经常位居 NBA 实力排行榜榜首,但他们只是有时在许多核心指标上领先联盟。
使用数据可视化,我可以更深入地了解这支球队,回答一些有关它的关键问题,并更好地分析赛季。 这篇博文将向你展示如何使用 Python 在 Elastic 中加载数据,使用 Elasticsearch 编写查询,使用 Kibana 创建仪表板。 你可以查看这篇博文的完整代码。
先决条件
本教程使用 Elasticsearch 版本 8.12; 如果你是新手,请查看我们的 Elasticsearch 和 Kibana 快速入门。
如果你的计算机上尚未安装 Python,请下载最新版本。 此示例使用 Python 3.12.1。
你将使用 nba_api 包获取有关波士顿凯尔特人队、Jupyter Notebooks 和 Elasticsearch Python 客户端的最新统计数据。 在测试此代码时,除非安装了 pandas,否则我会收到错误,因为 nba_data 创建 pandas DataFrame。
要安装这些软件包,你可以运行以下命令。
pip3 install nba_api jupyter elasticsearch pandas load_dotenv你将需要加载 Jupyter Notebook 以交互方式处理你的数据。 为此,你可以在终端中运行以下命令。
- export ES_USER=elastic
- export ES_PASSWORD=xnLj56lTrH98Lf_6n76y
-
- jupyter notebook
在上面,你需要根据自己的 Elasticsearch 设置替换上面的 ES_USER 及 ES_PASSWORD 值。
在右上角,你可以选择 “New” 来创建新的 Jupyter Notebook。
步骤 1:解析和清理波士顿凯尔特人队数据
第一步是连接到 NBA 数据并将该数据加载到 Elasticsearch 中。 你首先需要导入所需的库。 在此示例中,你将使用 nba_api 的静态球队数据来获取有关波士顿凯尔特人队的信息。 leaguegamefinder 端点允许你获取信息。 要连接到 Elastic,你将使用 Elasticsearch Python 客户端 elasticsearch。
要加载这些包,你可以使用以下代码:
- from dotenv import load_dotenv
- from nba_api.stats.static import teams
- from nba_api.stats.endpoints import leaguegamefinder
- from elasticsearch import Elasticsearch, helpers
- import os
-
-
- load_dotenv()
-
- elastic_user=os.getenv('ES_USER')
- elastic_password=os.getenv('ES_PASSWORD')
-
- url = f"https://{elastic_user}:{elastic_password}@localhost:9200"
- es = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)
-
- print(es.info())

你需要从 NBA 球队静态数据集中获取球队数据,其中每个球队都有一个 ID。 你可以使用列表理解来查找波士顿缩写为 BOS 的球队。 获得完整的 Celtics 对象后,你可以将其范围缩小到仅 ID,你可以使用它来查找比赛数据。
- nba_teams = teams.get_teams()
- celtics = [team for team in nba_teams if team['abbreviation'] == 'BOS'][0]
- celtics_id = celtics['id']
现在,你可以使用凯尔特人队的 ID 获取该球队的所有可用比赛数据。 你可以查看前五个结果,以确保使用 .head() 方法正确加载数据。
- celtics_games = leaguegamefinder.LeagueGameFinder(team_id_nullable=celtics_id)
- games = celtics_games.get_data_frames()[0]
- games.head()
在处理这些数据时,我注意到今年的数据包括季前数据。 因此,我使用赛季日期将数据范围缩小到当前赛季。 在 Jupyter Notebook 中,你可以调用 current_season 来查看完整的 DataFrame。
- current_season = games.loc[(games['GAME_DATE'] >= '2023-10-24') & (games['GAME_DATE'] <= '2024-06-20')]
- current_season
由于空值在将数据加载到 Elasticsearch 时可能会产生问题,因此你可以仔细检查该数据是否没有空值。 下面的行返回一个布尔值,让你知道数据是否有任何空值。 由于该数据集返回 False 值,因此它没有空值,因此我们不必进行进一步的清理。
current_season.isnull().values.any()第 2 步:将波士顿凯尔特人队数据加载到 Elasticsearch 中
在将数据加载到 Elastic 之前,你必须创建索引。 你可以为当前季节创建一个。
- INDEX_NAME = "boston_celtics_current_season"
-
- es.indices.create(index = INDEX_NAME)
你可以创建一个函数将当前季节的数据加载到 Elasticsearch 中。 每个 game 都被视为一个文档。
- def doc_generator(df, timeframe):
- for index, document in df.iterrows():
- yield {
- "_index": INDEX_NAME,
- "_id": f"{document['GAME_ID']}",
- "_source": document.to_dict(),
- }
Python 客户端的帮助程序功能允许你高效地将保存当前赛季比赛数据的 DataFrame 上传到 Elasticsearch。 通过调用刚刚创建的 doc_generator 函数,你可以将 DataFrame 转换为文档。
- helpers.bulk(es, doc_generator(current_season, index))
- es.indices.refresh(index=index)
第 3 步:使用 Elasticsearch 编写查询
现在你的数据已加载,你可以开始使用 Elasticsearch 编写查询,以了解有关波士顿凯尔特人队本赛季表现的更多信息。 首先,你可以创建一个查询来查看他们本赛季到目前为止已经取得了多少场胜利,并返回胜利的计数结果。
- search_query = {
- "query": {
- "match": {
- "WL": "W"
- }
- }
- }
-
- games_won = es.count(index="boston_celtics_current_season", body=search_query)
在处理复杂的数据集时,编写句子来帮助解释数据集有时会很有帮助。 以下是波士顿凯尔特人队本赛季赢得多少场比赛的一个例子。
print(f"The Celtics won {games_won['count']} games this season so far.")输出应如下所示:
The Celtics won 38 games this season so far.体育运动中的连胜是指球队或个人连续获胜或失败的一系列连续比赛或赛事。 连胜很重要,因为它们反映了一段时期的出色表现(连胜)或具有挑战性的阶段(连败)。 在分析一支球队的表现时,检查他们有多少连续得分通常是有帮助的。 你可以创建一个查询,允许你按比赛数据对输赢进行排序。
- streak_query = {
- "size": 1000,
- "sort": [
- {
- "GAME_DATE": {
- "order": "asc"
- }
- }
- ],
- "_source": ["GAME_DATE", "WL"]
- }
你可以使用 es.search() 方法根据上面的查询创建搜索。
- streak_search = es.search(
- index="boston_celtics_current_season",
- body=streak_query)
以下代码创建一个比赛日期和比赛结果的 JSON 对象。
gs = [hit['_source'] for hit in streak_search['hits']['hits']]要查看本赛季前五连胜,你可以为每个连胜创建一个字典并进行相应的排序。
- streaks = []
- current_streak = 1
- for i in range(1, len(gs)):
- if gs[i]['WL'] == gs[i-1]['WL']:
- current_streak += 1
- else:
- streaks.append((gs[i-1]['WL'], current_streak))
- current_streak = 1
-
-
- streaks.append((gs[-1]['WL'], current_streak))
- top_streaks = sorted(streaks, key=lambda x: x[1], reverse=True)[:5]
- top_streaks
第 4 步:使用 Kibana 创建仪表板
虽然我们可以继续编写查询来了解有关波士顿凯尔特人队的更多信息,但创建仪表板是从数据中获取见解的更有效方法。

在制作仪表板之前,你需要创建一个数据视图,以确保 Kibana 可以访问 Elasticsearch 索引中的数据。 对于数据视图,你需要为其命名,选择表示要可视化的多个索引的索引或模式,并提供时间戳字段,以便你可以创建基于时间的可视化。
注意:在进行可视化之前,你需要为当前的索引创建一个 data view。

创建数据视图后,你可以开始创建仪表板。 在 “Analytics” 标题下,选择 “Dashboard” 所在的位置,然后单击 “Create Dashboard” 所在的位置。
一个出色的可视化首先是为仪表板创建标题可视化。 你可以选择文本可视化和 Markdown 以将图像添加到标题中。
#  How are the Boston Celtics performing this season?
要了解凯尔特人队赢得的比赛是否多于输掉的比赛,你可以创建一个 waffle 图来说明在赛季的此时点,凯尔特人队赢得的比赛多于输掉的比赛。

你可以在此处查看此图表的配置:

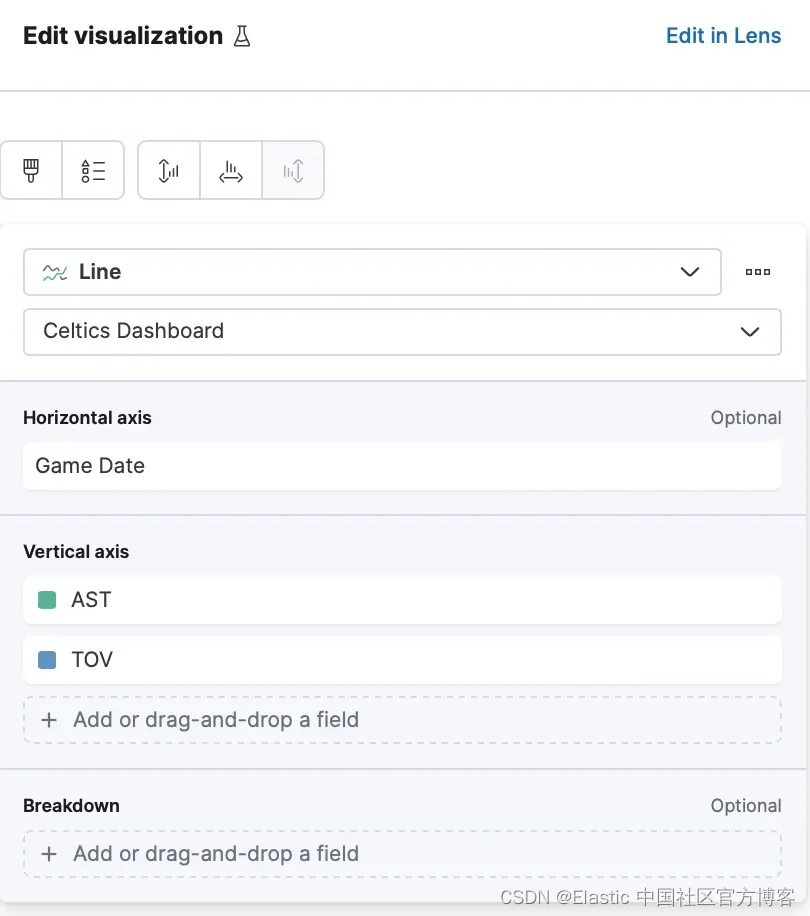
保持助攻多于失误是球队有效传球的一个重要指标。 截至本博文发布之日,随附的可视化结果清楚地表明球队在这方面表现良好,展示了熟练的球分配和团队合作。

该可视化的配置如下所示:
篮球比赛中的正负值显示了波士顿凯尔特人队比其他球队多了多少分,这个统计数据经常被用来解释一支球队对比赛的影响。 高分表明球队在比赛时在得分或阻止进球/得分方面往往表现良好。 高负分表明相反的情况 —— 球队往往会被超越。 赛季初,凯尔特人队在一场比赛中比另一支球队多得分超过 50 分,但随着时间的推移,这种情况逐渐正常化。 最近一场对阵密尔沃基雄鹿队的比赛(在撰写本文时)也是一个异常值。

以下是上述可视化的配置。

要了解有关凯尔特人队投篮频率的更多信息,你可以创建一些顶线,包括:
- 平均投篮命中率是多少?
- 三分线外的平均投篮命中率是多少?
- 平均罚球命中率是多少?

这些顶行的配置在 Kibana 中如下所示:
投篮命中率顶线配置:

三分线底线投篮命中率配置:

罚球命中率顶线配置:

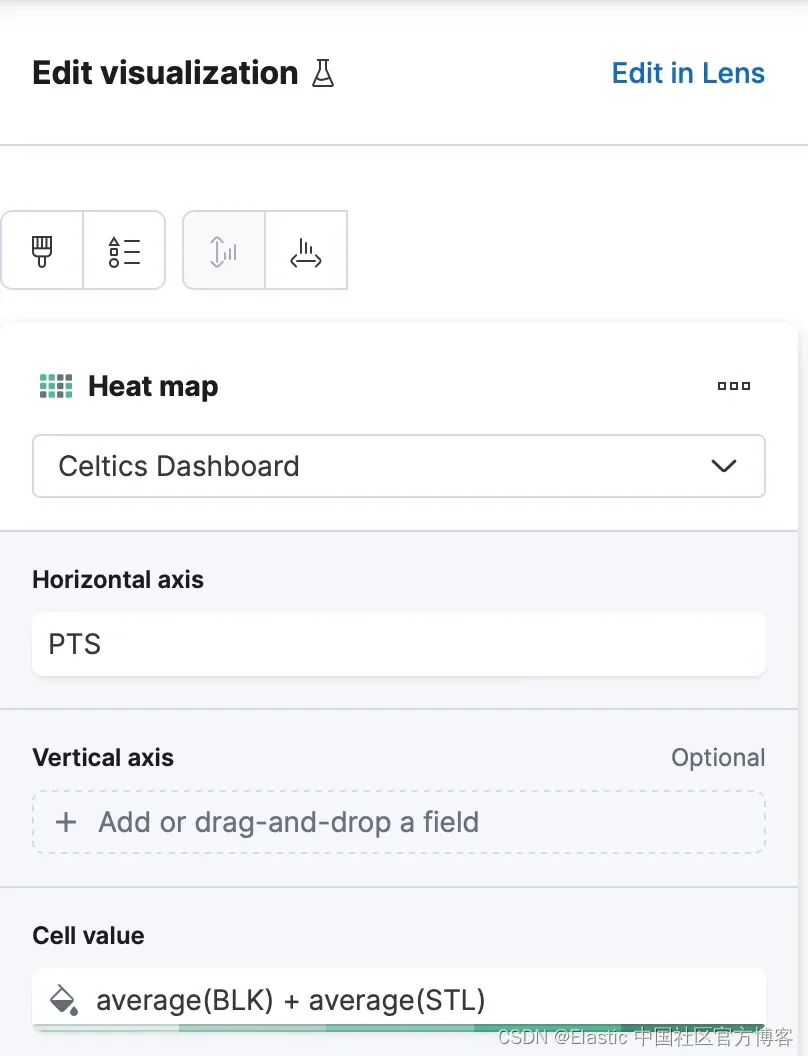
最终的可视化检查了凯尔特人队的得分是否会随着抢断和盖帽的增加而增加。 颜色代表盖帽平均值加上抢断平均值。 随着盖帽和抢断数量的增加,绿色会变暗。 然而,数据中缺乏明显的模式表明这些防守行为与其总体得分之间没有显着相关性。

此可视化的配置应如下所示:
结论
通过以这种方式可视化数据,你可以与数据进行稳健的交互并得出进一步的见解。 请务必查看这篇博文的完整代码。 下一步,创建一个数据管道,以编程方式将数据输入仪表板或利用我们的一些机器学习功能,例如异常检测。 你还可以通过添加凯尔特人队的历史数据或将凯尔特人队与 NBA 中的其他球队进行比较来扩展此数据集。 我们希望你可以继续使用 Python、Elasticsearch 和 Kibana。 与往常一样,如果你需要这篇博文激励你构建任何东西,或者你对我们的讨论论坛和社区 Slack 频道有任何疑问,请告诉我们。
更多关于可视化的文章,请参阅文章:
原文:Analyzing the Boston Celtics using Python, Elasticsearch, and Kibana — Elastic Search Labs

