
- 1微信小程序商城项目实战(第二篇:分类页)_微信小程序开发 商品分类页面
- 2东北农业大学计算机科学与技术复试名单,更新!最新182所院校复试信息汇总
- 3Putty的使用_putty csdn
- 4windows下使用Jupyter notebook远程访问服务器的两种方法_jupyter notebook局域网访问
- 5【HarmonyOS】装饰器下的状态管理与页面路由跳转实现_harmonyos应用启动后自动跳转主页面
- 6el-input输入保留两位小数_el-input保留两位小数
- 7物流行业专业词汇汇总
- 8Mac NTFS 磁盘读写工具选哪个好?Tuxera 还是 Paragon?_赤友ntfs和tuxera哪个好用
- 9字符编码和Emoji,理解编码,utf-8,utf-16,utf-32_string.fromcharcode 用utf-8编码
- 10Windows本地Nginx服务报错_系统找不到文件 nginx
R语言基础的代码语法解译笔记
赞
踩
1、双冒号,即:“::”
要使用某个包里的函数,通常做法是先加载(library)包,再调用函数。最新加载的包的namespace会成为最新的enviroment,某些情况下可能影响函数的结果。而package name::functionname的用法,一是可以在需要用某个函数时临时直接加载包,不用事先library。另一点更重要的是尽可能减少library带来的附带作用,这一点在开发R包时影响较大。而这种写法的副作用,是会稍微慢上那么几毫秒,在需要反复循环使用一个函数时对效率有影响,其他时候除了写起来麻烦一点,基本没有显见的副作用。
2、%>% (向右操作符,forward-pipe operator)
把左侧的数据或表达式,传递给右侧的函数调用或表达式进行运行,可以连续操作。相当于将左边的作为右边函数的第一个参数。
现实原理如下图所示,使用%>%把左侧的程序的数据集A传递右侧程序的B函数,B函数的结果数据集再向右侧传递给C函数,最后完成数据计算。

例如:
- f(x,y)等价于x %>% f(y)
- g(f(x,y),z)等价于x %>% f(y) %>% g()
- library(ggplot2)
- library(dplyr)
-
- cut_depth <- group_by(diamonds,cut,depth)
- cut_depth <- summarise(cut_depth,n=n())
- cut_depth <- filter(cut_depth,depth>55,depth<70)
- cut_depth <- mutate(cut_depth,prop=n/sum(n))
- cut_depth
-
- # 使用%>%
- cut_depth1 <- diamonds%>%
- group_by(cut,depth)%>%
- summarise(n=n())%>%
- filter(depth>55,depth<70)%>%
- mutate(prop=n/sum(n))
- cut_depth1
-
- # 另外一个例子
- library(magrittr)
-
- set.seed(123) #设置种子序列,保证结果可重复
- n1<-rnorm(10000)
- n2<-abs(n1)*50
- n3<-matrix(n2,ncol = 100)
- n4<-round(rowMeans(n3))
- hist(n4%%7)
-
- # 使用 %>%
- set.seed(123)
- rnorm(10000) %>%
- abs %>% `*` (50) %>%
- matrix(ncol=100) %>%
- rowMeans %>% round %>%
- `%%`(7) %>% hist
3、%T>%(向左操作符,tee operator)
功能和 %>% 基本是一样的,只不过它是把左边的值做为传递的值,而不是当前步计算得到的值。
现实原理如下图所示,使用%T>%把左侧的程序的数据集A传递右侧程序的B函数,B函数的结果数据集不再向右侧传递,而是把B左侧的A数据集再次向右传递给C函数,最后完成数据计算。
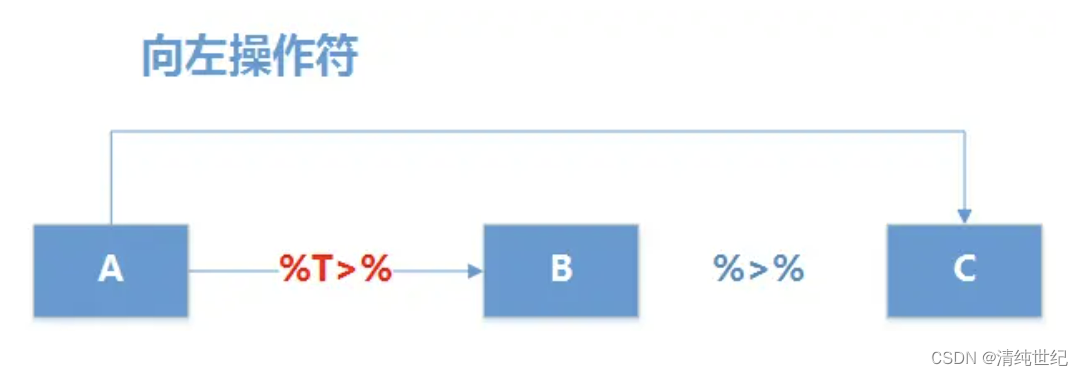
例子:
假设我们计算如下:
- library(magrittr)
-
- set.seed(123)
- rnorm(10000) %>%
- abs %>% `*` (50) %>%
- matrix(ncol=100) %>%
- rowMeans %>% round %>%
- `%%`(7) %>% hist %>% sum
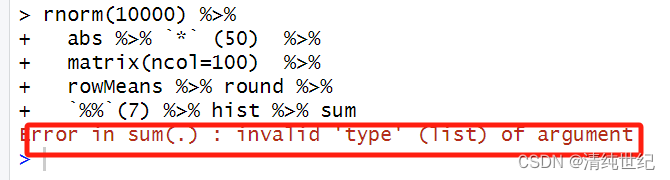
提示报错。这是由于输出直方图后,返回值为空,那么再继续使用管道,就会把空值向右进行传递,这样计算最后一步时就会出错。这时我们需求的是,把除以7的余数向右传递给最后一步求和。
使用%T>%改成如下:
- library(magrittr)
-
- set.seed(123)
- rnorm(10000) %>%
- abs %>% `*` (50) %>%
- matrix(ncol=100) %>%
- rowMeans %>% round %>%
- `%%`(7) %T>% hist %>% sum

计算出结果。
4、 %$% (解释操作符,exposition pipe-operator)
%$%的作用是把左侧数据的属性名传给右侧,让右侧的调用函数直接通过名字,就可以获取左侧的数据。比如,我们获得一个data.frame类型的数据集,通过使用 ,在右侧的函数中可以直接使用列名操作数据。
现实原理如下图所示,使用%$%把左侧的程序的数据集A传递右侧程序的B函数,同时传递数据集A的属性名,作为B函数的内部变量方便对A数据集进行处理,最后完成数据计算。

例子:
下面定义一个10行3列的data.frame,列名分别为x,y,z,获取x列大于5的数据集。使用 %$% 把列名x直接传到右侧进行判断。这里.代表左侧的完整数据对象。一行代码就实现了需求,而且这里不需要显示的定义中间变量。
- library(magrittr)
-
- set.seed(123)
- df<-data.frame(x=1:10,y=rnorm(10),z=letters[1:10])
- df[df$x>5,]
-
- # 使用%$%后
- set.seed(123)
- data.frame(x=1:10,y=rnorm(10),z=letters[1:10]) %$% .[x>5,]
5、%<>% (复合赋值操作符,compound assignment pipe-operator)
%<>%复合赋值操作符, 功能与 %>% 基本是一样的,多了一项额外的操作,就是把结果写回到最左侧的对象(覆盖原来的值)。比如,我们需要对一个数据集进行排序,那么需要获得排序的结果,用%<>%就是非常方便的。
现实原理如下图所示,使用%<>%把左侧的程序的数据集A传递右侧程序的B函数,B函数的结果数据集再向右侧传递给C函数,C函数结果的数据集再重新赋值给A,完成整个过程。

例子:
- library(magrittr)
-
- set.seed(123)
- x<-rnorm(10)
- x %>% abs %>% sort
- x # 取完绝对值,排完序之后的结果并没有直接写到x里面去
-
- # 使用%<>%
- set.seed(123)
- x<-rnorm(10)
- x %<>% abs %>% sort
- x # 但是如果使用%<>%操作符,你会发现取完绝对值,排完序之后的结果直接覆盖掉了原来的x。
6、符号:$
$符号用于提取数据框(data frame)或列表(list)中的成员。它允许访问数据框或列表中的某个列(成员),并返回该列的值。
例子:
- df <- data.frame(name = c("Alice", "Bob", "Charlie"),
- age = c(25, 30, 35))
-
- df$name
- df$age

注意:$符号只能用于数据框和列表类型的对象,不能用于向量和其他对象。
7、as.factor 或 factor函数作用
as.factor函数用于将一个变量转换为因子(factor)类型(强制转换),分组时用的较多。因子是R语言中用于表示分类变量的数据类型。当将一个变量转换为因子时,R会自动将变量的不同取值作为因子的水平(level),并将原始变量的值替换为对应水平的编码。可以使用as.factor()函数取代factor()函数。
例子:
- gender <- c("男", "女", "男", "男", "女")
-
- gender_factor <- as.factor(gender)
- gender_factor

这里返回结果包括以下两个。
- x向量,这是将转换为因子的向量。
- levels:原x向量内元素的可能值。
可以使用参数levels强制设定分类数据的顺序:
- gender <- c("男", "女", "男", "男", "女")
-
- gender_factor <- factor(gender, levels=c("女", "男"))
- gender_factor
如果有缺失的Levels值,也可以使用levels参数设置完整的Levels数据:
- gender <- c("男", "女", "男", "男", "女")
-
- gender_factor <- factor(gender, levels=c("女", "男", "中"))
- gender_factor
将因子水平进行修改:
- gender <- c("男", "女", "男", "男", "女")
-
- gender_factor <- factor(gender, levels=c("女", "男", "中"), labels = c("1","2","3"))
- gender_factor
注意:指定levels时,使用as.factor会报错。
8、aes 函数作用
aes函数是ggplot2包中的一个重要函数,用于创建美学映射(Aesthetic Mapping),即将数据的变量映射到图形的美学属性上。
aes函数的使用通常发生在ggplot()函数中的mapping参数中。它允许将数据的变量映射到图形的不同属性,如颜色、形状、大小、位置等。通过将美学属性与具体的数据列关联,可以创建丰富多样的图形效果,并在不同的图层中进行数据可视化。
- # 映射函数,函数的最常见参数有两个
- # x:x向量,将数据映射到本图层的x轴
- # y:y向量,将数据映射到本图层的y轴
- # …:其他向量,将数据映射到本图层的其他几何要素上
-
- library(ggplot2)
- aes(x, y, ...)
9、scale_colour_manual 函数作用
scale_colour_manual是ggplot2包中的一个函数,用于手动自定义颜色映射。它允许用户指定不同数据值对应的颜色,以及设置相应的标签和图例。
scale_colour_manual函数通常与ggplot函数中的aes函数和相关的图层函数(如geom_point、geom_line等)一起使用,用于自定义颜色映射。例如,使用以下代码可以创建一个散点图,并手动指定数据值1对应的颜色为红色,数据值2对应的颜色为蓝色。
- library(ggplot2)
-
- # 创建数据框
- df <- data.frame(x = c(1, 2, 1, 2), y = c(1, 2, 2, 1), group = c(1, 1, 2, 2))
-
- # 绘制散点图,并手动指定颜色映射
- ggplot(data = df, mapping = aes(x = x, y = y, color = factor(group))) +
- geom_point() + # 绘制散点图
- scale_color_manual(values = c("red", "blue"))
上述代码首先创建了一个数据框df,其中包含了三个变量x、y和group。然后使用ggplot函数创建一个散点图,并使用aes函数将x映射到x轴,y映射到y轴,group映射到颜色属性。最后,使用geom_point函数绘制散点图,并使用scale_color_manual函数手动指定颜色映射,将group为1的数据值映射为红色,group为2的数据值映射为蓝色。
通过调整scale_color_manual函数中的values参数,可以指定更多数据值对应的颜色。
10、scale_fill_manual 函数作用
scale_fill_manual是ggplot2包中的一个函数,用于手动自定义填充颜色的映射。它允许用户指定不同数据值对应的填充颜色,以及设置相应的标签和图例。
scale_fill_manual函数通常与ggplot函数中的aes函数和相关的图层函数(如geom_bar、geom_area等)一起使用,用于自定义填充颜色映射。例如,使用以下代码可以创建一个柱状图,并手动指定不同类别的填充颜色。
- library(ggplot2)
-
- # 创建数据框
- df <- data.frame(category = c("A", "B", "C", "D"),
- value = c(10, 15, 20, 25))
-
- # 创建柱状图,并手动指定填充颜色映射
- ggplot(data = df, mapping = aes(x = category, y = value, fill = category)) +
- geom_col() +
- scale_fill_manual(values = c("red", "blue", "green", "yellow"))
上述代码首先创建了一个数据框df,其中包含了两个变量category和value。然后使用ggplot函数创建一个柱状图,并使用aes函数将category映射到x轴,value映射到y轴,以及作为柱子的填充颜色。最后,使用geom_col函数绘制柱状图,并使用scale_fill_manual函数手动指定填充颜色映射,将不同的category类别映射为不同的颜色。
通过调整scale_fill_manual函数中的values参数,可以指定更多数据值对应的填充颜色。
11、stat_ellipse 函数作用
stat_ellipse是ggplot2包中的一个统计变换函数,用于在散点图上添加椭圆。它可以根据给定的数据点的均值和协方差矩阵,绘制出椭圆来表示数据的分布情况,提供了对数据集的可视化描述。
stat_ellipse函数通常与geom_point函数一起使用,用于在散点图上显示椭圆。例如,使用以下代码可以创建一个带有椭圆的散点图。
- library(ggplot2)
-
- # 创建数据框
- df <- data.frame(x = rnorm(100), y = rnorm(100))
-
- # 绘制散点图,并添加椭圆
- ggplot(data = df, mapping = aes(x = x, y = y)) +
- geom_point() +
- stat_ellipse()
上述代码首先创建了一个数据框df,其中包含了两个随机生成的变量x和y。然后使用ggplot函数创建一个散点图,并使用aes函数将x映射到x轴,y映射到y轴。最后,使用geom_point函数绘制散点图,并使用stat_ellipse函数添加椭圆。
stat_ellipse函数默认使用95%的置信区间绘制椭圆,即表示数据的大致范围。还可以通过调整参数来定制椭圆的样式,例如设置椭圆的颜色、填充、线条类型等。
完整例子:
- ## 设置种子
- set.seed(20240208)
-
- ## R包加载
- library(ggplot2)
-
- ## 数据构建(无意义)
- data1<-data.frame(x=rnorm(500,mean = 15,sd=10),
- y=rnorm(500,mean = 10,sd=10))
- data2<-data.frame(x=rnorm(500,mean = 20,sd=10),
- y=rnorm(500,mean = 15,sd=10))
- data<-rbind(data1,data2)
-
- ## kmeans聚类
- kmeans<-kmeans(data,2,nstart = 1000)
- data$cluster<-as.factor(kmeans$cluster)
-
- ## 绘图
- ggplot(data = data,aes(x=x,y=y,color=cluster))+
- geom_point(alpha=0.3)+
- stat_ellipse(aes(x=x,y=y,fill=cluster),geom = "polygon",level = 0.95,alpha=0.2)+
- scale_colour_manual(values = c("#00AFBB","#FC4E07"))+
- scale_fill_manual(values = c("#00AFBB","#FC4E07"))+
- theme_bw()->p1
- print(p1)
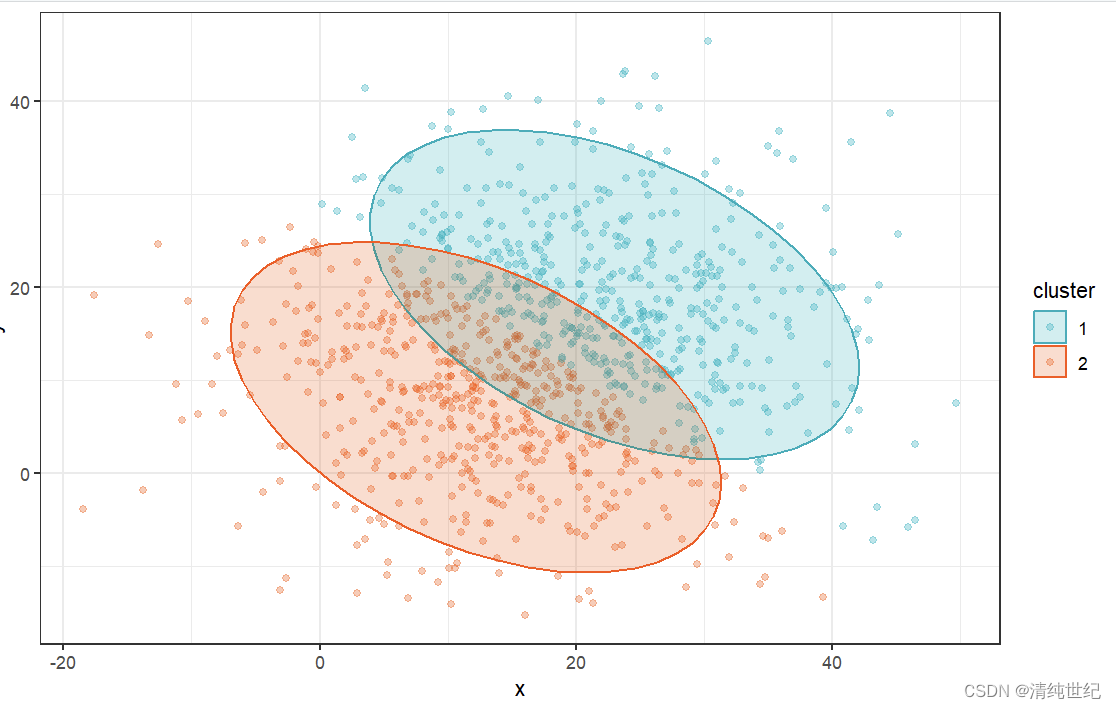
12、清理所有变量
rm(list=ls())13、查看R版本
R.version.string14、保存图片
PDF 格式:
- ggsave("example2.pdf", width = 4.0, height = 3.0)
- # ggsave("myggplot.png", width = 8, height = 8, unit = "cm", dpi = 300)
EPS 格式(需要多一个参数: device = cairo_ps),如果排版混乱取消宽高(但是这样是不是会导致小图字体混乱不清楚):
- ggsave("example2.eps", width = 4.0, height = 3.0, device = cairo_ps)
- # ggsave("example2.eps", p1, width = 4.0, height = 3.0, device = cairo_ps)
- # ggsave("example2.eps", device = cairo_ps)
如果效果不好,试一试(无指定宽高):
save_plot("example2.eps", p1, device = cairo_ps)输出SVG矢量文件(扩展包svglite):
- library(svglite)
- ggsave("myplot66.svg", width = 8, height = 8, units = "cm")
或者export:
- library(export)
- a=ggplot(mtcars,aes(mpg,disp))+geom_point(size=2)+facet_wrap(~gear+vs,scales = "free_y")
- graph2svg(a,"D:/Desktop/0000/012/m.svg")
15、指定更新包
devtools::install_version("ggforce", version = "0.4.1", repos = "http://cran.r-project.org")或者在github上发布的包历史版本安装:
- devtools::install_github("thomasp85/ggforce@v0.4.1")
- # devtools::install_github("用户名/仓库包名@v版本号")
- # 安装前打开包的主页,确定需要的版本号是存在的
-
- devtools::install_github("cardiomoon/webr") # 安装最新

