- 1局域网访问电脑中VMware虚拟机_“局域网访问电脑中vmware虚拟机”
- 2探究大语言模型(LLM):让ChatGPT火爆的背后_llm模型
- 3SanctuaryAI推出Phoenix: 专为工作而设计的人形通用机器人
- 4Java必备常见单词_java学习英语单词大全
- 5【六祎 - Framework】2023年;Gradle全局配置;Gradle两种配置;build.gradle & build.gradle.kts配置_build.gradle.kts和build.gradle
- 6聚类的评价指标NMI标准化互信息+python实现+sklearn调库
- 7cublasSgemmBatched使用说明
- 8Android EditText组件drawableLeft属性设置的图片和hint设置的文字之间的距离_android edittext drawableleft
- 9数据库基础(常见面试题)_with revoke option
- 10入门篇|学渣是如何自学数据结构的?
关于ARM架构和cortexM内核的知识总结_arm cortex
赞
踩
ARM究竟是什么
先了解下Acorn公司。
Acorn计算机公司创立于1978年,公司位于英格兰的剑桥。是著名的ARM公司的前身。1991年,Acorn计算机公司剥离了ARM部门,成立了ARM公司。
ARM公司是一家知识产权(IP)供应商,它与一般的半导体公司最大的不同就是不制造芯片且不向终端用户出售芯片,而是通过转让设计方案,由合作伙伴生产出各具特色的芯片。
ARM公司利用这种双赢的伙伴关系迅速成为了全球性RISC微处理器标准的缔造者。这种模式也给用户带来巨大的好处,因为用户只掌握一种ARM内核结构及其开发手段,就能够使用多家公司相同ARM内核的芯片。(更详细内容可自行查阅百度百科)
从上面我们知道,ARM是一家公司。
这家公司所设计的处理器内核架构我们称之为ARM架构。
ARM架构,曾称进阶精简指令集机器(Advanced RISC Machine)更早称作Acorn RISC Machine,是一个32位精简指令集(RISC)处理器架构。
所以,ARM也是ARM公司所设计的架构的一种称呼。
基于ARM架构设计的处理器我们通常称之为ARM处理器,通俗点,可以称为ARM芯片。
所以,ARM也可以是基于ARM架构的所有处理器的一种泛称。
ARM架构和内核版本
ARM架构发展至今分为 ARMv1~ARMv8几类,不同架构之间指令集存在差异。根据架构类型又开发出不同内核。具体见下表所示:
| 架构 | 位宽 | 内核 |
|---|---|---|
| ARMv1 | 32/26 | ARM1 |
| ARMv2 | 32/26 | ARM2、ARM3 |
| ARMv3 | 32 | ARM6, ARM7 |
| ARMv4 | 32 | ARM8 |
| ARMv4T | 32 | ARM7TDMI、ARM9TDMI |
| ARMv5 | 32 | ARM7EJ、ARM9E、ARM10E、XScale |
| ARMv6 | 32 | ARM11 |
| ARMv6-M | 32 | ARM Cortex-M0、ARM Cortex-M0+、ARM Cortex-M1 |
| ARMv7-M | 32 | ARM Cortex-M3 |
| ARMv7E-M | 32 | ARM Cortex-M4 |
| ARMv7-R | 32 | ARM Cortex-R4、ARM Cortex-R5、ARM Cortex-R7 |
| ARMv7-A | 32 | ARM Cortex-A5、ARM Cortex-A7、ARM Cortex-A8、ARM Cortex-A9、ARM Cortex-A12、ARM Cortex-A15、ARM Cortex-A17 |
| ARMv8-A | 64 | ARM Cortex-A53、ARM Cortex-A57、ARM Cortex-A72 |
ARM指令集
ARM采用的是32位架构
ARM 约定:
Byte :8 bits
Halfword :16 bits (2 byte)
Word : 32 bits (4 byte)
通常一款CPU只有一种指令集,但是大部分ARM core 提供:
ARM 指令集(32-bit)(之后出现的32位指令集,稳定)
Thumb 指令集(16-bit )(最先出现,16位指令集,省空间,但是不健全)
Thumb2指令集(16 & 32bit)(综合)
ARM指令集:ARM指令是32位的指令,编代码全部是 32bits 的,每条指令能承载更多的信息,因此使用最少的指令完成功能, 所以在相同频率下运行速度也是最快的, 但也因为每条指令是32bits 的而占用了最多的程序空间。
Thumb指令集:Thumb指令是16位的指令长度,编代码全部是 16bits 的,每条指令所能承载的信息少,因此它需要使用更多的指令才能完成功能, 因此运行速度慢, 但它也占用了最少的程序空间,但是Thumb指令集中的数据处理指令的操作数仍然是32位,指令地址也为32位,并且有些处理器可以根据指令译码器将Thumb指令转换为32位的ARM指令
Thumb-2指令集:Thumb-2指令集是16+32混合,在前面两者之间取了一个平衡, 兼有二者的优势, 当一个 操作可以使用一条 32bits指令完成时就使用 32bits 的指令, 加快运行速度, 而当一次操作只需要一条16bits 指令完成时就使用16bits 的指令,节约存储空间。
注:Cortex-M3中的指令是属于Thumb2指令集。
Cortex系列
ARM公司在经典处理器ARM11以后的产品改用Cortex命名,并分成A、R和M三类,旨在为各种不同的市场提供服务。
Cortex系列属于ARMv7架构,这是到2010年为止ARM公司最新的指令集架构。
ARMv7架构定义了三大分工明确的系列:
Cortex-A((Application Processors(应用处理器)))—面向性能密集型系统的应用处理器内核
Cortex-R(Real-time Processors (实时处理器))—面向实时应用的高性能内核
Cortex-M(Microcontroller Processors(微控制器处理器))—面向各类嵌入式应用的微控制器内核
由于应用领域不同,基于v7架构的Cortex处理器系列所采用的技术也不相同,基于v7A的称为Cortex-A系列,基于v7R的称为Cortex-R系列,基于v7M的称为Cortex-M系列。
Cortex-M
因为本人主要是从事STM32单片机开发,所以重点记录下CortexM内核的相关知识。
Microcontroller Processors(微控制器处理器)通常设计成面积很小和能效比很高。通常这些处理器的流水线很短,最高时钟频率很低(虽然市场上有此类的处理器可以运行在200Mhz之上)。 并且,新的Cortex-M处理器家族设计的非常容易使用。因此,ARM 微控制器处理器在单片机和深度嵌入式系统市场非常成功和受欢迎。
M系列应用:通用低端,工业,消费电子领域微控制器,偏向于控制方面,说白了就是一个高级的单片机。

STM32是基于Cortex-M3内核,使用的是v7架构,更准确的应该是说v7M架构。
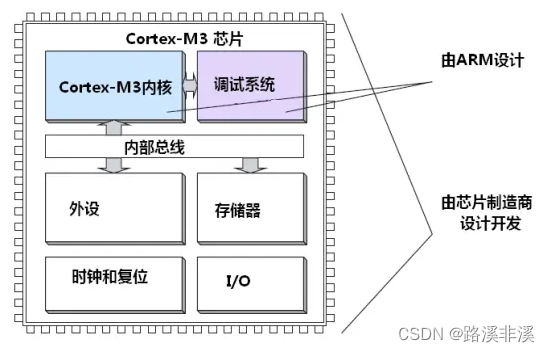
Cortex-M3
处理器内核
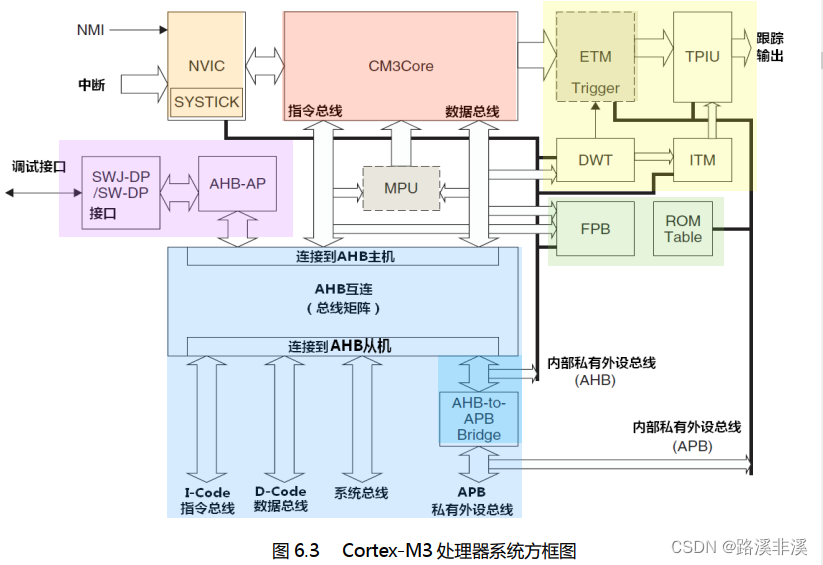
系统框图
CM3处理器里面除了处理核心外,还有好多其它组件,用于系统管理和调试支持。
注:虚线框住的MPU和ETM是可选组件,不一定会包含在每一个CM3的MCU中。
CM3Core:Cortex-M3处理器的中央处理核心
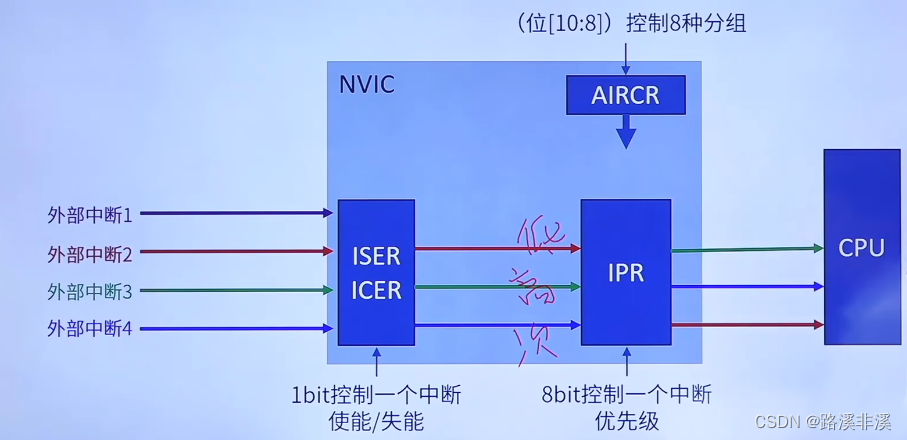
嵌套向量中断控制器NVIC:NVIC是一个在CM3中内建的中断控制器。中断的具体路数由芯片厂商定义。NVIC是和CPU紧耦合的,它还包含了若干个系统控制寄存器。因为NVIC支持中断嵌套,使得在CM3上处理嵌套中断时十分强大。NVIC还采用了向量中断(有一个中断向量表)的机制。在中断发生时,它会自动取出对应的服务例程入口地址,并且直接调用,无需软件判定中断源,为缩短中断延时做出非常重要的贡献。
存储器保护单元:MPU是一个选配的单元,有些CM3芯片可能没有配备该组件。如果有,则它可以把存储器分成一些regions,并分别予以保护。例如,它可以让某些regions在用户级下变成只读,从而阻止了一些用户程序破坏关键数据。
BusMatrix:BusMatrix是CM3内部总线系统的核心。它是一个AHB互联的网络,通过它可以让数据在不同的总线之间并行传送。BusMatrix还提供了附加的数据传送管理设施,包括一个写缓冲以及一个按位操作的逻辑(位带bit-band)
ABH to APB Bridge:它是一个总线桥,用于把若干个APB设备连接到CM3处理器的私有外设总线上(内部的和外部的) 。这些APB设备常见于调试组件。CM3还允许芯片厂商把附加的APB设备挂在这条APB总线上,并通过APB接入其外部私有外设总线。
SW-DP/SWJ-DP:串行线调试端口(SW-DP) /串口线 JTAG 调试端口(SWJ-DP)都与 AHB访问端口(AHB-AP)协同工作,以使外部调试器可以发起 AHB 上的数据传送,从而执行调试活动。在处理器核心的内部没有 JTAG 扫描链,大多数调试功能都是通过在 NVIC 控制下的 AHB 访问来实现的。 SWJ-DP支持串行线协议和 JTAG 协议,而SW-DP只支持串行线协议。
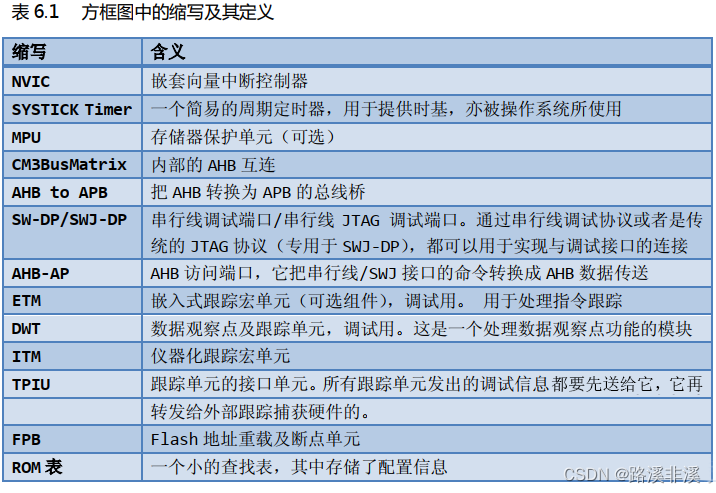
Cortex-M3的总线接口
I-Code总线
I-Code 总线是一条基于 AHB-Lite 总线协议的 32 位总线,负责在 0x0000_0000 – 0x1FFF_FFFF 之间的取指操作。取指以字的长度执行,即使是对于 16 位指令也如此。因此 CPU 内核可以一次取出两条 16 位 Thumb 指令。
D-Code总线
D-Code 总线也是一条基于 AHB-Lite 总线协议的 32 位总线,负责在 0x0000_0000—0x1FFF_FFFF之间的数据访问操作。尽管 CM3 支持非对齐访问,但你绝不会在该总线上看到任何非对齐的地址,这是因为处理器的总线接口会把非对齐的数据传送都转换成对齐的数据传送。因此,连接到 D-Code总线上的任何设备都只需支持 AHB-Lite 的对齐访问,不需要支持非对齐访问。
系统总线
系统总线也是一条基于 AHB-Lite 总线协议的 32 位总线,负责在 0x2000_0000 – 0xDFFF_FFFF 和0xE010_0000 – 0xFFFF_FFFF 之间的所有数据传送,取指和数据访问都算上。和 D-Code 总线一样,所有的数据传送都是对齐的。
外部私有外设总线
这是一条基于 APB 总线协议的 32 位总线。此总线来负责 0xE004_0000 – 0xE00F_FFFF 之间的私有外设访问。但是,由于此 APB 存储空间的一部分已经被 TPIU、 ETM 以及 ROM 表用掉了,就只留下了 0xE004_2000-E00F_F000 这个区间用于配接附加的(私有)外设。
调试访问端口总线
调试访问端口总线接口是一条基于“增强型 APB 规格”的 32 位总线,它专用于挂接调试接口,例如 SWJ-DP 和 SW-DP。(注:不要挪用此总线)
CM3有若干个总线接口,这里给出一个样板的连接实例
因为代码存储区既可以有指令总线访问(当从此区取指时),也可以被数据总线访问(当在此区访问数据时),所以需要在中间插入一个总线开关,称为“总线矩阵”;或者使用一个AHB总线复用器。当数据访问和取值同时尝试访问同一块区域时,可以赋予数据访问更高的优先级以提高性能。
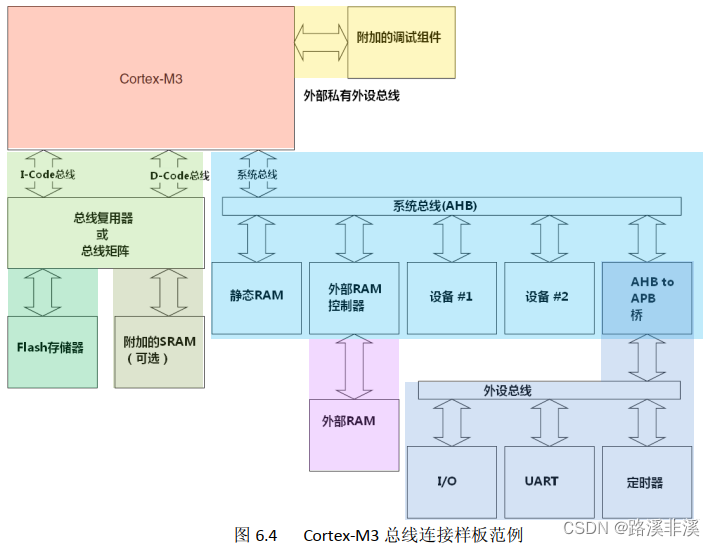
存储器映射
Cortex m3内核规定的存储器映射如下图所示。就好像ARM公司打造了一个柜子,从上到下有这几个抽屉,它规定了每个抽屉放的东西的种类,具体放什么放多少它不管(只要不超过抽屉的大小),由每个芯片厂商自己决定。
以下简单说明。
代码段:
1、从0x0000 0000的这块开始的是和系统启动方式有关的一块存储空间,根据启动方式的不同,作为flash或者系统存储区的别名。其实这块空间是预留的,不存数据,或者它压根不存在。在不同的启动方式下,这块区域会被映射到其他区域,具体见32的数据手册;
2、包含了Flash模块,用来存储代码,相当于电脑的硬盘,起始起止为0x0800 0000,终止地址依Flash大小而定,下图中0x0807 FFFF为512k的终止地址;
3、从0x1FFFF000 – 0x1FFF F7FF为系统存储器,是不可擦除的ROM区,存储ISP程序;
4、option bytes这个区域是16个字节,是控制flash区域的寄存器。
片上SRAM
相当于电脑的内存。
片上外设
放置了STM32F1的外设,包括GPIO、UART、ADC等所有外设的控制、状态、数据寄存器都在这个抽屉中。
片外RAM
我们可以自己扩展内存,但必须在STM32的FSMC控制器下进行,这个控制器的作用就是将内部AHB总线和外部扩展内存的总线进行转化,利用这个控制器,我们可以很方便的控制LCD,这里就不展开了。这1G的抽屉可以放下图的东西。这片空间STM32并没有放东西,STM2指定我们可以在其中扩展内存NOR/PSRAM1、NOR/PSRAM2……并接受FSMC控制器的控制。
片外外设
STM32F1放置了FSMC控制器的一些寄存器,就是在这些寄存器的配合下,FSMC控制器得以有效控制片外RAM进行读写操作。私有区域
M3的私有区域,放置的有比如NVIC寄存器、MPU寄存器、线上调试组件等等。这块区域地址是固定的,所有的芯片厂家都是一样的,因此至少在内核层面为应用程序的移植扫清了障碍。
完整映射如下所示:
注:ARM使用的是字节地址。
重点记录:
支持4GB存储空间;
仅对SRAM和外设区的前1M空间提供Bit-banding操作。
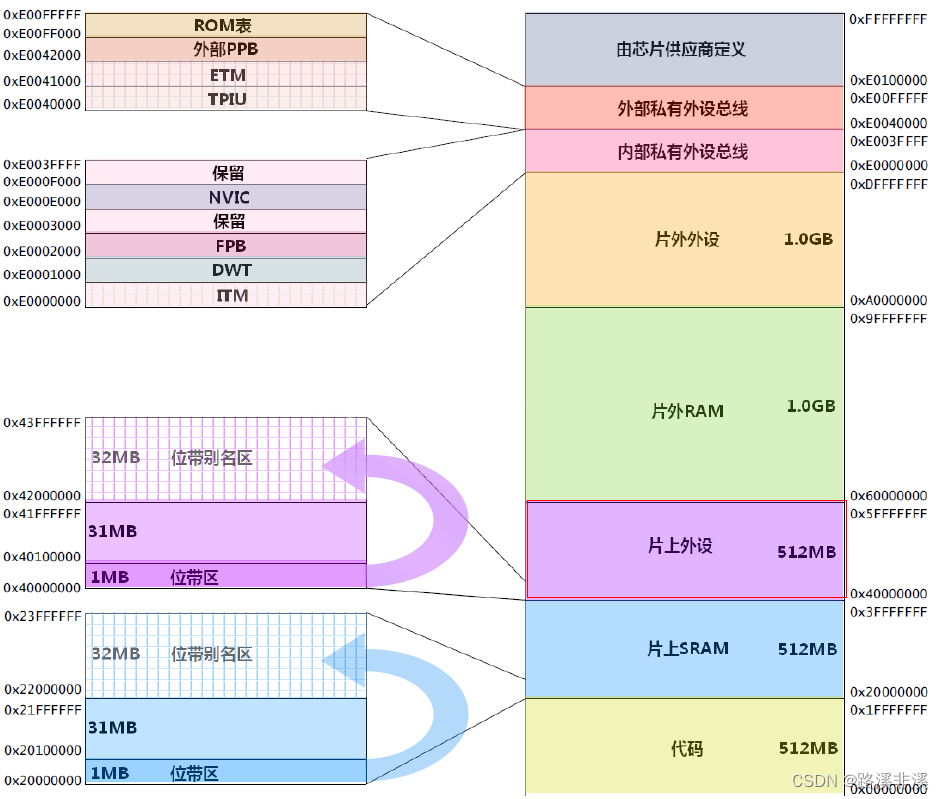

位带操作
概念其实30年前就有了,那还是8051单片机开创的先河。如今CortexM3 将此能力进化,这里的位带操作是8051位寻址区的威力大幅加强版。
位带操作就是指可以使用普通的加载/存储指令来对单一的比特(bit)来进行读写。打个比喻,就相当于是为位带区的每一位都起了一个别名,或者说是为位带区的每一位新建了一个快捷方式,通过对指定别名的访问来代替对指定位的访问。说明:指定位与别名之间的映射过程是由内核完成的,无需人工干预。
为了能使用普通指令来加载和存储,那么这个别名肯定得膨胀成32位(一个字),不过这个32位只有最低位(LSB)有效。所以这样就可以通过对别名的访问来代替对位带区指定位的访问了。
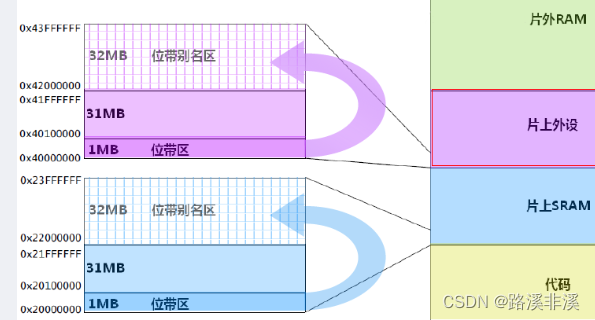
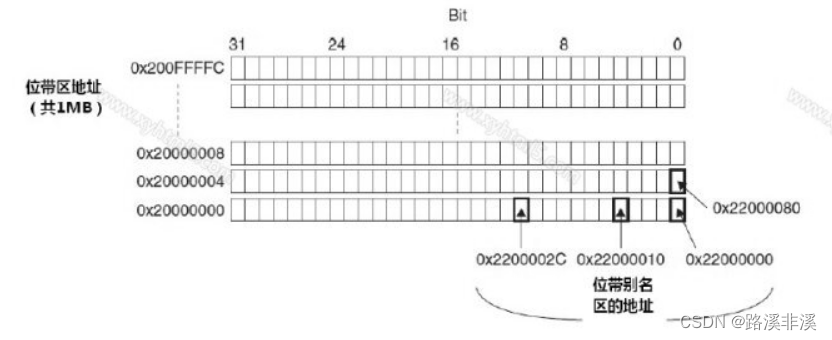
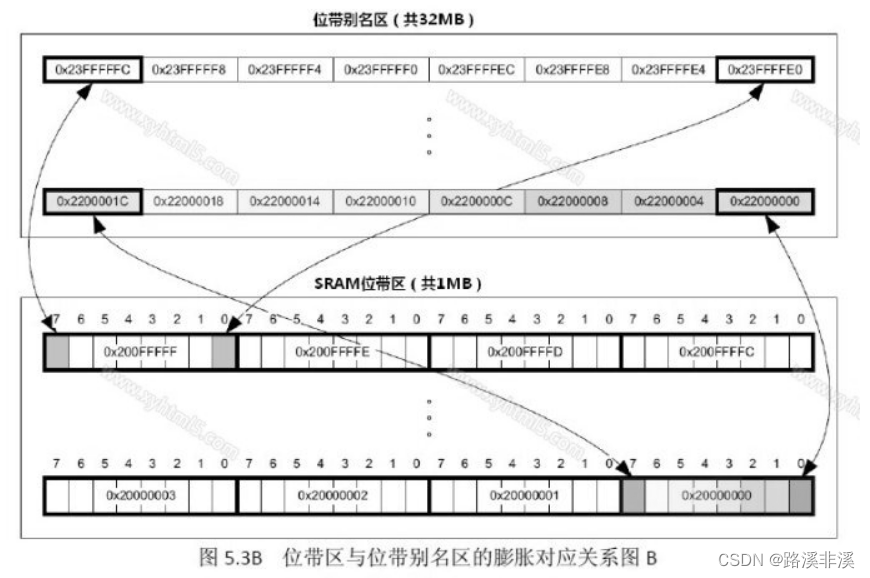
位带区:支持位带操作的地址范围,在cortexM3中有两个地区实现了位带操作,一个是SRAM的最低1MB范围,另一个是片内外设区的最低1MB范围。这两个区中的地址除了可以像普通的RAM 一样使用外,它们还都在“位带别名区”有自己的位带别名,位带别名区把每个比特膨胀成一个32 位的字。当你通过位带别名区访问这些字时,就可以达到访问原始比特的目的。
正因为位带区的1位会扩展成位带别名区对应的的32位,所以,位带别名区的大小是位带区的32倍。
对别名地址的访问最终会作用到位带区对应位,注意这个过程中有一个地址映射的过程。
位带区地址如下:
位带区和位带别名区的膨胀对应关系图如下:
注意图上标的都是地址,而不是地址里存的值。
对应关系有相应的计算公式:
注:以上部分内容来自CortexM3权威指南。
更多注意事项:
1、对位带别名区每个字的操作最终都会变换成对位带区对应比特位的操作;
2、访问位带别名区必须字对齐,否则会产生不可预料的结果;
3、对位带别名区的访问操作,将原有的“读-改-写”做成一个硬件级别支持的原子操作,不能被中断打断;
4、在C语言中,使用位带操作时,要访问的变量必须用volatile来定义,因为C编译器并没有直接支持位带操作。
5、超出位带支持地址范围的存储空间,不能使用位带操作。
6、位带操作是通过Cortex核内部的总线矩阵实现的,所以通过DMA访问SRAM不支持位带。

寄存器组
先了解下程序运行中涉及到的三个重要寄存器。
SP,堆栈指针
在随机存储器区划出一块区域作为堆栈区,数据可以一个个顺序地存入(压入)到这个区域之中,这个过程称为‘压栈’(push )。通常用一个指针(堆栈指针 SP---StackPointer)实现做一次调整,SP总指向最后一个压入堆栈的数据所在的数据单元(栈顶)。从堆栈中读取数据时,按照堆栈 指针指向的堆栈单元读取堆栈数据,这个过程叫做 ‘弹出’(pop ),每弹出一个数据,SP 即向相反方向做一次调整,如此就实现了后进先出的原则。这种形式的数据结构正好满足我们调用函数的方式:父函数调用子函数,父函数在前,子函数在后;返回时,子函数先返回,父函数后返回。
堆栈是计算机中广泛应用的技术,基于堆栈具有的数据进出LIFO特性,栈主要是用来存储局部变量、中间值、返回值等数据。
LR链接寄存器
LR为程序跳转时需要用到的寄存器,用来保存返回地址(同时也包含异常返回地址)。
程序经常会存在调用关系,当程序执行完子程序之后,肯定会返回到主程序,这是返回到主程序的地址就是在LR保存。
在一些CorteM系列的处理,LR的第0位会置1 表示,表示Thumb状态。
当然没有LR这个寄存器也可以的,直接将返回地址保存到栈中,最后执行完之后弹出到PC也行,但是寄存器的访问速度可以远高于栈(存储器SRAM),所以LR的作用还是很明显的。
注意:我之前一直以为链接地址是一个比较特殊的地址,其实就是链接到某个地方的地址,再直白点,就是某个语句的内存地址。链接寄存器就是用来存放返回地址的寄存器。
PC程序计数器
这个比较好理解,就是永远指向将要执行的语句地址。
小总结:函数是程序的基本单位,程序的执行,其实就是函数的不断调用。当一个父函数调用子函数,这三个寄存器会发生什么呢?PC会跟着程序位置走,跳转执行子函数之前,会先将返回地址(即执行完子程序后的那条指令)保存到LR寄存器中,至于堆栈,会根据先进后出,后进先出的原则进行,父子函数内的数据先依次入栈,然后返回时依次出栈即可,SP指针会一直移动,子函数执行结束,会根据LR内保存的返回地址返回到原来的地方继续执行父函数。这一过程对于中断来说也是类似的。
补充说明
PC永远是指向正在取指的指令(因为取指是执行指令的开始),读PC时,读出的是当前执行指令+4;写PC时会引发跳转操作。
将三级流水线当做整体来考虑的话,当前PC值,就是表示下一个要执行的指令地址。
PC和LR是有联系的。
之前,我一直以为LR存的所谓“返回地址”,就是哪里过去的,就回到哪里。
比如A处调用B,LR存的是A处的地址,其实不是的。
比如有三条指令
A
B,这是一个指令,指令的功能是跳转,即调用了子函数
C
执行A指令时,PC里存放的是B指令的地址,然后就执行B指令,因为B是一个跳转指令,为了能够在返回时,该指令能够继续执行C指令,所以需要将C指令的地址存在LR中,以便B指令执行结束后,继续返回C处执行;
由此可见,LR里存放的所谓返回地址,不是A处的地址,而是跳转指令的下一个指令地址,也就是上面C指令的地址。
再想一想,当执行B指令时,PC里存放的就是C指令的地址,所以当跳转到B时,只需要将当前的PC值存在LR里即可。
R14也称作子程序连接寄存器(Subroutine Link Register)或连接寄存器LR。当执行BL子程序调用指令时,R14中得到R15(程序计数器PC)的备份。
当通过BL或BLX指令调用子程序时,硬件自动将子程序返回地址保存在R14寄存器中。子程序返回时,把R14的值又复制到程序计数器PC,即可实现子程序返回。
另外,在异常处理时,LR不会存放当前PC的值,而是存放EXC_RETURN数值,具体可参考《ARM Cortex-M3 Cortex-M4 权威指南》第8章节“深入了解异常处理”。
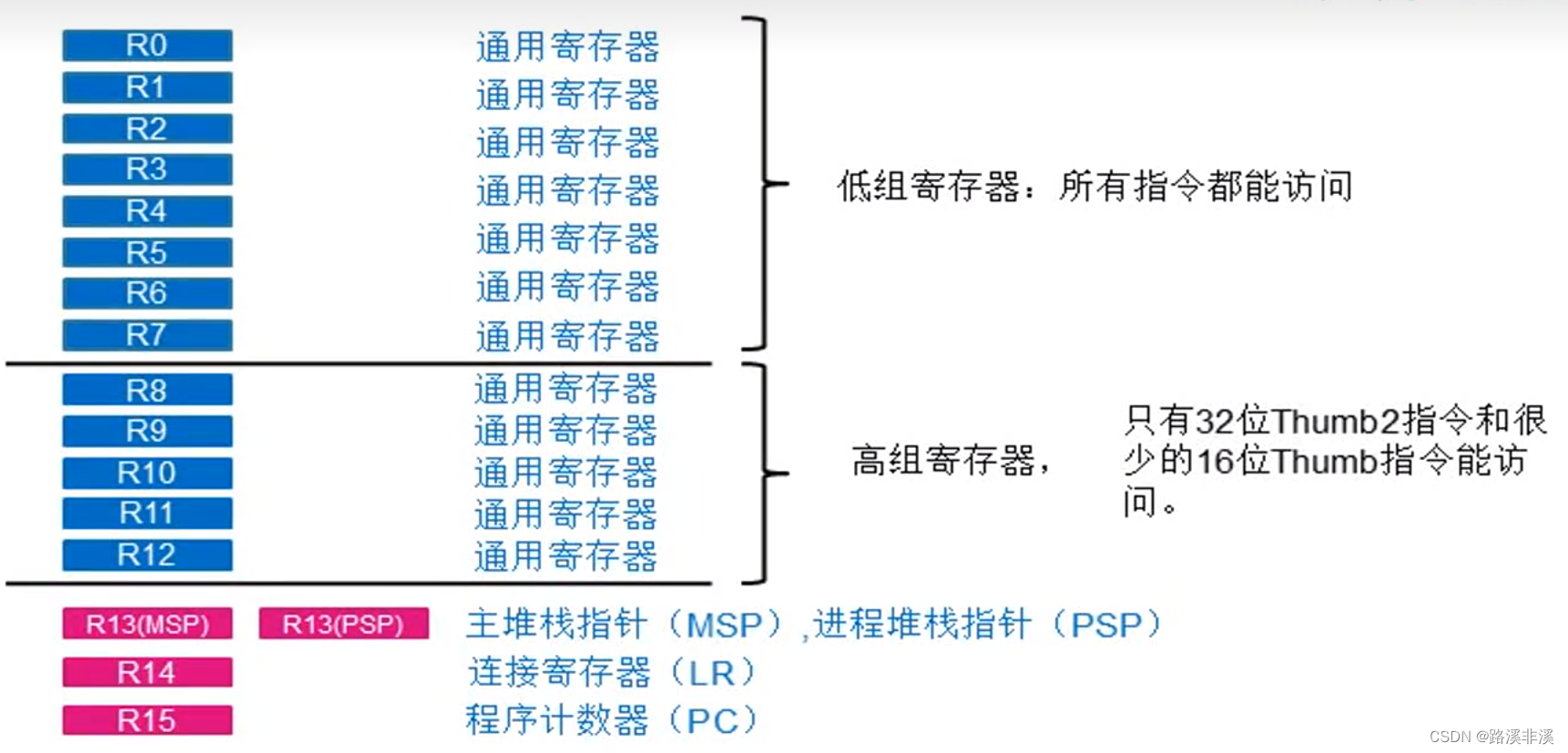
Cortex-M3内核中包含R0~R15共16个寄存器组,分为通用寄存器、堆栈寄存器、链接寄存器、程序寄存器。
R0-R12,通用寄存器;
R0-R12都是32位通用寄存器,用于数据操作;但是绝大多数16位Thumb指令只能访问R0-R7,而32位Thumb指令可以访问所有寄存器;R13,SP,堆栈指针;
堆栈是计算机存储数据的一种数据结构,SP的作用就是指示当前要出栈或入栈的数据,并在操作执行后自动递增或递减。ARM用的是满减栈。该区域通常由一块存储区和指向该存储区的指针SP构成。在堆栈中保存数据叫入栈,从堆栈中读取数据叫出栈。其实就是用来保存现场数据的,以便将来恢复现场。
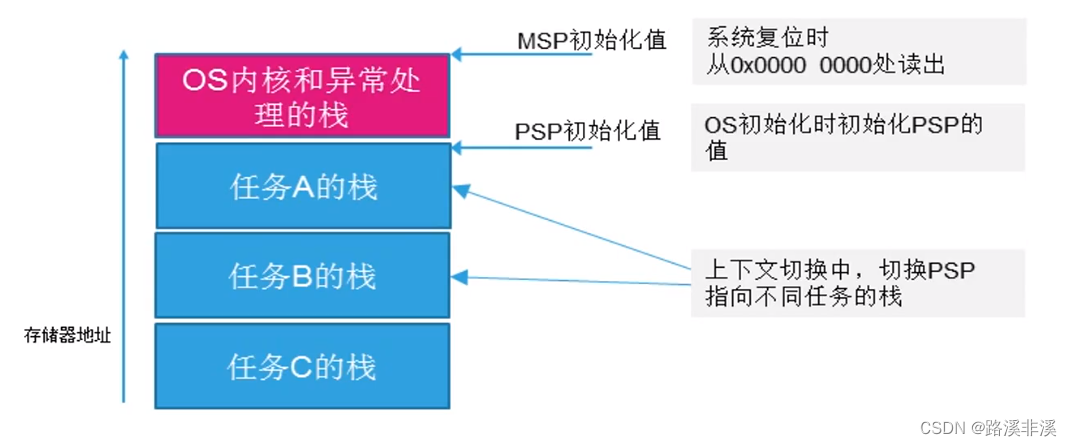
Cortex-M3有两个堆栈指针MSP和PSP,它们是Banked(Banked如何理解?有说是“注册银行指的是在同一个地址提供一个寄存器的多个副本。”),任一时刻只能使用其中一个;当引用R13/SP时,引用的是当前正在使用的那一个,另一个必须使用MRS/MSR指令来访问;
- 主堆栈指针MSP:复位后缺省堆栈指针,用于操作系统内核操作和异常处理例程;
- 进程堆栈指针PSP:由用户的应用程序代码使用;
堆栈指针的最低两位永远为0,这意味着堆栈总是4字节对齐的;
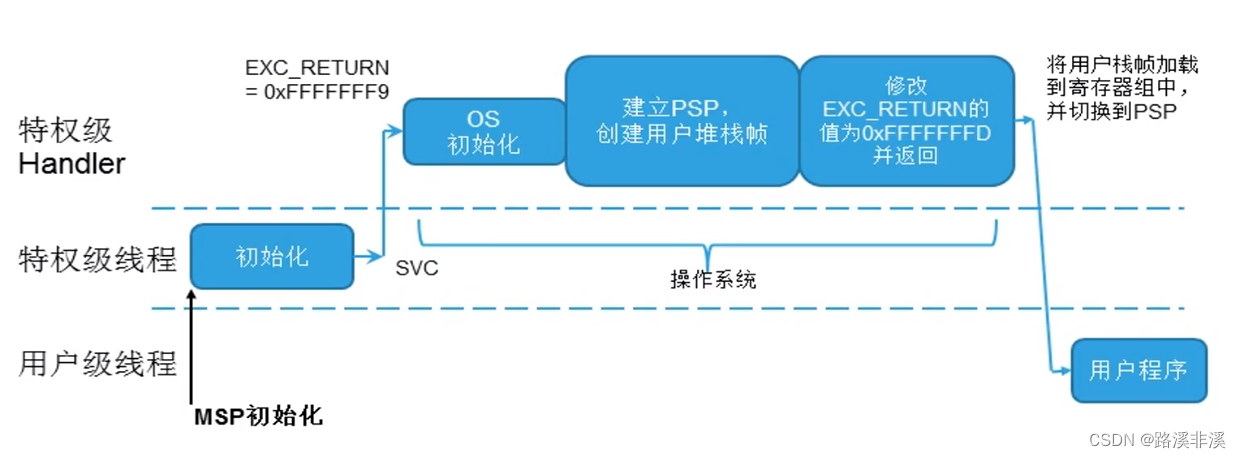
双堆栈指针的初始化:
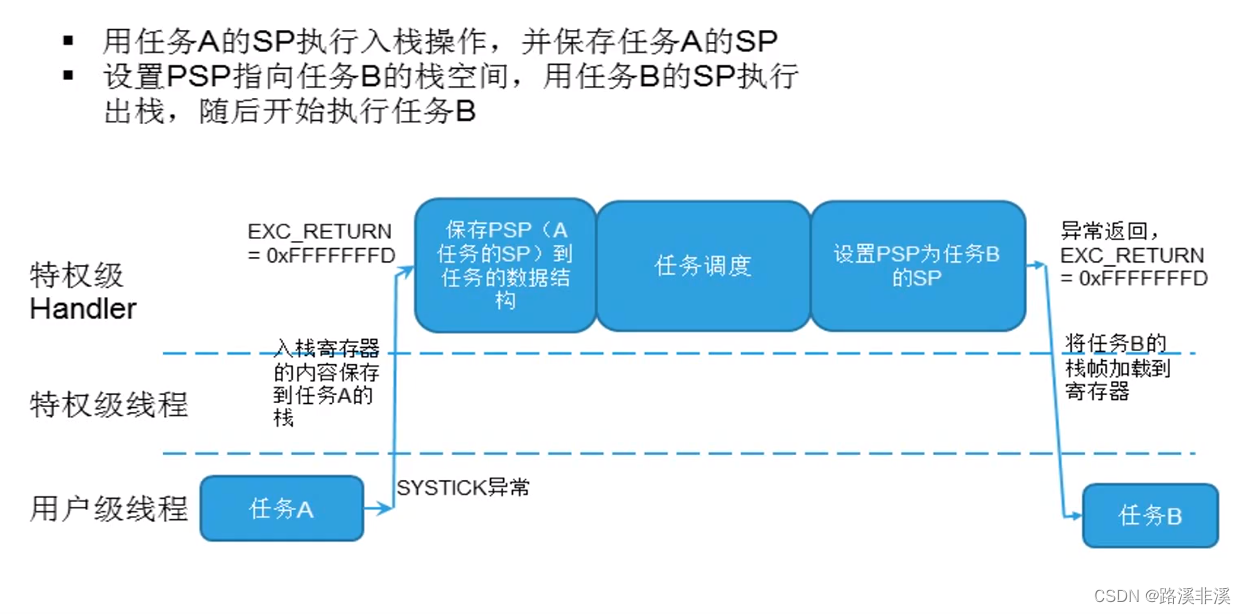
PSP在不同任务间切换:
R14,LR,链接寄存器;
当调用子程序时,由R14存储返回地址;如果子程序多于1级,则需要把前一级的R14压入堆栈;R15,PC,程序计数器寄存器
PC是程序计数器(program count),用来存储下一条将要执行的指令地址,PC指向哪里,CPU就会执行哪条指令,整个CPU中只有一个PC。注意:不是用来计数的。
读PC值,返回的是当前指令地址+4;如果修改它,就能改变程序的执行流;
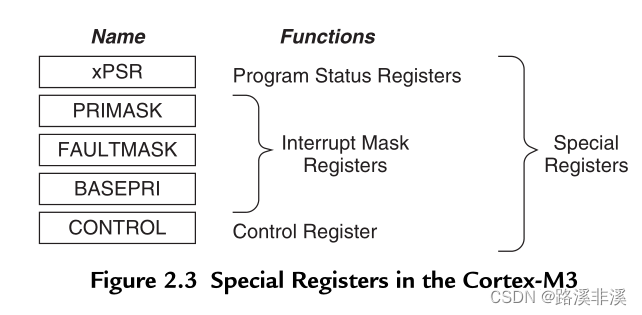
在分支时,无论直接写PC,还是使用分支指令,都必须保证加载到PC的数值是奇数(LSB=1),用以表明是在Thumb状态下执行,如果为0,将产生fault;除了以上几种寄存器,Cortex-M3在内核中还有一些特殊寄存器,包括:程序状态寄存器(PSRs)、中断屏蔽寄存器组(PRIMASK, FAULTMASK, BASEPRI)、控制寄存器(CONTROL)
这些特殊功能寄存器只能被特殊指令调用,在处理普通数据时不能使用。
他们的功能如下所示:
xPSR或PSRs 程序状态寄存器,给ALU(算数逻辑单元)提供标志位(0标志,进位标志、负数标志、溢出标志),执行标志、以及当前的中断服务号中断屏蔽寄存器
PRIMASK,这个寄存器只有一个位,置1后,将关闭所有可屏蔽中断的异常,只剩NMI和hardfault,默认值为0;
FAULTMASK,这个寄存器也只有一个位,置1后,屏蔽除NMI外的所有异常(包括硬fault),默认值为0;
BASEPRI,这个寄存器有9位,它定义了被屏蔽优先级的阈值;当它被设定为某个值后,所有优先级号大于等于此值得中断都被关闭,若设为0,则不关闭任何中断,默认值为0;
CONTROL,控制寄存器,定义特权模式的状态和选择堆栈指针
- CONTROL[0]:为0表示特权级的线程模式,为1表示用户级(非特权级)的线程模式;
- CONTROL[1]:为0表示选择MSP,为1表示选择PSP;

SP MSP PSP内容补充
Cortex-M3 的 双堆栈MSP和PSP_msp psp_薇远镖局的博客-CSDN博客
Cortex-M3 的 双堆栈MSP和PSP
重点内容:


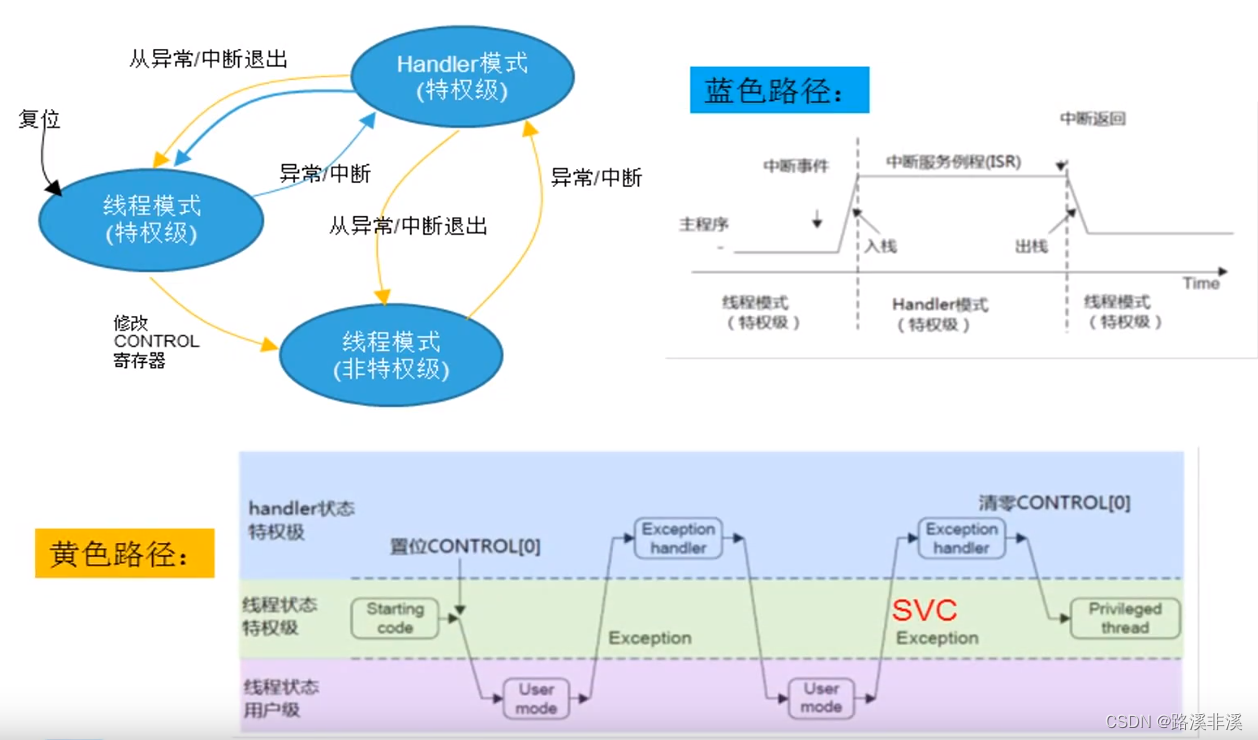
操作模式和特权级
Cortex-M3支持两种操作模式和两级特权级别。
两种操作模式为线程模式(Thread模式)和Handler模式,分别对应应用程序和异常/中断服务程序;
Cortex-M3通过特权级别的划分为特权级和非特权级,可以提供对存储器的保护,防止程序中的关键代码和重要数据被普通用户代码意外或者恶意地改变;
状态转换
SVC(System Service Call):系统服务调用异常
总结:
- 芯片复位后,进入线程模式特权级。
- 线程模式特权级与Handler模式特权级之间通过异常/中断的进出来切换。
- 在特权级下的代码可以通过置位CONTROL[0]来进入非特权级。
- Handler模式永远都是特权级的。不管是任何原因产生了任何异常,处理器都将以特权级来运行其服务例程,异常返回后,系统将回到产生异常时所处的级别。
- Handler模式通过异常/中断进入,退出即返回线程模式。从Handler模式异常返回时,也可以通过置位CONTROL[0](非特权级的线程模式)或清零CONTROL[0](特权级的线程模式)来改变返回线程模式的级别。
- 线程模式非特权级下的代码不能再试图修改CONTROL[0]来回到线程模式特权级。它必须通过一个异常进入到Handler模式,由那个异常Handler处理来修改,清零CONTROL[0]为线程模式特权级,才能在返回到线程模式后拿到特权级。

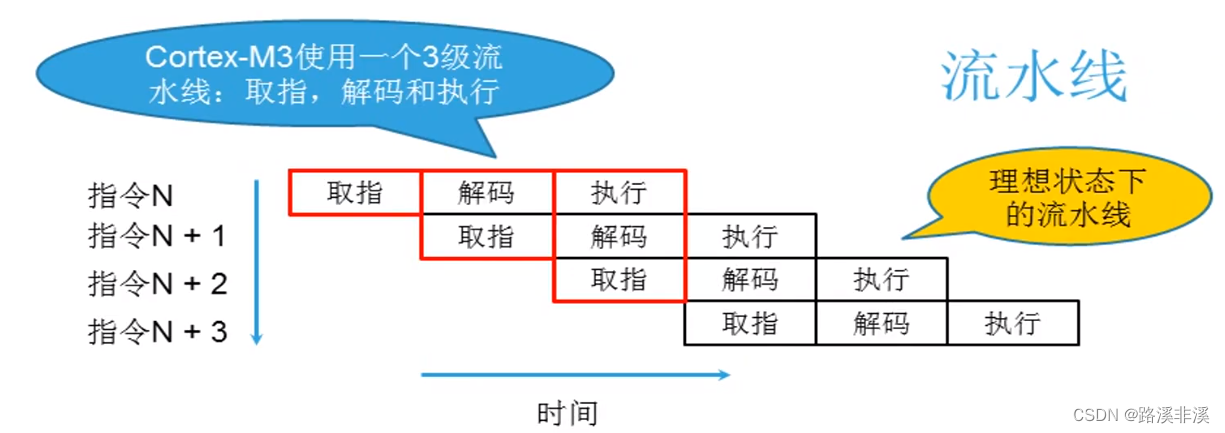
流水线
CortexM3采用三级流水线。
流水线的基本特征:
1、执行一条分支指令或者直接修改PC而发生跳转时,ARM内核有可能会清空流水线,而需要重新读取指令;
2、即使产生了一个中断,一条处于“执行”阶段的指令也将会完成,而流水线里其他指令将会被放弃,处理器将从向量表的适当入口开始填充流水线;
3、在处理器内核的预取单元中也有一个指令缓冲区,它允许后续的指令在执行前先在里面排队,也能在执行未对齐的32位指令时,避免流水线断流;
4、由于流水线的存在,以及出于对Thumb代码兼容的考虑,读取PC会返回当前指令地址+4的值;
当前指令地址指的是正在执行的代码的地址,而PC总是指向正在取值的指令的地址。
由于CPU是3级流水线的方式运行。在执行第一条指令的时候,已经对第二条指令译码,对第三条指令取值。
PC总是指向正在取值的指令。
由于在M3架构中,采用Thumb-2指令,Thumb-2指令是16位+32位指令并存的,加上出于对Thumb代码兼容的考虑,每个指令占据2个字节,所以PC总是返回PC+4。在ARM指令状态下,每条指令占据4字节,总是返回PC+8。
中断和异常
在ARM编程领域中,凡是打断程序顺序执行的事件,都被称为异常(exception),主要包括中断和其他需要服务的事件(比如错误异常和其他用于OS支持的系统异常)。
可见中断只是异常的一种。
编写处理异常的程序代码一般被称作异常处理。
程序代码也可以主动请求进入异常状态的(常用于系统调用)
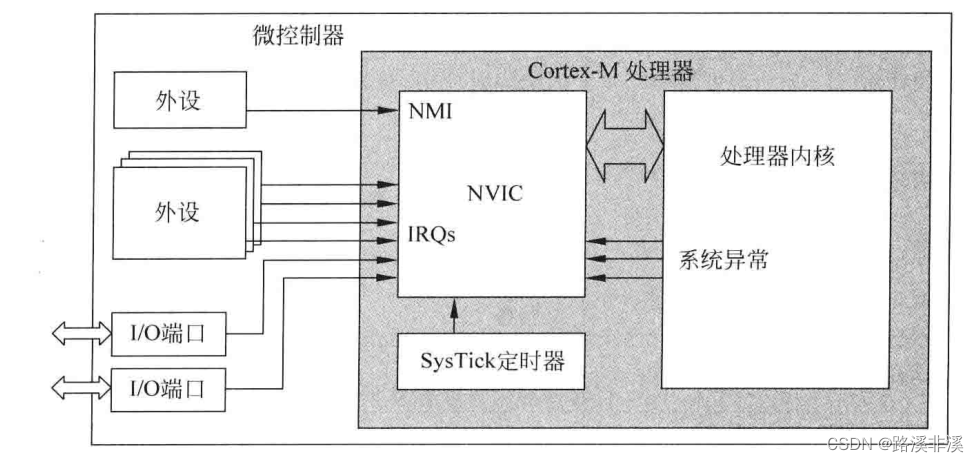
所有的 Cortex-M处理器都会提供一个用于中断处理的嵌套向量中断控制器(NVIC),用来接收和处理多个中断源产生的中断请求,如图所示:
Cortex-m3和 Cortex-m4的NVIC支持最多240个IRQ(Interuption Request中断请求,由外部触发,用于一般的外部中断处理)、1个不可屏蔽中断(NMI)、1个 SysTick(系统节拍)定时中断及多个系统异常。
多数IRQ由定时器、I/O端口和通信接口(如UART和IC)等外设产生;
NMI通常由看门狗定时器或掉电检测器等外设产生;
其余的异常则是来自处理器内核,中断还可以利用软件生成。
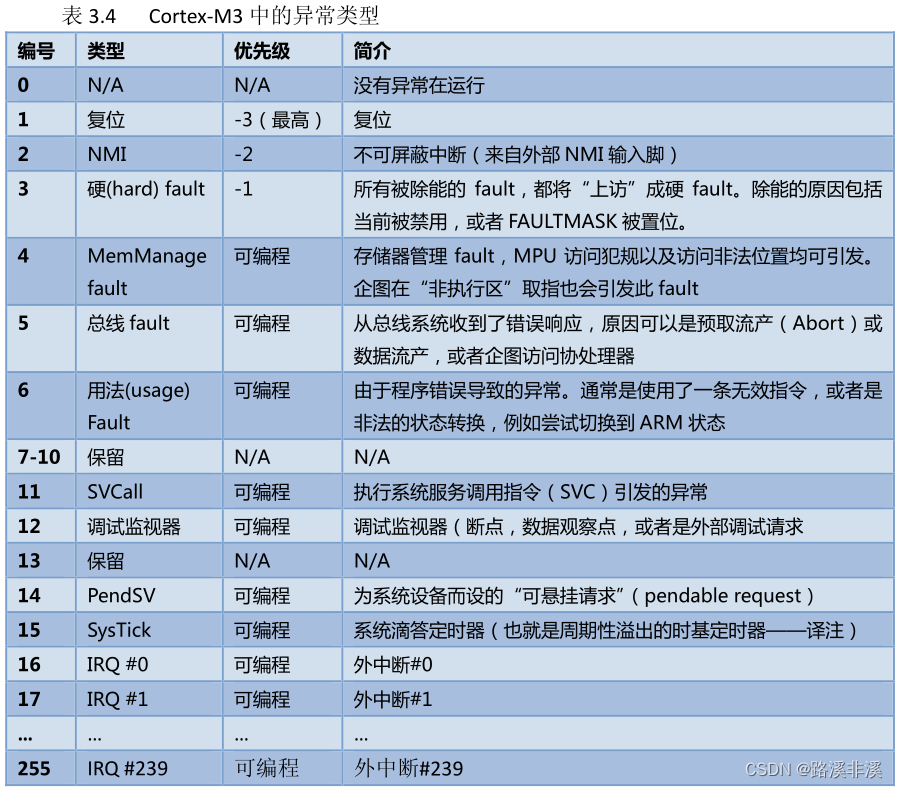
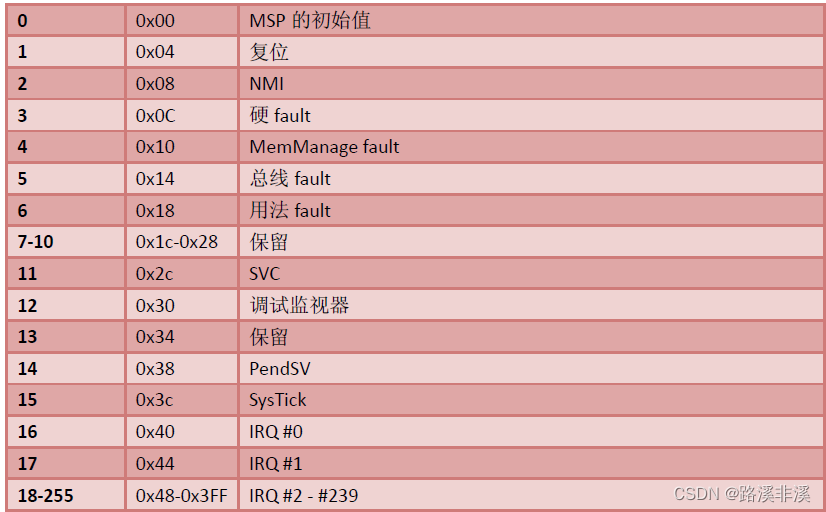
下表列出了 Cortex‐M3 可以支持的所有异常类型。
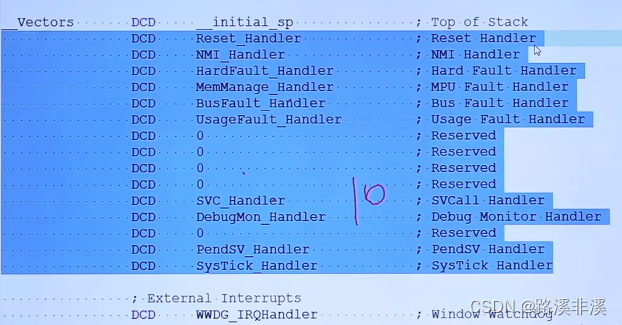
其中,编号0为无异常状态(CortexM3中定义),编号1~15的异常也在CortexM3中定义,属于系统异常;剩下的IRQ#0到IRQ#239共240个外部中断则由各芯片厂商定义。
除个别异常的优先级被定死外,其他异常的优先级都是可编程的。
芯片设计者可以修改CM3的硬件描述代码,所以做成芯片后,支持的中断源数目常常不到240个,并且优先级的位数也由芯片厂商最终决定。
以STM32F2为例,其支持10个系统异常和81个中断。
其中系统异常在startup_stm32f2xx.s中被定义;其他中断由stm32定义在stm32f2xx_it.c中。
系统异常说明
有若干个系统异常专用于fault处理。CM3中的Fault可分为以下几类:
- 硬fault
- 存储管理fault
- 总线fault
- 用法fault
SVC(系统服务调用,亦简称系统调用)和PendSV(可悬起系统调用),他们多用于在操作系统之上的软件开发中。
SVC用于产生系统函数的调用请求。操作系统不让用户程序直接访问硬件,而是通过提供一系列系统服务函数,用户程序使用SVC发出对系统服务函数的呼叫请求,以这种方法调用它们来简介访问硬件。因此,当用户程序想要控制特定的硬件时,它就会产生一个SVC异常,然后操作系统提供的SVC异常服务例程得到执行,它再调用相关的操作系统函数,后者完成用户程序请求的服务。SVC异常通过执行“SVC”指令来产生。该指令需要一个立即数,充当系统调用代号。SVC异常服务立场稍后会提取出此代号,从而解释本次调用的具体要求,再调用响应的服务函数。
PendSV:可悬起的系统调用,它和SVC协同使用。SVC异常是必须得到响应的(若因优先级不比当前正处理的高,或是其他原因使之无法立即响应,将上访成硬fault)。应用程序执行SVC时都是希望所需的请求立即得到响应。PendSV则不同,它是可以向普通的中断一样被悬起的,不想SVC那样会上访。OS可以利用它“缓期执行”一个异常————直到其他重要的任务完成后才执行动作。悬起PendSV的方法是:手工往NVIC的PendSV悬起寄存器中写1。悬起后,如果优先级不够高,则将缓期等待执行。
更详细内容参考:ARM Cortex-M3权威指南-基础(1) - zivlv - 博客园
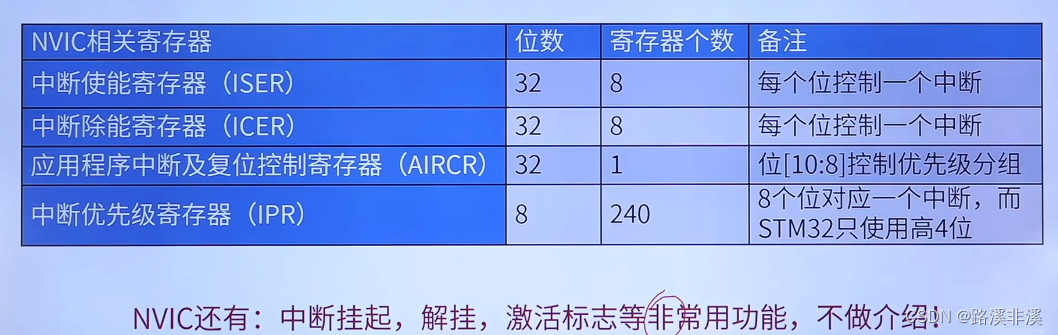
NVIC相关寄存器
其中,中断使能寄存器是用来控制240个外部中断的。
外部中断工作原理:
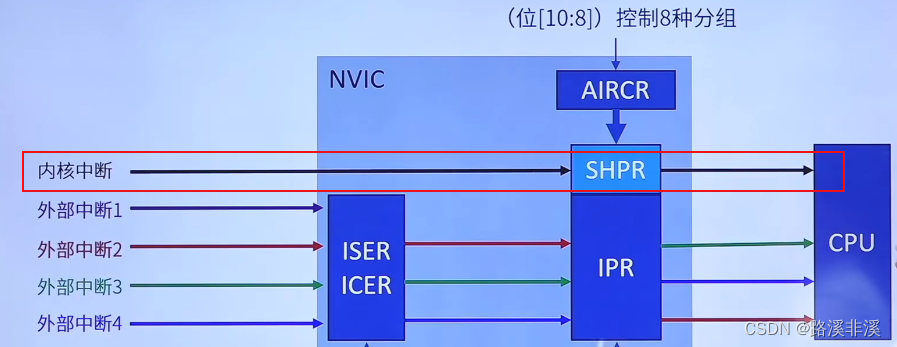
内核中断工作原理:
SHPR和IPR作用一样。
异常处理(中断向量表)
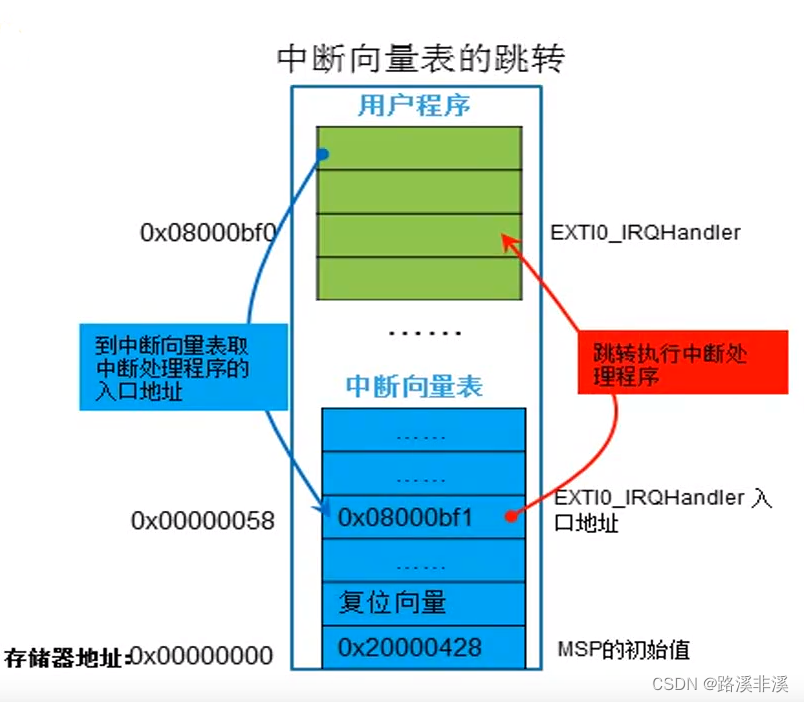
当CM3内核响应了一个发生的异常后,对应的异常服务例程(ESR)就会执行。为了决定ESR的入口地址,CM3使用了“向量表查表机制”。
向量表其实是一个WORD(32位整数)数组,每个下标对应一种异常,该下标对应的值则是该ESR的入口地址。
注:编号0所占的地址空间为:0x00到0x03,显然,占了4个字节,共32位。其他依次类推。
当用户程序运行过程中产生了中断,则会跳转到向量表的相应中断的入口处:
举个例子,如果发生了异常 11(SVC),则 NVIC 会计算出偏移移量是 11x4=0x2C,然后从那里取出服务例程的入口地址并跳入。
0 号异常的功能则是个另类,它并不是什么入口地址,而是给出了复位后 MSP 的初值。向量表在地址空间中的位置是可以设置的,通过NVIC中的一个重定位寄存器来指出向量表的地址。在复位后,默认该寄存器的值为0。因此,在地址0处必须包含一张向量表,用于初始时的异常分配。并且,向量表只能放在flash和RAM区。
注:中断向量表通常定义在程序的启动文件中,即xxx.s文件中。
DCD是四字节对齐指令。
当发生中断,CPU会自动地执行对应的中断服务函数。

中断响应
中断响应过程
中断返回过程
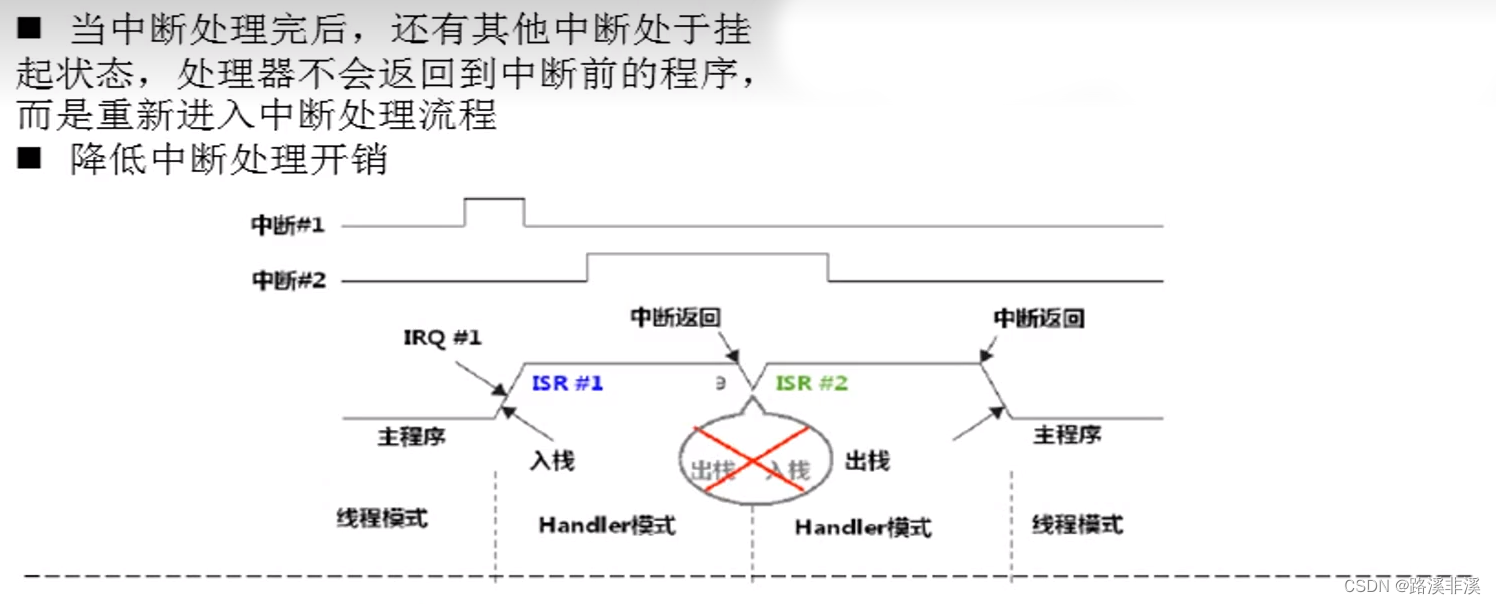
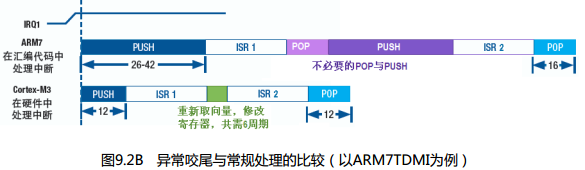
咬尾中断机制
当处理器在响应某异常时,如果又发生其它异常,但它们优先级不够高,则被阻塞——这个我们已经知道。那么在当前的异常执行返回后,系统处理悬起的异常时,倘若还是先POP然后又把POP出来的内容PUSH回去,这不是白白浪费CPU时间吗。为了改进这种铺张浪费行为,引入了咬尾中断机制。会省去前一个中断的出栈和后一个中断的入栈操作,直接到中断向量表中去取下一个中断服务程序的地址,所以整个过程只有一次入栈和出栈操作。
ISR,Interrupt Service Routines(中断服务程序)
晚到中断机制
CM3的中断处理还有另一个机制,它强调了优先级的作用,这就是“晚到的异常处理”。当CM3对某异常的响应序列还处在早期:入栈的阶段,尚未执行其服务例程时,如果此时收到了高优先级异常的请求,则本次入栈就成了为高优先级中断所做的入栈。可见,它虽然来晚了,却还是因优先级高而受到偏袒,低优先级的异常为它“火中取栗”。
前提是在执行低优先级中断的第一条指令之前,否则按照正常的流程处理。


优先级的定义
优先级的数值越小,则优先级越高。
CM3支持中断嵌套,使得高优先级异常会抢占低优先级异常。
有3个系统异常:复位、NMI、硬fault,他们有固定的优先级,并且他们的优先级是负数,从而高于所有其他异常。
所有其他异常的优先级都是可编程的,但不能编程为负数。
CM3支持多达256级的可编程优先级,并且支持128级抢占。但是绝大多数CM3芯片都会精简设计,以致实际上支持的优先级会更少,如8级、16级、32级。它们在设计时会裁掉表达优先级的几个低端有效位。(优先级号是以MSB对齐的)
举例来说,如果只使用了3个位来表达优先级,则优先级配置寄存器的结构会如下图所示:
CM3允许的最少使用位数为3位,即最少需要支持8级优先级。
通过让优先级以MSB对齐,可以简化程序的跨器件移植。比如,如果一个程序早先在支持4位优先级的器件上运行,在移植到只支持3位优先级的器件后,其功能不受影响。但是若对齐到LSB,则会使MSB丢失,导致数值大于7的低优先级一下子升高了。
CM3还把256级优先级分成高低两段,分别是抢占优先级和亚优先级。
NVIC中有一个寄存器是”应用程序中断及复位控制寄存器“(AIRCR),它里面有一个位段名为”优先级组“。把优先级分为两个位段:左边的对应抢占优先级,右边的对应亚优先级。如下:
抢占优先级决定了抢占行为:当系统正在响应某异常L时,如果来了抢占优先级更高的异常H,则H可以抢占L。亚优先级则处理”内务“:当抢占优先级相同的异常有不止一个悬起时,就优先响应亚优先级最高的异常。
这种优先级分组还规定:亚优先级至少是1个位。因此抢占优先级最多是7个位,也就造成了最多只有128级抢占的现象。
注:同一个程序中,只能有一种优先级分组。

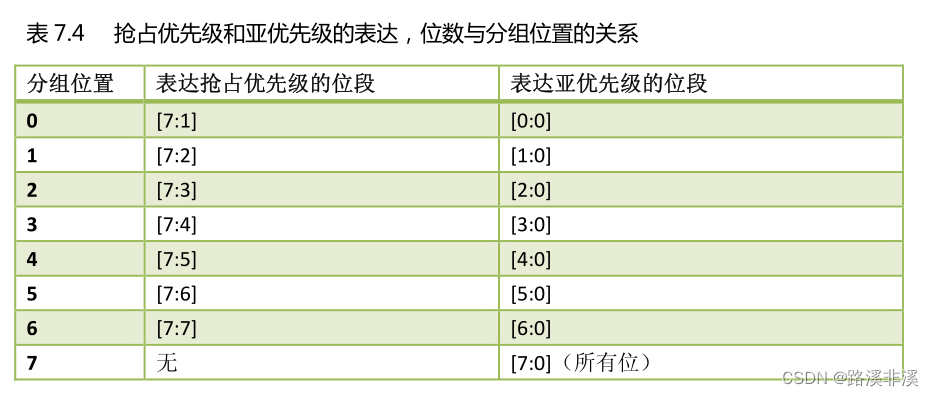
Systick定时器
先直接参考:
【STM32】Systick滴答定时器_一只大喵咪1201的博客-CSDN博客
Systick定时器,是一个简单的定时器,对于CM3、CM4内核芯片,都有Systick定时器。Systick定时器常用来做延时,或者实时系统的心跳时钟。这样可以节省MCU资源,不用浪费一个定时器。
Systic定时器也叫做滴答定时器,是一个24 位的倒计数定时器,计到0时,将从RELOAD 寄存器中自动重装载定时初值。只要不把它在SysTick 控制及状态寄存器中的使能位清除,就永不停息,即使在睡眠模式下也能工作。
如果想熟悉框图,可直接参考:嵌入式学习笔记——SysTick(系统滴答)_systick寄存器_小向是个Der的博客-CSDN博客SysTick定时器被捆绑在NVIC中,用于产生SYSTICK异常(异常号:15),被操作系统所调用(当上了操作系统时,其他应用程序则不能再使用该滴答时钟来延时)。
大多操作系统需要一个硬件定时器来产生操作系统需要的滴答中断,作为整个系统的时基,提供定时器、任务切换等作用。
CM3芯片内部都带有一个定时器,软件在不同CM3器件间移植工作得以简化。该定时器的时钟源可以是内部时钟(FCLK,CM3的自由时钟)、或者外部时钟(CM3处理器的STCLK信号)
校准值寄存器提供了这样一个解决方案:TENMS值为芯片产生10ms中断的默认值。最简单的作法就是:直接把TENMS的值写入重装载寄存器,这样一来,就能做到每10ms来一次 SysTick异常。如果需要其它的SysTick异常周期,则可以根据TENMS的值加以比例计算。
补充:
这是一个24位的系统节拍定时器system tick timer,SysTick,具有自动重载和溢出中断功能,所有基于Cortex_M3处理器的微控制器都可以由这个定时器获得一定的时间间隔。
作用:
在单任务引用程序中,因为其架构就决定了它执行任务的串行性,这就引出一个问题:当某个任务出现问题时,就会牵连到后续的任务,进而导致整个系统崩溃。要解决这个问题,可以使用实时操作系统(RTOS)
因为RTOS以并行的架构处理任务,单一任务的崩溃并不会牵连到整个系统。这样用户出于可靠性的考虑可能就会基于RTOS来设计自己的应用程序。这样SYSTICK存在的意义就是提供必要的时钟节拍,为RTOS的任务调度提供一个有节奏的“心跳”。
微控制器的定时器资源一般比较丰富,比如STM32存在8个定时器,为啥还要再提供一个SYSTICK?原因就是所有基于ARM Cortex_M3内核的控制器都带有SysTick定时器,这样就方便了程序在不同的器件之间的移植。而使用RTOS的第一项工作往往就是将其移植到开发人员的硬件平台上,由于SYSTICK的存在无疑降低了移植的难度。
SysTick定时器除了能服务于操作系统之外,还能用于其它目的:如作为一个闹铃,用于测量时间等。
要注意的是,当处理器在调试期间被喊停(halt)时,则SysTick定时器亦将暂停运作。
补充:
FCLK,Cortex自由运行时钟
直接送给Cortex的自由运行时钟(freerunningclock)FCLK。
FCLK为处理器的自由振荡的处理器时钟,用来采样中断和为调试模块计时。在处理器休眠时,通过FCLK保证可以采样到中断和跟踪休眠事件。Cortex-M3内核的“自由运行时钟(freerunningclock)”FCLK。“自由”表现在它不来自系统时钟HCLK,因此在系统时钟停止时FCLK也继续运行。FCLK和HCLK互相同步。FCLK是一个自由振荡的HCLK。FCLK和HCLK应该互相平衡,保证进入Cortex-M3时的延迟相同。
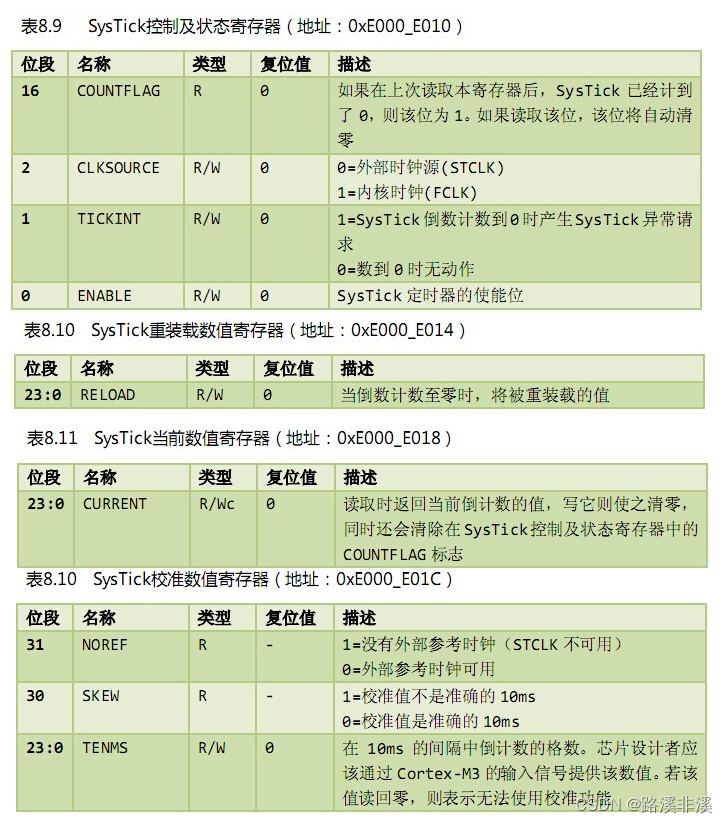
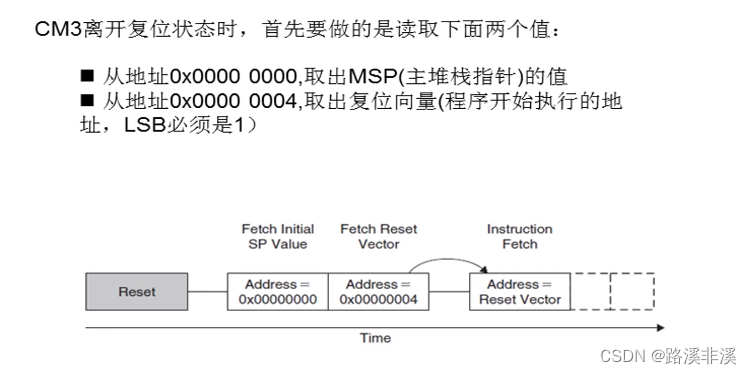
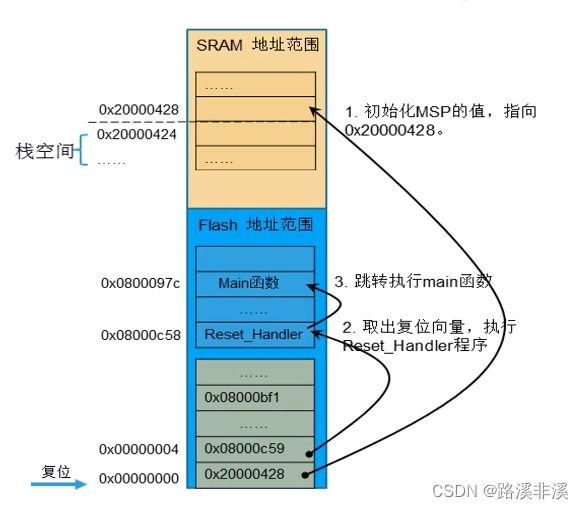
复位时程序的执行步骤
取出复位向量,就是指执行复位程序。
需要说明的是,必须保证加载到PC的值是奇数,也就是说最低位必须为1,用以表明当前指令在Thumb-2状态下执行。如果写了0,则会产生一个fault异常。
更直观的示意图如下:
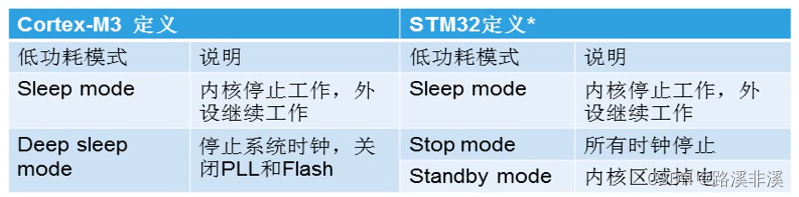
低功耗模式
CortexM3定义了两种低功耗模式。
STM32在此基础上分为3种低功耗模式。
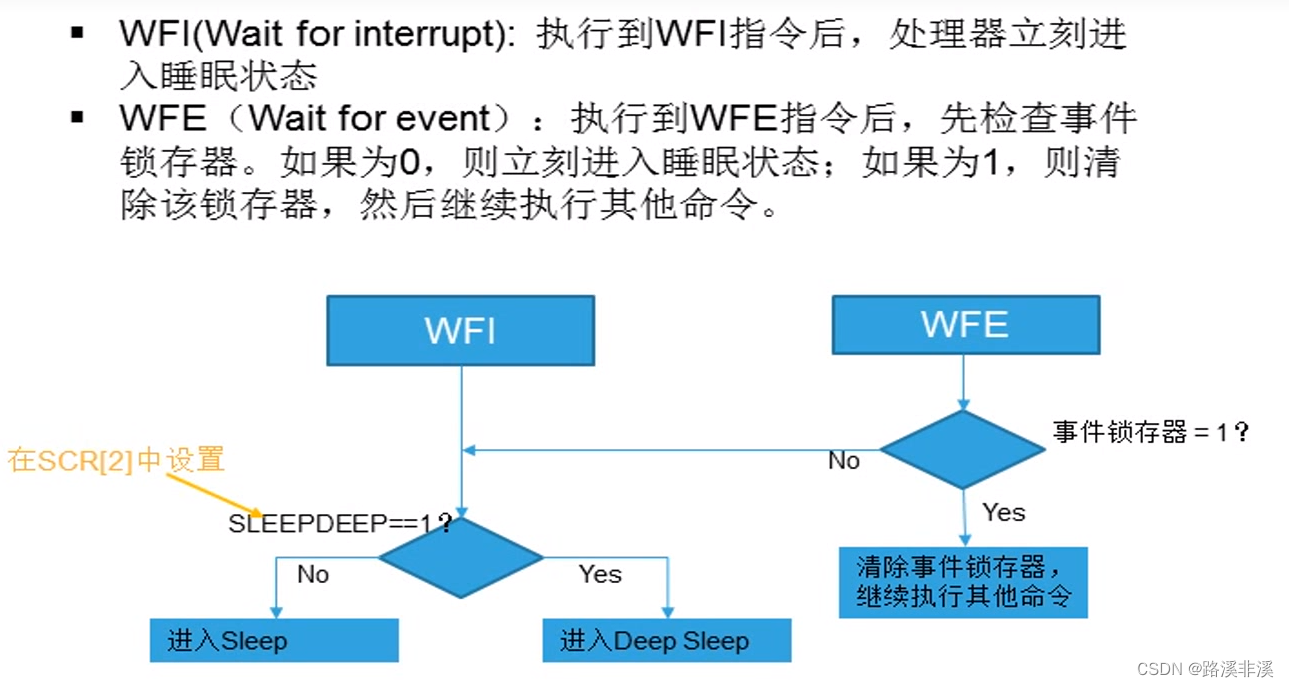
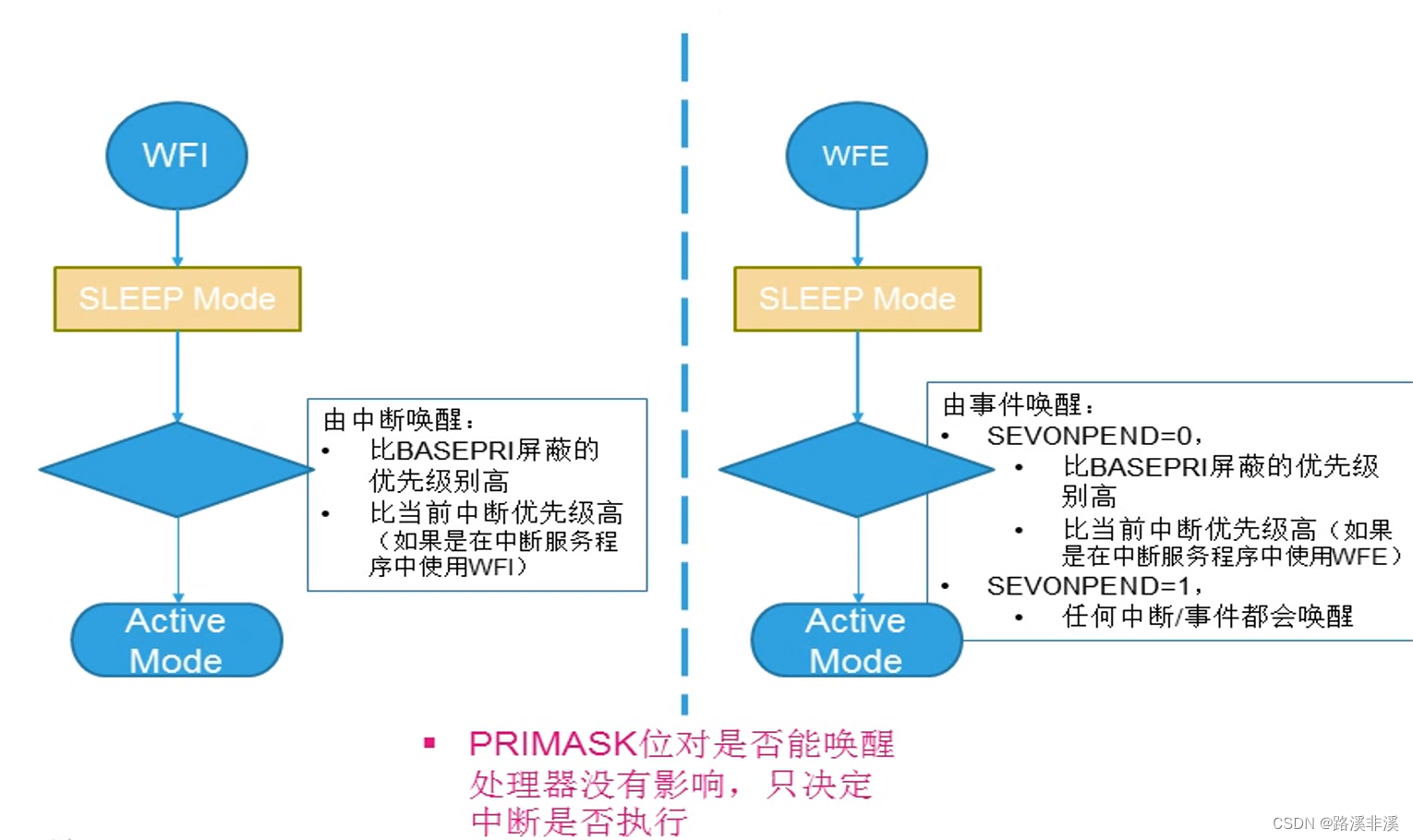
两种进入模式
退出方式
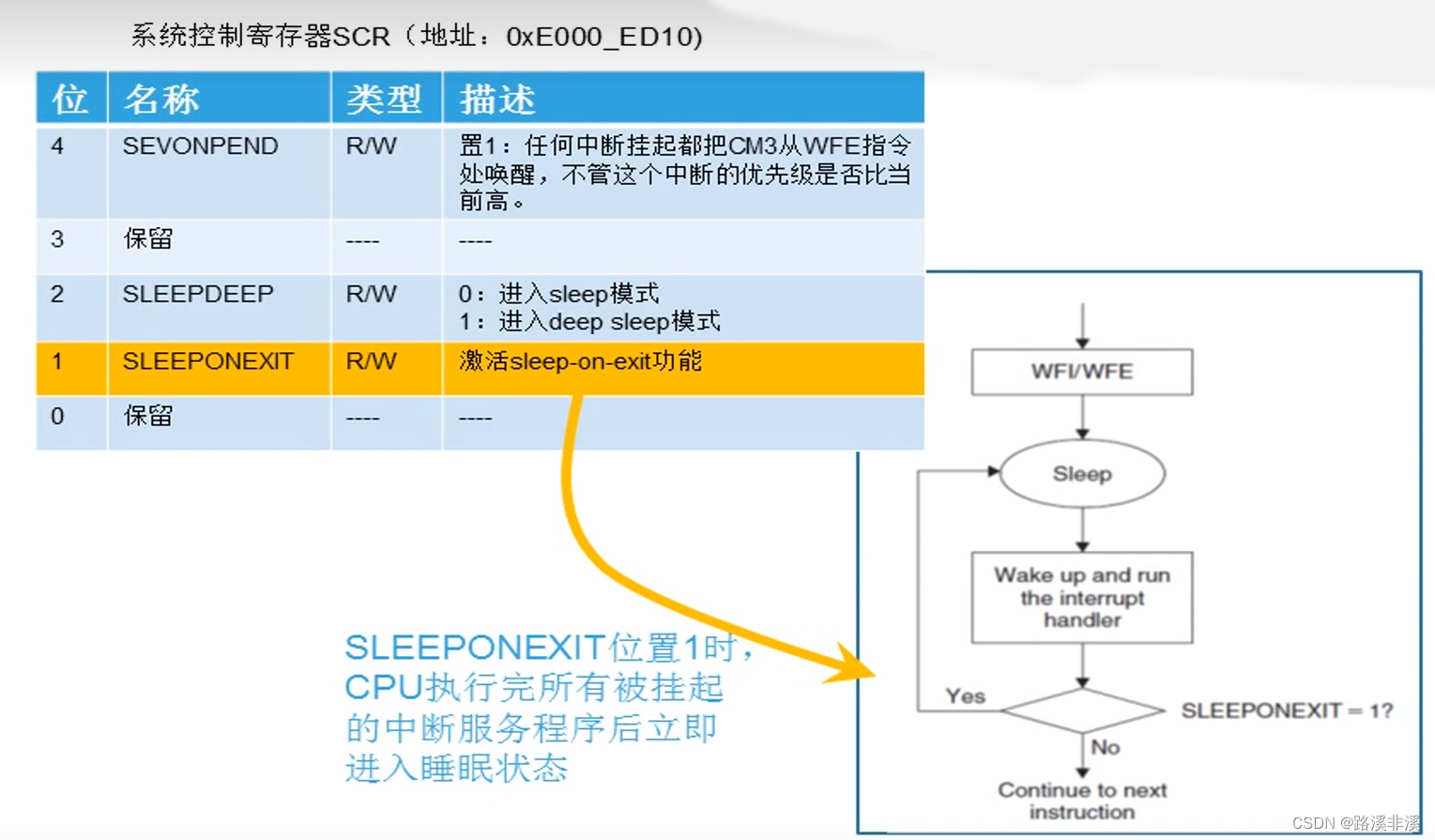
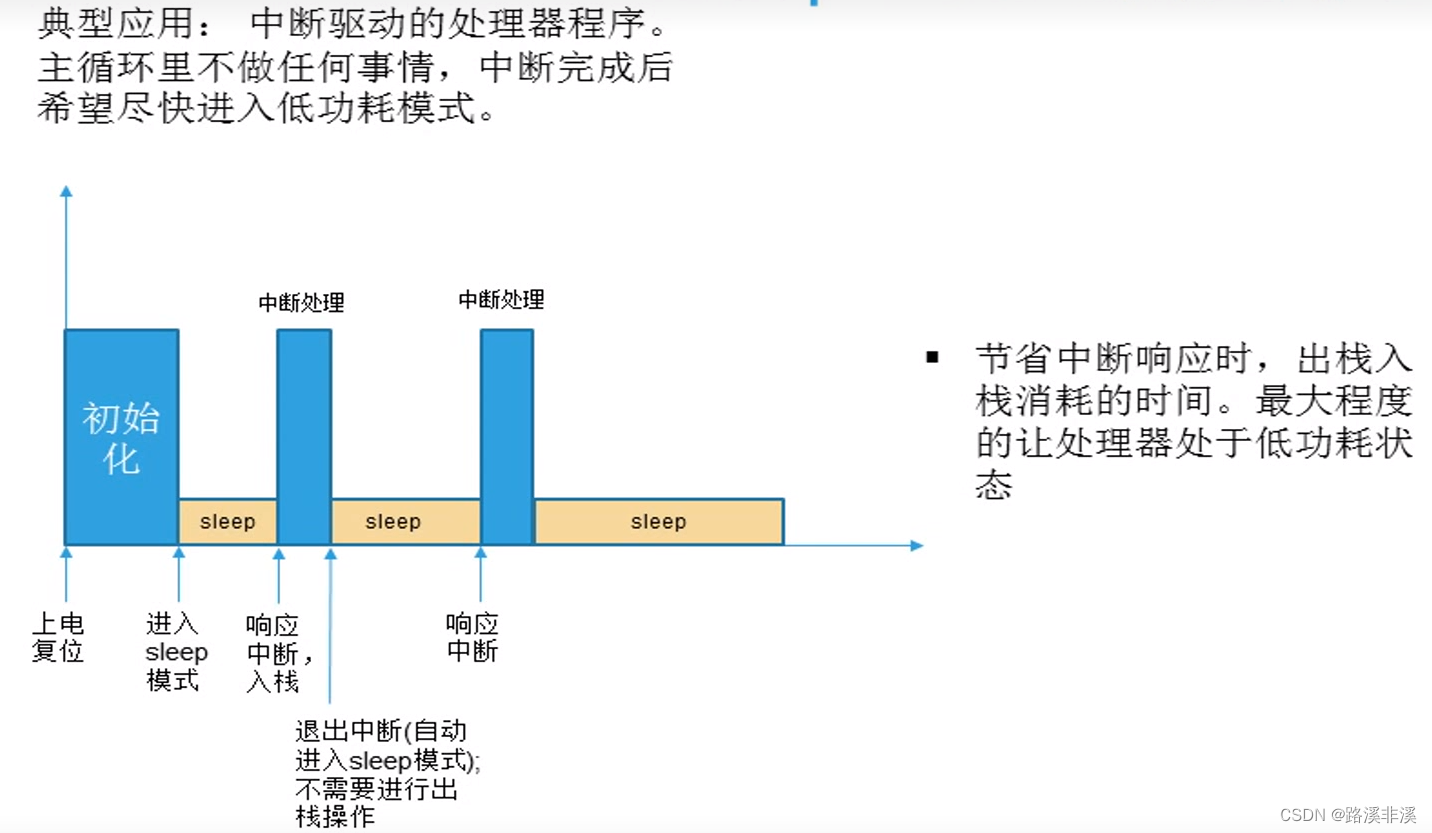
自动睡眠机制
典型应用
存储器保护单元MPU
MPU使命-关键系统
这种系统往往都用于性命攸关的场合,且必须连续无故障地工作,比如,火车调度系统、生命维持系统、大型发动机驱动器、核子反应堆控制、网络/电信的数据交换中枢等。如果失能,将导致惨重的经济与损失,甚至会使无数人死于非命。因此,决不允许这类系统出现
上述情况。然而,这些系统的复杂度往往都非常高,几乎不可能由开发人员保证这种可靠性。因此,需要在硬件水平上加入一个“公安机关”。通过它设置各种类型的“禁地”,并且施加多种规章条例。一旦发现违章,则强制改变执行流和处理器的工作状态,以便可以由软件做进一步的处理。这样,就可以为不同的程序限定一个内存使用范围,从而使野指针或恶意破坏无法影响不允许访问的区域。此即存储器保护单元(MPU)。
有时,对存储器的管理更进一步,做到可以对地址执行变换的程度,此时程序使用的地址未必是真实的存储器地址。它在 MPU 的基础上,还消灭了内存碎片和浪费,并且能进一步地让应用程序拥有方便舒适的地址空间,从而使程序规模可以扩大甚至数百倍。此即为“存储器管理单元”(MMU)。
关于单片机的MMU单片机中地址映射之后查看一个变量的地址是虚拟地址还是物理地址?都是物理地址,因为单片机没有MMU(至少Cortex-M系列没有)。单片机通常不使用虚拟内存技术,其寄存器地址是物理地址。单片机的内存和寄存器都是直接映射到硬件资源上的,没有使用虚拟内存的地址映射机制。一般有MMU的比如操作系统中,使用的都是虚拟地址。
在Cortex‐M3处理器中可以选配一个存储器保护单元(MPU),它可以实施对存储器(主要是内存和外设寄存器)的保护,以使软件更加健壮和可靠。在使用前,必须根据需要对其编程。如果没有启用MPU,则等同于系统中没有配MPU。MPU有如下的能力可以提高系统的可靠性:
阻止用户应用程序破坏操作系统使用的数据
阻止一个任务访问其它任务的数据区,从而把任务隔开。
可以把关键数据区设置为只读,从根本上消除了被破坏的可能。
检测意外的存储访问,如,堆栈溢出,数组越界。此外,还可以通过MPU设置存储器regions的其它访问属性,比如,是否缓区,是否缓冲等。
MPU在执行其功能时,是以所谓的“region”为单位的。一个region其实就是一段连续的地址,只是它们的位置和范围都要满足一些限制(对齐方式,最小容量等)。CM3的MPU共支持8个regions。怎么,嫌少?是少了点,不过,还允许把每个region进一步划分成更小的“子region”。此外,还允许启用一个“背景region”(即没有MPU时的全部地址空间),不过它是只能由特权级享用。在启用MPU后,就不得再访问定义之外的地址区间,也不得访问未经授权的region。否则,将以“访问违例”处理,触发MemManage fault。
补充
Cortex-M3 处理器有一个可配置引脚 BIGEND,用来选择小端格式或大端格式。 通常是以小端格式访问代码,小端格式是ARM 处理器的默认存储器格式。
Cortex-M3采用适合于微控制器应用的三级流水线,且增加了分支预测功能。
现代处理器大多采用指令预取和流水线技术,以提高处理器的指令执行速度。流水线处理器在正常执行指令时,如果碰到分支(跳转)指令,由于指令执行的顺序可能会发生变化,指令预取队列和流水线中的部分指令就可能作废,而需要从新的地址重新取指、执行,这样就会使流水线“断流”,处理器性能因此而受到影响。特别是现代C语言程序,经编译器优化生成的目标代码中,分支指令所占的比例可达10-20%,对流水线处理器的影响会的更大。为此,现代高性能流水线处理器中一般都加入了分支预测部件,就是在处理器从存储器预取指令时,当遇到分支(跳转)指令时,能自动预测跳转是否会发生,再从预测的方向进行取指,从而提供给流水线连续的指令流,流水线就可以不断地执行有效指令,保证了其性能的发挥。
ARM Cortex-M3内核的预取部件具有分支预测功能,可以预取分支目标地址的指令,使分支延迟减少到一个时钟周期。
ARM7、ARM9等内核使用不同的处理器状态分别执行32位的ARM指令和16位的Thumb指令,使用状态切换指令完成ARM状态和Thumb状态的切换。Cortex-M3使用更高效的Thumb2指令集,它是一种16/32位混合编码指令,兼容Thumb指令。对于一个应用程序编译生成的Thumb2代码,以接近Thumb编码的代码尺寸,达到了接近ARM编码的运行性能。Thumb2是一种紧凑、高效的新一代指令集。Thumb2指令集是面向高级语言的指令集,适合于C语言编程,由编译器生成目标代码,不建议直接使用Thumb2汇编语言编程。
32位硬件除法和单周期乘法
以往的ARM处理器没有除法指令,在某些除法密集型应用中性能不尽如意。Cortex-M3加入了32位除法指令,弥补了这一缺陷,使Cortex-M3可以和其他通用处理器一样,完成各种数学运算操作。
Cortex-M3还改进了乘法运算部件,32位x32位乘法操作只要一个时钟周期。这一性能使得使用Cortex-M3来进行乘、乘加运算时,已逼近DSP的性能,因此特别适合一些需要简单DSP的应用领域,如电机控制、数字滤波、FFT变换等。
需要指出的是,32位的乘/除运算,对于一个8位机而言,已经是一段比较复杂的程序,而对于32位的Cortex-M3而言,只需一句指令。因此,即使二者工作主频一样,实际运行性能也不是一个数量级的。
支持存储器非对齐访问
基于Cortex-M3的MCU,为提高性能,其内部存储器(Flash、RAM)都是32位编址的。这样当常量、变量是字节或半字类型时,如果处理器只支持对齐访问(以往的处理器都是如此),那么这些字节/半字类型的数据也必须被分配、占用一个32位的存储单元,这样就浪费了部分存储空间。
Cortex-M3支持存储器的非对齐访问,它可以访问存储在一个32位单元中的字节/半字类型数据,这样4个字节类型(或2个半字类型)数据可以被分配在一个32位的单元中,提高了存储器的利用率。对于一般的应用程序而言,这种技术可以节省约25%的SRAM使用量,从而可以选择SRAM较小、更廉价的MCU。
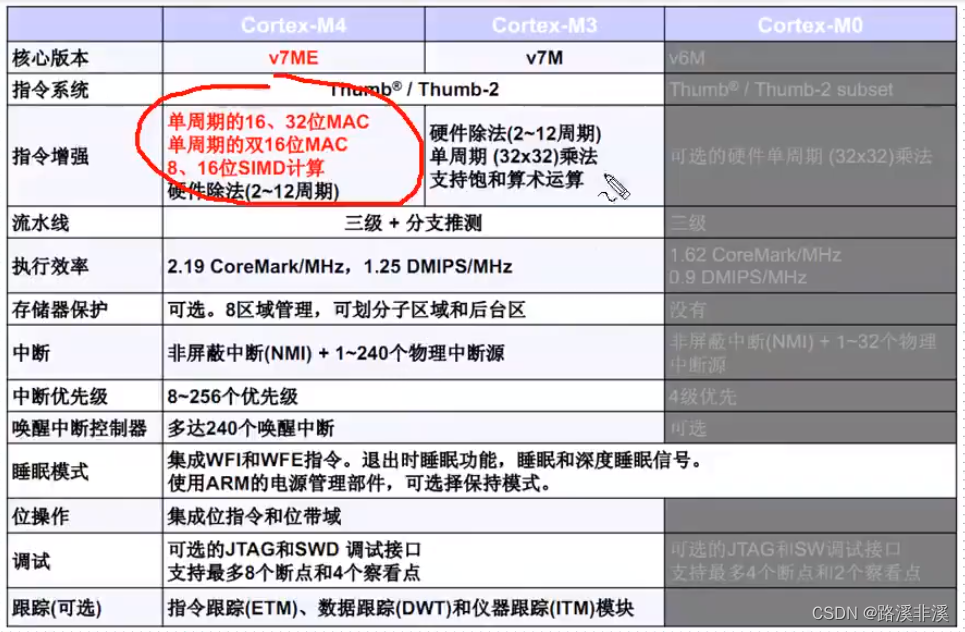
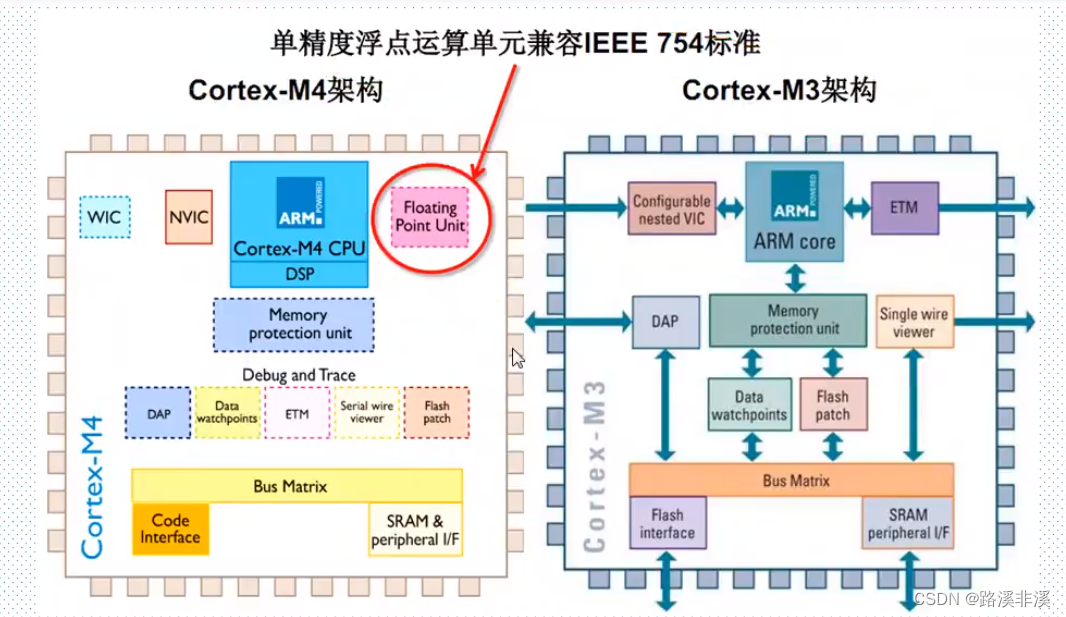
关于M4内核
相比于M3,在内核层面主要是增加了FPU和DSP
STM32F4采用Cortex-M4内核,相比Cortex-M3系列除了内置硬件FPU单元,在数字信号处理方面还增加了DSP指令集,支持诸如单周期乘加指令(MAC),优化的单指令多数据指令(SIMD),饱和算数等多种数字信号处理指令集。相比Cortex-M3,Cortex-M4在数字信号处理能力方面得到了大大的提升。Cortex-M4执行所有的DSP指令集都可以在单周期内完成,而Cortex-M3需要多个指令和多个周期才能完成同样的功能。
个人理解就是处理数据更快。